Introducción
Ya hablamos de lo que es la forma canónica y la forma estándar de un problema lineal. Como platicamos, esto nos permitirá darle solución a los problemas siguiendo métodos que requieren tener el problema en alguna de estas dos formas. Lo que haremos ahora es reflexionar a qué nos referimos con resolver un problema de programación lineal. Para ello, recordemos los distintos tipos de soluciones que los problemas lineales pueden tener.
Tipos de soluciones y región de factibilidad
Recordemos los conceptos de soluciones factibles, soluciones básicas factibles (degeneradas y no degeneradas) y de región de factibilidad.
Supongamos que tenemos un problema de programación lineal en su forma canónica:
\begin{align*}
Max \quad z &= cx\\
s.a&\\
Ax &\leq b\\
x &\geq \bar 0\\
\end{align*}
donde usamos la misma notación que en la entrada anterior. Recordemos que $c$ es un vector fila en $\mathbb{R}^n$, $x$ es un vector columna en $\mathbb{R}^n$, $b$ es vector columna en $\mathbb{R}^m$ y $A$ es una matriz de $m\times n$. Recuerda que en la expresión anterior entendemos $\bar 0$ como un vector en $\mathbb{R}^n$ con entradas todas iguales a cero.
También recordemos la forma estándar de un problema de programación lineal:
\begin{align*}
Max \quad z &= cx\\
s.a&\\
Ax &=b\\
x &\geq \bar 0\\
\end{align*}
en donde $c$ es un vector fila en $\mathbb{R}^n$, $x$ es un vector columna en $\mathbb{R}^{n}$, $b$ es un vector columna en $\mathbb{R}^{m}$ y $A$ es una matriz de valores reales de $m \times n$.
Como recordatorio, tenemos las siguientes definiciones para los tipos de soluciones del problema lineal.
Definición. Una solución factible es aquella que satisface las restricciones de un problema de programación lineal.
Definición. La región de factibilidad es el conjunto de todas las soluciones factibles de un problema de programación lineal.
Definición. Una solución básica es una solución $x = (x_1,x_2, \ldots, x_n)$ correspondiente al problema en forma estándar ($Ax = b$) que tiene al menos $n-m$ entradas iguales a cero y las columnas de las $m$ variables restantes son linealmente independientes.
Definición. Una solución básica factible es una solución básica cuyas variables son todas no negativas.
Definición. Una solución básica factible no degenerada es una solución básica $x$ correspondiente a una solución $x$ del problema en forma estándar con exactamente $m$ componentes positivas. En otras palabras, $x$ tiene exactamente $n-m$ entradas iguales a cero.
Definición. Una solución básica factible degenerada es una solución básica correspondiente a una solución $x$ del problema en forma estándar con menos de $m$ componentes positivas. En otras palabras, $x$ tiene más de $n-m$ entradas iguales a cero.
Las soluciones básicas factibles no degeneradas son las que más nos interesan ya que el óptimo se encuentra entre estas soluciones. También se puede demostrar que toda solución básica factible es un punto extremo de la región factible.
A continuación explicaremos algunos de estos puntos con un ejemplo detallado, que te ayudará a entender la intuición detrás de estas definiciones y de su importancia.
Ejemplos de región de factibilidad y tipos de solución
Consideremos el siguiente problema de programación lineal en su forma canónica:
\begin{align*}
Max. \quad z &= 2x_1 + 3x_2\\
s.a.&\\
&\begin{matrix}2x_1 &+ x_2 &\leq & 4\\
x_1 &+ 2x_2 &\leq &5\end{matrix}\\
&x_1, x_2 \geq 0.
\end{align*}
La región de factibilidad es el conjunto de todos los $(x_1,x_2)$ (en el plano $\mathbb{R}^2$) que cumplen las restricciones del problema, es decir, $2x_1 + x_2 \leq 4$, $x_1 + 2x_2 \leq 5$ y $x_1,x_2 \geq 0$. Para entender esto mejor, vamos a ilustrar cada restricción en $\mathbb{R}^2$ a continuación :
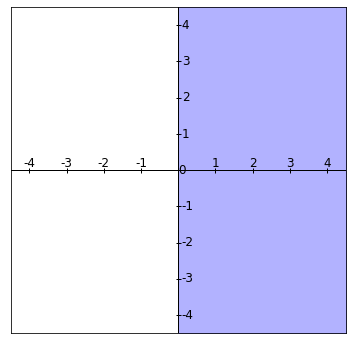
Región 1: La región $x_1\geq 0$, que son todos los elementos de $\mathbb{R}^2$ que se encuentran a la derecha del eje $Y$ incluyéndolo:
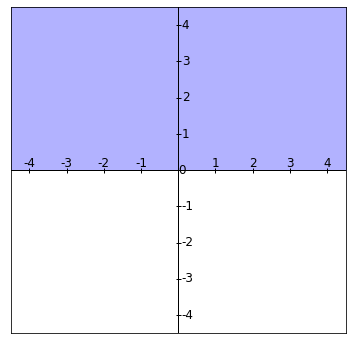
Región 2: La región $x_2\geq 0$, que son todos los elementos de $\mathbb{R}^2$ que se encuentran arriba del eje $X$ incluyéndolo:
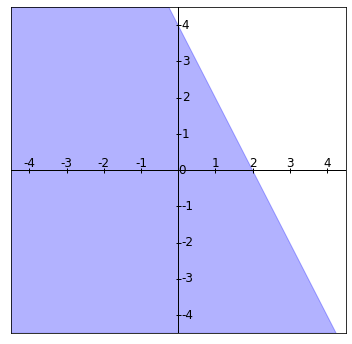
Región 3: La región $2x_1 + x_2 \leq 4$, que son los elementos en $\mathbb{R}^2$ que están debajo de la recta $2x_1+x_2=4$ incluyéndola:
Región 4: La región $x_1+2x_2\leq 5$, que son los elementos en $\mathbb{R}^2$ que están debajo de la recta $x_1+2x_2=5$ incluyéndola:
Como queremos que se cumplan todas las restricciones al mismo tiempo, los puntos $(x_1,x_2) \in \mathbb{R}^2$ de la región de factibilidad que se encuentren en todas las regiones al mismo tiempo, es decir, los puntos que estén en la intersección. Al sobreponer las regiones que acabamos de ilustrar, obtenemos la región encerrada en la siguiente figura:
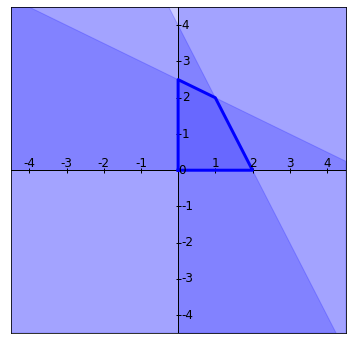
También puedes explorar el interactivo de Geogebra en donde se han coloreado los complementos de las regiones para más claridad. Puedes usar el cursor para mover la figura y las herramientas de lupa para hacer acercamientos y alejamientos.
Como hemos mencionado, el óptimo de un problema de programación lineal es una solución básica factible no degenerada y toda solución básica factible no degenerada se encuentra en algún vértice de la región de factibilidad. Entonces, el valor máximo de la función $2x_1+3x_2$ se alcanza en alguno de los vértices del polígono que es la región factible. Veamos dónde el álgebra nos dice esto.
Para ello, pensemos al problema en su forma estándar, tomando variables de holgura $s_1$ y $s_2$. Las restricciones que tienen las cuatro variables en conjunto son las siguientes.
\begin{align*}
2x_1 + x_2 + s_1 &= 4\\
x_1 + 2x_2 + s_2 &= 5\\
x_1, x_2, s_1, s_2 &\geq 0.
\end{align*}
La matriz $A’$ es $\begin{pmatrix}2 & 1 & 1 & 0 \\ 1 & 2 & 0 & 1 \end{pmatrix}$, tiene rango $2$ (recordemos que el rengo de una matriz es el número de filas o columnas linealmente independientes que posee). Las soluciones básicas y no degeneradas corresponden a tener en ese sistema de ecuaciones exactamente $m=2$ variables positivas, de manera que necesitamos hacer exactamente $n-m=4-2=2$ de estas variables iguales a cero. Al hacer esto, podemos resolver para las $m=2$ variables restantes. Por ejemplo, si establecemos $x_1 = 0$ y $x_2 = 0$, las ecuaciones se convierten en:
\begin{align*}
s_1 = 4\\
s_2 = 5\\
x_1, x_2, s_1, s_2 \geq 0,
\end{align*}
que tiene solución única $(x_1,x_2,s_1,s_2)=(0,0,4,5)$. Así, la solución básica del problema en forma canónica es $(x_1,x_2)=(0,0)$. Hay que recordar la solución básica sólo para las variables originales, es decir, las del problema en forma canónica.
Esta solución corresponde al punto $A$ del interactivo de GeoGebra. Se puede determinar otra solución básica fijando $s_1 = 0$ y $s_2 = 0$, donde el sistema sería ahora
\begin{align*}
2x_1 + x_2 = 4\\
x_1 + 2x_2 = 5\\
x_1, x_2, s_1, s_2 \geq 0,
\end{align*}
Resolvamos este sistema de ecuaciones de forma rápida. Si multiplicamos la segunda ecuación por un $-2$ y sumamos ambas ecuaciones, la variable $x_1$ se eliminará y tendremos solo una ecuación: $-3x_2 = -6$ lo que es equivalente a $x_2 = 2$. Si sustituimos ahora este valor para $x_2$ en cualquiera de las ecuaciones, tras unos simples despejes tendremos que $x_1 = 1$.
Así, la solución básica que se obtiene es $(x_1,x_2)=(1,2)$, que es el punto $D$ del interactivo de GeoGebra.
Si seguimos considerando todas las posibilidades en las que dos variables son cero y resolvemos los ssistemas de ecuaciones resultantes, eso nos dará todas soluciones básicas no degeneradas. La solución óptima es la solución básica factible (punto extremo) con el mejor valor objetivo.
En este ejemplo tenemos $\binom{4}{2} = \frac{4!}{2!2!} = 6$ formas de volver dos de las $n$ variables iguales a cero. Ya para las variables $x_1$ y $x_2$, los puntos que obtenemos son los puntos $A$, $B$, $C$, $D$ que son puntos extremos de la región de factibilidad. Los puntos $E$ y $F$ del interactivo también son puntos básicos y no degenerados (son las otras dos intersecciones de las rectas que dibujamos), pero como no satisfacen la condición de factibilidad del problema, entonces no los podemos considerar y por lo tanto no son candidatos a dar el valor óptimo.
La siguiente tabla muestra todas las soluciones básicas factibles y no factibles de este problema:
| Variables no básicas (cero) | Variables básicas | Solución para $(x_1,x_2)$ | Punto de extremo asociado | ¿Factible? | Valor objetivo z |
| $(x_1, x_2) = (0,0)$ | $(s_1, s_2) = (4,5)$ | $(0, 0)$ | A | Sí | 0 |
| $(x_1, s_1) = (0,0)$ | $(x_2, s_2) = (4,-3)$ | $(0, 4)$ | E | No ya que $s_2 < 0$ | 12 (No factible) |
| $(x_1, s_2) = (0,0)$ | $(x_2, s_1) = (2.5,1.5) $ | $(0, 2.5)$ | B | Sí | 7.5 |
| $(x_2, s_1) = (0,0)$ | $(x_1, s_2) = (2,3)$ | $(2, 0)$ | C | Sí | 4 |
| $(x_2, s_2) = (0,0)$ | $(x_1, s_1) = (5, -6)$ | $(5, 0)$ | F | No ya que $s_1 < 0$ | 10 (No factible) |
| $(s_1, s_2) = (0,0)$ | $(x_1, x_2) = (1,2)$ | $(1, 2)$ | D | Sí | 8 (óptimo) |
Más adelante…
Notemos que a medida que el tamaño del problema se incrementa, enumerar todos los puntos esquina se volverá una tarea que tomaría mucho tiempo. Por ejemplo, si tuviéramos $20$ variables (ya con las de holgura) y $10$ restricciones, es necesario resolver considerar $\binom{20}{10}=184756$ formas de crear ecuaciones de $10\times 10$, y resolver cada una de ellas. Aunque esto es finito, son demasiadas operaciones. Y este en la práctica incluso es un ejemplo pequeño, ya que en la vida real hay problemas lineales que pueden incluir miles de variables y restricciones.
Por ello, se vuelve cruciar encontrar un método que atenúe esta carga computacional en forma drástica, que permita investigar sólo un subconjunto de todas las posibles soluciones factibles básicas no degeneradas (vértices de la región de factibilidad), pero que garantice encontrar el óptimo. Una idea intuitiva que debería servir es comenzar en un vértice y «avanzar en una dirección que mejore la función objetivo». Esto precisamente es la intuición detrás del método simplex, que repasaremos a continuación.
Tarea moral
- Considera el siguiente problema lineal en su forma canónica:
\begin{align*}
Min \quad z &= 2x_1 + 3x_2 \\
s.a.&\\
&\begin{matrix}x_1 &+ 3x_2 &\geq&6\\
3x_1 &+ 2x_2 &\geq &6\end{matrix}\\
&x_1, x_2 \geq 0.
\end{align*}
Usa el procedimiento descrito arriba para encontrar todas sus soluciones básicas no degeneradas y encontrar el óptimo del problema.
- Considera un problema de programación lineal en dos variables $x$ y $y$, en forma canónica y con $m$ restricciones (desigualdades), además de las restricciones $x\geq 0$ y $y\geq 0$. Explica con tus propias palabras por qué la región de factibilidad siempre es un polígono con a lo más $m+2$ lados, y por qué entonces basta evaluar la función objetivo en a lo más $m+2$ puntos para encontrar su máximo.
- Explica con tus palabras cómo se vería la región de factibilidad de un problema de programación lineal de maximización que no tenga máximo. ¿Qué cambios se le tendrían que hacer a las restricciones del primer ejemplo para que se volviera un problema de maximización sin máximo?
Respuestas
1.- Primero vamos a cambiar este problema a su forma estándar.
Definamos variables de holgura no negativas $s_1$ y $s_2$ tales que $x_1 + 3x_2 – s_1 = 6$ y $3x_1 +2x_2 – s_2 = 6$.
Entonces la forma estandar del problema sería de la siguiente manera:
\begin{align*}
Min \quad z &= 2x_1 + 3x_2 \\
s.a.&\\
&\begin{matrix}x_1 &+ 3x_2 &- s_1 = &6\\
3x_1 &+ 2x_2 &- s_2 = &6\end{matrix}\\
&x_1, x_2, s_1, s_2 \geq 0.
\end{align*}
Su matriz A asociado a las restricciones $\begin{pmatrix}1 & 3 & -1 & 0 \\ 3 & 2 & 0 & -1 \end{pmatrix}$ en una matriz de $2 \times 4$. Las soluciones básicas no degeneradas $x’$ en $\mathbb{R}^4$ tienen $4-2 = 2$ entradas iguales a 0.
| Variables no básicas (cero) | Variables básicas | Solución para $(x_1,x_2)$ | Punto de extremo asociado | ¿Factible? | Valor objetivo z |
| $(x_1, x_2) = (0,0)$ | $(s_1, s_2) = (-6,-6)$ | $(0, 0)$ | A | No ya que $s_1,s_2 < 0$ | 0 |
| $(x_1, s_1) = (0,0)$ | $(x_2, s_2) = (2,-2)$ | $(0, 2)$ | B | No ya que $s_2 < 0$ | 6 (No factible) |
| $(x_1, s_2) = (0,0)$ | $(x_2, s_1) = (3,3)$ | $(0, 3)$ | C | Sí | 9 |
| $(x_2, s_1) = (0,0)$ | $(x_1, s_2) = (6, 12) $ | $(6, 0)$ | D | Sí | 12 |
| $(x_2, s_2) = (0,0)$ | $(x_1, s_1) = (2,-4)$ | $(2, 0)$ | E | No ya que $s_1 < 0$ | 4 (No factible) |
| $(s_1, s_2) = (0,0)$ | $(x_1, x_2) = (6/7,12/7)$ | $(6/7,12/7)$ | F | Sí | 48/7 = 6 + 6/7 (óptimo) |
Por lo que el óptimo se encuentra en el punto F = (6/7, 12/7).
En el siguiente interactivo de GeoGebra, verifica uno por uno los puntos extremos que se encontraron.
2.- Se podría argumentar tal vez que cada restricción de un problema de programación lineal representa un lado del polígono que forma la región factible. Y como tenemos m restricciones en el problema y las condiciones de no negatividad son 2 restricciones más, el polígono tendrá a lo más m+2 lados.
3.- La región de factibilidad se vería como una región no acotada en el primer cuadrante del plano. En esta región, dada un punto x dentro de ella, existe otro punto x’ tal que $z(x) < z(x’)$.
El que se tendría que hacer en el primer problema sería simplemente invertir las desigualdades de las restricciones:
\begin{align*}
Max. \quad z &= 2x_1 + 3x_2\\
s.a.&\\
&\begin{matrix}2x_1 &+ x_2 &\geq & 4\\
x_1 &+ 2x_2 &\geq &5\end{matrix}\\
&x_1, x_2 \geq 0.
\end{align*}
Se puede verificar haciendo los cambios en el primer interactivo que estos cambios nos cambiaran la región factible a una región no acotada.
Referencias bibliográficas
- Wayne L. Winston, Operations Research, Belmont, CA, USA: Thomson Learning, 2004.
- David G. Luenberger, Linear and Nonlinear Programming, Stanford, CA, USA: Springer, 2008.
- Frederick S. Hillier, Gerald J. Lieberman, Introducción a la investigación de operaciones, Stanford, CA, USA: McGRAW-HILL, 2010.
Entradas relacionadas
- Ir a Investigación de Operaciones
- Entrada anterior del curso: Forma canónica y forma estándar de un problema lineal
- Entrada siguiente del curso: