Introducción
Una pregunta geométrica muy natural es determinar cómo es la intersección de dos objetos geométricos, es decir, cuales son aquellos puntos que pertenecen a ambos. En el caso de las rectas, eso tiene una respuesta sencilla: la intersección de dos rectas puede ser vacía (cuando son paralelas), o bien un único punto, o bien una recta (cuando son la misma recta).
Como veremos a continuación, esto es sencillo de formalizar utilizando la forma normal de las rectas. Más aún, la forma normal nos ayudará a detectar mediante una cuenta sencilla exactamente en cuál de los casos anteriores nos encontramos. Así mismo, en caso de estar en la caso de que la intersección sea un único punto, también nos dará un procedimiento para encontrar sus coordenadas.
¿Cuándo dos vectores son paralelos?
Antes de estudiar concretamente la intersección de dos rectas, vamos a apoyarnos de la intuición que hemos desarrollado. Si tenemos rectas en forma normal correspondientes a vectores normales $u$ y $v$, entonces sabemos que las rectas son perpendiculares, respectivamente a los vectores $u$ y $v$. Si estos vectores están en la misma dirección, entonces las rectas también. Por ello, las rectas serán paralelas y entonces la intuición nos dice que o bien no se intersectarán, o bien serán la misma recta. Parece ser entonces importante encontar un criterio algebraico para saber cuándo dos vectores son paralelos o no.
Consideremos dos vectores no nulos $u=(u_1,u_2)$ y $v=(v_1,v_2)$. ¿Cuándo estos vectores son paralelos? Como los vectores están anclados en el origen, esto sucede únicamente cuando o bien $u$ es múltiplo escalar de $v$, o bien $v$ es múltiplo escalar de $u$. De esto sale el siguiente criterio algebraico:
Proposición. Tomemos dos vectores no nulos $u=(u_1,u_2)$ y $v=(v_1,v_2)$. Estos vectores son paralelos si y sólo si la expresión $u_1v_2-u_2v_1$ es igual a cero.
Demostración. Demostraremos la proposición en ambas direcciones.
$(\Rightarrow)$ Supongamos que los vectores $u=(u_1,u_2)$ y $v=(v_1,v_2)$ son paralelos. Si $u$ y $v$ son paralelos, entonces uno es un múltiplo escalar del otro. Sin pérdida de generalidad, supongamos que $u = k v$ para algún escalar $k \in \mathbb{R}$. Esto significa que:
$$u_1 = kv_1 \quad \text{y} \quad u_2 = kv_2.$$
Sustituyendo estas expresiones en $u_1v_2-u_2v_1$, obtenemos:
\begin{align*} u_1v_2-u_2v_1 &= (kv_1)v_2 – (kv_2)v_1 \\ &= kv_1v_2 – kv_2v_1 \\ &= 0. \end{align*}
Por lo tanto, si $u$ y $v$ son paralelos, entonces $u_1v_2-u_2v_1 = 0$.
$(\Leftarrow)$ Ahora supongamos que $u_1v_2-u_2v_1 = 0$. Queremos demostrar que $u$ y $v$ son paralelos. La condición $u_1v_2-u_2v_1 = 0$ se puede reescribir como $u_1v_2 = u_2v_1$.
Como $v$ no es el vector nulo, tenemos los siguientes casos:
- Caso 1: $v_1 \neq 0$. De la igualdad $u_1v_2 = u_2v_1$, podemos despejar $u_2$ como $u_2 = \frac{u_1v_2}{v_1}$. Definamos $k = \frac{u_1}{v_1}$. Entonces, $u_1 = kv_1$. Sustituyendo $u_1$ en la expresión para $u_2$: $$u_2 = \frac{(kv_1)v_2}{v_1} = kv_2.$$ Así, tenemos $u_1 = kv_1$ y $u_2 = kv_2$, lo que implica que $$u = (u_1, u_2) = (kv_1, kv_2) = k(v_1, v_2) = kv.$$ Por lo tanto, $u$ es un múltiplo escalar de $v$, y son paralelos.
- Caso 2: $v_1 = 0$. Dado que $v \neq (0,0)$, si $v_1 = 0$, entonces $v_2 \neq 0$. La condición $u_1v_2 = u_2v_1$ se convierte en $u_1v_2 = u_2 \cdot 0$, lo que implica $u_1v_2 = 0$. Como $v_2 \neq 0$, debemos tener $u_1 = 0$. En este subcaso, los vectores son $v=(0,v_2)$ y $u=(0,u_2)$. Estos vectores son paralelos pues ambos están en el eje $y$. Más concretamente, $u=\frac{u_2}{v_2} v$.
En ambos casos, si $u_1v_2-u_2v_1 = 0$, los vectores $u$ y $v$ son paralelos.
$\square$
Así, la expresión $u_1v_2-u_2v_1$ parece ser muy importante para nuestro problema de determinar la intersección de dos rectas. En efecto, en las siguientes secciones volverá a aparecer.
Intersección de rectas en forma normal
La siguiente proposición nos dice exactamente cómo es la intersección de dos rectas una vez que las tenemos en forma normal.
Proposición. Sean $a_1,a_2$ vectores no nulos de $\mathbb{R}^2$ y $b_1,b_2$ número reales. Consideremos las siguientes dos rectas en forma normal:
\begin{align*}
\ell_1 &= \{(x,y) \in \mathbb{R}^2: a_1 \cdot (x,y) = b_1\} \\
\ell_2 &= \{(x,y) \in \mathbb{R}^2: a_2 \cdot (x,y) = b_2\}.
\end{align*}
La intersección de estas rectas tiene las siguientes posibilidades:
- Si $a_1$ y $a_2$ no son vectores paralelos, entonces la intersección de $\ell_1$ y $\ell_2$ es única.
- Si $a_1$ y $a_2$ son vectores paralelos, entonces $a_1=ka_2$ para algún real $k$:
- Si $b_1=kb_2$, entonces ambas ecuaciones representan la misma recta y entonces la intersección es ella misma.
- Si $b_1\neq kb_2$, entonces las rectas son distintas y paralelas y por lo tanto tienen intersección vacía.
Demostración. Vayamos por casos. Nombremos $a_1=(a_{11},a_{12})$ y $a_2=(a_{21},a_{22})$.
Las ecuaciones de las rectas son:
$$
\begin{cases}
a_{11}x + a_{12}y = b_1 \\
a_{21}x + a_{22}y = b_2
\end{cases}
$$
Esto es un sistema de ecuaciones lineales. Analicemos las posibilidades:
- Caso 1: $a_1$ y $a_2$ no son vectores paralelos. Según la proposición anterior, dos vectores $a_1=(a_{11},a_{12})$ y $a_2=(a_{21},a_{22})$ no son paralelos si y sólo si la expresión $a_{11}a_{22}-a_{12}a_{21}$ es distinta de cero. Multiplicando la primera ecuación por $a_{21}$ y la segunda ecuación por $a_{11}$ obtenemos lo siguiente:
\begin{align*} a_{21}(a_{11}x + a_{12}y) &= a_{21}b_1 \\ a_{11}(a_{21}x + a_{22}y) &= a_{11}b_2 \end{align*}
Lo que resulta en el sistema equivalente:
\begin{align*} a_{11}a_{21}x + a_{12}a_{21}y &= a_{21}b_1 \\ a_{11}a_{21}x + a_{11}a_{22}y &= a_{11}b_2 \end{align*}
Restando la primera ecuación de la segunda, eliminamos $x$ y obtenemos:
\begin{align*} (a_{11}a_{21}x + a_{11}a_{22}y) – (a_{11}a_{21}x + a_{12}a_{21}y) &= a_{11}b_2 – a_{21}b_1 \\ (a_{11}a_{22} – a_{12}a_{21})y &= a_{11}b_2 – a_{21}b_1 \end{align*}
Dado que $a_{11}a_{22}-a_{12}a_{21} \neq 0$, podemos despejar $y$ para obtener un valor único. De manera análoga, se puede encontrar un valor único para $x$. Esto demuestra que existe una única solución $(x,y)$ para el sistema, lo que significa que la intersección de $\ell_1$ y $\ell_2$ es única. - Caso 2: $a_1$ y $a_2$ son vectores paralelos, y $b_1=kb_2$ para algún $k \in \mathbb{R}$. Si $a_1$ y $a_2$ son paralelos, entonces $a_1 = ka_2$ para algún escalar $k \in \mathbb{R}$ (ya que $a_1$ y $a_2$ son vectores no nulos). Esto implica que $a_{11} = ka_{21}$ y $a_{12} = ka_{22}$. La ecuación de la recta $\ell_1$ es $a_{11}x + a_{12}y = b_1$. Sustituyendo las expresiones para $a_{11}$ y $a_{12}$ en esta ecuación, obtenemos: \begin{align*} (ka_{21})x + (ka_{22})y &= b_1 \\ k(a_{21}x + a_{22}y) &= b_1 \end{align*} Sabemos que para los puntos en $\ell_2$, se cumple $a_{21}x + a_{22}y = b_2$. Sustituyendo esto en la ecuación anterior, obtenemos $kb_2 = b_1$. Si se cumple la condición $b_1=kb_2$, entonces la ecuación de $\ell_1$ se convierte en $k(a_{21}x + a_{22}y) = kb_2$. Dado que $a_1$ es no nulo, $k$ no puede ser cero. Podemos dividir por $k$ para obtener $a_{21}x + a_{22}y = b_2$. Esta es exactamente la ecuación de la recta $\ell_2$. Por lo tanto, ambas ecuaciones representan la misma recta, y su intersección es la recta completa.
- Caso 3: $a_1$ y $a_2$ son vectores paralelos, y $b_1 \neq kb_2$ para algún $k \in \mathbb{R}$. Similar al Caso 2, si $a_1$ y $a_2$ son paralelos, entonces $a_1 = ka_2$ para algún $k \in \mathbb{R}$. Esto lleva a que la ecuación de $\ell_1$ pueda escribirse como $k(a_{21}x + a_{22}y) = b_1$. Si existiera un punto $(x,y)$ en la intersección de $\ell_1$ y $\ell_2$, debería satisfacer ambas ecuaciones. Es decir, $a_{21}x + a_{22}y = b_2$ (por ser un punto de $\ell_2$) y $k(a_{21}x + a_{22}y) = b_1$ (por ser un punto de $\ell_1$). Sustituyendo la primera en la segunda, obtendríamos $kb_2 = b_1$. Sin embargo, la condición de este caso es que $b_1 \neq kb_2$. Esto significa que no puede haber ningún punto $(x,y)$ que satisfaga ambas ecuaciones simultáneamente. Por lo tanto, las rectas son paralelas y distintas, y su intersección es vacía.
$\square$
Ejemplo de rectas iguales
Veamos ahora ejemplos de cada una de estas posibilidades:
Ejemplo. Encuentra la intersección de las rectas dadas por las siguientes ecuaciones.
\begin{align*}
(1,-2)\cdot (x,y) = 3\\
(-2,4) \cdot (x,y) = -6.
\end{align*}
Solución. Identifiquemos los vectores normales $a_1$ y $a_2$, y los escalares $b_1$ y $b_2$:
$$a_1 = (1,-2), \quad b_1 = 3$$
$$a_2 = (-2,4), \quad b_2 = -6$$
Primero, verificamos si los vectores normales $a_1$ y $a_2$ son paralelos. Calculamos la expresión $a_{11}a_{22}-a_{12}a_{21}$:
\begin{align*} a_{11}a_{22}-a_{12}a_{21} &= (1)(4) – (-2)(-2) \\ &= 4 – 4 \\ &= 0. \end{align*}
Dado que la expresión es cero, los vectores $a_1$ y $a_2$ son paralelos. De hecho, por inspección notamos que $(1,-2) = -\frac{1}{2}(-2,4)$.
Notemos que también sucede que $b_1=3=-\frac{1}{2}6$. Según la proposición, las rectas son entonces la misma. Por lo tanto, la intersección de las dos rectas es la recta misma, $\ell_1$. Podemos escribir la solución como el conjunto de puntos $(x,y)$ que satisfacen $x – 2y = 3$.
$\triangle$
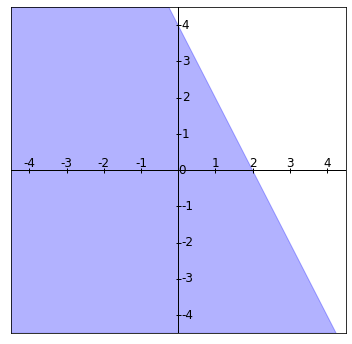
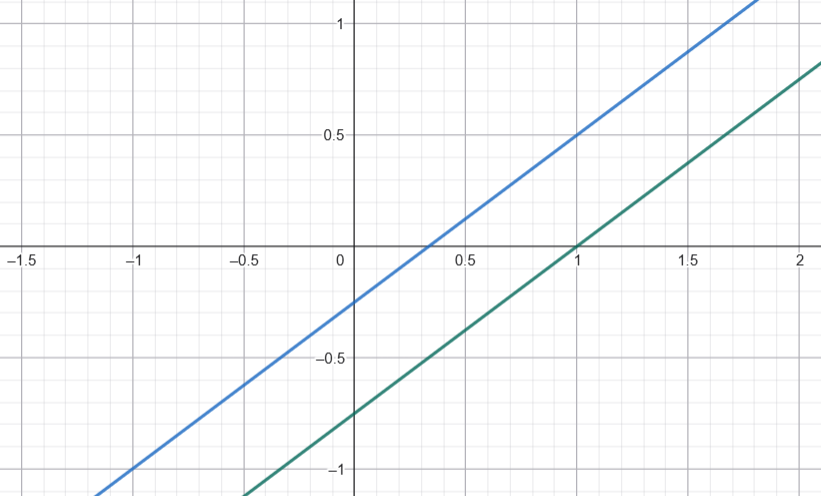
Ejemplo de rectas que no se intersectan
Ejemplo. Encuentra la intersección de las rectas dadas por las siguientes ecuaciones:
\begin{align*}
(3,-4)\cdot (x,y) = 3\\
(-6,8) \cdot (x,y) = -2.
\end{align*}
Solución. Identifiquemos los vectores normales $a_1$ y $a_2$, y los escalares $b_1$ y $b_2$:
$$a_1 = (3,-4), \quad b_1 = 3$$
$$a_2 = (-6,8), \quad b_2 = -2$$
Primero, verificamos si los vectores normales $a_1$ y $a_2$ son paralelos. Calculamos la expresión $a_{11}a_{22}-a_{12}a_{21}$:
\begin{align*} a_{11}a_{22}-a_{12}a_{21} &= (3)(8) – (-4)(-6) \\ &= 24 – 24 \\ &= 0 \end{align*}
Como obtenemos cero, los vectores $a_1$ y $a_2$ son paralelos. Esto significa que $a_1 = ka_2$ para algún escalar $k$. En efecto, $a_1= -\frac{1}{2} a_2$. Sin embargo, ahora $-\frac{1}{2} b_2 = 1 \neq 3 = b_1$. Esto significa que las rectas son paralelas y distintas.
Por lo tanto, la intersección de las dos rectas es vacía.
$\triangle$
La siguiente figura muestra ambas rectas. En efecto, las rectas parecen ser paralelas.
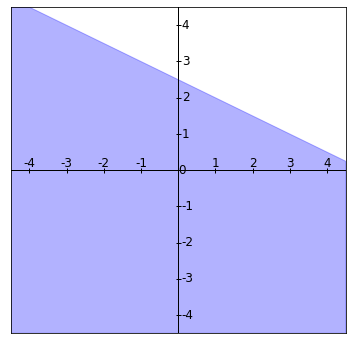
Ejemplo de rectas que se intersectan en un único punto
Ejemplo. Determina dónde se intersectan la recta paralela a $(3,1)$ que pasa por el punto $(1,1)$ y la recta perpendicular a $(2,2)$ que pasa por el punto $(5,-3)$.
Solución. Para poder usar los resultados de esta entrada, primero pasaremos cada una de estas ecuaciones a forma normal $a \cdot (x,y) = b$.
Recta 1: Paralela a $(3,1)$ y pasa por $(1,1)$.
Si la recta es paralela al vector $(3,1)$, su vector normal $a_1$ debe ser perpendicular a $(3,1)$. Un vector perpendicular a $(3,1)$ es, por ejemplo, $a_1 = (-1,3)$.
La ecuación de la recta es de la forma $-x + 3y = b_1$. Para encontrar $b_1$, sustituimos el punto $(1,1)$ por el que pasa la recta:
$$b_1= -(1) + 3(1) = 2.$$
Así, la primera recta en forma normal es $\ell_1 =\{(-1,3) \cdot (x,y) = 2\}$, correspondiente a la ecuación $-x+3y=2$.
Recta 2: Perpendicular a $(2,2)$ y pasa por $(5,-3)$.
Si la recta es perpendicular al vector $(2,2)$, entonces su vector normal $a_2$ es $(2,2)$.
La ecuación de la recta es de la forma $2x + 2y = b_2$. Para encontrar $b_2$, sustituimos el punto $(5,-3)$ por el que pasa la recta:
$$b_2 = 2(5)+2(-3)=4.$$
Así, la segunda recta en forma normal corresponde a la ecuación $2x+y=4$, que es equivalente a $x+y=2$. Así, podemos ponerle en forma normal como $\ell_2=\{(1,1) \cdot (x,y) = 2\}$.
De este modo, encontrar los puntos de intersección de las rectas corresponde a resolver el siguiente sistema de ecuaciones:
$$\begin{cases} -x + 3y = 2\\ x + y = 2. \end{cases}$$
Identificamos los vectores normales $a_1 = (-1,3)$ y $a_2 = (1,1)$. Veamos si $a_1$ y $a_2$ son paralelos. Para ello, calculamos la expresión $a_{11}a_{22}-a_{12}a_{21}$:
\begin{align*} a_{11}a_{22}-a_{12}a_{21} &= (-1)(1) – (3)(1) \\ &= -1 – 3 \\ &= -4. \end{align*}
Dado que el resultado no es cero, los vectores $a_1$ y $a_2$ no son paralelos. Según la proposición, esto significa que la intersección de las dos rectas es un punto único, que podemos encontrar resolviendo el sistema de ecuaciones. Sumando la primera ecuación con la segunda:
\begin{align*} (-x + 3y) + (x + y) &= 2 + 2 \\ 4y &= 4 \\ y &= 1. \end{align*}
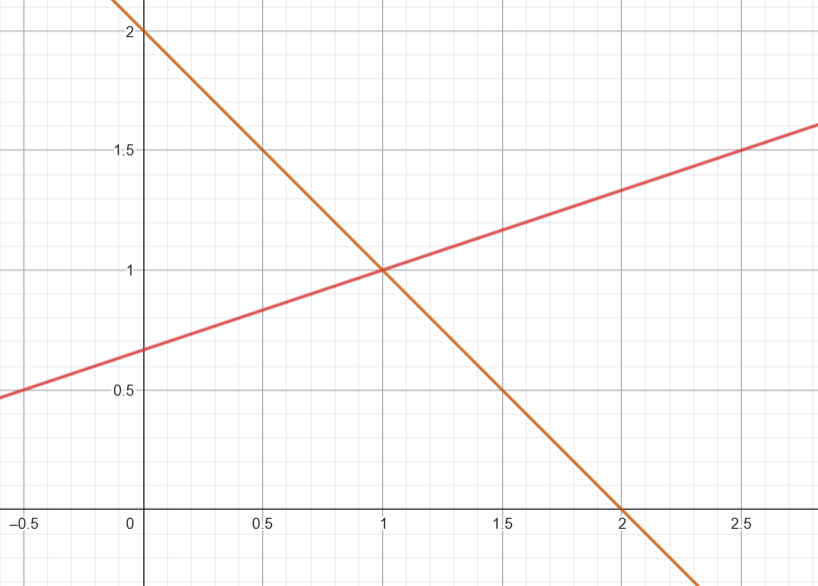
Como $y$ es $1$, entonces de la segunda igualdad concluimos que $x=1$ también. Por lo tanto, las rectas se intersecan en el punto $(1,1)$.
$\triangle$
La siguiente figura muestra ambas rectas. La visualización coincide con lo que demostramos formalmente.
Más adelante…
Hemos entendido cómo se ve la intersección de rectas a partir de su forma normal. Pero la forma normal de una recta no sólo nos ayuda a hablar de la recta misma. Una pequeña variación nos permite hablar también de cada uno de los dos pedazos en los que queda dividido el plano por la recta. A cada uno de estos pedazos le llamamos semiplano. ¿Cómo se verá la intersección de semiplanos? Daremos una introducción a estas ideas en la siguiente entrada.
Tarea moral
- De la siguiente lista de vectores, identifica todos aquellos $u$ y $v$ que cumplan que $u$ es paralelo a $v$:
\begin{align*}&(1,1), (3,3), (5,2), (2,5), (10,4), \\&(-5,-2), (-3,3), (2,-2), (4,0), (5,1).\end{align*} - Encuentra la intersección de las siguientes parejas de rectas:
- $2x+3y=1$ y $3x+2y=2$.
- $15+20y=12$ y $-6x-8y=7$.
- $x+y=1$ y $-x-y=-1$.
- En los resultados de esta entrada hemos pedido que los vectores $u$ y $v$ sean no nulos para que las rectas en forma normal estén bien definidas. Pero si alguno de estos vectores es cero, todavía se pueden plantear un sistema de dos ecuaciones. ¿Qué posibilidades hay para estos sistemas de ecuaciones?
- Si tenemos vectores $u$, $v$ y $w$ en el plano, muestra que están en una misma línea si y sólo si $u-v$ y $w-v$ son paralelos.
- Toma tres vectores $u$, $v$ y $w$ de modo que no estén en una misma línea. La altura desde $u$ es la recta por $u$, perpendicular a $v-w$. De manera análoga se definen las alturas por $v$ y $w$.
- Encuentra la intersección de la altura por $u$ y la altura por $v$.
- Encuentra la intersección de la altura por $u$ y la altura por $w$.
- Demuestra analíticamente, con las técnicas que hemos platicado aquí, que las tres alturas pasan por un mismo punto.
Entradas relacionadas
- Ir a Geometría Analítica I
- Entrada anterior del curso:
- Siguiente entrada del curso: