Introducción
Uno de los conceptos más importantes en el álgebra lineal es la operación conocida como determinante. Si bien este concepto se extiende a distintos objetos, en esta entrada lo revisaremos como una operación que se puede aplicar a matrices cuadradas. Como veremos, el determinante está muy conectado con otros conceptos que hemos platicado sobre matrices
Definición para matrices de $2\times 2$
A modo de introducción, comenzaremos hablando de determinantes para matrices de $2\times 2$. Aunque este caso es sencillo, podremos explorar algunas de las propiedades que tienen los determinantes, las cuales se cumplirán de manera más genera. Así, comencemos con la siguiente definición.
Definición. Para una matriz $A = \begin{pmatrix} a & b \\ c & d \end{pmatrix}$, definimos su determinante como
\[
\operatorname{det}(A) = ad – bc.
\]
Basándonos en esta definición, podemos calcular los determinantes
\[
\operatorname{det}
\begin{pmatrix} 9 & 3 \\ 5 & 2 \end{pmatrix}=9\cdot 2 – 3\cdot 5 = 3
\]
y
\[
\operatorname{det}
\begin{pmatrix} 4 & -3 \\ 12 & -9 \end{pmatrix}
=
4\cdot (-9)-(-3)\cdot 12= 0.
\]
Otra notación que podemos encontrar para determinantes es la notación de barras. Lo que se hace es que la matriz se encierra en barras verticales, en vez de paréntesis. Así, los determinantes anteriores también se pueden escribir como
\[
\begin{vmatrix} 9 & 3 \\ 5 & 2 \end{vmatrix} = 3
\qquad
\text{y}
\qquad
\begin{vmatrix} 4 & -3 \\ 12 & -9 \end{vmatrix} = 0.
\]
Primeras propiedades del determinante
El determinante de una matriz de $2\times 2$ ayuda a detectar cuándo una matriz es invertible. De hecho, esto es algo que vimos previamente, en la entrada de matrices invertibles. En ella, dijimos que una matriz $A = \begin{pmatrix} a & b \\ c & d \end{pmatrix}$ es invertible si y sólo si se cumple que $ad – bc \ne 0$. ¡Aquí aparece el determinante! Podemos reescribir el resultado de la siguiente manera.
Teorema. Una matriz de la forma $A = \begin{pmatrix} a & b \\ c & d \end{pmatrix}$ es invertible si y sólo si $\det(A) \ne 0$. Cuando el determinante es distinto de cero, la inversa es $A^{-1} = \frac{1}{\det(A)}\begin{pmatrix} d & -b \\ -c & a \end{pmatrix}$.
Otra propiedad muy importante que cumple el determinante para matrices de $2\times 2$ es la de ser multiplicativo; es decir, para matrices $A$ y $B$ se cumple que $\operatorname{det}(AB) = \operatorname{det}(A) \operatorname{det}(B)$. La demostración de esto se basa directamente en las definiciones de determinante y de producto de matrices. Hagamos las cuentas a continuación para matrices $A=\begin{pmatrix}
a_{11} & a_{12} \\
a_{21} & a_{22}
\end{pmatrix}$ y $B=\begin{pmatrix}
b_{11} & b_{12} \\
b_{21} & b_{22}
\end{pmatrix}.$
Tenemos que:
\begin{align*}
\operatorname{det}(AB)
&=
\operatorname{det}
\left(
\begin{pmatrix}
a_{11} & a_{12} \\
a_{21} & a_{22}
\end{pmatrix}
\begin{pmatrix}
b_{11} & b_{12} \\
b_{21} & b_{22}
\end{pmatrix}
\right)
\\[5pt]
&=
\operatorname{det}
\begin{pmatrix}
a_{11}b_{11} + a_{12}b_{21} & a_{11}b_{12} + a_{12}b_{22} \\
a_{21}b_{11} + a_{22}b_{21} & a_{21}b_{12} + a_{22}b_{22}
\end{pmatrix}
\\[5pt]
&=
(a_{11}b_{11} + a_{12}b_{21})(a_{21}b_{12} + a_{22}b_{22})-(a_{11}b_{12} + a_{12}b_{22})(a_{21}b_{11} + a_{22}b_{21})
\\[5pt]
&=
a_{11}a_{22}b_{11}b_{22} – a_{12}a_{21}b_{11}b_{22} – a_{11}a_{22}b_{12}b_{21} + a_{12}a_{21}b_{12}b_{21}
\\[5pt]
&=
(a_{11}a_{22} – a_{12}a_{21})(b_{11}b_{22} – b_{12}b_{21})
\\[5pt]
&=
\operatorname{det}
\begin{pmatrix}
a_{11} & a_{12} \\
a_{21} & a_{22}
\end{pmatrix}
\operatorname{det}
\begin{pmatrix}
b_{11} & b_{12} \\
b_{21} & b_{22}
\end{pmatrix}
\\[5pt]
&=
\operatorname{det}(A)\operatorname{det}(B).
\end{align*}
Interpretación geométrica del determinante de $2\times 2$
El determinante también tiene una interpretación geométrica muy interesante. Si tenemos una matriz de $2\times 2$, entonces podemos pensar a cada una de las columnas de esta matriz como un vector en el plano. Resulta que el determinante es igual al área del paralelogramo formado por estos vectores.
Por ejemplo, si consideramos la matriz
\[
\begin{pmatrix} 4 & 2 \\ 1 & 3 \end{pmatrix},
\]
podemos ver que el vector asociado a su primera columna es el vector $(4,1)$, mientras que el vector asociado a su segunda columna es $(2,3)$:
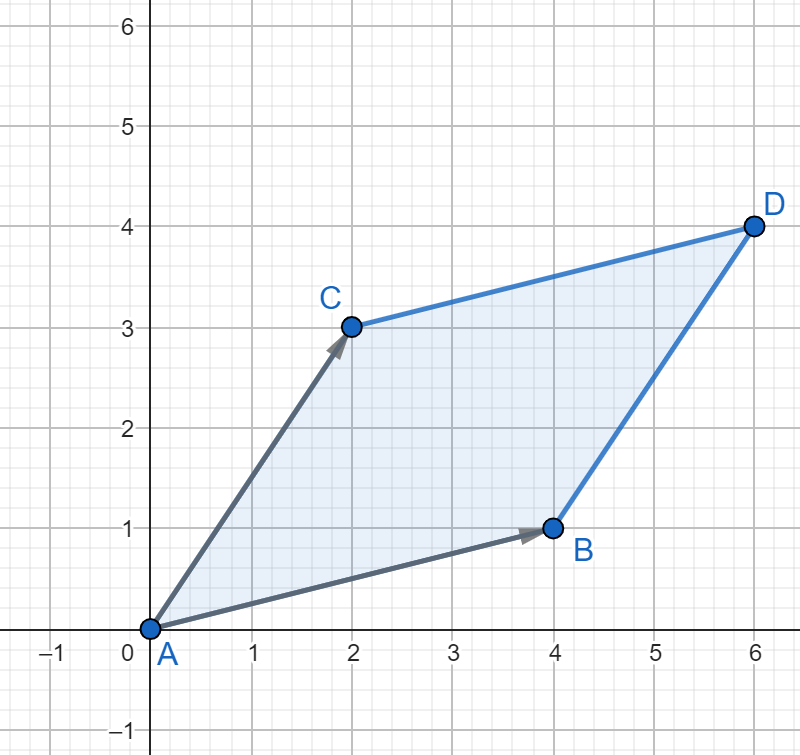
Así, el paralelogramo $ABDC$ de la figura anterior formado por estos dos vectores tiene área igual a
\[
\operatorname{det}
\begin{pmatrix} 4 & 2 \\ 1 & 3 \end{pmatrix}
= 4\cdot 3 – 2\cdot 1 = 10.
\]
No daremos la demostración de este hecho, pues se necesita hablar más sobre la geometría del plano. Sin embargo, las ideas necesarias para este resultado pueden consultarse en un curso de Geometría Analítica I.
Definición recursiva
También nos interesa hablar de determinantes de matrices más grandes. De hecho, nos interesa hablar del determinante de cualquier matriz cuadrada. La definición formal requiere de varios conocimientos de Álgebra Lineal I. Sin embargo, por el momento podemos platicar de cómo se obtienen los determinantes de matrices recursivamente. Con esto queremos decir que para calcular el determinante de matrices de $3\times 3$, necesitaremos calcular varios de matrices de $2\times 2$. Así mismo, para calcular el de matrices de $4\times 4$ requeriremos calcular varios de matrices de $3\times 3$ (que a su vez requieren varios de $2\times 2$).
Para explicar cómo es esta relación de poner determinantes de matrices grandes en términos de matrices más pequeñas, primeramente definiremos la función $\operatorname{sign}$, la cual asigna a cada pareja de enteros positivos $(i,j)$ el valor
\[
\operatorname{sign}(i,j) = (-1)^{i+j}.
\]
A partir de la función $\operatorname{sign}$ podemos hacer una matriz cuya entrada $a_{ij}$ es $\operatorname{sign}(i,j)$. Para visualizarla más fácilmente, podemos pensar que a la entrada $a_{11}$ (la cual se encuentra en la esquina superior izquierda) le asigna el signo “$+$”, y posteriormente va alternando los signos del resto de entradas. Por ejemplo, los signos correspondientes a las entradas de la matriz de $3 \times 3$
\[
\begin{pmatrix}
a_{11} & a_{12} & a_{13} \\
a_{21} & a_{22} & a_{23} \\
a_{31} & a_{32} & a_{33}
\end{pmatrix}
\]
serían
\[
\begin{pmatrix}
+ & – & + \\
– & + & – \\
+ & – & +
\end{pmatrix},
\]
mientras que los signos correspondientes a las entradas de la matriz de $4 \times 4$
\[
\begin{pmatrix}
a_{11} & a_{12} & a_{13} & a_{14} \\
a_{21} & a_{22} & a_{23} & a_{24} \\
a_{31} & a_{32} & a_{33} & a_{34} \\
a_{41} & a_{42} & a_{43} & a_{44}
\end{pmatrix}
\]
serían
\[
\begin{pmatrix}
+ & – & + & – \\
– & + & – & + \\
+ & – & + & – \\
– & + & – & +
\end{pmatrix}.
\]
Ya que entendimos cómo se construyen estas matrices, el cálculo de determinantes se realiza como sigue.
Estrategia. Realizaremos el cálculo de determinante de una matriz de $n \times n$ descomponiéndola para realizar el cálculo de determinantes de matrices de $(n-1) \times (n-1)$. Eventualmente llegaremos al calcular únicamente determinantes de matrices de $2 \times 2$, para las cuales ya tenemos una fórmula. Para esto, haremos los siguientes pasos repetidamente.
- Seleccionaremos una fila o columna arbitraria de la matriz original (como en este paso no importa cuál fila o columna seleccionemos, buscaremos una que simplifique las operaciones que realizaremos; generalmente nos convendrá seleccionar una fila o columna que cuente en su mayoría con ceros).
- Para cada entrada $a_{ij}$ en la fila o columna seleccionada, calculamos el valor de
\[
\operatorname{sign}(i,j) \cdot a_{ij} \cdot \operatorname{det}(A_{ij}),
\]
donde $A_{ij}$ es el la matriz que resulta de quitar la fila $i$ y la columna $j$ a la matriz original. - El determinante de la matriz será la suma de todos los términos calculados en el paso anterior.
Veamos algunos ejemplos de cómo se utiliza la estrategia recién descrita.
Ejemplo con matriz de $3\times 3$
Consideremos la matriz de $3 \times 3$
\[
\begin{pmatrix}
3 & 1 & -1 \\
6 & -1 & -2 \\
4 & -3 & -2
\end{pmatrix}.
\]
A primera vista no hay alguna fila o columna que parezca simplificar los cálculos, por lo cual podemos proceder con cualquiera de estas; nosotros seleccionaremos la primera fila.
\[
\begin{pmatrix}
\fbox{3} & \fbox{1} & \fbox{-1} \\
6 & -1 & -2 \\
4 & -3 & -2
\end{pmatrix}.
\]
Para cada término de la primera fila, calculamos el producto
\[
\operatorname{sign}(i,j) \cdot a_{ij} \cdot \operatorname{det}(A_{i,j}),
\]
obteniendo
\begin{align*}
\operatorname{sign}(1,1) \cdot (a_{11}) \cdot \operatorname{det}(A_{11})
&= +(3)\operatorname{det}
\begin{pmatrix}
\blacksquare & \blacksquare & \blacksquare \\
\blacksquare & -1 & -2 \\
\blacksquare & -3 & -2
\end{pmatrix}
\\[5pt]
&= +(3)\operatorname{det} \begin{pmatrix} -1 & -2 \\ -3 & -2 \end{pmatrix}
\\[5pt]
&= +(3)[(-1)(-2) – (-2)(-3)]
\\[5pt]
&= +(3)(-4)
\\[5pt]
&= -12,
\\[10pt]
\operatorname{sign}(1,2) \cdot (a_{12}) \cdot \operatorname{det}(A_{12})
&= -(1)\operatorname{det}
\begin{pmatrix}
\blacksquare & \blacksquare & \blacksquare \\
6 & \blacksquare & -2 \\
4 & \blacksquare & -2
\end{pmatrix}
\\[5pt]
&= -(1)\operatorname{det}
\begin{pmatrix} 6 & -2 \\ 4 & -2 \end{pmatrix}
\\[5pt]
&=-(1)[(6)(-2) – (-2)(4)]
\\[5pt]
&=-(1)(-4)
\\[5pt]
&=4,
\\[10pt]
\operatorname{sign}(1,3) \cdot (a_{13}) \cdot \operatorname{det}(A_{13})
&= +(-1)\operatorname{det}
\begin{pmatrix}
\blacksquare & \blacksquare & \blacksquare \\
6 & -1 & \blacksquare \\
4 & -3 & \blacksquare
\end{pmatrix}
\\[5pt]
&= +(-1)\operatorname{det} \begin{pmatrix} 6 & -1 \\ 4 & -3 \end{pmatrix}
\\[5pt]
&= +(-1)[(6)(-3) – (-1)(4)]
\\[5pt]
&= +(-1)(-14)
\\[5pt]
&= 14.
\end{align*}
Finalmente, el determinante de nuestra matriz original será la suma de los términos calculados; es decir,
\[
\begin{pmatrix}
3 & 1 & -1 \\
6 & -1 & -2 \\
4 & -3 & -1
\end{pmatrix}
=
(-12) + (4) + (14) = 6.
\]
Ejemplo con matriz de $4\times 4$
En el siguiente ejemplo veremos cómo el escoger una fila o columna en específico nos puede ayudar a simplificar mucho los cálculos.
Consideremos la matriz
\[
\begin{pmatrix}
4 & 0 & 2 & 2 \\
-1 & 3 & -2 & 5 \\
-2 & 0 & 2 & -3 \\
1 & 0 & 4 & -1
\end{pmatrix}.
\]
Observemos que el valor de tres de las entradas de la segunda columna es $0$. Por esta razón, seleccionaremos esta columna para descomponer la matriz:
\[
\begin{pmatrix}
4 & \fbox{0} & 2 & 2 \\
-1 & \fbox{3} & -2 & 5 \\
-2 & \fbox{0} & 2 & -3 \\
1 & \fbox{0} & 4 & -1
\end{pmatrix}.
\]
El siguiente paso será calcular el producto
\[
\operatorname{sign}(i,j) \cdot a_{ij} \cdot \operatorname{det}(A_{ij}),
\]
para cada entrada de esta columna. Sin embargo, por la elección de columna que hicimos, podemos ver que el valor de $a_{ij}$ es 0 para tres de las entradas, y por tanto también lo es para el producto que deseamos calcular. De este modo, únicamente nos restaría calcular el producto
\begin{align*}
\operatorname{sign}(2,2) \cdot a_{22} \cdot \operatorname{det}(A_{22})
&=
+(3)\operatorname{det}
\begin{pmatrix}
4 & \blacksquare & 2 & 2 \\
\blacksquare & \blacksquare & \blacksquare & \blacksquare \\
-2 & \blacksquare & 2 & -3 \\
1 & \blacksquare & 4 & -1
\end{pmatrix}
\\[5pt]
&= +(3)\operatorname{det}
\begin{pmatrix}
4 & 2 & 2 \\
-2 & 2 & -3 \\
1 & 4 & -1
\end{pmatrix}.
\end{align*}
Se queda como ejercicio al lector concluir que el resultado de este último producto es 30.
De este modo, obtenemos que
\[
\operatorname{det}
\begin{pmatrix}
4 & 0 & 2 & 2 \\
-1 & 3 & -2 & 5 \\
-2 & 0 & 2 & -3 \\
1 & 0 & 4 & -1
\end{pmatrix}
= 0 + 30 + 0 + 0 = 30.
\]
Aunque esta definición recursiva nos permite calcular el determinante de una matriz cuadrada de cualquier tamaño, rápidamente se vuelve un método muy poco práctico (para obtener el determinante de una matriz de $6 \times 6$ tendríamos que calcular hasta 60 determinantes de matrices de $2 \times 2$). En el curso de Álgebra Lineal I se aprende otra definición de determinante a través de permutaciones, de las cuales se desprenden varios métodos más eficientes para calcular determinante. Hablaremos un poco de estos métodos en la siguiente entrada.
Las propiedades de $2\times 2$ también se valen para $n\times n$
Las propiedades que enunciamos para matrices de $2\times 2$ también se valen para determinantes de matrices más grandes. Todo lo siguiente es cierto, sin embargo, en este curso no contamos con las herramientas para demostrar todo con la formalidad apropiada:
- El determinante es multiplicativo: Si $A$ y $B$ son matrices de $n\times n$, entonces $\operatorname{det}(AB) = \operatorname{det}(A)\operatorname{det}(B)$.
- El determinante detecta matrices invertibles: Una matriz $A$ de $n\times n$ es invertible si y sólo si su determinante es distinto de $0$.
- El determinante tiene que ver con un volumen: Los vectores columna de una matriz $A$ de $n\times n$ hacen un paralelepípedo $n$-dimensional cuyo volumen $n$-dimensional es justo $\det{A}$.
Más adelante…
En esta entrada conocimos el concepto de determinante de matrices, vimos cómo calcularlo para matrices de distintos tamaños y revisamos cómo se interpreta cuando consideramos las matrices como transformaciones de flechas en el plano. En la siguiente entrada enunciaremos y aprenderemos a usar algunas de las propiedades que cumplen los determinantes.
Tarea moral
- Calcula los determinantes de las siguientes matrices:
- $\begin{pmatrix} 5 & 8 \\ 3 & 9 \end{pmatrix}, \begin{pmatrix} 10 & 11 \\ -1 & 9 \end{pmatrix}, \begin{pmatrix} 31 & 38 \\ 13 & -29 \end{pmatrix}$
- $\begin{pmatrix} 1 & 5 & 2 \\ 3 & -1 & 8 \\ 0 & 2 & 5 \end{pmatrix}, \begin{pmatrix} 1 & 8 & 4 \\ 0 & 5 & -3 \\ 0 & 0 & -1 \end{pmatrix}, \begin{pmatrix} 1 & 1 & 1 \\ 2 & 2 & 2 \\ 3 & 3 & 3 \end{pmatrix}$
- $\begin{pmatrix} 5 & 7 & -1 & 2 \\ 3 & 0 & 1 & 0 \\ 2 & -2 & 2 & -2 \\ 5 & 1 & 1 & 0 \end{pmatrix}, \begin{pmatrix} 1 & 2 & 3 & 4 \\ 5 & 6 & 7 & 8 \\ 9 & 10 & 11 & 12 \\ 13 & 14 & 15 & 16 \end{pmatrix}$
- Demuestra que para una matriz $A$ y un entero positivo $n$ se cumple que $\det(A^n)=\det(A)^n$.
- Sea $A$ una matriz de $3\times 3$. Muestra que $\det(A)=\det(A^T)$.
- Sea $A$ una matriz invertible de $2\times 2$. Demuestra que $\det(A)=\det(A^{-1})^{-1}$.
- ¿Qué le sucede al determinante de una matriz $A$ cuando intercambias dos filas? Haz algunos experimentos para hacer una conjetura, y demuéstrala.
Entradas relacionadas
- Ir a Álgebra Superior I
- Entrada anterior del curso: Traza de matrices y propiedades
- Entrada siguiente del curso: Cálculo de determinantes