Las matemáticas es una ciencia que dibuja conclusiones necesarias.
– Benjamin Peirce
Introducción
En la entrada anterior estudiamos los sistemas lineales en los que los valores propios de la matriz $\mathbf{A}$ eran reales y distintos, en esta entrada estudiaremos sistemas lineales en los que los valores propios son complejos.
Antes de comenzar con el desarrollo cualitativo es conveniente recordar algunos resultados importantes de estos sistemas.
Sistemas lineales con valores propios complejos
El sistema que estamos analizando es
\begin{align*}
x^{\prime} &= ax + by \\
y^{\prime} &= cx + dy \label{1} \tag{1}
\end{align*}
Definimos,
$$\mathbf{Y}^{\prime} = \begin{pmatrix}
x^{\prime} \\ y^{\prime}
\end{pmatrix}, \hspace{1cm} \mathbf{Y} = \begin{pmatrix}
x \\ y
\end{pmatrix} \hspace{1cm} y \hspace{1cm} \mathbf{A} = \begin{pmatrix}
a & b \\ c & d
\end{pmatrix}$$
De manera que el sistema (\ref{1}) se pueda escribir como
$$\mathbf{Y}^{\prime} = \mathbf{AY} \label{2} \tag{2}$$
Sea
$$\lambda = \alpha + i \beta \label{3} \tag{3}$$
un valor propio de la matriz $\mathbf{A}$, con $\alpha$ y $\beta$ reales. Y sea
$$\mathbf{K} = \mathbf{U} + i \mathbf{V} \label{4} \tag{4}$$
un vector propio de $\mathbf{A}$ asociado a $\lambda$. Entonces la solución del sistema (\ref{1}) se puede escribir como
$$\mathbf{Y}(t) = (\mathbf{U} + i \mathbf{V}) e^{(\alpha + i \beta)t} \label{5} \tag{5}$$
En la unidad anterior vimos que si definimos los vectores
$$\mathbf{W}_{1} = Re \{ \mathbf{Y} \} \hspace{1cm} y \hspace{1cm} \mathbf{W}_{2} = Im \{ \mathbf{Y} \}$$
donde $\mathbf{W}_{1}$ y $\mathbf{W}_{2}$ están dados como
$$\mathbf{W}_{1}(t) = e^{\alpha t} [\mathbf{U} \cos(\beta t) -\mathbf{V} \sin(\beta t)] \label{6} \tag{6}$$
y
$$\mathbf{W}_{2}(t) = e^{\alpha t} [\mathbf{U} \sin(\beta t) + \mathbf{V} \cos(\beta t)] \label{7} \tag{7}$$
entonces la solución general real del sistema (\ref{1}) es
$$\mathbf{Y}(t) = c_{1} \mathbf{W}_{1}(t) + c_{2} \mathbf{W}_{2}(t) \label{8} \tag{8}$$
Por lo tanto, las soluciones linealmente independientes son
$$\mathbf{Y}_{1}(t) = c_{1} e^{\alpha t} \left[ \mathbf{U} \cos(\beta t) -\mathbf{V} \sin(\beta t) \right] \label{9} \tag{9}$$
y
$$\mathbf{Y}_{2}(t) = c_{2} e^{\alpha t} \left[ \mathbf{U} \sin(\beta t) + \mathbf{V} \cos(\beta t) \right] \label{10} \tag{10}$$
La expresión $k_{1} \cos(\beta t) + k_{2} \sin(\beta t)$, donde $k_{1}$ y $k_{2}$ son constantes, se puede expresar en la forma $R \cos(\beta t -\delta)$ para una elección adecuada de constantes $R$ y $\delta$. De tarea moral demuestra que la solución (\ref{8}) se puede expresar de la siguiente forma.
$$\mathbf{Y}(t) = e^{\alpha t} \begin{pmatrix}
R_{1} \cos(\beta t -\delta_{1}) \\ R_{2} \cos(\beta t -\delta_{2})
\end{pmatrix} \label{11} \tag{11}$$
para alguna elección de constantes $R_{1} \geq 0$, $R_{2} \geq 0$, $\delta_{1}$ y $\delta_{2}$.
Con esto en mente pasemos a estudiar cada caso en el que los valores propios son complejos.
Valores propios complejos con parte real nula
Caso 1: $\lambda_{1} = \alpha + i \beta$ y $\lambda_{2} = \alpha -i \beta$, con $\alpha = 0$.
En este caso se dice que los valores propios son imaginarios puros ya que no tienen parte real. De la solución (\ref{11}) vemos que si $\alpha = 0$, entonces la expresión se reduce a
$$\mathbf{Y}(t) = \begin{pmatrix}
R_{1} \cos(\beta t -\delta_{1}) \\ R_{2} \cos(\beta t -\delta_{2})
\end{pmatrix} \label{12} \tag{12}$$
Las soluciones $x(t)$ y $y(t)$ son
$$x(t) = R_{1} \cos(\beta t -\delta_{1}) \hspace{1cm} y \hspace{1cm} y(t) = R_{2} \cos(\beta t -\delta_{2}) \label{13} \tag{13}$$
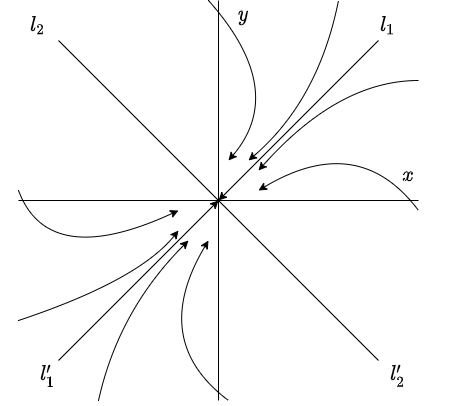
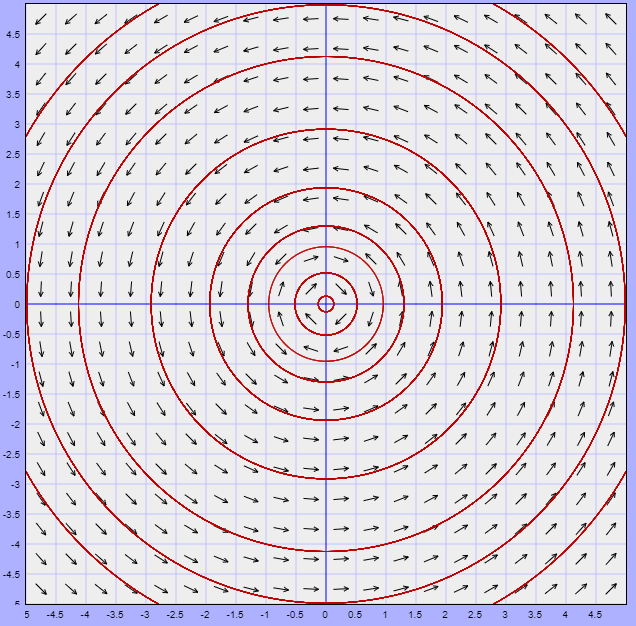
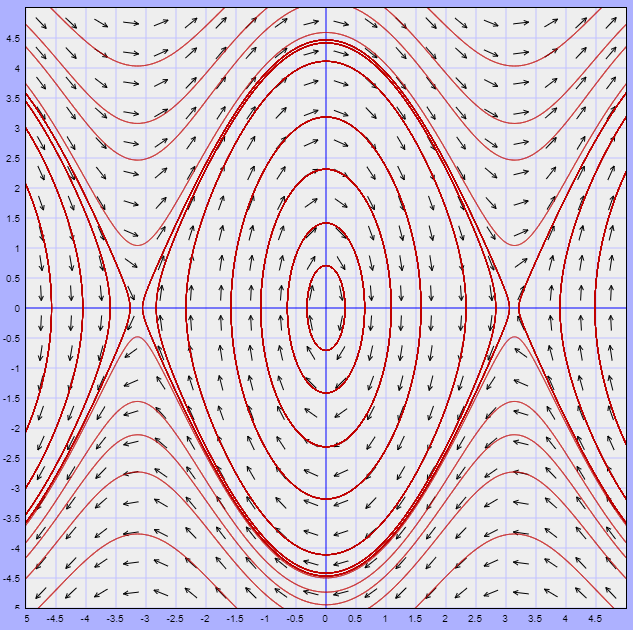
Estas funciones son periódicas en el tiempo, con periodo $2 \pi / \beta$. Como $|\cos(\beta t -\delta_{1})| \leq 1$ y $|\cos(\beta t -\delta_{2})| \leq 1$, entonces la función $x(t)$ varia entre $-R_{1}$ y $+R_{1}$, mientras que $y(t)$ varia entre $-R_{2}$ y $+R_{2}$. Por tanto, la trayectoria de cualquier solución $\mathbf{Y}(t)$ de (\ref{1}) es una curva cerrada que rodea al origen $x = y = 0$, es por ello que se dice que el punto de equilibrio $Y_{0} = (0, 0)$ es un centro y es estable.
A continuación se muestra el plano fase.
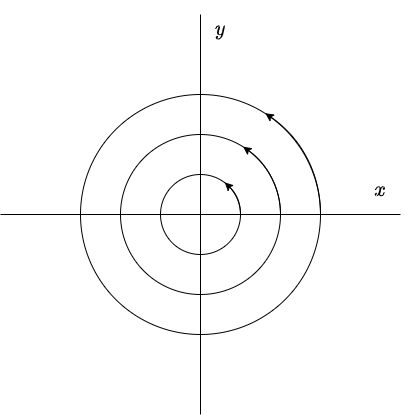
La dirección de las trayectorias se determina a partir del sistema (\ref{1}). Buscamos el signo de $y^{\prime}$ cuando $y = 0$. Si $y^{\prime}$ es mayor que cero para $y = 0$ y $x > 0$, entonces todas las trayectorias se mueven en sentido contrario a las manecillas del reloj. Si $y^{\prime}$ es menor que cero para $y = 0$ y $x > 0$, entonces todas las trayectorias se mueven en el sentido de las manecillas del reloj.
Ahora estudiemos los casos en los que los valores propios tienen parte real no nula.
Valores propios complejos con parte real negativa
Caso 2: $\lambda_{1} = \alpha + i \beta$ y $\lambda_{2} = \alpha -i \beta$, con $\alpha < 0$.
En este caso las soluciones son
$$\mathbf{Y}(t) = e^{\alpha t} \begin{pmatrix}
R_{1} \cos(\beta t -\delta_{1}) \\ R_{2} \cos(\beta t -\delta_{2})
\end{pmatrix}$$
o bien,
$$x(t) = e^{\alpha t} R_{1} \cos(\beta t -\delta_{1}) \hspace{1cm} y \hspace{1cm} y(t) = e^{\alpha t} R_{2} \cos(\beta t -\delta_{2}) \label{14} \tag{14}$$
Si $t = 0$, se obtiene que
$$\mathbf{Y}(0) = \begin{pmatrix}
R_{1} \cos(-\delta_{1}) \\ R_{2} \cos(-\delta_{2})
\end{pmatrix} \label{15} \tag{15}$$
Sabemos que el periodo es $2 \pi / \beta$, notemos que si $t = 2 \pi / \beta$, entonces
$$\mathbf{Y}(2 \pi / \beta) = e^{2 \pi \alpha / \beta} \begin{pmatrix}
R_{1} \cos(2 \pi -\delta_{1}) \\ R_{2} \cos(2 \pi -\delta_{2})
\end{pmatrix} = e^{2 \pi \alpha / \beta} \begin{pmatrix}
R_{1} \cos(-\delta_{1}) \\ R_{2} \cos(-\delta_{2})
\end{pmatrix}$$
esto es,
$$\mathbf{Y}(2 \pi / \beta) = e^{2 \pi \alpha / \beta } \mathbf{Y}(0) \label{16} \tag{16}$$
Como
$$\mathbf{Y}(2 \pi / \beta) < \mathbf{Y}(0)$$
es decir,
$$x(2 \pi / \beta) < x(0) \hspace{1cm} y \hspace{1cm} y( 2 \pi / \beta) < y(0)$$
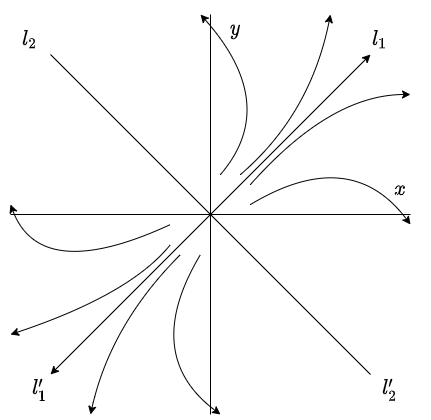
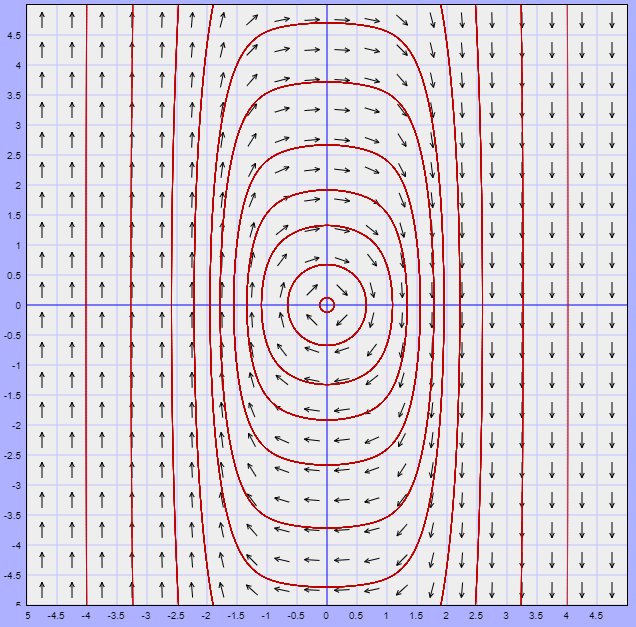
entonces $\mathbf{Y}(2 \pi / \beta)$ está más cerca del origen que $\mathbf{Y}(0)$. Esto significa que, para $\alpha < 0$, el efecto del factor $e^{\alpha t}$ sobre la solución (\ref{11}) es el de cambiar las curvas cerradas del caso anterior en espirales que se aproximan hacia el origen.
El plano fase se muestra a continuación.
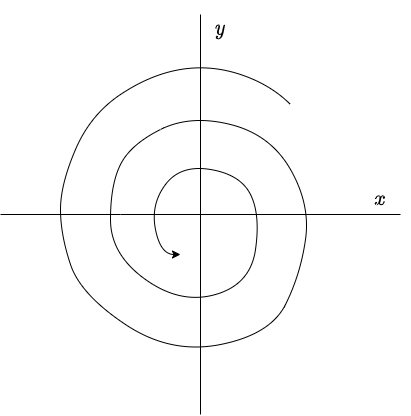
De forma similar al caso anterior, la dirección de las trayectorias se determina a partir del sistema (\ref{1}). En este caso se dice que el punto de equilibrio $Y_{0} = (0, 0)$ de (\ref{1}) es un foco estable, o también se conoce como espiral atractor. La estabilidad de este punto de equilibrio es asintóticamente estable.
Para concluir veamos que ocurre si $\alpha$ es positiva.
Valores propios complejos con parte real positiva
Caso 3: $\lambda_{1} = \alpha + i \beta$ y $\lambda_{2} = \alpha -i \beta$, con $\alpha > 0$.
En este caso nuevamente las soluciones son
$$\mathbf{Y}(t) = e^{\alpha t} \begin{pmatrix}
R_{1} \cos(\beta t -\delta_{1}) \\ R_{2} \cos(\beta t -\delta_{2})
\end{pmatrix}$$
o bien,
$$x(t) = e^{\alpha t} R_{1} \cos(\beta t -\delta_{1}) \hspace{1cm} y \hspace{1cm} y(t) = e^{\alpha t} R_{2} \cos(\beta t -\delta_{2})$$
Sin embargo, debido a que $\alpha > 0$, se puede probar que
$$\mathbf{Y}(2 \pi / \beta) > \mathbf{Y}(0)$$
es decir,
$$x(2 \pi / \beta) > x(0) \hspace{1cm} y \hspace{1cm} y( 2 \pi / \beta) > y(0)$$
lo que significa que ahora $\mathbf{Y}(0)$ está más cerca del origen que $\mathbf{Y}(2 \pi / \beta)$.
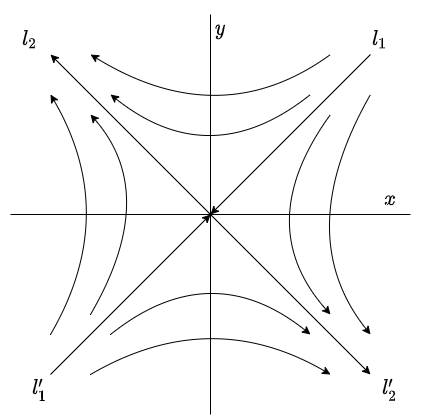
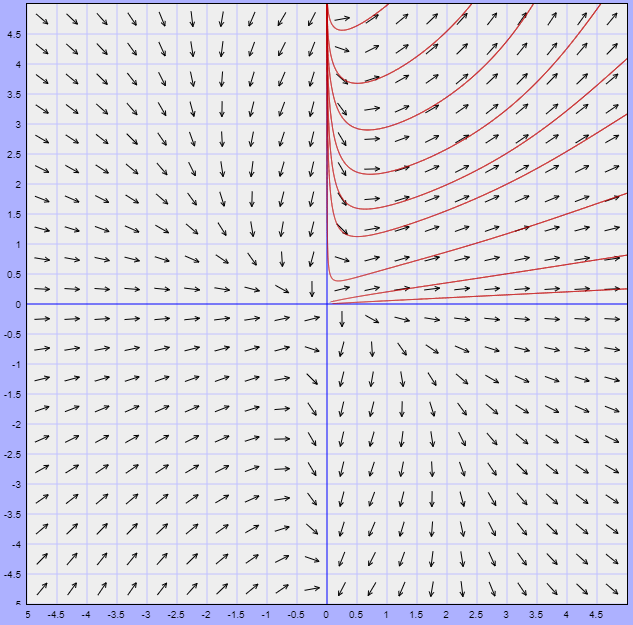
Por lo tanto, en este caso todas las soluciones de (\ref{1}) describen espirales que se alejan del origen conforme $t \rightarrow \infty$, y se dice que el punto de equilibrio $Y_{0} = (0, 0)$ de (\ref{1}) es un foco inestable o espiral repulsor. Es claro que el punto de equilibrio es inestable.
El plano fase se muestra a continuación.
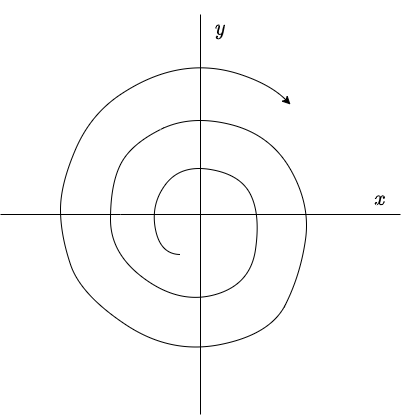
Hemos revisado los casos posibles. Para concluir con la entrada realicemos un ejemplo por cada caso.
Caso 1: $\lambda_{1} = \alpha + i \beta$ y $\lambda_{2} = \alpha -i \beta$, con $\alpha = 0$.
Ejemplo: Resolver el siguiente sistema lineal y hacer un análisis cualitativo de las soluciones.
$$\mathbf{Y}^{\prime} = \begin{pmatrix}
2 & 1 \\ -5 & -2
\end{pmatrix} \mathbf{Y}$$
Solución: Determinemos los valores propios.
$$\begin{vmatrix}
2 -\lambda & 1 \\ -5 & -2 -\lambda
\end{vmatrix} = (2 -\lambda)(-2 -\lambda) + 5 = \lambda^{2} + 1 = 0$$
Las raíces son $\lambda_{1} = i$ y $\lambda_{2} = -i$, notamos que $\alpha = 0$ y $\beta = 1$, determinemos los vectores propios resolviendo la ecuación
$$(\mathbf{A} -i \mathbf{I}) \mathbf{K} = \mathbf{0}$$
o bien,
$$\begin{pmatrix}
2 -i & 1 \\ -5 & -2-i
\end{pmatrix} \begin{pmatrix}
k_{1} \\ k_{2}
\end{pmatrix} = \begin{pmatrix}
0 \\ 0
\end{pmatrix}$$
Las ecuaciones que se obtienen son
\begin{align*}
(2 -i)k_{1} + k_{2} &= 0 \\
-5k_{1} -(2 + i)k_{2} &= 0
\end{align*}
Vemos que
$$k_{1} = -\left( \dfrac{2 + i}{5} \right)k_{2}$$
Sea $k_{2} = -5$, tal que $k_{1} = 2 + i$, así el primer vector propio es
$$\mathbf{K}_{1} = \begin{pmatrix}
2 + i \\ -5
\end{pmatrix} = \begin{pmatrix}
2 \\ -5
\end{pmatrix} + i \begin{pmatrix}
1 \\ 0
\end{pmatrix}$$
Sabemos que $\mathbf{K}_{2} = \bar{\mathbf{K}}_{1}$, entonces el segundo vector propio asociado al valor propio $\lambda_{2} = -i$ es
$$\mathbf{K}_{2} = \begin{pmatrix}
2 -i \\ -5
\end{pmatrix} = \begin{pmatrix}
2 \\ -5
\end{pmatrix} -i \begin{pmatrix}
1 \\ 0
\end{pmatrix}$$
La primera solución linealmente independiente es
$$\mathbf{Y}_{1}(t) = e^{it} \begin{pmatrix}
2 + i \\ -5
\end{pmatrix}$$
Notemos lo siguiente.
\begin{align*}
e^{it} \begin{pmatrix}
2 + i \\ -5
\end{pmatrix} &= \left[ \cos(t) + i \sin(t) \right] \left[ \begin{pmatrix}
2 \\ -5
\end{pmatrix} + i \begin{pmatrix}
1 \\ 0
\end{pmatrix} \right] \\
&= \cos(t) \begin{pmatrix}
2 \\ -5
\end{pmatrix} -\sin(t) \begin{pmatrix}
1 \\ 0
\end{pmatrix} + i \cos(t) \begin{pmatrix}
1 \\ 0
\end{pmatrix} + i \sin(t) \begin{pmatrix}
2 \\ -5
\end{pmatrix}
\end{align*}
De donde definimos
$$\mathbf{W}_{1} = \cos(t) \begin{pmatrix}
2 \\ -5
\end{pmatrix} -\sin(t) \begin{pmatrix}
1 \\ 0
\end{pmatrix}$$
y
$$\mathbf{W}_{2} = \sin(t) \begin{pmatrix}
2 \\ -5
\end{pmatrix} + \cos(t) \begin{pmatrix}
1 \\ 0
\end{pmatrix}$$
Por lo tanto, la solución general real es
$$\mathbf{Y}(t) = c_{1} \left[ \cos(t) \begin{pmatrix}
2 \\ -5
\end{pmatrix} -\sin(t) \begin{pmatrix}
1 \\ 0
\end{pmatrix} \right] + c_{2} \left[ \sin(t) \begin{pmatrix}
2 \\ -5
\end{pmatrix} + \cos(t) \begin{pmatrix}
1 \\ 0
\end{pmatrix} \right]$$
En términos de las funciones $x(t)$ y $y(t)$ se tienen las soluciones
\begin{align*}
x(t) &= [2c_{1} + c_{2}] \cos(t) + [-c_{1} + 2c_{2}] \sin(t) \\
y(t) &= -5c_{1} \cos(t) -5c_{2} \sin(t)
\end{align*}
Las soluciones son de la forma
\begin{align*}
x(t) &= k_{1} \cos(t) + k_{2} \sin(t) \\
y(t) &= k_{3} \cos(t) + k_{4} \sin(t)
\end{align*}
También es posible determinar las constantes $R_{1}$, $R_{2}$, $\delta_{1}$ y $\delta_{2}$ en términos de las constantes $c_{1}$ y $c_{2}$, tal que la solución se pueda escribir como
\begin{align*}
x(t) &= R_{1} \cos(t -\delta_{1})\\
y(t) &= R_{2} \cos(t -\delta_{2})
\end{align*}
En este caso como $\beta = 1$, entonces el periodo es $T = 2\pi$. La función paramétrica que define las trayectorias está dada por
$$f(t) = (k_{1} \cos(t) + k_{2} \sin(t), k_{3} \cos(t) + k_{4} \sin(t))$$
Es claro que las trayectorias son curvas cerradas con periodo $2 \pi$.
Para determinar la dirección de las trayectorias consideremos la ecuación $y^{\prime}$ del sistema, dicha ecuación es
$$y^{\prime} = -5x -2y$$
Si $y = 0$ se tiene la ecuación $y^{\prime} = -5x$, vemos que si $x > 0$, entonces $y^{\prime} < 0$, por lo tanto las trayectorias se mueven en el sentido de las manecillas del reloj.
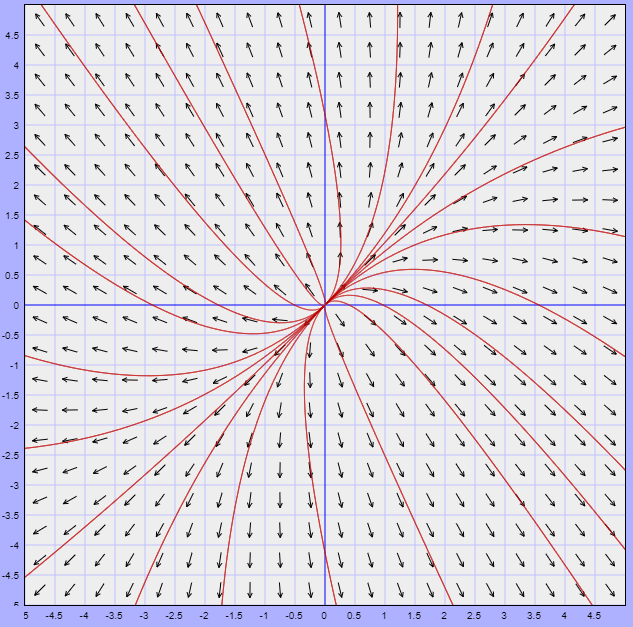
El plano fase indicando algunas trayectorias se muestra a continuación.
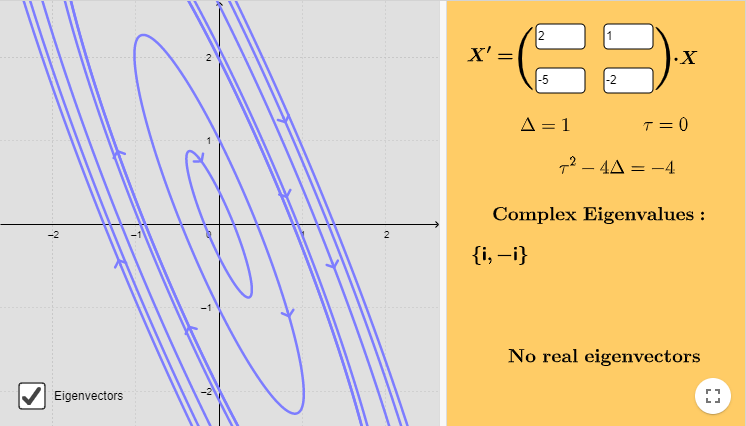
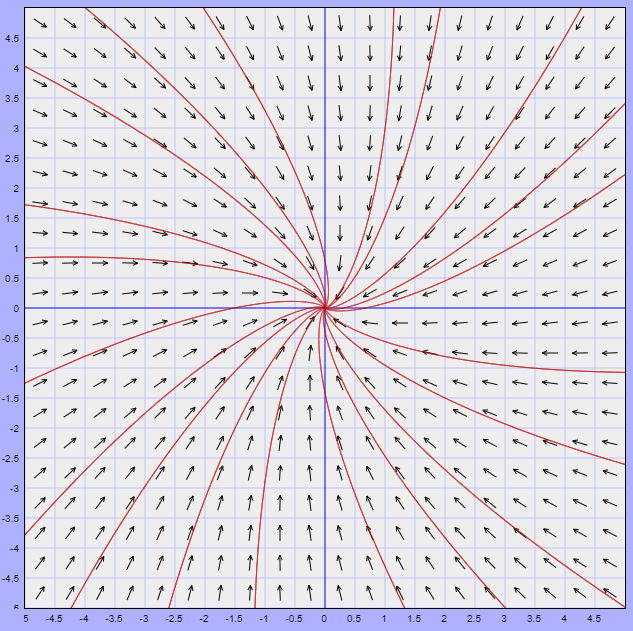
El campo vectorial está definido por la función
$$F(x, y) = (2x + y, -5x -2y)$$
A continuación se muestra dicho campo vectorial y algunas trayectorias.
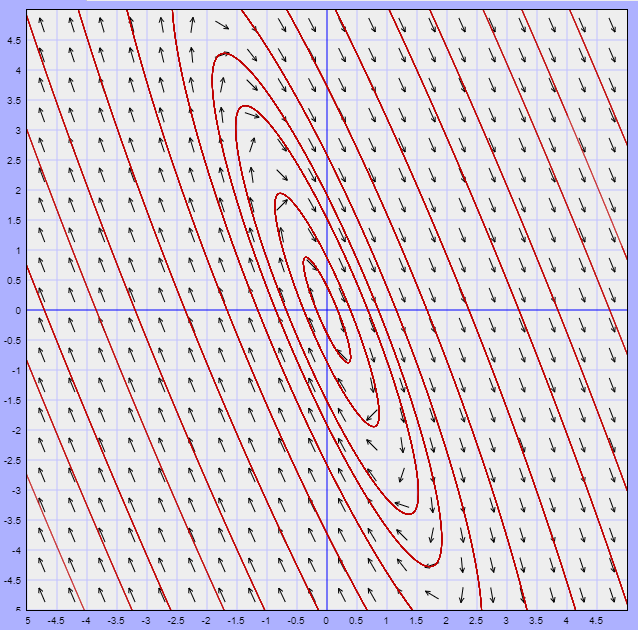
Efectivamente, el punto de equilibrio $Y_{0} = (0, 0)$ es un centro.
$\square$
Veamos como se pierde esta regularidad si $\alpha \neq 0$.
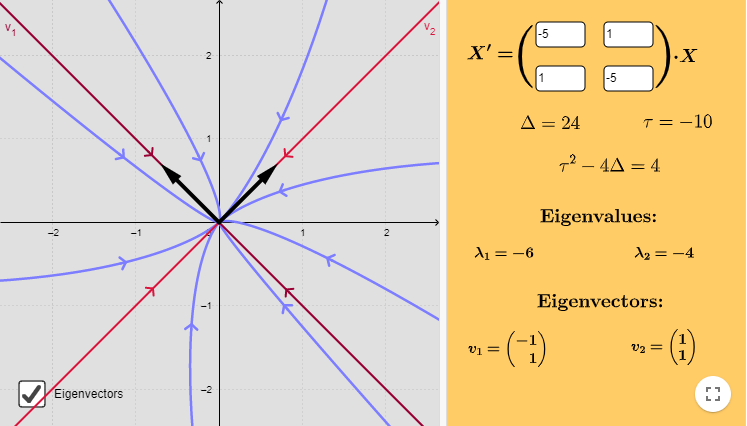
Caso 2: $\lambda_{1} = \alpha + i \beta$ y $\lambda_{2} = \alpha -i \beta$, con $\alpha < 0$.
Ejemplo: Resolver el siguiente sistema lineal y hacer un análisis cualitativo de las soluciones.
$$\mathbf{Y}^{\prime} = \begin{pmatrix}
-1 & -4 \\ 1 & -1
\end{pmatrix} \mathbf{Y}$$
Solución: Determinemos los valores propios.
$$\begin{vmatrix}
-1 -\lambda & -4 \\ 1 & -1 -\lambda
\end{vmatrix} = (-1 -\lambda)^{2} + 4 = \lambda^{2} + 2 \lambda + 5 = 0$$
Las raíces son $\lambda_{1} = -1 + 2i$ y $\lambda_{2} = -1 -2i$ (con $\alpha = -1$ y $\beta = 2$). Resolvamos la siguiente ecuación para obtener los vectores propios.
$$(\mathbf{A} -( -1 + 2i) \mathbf{I}) \mathbf{K} = \mathbf{0}$$
o bien,
$$\begin{pmatrix}
-2i & -4 \\ 1 & -2i
\end{pmatrix} \begin{pmatrix}
k_{1} \\ k_{2}
\end{pmatrix} = \begin{pmatrix}
0 \\ 0
\end{pmatrix}$$
Se obtiene que $k_{1} = 2ik_{2}$. Sea $k_{2} = 1$, entonces $k_{1} = 2i$, así el primer vector propios es
$$\mathbf{K}_{1} = \begin{pmatrix}
2i \\ 1
\end{pmatrix} = \begin{pmatrix}
0 \\ 1
\end{pmatrix} + i \begin{pmatrix}
2 \\ 0
\end{pmatrix} $$
Considerando que $\mathbf{K}_{2} = \bar{\mathbf{K}}_{1}$ , entonces el segundo vector propio, asociado a $\lambda_{2} = -1 -2i$ es
$$\mathbf{K}_{2} = \begin{pmatrix}
-2i \\ 1
\end{pmatrix} = \begin{pmatrix}
0 \\ 1
\end{pmatrix} -i \begin{pmatrix}
2 \\ 0
\end{pmatrix}$$
Sabemos que la primer solución es
$$\mathbf{Y}_{1}(t) = e^{(-1 + 2i)t} \begin{pmatrix}
2i \\ 1
\end{pmatrix}$$
Notemos lo siguiente.
\begin{align*}
e^{(-1 + 2i)t} \begin{pmatrix}
2i \\ 1
\end{pmatrix} &= e^{-t} [\cos(2t) + i \sin(2t)] \left[ \begin{pmatrix}
0 \\ 1
\end{pmatrix} + i \begin{pmatrix}
2 \\ 0
\end{pmatrix} \right] \\
&= e^{-t} \left[ \cos(2t) \begin{pmatrix}
0 \\ 1
\end{pmatrix} -\sin(2t) \begin{pmatrix}
2 \\ 0
\end{pmatrix} + i \cos (2t) \begin{pmatrix}
2 \\ 0 \end{pmatrix} + i \sin(2t) \begin{pmatrix}
0 \\ 1 \end{pmatrix} \right]
\end{align*}
De donde definimos
$$\mathbf{W}_{1}(t) = e^{-t} \left[ \cos(2t) \begin{pmatrix}
0 \\ 1
\end{pmatrix} -\sin (t) \begin{pmatrix}
2 \\ 0
\end{pmatrix} \right]$$
y
$$\mathbf{W}_{2}(t) = e^{-t} \left[ \cos(t) \begin{pmatrix}
2 \\ 0
\end{pmatrix} + \sin(2t) \begin{pmatrix}
0 \\ 1
\end{pmatrix} \right]$$
Por lo tanto, la solución general real es
$$\mathbf{Y}(t) = c_{1} e^{-t} \left[ \cos(2t) \begin{pmatrix}
0 \\ 1
\end{pmatrix} -\sin (t) \begin{pmatrix}
2 \\ 0
\end{pmatrix} \right] + c_{2} e^{-t} \left[ \cos(t) \begin{pmatrix}
2 \\ 0
\end{pmatrix} + \sin(2t) \begin{pmatrix}
0 \\ 1
\end{pmatrix} \right]$$
Las funciones $x(t)$ y $y(t)$ son
\begin{align*}
x(t) &= -2c_{1}e^{-t} \sin(2t) + 2c_{2}e^{-t} \cos(2t) \\
y(t) &= c_{1}e^{-t} \cos(2t) + c_{2}e^{-t} \sin(2t)
\end{align*}
Estas funciones también se pueden escribir como
\begin{align*}
x(t) &= e^{-t} R_{1} \cos(2t -\delta_{1}) \\
y(t) &= e^{-t} R_{2} \cos(2t -\delta_{2})
\end{align*}
De tarea moral determina las constantes $R_{1}$, $R_{2}$, $\delta_{1}$ y $\delta_{2}$ en términos de las constantes $c_{1}$ y $c_{2}$.
Podemos notar que las soluciones ya no son trayectorias cerradas debido al término $e^{-t}$. En este caso el periodo es $t = 2 \pi / 2 = \pi$. Notemos que
\begin{align*}
x(0) &= 2c_{2} = R_{1} \cos(-\delta_{1}) \\
y(0) &= c_{1} = R_{2} \cos(-\delta_{2})
\end{align*}
Mientras que
\begin{align*}
x(\pi) &= 2 e^{-\pi} c_{2} = R_{1} e^{-\pi} \cos(-\delta_{1}) \\
y(\pi) &= e^{-\pi} c_{1} = R_{2} e^{-\pi} \cos(-\delta_{2})
\end{align*}
Como $e^{-\pi} < 1$, entonces
$$x(\pi) < x(0) \hspace{1cm} y \hspace{1cm} y(\pi) < y(0)$$
Por lo tanto las trayectorias corresponden a espirales que se aproximan hacia el origen.
La función paramétrica que define las trayectorias es
$$f(t) = (-2c_{1}e^{-t} \sin(2t) + 2c_{2}e^{-t} \cos(2t), c_{1}e^{-t} \cos(2t) + c_{2}e^{-t} \sin(2t))$$
Para determinar la dirección en que giran las trayectorias consideremos la ecuación $y^{\prime}$ del sistema, dicha ecuación es
$$y^{\prime} = x -y$$
Si $y = 0$, entonces $y^{\prime} = x$ y si $x > 0$, entonces $y^{\prime} > 0$, por lo tanto las trayectorias se mueven en el sentido opuesto a las manecillas del reloj.
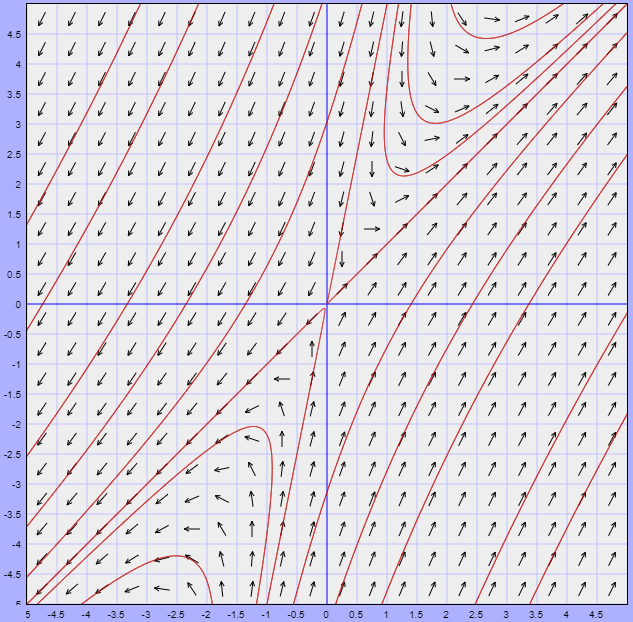
El plano fase con algunas trayectorias se muestra a continuación.
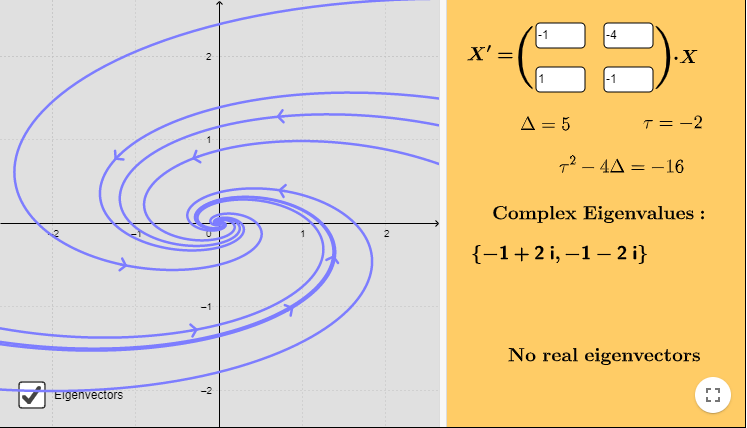
El campo vectorial asociado está definido por la función
$$F(x, y) = (-x -4y, x -y)$$
Dicho campo y algunas trayectorias se muestran en la siguiente figura.
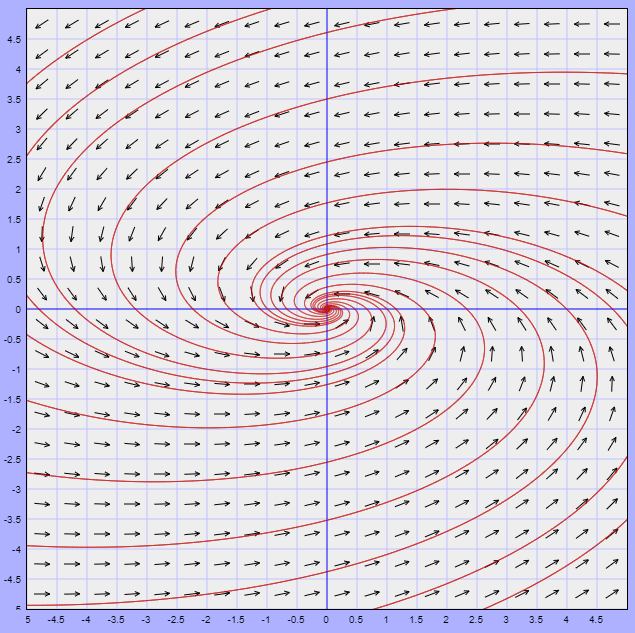
El punto de equilibrio $Y_{0} = (0, 0)$ es un foco estable.
$\square$
Concluyamos con un último ejemplo.
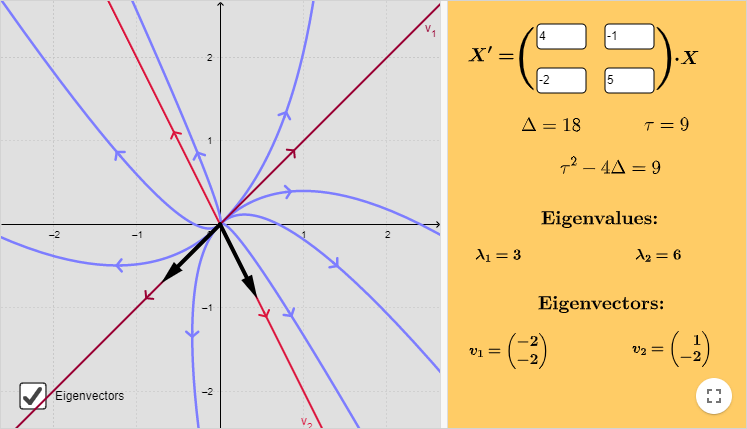
Caso 3: $\lambda_{1} = \alpha + i \beta$ y $\lambda_{2} = \alpha -i \beta$, con $\alpha > 0$.
Ejemplo: Resolver el siguiente sistema lineal y hacer un análisis cualitativo de las soluciones.
$$\mathbf{Y}^{\prime} = \begin{pmatrix}
3 & -2 \\ 4 & -1
\end{pmatrix} \mathbf{Y}$$
Solución: Determinemos los valores propios.
$$\begin{vmatrix}
3 -\lambda & -2 \\ 4 & -1 -\lambda
\end{vmatrix} = (3 -\lambda)(-1 -\lambda) + 8 = \lambda^{2} -2 \lambda + 5 = 0$$
Los valores propios son $\lambda_{1} = 1 + 2i$ y $\lambda_{2} = 1 -2i$ (con $\alpha = 1$ y $\beta = 2$ ). Determinemos los vectores propios con la ecuación
$$(\mathbf{A} -(1 + 2i) \mathbf{I}) \mathbf{K} = \mathbf{0}$$
o bien,
$$\begin{pmatrix}
2 -2i & -2 \\ 4 & -2 -2i
\end{pmatrix} \begin{pmatrix}
k_{1} \\ k_{2}
\end{pmatrix} = \begin{pmatrix}
0 \\ 0
\end{pmatrix}$$
De este sistema se obtiene que
$$k_{1} = \left( \dfrac{1+ i}{2} \right) k_{2}$$
Sea $k_{2} = 1$, entonces $k_{1} = \dfrac{1 + i}{2}$, así el primer vector propio es
$$\mathbf{K}_{1} = \begin{pmatrix}
\dfrac{1 + i}{2} \\ 1
\end{pmatrix} = \begin{pmatrix}
0 \\ 1
\end{pmatrix} + i \begin{pmatrix}
\dfrac{1}{2} \\ 0
\end{pmatrix} $$
y sabemos enseguida que
$$\mathbf{K}_{2} = \begin{pmatrix}
\dfrac{1 -i}{2} \\ 1
\end{pmatrix} = \begin{pmatrix}
0 \\ 1
\end{pmatrix} -i \begin{pmatrix}
\dfrac{1}{2} \\ 0
\end{pmatrix} $$
La primer solución linealmente independiente es
$$Y_{1}(t) = e^{(1 + 2i)t} \begin{pmatrix}
\dfrac{1 + i}{2} \\ 1
\end{pmatrix}$$
Vemos que
\begin{align*}
e^{(1 + 2i)t} \begin{pmatrix}
\dfrac{1 + i}{2} \\ 1
\end{pmatrix} &= e^{t} [\cos(2t) + i \sin(2t)] \left[ \begin{pmatrix}
\dfrac{1}{2} \\ 1
\end{pmatrix} + i \begin{pmatrix}
\dfrac{1}{2} \\ 0
\end{pmatrix} \right] \\
&= e^{t} \left[ \cos(2t) \begin{pmatrix}
\dfrac{1}{2} \\ 1
\end{pmatrix} -\sin(2t) \begin{pmatrix}
\dfrac{1}{2} \\ 0
\end{pmatrix} + i \cos(2t) \begin{pmatrix}
\dfrac{1}{2} \\ 0
\end{pmatrix} + i \sin(2t) \begin{pmatrix}
\dfrac{1}{2} \\ 1
\end{pmatrix} \right]
\end{align*}
de donde,
$$\mathbf{W}_{1}(t) = e^{t} \left[ \cos(2t) \begin{pmatrix}
\dfrac{1}{2} \\ 1
\end{pmatrix} -\sin(2t) \begin{pmatrix}
\dfrac{1}{2} \\ 0
\end{pmatrix} \right]$$
y
$$\mathbf{W}_{2}(t) = e^{t} \left[ \cos(2t) \begin{pmatrix}
\dfrac{1}{2} \\ 0
\end{pmatrix} + \sin(2t) \begin{pmatrix}
\dfrac{1}{2} \\ 1
\end{pmatrix} \right]$$
Por lo tanto, la solución general real del sistema es
$$\mathbf{Y}(t) = c_{1} e^{t} \left[ \cos(2t) \begin{pmatrix}
\dfrac{1}{2} \\ 1
\end{pmatrix} -\sin(2t) \begin{pmatrix}
\dfrac{1}{2} \\ 0
\end{pmatrix} \right] + c_{2} e^{t} \left[ \cos(2t) \begin{pmatrix}
\dfrac{1}{2} \\ 0
\end{pmatrix} + \sin(2t) \begin{pmatrix}
\dfrac{1}{2} \\ 1
\end{pmatrix} \right]$$
Las funciones $x(t)$ y $y(t)$ son
\begin{align*}
x(t) &= e^{t} \left( \dfrac{c_{1} + c_{2}}{2} \right) \cos(2t) + e^{t} \left( \dfrac{c_{2} -c_{1}}{2} \right) \sin(2t) \\
y(t) &= c_{1}e^{t} \cos(2t) + c_{2}e^{t} \sin(2t)
\end{align*}
El periodo de las soluciones es $T = 2 \pi / 2 = \pi$. Muestra, de manera similar a como lo hicimos en el ejemplo anterior, que
$$x(\pi) > x(0) \hspace{1cm} y \hspace{1cm} y(\pi) > y(0)$$
esto debido a que $e^{\pi} > 1$. Por lo tanto, las trayectorias describen espirales que se alejan del origen.
La función paramétrica que define a las trayectorias es
$$f(t) = (k_{1} e^{t} \cos(2t) + k_{2} e^{t} \sin(2t), c_{1}e^{t} \cos(2t) + c_{2}e^{t} \sin(2t) )$$
Con
$$k_{1} = \left( \dfrac{c_{1} + c_{2}}{2} \right) \hspace{1cm} y \hspace{1cm} k_{2} = \left( \dfrac{c_{2} -c_{1}}{2} \right)$$
Para determinar la dirección de las trayectorias consideremos la ecuación
$$y^{\prime} = 4x -y$$
Si $y = 0$ se obtiene que $y^{\prime} = 4x$ y si $x > 0$, entonces $y^{\prime} > 0$, por lo tanto, las trayectorias se mueven en el sentido opuesto a las manecillas del reloj.
El plano fase se muestra a continuación.
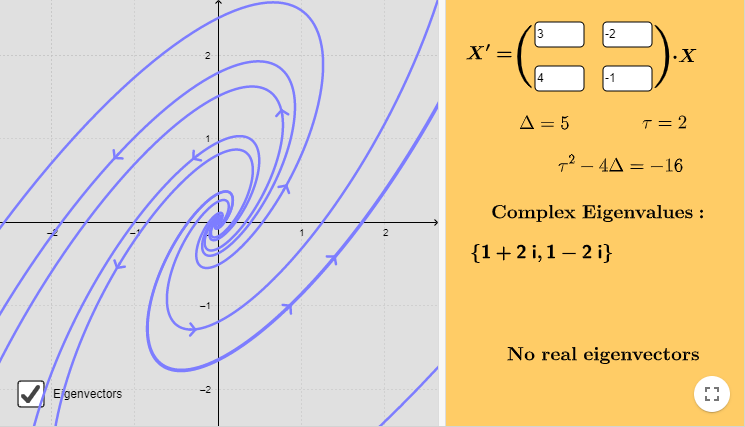
La función vectorial que define al campo vectorial es
$$F(x, y) = (3x -2y, 4x -y)$$
El campo vectorial y algunas trayectorias se ilustran en la siguiente figura.
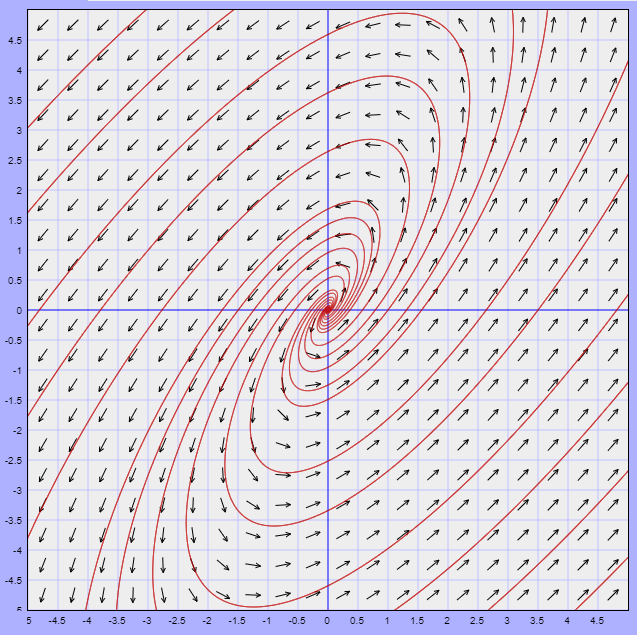
El punto de equilibrio $Y_{0} = (0, 0)$ corresponde a un foco inestable.
$\square$
Hemos concluido con esta entrada. Continuemos en la siguiente entrada con el análisis en el caso en el que los valores propios de la matriz $\mathbf{A}$ son iguales.
Tarea moral
Los siguientes ejercicios no forman parte de la evaluación del curso, pero servirán para entender mucho mejor los conceptos vistos en esta entrada, así como temas posteriores.
- Resolver los siguientes sistemas lineales y hacer un análisis cualitativo de las soluciones.
- $\mathbf{Y}^{\prime} = \begin{pmatrix}
0 & 4 \\ -9 & 0
\end{pmatrix} \mathbf{Y}$
- $\mathbf{Y}^{\prime} = \begin{pmatrix}
6 & -1 \\ 5 & 2
\end{pmatrix} \mathbf{Y}$
- $\mathbf{Y}^{\prime} = \begin{pmatrix}
1 & -1 \\ 5 & -3
\end{pmatrix} \mathbf{Y}$
- $\mathbf{Y}^{\prime} = \begin{pmatrix}
2 & -5 \\ 4 & -2
\end{pmatrix} \mathbf{Y}$
- $\mathbf{Y}^{\prime} = \begin{pmatrix}
4 & 5 \\ -2 & 6
\end{pmatrix} \mathbf{Y}$
- $\mathbf{Y}^{\prime} = \begin{pmatrix}
1 & -8 \\ 1 & -3
\end{pmatrix} \mathbf{Y}$
Más adelante…
Continuando con nuestro estudio cualitativo de los sistemas lineales homogéneos con dos ecuaciones diferenciales, en la siguiente entrada veremos que ocurre en el plano fase cuando los valores propios de la matriz $\mathbf{A}$ son repetidos.
Entradas relacionadas
- Página principal del curso: Ecuaciones Diferenciales I
- Entrada anterior del curso: Teoría cualitativa de los sistemas lineales homogéneos – Valores propios reales y distintos
- Siguiente entrada del curso: Teoría cualitativa de los sistemas lineales homogéneos – Valores propios repetidos
- Video relacionado al tema: Plano fase para sistemas lineales con valores propios complejos
Agradecimientos
Trabajo realizado con el apoyo del Programa UNAM-DGAPA-PAPIME PE104522 «Hacia una modalidad a distancia de la Licenciatura en Matemáticas de la FC-UNAM – Etapa 2»