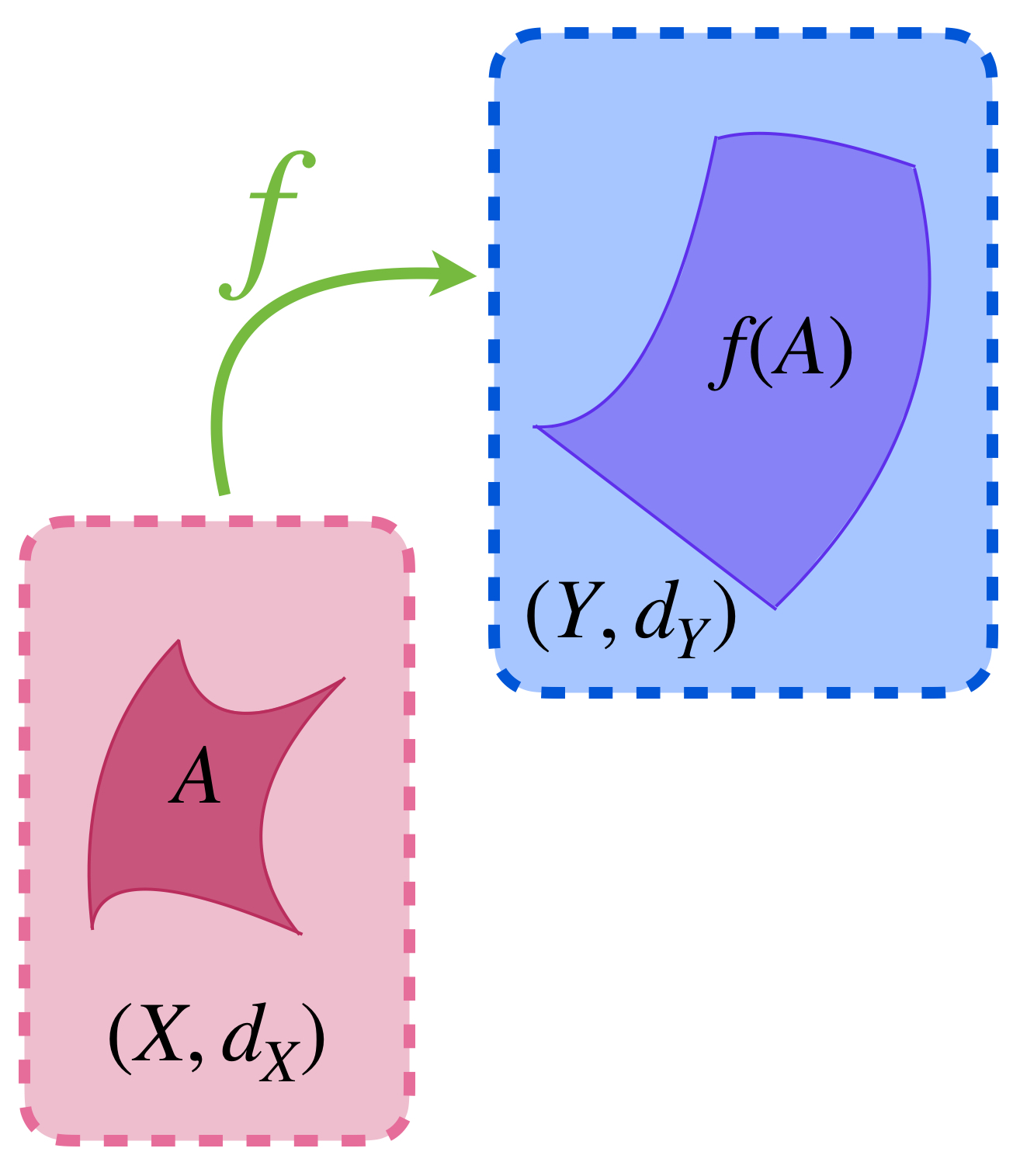
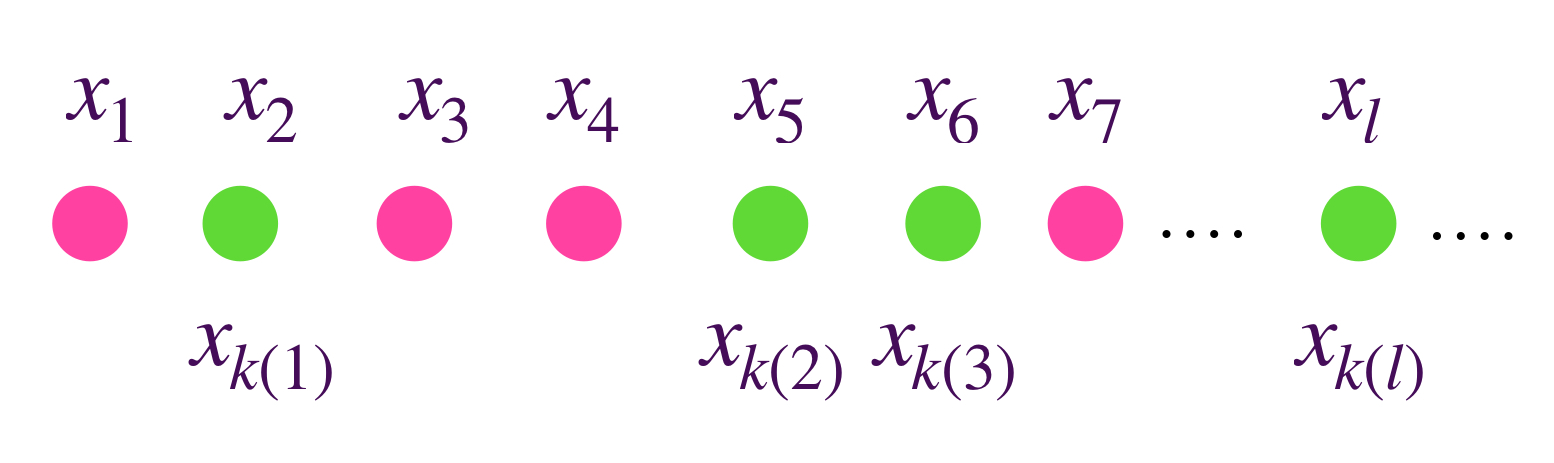Es momento de interactuar entre dos espacios métricos, $(X,d_X)$ y $(Y,d_Y)$, cada uno con su respectivo conjunto de puntos y métrica definida en ellos. Podemos relacionar puntos del espacio métrico $X$ con puntos en el espacio métrico $Y.$ Será natural preguntarse qué ocurre con las distancias en el nuevo espacio métrico, en comparación con el de origen. Considera la siguiente:
Definición. Imagen de un conjunto. Sean $(X,d_X)$ y $(Y,d_Y)$ espacios métricos. Si $A \subset X$ y $f: X \to Y$ es una función, entonces $f \,$ define un conjunto en $Y$ dado por $f(A):=\{f(x)|x\in A\}$, que llamaremos la imagen de $A$ bajo $f \,$ y es la colección de elementos que se le asignan a cada elemento de $A.$
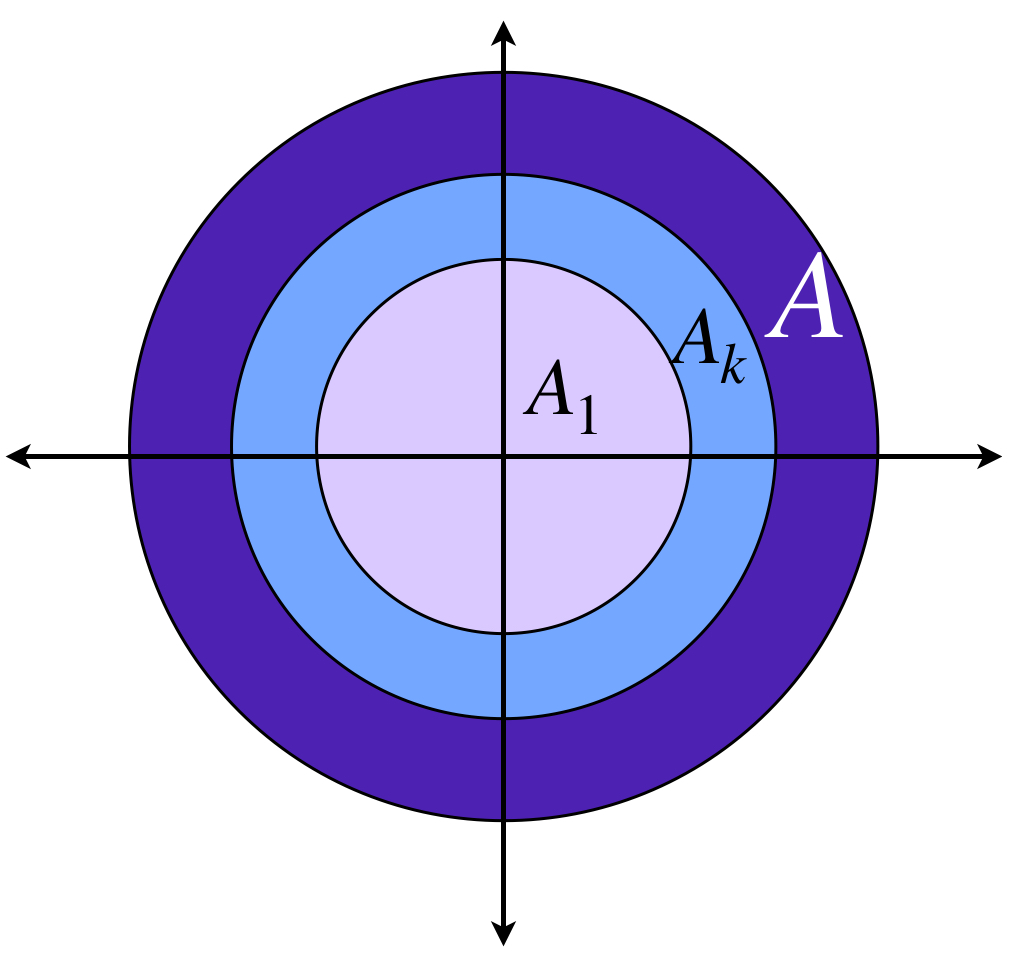
Representación del conjunto $f(A),$ el conjunto al que $A$ es enviado bajo $f.$
Ahora preguntamos: ¿bajo qué circunstancias una función envía puntos de $A \subset X$ a puntos en $Y$ que se aproximan a algún punto $L \in Y$?
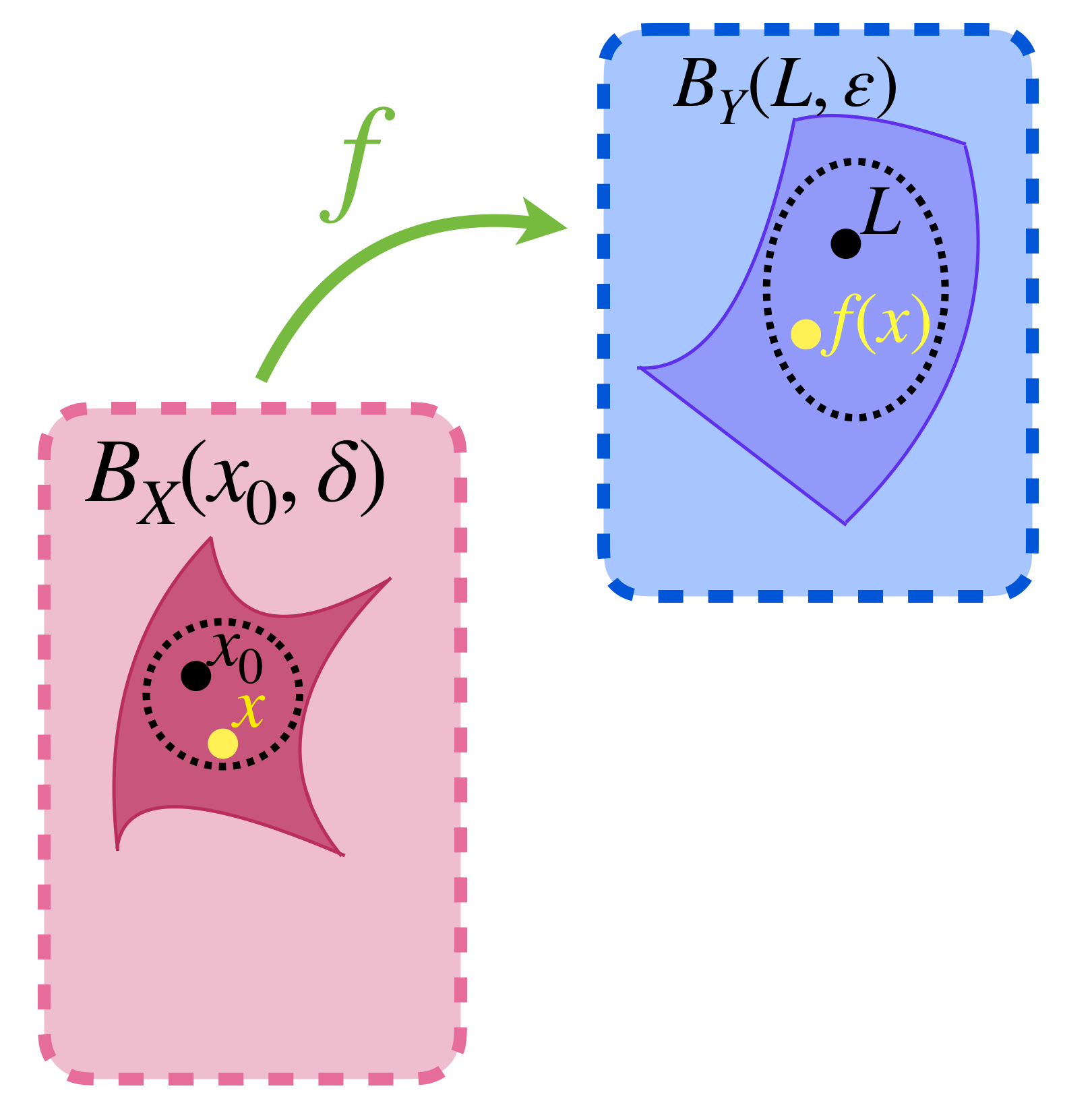
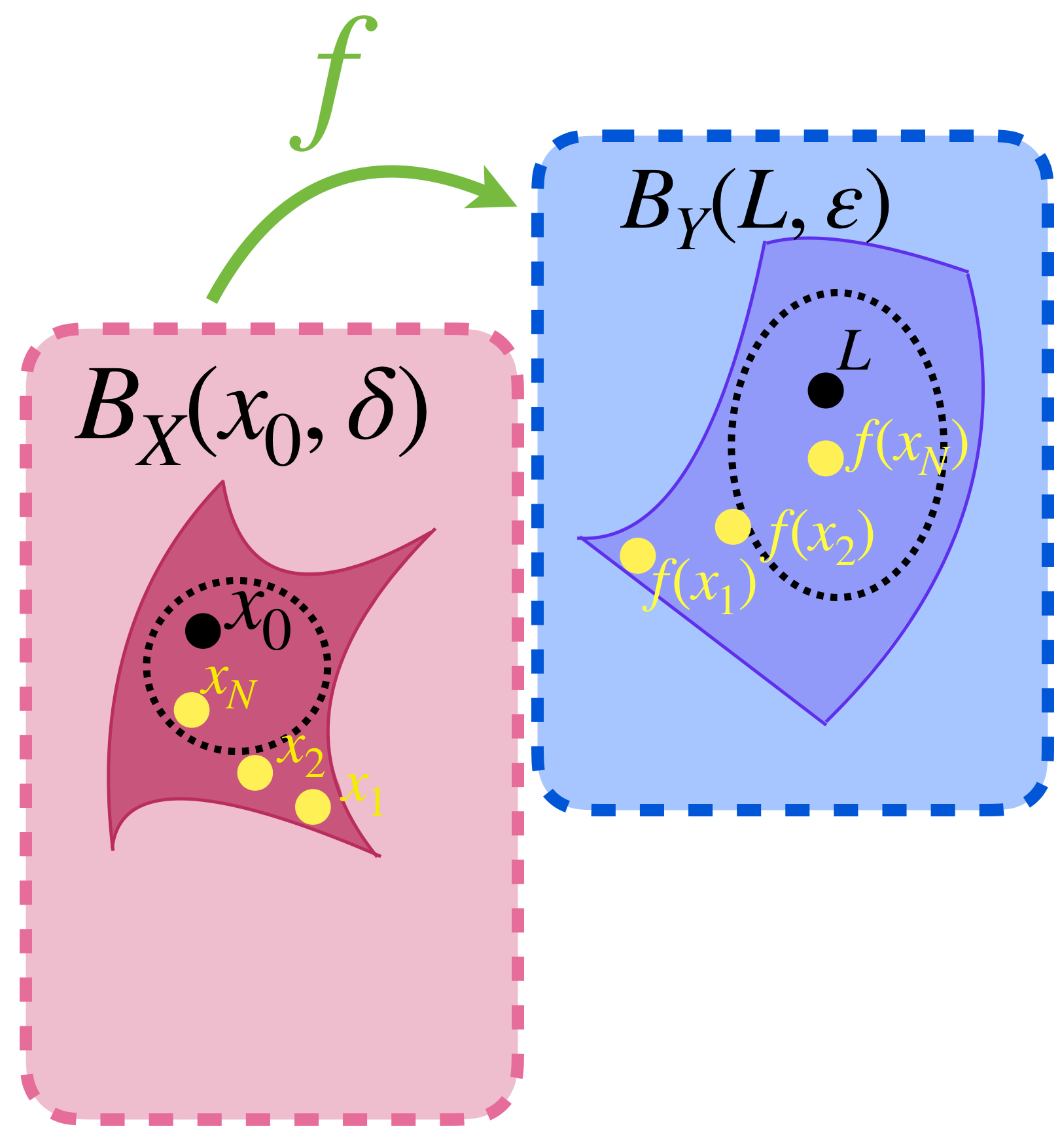
Si $x_0$ es un punto de acumulación en $A$, por definición, todas sus bolas abiertas tienen elementos en $A$ distintos de $x_0.$ Podemos así, identificar puntos cercanos a $x_0$, según la distancia $d_X$, que bajo la función $f$ sean enviados a puntos en $Y$ que estén cerca de un punto $L$, según la distancia $d_Y.$ Como los puntos cerca de $L$ en $(Y,d_Y)$ son los que están en la bola de radio $\varepsilon$ con centro en $L,$ se busca conseguir que los puntos cerca de $x_0$ caigan justamente en $B_Y(L,\varepsilon).$ (El subíndice $Y$ en $B_Y$ nos recuerda en qué espacio métrico es considerada la bola abierta. Recuerda que pueden ser diferentes, según la métrica a la que se refiera).
Un elemento de la bola abierta con centro en $x_0$ «cae dentro» de la bola abierta con centro en $L.$
De manera formal tenemos la siguiente:
Definición. Límite de una función. Sea $f: X \to Y$ una función entre espacios métricos y $x_0$ un punto de acumulación de $A.$ Decimos que el límite de $f$, cuando $x$ tiende al punto $x_0$ es $L \in Y$, si ocurre que para todo $\varepsilon >0$ existe $\delta > 0$ tal que para todo $x\neq x_0, \text{ si } d_X(x,x_0)< \delta$ entonces $\, d_Y(f(x),L)<\varepsilon.$ Se denota como: $$\underset{x \to x_0}{lim} \,f(x) \,:=L$$ Se dice entonces que $f(x) \to L$ cuando $x \to x_0.$
Esta definición se puede expresar en términos de bolas abiertas como sigue: $\, \underset{x \to x_0}{lim} \,f(x) \,=L \,$ si para todo $\varepsilon >0$ existe $\delta > 0$ tal que $f(B_X(x_0,\delta) \setminus \{x_0\}) \subset B_Y(L,\varepsilon).$
Veamos un resultado que nos permite concluir límites a partir de sucesiones.
Proposición. Considera $A \subset X$ y $x_0 \in A$ un punto de acumulación en $A.$ Entonces $$\underset{x \to x_0}{lim} \, f(x) \,=L$$ si y solo si para toda sucesión $(x_n)_{n \in \mathbb{N}}$ en $A \setminus \{x_0\}$ tal que $x_n \to x_0$ ocurre que $$\underset{n \to \infty}{lim} \, f(x_n) \,=L.$$ Demostración: Sea $(x_n)_{n \in \mathbb{N}} \,$ una sucesión en $A \setminus \{x_0\}$ que converge a $x_0 \,$ y sea $\varepsilon >0.$ Como $\underset{x \to x_0}{lim} \, f(x) \,=L$ entonces existe $\delta>0$ tal que para todo $x\neq x_0, \text{ si } d_X(x,x_0)< \delta \,$ entonces $\, d_Y(f(x),L)<\varepsilon.$
Si $(x_n) \to x_0 \,$ en $X \,$ entonces $(f(x_n)) \to L \,$ en $Y.$
Como $(x_n) \to x_0$, entonces existe $N \in \mathbb{N}$ tal que para todo $ \, n\geq N, \, d_X(x_n,x_0)< \delta$, así para todo $ \, n \geq N, \, d_Y(f(x_n),L) < \varepsilon$ por lo tanto $f(x_n) \to L\, $ en $\, Y.$
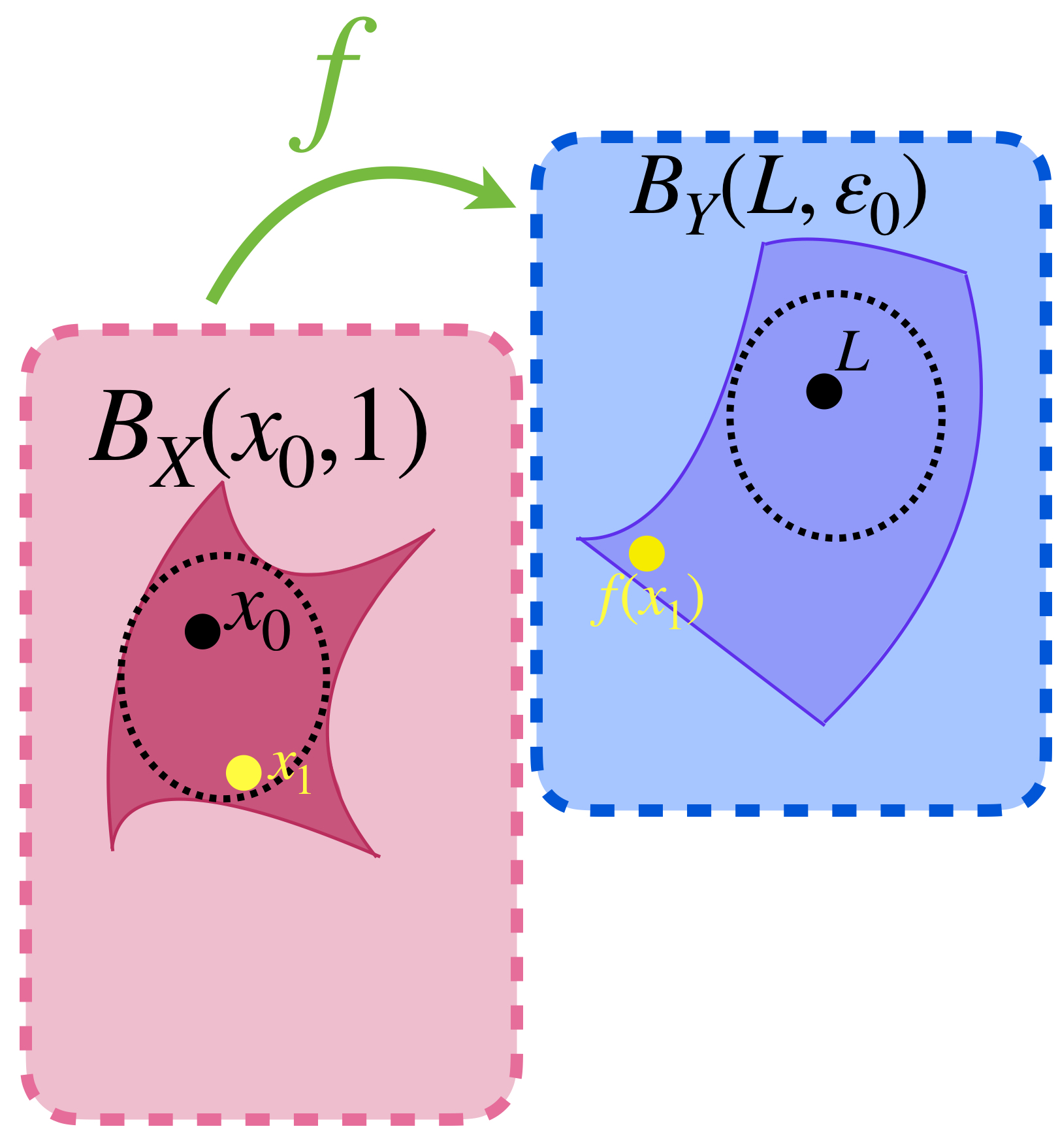
Ahora supón que el recíproco no es cierto. Entonces existe $\varepsilon_0 >0$ tal que para todo $ \, \delta>0$ existe $x_0 \neq x_0 \,$ con $\, d_X(x_0,x_0)<\delta$ pero $\, d_Y(f(x_0),L)> \varepsilon_0.$
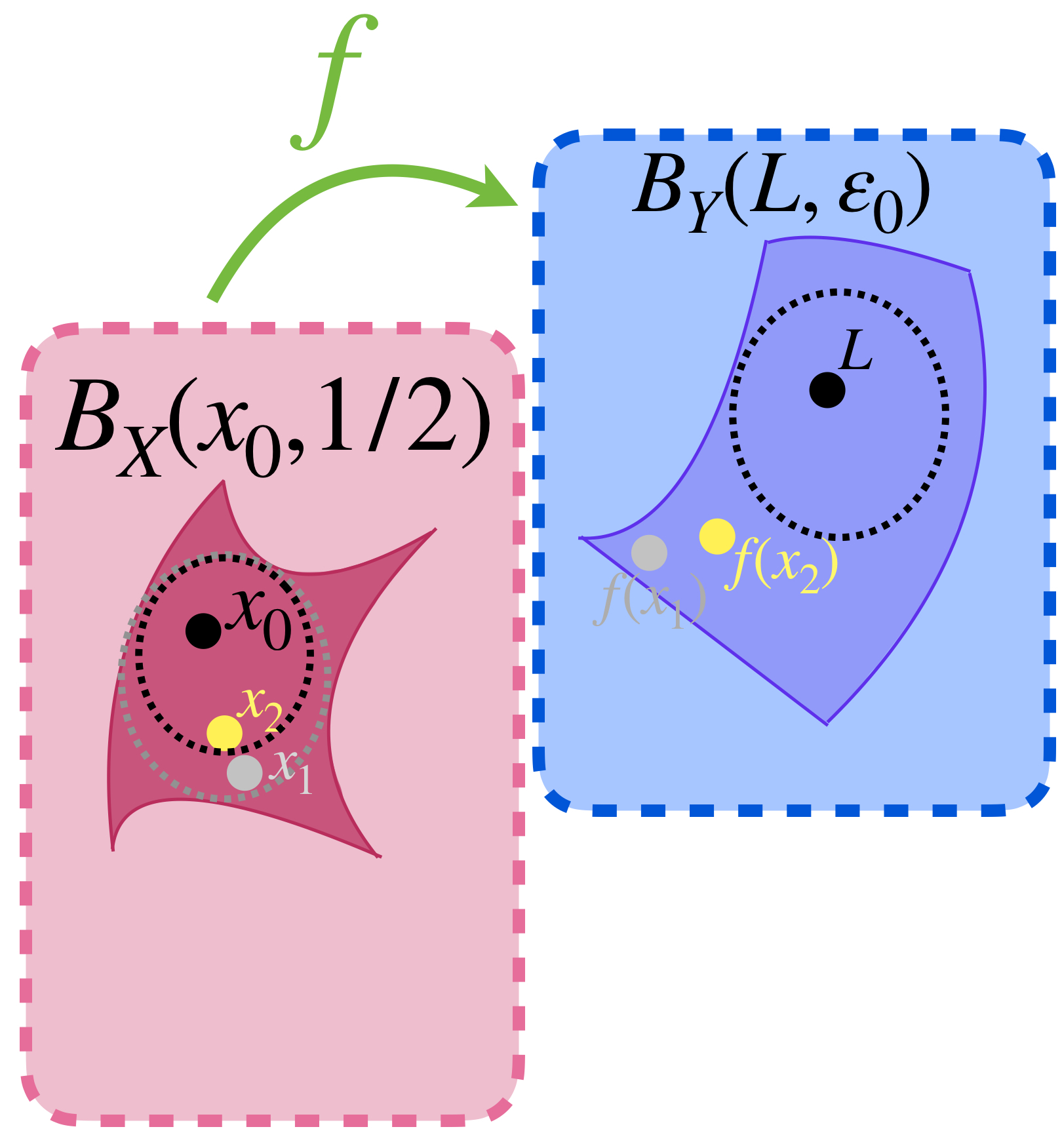
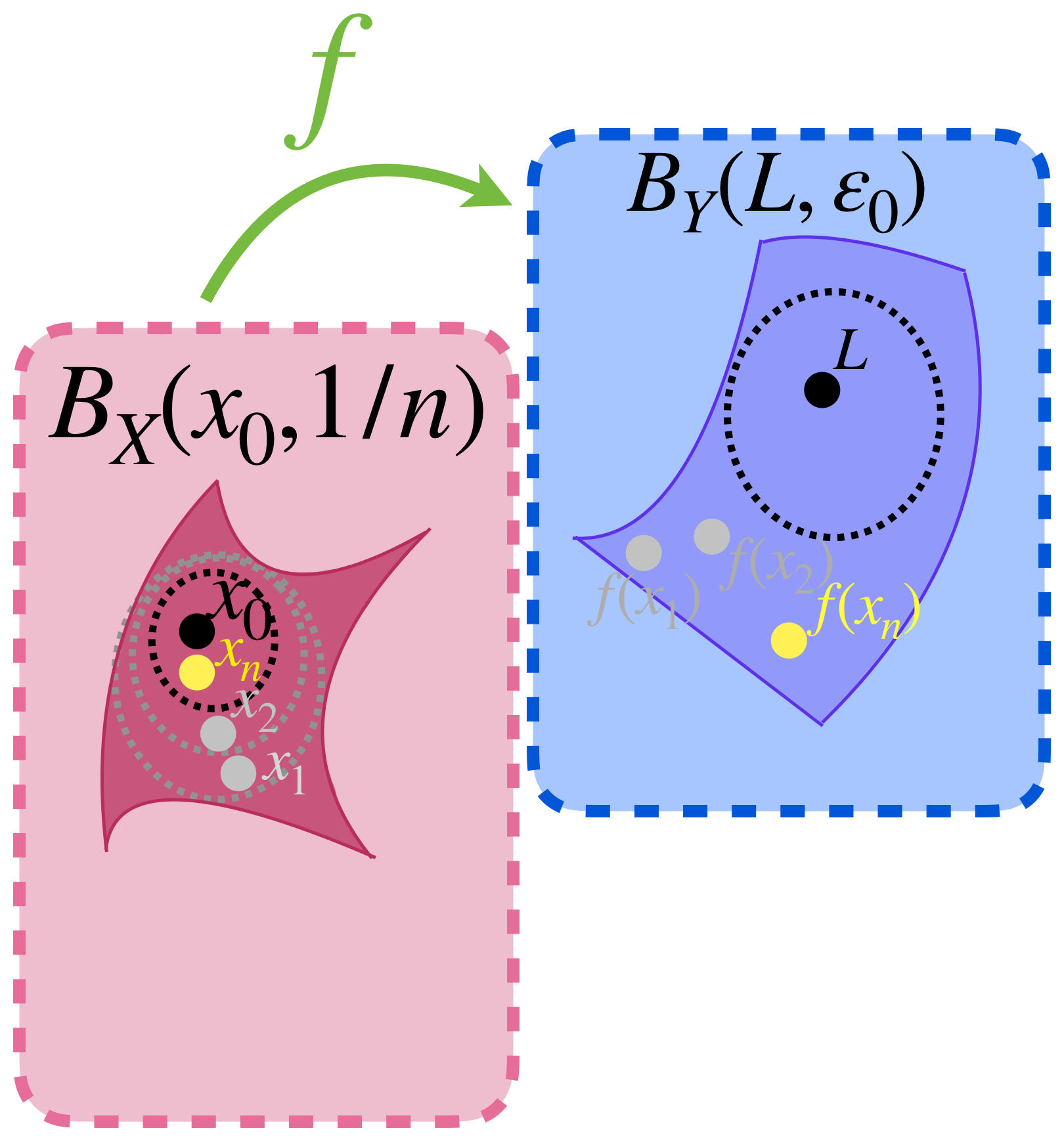
De modo que para cada bola abierta con centro en $x_0$ y radio $\frac{1}{n}$ con $n \in \mathbb{N}$ podemos elegir un punto $x_n \in (B_X(x_0,\frac{1}{n}) \setminus \{x_0\})$ pero $\, d_Y(f(x_n),L)> \varepsilon_0.$
Hay un punto en $B_X(x_0,1)$ que $f$ envía fuera de $B_Y(L,\varepsilon_0).$
La sucesión $x_n \to x_0 \,$ pero la sucesión $(f(x_n))_{n \in \mathbb{N}} \,$ al quedarse siempre fuera de la bola abierta $B_Y(L,\varepsilon_0)$ no converge a $L$, lo cual es una contradicción.
Hay un punto en $B_X(x_0,1/2)$ que $f$ envía fuera de $B_Y(L,\varepsilon_0).$
Por lo tanto $\, \underset{x \to x_0}{lim} \, f(x) \,=L.$
Hay un punto en $B_X(x_0,1/n)$ que $f$ envía fuera de $B_Y(L,\varepsilon_0).$
Las siguientes proposiciones son propiedades de límites de funciones en los espacios métricos mencionados:
Proposición. Sea $z \in \mathbb{C}$ con $z = a+bi$ donde $a,b \in \mathbb{R}.$ La métrica usual en los complejos es la inducida por la norma: $$\norm{z}:= \sqrt{a^2+b^2}.$$ Sean $f:A \to \mathbb{C}$ y $g:A \to \mathbb{C}.$ Si se definen Si se definen la suma de funciones como $$(f+g)(x):=f(x)+g(x)$$ y el producto de funciones como $$(f g)(x):=f(x)g(x)$$ entonces, si $x_0 \,$ es un punto de acumulación en $A$ y $\underset{x \to x_0}{lim}\, f(x) \,=L_1 \,$ y $\, \underset{x \to x_0}{lim}\, g(x) \,=L_2$, se tiene que:
a) $\underset{x \to x_0}{lim} \, f(x) \pm g(x) \,=L_1 \pm L_2.$ b) $\underset{x \to x_0}{lim} \, f(x)g(x) \,=L_1 L_2.$ c) $\underset{x \to x_0}{lim} \, f(x) / g(x) \,=L_1 / L_2$ cuando $L_2 \neq 0.$
La demostración se deja como ejercicio.
Proposición. Sean $f,g: A \subset X \to \mathbb{R}^n\, $ Si se definen la suma de funciones como $$(f+g)(x):=f(x)+g(x)$$ y el producto punto (o producto escalar) como $$(f \cdot g)(x):=f(x) \cdot g(x)$$ entonces, si $x_0 \,$ es un punto de acumulación en $A$ y $\underset{x \to x_0}{lim}\, f(x) \,=L_1 \,$ y $\, \underset{x \to x_0}{lim} \,g(x) \,=L_2$, se tiene que:
Nota que no hemos evaluado la función en $x_0,$ la definición no necesita siquiera que la función esté definida ahí. La próxima vez veremos el caso en que la función sí está definida en $x_0 \in A \subset X$ y más aún, tiene como límite al punto $f(x_0).$ Hablaremos así de funciones continuas en un punto $x_0$ y observaremos el efecto que estas funciones producen en subconjuntos abiertos y cerrados de un espacio métrico.
En esta entrada vamos a ver una forma de definir distancias (sí, de nuevo) pero ahora no directamente entre los elementos de un conjunto, sino entre los subconjuntos de un espacio métrico. Entonces, los subconjuntos pasarán a ser vistos como elementos de un nuevo espacio con cierta métrica. Al final haremos sucesiones de conjuntos. Descubriremos bajo qué condiciones estas sucesiones de conjuntos convergen. Será emocionante descubrir que dos conjuntos están cerca uno de otro, cuando son muy parecidos entre sí (en forma y tamaño).
El contenido a exponer se basa predominantemente en el libro «A course in Metric Geometry», escrito por Dmitri Burago, Yuri Burago y Sergei Ivanov (páginas 252 y 253). Omitiremos las demostraciones de las proposiciones, pues no son parte de los objetivos del curso. El lector puede consultarlas en el libro mencionado si así lo desea.
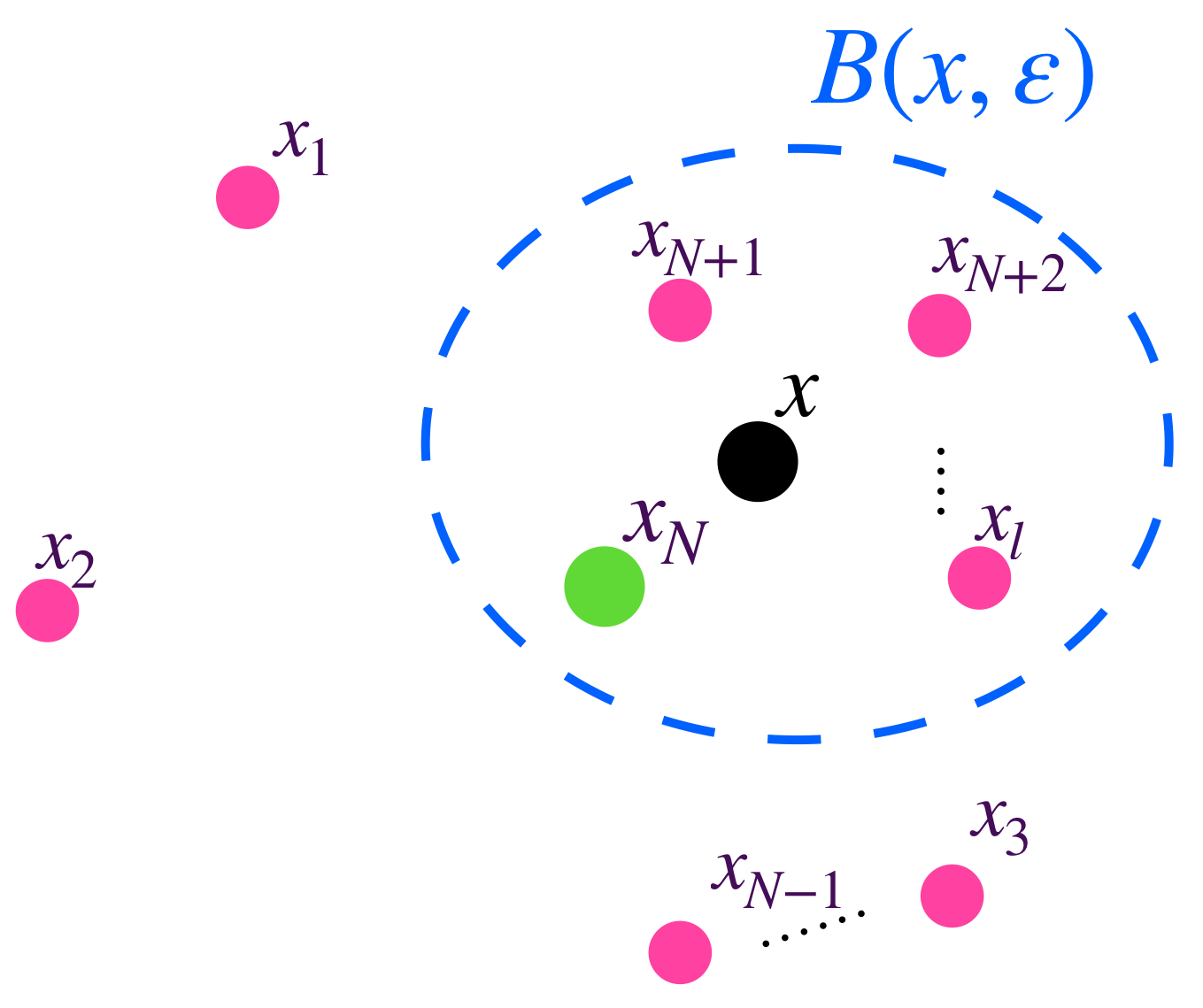
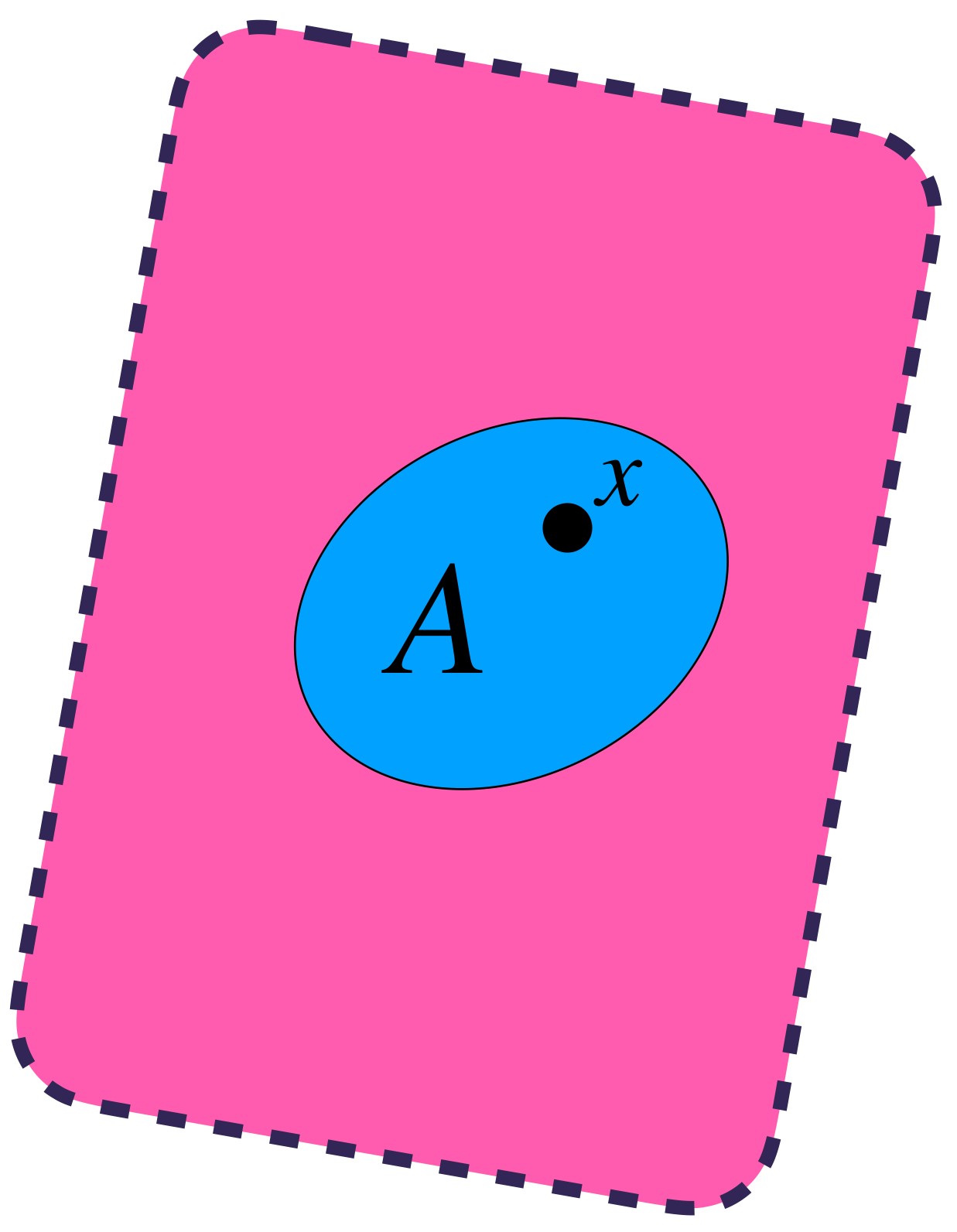
Sea $(X,d)$ un espacio métrico. Visualiza un conjunto $A \subset X$ y un punto arbitrario $x \in A.$
$x$ está en $A.$
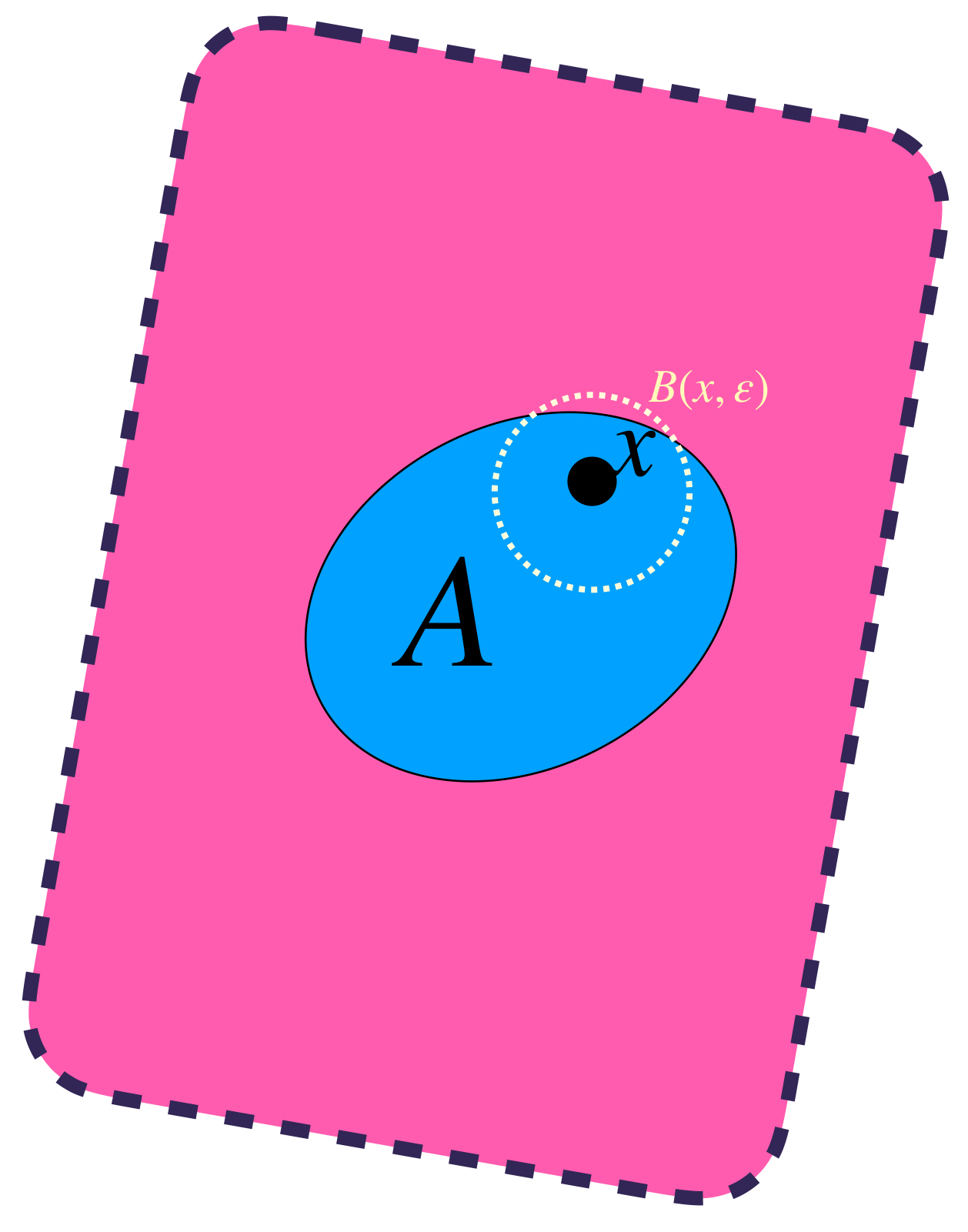
Sea $\varepsilon >0.$ Este valor define a $B(x,\varepsilon).$
$x$ está en la bola de radio $\varepsilon.$
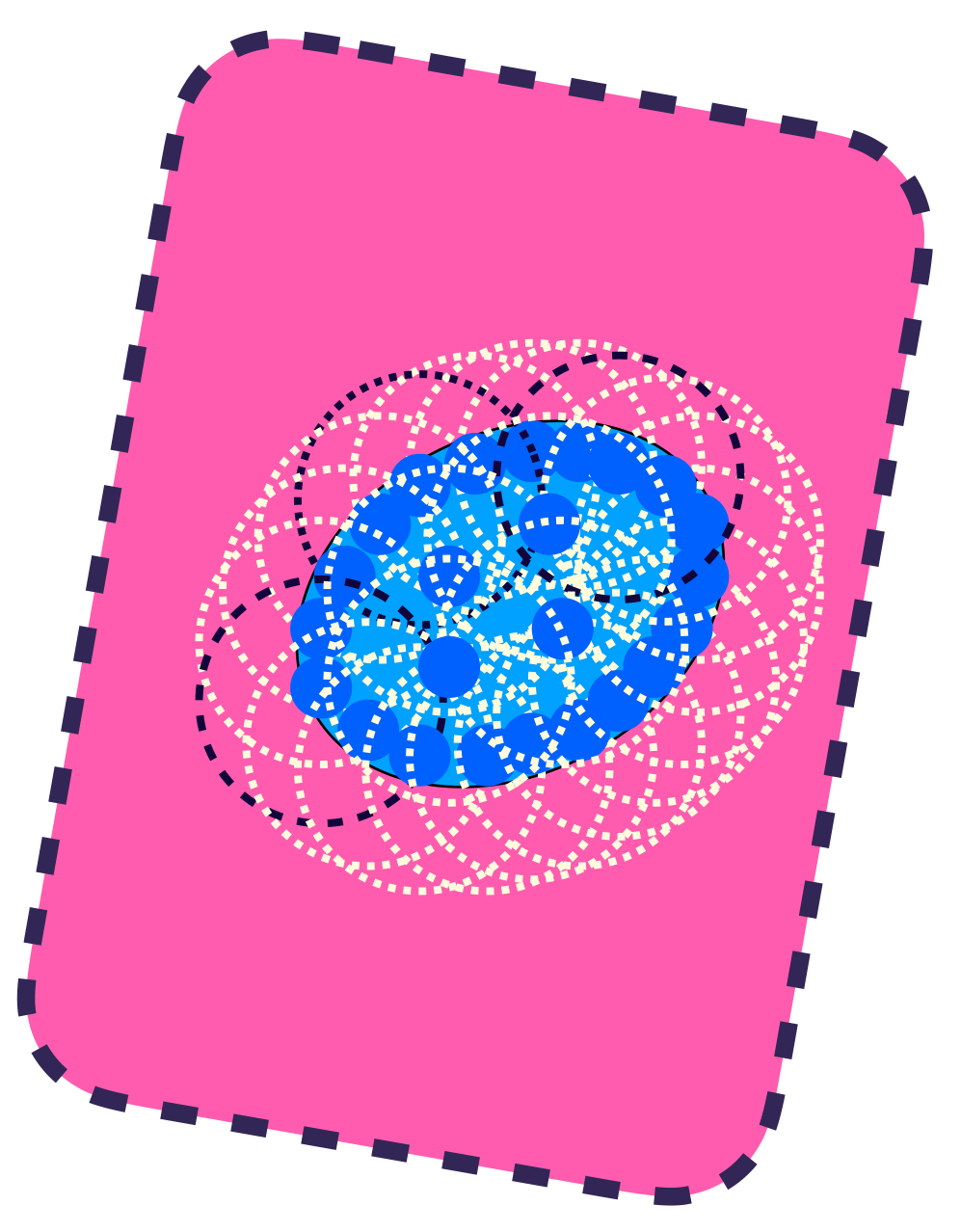
Visualiza la unión de todas las bolas de radio $\varepsilon.$ Definimos el conjunto $U_\varepsilon(A) := \underset{x\in A}{\cup}B(x,\varepsilon).$ Nota que este conjunto contiene al conjunto $A.$
Todas las bolas de radio $\varepsilon$ con centro en un punto de $A.$
El conjunto $U_\varepsilon(A)$ es la unión de todas las bolas.
Asímismo, todos los elementos de $U_\varepsilon(A)$ distan en menos que $\varepsilon$ a algún elemento de $A$, pues están en una de las bolas de radio $\varepsilon.$
Un punto $y$ en $U_\varepsilon(A)$ tiene distancia menor que $\varepsilon$ a un punto en $A.$
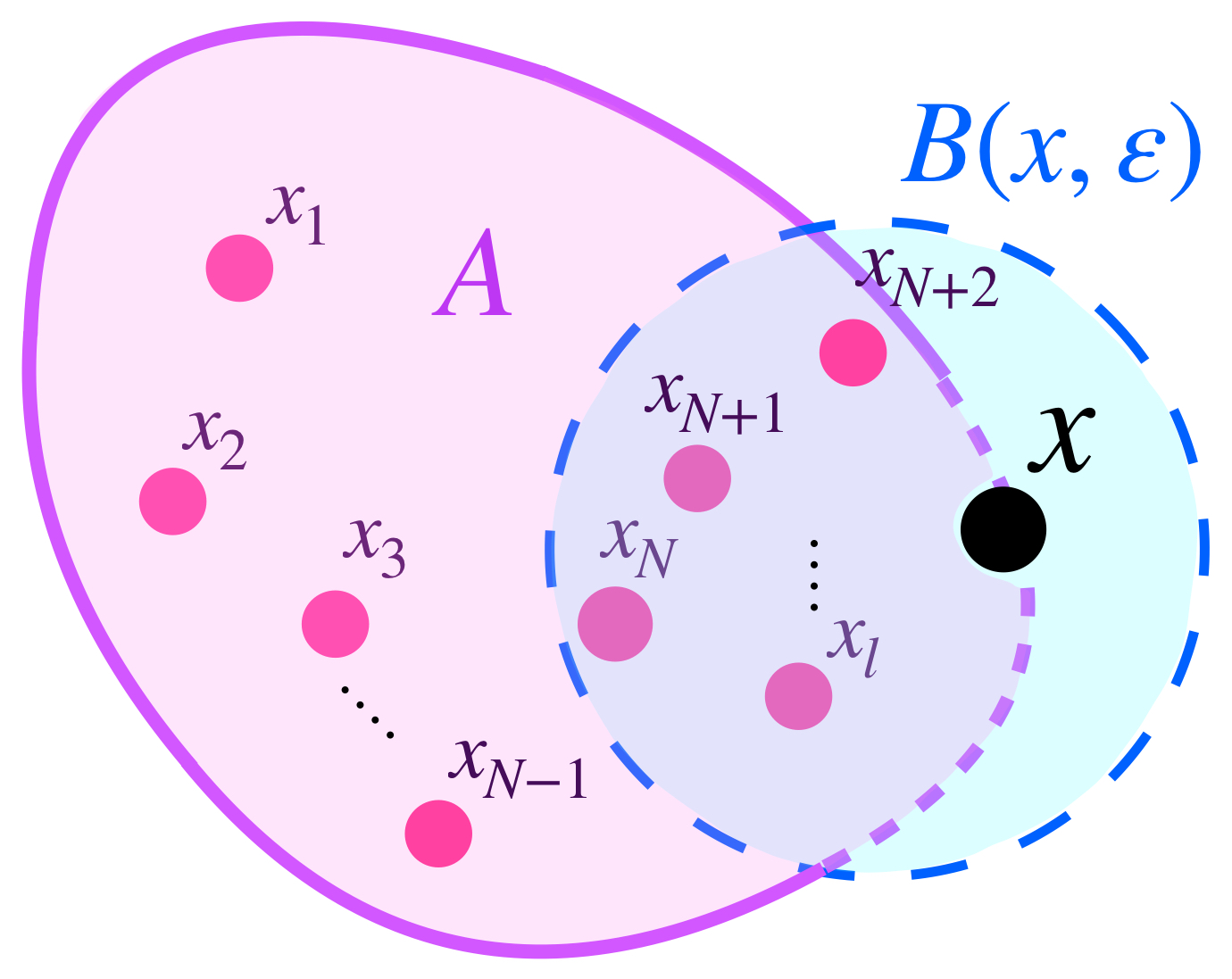
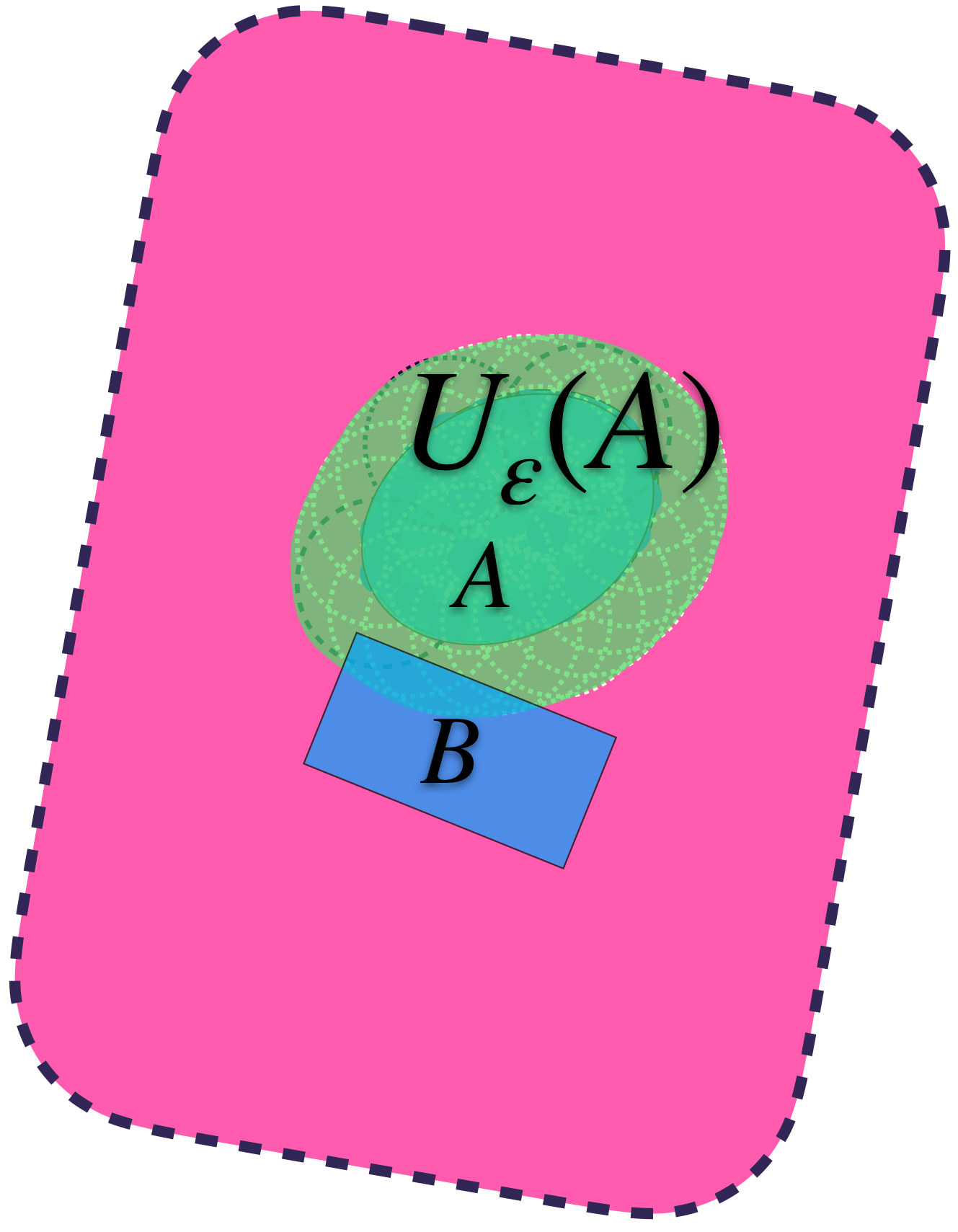
Pensemos ahora en los conjuntos definidos de esta forma en $A$ pero buscando que también contengan a un conjunto $B \subset X$
Se puede dar el caso en que aunque $U_\varepsilon(A)$ contiene a $A,$ no contiene al conjunto $B.$
$U_\varepsilon(A)$ no cubre a $B$ completamente.
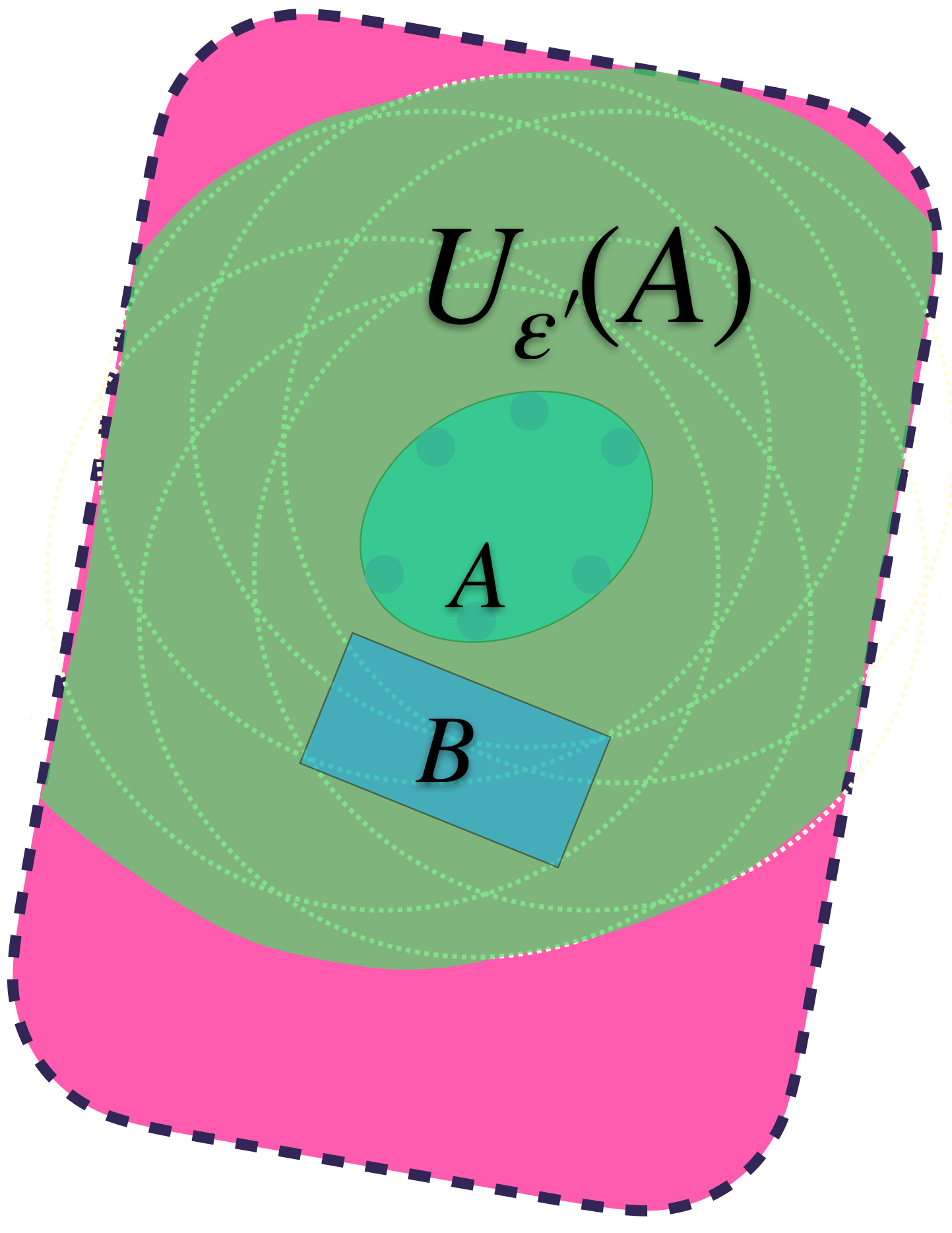
Identificando valores para $\varepsilon >0$ suficientemente grandes, se logra la contención deseada:
$U_{\varepsilon’}(A)$ también contiene a $B.$
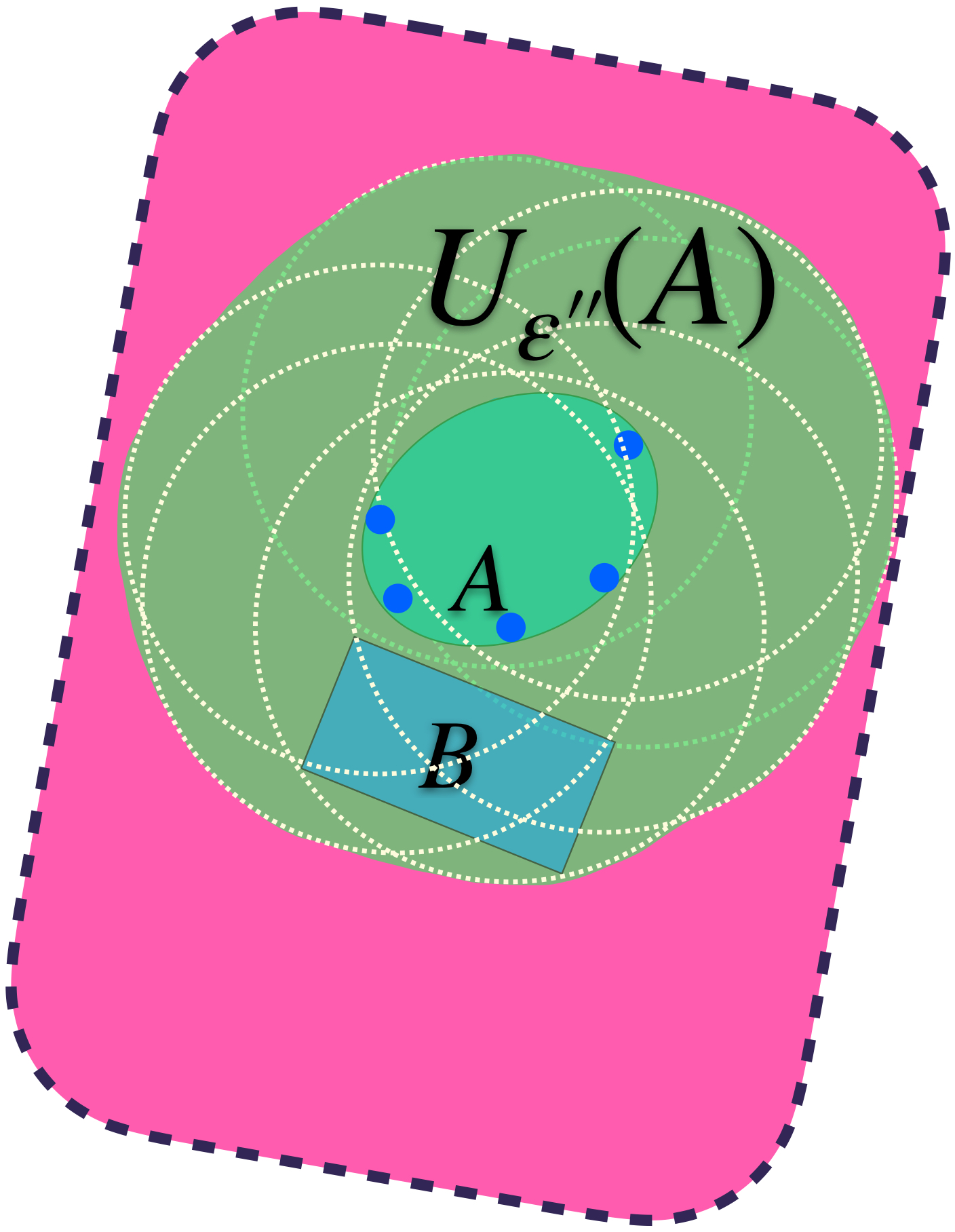
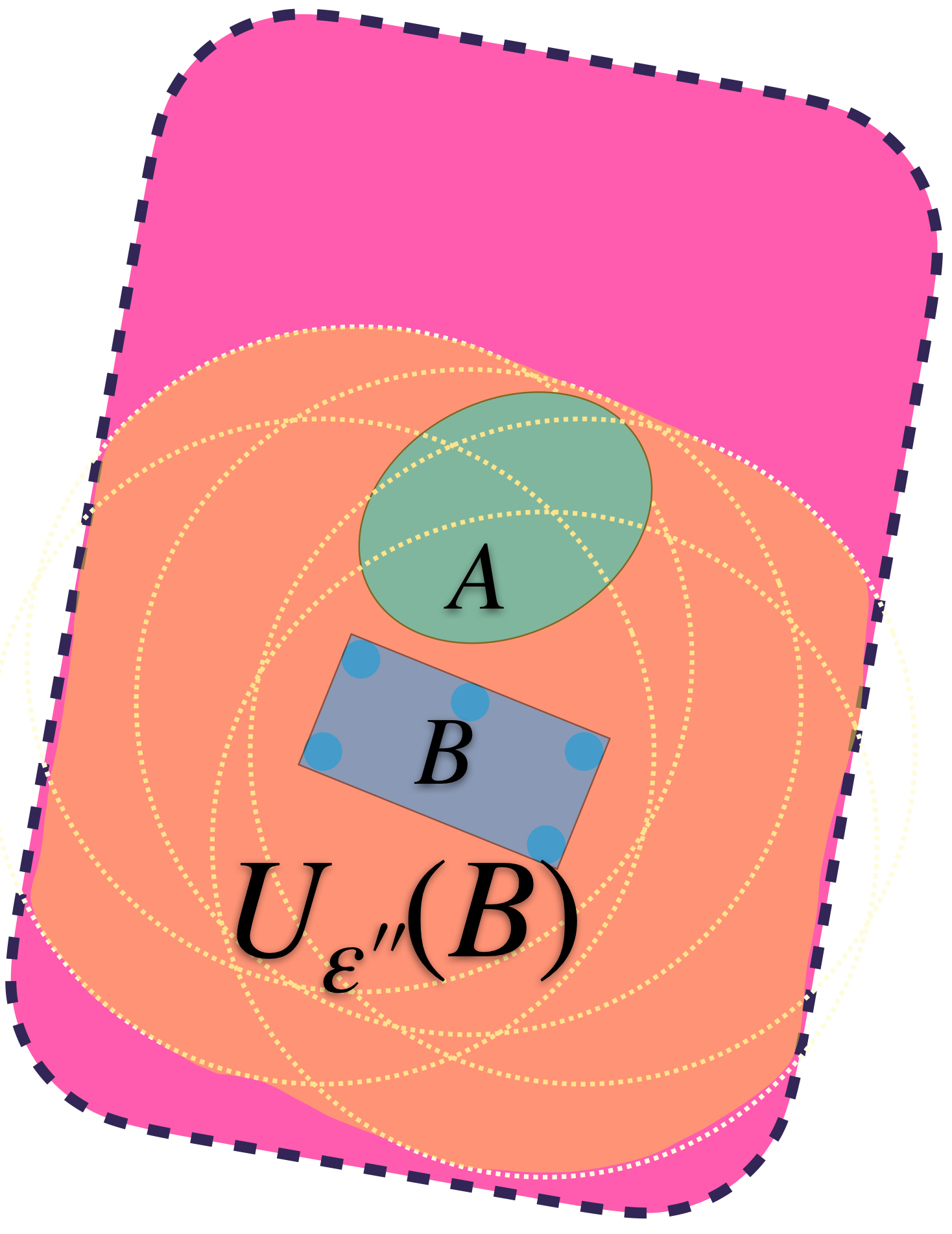
Podemos identificar al ínfimo de los $\varepsilon$´s $>0$ y encontrar así un conjunto $U_{\varepsilon´´}(A)$ más ajustado pero que sigue conteniendo a ambos conjuntos.
$U_{\varepsilon´´}(A)$ es el conjunto más pequeño que cubre lo deseado.
Análogamente, vamos a identificar los conjuntos $U_\varepsilon(B)$ que también contienen a $A.$
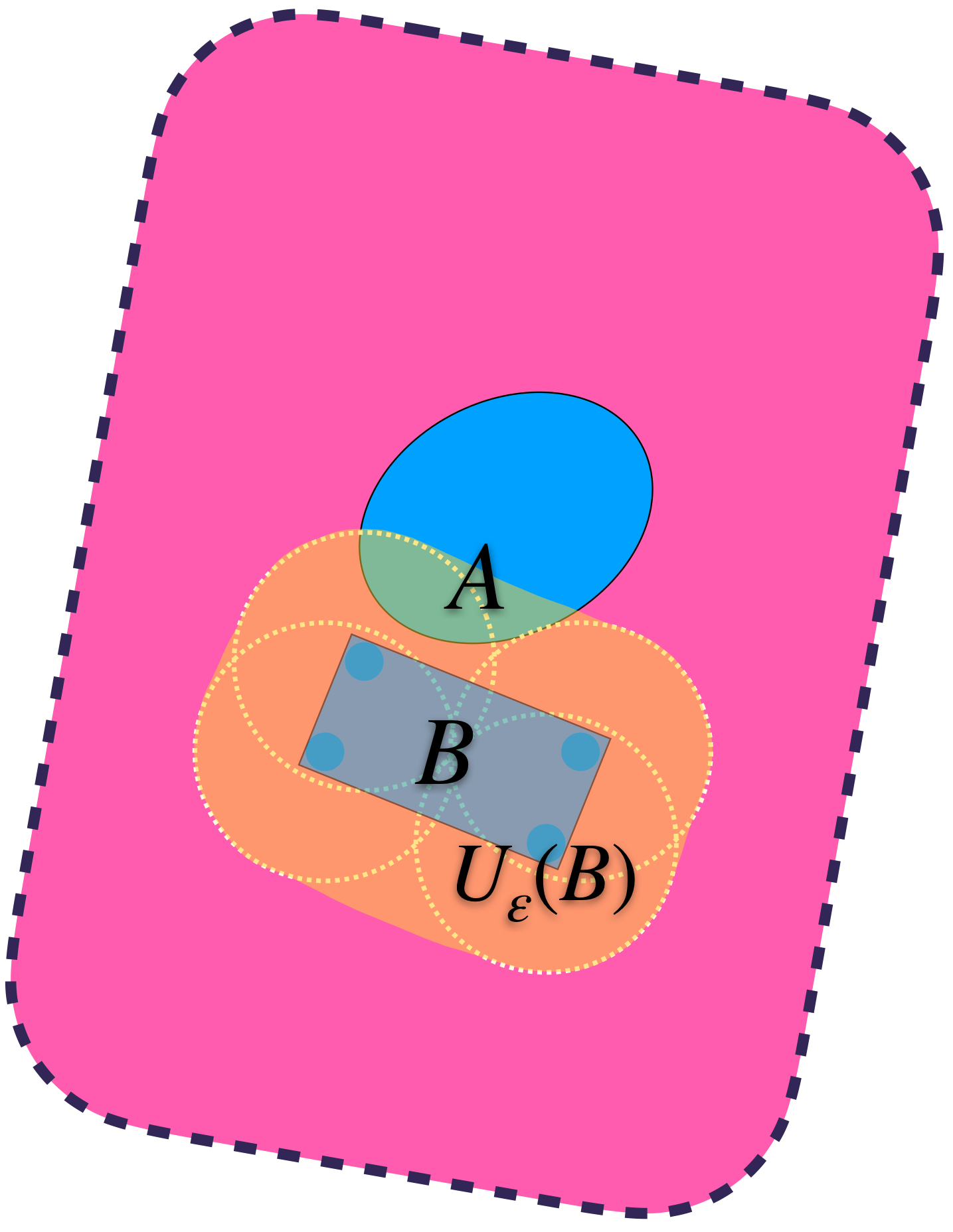
Se puede dar el caso en que aunque $U_\varepsilon(B)$ contiene a $B,$ no contiene al conjunto $A.$
$U_\varepsilon(B)$ no cubre a $A$ completamente.
Identificando valores para $\varepsilon >0$ suficientemente grandes, se logra la contención deseada:
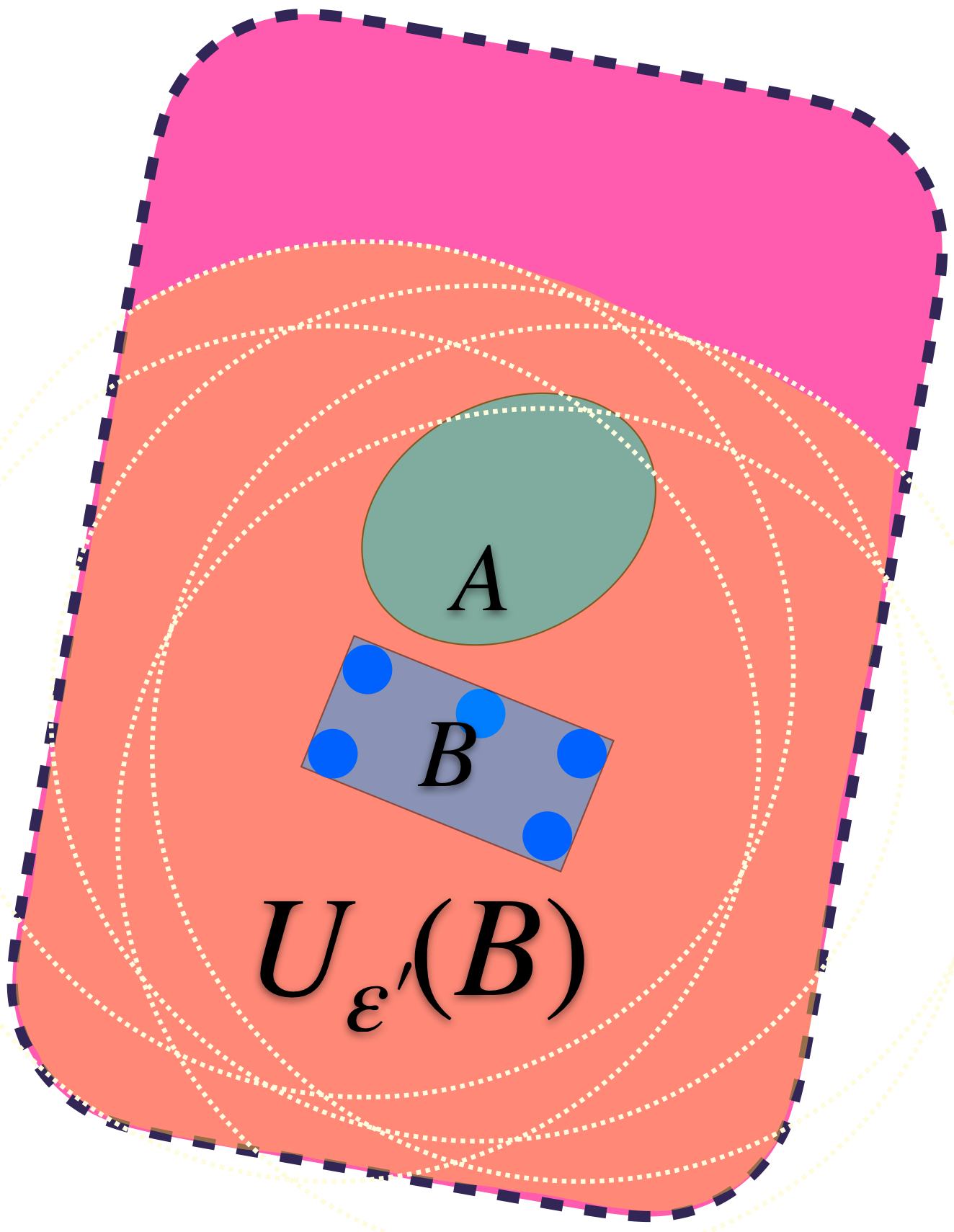
$U_{\varepsilon’}(B)$ también contiene a $A.$
Podemos identificar al ínfimo de los $\varepsilon$´s $>0$ y encontrar así un conjunto $U_{\varepsilon´´}(B)$ más ajustado pero que sigue conteniendo a ambos conjuntos.
$U_{\varepsilon´´}(B)$ es el conjunto más pequeño que cubre lo deseado.
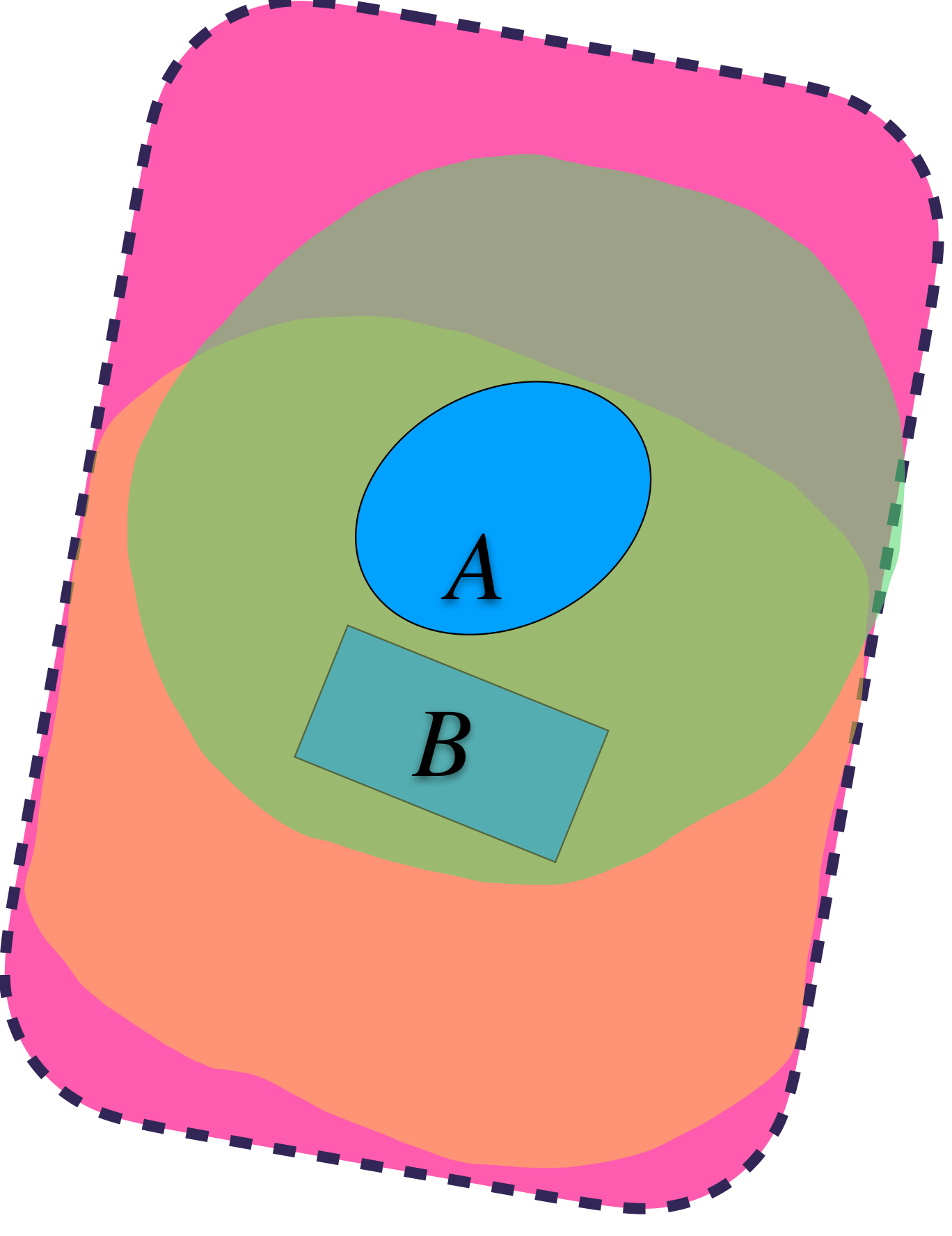
Si seleccionamos al ínfimo de los $\varepsilon$’s tales que ambos conjuntos quedan contenidos de la forma $A \subset U_\varepsilon(B)$ y $B \subset U_\varepsilon(A).$ Podemos definir la distancia de Hausdorff entre $A$ y $B$ como ese ínfimo. Formalmente: $$d_H(A,B) := inf \{\varepsilon>0 \, | \, A \subset U_\varepsilon(B) \, \text{ y }\, B \subset U_\varepsilon(A) \}$$
$A \subset U_\varepsilon(B) \,$ y $\, B \subset U_\varepsilon(A).$
Sean $A\subset X, \,$ $B\subset X$ y $\varepsilon >0.$ Si definimos $\text{dist}(a,B) := \underset{b \in B}{inf} \, d(a,b)$ para cada $a \in A$ y análogamente $\text{dist}(b,A) := \underset{a \in A}{inf} \, d(a,b)$ para $b \in B$ entonces las siguientes son propiedades de la distancia de Hausdorff.
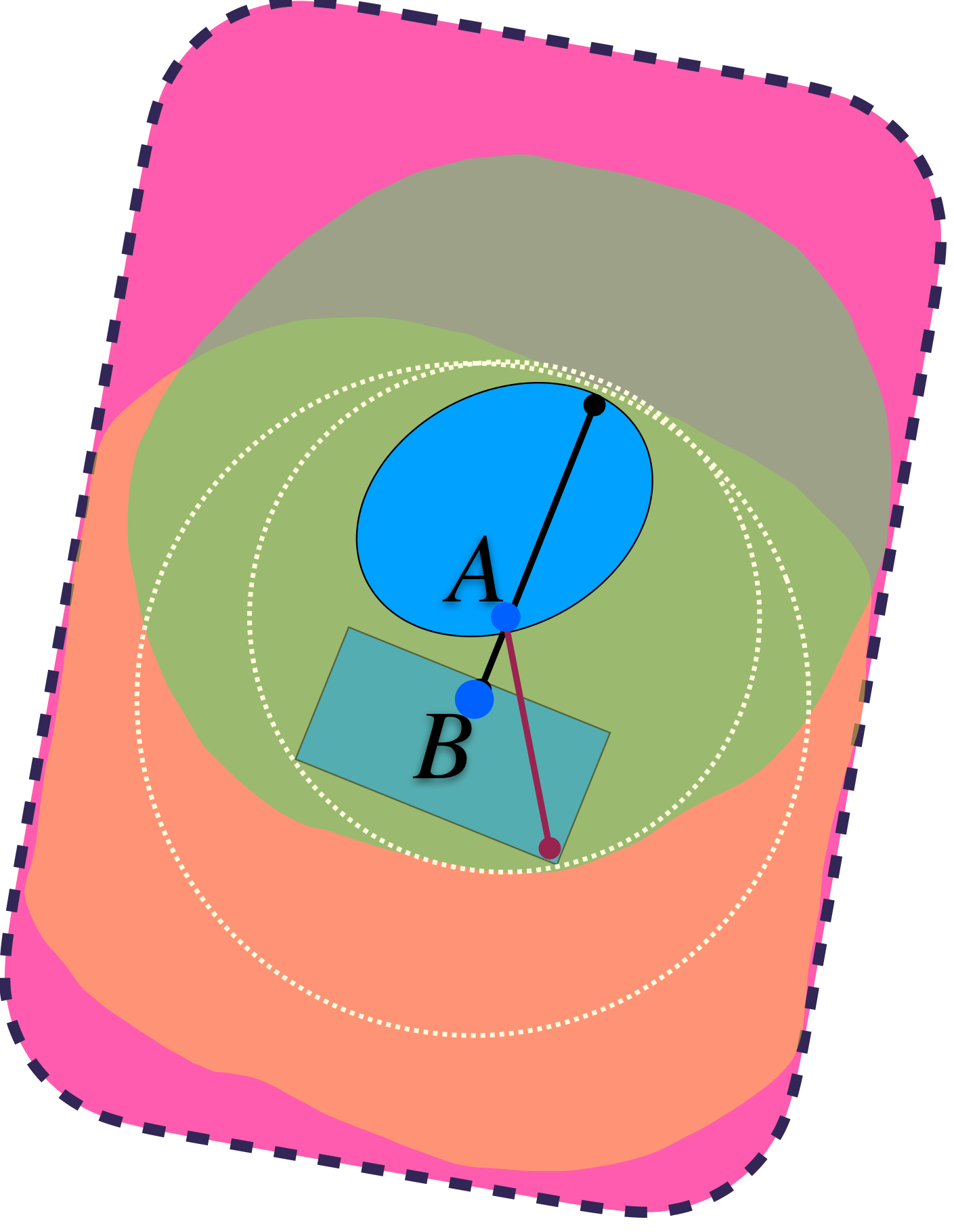
Las líneas señalan las distancias «más grandes» que hay de algún punto de $A$ al conjunto $B$ y de un punto de $B$ al conjunto $A.$ Se garantiza que el máximo define el radio de las bolas que hace que los dos conjuntos $U_{\varepsilon}(A)$ y $U_{\varepsilon}(B)$ contengan tanto a $A$ como a $B.$
b) $d_H(A,B) \leq \varepsilon$ si y solo si para todo $a \in A,$ $\text{dist}(a,B) \leq \varepsilon$ y para todo $b \in B, \, \text{dist}(b,A) \leq \varepsilon.$ Esto puede no ocurrir si cambiamos «$\leq$» por «$<$».
Anteriormente hemos hablado de la definición de una función acotada (Espacios de funciones) y de una sucesión acotada (Convergencia), veamos esta definición de un modo más general:
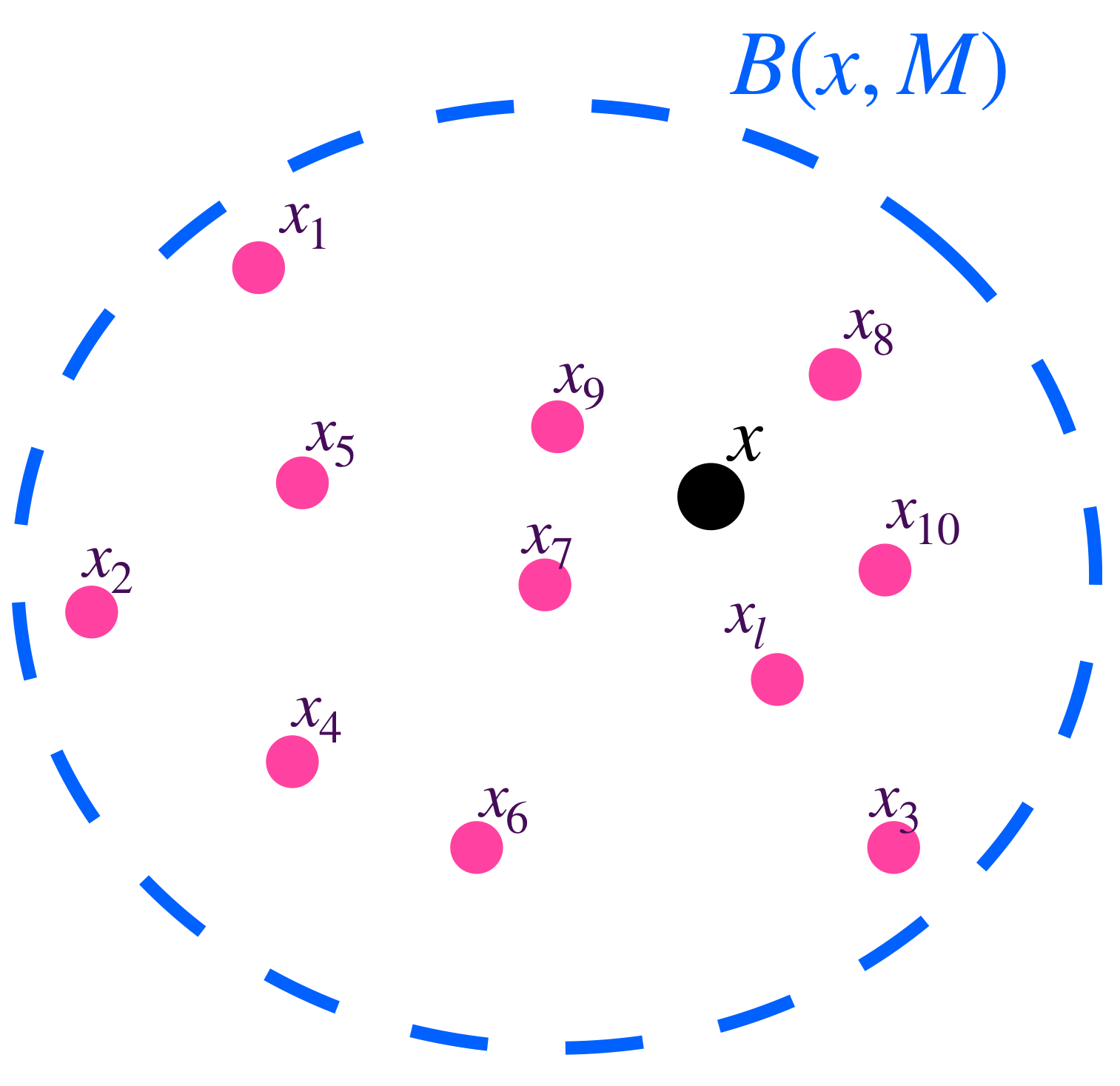
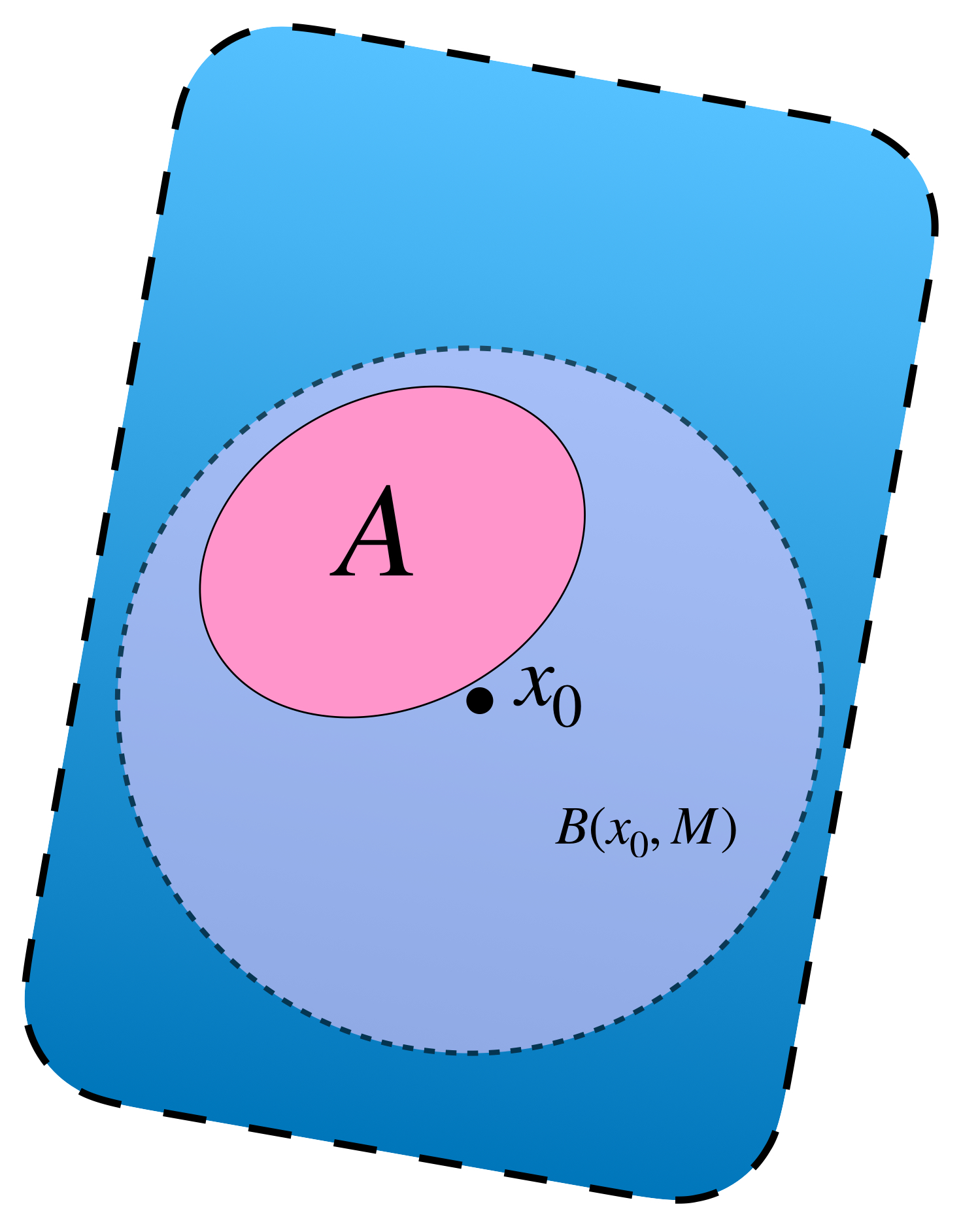
Definición. Conjunto acotado. Sea $A \subset X$ decimos que $A$ es un conjunto acotado en $X$ si existe un punto $x_0 \in X$ y $M >0$ tal que para toda $x \in A$ se cumple que $d(x,x_0)<M.$ Nota que esto es equivalente a decir que $A \subset B(x_0,M).$
$A$ es acotado si está contenido en $B(x_0,M).$
Proposición. Si $(X,d)$ es un espacio métrico, entonces $d_H$ define una métrica en el conjunto de conjuntos cerrados y acotados $\mathcal{M}(X):=\{F \subset X: F \text{ es cerrado y acotado}\}.$ (En el libro de Burago la métrica puede tomar el valor infinito, en ese sentido $d_H \,$ también sería una métrica en el conjunto de los subconjuntos cerrados de $X$, incluyendo los no acotados).
Eso significa que $A,B \in \mathcal{M}(X)$ cumplen:
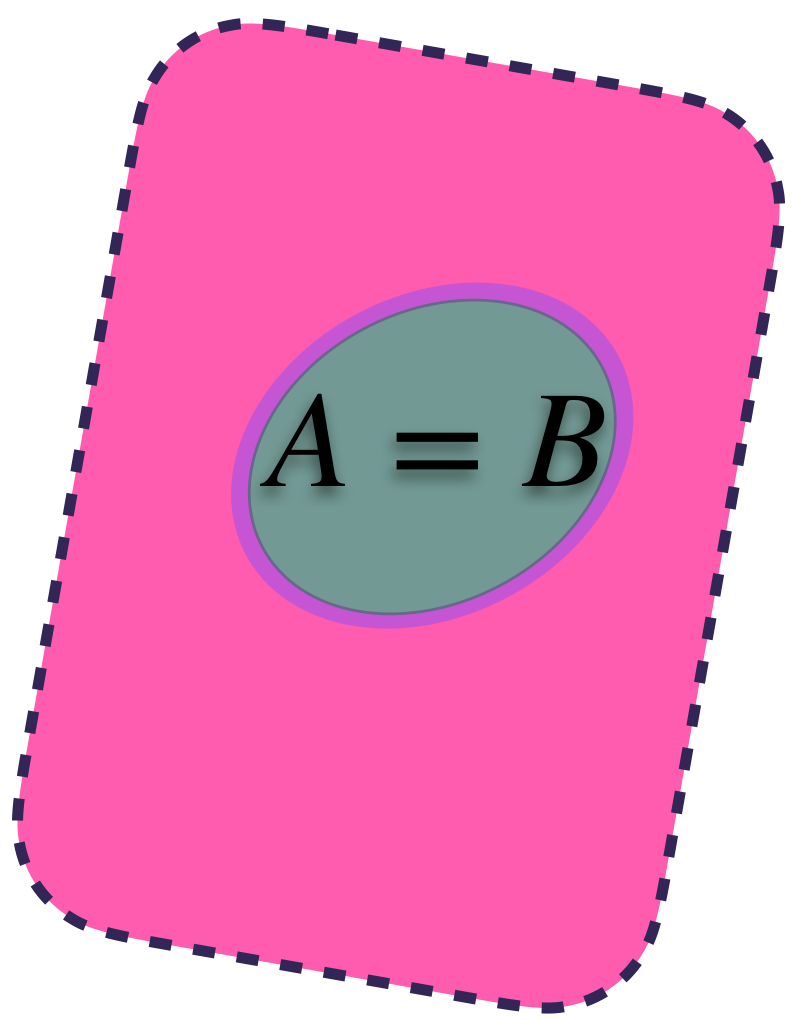
1) $d_H(A,B)=0$ si y solo si los conjuntos son iguales. En este caso tendremos que para todo $\varepsilon>0$ $A \subset U_\varepsilon(B)$ y $B \subset U_\varepsilon(A).$ Además $U_\varepsilon(B)=U_\varepsilon(A).$
$d_H = 0$ entre conjuntos iguales.
2) La propiedad de simetría en espacios métricos dice que $d_H(A,B) = d_H(B,A)$
La distancia $d_H$ es simétrica.
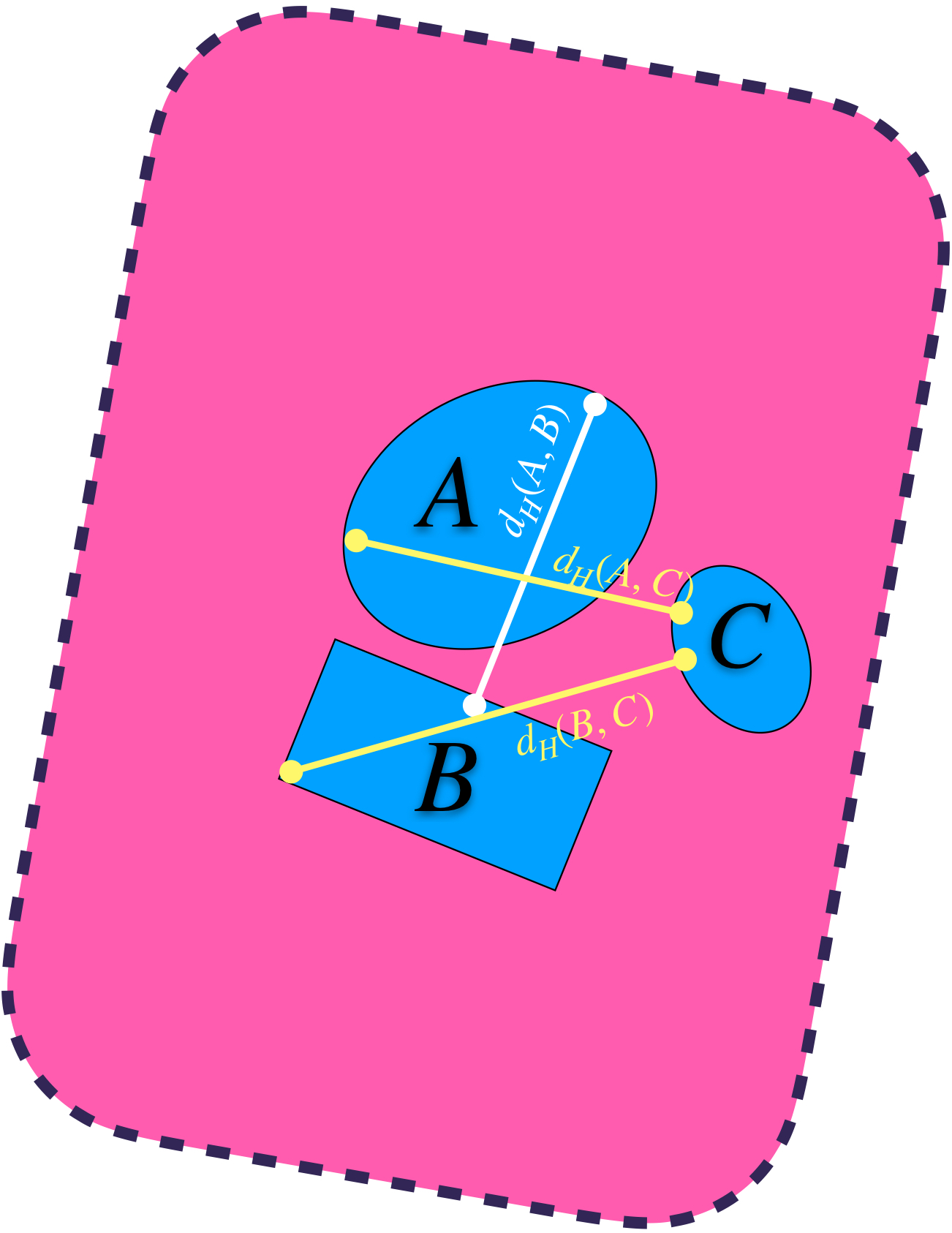
3) Se cumple la desigualdad del triángulo entre conjuntos: $$d_H(A,B) \leq d_H(A,C) + d_H(C,B).$$ Para fines ilustrativos de esta propiedad recordemos que: $d_H(A,B) = max\{\underset{a \in A}{sup} \, \text{dist}(a,B),\underset{b \in B}{sup} \, \text{dist}(b,A)\}.$ $d_H(A,C) = max\{\underset{a \in A}{sup} \, \text{dist}(a,C),\underset{c \in C}{sup} \, \text{dist}(c,A)\}.$ $d_H(B,C) = max\{\underset{b \in B}{sup} \, \text{dist}(b,C),\underset{c \in C}{sup} \, \text{dist}(c,B)\}.$ La imagen siguiente representa esas distancias.
Desigualdad del triángulo a partir de máximos.
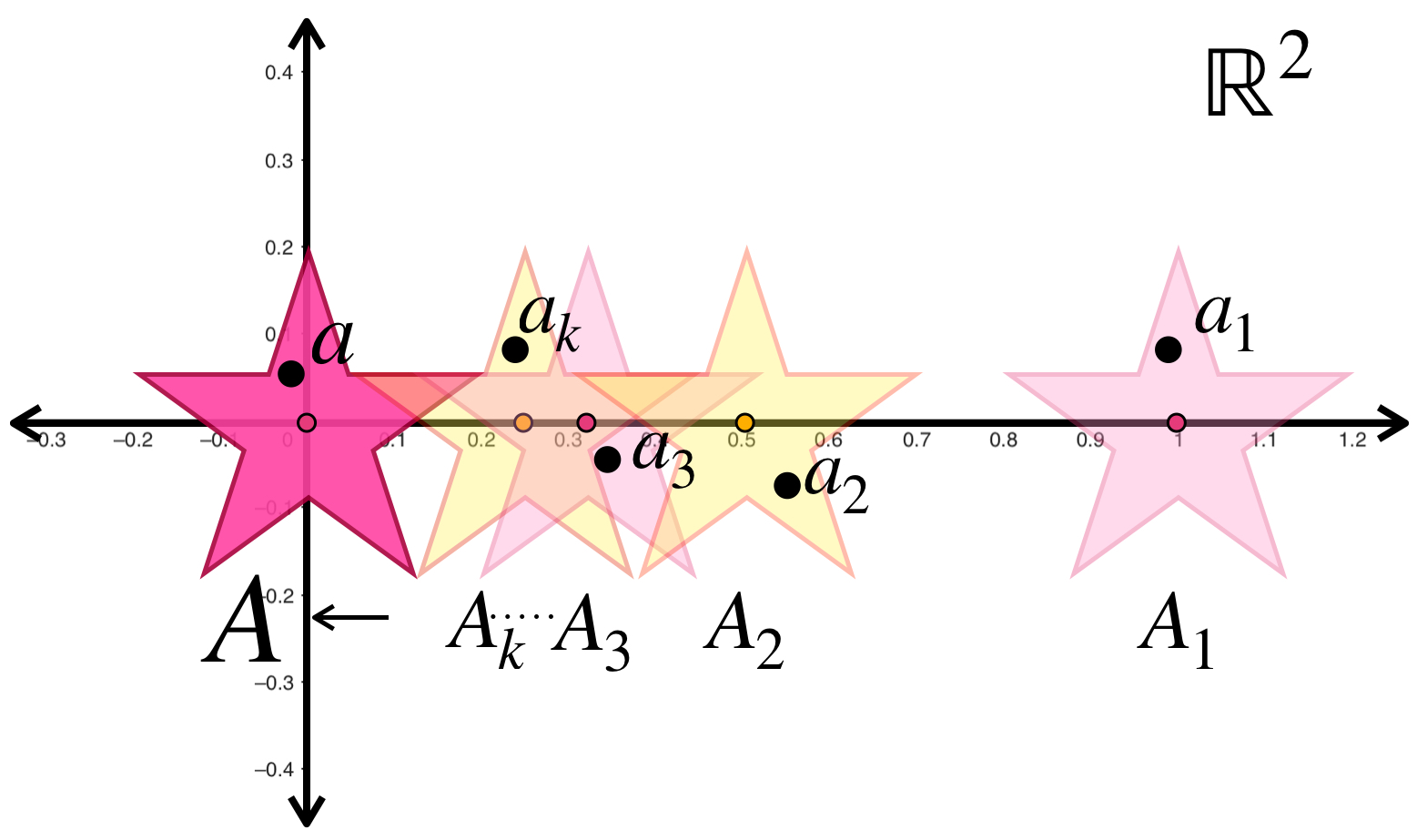
A continuación, visualizaremos ejemplos de sucesiones en el espacio métrico de Hausdorff. Entonces los elementos de las sucesiones serán conjuntos cerrados y acotados. Si $(A_n)_{n \in \mathbb{N}} \,$ es una sucesión de conjuntos de un espacio métrico y $A_n \to A$ en la métrica de Hausdorff, entonces $d_H(A_n,A) \to 0$ en $\mathbb{R}.$ Eso significa que los conjuntos indicados por la sucesión no solo se van a acercar (en posición, si podemos pensarlo así) al conjunto $A$, sino que se van a ver como éste (pues cuando $d_H =0$ los conjuntos son iguales).
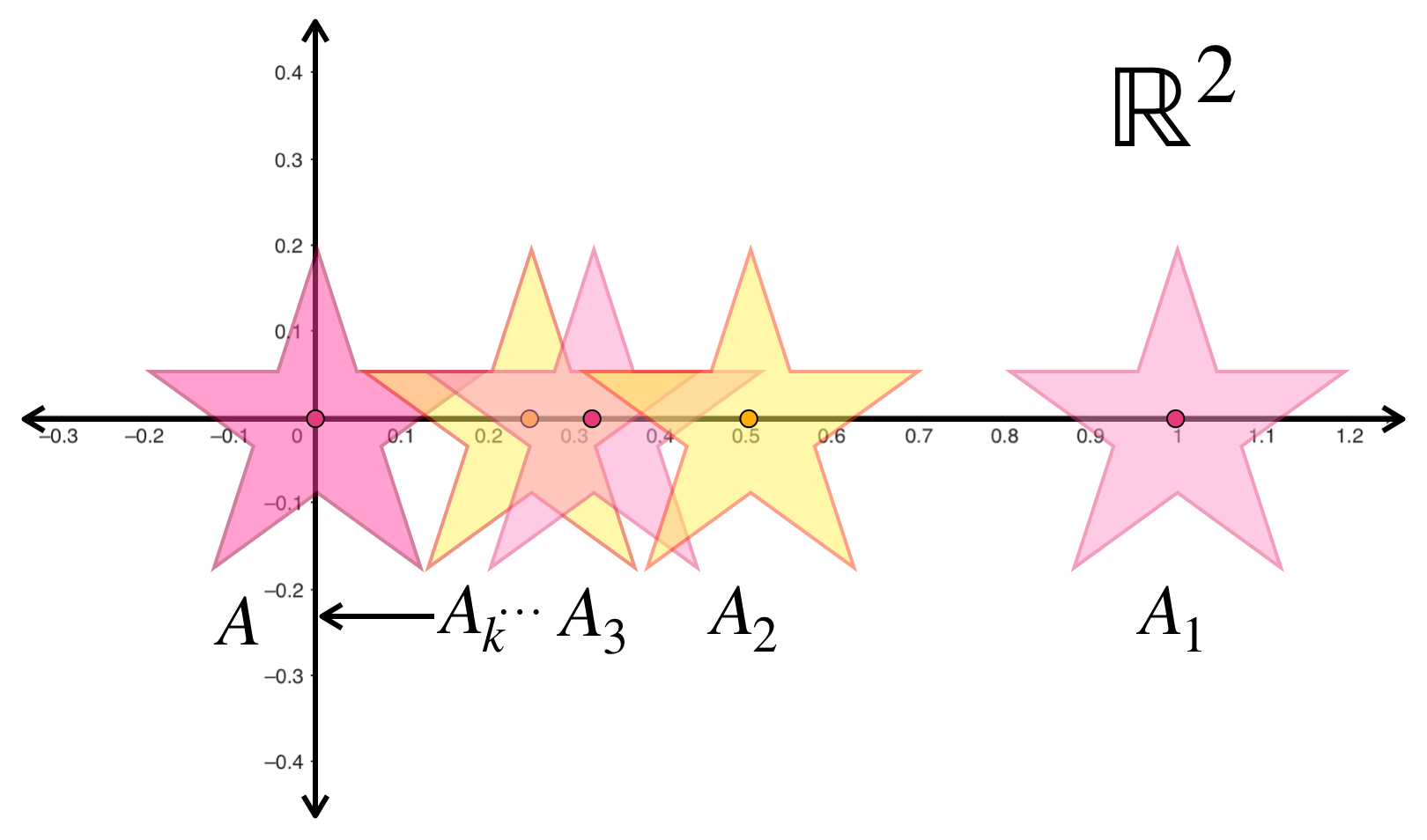
La sucesión presentada muestra estrellas de la misma forma y tamaño pero distinta posición en $\mathbb{R}^2$ cada vez más grandes pero proporcionales entre sí. Para cada $n \in \mathbb{N}$ la estrella $A_n$ tiene su centro en el punto $(\frac{1}{n},0).$ Entonces la sucesión $(A_n)_{n \in \mathbb{N}}\,$ converge a la estrella con centro en $(0,0).$
Representación de sucesión de conjuntos (estrellas) que convergen al conjunto $A.$
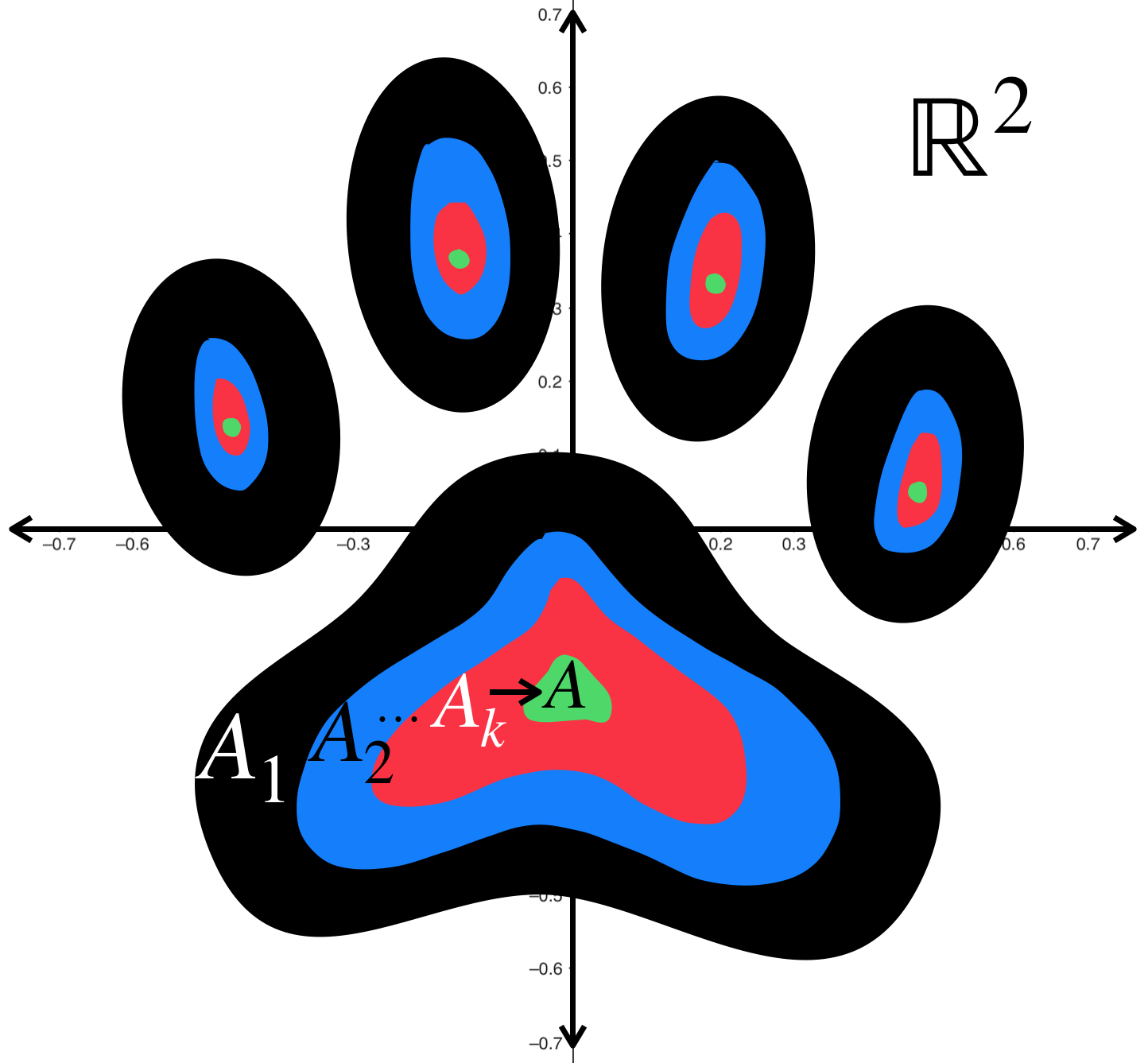
La sucesión de huellas de perrito muestra manchas cada vez más pequeñas que convergen a las manchas verdes.
Representación de sucesión de conjuntos (huellas de perrito) que convergen al conjunto $A.$
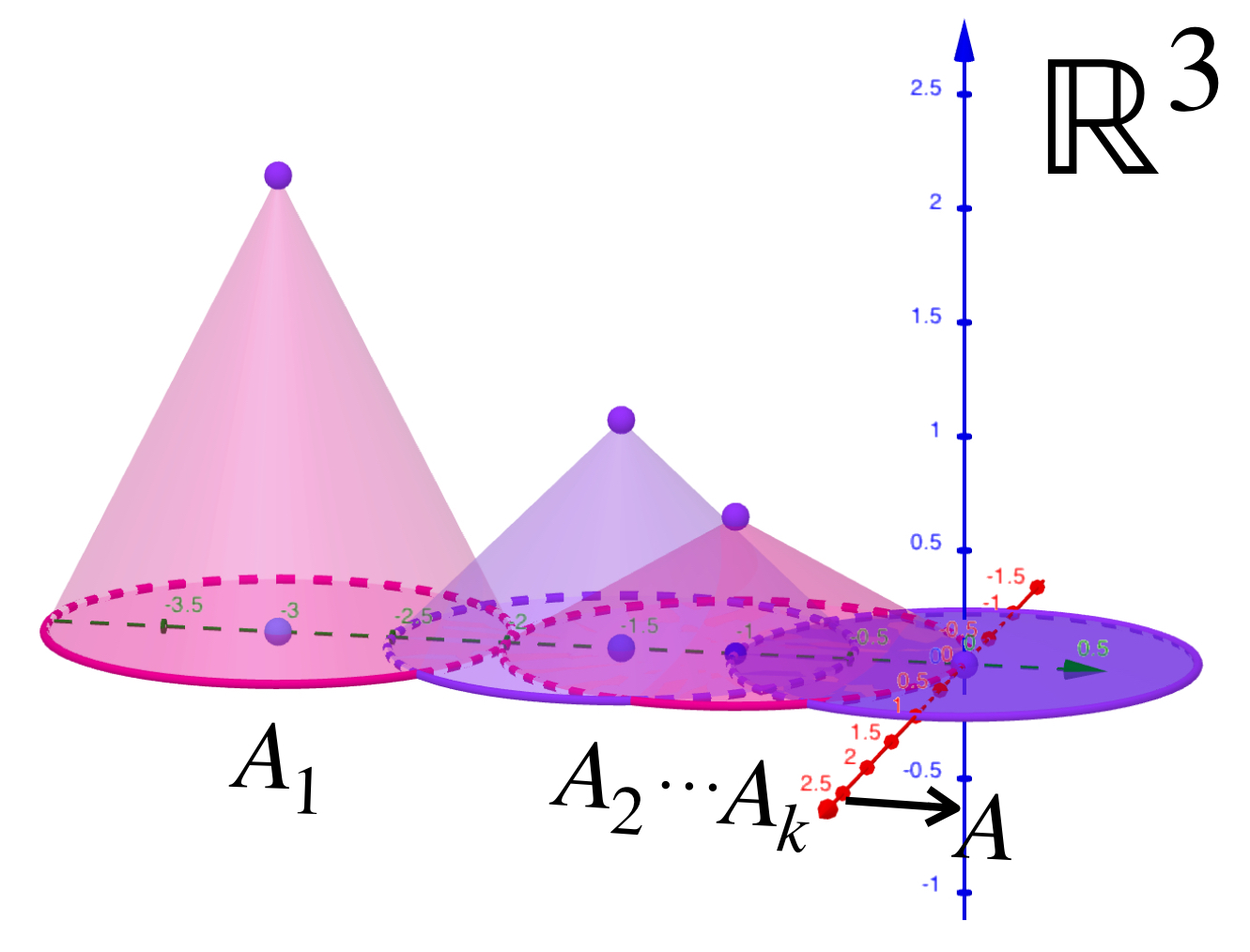
Tenemos una sucesión de «conos» $(A_n)_{n \in \mathbb{N}}\,$ definida como sigue: para cada $n \in \mathbb{N}$ el cono $A_n$ tiene su centro en $(0,\frac{-3}{n},0)$, altura $\frac{2}{n}$ y radio $1.$ Entonces los conos ven disminuída su altura hasta llegar a $0$ mientras que el centro se desplaza al origen. Finalmente convergen al círculo unitario en el plano horizontal.
Representación de sucesión de conjuntos («conos») que convergen al conjunto $A.$
Formalmente, tenemos los siguientes:
Ejemplos de sucesiones de conjuntos en espacios euclidianos que convergen a un conjunto $A$ en el espacio de Hausdorff.
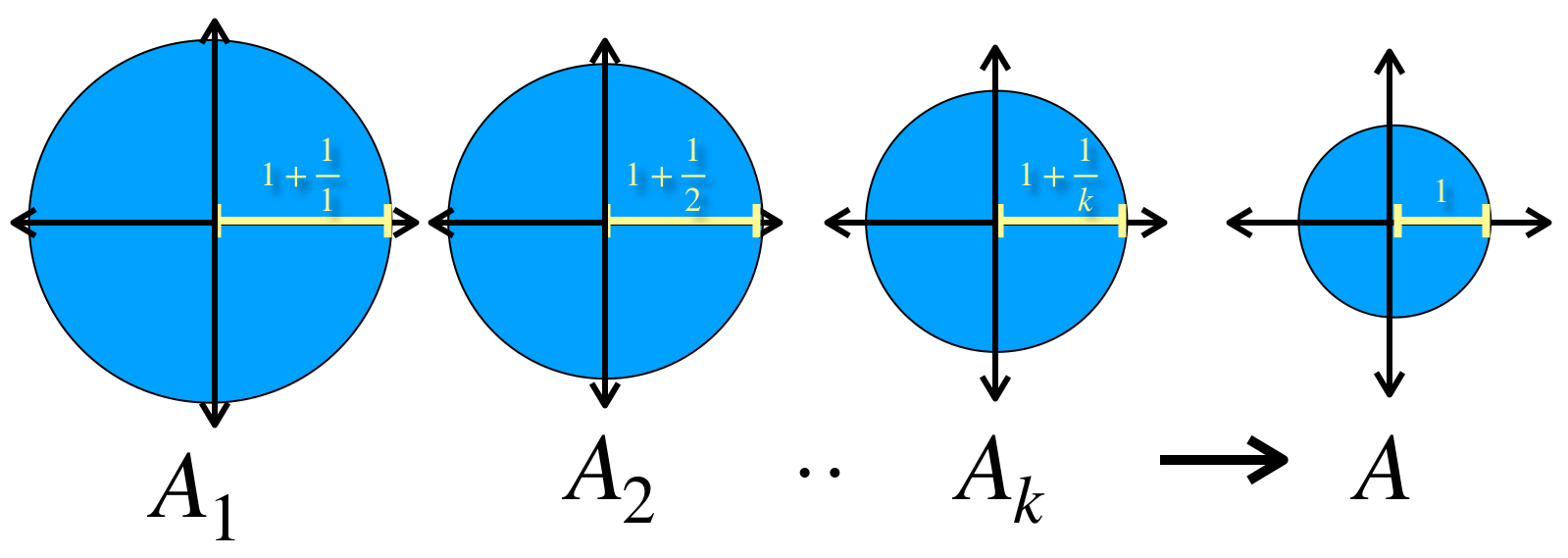
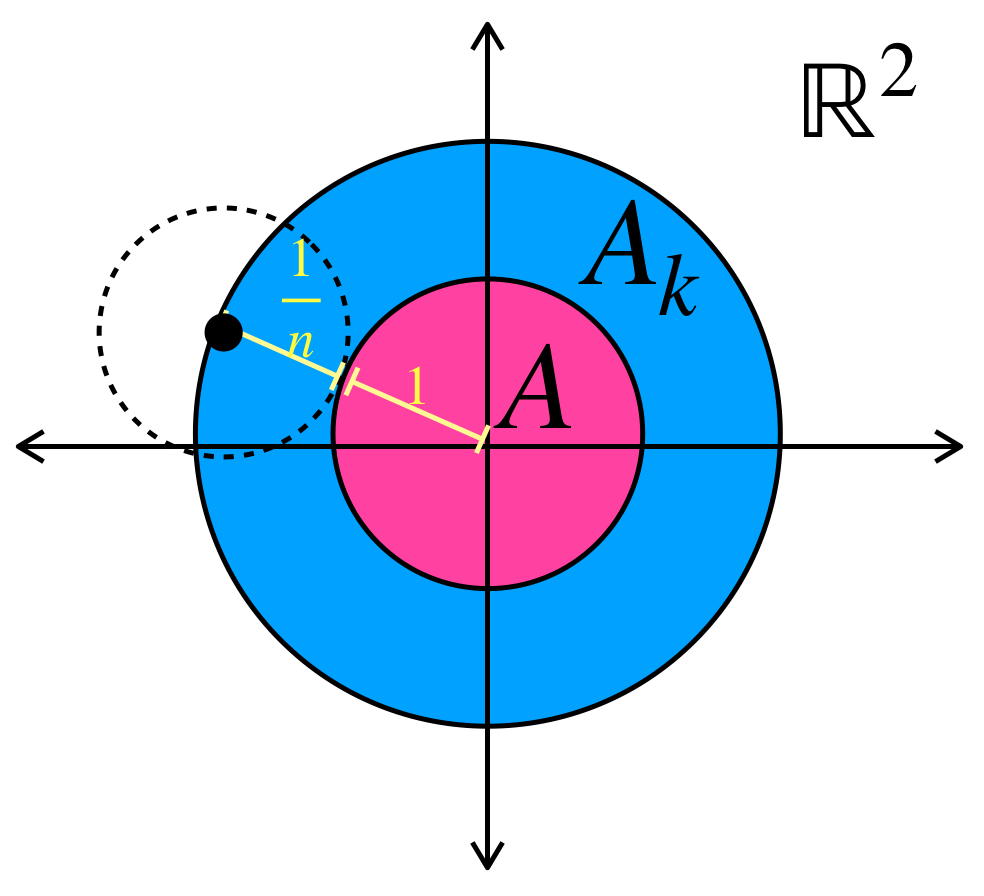
Para cada $n \in \mathbb{N}$ considera en el espacio euclidiano $\mathbb{R}^2$ el conjunto $A_n := \overline{B}(0,1+\frac{1}{n}).$ Entonces $(A_n)_{n \in \mathbb{N}}\,$ es una sucesión en el espacio de Hausdorff que converge al conjunto $A:=\overline{B}(0,1).$
Representación de sucesión de conjuntos (círculos) que convergen al conjunto $A.$
Representación del término $A_k$ y el límite de la sucesión, $A.$
Basta con demostrar que $d_{H}(A_n,A) = max\{\underset{a \in A_n}{sup} \, \text{dist}(a,A),\underset{b \in A}{sup} \, \text{dist}(b,A_n)\} \to 0$ en $\mathbb{R}.$ Es sencillo probar que para cada $n \in \mathbb{N}, \,d_{H}(A_n,A) = \frac{1}{n} \to 0 \in \mathbb{R}$ por lo tanto $A_n \to A.$
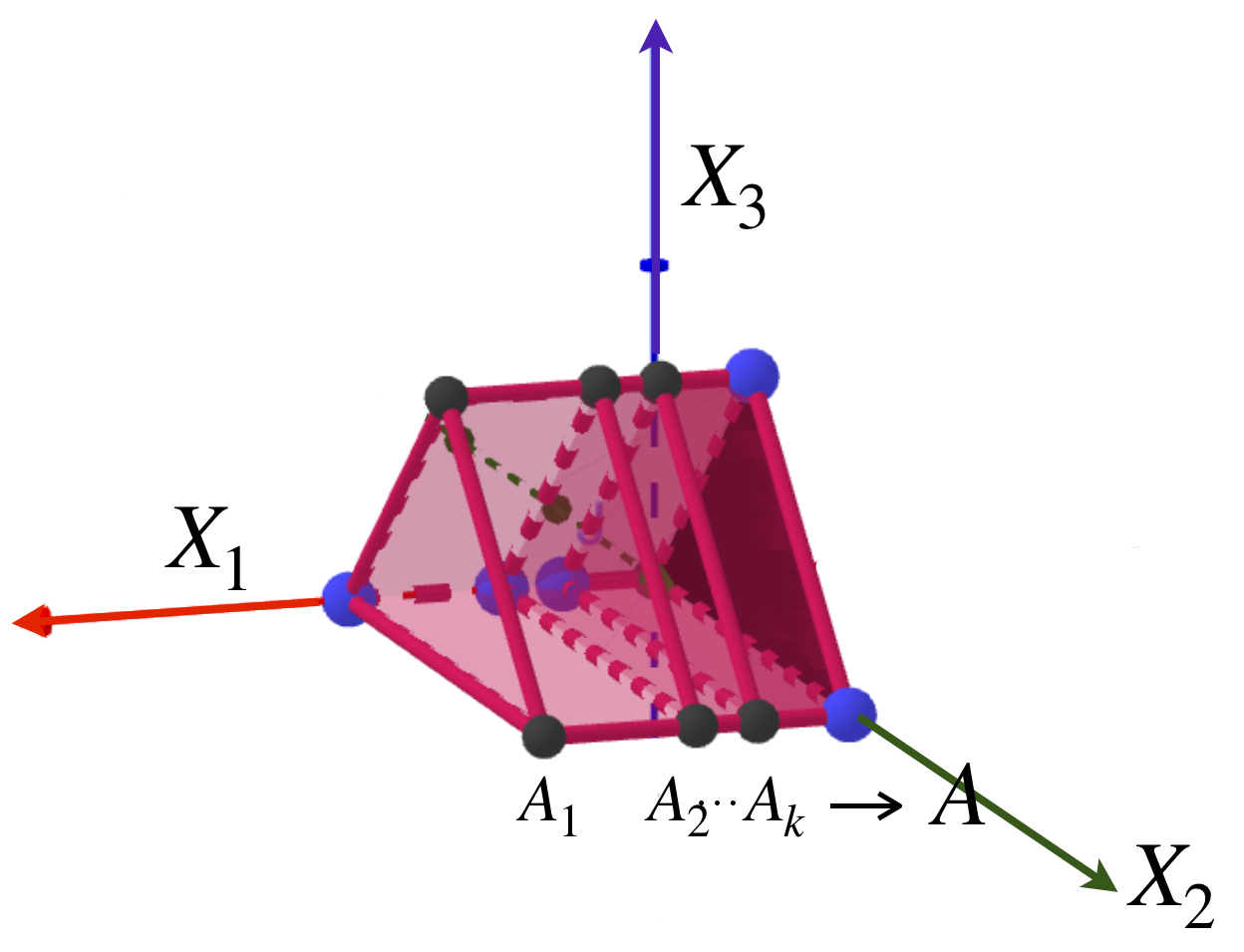
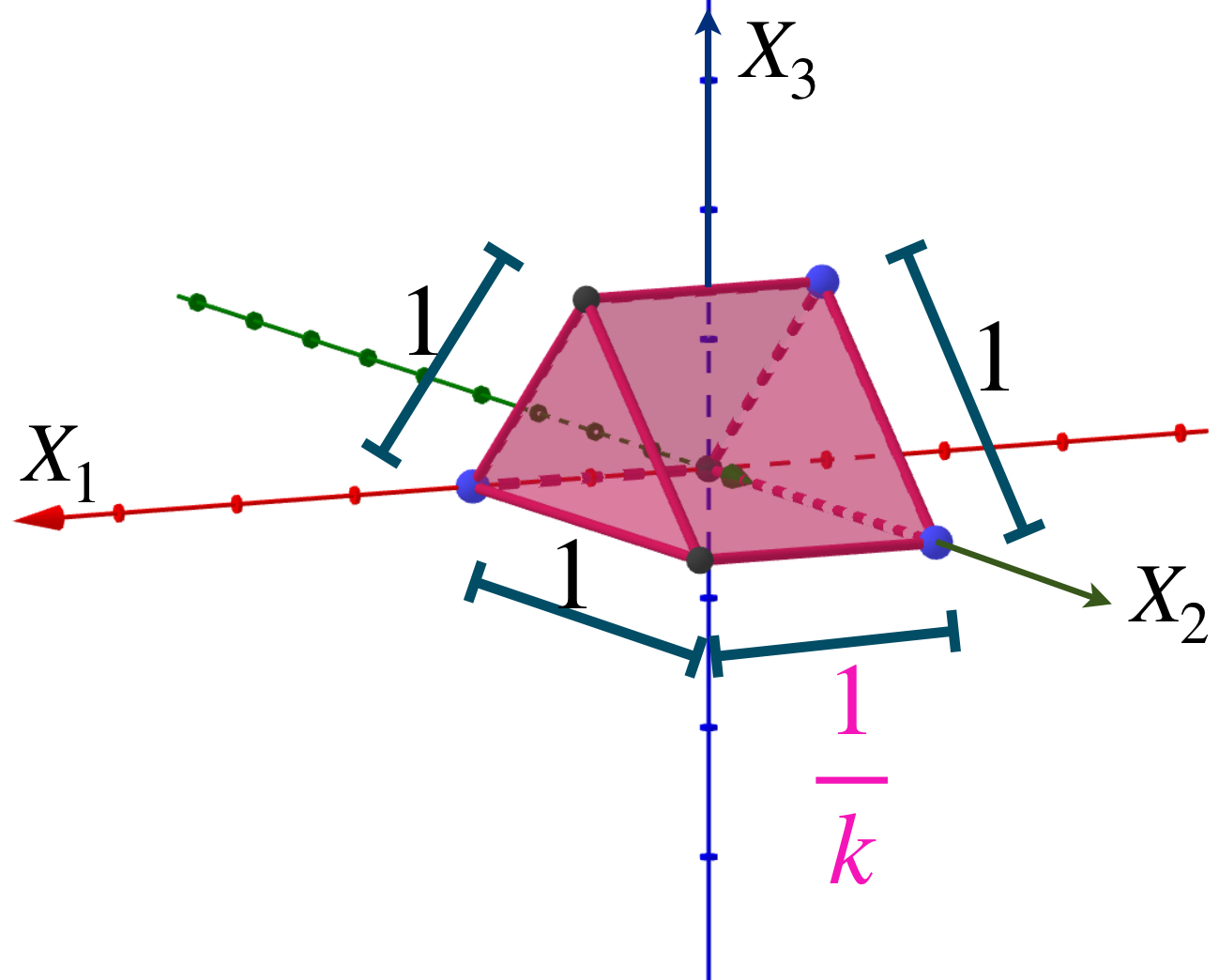
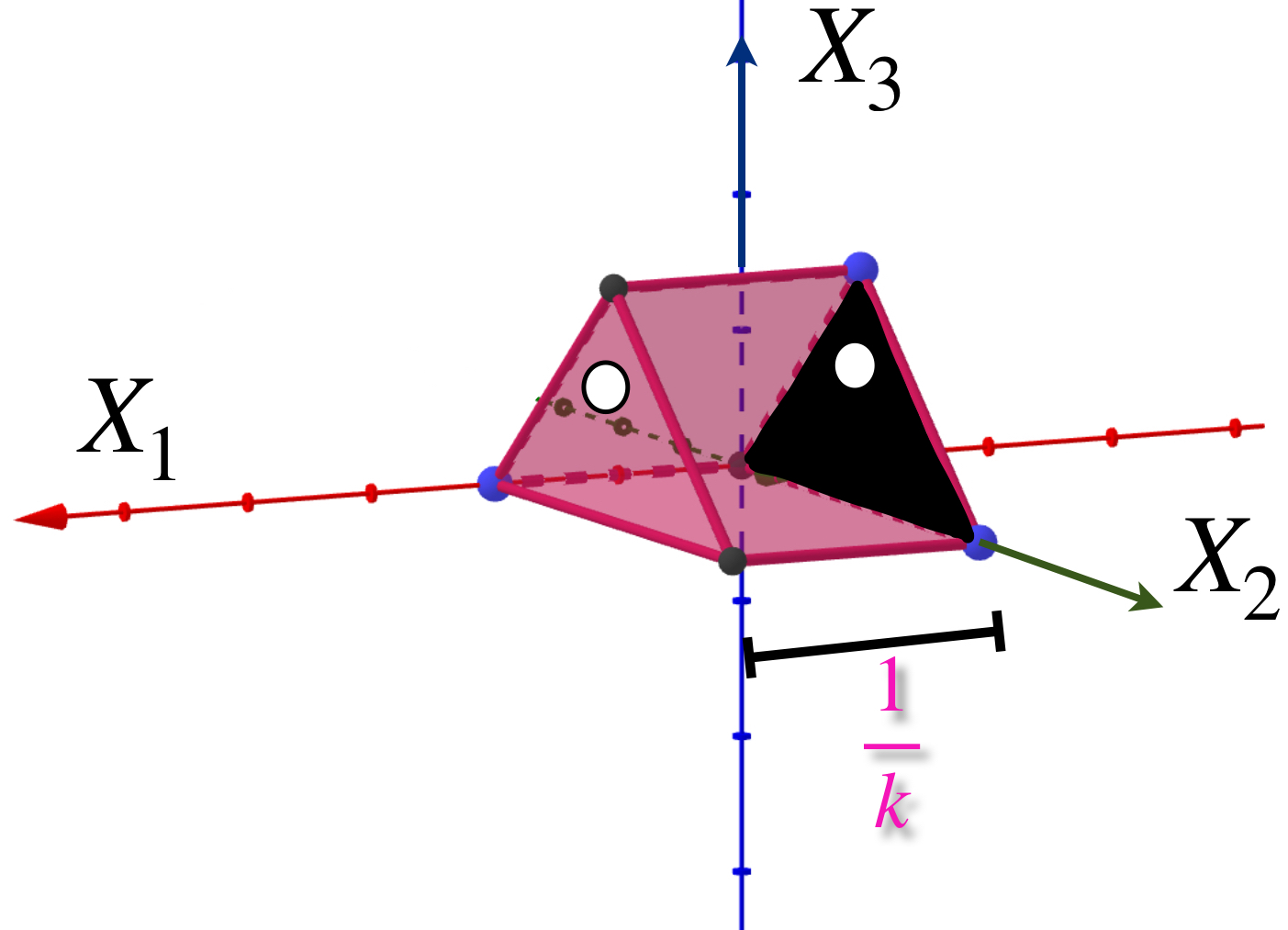
Presentamos una sucesión de prismas ubicadas en el espacio euclidiano $\mathbb{R}^3$ como muestra la imagen.
Los prismas convergen a la cara del fondo.
Prisma $A_k.$
Representación del término $A_k$ y el límite de la sucesión, $A.$
Sea $A$ el triángulo que es una cara del prisma y está en el plano $X_2, X_3.$ Nota que para cada $k \in \mathbb{N}$, $d_{H}(A_k,A) = max\{\underset{a \in A_k}{sup} \, \text{dist}(a,A),\underset{b \in B}{sup} \, \text{dist}(b,A_k)\}= \frac{1}{k}$
Entonces $d_{H}(A_n,A) = \frac{1}{n} \to 0 \in \mathbb{R}$ por lo tanto $A_n \to A.$
La demostración de las siguientes dos sucesiones se dejará como ejercicio.
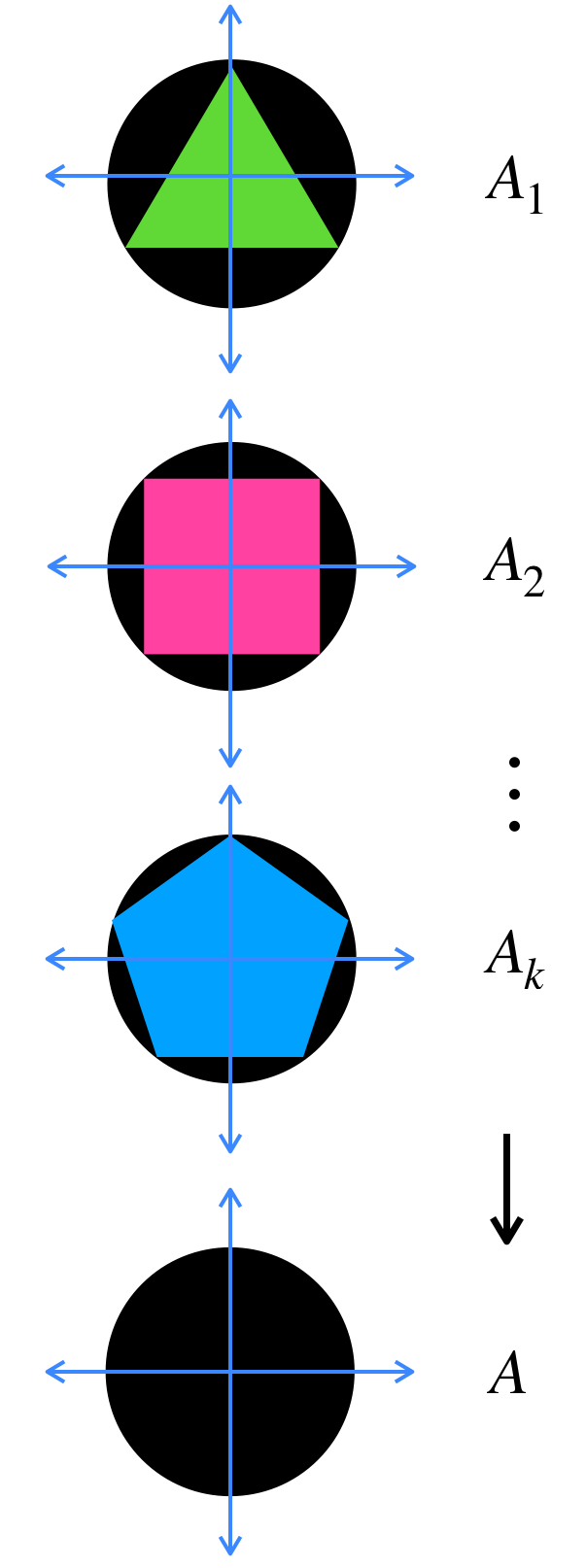
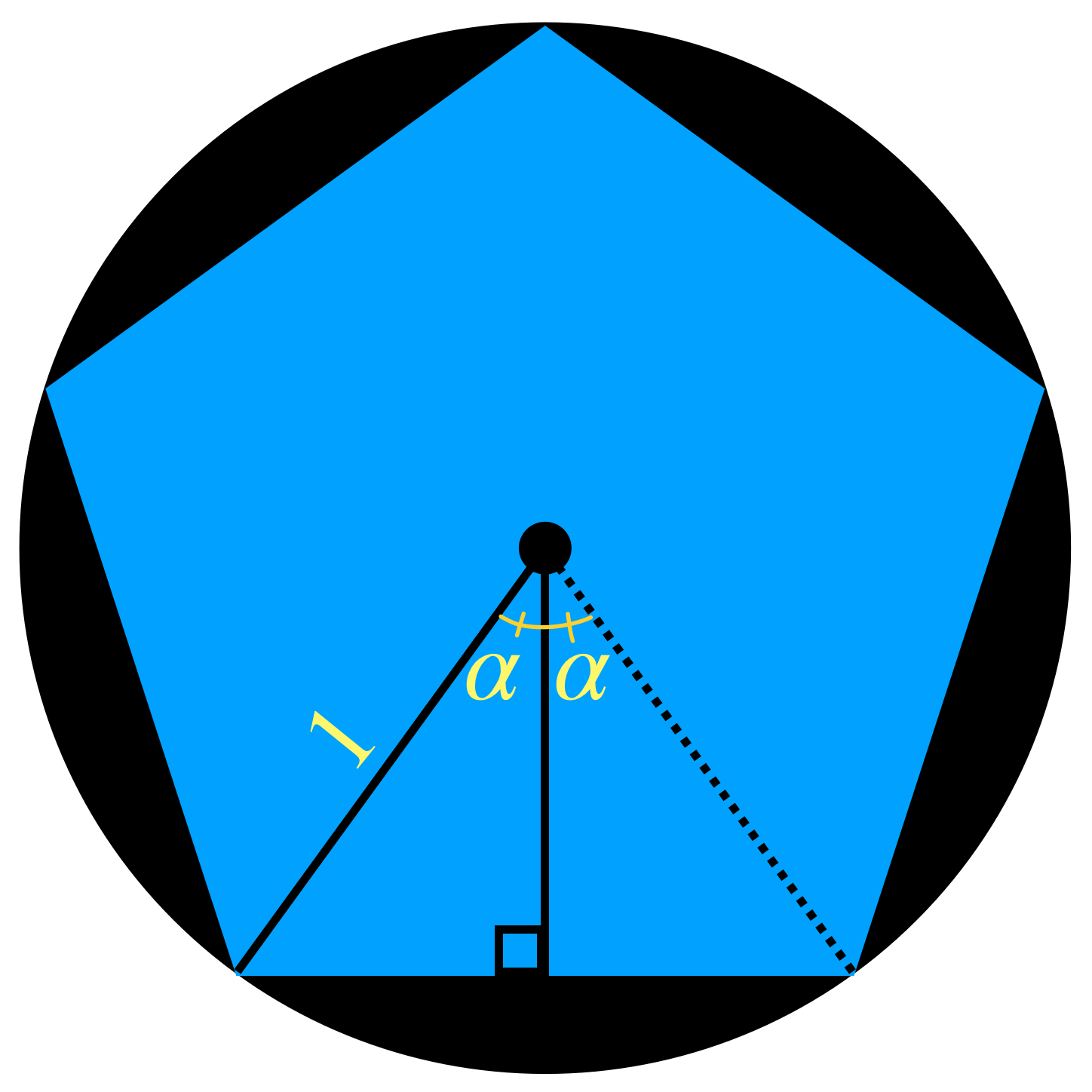
Tenemos una sucesión de polígonos regulares en $\mathbb{R}^2,$ $(A_n)_{n \in \mathbb{N}}, \,$ donde para cada natural $n$, $ A_n$ es el polígono regular de $\, n \,$ lados con centro en $(0,0)$ y circunscrito en el círculo con centro en $(0,0)$ y radio $1.$ Demuestra que $A_n \to \overline{B}(0,1)$ en el espacio de Hausdorff.
Los polígonos convergen al círculo unitario.
Representación de la sucesión $(A_n)$ y el límite, $A.$
Como sugerencia, puedes demostrar que la medida del apotema vista como $\, cos \alpha \,$ tiende a $1$ en $\mathbb{R}.$
Apotema = $\, cos \alpha.$
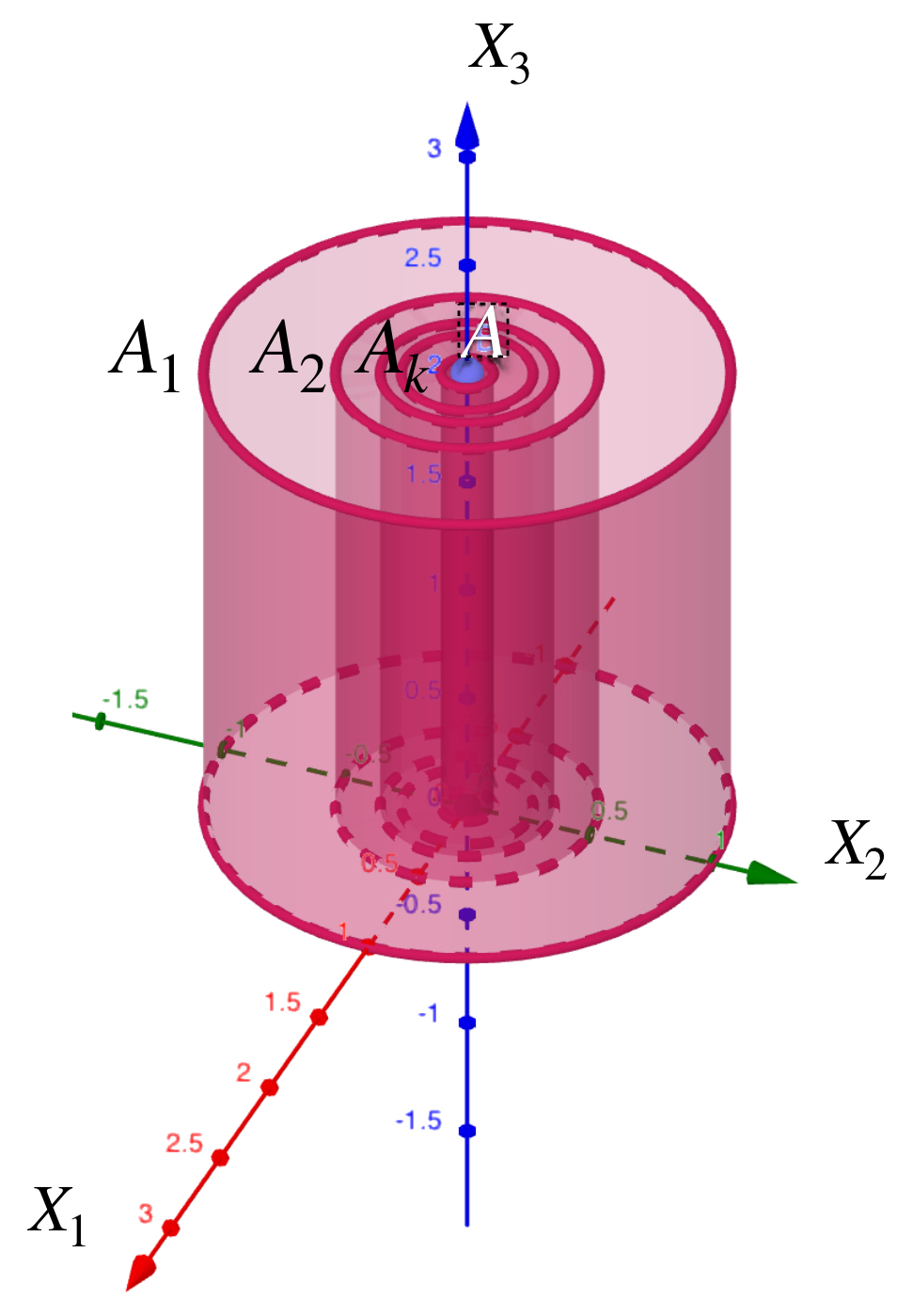
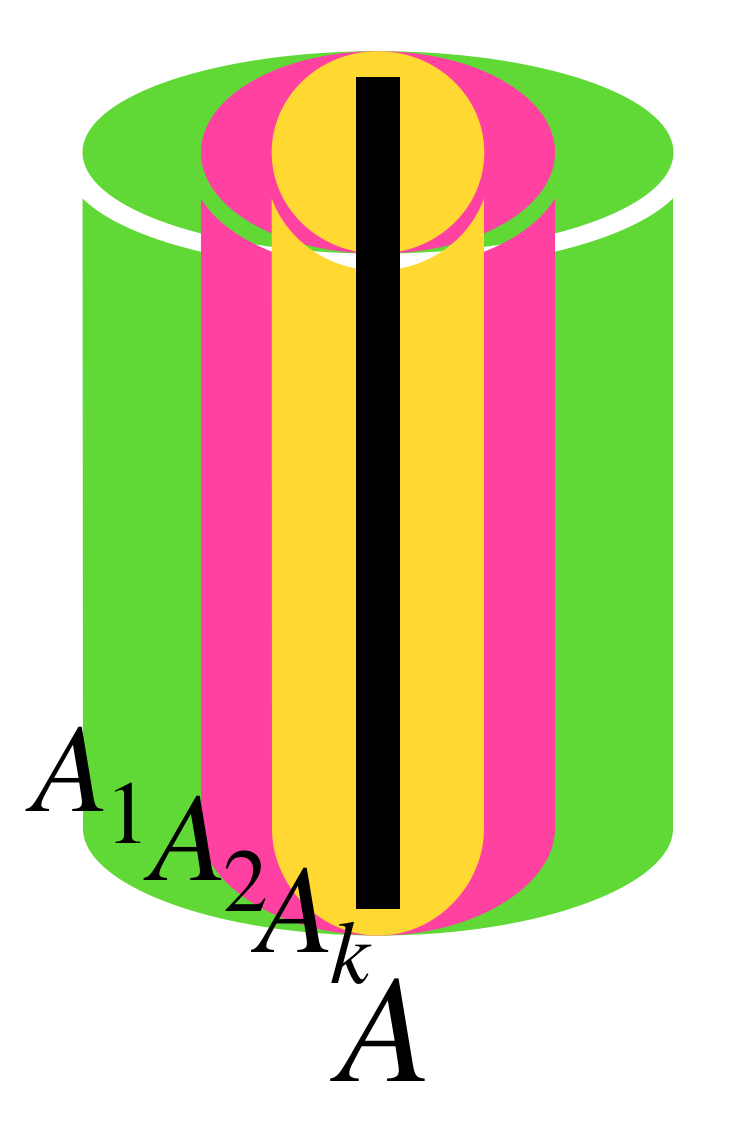
La siguiente sucesión muestra cilindros en $\mathbb{R}^3.$
Los cilindros convergen al segmento del centro.
Representación del término $A_k.$
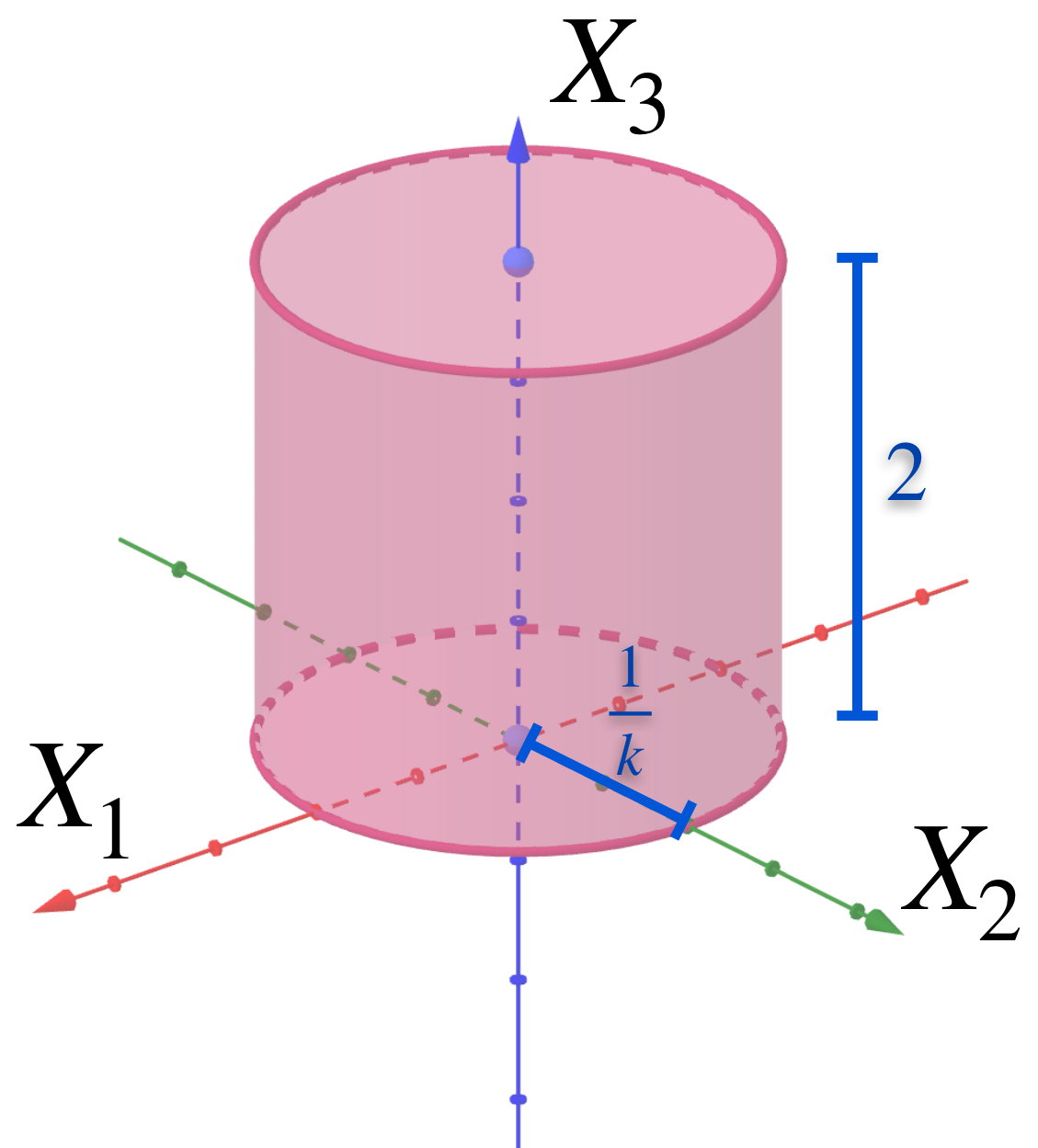
Para cada $n \in \mathbb{N}$ considera $A_n$ como el cilindro que tiene de base al círculo con centro en el origen, radio $\frac{1}{n}$ y altura $2.$ Demuestra que la sucesión $(A_n)_{n \in \mathbb{N}}\,$ converge al segmento $\{(0,0,x_3): x_3 \in [0,2]\}.$
Ahora presentaremos algunas condiciones que garantizan la convergencia en sucesiones de conjuntos. En la última se menciona la noción de compacidad, concepto del que se hablará más adelante, a partir de la entrada Compacidad en espacios métricos. Por el momento podemos imaginar el resultado en espacios euclidianos, donde los compactos son los conjuntos cerrados y acotados.
Proposición. Sea $(A_n)_{n \in \mathbb{N}} \,$ una sucesión en $\mathcal{M}(X)$ tal que $A_n \to A$ en $\mathcal{M}(X).$ Entonces:
a) $A$ es el conjunto de límites de todas las sucesiones convergentes $(x_n)_{n \in \mathbb{N}}$ en $X$ tales que para toda $n \in \mathbb{N}, \, a_n \in A_n.$
Una sucesión convergente $(a_n)$ en $X$ con $a_k \in A_k$ tiene su punto de convergencia en $A.$
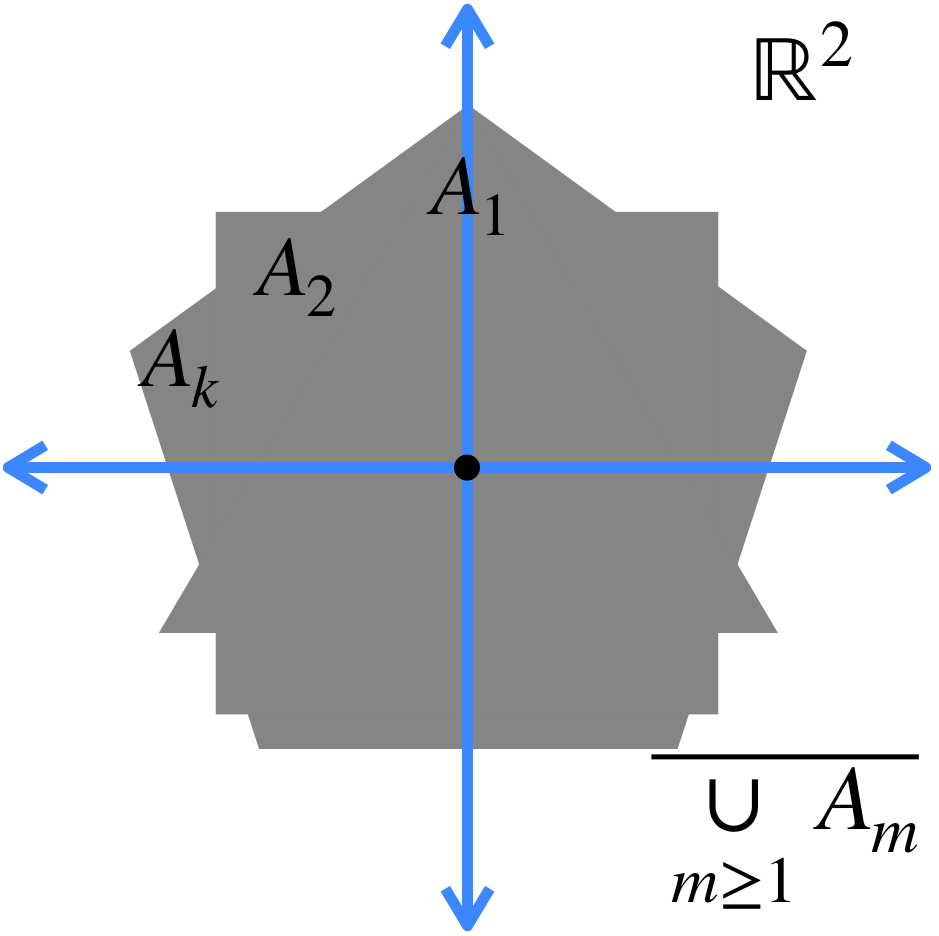
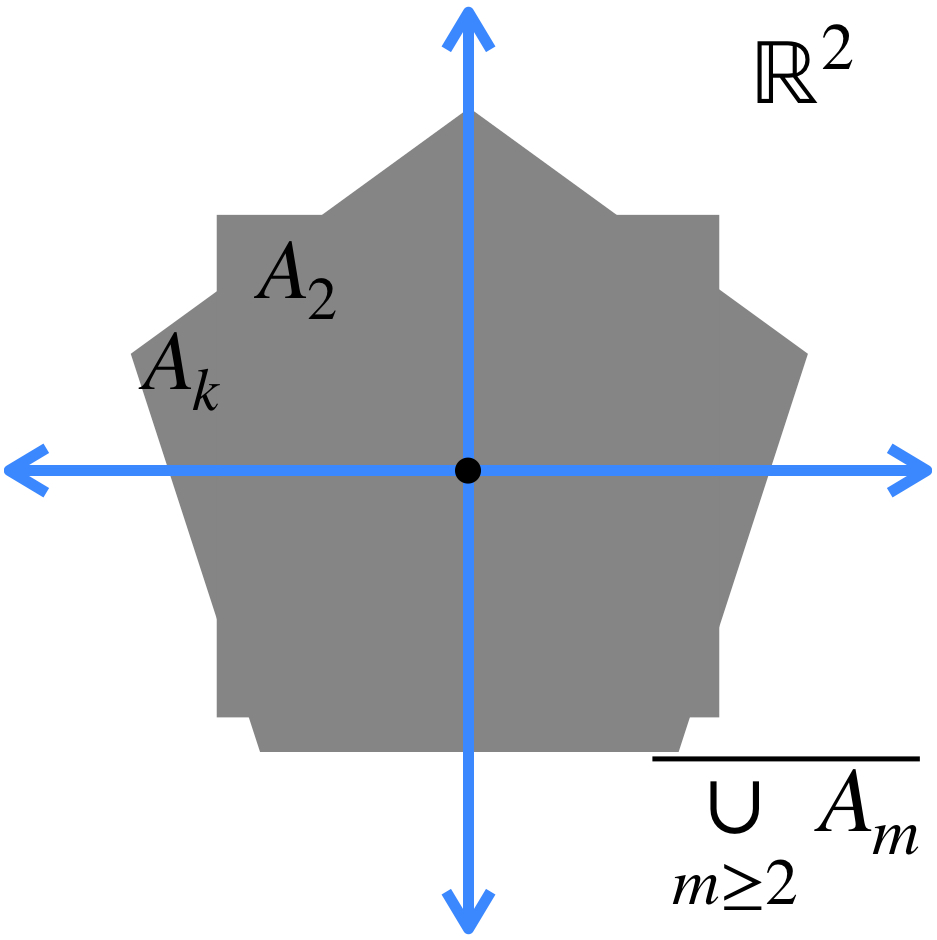
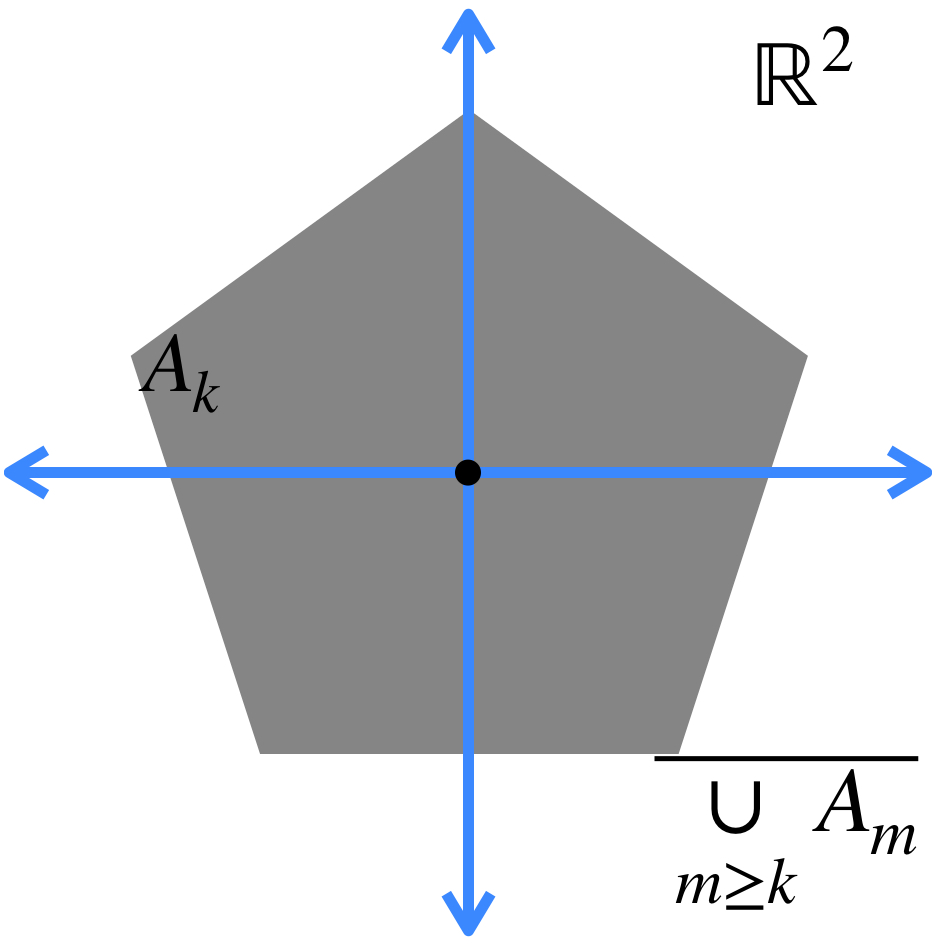
b) El conjunto al que converge la sucesión está dado por: $A = \underset{n \in \mathbb{N}}{\cap} (\overline{\underset{m \geq n}{\cup} A_m}).$
Esto significa que en cada iteración, vamos a considerar la cerradura de la unión de todos los conjuntos, exceptuando los de las primeras posiciones (según la iteración en la que vayamos). Esto define nuevos conjuntos, cuya intersección es el conjunto al que la sucesión converge.
Representación de una sucesión en $\mathcal{M}(\mathbb{R}^2).$
La intersección de todos los conjuntos de este estilo es el conjunto al que la sucesión converge:
Proposición. Sea $(X,d)$ un espacio métrico compacto y $(A_n)_{n \in \mathbb{N}} \,$ una sucesión de subespacios compactos en él, entonces: a) Si $A_{n+1} \subset A_n$, entonces $A_n \to \underset{n \in \mathbb{N}}{\cap}A_n$ en $\mathcal{M}(X).$
Entonces cuando una sucesión es tal que cada término está contenido en el anterior, la sucesión converge a la intersección de todos los conjuntos. Al final de la entrada Compacidad en espacios métricos veremos por qué podemos asegurar que esa intersección no es vacía.
Sucesión de cilindros donde «el siguiente» está contenido en «el anterior».
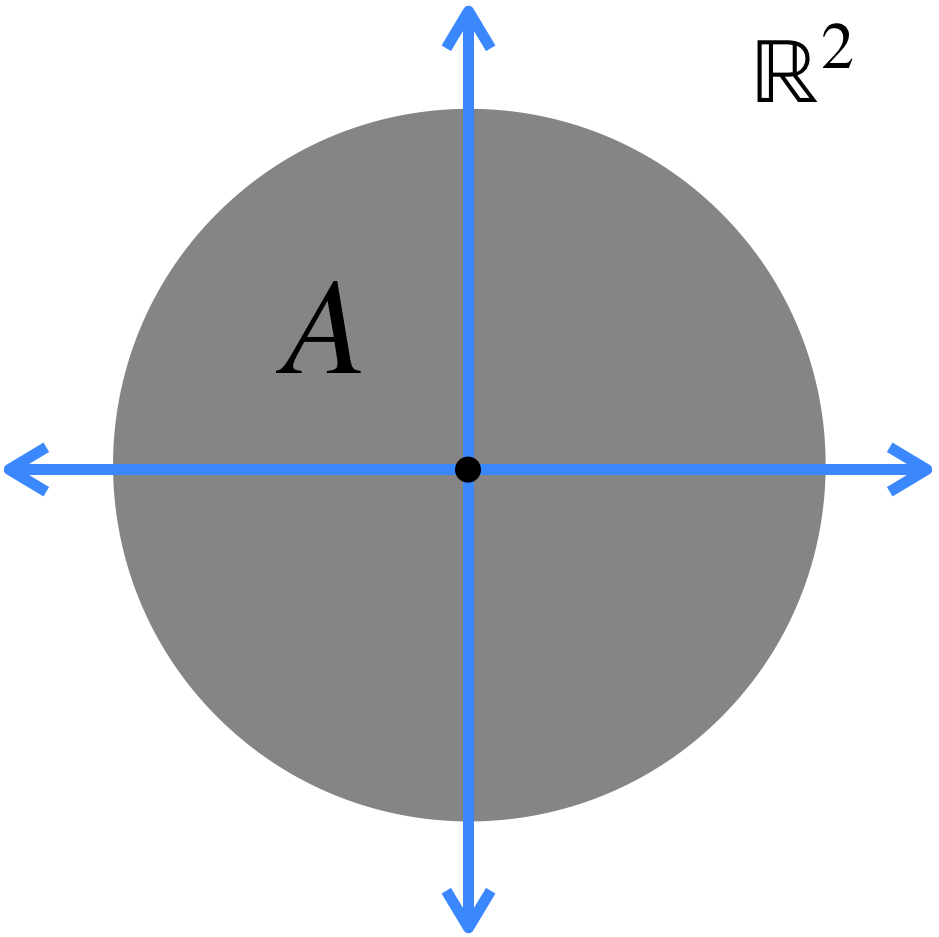
b) Si para todo $n \in \mathbb{N}, \, A_n \subset A_{n+1}$, entonces $A_n \to \overline{\underset{n \in \mathbb{N}}{\cup}A_n}$ en $\mathcal{M}(X).$
Entonces cuando una sucesión es tal que cada término contiene al anterior, la sucesión converge a la cerradura de la unión de todos los conjuntos.
Sucesión donde cada término está contenido en el siguiente.
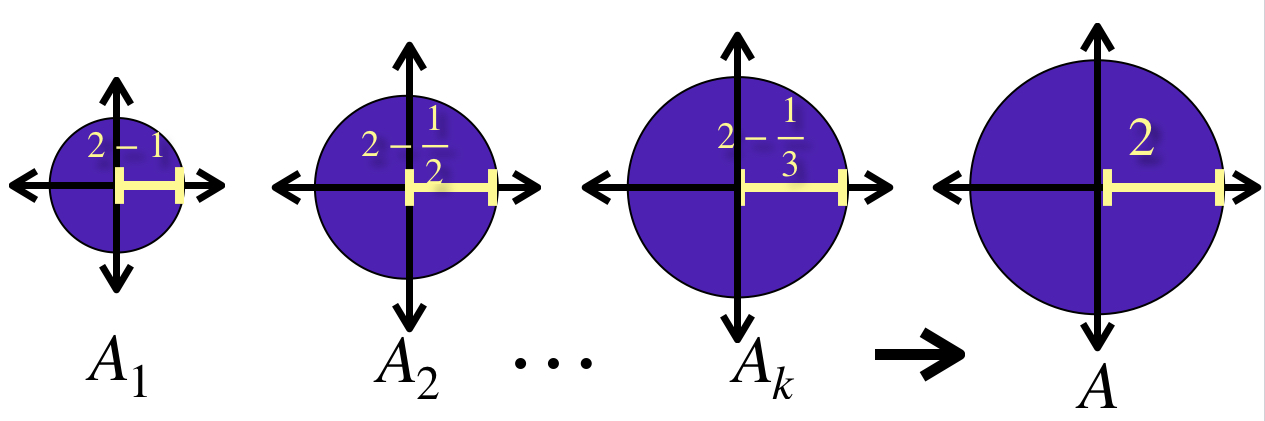
En el dibujo la sucesión $(A_n)_n \in \mathbb{N}$ tiene como conjunto $A_n = \overline{B}(0,2-\frac{1}{n})$ para cada $n \in \mathbb{N}.$ Es sencillo demostrar que $A_n \to \overline{B}(0,2)$ en $\mathbb{R}^2.$
El límite contiene todos los términos de la sucesión.
Más adelante…
Ya que hemos estudiado algunas propiedades en un espacio métrico, comenzaremos a relacionar un espacio con otros a través de funciones. Veremos bajo qué circunstancias es posible hablar de “cercanía” en puntos del contradominio cuando se parte de puntos cercanos en el espacio métrico del dominio.
Tarea moral
Describe las características de las sucesión definida como: $A_1=[0,1]$ $A_2=[0,1] \setminus (\frac{1}{3},\frac{2}{3})=[0,\frac{1}{3}] \cup [\frac{2}{3},1],$ $A_3=[0,\frac{1}{3}] \setminus (\frac{1}{9},\frac{2}{9}) \cup [\frac{2}{3},1]\setminus (\frac{7}{9},\frac{8}{9})=[0,\frac{1}{9}] \cup [\frac{2}{9},\frac{1}{3}] \cup [\frac{2}{3},\frac{7}{9}] \cup[\frac{8}{9},1]$ Y así, recursivamente, se va quitando la tercera parte central, de cada intervalo que quedaba. La intersección de estos conjuntos es conocido como el conjunto de Cantor. ¿Bajo qué resultados mencionados en esta entrada podemos concluir la convergencia de la sucesión?
El copo de nieve de Koch es la curva a la que converge una sucesión definida como sigue: $A_1$ es un triángulo equilátero. $A_2$ sustituye la tercera parte central de cada lado por dos aristas de la misma medida. $A_3$ Hace lo mismo. Se repite el proceso recursivamente ¿Qué puedes decir del área encerrada por las curvas a medida que la sucesión aumenta? ¿Hay condiciones suficientes para concluir la convergencia de estos conjuntos?
Demuestra la convergencia en el espacio de Hausdorff de la sucesión de polígonos circunscritos descrita anteriormente.
Demuestra la convergencia en el espacio de Hausdorff de la sucesión de cilindros expresada anteriormente.
Bibliografía
Burago, D., Burago, Y., Ivanov, S., A course in Metric Geometry. Graduate Studies in Mathematics, 33. Providence, Rhode Island: American Mathematical Society, 2001. Págs: 252 y 253.
Ante el modelado de situaciones, resulta útil identificar qué tan lejos está un objeto de convertirse en otro. Si se identifica una secuencia o patrón entre una situación y la siguiente, posiblemente se pueda comprobar que, tras varios cambios, nos aproximaremos a algún resultado específico. El Análisis Matemático ofrece herramientas que formalizan este estudio. En la sección que a continuación presentamos trabajaremos más con la noción de cercanía a través de distancias que van tendiendo a cero. Esta vez lo haremos con una sucesión que toma elementos del espacio métrico. Se verá bajo qué condiciones estos puntos se acercan cada vez más a cierto punto en el espacio métrico. Comencemos con la siguiente:
Definición. Sucesión. Sea $(X,d)$ un espacio métrico. Decimos que una función $(x_n): \mathbb{N} \to X$ es una sucesión en $X$.
Podemos pensar entonces que una sucesión elige, para cada número natural $n$, un elemento $x_n$ del conjunto $X$ (que es como vamos a denotar el valor de la sucesión en el término $n).$ La sucesión es comúnmente denotada como $(x_n)_{n \in \mathbb{N}} \,$ o simplemente como $(x_n).$
Representación de una sucesión en $(X,d).$
¿Bajo qué condiciones podemos decir que la sucesión se aproxima cada vez más a cierto punto $x$ en $(X,d)$? Para que esto ocurra se espera que, siempre que se fije una distancia $\varepsilon >0$ como referencia, se pueda asegurar que los últimos elementos de la sucesión, tengan una distancia al punto $x$ menor que $\varepsilon$, es decir, que exista un número natural $N \,$ de modo que todos los puntos asignados por la sucesión a partir de la posición $N$, estén “dentro” de la bola de radio $\varepsilon$ con centro en $x$, el punto de convergencia. De manera formal, tenemos la:
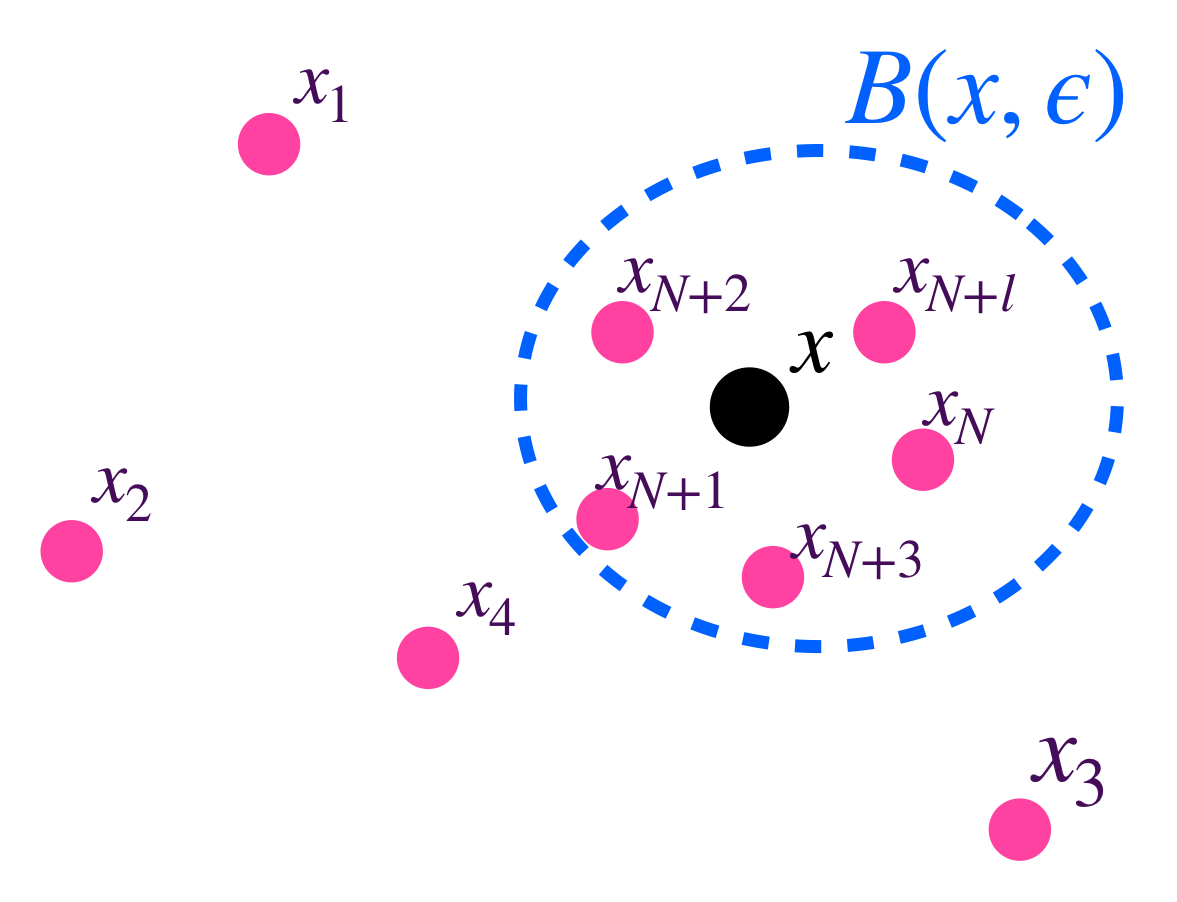
Definición. Sucesión convergente. Vamos a decir que una sucesión $(x_n)_{n \in \mathbb{N}} \,$ es convergente en $(X,d)$ si existe $x \in X$ tal que para todo $\varepsilon >0$ existe $N \in \mathbb{N}$ tal que para todo $n \geq N$ ocurre que $d(x_n,x)<\varepsilon$.
Los últimos puntos de la sucesión están dentro de la bola de radio $\varepsilon$ con centro en $x$.
Si es así, diremos que $(x_n)_{n \in \mathbb{N}} \,$ converge a $x$ y se indicará en la notación como: $$x_n \to x$$ o como: $$\underset{n \to \infty}{lim} \, x_n =x$$ Nota: $x_n \to x \text{ en } X \iff d(x_n,x) \to 0 \text{ en } \mathbb{R}$. Si la sucesión no es convergente decimos que es divergente.
Ahora veamos que una sucesión no puede converger a dos puntos diferentes:
Proposición. Si $(x_n)_{n \in \mathbb{N}} \,$ es una sucesión convergente en $X$ entonces el límite $\underset{n \to \infty}{lim} \, x_n \,$ es único. Demostración: Supongamos que $x_n \to x_a \,$ y $\, x_n \to x_b \,$ en $X$. Sea $\varepsilon>0$. Siguiendo la definición de convergencia se tiene que para todo $\frac{\varepsilon}{2} >0$ existen números naturales $N_a\, $ y $\, N_b\, $ tales que para todo $n\geq N_a, \, d(x_n,x_a)< \frac{\varepsilon}{2}$ y para todo $n\geq N_b, \, d(x_n,x_b)< \frac{\varepsilon}{2}$. Si elegimos $N = max\{N_a,N_b\}$ las dos condiciones anteriores se satisfacen. Entonces, para toda $n\geq N$, $0 \leq d(x_a,x_b) \leq d(x_a,x_n)+d(x_n,x_b) < \frac{\varepsilon}{2}+\frac{\varepsilon}{2}= \varepsilon$ Nota entonces que para todo $ \, \varepsilon >0,$ la distancia entre $x_a$ y $x_b$ queda acotada por $0 \leq d(x_a,x_b) < \varepsilon.$ En conclusión, $d(x_a,x_b)=0$, por lo tanto los puntos de convergencia son iguales.
Es importante mencionar que la convergencia de una sucesión depende tanto de la métrica como del conjunto a considerar. Una sucesión puede ser convergente en un espacio métrico pero no serlo en otro. Por ejemplo, la sucesión que a cada natural $n$ le asigna el número $\frac{1}{n}$ cumple que $(\frac{1}{n}) \to 0$ en $\mathbb{R}$ con la métrica euclidiana, pero en el subespacio euclidiano $(0,1]$ no es convergente, pues $0$ no está en el subespacio.
Definición. Subsucesión de $(x_n)_{n \in \mathbb{N}}.$ Una subsucesión $(x_{k(n)})_{n \in \mathbb{N}} \,$ es una composición de la sucesión $(x_n)_{n \in \mathbb{N}}$ con una función estrictamente creciente, $k:\mathbb{N} \to \mathbb{N}$. Esto significa que una subsucesión tomará elementos en $X$ de la sucesión, en el mismo orden en que aparecen, aunque es posible que vaya descartando algunos.
Los puntos en verde señalan un ejemplo de subsucesión.
Hay una relación entre el límite de una sucesión y los de sus subsucesiones:
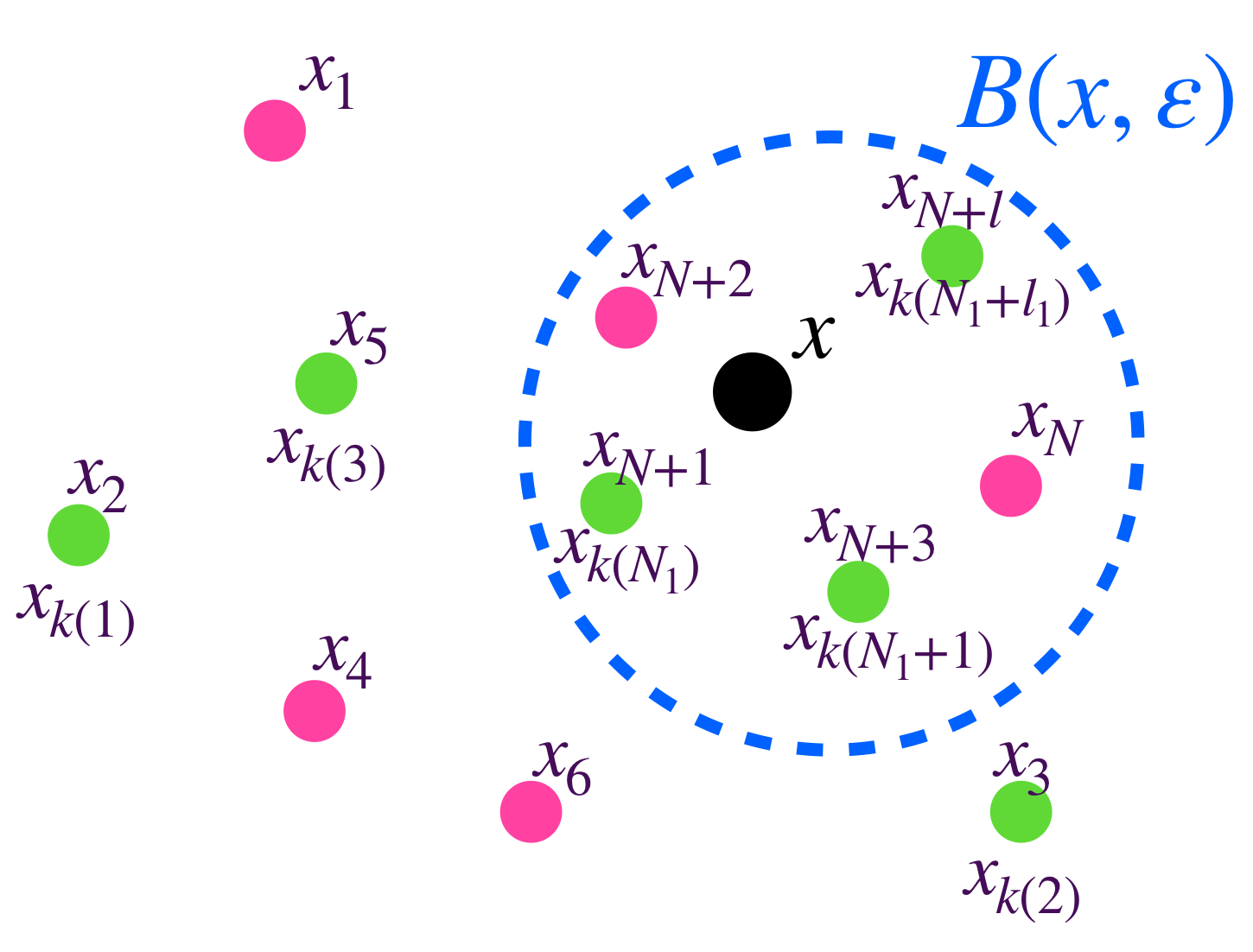
Proposición. Una sucesión $(x_n)_{n \in \mathbb{N}}$ converge a $x$ en $X$ si y solo si toda subsucesión $(x_{k(n)})_{n \in \mathbb{N}}$ converge a $x$ en $X$.
Tanto los últimos puntos de la sucesión como los de la subsucesión se aproximan al punto de convergencia.
Demostración: Sea $(x_{k(n)})_{n \in \mathbb{N}} \,$ una subsucesión de $(x_n)_{n \in \mathbb{N}}$. Como $(x_n)_{n \in \mathbb{N}} \,$ converge entonces existe $N \in \mathbb{N}$ tal que para todo $n \geq N, \, d(x_n,x) < \varepsilon$. Ya que $k: \mathbb{N} \to \mathbb{N}$ es estrictamente creciente, tenemos que para todo $j \geq N, \, k(j) \geq k(N) \geq N$. Así, $d(x_{k(j)},x)< \varepsilon$, lo cual demuestra que $(x_{k(n)}) \to x$. El regreso es trivial, pues es posible definir una subsucesión como la sucesión misma.
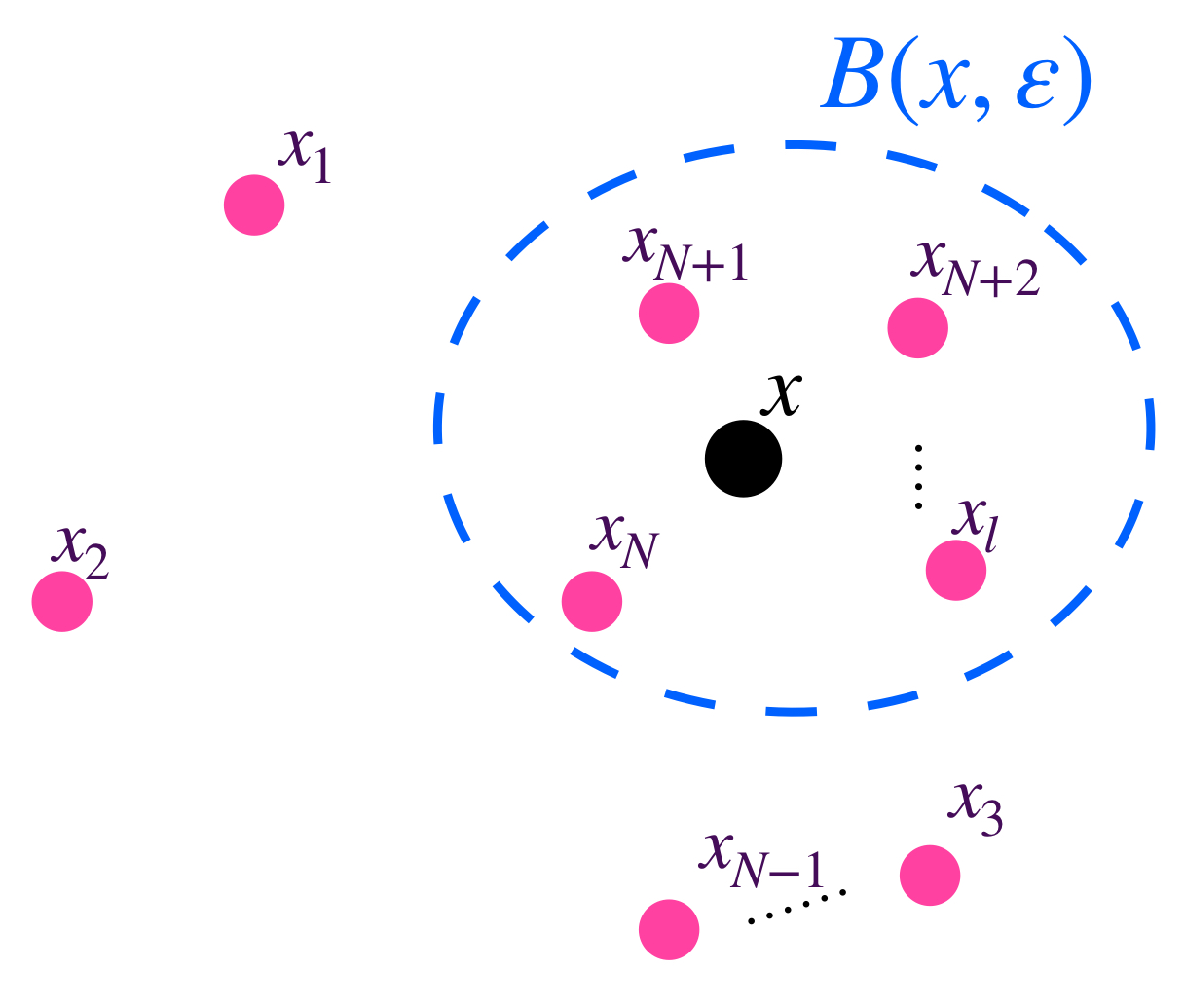
Definición. Sucesión acotada. Diremos que una sucesión $(x_n)_{n \in \mathbb{N}} \,$ en $X$ es acotada si existe $M \in \mathbb{R}$ y $x \in X$ tales que para todo $ \, n \in \mathbb{N}$ ocurre que $d(x,x_n) \leq M$. Esto significa que una sucesión es acotada si todos los puntos $x_n,$ con $n \in \mathbb{N}$ están en una bola abierta con centro en algún punto $x$ del espacio métrico.
Representación de una sucesión acotada.
¿Es posible concluir que una sucesión es convergente si sabemos que se trata de una sucesión acotada? Al final se te propondrá dar un ejemplo de una sucesión acotada que no sea convergente. En contraparte, tenemos la siguiente:
Proposición. Toda sucesión convergente es acotada.
Demostración: Sea $(x_n)_{n \in \mathbb{N}} \,$ una sucesión que converge a $x$ en $X$. Buscamos «encerrar» todos los puntos de la sucesión en una bola abierta. Si suponemos $\varepsilon = 1$, existe $N \in \mathbb{N}$ tal que para todo $n \geq N, \, d(x_n,x)<1$. Hasta aquí ya logramos «encerrar» todos los puntos de la sucesión a partir de $x_N$.
A partir de $x_N$, los puntos de la sucesión están en una bola abierta.
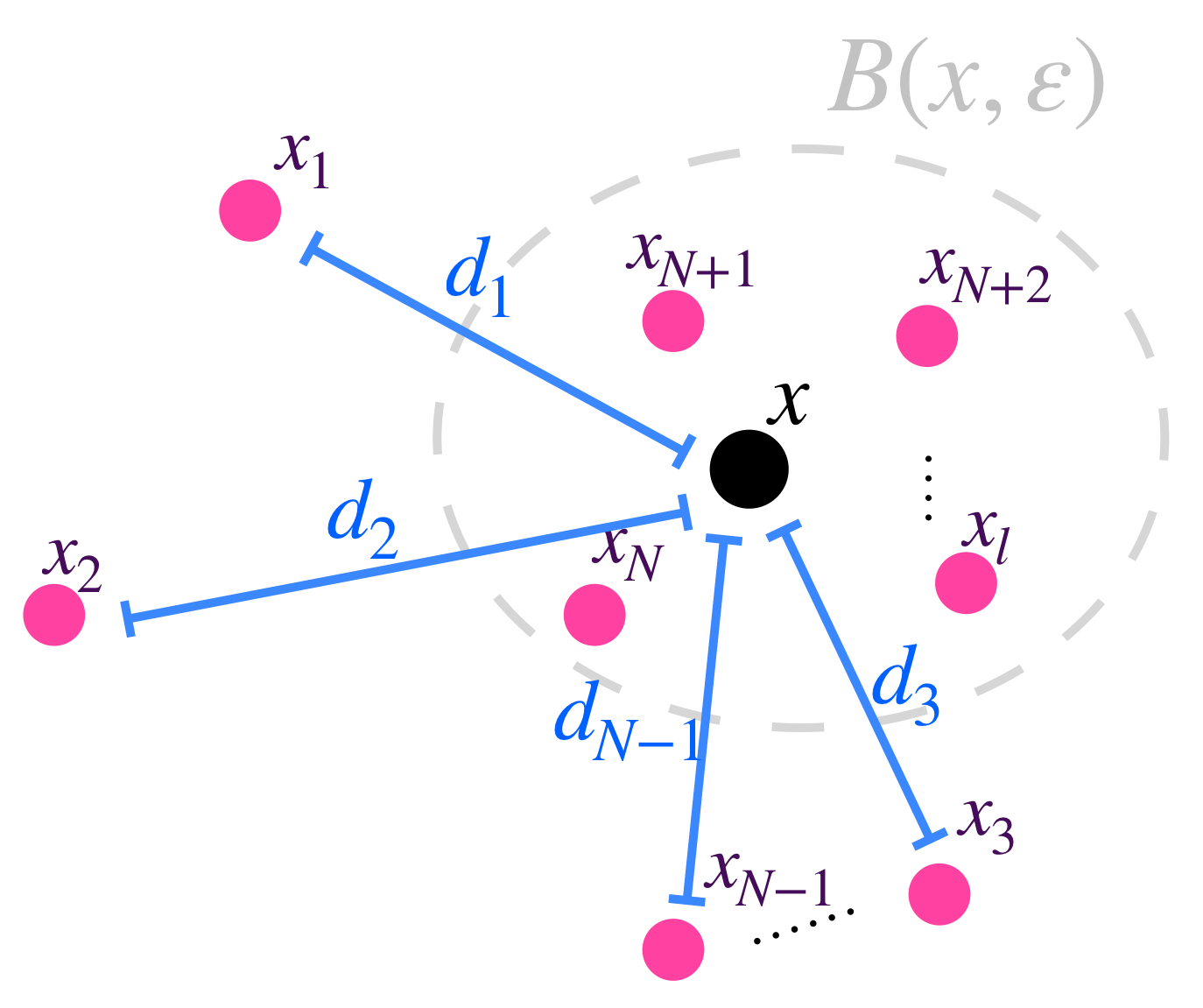
Para encerrar los elementos que van antes en la sucesión, considera las distancias entre $x$ y cada uno de esos puntos como $d_i := d(x_i,x), \, i=1,…,N-1$.
Representación de las distancias entre $x$ y los puntos $x_1, x_2,…,x_{N-1}.$
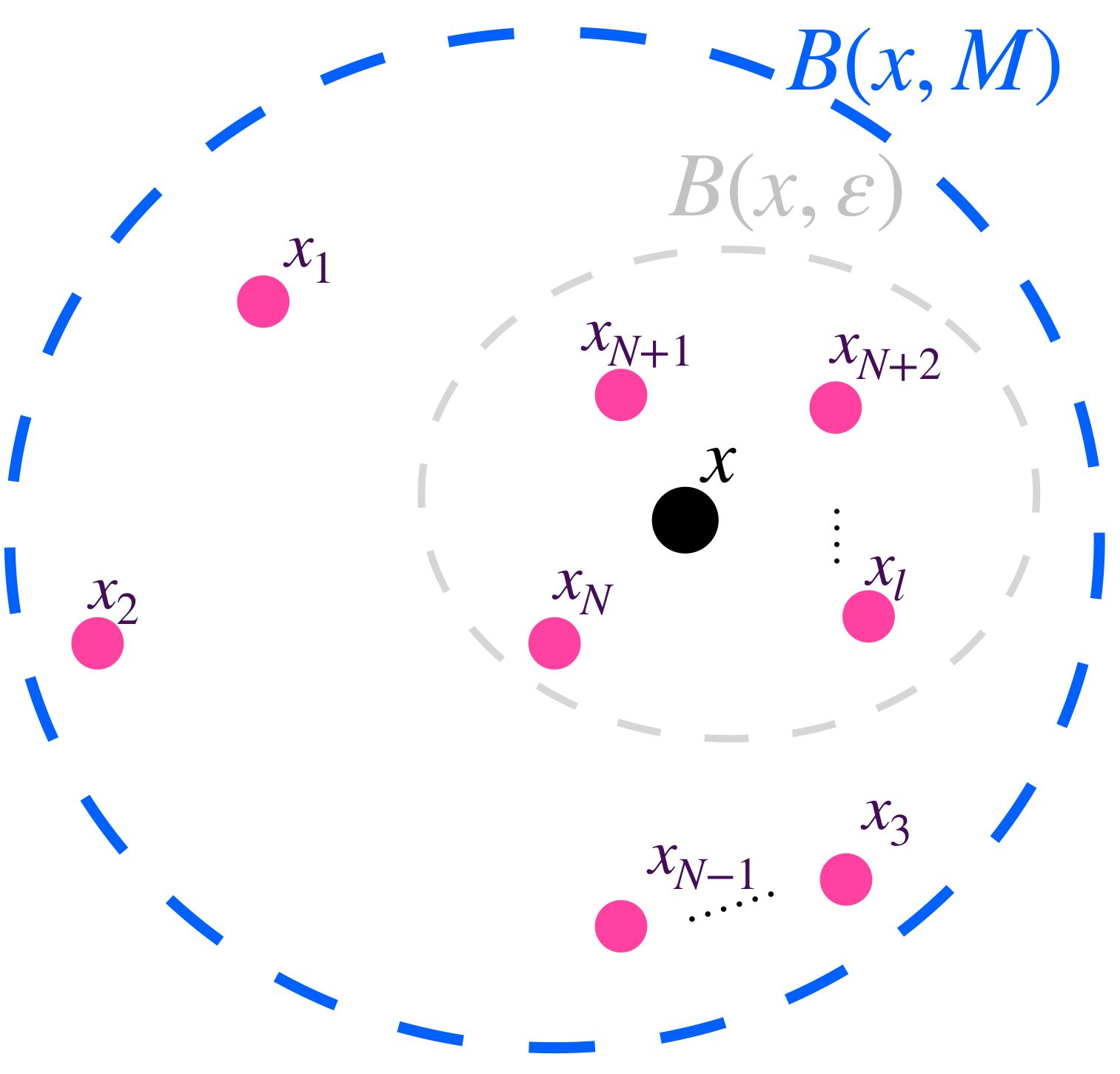
Si hacemos $M = max\{d_1,…,d_{N-1},1\}, \,$ se consigue que para todo $n \in \mathbb{N}, \, d(x_n,x)<M$ con lo cual se demuestra que la sucesión es acotada.
Todos los puntos de la sucesión están en una bola abierta.
Los últimos resultados que expondremos en esta entrada son muy importantes, en el sentido en que suele acudirse a ellos para otras demostraciones. Te sugerimos tenerlos presentes.
Proposición. Si $x_n \to x$ en $X$ entonces $x$ es un punto de contacto del conjunto $\{x_n \,|n \in \mathbb{N}\} \,$ (el conjunto de elementos de la sucesión). Según la definición, basta con demostrar que toda bola abierta de radio $\varepsilon >0$ con centro en $x$ interseca al conjunto $\{x_n\}$. La demostración se deja como ejercicio.
Toda bola abierta con centro en el punto de convergencia tiene elementos de la sucesión.
Proposición. Sea $A \subset X$ y $x \in X$. Entonces $x \in \overline{A}$ si y solo si existe una sucesión $(x_n)_{n \in \mathbb{N}} \,$ en $A$ tal que $x_n \to x$ en $X$.
Demostración: El regreso se concluye a partir de la proposición anterior. Si $x \in \overline{A}$ entonces todas las bolas abiertas con centro en $x$ intersecan al conjunto $A$. Así, para cada $n \in \mathbb{N}$, podemos elegir un punto $x_n \in B(x, \frac{1}{n}) \cap A$. Como $d(x,x_n)< \frac{1}{n} \to 0$ en $\mathbb{R}$, se concluye que $x_n \to x$ en $X$.
Todo punto de contacto de un conjunto tiene una sucesión (de elementos del conjunto) que converge a él.
Más adelante…
Tendremos un acercamiento a un espacio métrico cuyos elementos son los subconjuntos cerrados de otro espacio métrico. Al definir la distancia entre estos subconjuntos cerrados veremos que, si una sucesión de ellos converge, entonces lo hace en un subconjunto cerrado. Ya que eso significa que la distancia tiende a cero, y la distancia entre dos elementos es cero cuando son iguales, podemos esperar que los subconjuntos de la sucesión se parecerán cada vez más, al subconjunto al cual convergen.
Tarea moral
Prueba que si $(x_n) \to x$ en $X$ entonces $x$ es un punto de contacto del conjunto $\{x_n \,|n \in \mathbb{N}\}$.
Demuestra que una sucesión constante converge.
¿Puede una sucesión ser convergente en el espacio discreto? ¿Bajo qué condiciones?
Da un ejemplo de una sucesión en $\mathbb{Q}$ que converge en $\mathbb{R}$ pero no en $\mathbb{Q}$.
Sea $A \subset X$. Demuestra que $x$ es un punto interior de $A$ si y solo si para toda $(x_n)_{n \in \mathbb{N}}$ que converge a $x$ en $X$, existe $N>0$ tal que para todo $ \, n \geq N, x_n \in A$.
Demuestra que $x \in X$ es un punto frontera de $A \subset X$ si y solo si existen sucesiones $(a_n)_{n \in \mathbb{N}}$ en $A$ y $(b_n)_{n \in \mathbb{N}}$ en $X\setminus A$ que convergen a $x$.
Demuestra que si la imagen de una sucesión es finita entonces la sucesión es convergente.
Da un ejemplo de una sucesión acotada que no sea convergente.
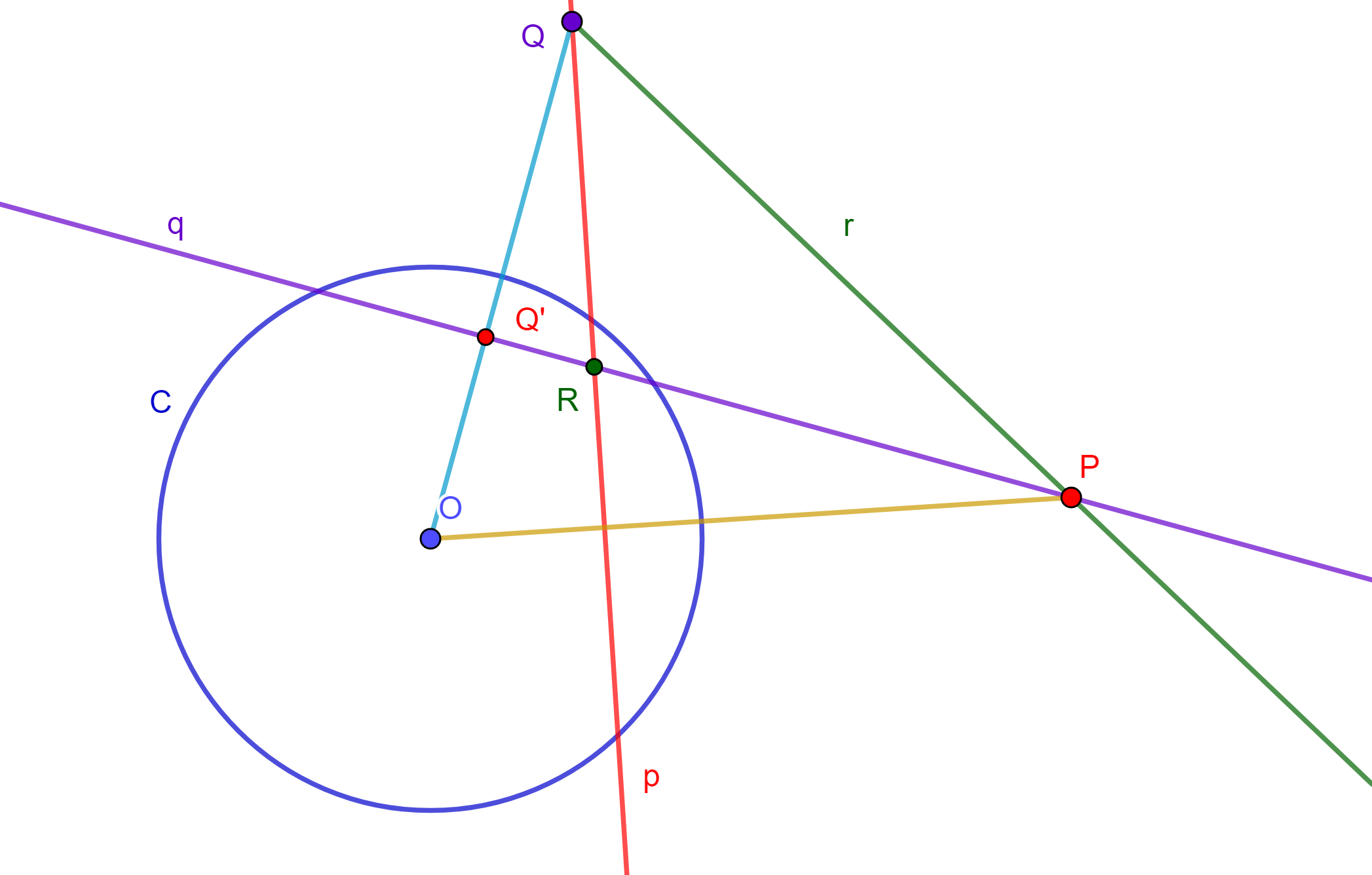
Se tiene una correspondencia geométrica fundamental, la cual implica la transformación de cada punto del plano en una línea recta única y viceversa, mediante el uso de una circunferencia. La línea recta vinculada a un punto se denomina la polar de dicho punto, mientras que el punto mismo recibe el nombre de polo de la línea, es por ello que estudiaremos el tema de polos y polares.
Polos y Polares
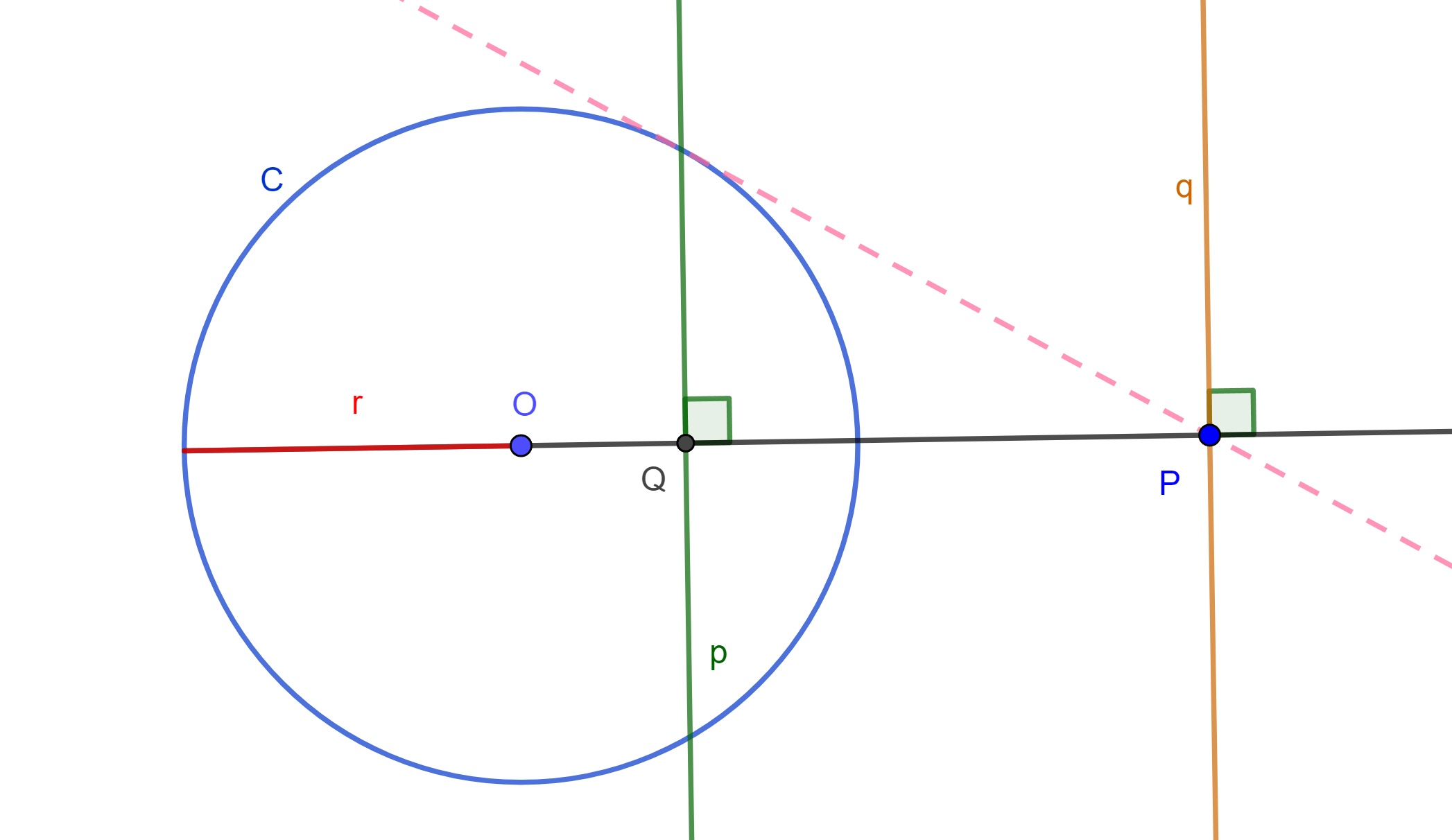
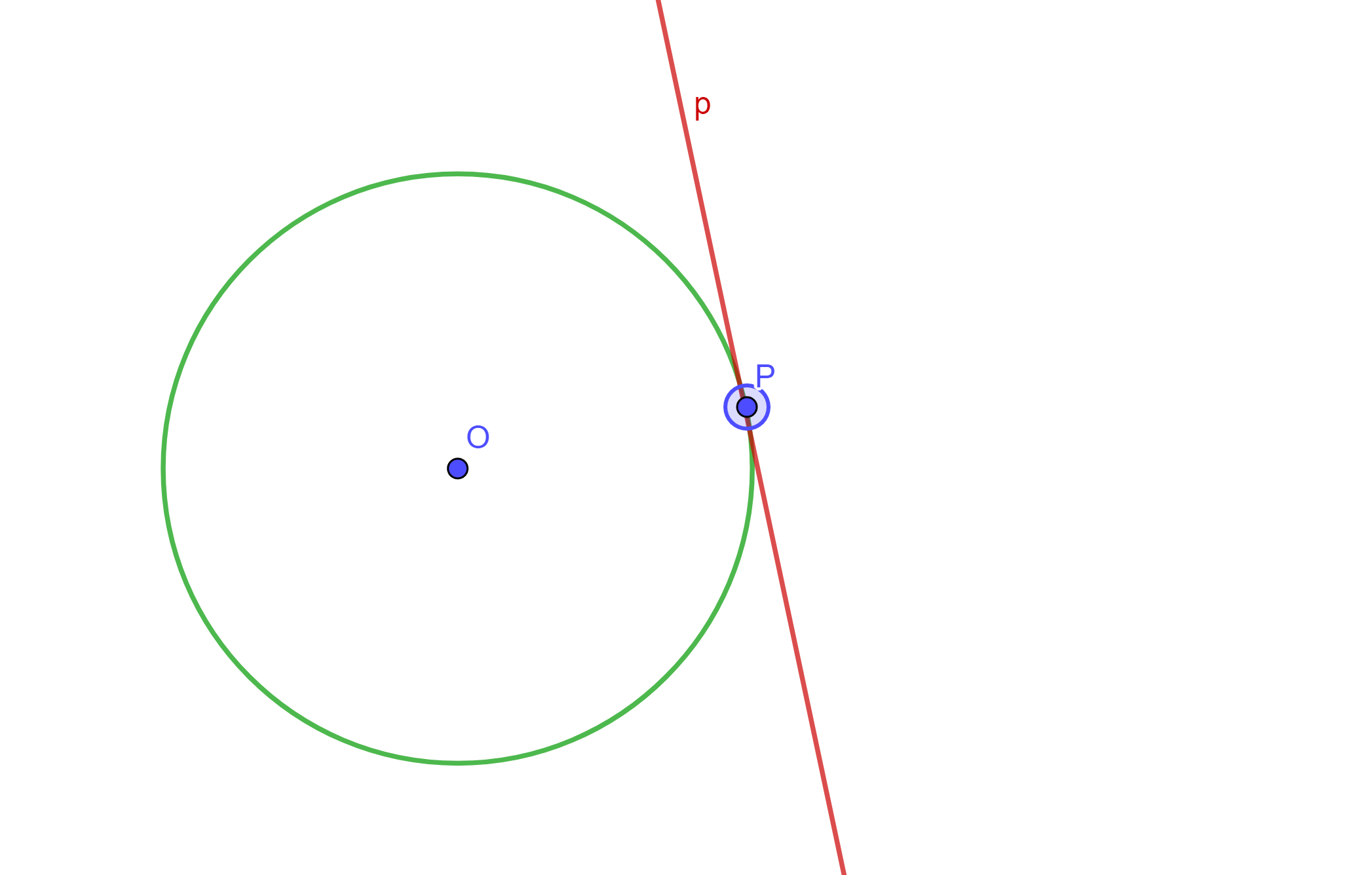
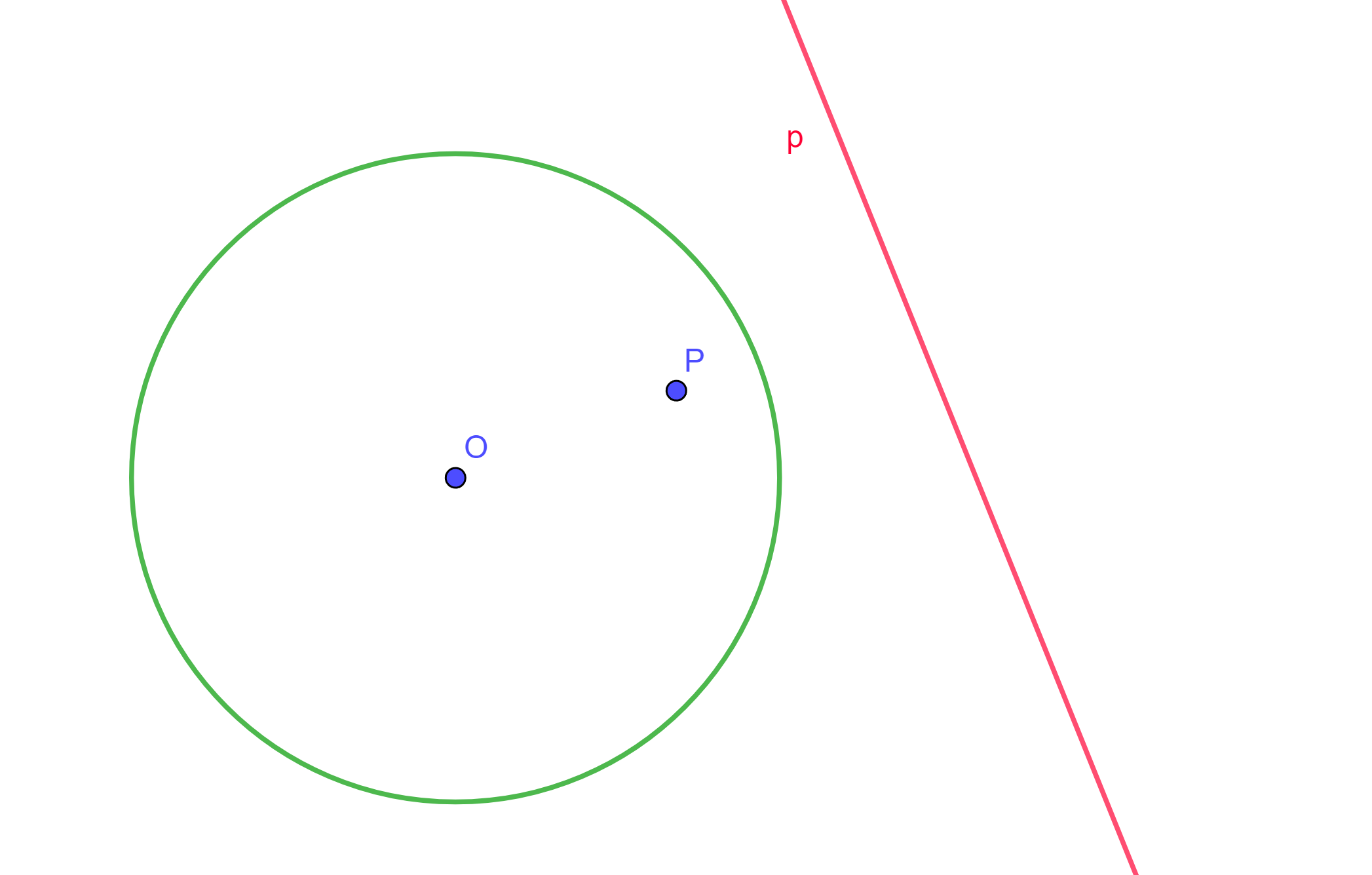
Definición. Dada una circunferencia $C(O,r)$, dos puntos inversos $P$ y $Q$ respecto a $C(O,r)$. Sea $p$ la perpendicular a $OQ$ y que pasa por $Q$, y sea $q$ la perpendicular a $OP$ y pasa por $P$.
Entonces se dirá que «$p$ es la recta polar de $P$» y «$q$ es la recta polar de $Q$» ambas respecto a $C$. De igual forma se dirá que «$Q$ es el polo de $q$» y «$P$ es el polo de $p$» ambos respecto a $C$.
Se cumplen varias propiedades:
1.- Si $P$ es un punto exterior a la circunferencia, entonces $p$ es secante a la circunferencia $C$.
2.- Si $P$ es un punto de $C$, entonces $p$ es tangente a la circunferencia $C$.
3.- Si $P$ es un punto interior a $C$, entonces $p$ es ajena a la circunferencia $C$.
4.- La polar del centro de la circunferencia es la línea al infinito, y el polo de un diámetro de circunferencia $C$ es un punto al infinito.
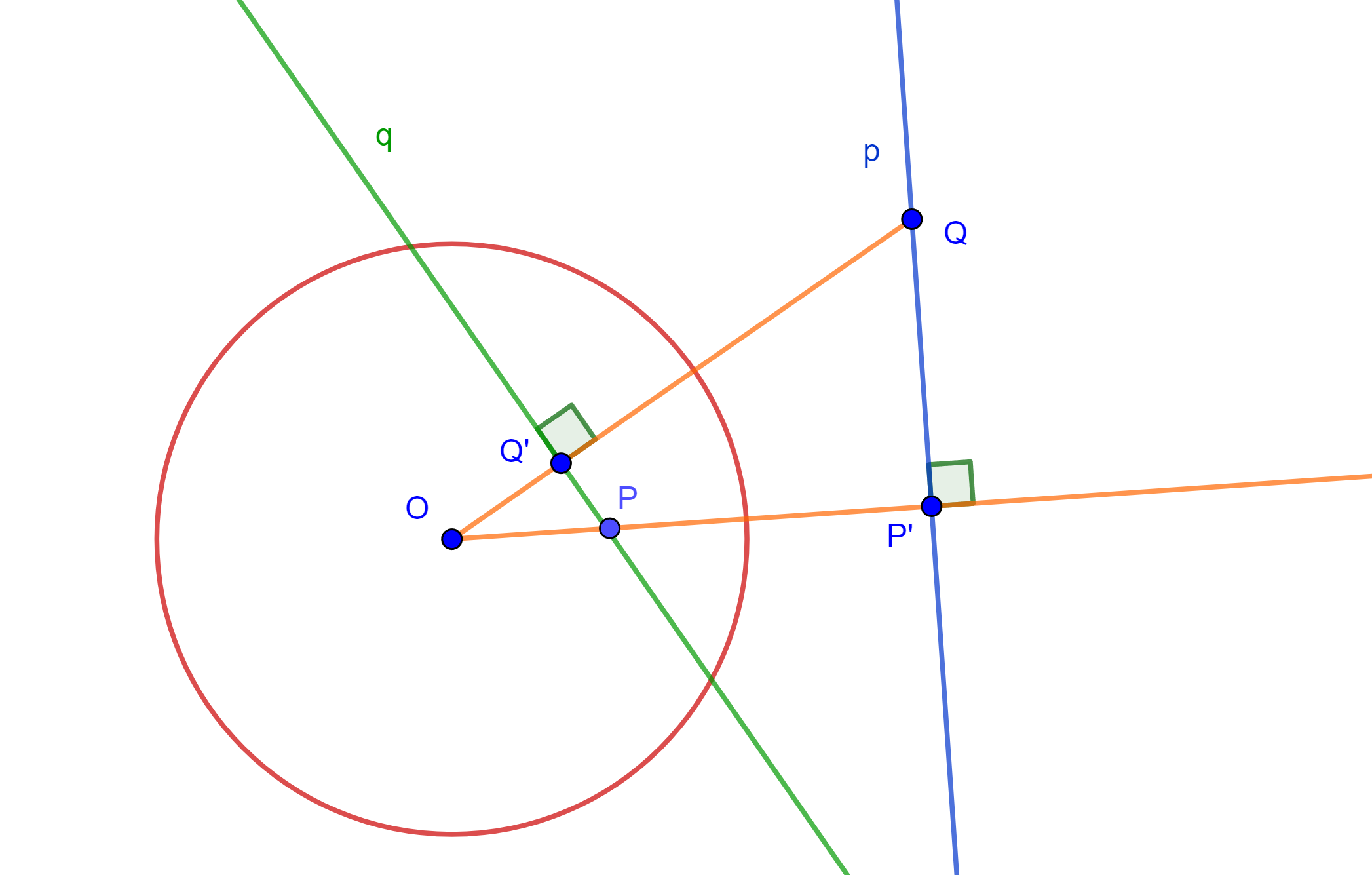
Teorema. (Fundamental de Polos y Polares) Si respecto a una circunferencia dada $C(O,r)$, la polar de $P$ pasa por $Q$ entonces la polar de $Q$ pasa por $P$. A las rectas $p$ y $q$, se les llama conjugadas polares y, a los puntos $P$ y $Q$ se les denomina conjugados polares.
Demostración. Se tiene que $p$ es la polar de $P$ y $Q$ pertenece a $p$, ahora se tiene que $Q’$ es el inverso de $Q$ entonces $OP \times OP’ = r^2 = OQ \times OQ’$, por lo cual se tiene un cuadrilátero cíclico $PP’QQ’$, entonces $Q’P$ es perpendicular a $OQ$.
Por lo tanto, $Q’P=q$ es polar de $Q$.
$\square$
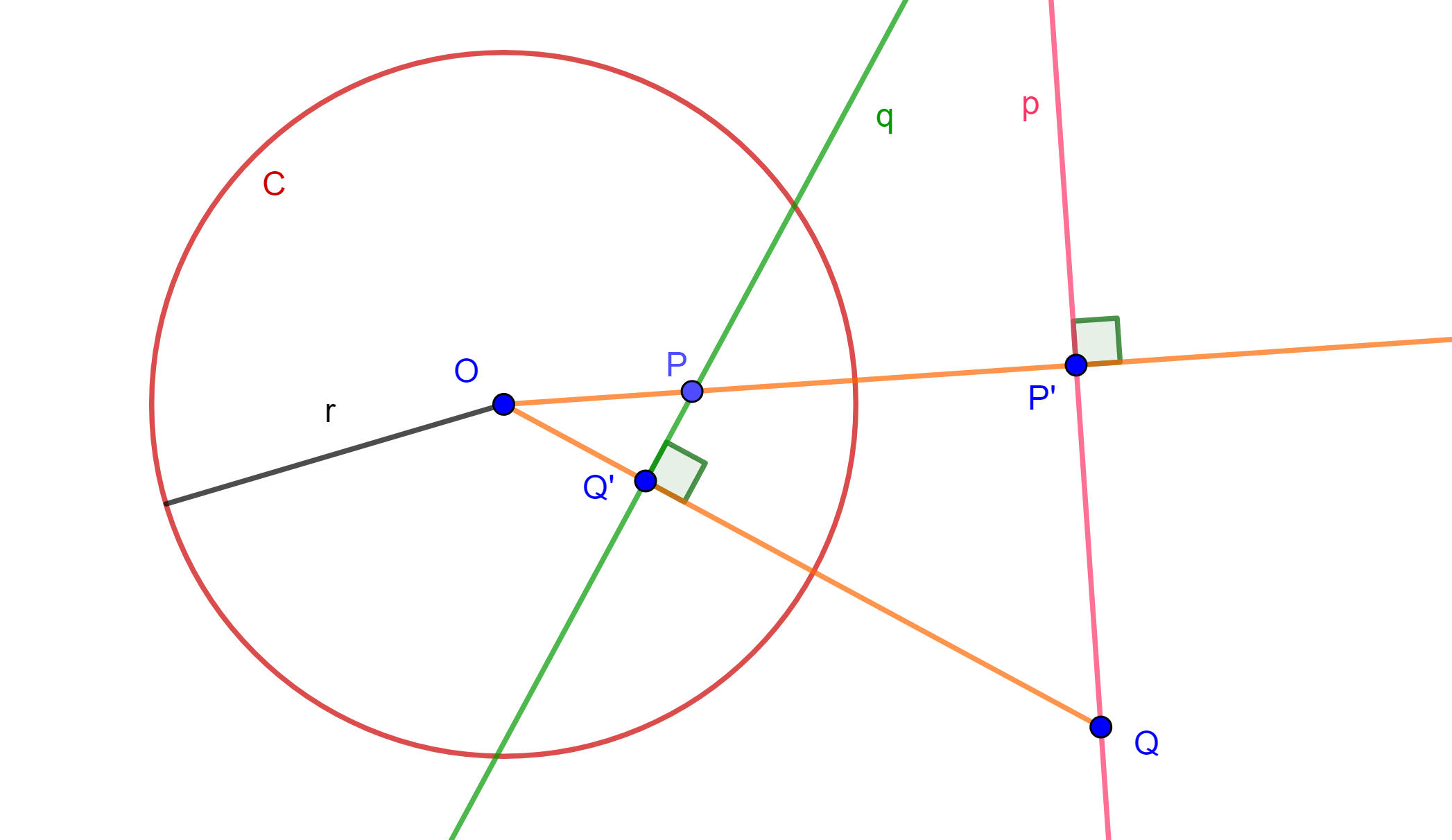
Corolario. Sean $p$ y $q$ líneas tales que, con respecto a una circunferencia $C$ dada, se dice que el polo de $p$ está en $q$, entonces el polo de $q$ está en $p$.
Demostración. Dadas $p$ y $q$ dos rectas y $P$ el polo de $p$, supongamos que $P$ está en $q$.
Sea $P’$ el inverso de $P$ y $P’$ perteneciente a $p$. Sean $OQ’$ perpendicular a $q$ y $Q$ es $OQ’$ intersección con $p$, pero $PQ’QP$ es un cuadrilátero cíclico, la circunferencia que lo contiene es ortogonal a $C$ y su inversa respecto a $C$ es ella misma, también $OP \times OP’ = OQ \times OQ’ = r^2$.
Entonces $Q$ y $Q’$ son inversas, por lo tanto, $Q$ es polo de $q$.
$\square$
«Se puede decir que las polares de una hilera son las líneas de un haz y que los polos de las líneas de un haz son los puntos de una hilera.»
Definición. (Puntos Conjugados) Dados dos puntos $P$ y $Q$ con respecto a una circunferencia, tales que la polar de uno pasa por el otro, diremos que $P$ y $Q$ son puntos conjugados respecto a la circunferencia $C$.
Definición. (Líneas Conjugadas) Respecto a una circunferencia $C$, se tienen dos líneas $p$ y $q$ tales que el polo de una está en el otro, se dirá que $p$ y $q$ son rectas conjugadas respecto a la circunferencia $C$.
Se tienen las siguientes propiedades:
1.- De dos puntos conjugados distintos en una línea que interseque la circunferencia, uno está dentro y el otro fuera de la circunferencia.
Demostración. Sea $r$ la línea que contiene a $P$ y $Q$, sea $R$ el polo de $r$ por lo cual la polar de $R$ es $r$ y pasa por $P$, entonces la polar de $P$ pasa por $R$, ahora como $P$ y $Q$ son conjugados entonces la polar de $P$ pasa por $Q$, por lo cual la polar de $P$ es la línea $RQ$ !
Por lo tanto, uno de los dos puntos conjugados está dentro y el otro afuera de la circunferencia.
$\square$
2.- Dadas dos líneas distintas conjugadas que se intersecan fuera de la circunferencia, una corta la circunferencia y la otra no.
3.- Cualquier punto en la circunferencia es conjugado a todos los puntos de la tangente en ese punto.
4.- Cualquier tangente a la circunferencia es conjugada a todas las líneas por su punto de contacto.
Más adelante…
La relación armónica está relacionada con respecto a lo hablado de polos y polares, por lo cual más adelante se hablara sobre teoremas relacionados con ambos temas.
Uno de los conceptos más importantes en el álgebra lineal es la operación conocida como determinante. Si bien este concepto se extiende a distintos objetos, en esta entrada lo revisaremos como una operación que se puede aplicar a matrices cuadradas. Como veremos, el determinante está muy conectado con otros conceptos que hemos platicado sobre matrices
Definición para matrices de $2\times 2$
A modo de introducción, comenzaremos hablando de determinantes para matrices de $2\times 2$. Aunque este caso es sencillo, podremos explorar algunas de las propiedades que tienen los determinantes, las cuales se cumplirán de manera más genera. Así, comencemos con la siguiente definición.
Definición. Para una matriz $A = \begin{pmatrix} a & b \\ c & d \end{pmatrix}$, definimos su determinante como \[ \operatorname{det}(A) = ad – bc. \]
Otra notación que podemos encontrar para determinantes es la notación de barras. Lo que se hace es que la matriz se encierra en barras verticales, en vez de paréntesis. Así, los determinantes anteriores también se pueden escribir como \[ \begin{vmatrix} 9 & 3 \\ 5 & 2 \end{vmatrix} = 3 \qquad \text{y} \qquad \begin{vmatrix} 4 & -3 \\ 12 & -9 \end{vmatrix} = 0. \]
Primeras propiedades del determinante
El determinante de una matriz de $2\times 2$ ayuda a detectar cuándo una matriz es invertible. De hecho, esto es algo que vimos previamente, en la entrada de matrices invertibles. En ella, dijimos que una matriz $A = \begin{pmatrix} a & b \\ c & d \end{pmatrix}$ es invertible si y sólo si se cumple que $ad – bc \ne 0$. ¡Aquí aparece el determinante! Podemos reescribir el resultado de la siguiente manera.
Teorema. Una matriz de la forma $A = \begin{pmatrix} a & b \\ c & d \end{pmatrix}$ es invertible si y sólo si $\det(A) \ne 0$. Cuando el determinante es distinto de cero, la inversa es $A^{-1} = \frac{1}{\det(A)}\begin{pmatrix} d & -b \\ -c & a \end{pmatrix}$.
Otra propiedad muy importante que cumple el determinante para matrices de $2\times 2$ es la de ser multiplicativo; es decir, para matrices $A$ y $B$ se cumple que $\operatorname{det}(AB) = \operatorname{det}(A) \operatorname{det}(B)$. La demostración de esto se basa directamente en las definiciones de determinante y de producto de matrices. Hagamos las cuentas a continuación para matrices $A=\begin{pmatrix} a_{11} & a_{12} \\ a_{21} & a_{22} \end{pmatrix}$ y $B=\begin{pmatrix} b_{11} & b_{12} \\ b_{21} & b_{22} \end{pmatrix}.$
Interpretación geométrica del determinante de $2\times 2$
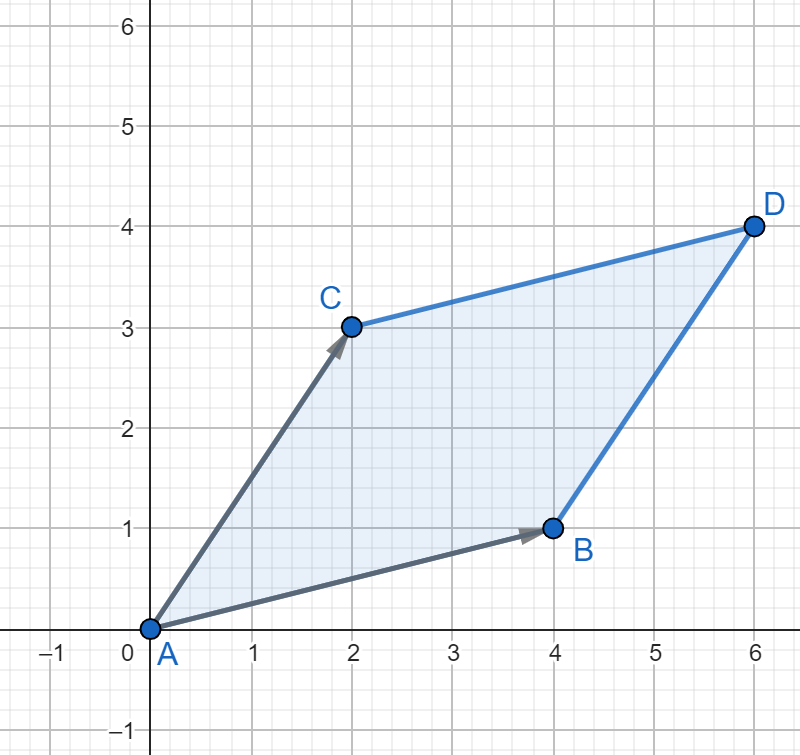
El determinante también tiene una interpretación geométrica muy interesante. Si tenemos una matriz de $2\times 2$, entonces podemos pensar a cada una de las columnas de esta matriz como un vector en el plano. Resulta que el determinante es igual al área del paralelogramo formado por estos vectores.
Por ejemplo, si consideramos la matriz \[ \begin{pmatrix} 4 & 2 \\ 1 & 3 \end{pmatrix}, \] podemos ver que el vector asociado a su primera columna es el vector $(4,1)$, mientras que el vector asociado a su segunda columna es $(2,3)$:
Así, el paralelogramo $ABDC$ de la figura anterior formado por estos dos vectores tiene área igual a \[ \operatorname{det} \begin{pmatrix} 4 & 2 \\ 1 & 3 \end{pmatrix} = 4\cdot 3 – 2\cdot 1 = 10. \]
No daremos la demostración de este hecho, pues se necesita hablar más sobre la geometría del plano. Sin embargo, las ideas necesarias para este resultado pueden consultarse en un curso de Geometría Analítica I.
Definición recursiva
También nos interesa hablar de determinantes de matrices más grandes. De hecho, nos interesa hablar del determinante de cualquier matriz cuadrada. La definición formal requiere de varios conocimientos de Álgebra Lineal I. Sin embargo, por el momento podemos platicar de cómo se obtienen los determinantes de matrices recursivamente. Con esto queremos decir que para calcular el determinante de matrices de $3\times 3$, necesitaremos calcular varios de matrices de $2\times 2$. Así mismo, para calcular el de matrices de $4\times 4$ requeriremos calcular varios de matrices de $3\times 3$ (que a su vez requieren varios de $2\times 2$).
Para explicar cómo es esta relación de poner determinantes de matrices grandes en términos de matrices más pequeñas, primeramente definiremos la función $\operatorname{sign}$, la cual asigna a cada pareja de enteros positivos $(i,j)$ el valor \[ \operatorname{sign}(i,j) = (-1)^{i+j}. \] A partir de la función $\operatorname{sign}$ podemos hacer una matriz cuya entrada $a_{ij}$ es $\operatorname{sign}(i,j)$. Para visualizarla más fácilmente, podemos pensar que a la entrada $a_{11}$ (la cual se encuentra en la esquina superior izquierda) le asigna el signo “$+$”, y posteriormente va alternando los signos del resto de entradas. Por ejemplo, los signos correspondientes a las entradas de la matriz de $3 \times 3$ \[ \begin{pmatrix} a_{11} & a_{12} & a_{13} \\ a_{21} & a_{22} & a_{23} \\ a_{31} & a_{32} & a_{33} \end{pmatrix} \] serían \[ \begin{pmatrix} + & – & + \\ – & + & – \\ + & – & + \end{pmatrix}, \] mientras que los signos correspondientes a las entradas de la matriz de $4 \times 4$ \[ \begin{pmatrix} a_{11} & a_{12} & a_{13} & a_{14} \\ a_{21} & a_{22} & a_{23} & a_{24} \\ a_{31} & a_{32} & a_{33} & a_{34} \\ a_{41} & a_{42} & a_{43} & a_{44} \end{pmatrix} \] serían \[ \begin{pmatrix} + & – & + & – \\ – & + & – & + \\ + & – & + & – \\ – & + & – & + \end{pmatrix}. \]
Ya que entendimos cómo se construyen estas matrices, el cálculo de determinantes se realiza como sigue.
Estrategia. Realizaremos el cálculo de determinante de una matriz de $n \times n$ descomponiéndola para realizar el cálculo de determinantes de matrices de $(n-1) \times (n-1)$. Eventualmente llegaremos al calcular únicamente determinantes de matrices de $2 \times 2$, para las cuales ya tenemos una fórmula. Para esto, haremos los siguientes pasos repetidamente.
Seleccionaremos una fila o columna arbitraria de la matriz original (como en este paso no importa cuál fila o columna seleccionemos, buscaremos una que simplifique las operaciones que realizaremos; generalmente nos convendrá seleccionar una fila o columna que cuente en su mayoría con ceros).
Para cada entrada $a_{ij}$ en la fila o columna seleccionada, calculamos el valor de \[ \operatorname{sign}(i,j) \cdot a_{ij} \cdot \operatorname{det}(A_{ij}), \] donde $A_{ij}$ es el la matriz que resulta de quitar la fila $i$ y la columna $j$ a la matriz original.
El determinante de la matriz será la suma de todos los términos calculados en el paso anterior.
Veamos algunos ejemplos de cómo se utiliza la estrategia recién descrita.
A primera vista no hay alguna fila o columna que parezca simplificar los cálculos, por lo cual podemos proceder con cualquiera de estas; nosotros seleccionaremos la primera fila. \[ \begin{pmatrix} \fbox{3} & \fbox{1} & \fbox{-1} \\ 6 & -1 & -2 \\ 4 & -3 & -2 \end{pmatrix}. \]
Observemos que el valor de tres de las entradas de la segunda columna es $0$. Por esta razón, seleccionaremos esta columna para descomponer la matriz: \[ \begin{pmatrix} 4 & \fbox{0} & 2 & 2 \\ -1 & \fbox{3} & -2 & 5 \\ -2 & \fbox{0} & 2 & -3 \\ 1 & \fbox{0} & 4 & -1 \end{pmatrix}. \]
El siguiente paso será calcular el producto \[ \operatorname{sign}(i,j) \cdot a_{ij} \cdot \operatorname{det}(A_{ij}), \] para cada entrada de esta columna. Sin embargo, por la elección de columna que hicimos, podemos ver que el valor de $a_{ij}$ es 0 para tres de las entradas, y por tanto también lo es para el producto que deseamos calcular. De este modo, únicamente nos restaría calcular el producto \begin{align*} \operatorname{sign}(2,2) \cdot a_{22} \cdot \operatorname{det}(A_{22}) &= +(3)\operatorname{det} \begin{pmatrix} 4 & \blacksquare & 2 & 2 \\ \blacksquare & \blacksquare & \blacksquare & \blacksquare \\ -2 & \blacksquare & 2 & -3 \\ 1 & \blacksquare & 4 & -1 \end{pmatrix} \\[5pt] &= +(3)\operatorname{det} \begin{pmatrix} 4 & 2 & 2 \\ -2 & 2 & -3 \\ 1 & 4 & -1 \end{pmatrix}. \end{align*} Se queda como ejercicio al lector concluir que el resultado de este último producto es 30.
Aunque esta definición recursiva nos permite calcular el determinante de una matriz cuadrada de cualquier tamaño, rápidamente se vuelve un método muy poco práctico (para obtener el determinante de una matriz de $6 \times 6$ tendríamos que calcular hasta 60 determinantes de matrices de $2 \times 2$). En el curso de Álgebra Lineal I se aprende otra definición de determinante a través de permutaciones, de las cuales se desprenden varios métodos más eficientes para calcular determinante. Hablaremos un poco de estos métodos en la siguiente entrada.
Las propiedades de $2\times 2$ también se valen para $n\times n$
Las propiedades que enunciamos para matrices de $2\times 2$ también se valen para determinantes de matrices más grandes. Todo lo siguiente es cierto, sin embargo, en este curso no contamos con las herramientas para demostrar todo con la formalidad apropiada:
El determinante es multiplicativo: Si $A$ y $B$ son matrices de $n\times n$, entonces $\operatorname{det}(AB) = \operatorname{det}(A)\operatorname{det}(B)$.
El determinante detecta matrices invertibles: Una matriz $A$ de $n\times n$ es invertible si y sólo si su determinante es distinto de $0$.
El determinante tiene que ver con un volumen: Los vectores columna de una matriz $A$ de $n\times n$ hacen un paralelepípedo $n$-dimensional cuyo volumen $n$-dimensional es justo $\det{A}$.
Más adelante…
En esta entrada conocimos el concepto de determinante de matrices, vimos cómo calcularlo para matrices de distintos tamaños y revisamos cómo se interpreta cuando consideramos las matrices como transformaciones de flechas en el plano. En la siguiente entrada enunciaremos y aprenderemos a usar algunas de las propiedades que cumplen los determinantes.
Tarea moral
Calcula los determinantes de las siguientes matrices:



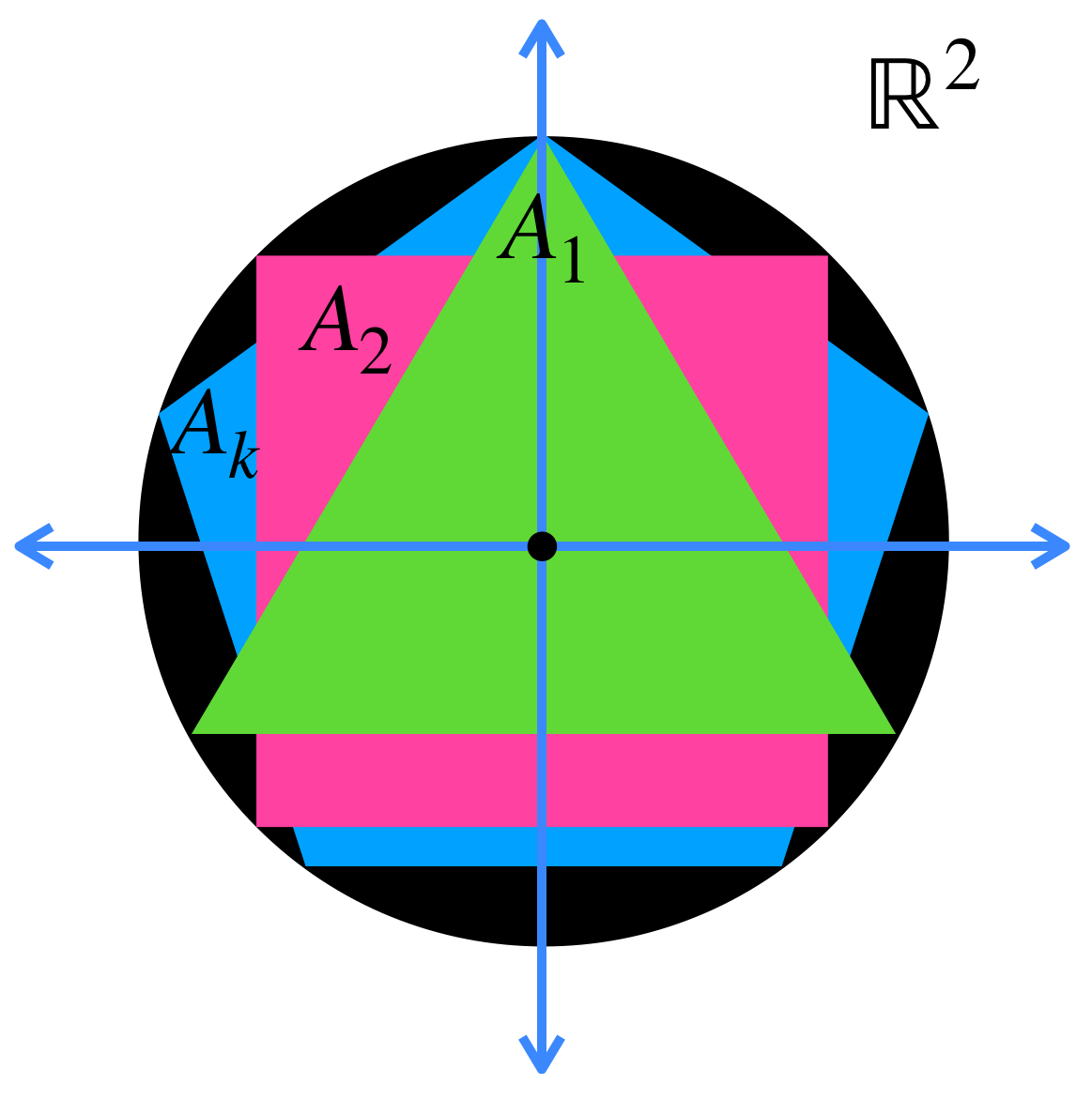
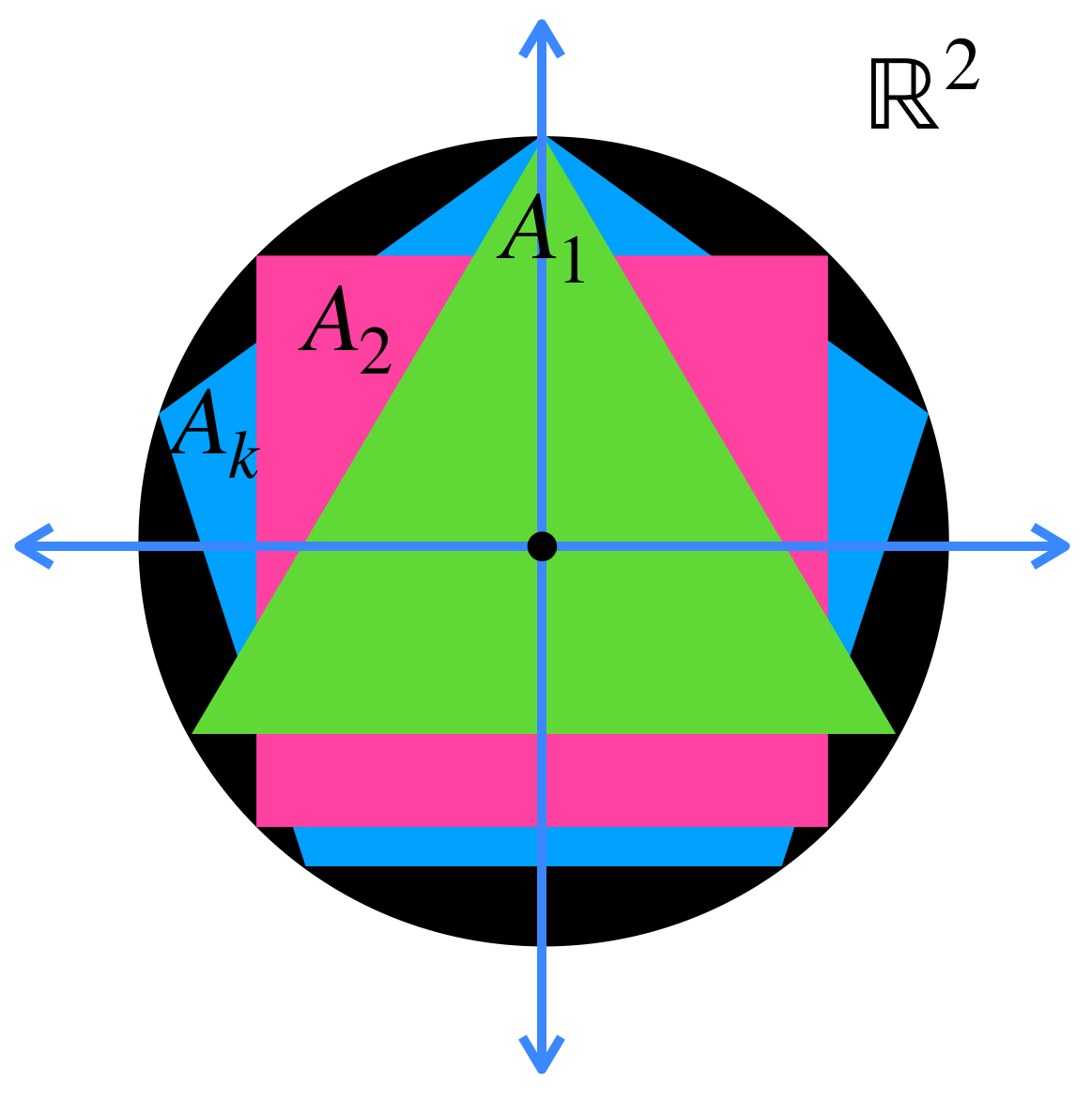
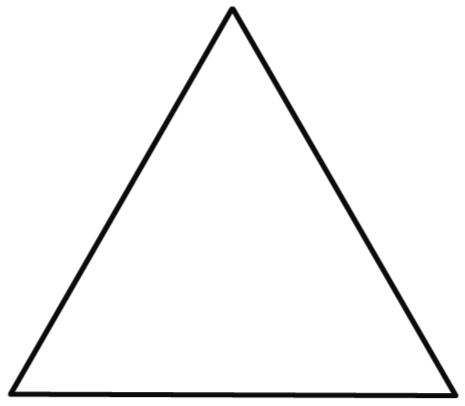 $A_1$ es un triángulo equilátero.
$A_1$ es un triángulo equilátero. $A_2$ sustituye la tercera parte central de cada lado por dos aristas de la misma medida.
$A_2$ sustituye la tercera parte central de cada lado por dos aristas de la misma medida. $A_3$ Hace lo mismo. Se repite el proceso recursivamente
$A_3$ Hace lo mismo. Se repite el proceso recursivamente