Introducción
En esta entrada empezamos a hacer un repaso de algunos conceptos geométricos elementales que probablemente has encontrado a lo largo de tu formación. Por un lado, esto puede ayudarte a recordar objetos geométricos específicos y resultados con los que ya te has encontrado. Además, es importante revisar nuevamente estos conceptos pues a partir de ahora necesitamos ser muy precisos con el lenguaje. Por ejemplo, será necesario que distingamos apropiadamente los segmentos, rectas y rayos entre ellos. Finalmente, esta entrada te ayudará a acostumbrarte a la notación que usamos en geometría, es decir, qué tipos de etiquetas le ponemos a cada tipo de objeto geométrico.
Antes de comenzar, hay una aclaración importante por hacer. El repaso que haremos de geometría es un repaso intuitivo. Más adelante, cuando asignemos coordenadas al plano y comencemos a hablar de vectores, entonces ahora sí ya estaremos definiendo nuestros conceptos geométricos de manera formal y tendremos que ser más cuidadosos con la argumentación lógica.
Objetos geométricos básicos
Puedes pensar a un punto como lo que obtienes al colocar la punta del lapiz sobre el papel. Es una figura que tiene una única posición. A los puntos usualmente los denotaremos con letras mayúsculas: $A$, $B$, $C$, $P$, $Q$, $R$, etc.

Un segmento es lo que se obtiene al unir dos puntos directamente el uno al otro. Otra manera de pensarlo es que se tiene que ir de un punto al otro de la manera «más rápida» o «más derecha» posible. A los dos puntos les llamamos los extremos del segmento. Si los nombres de los extremos de un segmento son $A$ y $B$, entonces al segmento lo nombramos $\overline{AB}$. En caso de tener que referirnos al segmento sin usar sus extremos, le podemos dar nombre con letra minúscula, por ejemplo $r, s, t$, etc.
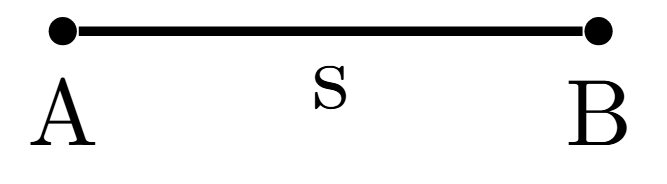
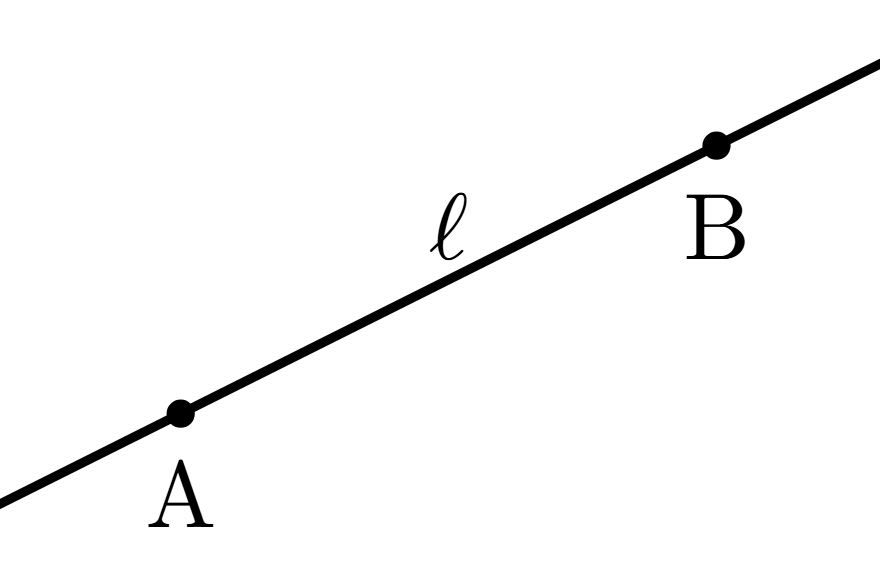
Cuando extendemos un segmento indefinidamente más allá de los dos puntos que lo definen, obtenemos una recta. Una recta queda definida por cualesquiera dos puntos distintos en ella. Si una recta tiene a los puntos distintos $A$ y $B$, entonces llamamos $AB$ a la recta. Aunque sea imposible de apreciarlo en el papel, en pizarrón o en la pantalla de una computadora, las rectas se extienden indefinidamente. Cuando no queremos usar puntos para referirnos a las rectas, las podemos llamar con letras minúsculas como $a,b,c,\ell$, etc.
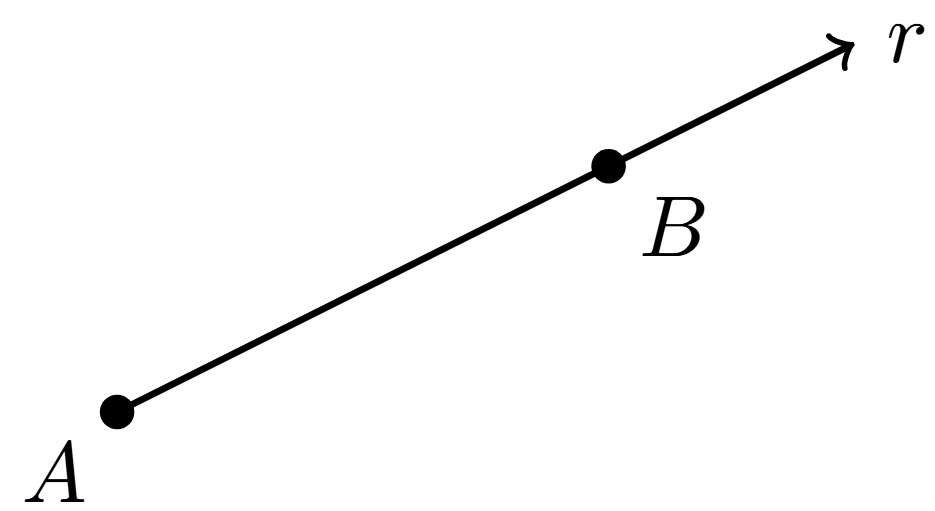
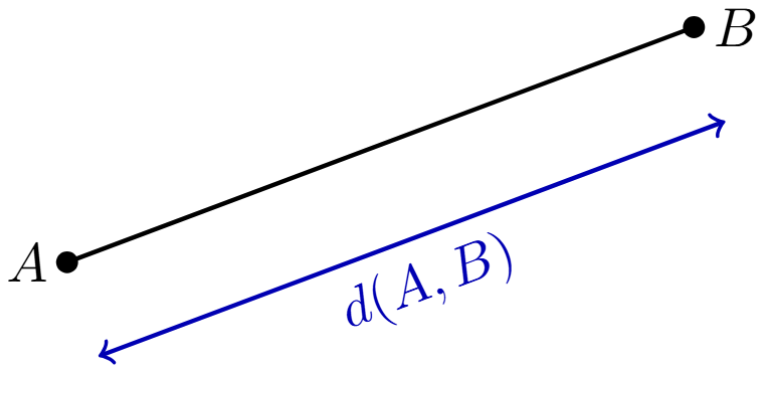
Si sólo extendemos el segmento más allá de sólo uno de los puntos que lo definen, entonces a la figura que obtenemos le llamamos un rayo. Observa que si tenemos dos puntos $A$ y $B$, entonces es distinto el rayo que extiende al segmento más allá de $B$, que el que extiende al segmento más allá de $A$. Al primero le llamamos el rayo desde $A$ por $B$ (como el que se muestra en la figura). Al segundo le llamamos el rayo desde $B$ por $A$. A los rayos, como a los segmentos, los podemos llamar con letras minúsculas como $r,s,t$,etc.
Cuando dos rectas, segmentos o rayos pasan por un mismo punto, decimos que se intersectan en dicho punto. En la siguiente figura, las rectas $\ell$ y $m$ se intersectan en el punto $P$.
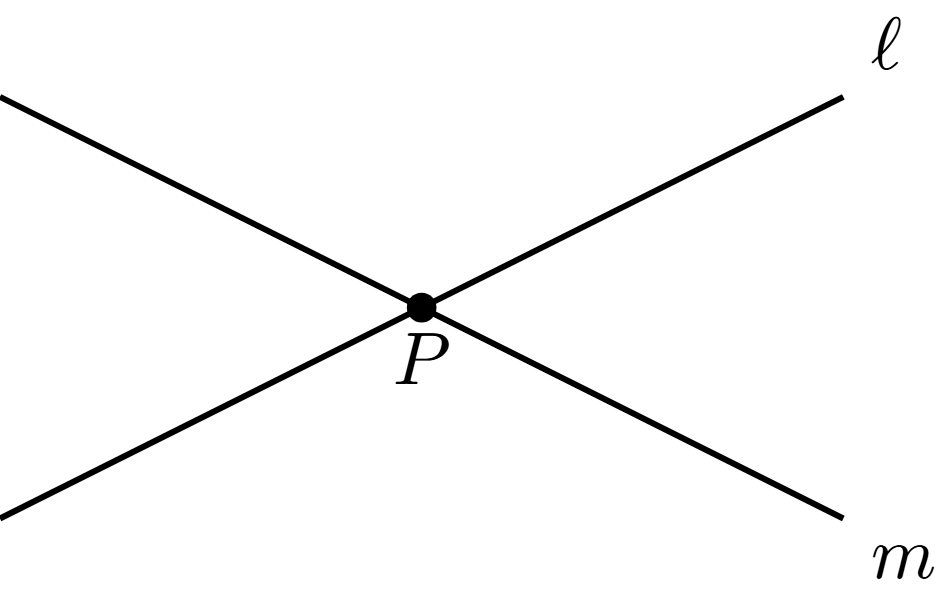
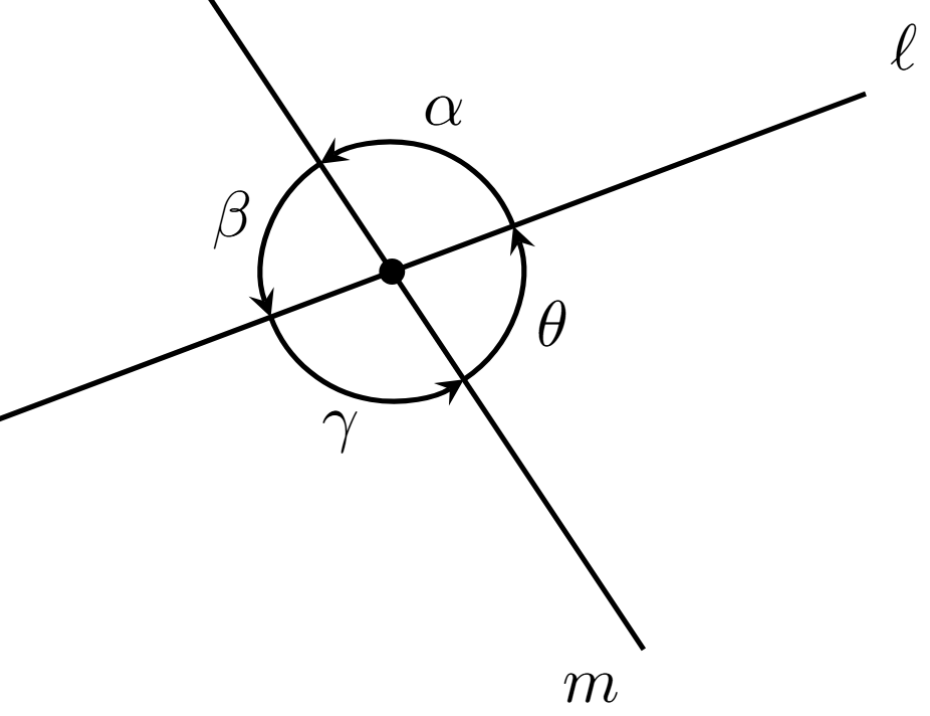
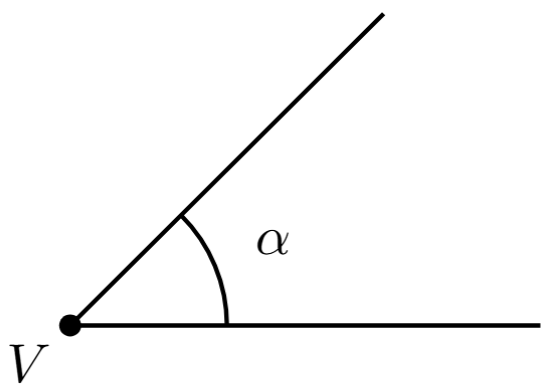
Si $P$ es un punto de intersección de dos rectas distintas $\ell$ y $m$, entonces alrededor de $P$ se forman cuatro regiones. A cada una de las $4$ aperturas entre ambas rectas les llamamos un ángulo entre ellas. De manera similar podemos definir ángulos entre segmentos o rayos que se intersecten, o cualquier mezcla de estos objetos. Los ángulos usualmente los denotamos con letras griegas, como $\alpha, \beta, \gamma, \theta$, etc. (alpha, beta, gamma, theta, etc.).
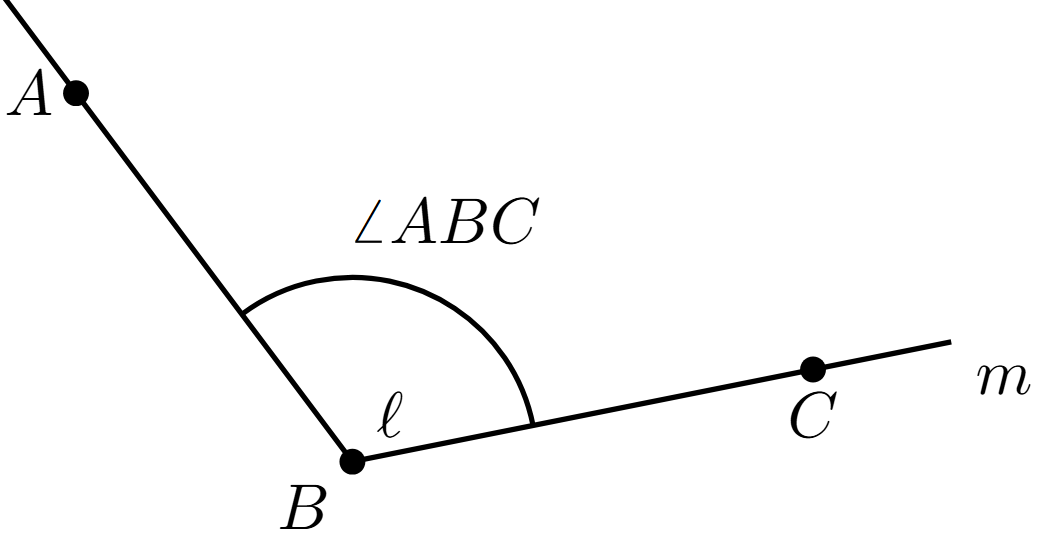
También podemos referirnos a ellos mediante un punto $A$ en $\ell$, el punto $B$ de intersección y un punto $C$ en $m$, en cuyo caso nos referiremos al ángulo como $\angle ABC$.
Triángulos
Es sumamente inusual que al colocar tres puntos $A$, $B$ y $C$ suceda que haya una misma recta que pase por los tres. Cuando esto pasa, decimos que los puntos están alineados o que son colineales.
Si tomamos tres puntos no alineados $A$, $B$ y $C$, entonces podemos dibujar tres segmentos $BC$, $CA$ y $AB$. A la figura conformada por los tres puntos y los tres segmentos le llamamos un triángulo y usualmente lo denotamos por $\triangle ABC$. A $A$, $B$ y $C$ les llamamos los vértices del triángulo. A los segmentos $BC$, $CA$ y $AB$ les llamamos los lados del triángulo. Usualmente nombramos a estos lados $a,b,c$ para que cada lado use la misma letra que el vértice opuesto (pero en minúscula). A los ángulos dentro del triángulo en $A$, $B$ y $C$ les llamamos usualmente $\alpha, \beta, \gamma$.
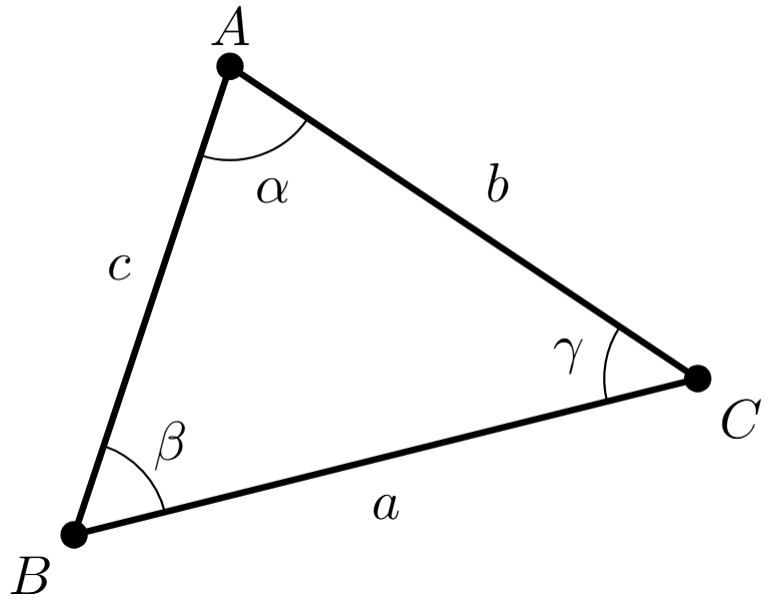
Si quisiéramos insistir en llamar triángulo al caso en el que $A$, $B$ y $C$ están una misma recta, insistiremos en llamarlo un triángulo degenerado. En este caso, el triángulo está «apachurrado» y los segmentos que definen los puntos se enciman entre sí.
Mediciones
Parte de la raiz etimológica de la palabra geometría está relacionada con medir. En geometría, nos interesan ciertas magnitudes geométricas asociadas a objetos geométricos. Por el momento, apelaremos a la intuición que has desarrollado con anterioridad para definir estos conceptos pero, como mencionamos arriba, más adelante los formalizaremos.
La distancia entre dos puntos $A$ y $B$ es una magnitud que mide qué tan alejados están los puntos entre sí. Mientras más alejados, mayor distancia entre ellos. Un punto $A$ está a distancia $0$ de sí mismo. Es lo que solías medir con una regla: si colocas un punto en el $0$ de la regla y el otro cae en el número $d$ de la regla, entonces la distancia entre ambos puntos será $d$. Podemos referirnos a la distancia con la letra $d$ y haciendo referencia a los puntos así: $d(A,B)$.
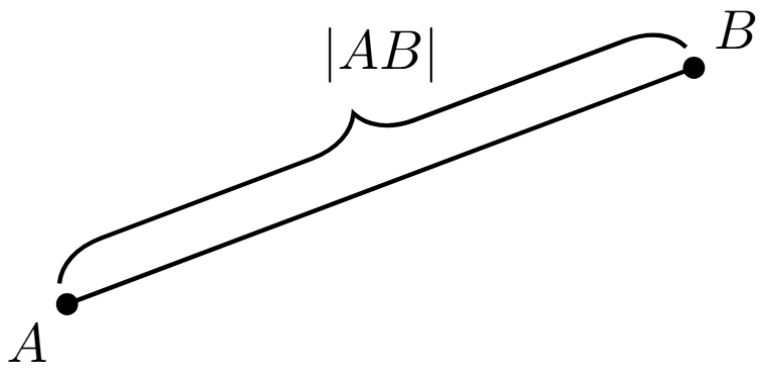
Una magnitud estrechamente relacionada con la distancia es la longitud de un segmento, y se puede pensar exactamente como la distancia entre sus extremos. Mientras más largo sea un segmento (intuitivamente, mientras más tengamos que dibujar para hacerlo), mayor será su longitud. Nos referiremos a la longitud de un segmento $AB$ con la expresión $|AB|$.
Otra medida importante es la de ángulo, que nos indica qué tan abierta la región del msimo nombre definida por dos rectas (o segmentos, o rayos), como la definimos arriba. A mayor apertura en el vértice del ángulo, mayor será la magnitud que le asociamos. Así, típicamente no hacemos distinción entre la región y su apertura, ni en nombre, ni en notación.
Finalmente, también nos interesa una medida de qué tan grande es la región contenida en una figura geométrica en el plano. A esta medida le llamamos el área de la región.
Transformaciones geométricas
Otra noción muy importante en la geometría analítica es la de «transformación». Esto se refiere a alterar nuestros objetos geométricos de alguna manera. Típicamente, esta manera es «amigable» en algún sentido, por ejemplo, respeta distancias o proporciones. Las siguientes son las transformaciones geométricas con las que debes estar más familiarizado de manera intuitiva.
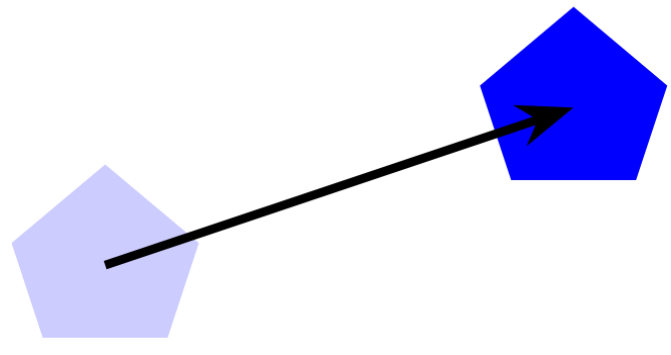
Las traslaciones consisten en mover un objeto de lugar, pero simplemente desplazándolo, sin girarlo.
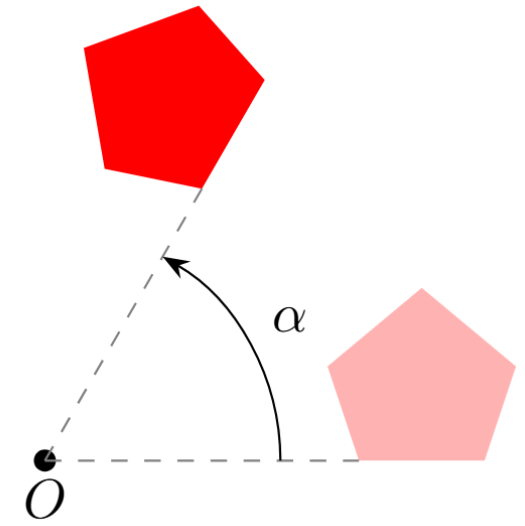
Las rotaciones consisten en girar un objeto geométrico alrededor de un punto que llamamos el centro de rotación. Para saber cuánto rotamos, usamos un ángulo de rotación. En la siguiente figura puedes ver una rotación con centro $O$ y ángulo $\alpha$.
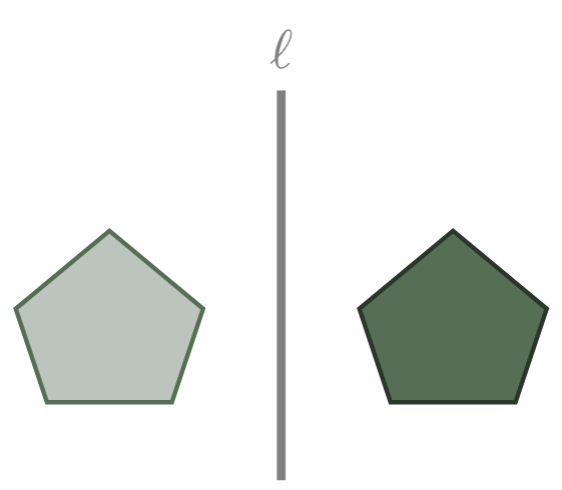
Las reflexiones consisten en tomar una recta $\ell$ y usarla como espejo, para reflejar en él el objeto que nos interesa.
También consideraremos los reescalamientos, que pueden ser expansiones o contracciones. Tras aplicarlas, obtenemos un objeto geométrico más grande o más pequeño, pero que preserva las proporciones. Para definirlas, usualmente necesitamos un centro de reescalamiento $O$ y un factor de reescalamiento $r$. A continuación se muestran algunos ejemplos con con reescalamientos $2$, $1/2$ y $-1$, con la figura de sombreado claro como el objeto original. ¡El reescalamiento de $-1$ voltea la figura alrededor de $O$!
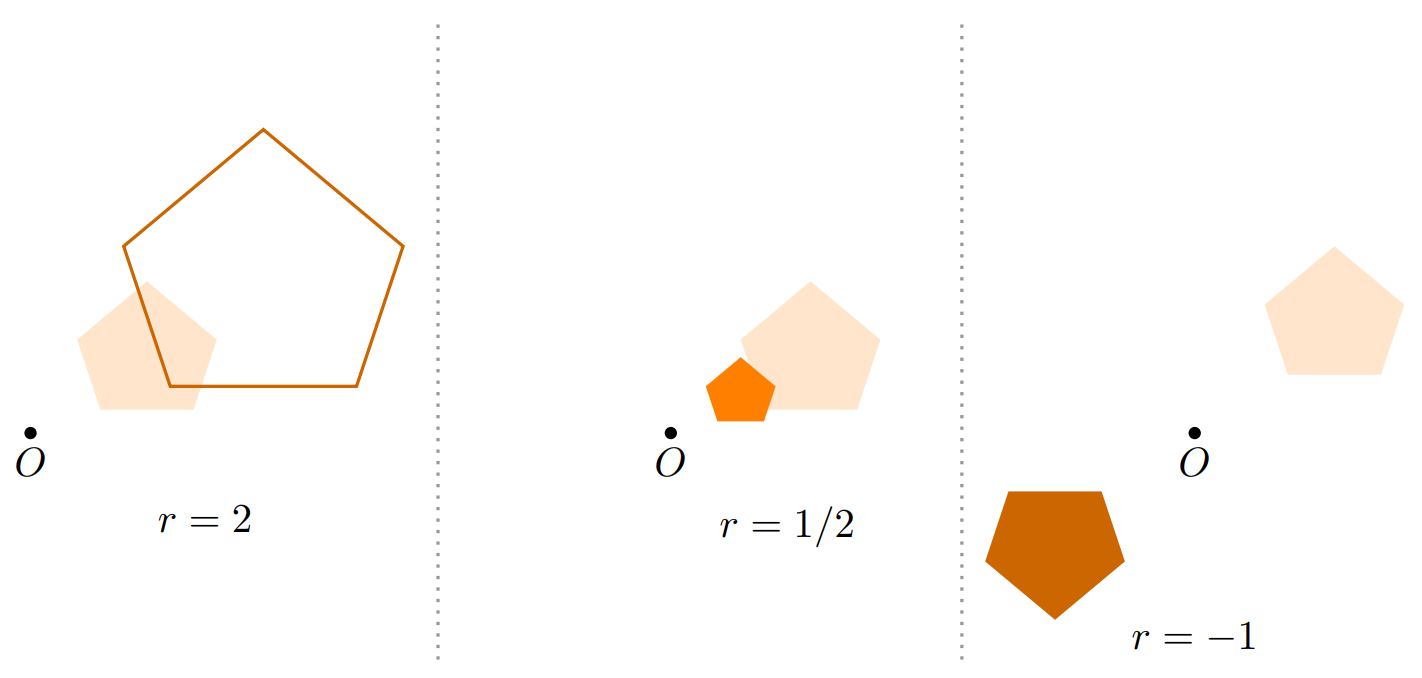
Hay más transformaciones geométricas, como las proyecciones o cizallamientos. Sin embargo, por ahora no hablaremos de ellas.
Aunque ahora hemos platicado lo que le hace una transformación a un objeto geométrico particular, usualmente nos interesará lo que le hace a todo el plano.
Más adelante…
En esta entrada repasamos varias nociones básicas de la geometría de una manera intuitiva. Es importante que tengas esta entrada como referencia, pues los nombres que usamos ahora para objetos geométricos, propiedades geométricas y transformaciones, serán los que usaremos más adelante. En las siguientes entradas continuaremos con un repaso de los resultados geométricos principales. Este repaso seguirá siendo intuitivo. Más adelante introduciremos formalidad en nuestro estudio de la geometría analítica.
Tarea moral
A continuación hay algunos ejercicios para que practiques los conceptos vistos en esta entrada. Te será de mucha utilidad intentarlos para entender más la teoría vista.
- Repasa la diferencia entre rectas, segmentos y rayos.
- Explora la interfaz de GeoGebra para asegurarte de que sepas trazar todo lo que hemos platicado. En caso de que no encuentres la funcionalidad, averigua cómo hacerlo mediante una búsqueda en línea o mediante algún video explicativo.
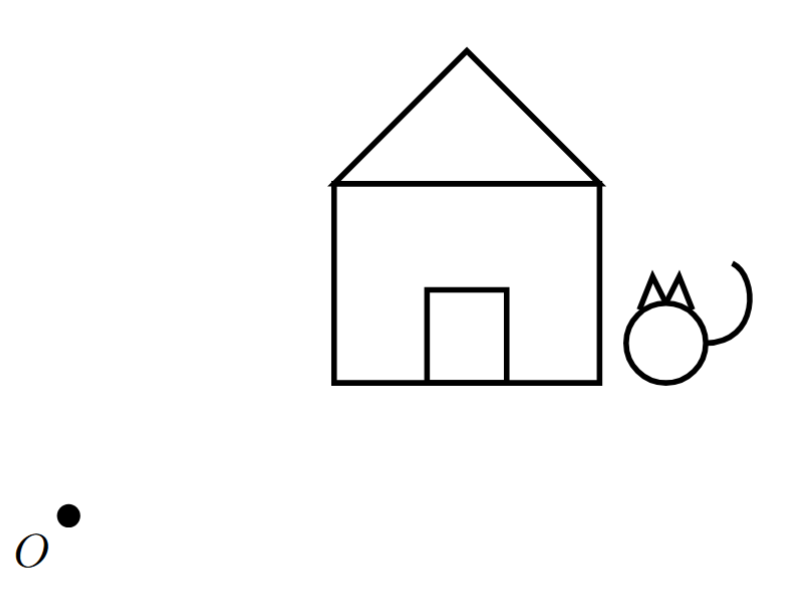
- Copia la siguiente figura en una hoja de papel. Luego, realiza manualmente una rotación de 90 grados alrededor del punto $O$.
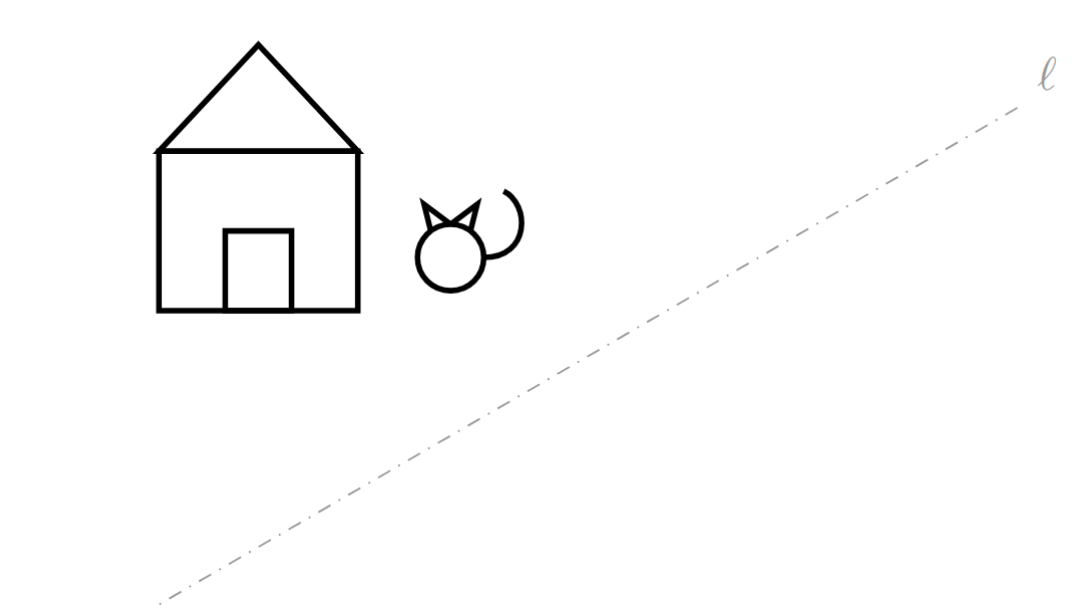
- Copia la siguiente figura en una hoja de papel. Luego, realiza manualmente una reflexión de la figura con respecto a la recta $\ell$.
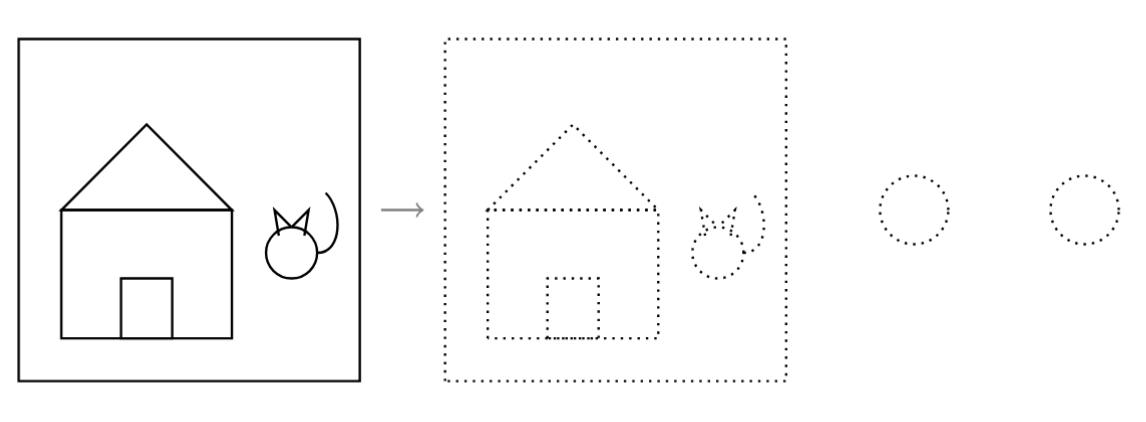
- Ahora vamos a trasladar al gato y a la casa. Pero tienes que hacerlo repetidamente. Haz la figura en tu cuaderno de modo que quede dentro de un cuadrado de 4cm de lado. Luego, repetidamente traslada ese cuadrado 5cm a la derecha para poner todas las copias que puedas de la figura hasta que se te acabe la hoja. Entonces, las transformaciones geométricas las podemos aplicar una y otra vez.
Entradas relacionadas
- Ir a Geometría Analítica I
- Entrada anterior del curso: Introducción al curso
- Siguiente entrada del curso: