En la unidad anterior desarrollamos todo lo concerniente a los números reales, ahora comenzaremos a ver funciones. Para ello recordemos de nuestros cursos de álgebra cómo se define el producto cartesiano de un par de conjuntos $A$ y $B$: $$ A\times B := \left\{ (a,b) : a \in A, b \in B \right\},$$ así vemos que sus elementos son pares ordenados.
Por lo que decimos que cualquier subconjunto $R \subseteq A\times B$, es llamado una relación entre $A$ y $B$.
Basándonos en este par de conceptos daremos la definición formal de función entre un par de conjuntos.
Definición de función
Definición (función): Una función $f$ entre los conjuntos $A$ y $B$ es una relación tal que:
Para todo $a \in A$ existe $b \in B$ donde $(a,b) \in f$.
Si $(a, b_{1}), (a, b_{2})$ entonces $b_{1}= b_{2}$.
Notación:
$f : A \rightarrow B$ es una función con dominio $A$ y codominio $B$.
$f(a)=b$ es llamada la regla de correspondencia de f.
En resumen, a una función $f : A \rightarrow B$ la conforman tres cosas:
Su dominio.
Su codominio.
Su regla de correspondencia.
El conjunto imagen de una función
Definición (Conjunto imagen): Sea $f : A \rightarrow B$ una función. La imagen de f se define como: $$Im_{f}:= \left\{ b \in B : \exists a \in A (f(a) =b) \right\}.$$ Simplificado sería: $$Im_{f}:= \left\{ f(a) \in B : a \in A \right\}.$$
Ejemplo: Sea $f: \r \rightarrow \r$. Si $f(x)=|x|$ entonces $Im_{f}=[0, \infty)$.
Demostración: $\subseteq )$ Sea $x \in \r$. Vemos que $f(x)= |x|\geq 0$ por lo que $f(x) \in [0, \infty)$.
$\supseteq )$ Tomemos $y \in [0, \infty)$. Debemos probar que existe $x \in \r$ tal que $f(x)= y$. Sea $x=y \in \r$ con $y \geq 0$. Así se sigue que $f(y)= |y|=y$ por lo que $f(y)=x$.
$\square$
Ejemplo
Encuentra el dominio y la imagen de la siguiente función: $$f(x)= \sqrt{1-x^{2}}\quad \text{.}$$
Dominio: Vemos que $y=\sqrt{1-x^{2}}$ está bien definido \begin{align*} &\Leftrightarrow 1-x^{2} \geq 0\\ &\Leftrightarrow 1 \geq x^{2}\\ &\Leftrightarrow 1 \geq |x|\\ \end{align*} Así concluimos que el dominio es el conjunto: $$D_{f}= [-1,1]\quad \text{.}$$ Imagen: Como $x \in [-1,1]$ entonces \begin{align*} -1 \leq x \leq 1 &\Leftrightarrow 0 \leq x^{2} \leq 1\\ &\Leftrightarrow 0 \geq -x^{2} \geq -1\\ &\Leftrightarrow 1\geq 1-x^{2} \geq 1-1\\ &\Leftrightarrow 1\geq 1-x^{2} \geq 0\\ &\Leftrightarrow 1\geq \sqrt{1-x^{2}} \geq 0\\ \end{align*}
Por lo anterior tenemos: $$Im_{f} = [0,1]\quad \text{.}$$
Ejercicio 1
Encuentra el dominio de la siguiente función: \begin{equation*} f(x)= \frac{1}{4-x^{2}} \end{equation*}
Vemos que la función está bien definido si y sólo si: \begin{align*} 4-x^{2} \neq 0 &\Leftrightarrow (2-x)(2+x) \neq 0\\ &\Leftrightarrow x \neq 2 \quad \text{y} \quad x\neq -2 \end{align*} Por lo que su dominio sería: $$D_{f}= \r – \left\{-2,2 \right\}\quad \text{.}$$ es decir, todos los reales quitando el $-2$ y el $2$.
Ejercicio 2
Encuentra el dominio de la siguiente función: $$f(x)= \sqrt{x-x^{3}}\quad \text{.}$$
Dominio: Vemos ahora que para $y=\sqrt{x-x^{3}}$ está bien definido \begin{align*} &\Leftrightarrow x-x^{3} \geq 0\\ &\Leftrightarrow x(1-x^{2}) \geq 0\\ &\Leftrightarrow x(1-x)(1+x) \geq 0\\ &\Leftrightarrow x \geq 0,\quad x\leq 1, \quad x \geq -1 \end{align*}
De las condiciones anteriores vemos que tenemos los siguientes posibles intervalos que cumplen la desigualdad inicial:
$(-\infty, -1]$ Vemos que al sustituir $x= -1 \in (-\infty,-1]$ tenemos que: $$-1-(-1)^{3} = -1-(-1)= 0 \geq 0$$ por lo que se cumple la desigualdad $x-x^{3} \geq 0$.
$(-1,0)$ Tomando $x=-\frac{1}{2}$ vemos que: $$-\frac{1}{2} -\left(-\frac{1}{2} \right) ^{3} = -\frac{1}{2} + \frac{1}{8} = -\frac{3}{8}$$ Por lo que no se cumple ser mayor o igual que cero.
$[1,0]$ Ahora si tomamos $x=1$ observamos: $$1- 1^{3} =1-1 =0$$ por lo que cumple la desigualdad.
$(1,\infty)$ Por último si consideramos $x= 2$ ocurre que: $$2- (2)^{3} =2-8 =-6$$ que no cumple la desigualdad.
Del análisis anterior vemos que los intervalos que cumplen con $x-x^{3} \geq 0$ son: $$(-\infty, -1] \cup [1,0]\quad \text{.}$$ Por lo que el dominio de la función sería: $$D_{f}=(-\infty, -1] \cup [1,0]\quad \text{.}$$
Gráfica de una función
Definición (gráfica): Sea $f:D_{f} \subseteq \r \rightarrow \r$ Definimos a la gráfica de f como el conjunto: $$ Graf(f)= \left\{ (x,y)\in {\mathbb{R}}^2: x \in D_{f}, \quad y=f(x) \right\},$$ que es equivalente a decir: $$Graf(f)= \left\{(x, f(x)): x \in D_{f} \right\}\quad \text{.}$$
Ejemplos
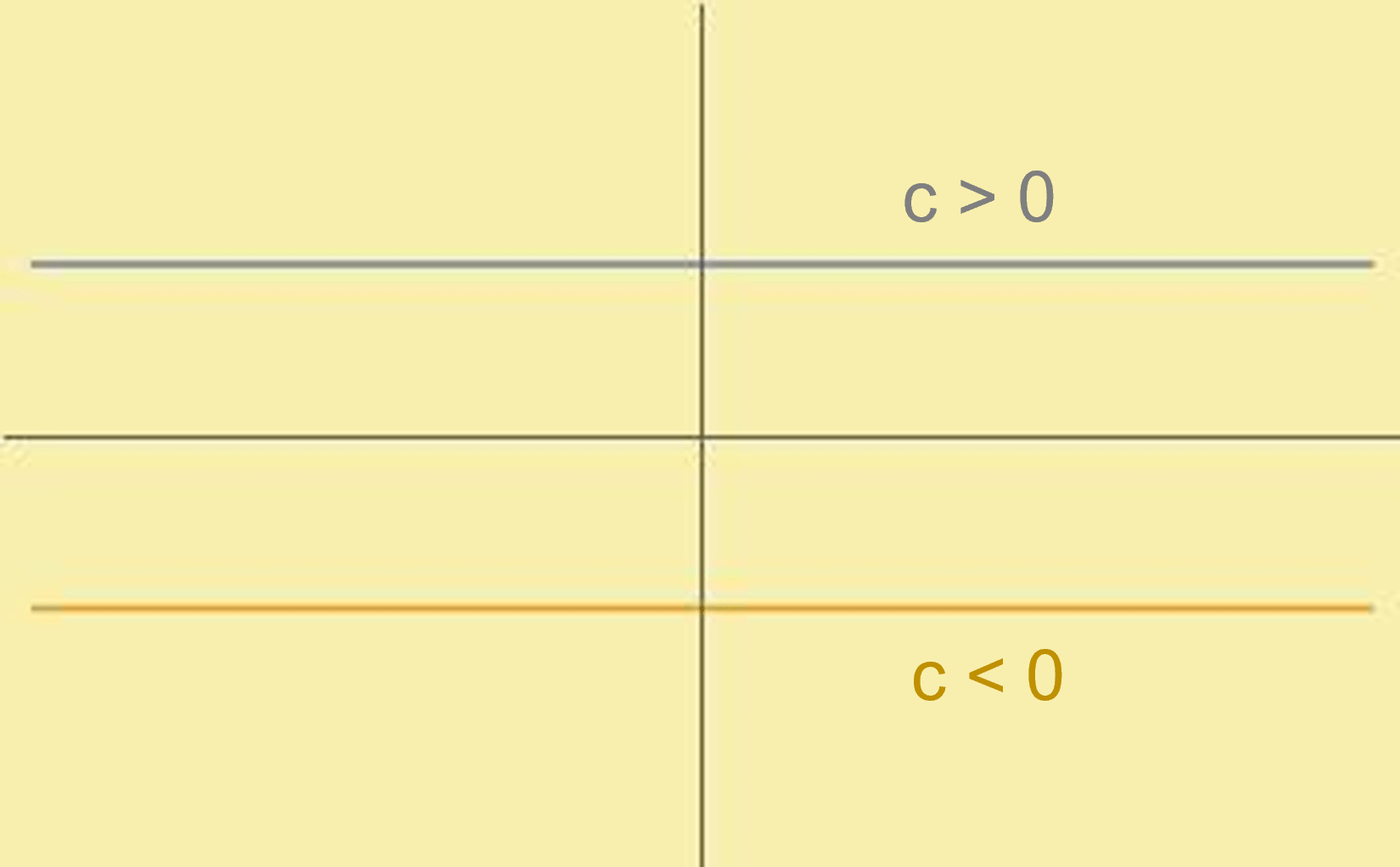
Para la función constante tenemos: $$f(x)=c ,$$ donde $D_{f}= \r$ y $Im_{f}= {c}$.
Por lo que su gráfica se vería como:
Para la función identidad tenemos: $$Id(x)=x ,$$ donde $D_{f}= \r$ y $Im_{f}= \r$.
Así su gráfica se vería:
Más adelante
En la próxima entrada veremos las definiciones relacionadas con las operaciones entre funciones: suma, producto, cociente y composición.
Tarea moral
A continuación encontrarás una serie de ejercicios que te ayudarán a repasar los conceptos antes vistos:
Sea $f: \r \rightarrow \r$. Demuestra que si $f(x)=x^{2}$ entonces $Im_{f}=[0, \infty).$
Trabajo realizado con el apoyo del Programa UNAM-DGAPA-PAPIME PE104522 «Hacia una modalidad a distancia de la Licenciatura en Matemáticas de la FC-UNAM – Etapa 2»
En la entrada anterior mostramos el teorema de factorización para polinomios con coeficientes reales. Lo que haremos ahora es ver que podemos aplicarlo en la resolución de desigualdades de polinomios en $\mathbb{R}[x]$. El objetivo es que, al final de la entrada, entendamos cómo se pueden resolver problemas como los siguientes:
Problema 1. Determina todos los números $x$ en $\mathbb{R}$ para los cuales $$x^6-12x^4-49x^2-30 > 3x^5-48x^3-51x+6.$$
Problema 2. Determina todos los números $x$ en $\mathbb{R}$ para los cuales $$\frac{1}{x}>x^3-x^2+1.$$
Antes de hablar de resolución de desigualdades de polinomios, veremos una forma alternativa de factorizar en $\mathbb{R}[x]$ usando potencias.
Teorema de factorización de polinomios reales con potencias
De acuerdo al teorema de factorización en $\mathbb{R}[x]$, un polinomio $p(x)$ se puede factorizar de manera única en factores lineales y factores cuadráticos con discriminante negativo. De ser necesario, podemos agrupar los factores lineales iguales y reordenarlos para llegar a una factorización de la forma $$a(x-r_1)^{\alpha_1}\cdots(x-r_m)^{\alpha_m}(x^2-b_1x+c_1)\cdots (x^2-b_{n}x+c_{n}),$$ en donde:
$a$ es un real distinto de cero,
$\alpha_1,\ldots,\alpha_m$ y $n$ son enteros positivos tales que $2n+\sum_{i=1}^m \alpha_i$ es igual al grado de $p(x)$,
para cada $i$ en $\{1,\ldots,m\}$ se tiene que $r_i$ es raíz real de $p(x)$ y $r_1<r_2<\ldots<r_m$
para cada $j$ en $ \{1,\ldots,n\}$ se tiene que $b_j,c_j$ son reales tales que $b_j^2-4c_j<0$.
Observa que los $r_i$ son ahora distintos y que están ordenados como $r_1<\ldots<r_m$. De aquí, obtenemos que $(x-r_i)^{\alpha_i}$ es la mayor potencia del factor lineal $x-r_i$ que divide a $p(x)$. Este número $\alpha_i$ se usa frecuentemente, y merece una definición por separado.
Definición. Sea $p(x)$ un polinomio en $\mathbb{R}[x]$ y $r$ una raíz de $p(x)$. La multiplicidad de $r$ como raíz de $p(x)$ es el mayor entero $\alpha$ tal que $$(x-r)^\alpha \mid p(x).$$ Decimos también que $r$ es una raíz de multiplicidad $\alpha$.
Ejemplo. El polinomio $k(x)=x^4-x^3-3x^2+5x-2$ se factoriza como $(x-1)^3(x+2)$. Así, la multiplicidad de $1$ como raíz de $k(x)$ es $3$. Además, $-2$ es una raíz de $k(x)$ de multiplicidad $1$.
$\triangle$
Después hablaremos de una forma práctica en la que podemos encontrar la multiplicidad de una raíz, cuando hablemos de continuidad de polinomios y sus derivadas.
Desigualdades de polinomios reales factorizados
Supongamos que tenemos un polinomio $p(x)$ no constante en $\mathbb{R}[x]$ para el cual conocemos su factorización en la forma $$a(x-r_1)^{\alpha_1}\cdots(x-r_m)^{\alpha_m}(x^2-b_1x+c_1)\cdots (x^2-b_{n}x+c_{n}),$$ y que queremos determinar para qué valores reales $r$ se cumple que $$p(r)>0.$$
Daremos por cierto el siguiente resultado, que demostraremos cuando hablemos de continuidad de polinomios.
Proposición. Las evaluaciones en reales de un polinomio cuadrático y mónico en $\mathbb{R}[x]$ de discriminante negativo, siempre son positivas.
Lo que nos dice este resultado es que, para fines de la desigualdad que queremos resolver, podemos ignorar los factores cuadráticos en la factorización de $p(x)$ pues
$$a(x-r_1)^{\alpha_1}\cdots(x-r_m)^{\alpha_m}(x^2-b_1x+c_1)\cdots (x^2-b_{n}x+c_{n})$$ y $$a(x-r_1)^{\alpha_1}\cdots(x-r_m)^{\alpha_m}$$ tienen el mismo signo.
Por la miasma razón, podemos ignorar aquellos factores lineales con exponente par, y de los de exponente impar, digamos $(x-r)^{2\beta +1}$ obtenemos una desigualdad equivalente si los remplazamos por exponente $1$, pues $(x-r)^{2\beta}$ es positivo y por lo tanto no cambia el signo de la desigualdad si lo ignoramos.
En resumen, cuando estamos resolviendo una desigualdad del estilo $p(x)>0$ podemos, sin cambiar el conjunto solución, reducirla a una de la forma $$q(x):=a(x-r_1)(x-r_2)\ldots(x-r_m)>0.$$ La observación clave para resolver desigualdades de este estilo está resumida en el siguiente resultado.
Proposición. Tomemos un polinomio $q(x)$ en $\mathbb{R}[x]$ de la forma $$q(x)=a(x-r_1)(x-r_2)\ldots(x-r_m)$$ con $r_1<\ldots<r_m$ reales.
Si $m$ es par:
Para reales $r$ en la unión de intervalos $$(-\infty,r_1)\cup(r_2,r_3)\cup\ldots \cup (r_{m-2},r_{m-1})\cup (r_m,\infty),$$ la evaluación $q(r)$ tiene el mismo signo que $a$
Para reales $r$ en la unión de intervalos $$(r_1,r_2)\cup(r_3,r_4)\cup\ldots \cup (r_{m-3},r_{m-2})\cup (r_{m-1},r_m),$$ la evaluación $q(r)$ tiene signo distinto al de $a$.
Si $m$ es impar:
Para reales $r$ en la unión de intervalos $$(r_1,r_2)\cup(r_3,r_4)\cup\ldots \cup (r_{m-2},r_{m-1})\cup (r_m,\infty),$$ la evaluación $q(r)$ tiene el mismo signo que $a$.
Para reales $r$ en la unión de intervalos $$(-\infty,r_1)\cup(r_2,r_3)\cup\ldots \cup (r_{m-3},r_{m-2})\cup (r_{m-1},r_m),$$ la evaluación $q(r)$ tiene signo distinto al de $a$.
Demostración. El producto $(r-r_1)(r-r_2)\ldots(r-r_m)$ es positivo si y sólo si tiene una cantidad par de factores negativos. Si $r>r_m$, todos los factores son positivos, y por lo tanto $q(r)$ tiene el mismo signo que $a$ cuando $r$ está en el intervalo $(r_m,\infty)$.
Cada que movemos $r$ de derecha a izquierda y cruzamos un valor $r_i$, cambia el signo de exactamente uno de los factores, y por lo tanto la paridad de la cantidad de factores negativos. El resultado se sigue de hacer el análisis de casos correspondiente.
$\square$
Veamos cómo podemos utilizar esta técnica para resolver desigualdades polinomiales que involucran a un polinomio que ya está factorizado en irreducibles.
Problema 1. Determina para qué valores reales $x$ se tiene que $$-2(x-5)^7(x+8)^4(x+2)^3(x+10)(x^2-x+2)^3$$ es positivo.
Solución. Por la discusión anterior, podemos ignorar el polinomio cuadrático del final, pues es irreducible. También podemos ignorar los factores lineales con potencia par, y podemos remplazar las potencias impares por unos. Así, basta con encontrar los valores reales de $x$ para los cuales $$q(x)=-2(x-5)(x+2)(x+10)$$ es positivo. Tenemos $3$ factores, así que estamos en el caso de $m$ impar en la proposición.
Las tres raíces, en orden, son $-10, -2, 5$. Por la proposición, para $x$ en la unión de intervalos $$(-\infty,-10)\cup (-2,5)$$ se tiene que $q(x)$ tiene signo distinto al de $a=-2$ y por lo tanto es positivo. Para $x$ en el conjunto $$(-10,-2)\cup (5,\infty)$$ se tiene que $q(x)$ tiene signo igual al de $a=-2$, y por lo tanto es negativo. De esta forma, la respuesta es el conjunto $$(-\infty,-10)\cup (-2,5).$$
Puedes dar clic aquí para ver en GeoGebra las gráfica de $q(x)$ y del polinomio original, y verificar que tienen el mismo signo en los mismos intervalos.
$\triangle$
Si estamos resolviendo una desigualdad y el valor de $a$ en la factorización es positivo, es un poco más práctico ignorarlo desde el principio, pues no afecta a la desigualdad.
Problema 2. Determina para qué valores reales $x$ se tiene que $$7(x+7)^{13}(x+2)^{31}(x-5)^{18}(x^2+1)$$ es positivo.
Solución. Tras las cancelaciones correspondientes, obtenemos la desigualdad equivalente $$(x+7)(x+2)>0.$$
Las raíces del polinomio que aparece son $-7$ y $-2$. De acuerdo a la proposición, estamos en el caso con $m$ par. De esta forma, la expresión es negativa en el intervalo $(-7,-2)$ y es positiva en la unión de intervalos $$(-\infty,-7)\cup (-2,\infty).$$
$\triangle$
Otras desigualdades de polinomios y manipulaciones algebraicas
Si tenemos otras expresiones polinomiales, también podemos resolverlas con ideas similares, solo que a veces se tienen que hacer algunas manipulaciones previas para llevar la desigualdad a una de la forma $p(x)>0$.
Problema. Determina todos los números $x$ en $\mathbb{R}$ para los cuales $$x^6-12x^4-49x^2-30 > 3x^5-48x^3-51x+6.$$
Solución. El problema es equivalente a encontrar los reales $x$ para los cuales $$x^6-3x^5+12x^4+48x^3-29x^2+51x-36>0.$$ El polinomio del lado izquierdo se puede factorizar como $(x-3)^2(x-1)(x+4)(x^2+1)$, así que obtenemos el problema equivalente $$(x-3)^2(x-1)(x+4)(x^2+1)>0,$$ que ya sabemos resolver. El resto de la solución queda como tarea moral.
Puedes ver la gráfica del polinomio $$(x-3)^2(x-1)(x+4)(x^2+1)$$ en GeoGebra si das clic aquí.
$\triangle$
Tener cuidado al multiplicar por denominadores
Hay que tener cuidado al realizar algunas manipulaciones algebraicas, pues pueden cambiar el signo de la desigualdad que estamos estudiando. Veamos un ejemplo donde sucede esto.
Problema. Determina todos los números $x$ en $\mathbb{R}$ para los cuales $$\frac{1}{x}>x^3-x^2+1.$$
Solución. La expresión no está definida en $x=0$, pues se anula un denominador. Supongamos entonces que $x\neq 0$, y recordémoslo al expresar la solución final. Vamos a multiplicar la desigualdad por $x$, pero tenemos que hacer casos.
Si $x>0$, entonces el signo de desigualdad no se altera y obtenemos la desigualdad equivalente $$0>x^4-x^3+x-1=(x-1)(x+1)(x^2-x+1).$$ El factor cuadrático es irreducible y lo podemos ignorar. Si estuviéramos trabajando en todo $\mathbb{R}$, el conjunto solución sería el intervalo $(-1,1)$. Sin embargo, tenemos que restringir este conjunto solución sólo al caso en el que estamos, es decir, $x>0$. Así, para este caso sólo los reales en $(0,1)$ son solución.
Si $x<0$, entonces el signo de la desigualdad sí se altera, y entonces obtenemos la desigualdad equivalente $$0<x^4-x^3+x-1=(x-1)(x+1)(x^2-x+1).$$ De nuevo podemos ignorar el factor cuadrático. La desigualdad tiene solución en todo $\mathbb{R}$ al conjunto $(-\infty,-1)\cup (1,\infty)$, pero en este caso debemos limitarlo adicionalmente con la restricción $x<0$. De este modo, las soluciones para este caso están en el intervalo $(-\infty,-1)$.
Ahora sí, juntando ambos casos, tenemos que el conjunto solución final es $$(-\infty,-1)\cup(0,1).$$
Puedes ver la gráfica en GeoGebra de $\frac{1}{x}-x^3+x^2-1$ dando clic aquí. Ahí puedes verificar que esta expresión es positiva exactamente en el conjunto que encontramos.
$\triangle$
Más adelante…
Como queda claro, resulta ser útil tener un polinomio en su forma factorizada para resolver desigualdades de polinomios reales. En los ejemplos que dimos en esta entrada, se dieron las factorizaciones de los polinomios involucrados. En el resto del curso veremos herramientas que nos permitirán encontrar la factorización de un polinomio o, lo que es parecido, encontrar sus raíces:
Veremos propiedades de continuidad de polinomios para mostrar la existencia de raíces para polinomios reales en ciertos intervalos.
El teorema del factor nos dice que si $r$ es raíz de $p(x)$, entonces $x-r$ divide a $p(x)$. Sin embargo, no nos dice cuál es la multiplicidad de $r$. Veremos que la derivada de un polinomio nos puede ayudar a determinar eso.
También veremos el criterio de la raíz racional, que nos permite enlistar todos los cantidatos a ser raíces racionales de un polinomio $p(x)$ con coeficientes racionales.
Finalmente, veremos que para los polinomios de grado $3$ y $4$ hay formas de obtener sus raíces de forma explícita, mediante las fórmulas de Cardano y de Ferrari.
Tarea moral
A continuación hay algunos ejercicios para que practiques los conceptos vistos en esta entrada. Te será de mucha utilidad intentarlos para entender más la teoría vista.
Completa la solución del problema enunciado en la sección de manipulaciones algebraicas.
Encuentra el conjunto solución de números reales $x$ tales que $$(x+1)(x+2)^2(x+3)^3(x+4)^4>0.$$
Determina las soluciones reales a la desigualdad $$\frac{x-1}{x+2}>\frac{x+2}{x-1}.$$ Ten cuidado con los signos. Verifica tu respuesta en este enlace de GeoGebra, que muestra la gráfica de $f(x)=\frac{x-1}{x+2}-\frac{x+2}{x-1}$.
Realiza las gráficas de otros polinomios de la entrada en GeoGebra para verificar las soluciones dadas a las desigualdades de polinomios.
Revisa esta entrada, en donde se hablan de aplicaciones de desigualdades polinomiales para un problema de un concurso de matemáticas.
Trabajo realizado con el apoyo del Programa UNAM-DGAPA-PAPIME PE104522 «Hacia una modalidad a distancia de la Licenciatura en Matemáticas de la FC-UNAM – Etapa 2»
En esta entrada voy a platicar de una forma en la que se puede plantear un modelo de epidemia básico usando álgebra lineal. Es un modelo bastante simple, sin embargo a partir de él se pueden verificar varias de las lecciones que hemos estado aprendiendo durante la crisis del coronavirus. A grandes rasgos, haremos algunas suposiciones razonables para plantear una epidemia como un modelo de Markov.
Ya que hagamos esto, estudiaremos dos escenarios posibles: en el que la gente sale de sus casas y en el que la gente se queda en sus casas. Para ello usaremos las librerías NumPy y Matplotlib de Python para hacer las cuentas y generar bonitas gráficas como la siguiente:
Ejemplo del tipo de gráficas que obtendremos en la entrada
En particular, veremos que incluso de este modelo simple se notan contrastes importantes en ambos escenarios. En particular, se puede deducir la importancia de #QuédateEnCasa para retrasar el contagio y no saturar los sistemas de salud.
Advertencia: De ninguna forma esta entrada pretende modelar, específicamente, la evolución del coronavirus. Para ello hay expertos trabajando en el tema, y están usando modelos mucho más sofisticados que el que platicaré. Esta entrada es, en todo caso, una introducción al tema y ayuda a explicar, poco a poco, algunos de los argumentos que se usan en modelación matemática de epidemias.
Suposiciones y modelo tipo Markov
Comenzemos a plantear el modelo de epidemia básico. Pensemos en una enfermedad imaginaria, que se llama «Imagivid» y en un territorio imaginario que se llama «Imagilandia», donde la población inicial es de $100,000$ habitantes sanos, en el día $0$.
Vamos a pensar que una persona puede estar en alguno de los siguientes cinco estados:
Sano
Síntomas leves
Síntomas graves
Recuperado
Fallecido
Para cada día $n$, consideremos el vector $$X(n)=(s(n),l(n),g(n),r(n),f(n))$$ de $5$ entradas cuyas entradas son los sanos, de síntomas leves, de síntomas graves, recuperados y fallecidos al día $n$. Por ejemplo al día $0$ dijimos que todos están sanos, así que $X(0)=(100000,0,0,0,0)$.
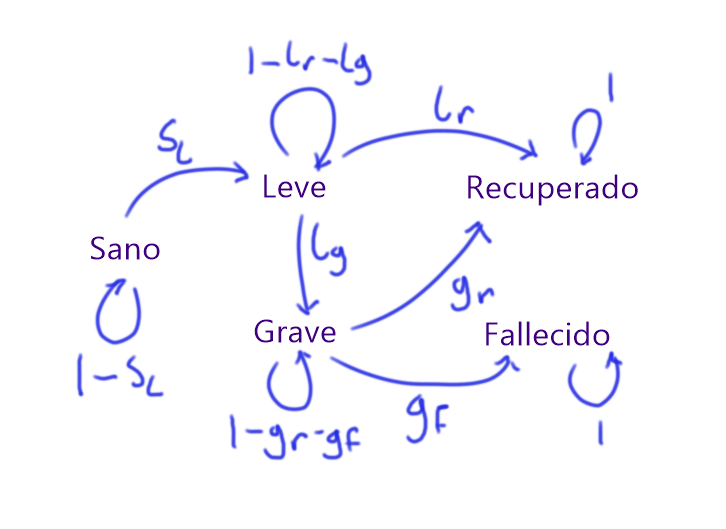
Haremos las siguientes suposiciones de cómo se pasa de un estado a otro
Los únicos fallecidos del periodo de tiempo que tendremos son por Imagivid. Sólo se puede fallecer de ello tras tener síntomas graves. Si alguien tiene síntomas graves, entonces tiene cierta probabilidad $g_f$ de fallecer al día siguiente, $g_r$ de recuperarse y por lo tanto $1-g_r-g_f$ de quedarse como enfermo grave.
Imagivid se contagia de persona a persona, y de un día a otro una persona tiene probabilidad $s_l$ de pasar de estar sana a tener síntomas leves. No se puede pasar directamente a tener síntomas graves, recuperarse o morir. De modo que se queda sana de un día a otro con probabilidad $1-s_l$
Si una persona tiene síntomas leves, tiene probabilidad $l_g$ de pasar a tener síntomas graves y $l_r$ de pasar a recuperarse. Por lo tanto, tiene probabilidad $1-l_g-l_r$ de quedarse con síntomas leves.
Una persona que se recupera desarrolla inmunidad a Imagivid, así que se queda en ese estado.
Una persona que fallece, se queda en ese estado.
En otras palabras, tenemos el siguiente diagrama de cómo se pasa de tener un estado a otro, en donde los números en las flechas muestran la probabilidad de pasar de un estado a otro:
Diagrama de probabilidades de transición
En lenguaje técnico, estamos modelando a la epidemia como un proceso de Markov. Sin embargo, no es necesario entender toda la teoría de procesos de Markov para entender lo que sigue, pues la idea es bastante intuitiva.
Con estos números y suposiciones, podemos entender, en valor esperado, cómo será el vector de población $$X(n+1)=(s(n+1), l(n+1), g(n+1), r(n+1), f(n+1))$$ si sabemos cómo es el vector $$X(n)=(s(n), l(n), g(n), r(n), f(n)).$$ Por ejemplo, podemos esperar que la cantidad de recuperados al día $n+1$ sea $$r(n+1)=l_r \cdot l(n)+ g_r \cdot g(n) + 1 \cdot r(n),$$ pues de los de síntomas leves del día $n$ habrá una proporción $l_r$ de ellos que se recuperen, de los graves del día $n$ habrá una proporción $g_r$ de ellos que se recuperen, y todos los recuperados del día $n$ se quedan recuperados. De esta forma, obtenemos el siguiente sistema de ecuaciones de lo que podemos esperar: \begin{align*} s(n+1)&=(1-s_l) \cdot s(n)\\ l(n+1)&=s_l \cdot s(n) + (1-l_r-l_g) \cdot l(n)\\ g(n+1)&= l_g \cdot l(n) + (1-g_r-g_f) \cdot g(n)\\ r(n+1)&=l_r \cdot l(n) + g_r \cdot g(n) + 1 \cdot r(n)\\ f(n+1)&=g_f \cdot g(n) + 1 \cdot f(n), \end{align*}
Este sistema de ecuaciones se puede escribir de una forma mucho más compacta. Si definimos la matriz $$A=\begin{pmatrix} 1-s_l & 0 & 0 & 0 & 0 \\s_l & 1-l_r-l_g & 0 & 0 & 0 \\0 & l_g & 1-g_r-g_f & 0 & 0 \\ 0 & l_r & g_r & 1 & 0\\ 0 & 0 & g_f & 0 & 1 \end{pmatrix},$$ las ecuaciones anteriores se pueden abreviar simplemente a $$X(n+1)=AX(n).$$
De esta forma, si queremos entender qué esperar del día $n$, basta hacer la multiplicación matricial $X(n)=A^n X(0)$.
Un ejemplo concreto en Python
El modelo de epidemia básico que planteamos arriba depende de cinco parámetros:
$s_l$, la probabilidad de pasar de estar sano a tener síntomas leves,
$l_g$, la probabilidad de pasar de tener síntomas leves a graves,
$l_r$, la probabilidad de pasar de tener síntomas leves a recuperarse,
$g_r$, la probabilidad de pasar de tener síntomas graves a recuperarse y
$g_f$, la probabilidad de pasar de tener síntomas graves, a fallecer.
Hagamos un ejemplo concreto, en el que estos parámetros para Imagivid son los siguientes: $s_l=0.30$, $l_g=0.10$, $l_r=0.20$, $g_r=0.10$ y $g_f=0.10$. En «la vida real», para hacer una modelación correcta se tienen que estimar estos parámetros de lo que ya se sepa de la enfermedad.
Si ponemos estos valores, la matriz que obtenemos es la siguiente:
Vamos a usar la fórmula que obtuvimos en la sección anterior para entender cómo va evolucionando la epidemia de Imagivid. Para no hacer las cuentas a mano, usaremos Python. Trabajaremos con Python 3 y usaremos Numpy (para las cuentas de matrices) y Matplotlib (para visualizar gráficas). En el siguiente código definimos la población inicial, los parámetros de transición y la matriz de la sección anterior.
import numpy as np
import matplotlib.pyplot as plt
# En cada momento tendremos un vector
# de la distribución de la población
# (sanos, sintomas leves, sintomas graves,
# recuperados, fallecidos)
# Población inicial
x_0=(100000,0,0,0,0)
# Definimos las probabilidades de
# transición
S_L = 0.30
L_G = 0.10
L_R = 0.20
G_R = 0.10
G_F = 0.10
# Definimos la matriz A
A=np.array([[1-S_L,0,0,0,0],[S_L,1-L_G-L_R,0,0,0],[0,L_G,1-G_R-G_F,0,0],[0,L_R,G_R,1,0],[0,0,G_F,0,1]])
Vamos a estudiar la evolución de Imagivid por 60 días. Por ello, vamos a hacer un bucle en Python que calcule cómo son los vectores de población de todos estos 60 días. Para empezar a entender cómo funciona nuestro modelo de epidemia, también pediremos que muestre los valores para los días 1, 2 y 3.
# Encontramos la evolución de la
# epidemia los primeros 60 días
evolution=[x_0]
for j in range(60):
evolution.append(np.matmul(A,evolution[-1]))
# Mostramos lo que pasa los primeros
# 3 días
for j in range(1,4):
print(evolution[j])
Los valores que obtenemos son \begin{align*} X_1 &= (70000,30000,0,0,0)\\ X_2 &= (49000, 42000, 3000, 6000)\\ X_3 &= (34300, 44100, 6600, 14700, 300). \end{align*}
Esto nos dice que al primer día hay $70000$ sanos y $30000$ con síntomas leves. En los primeros dos días no hay fallecidos, pues de acuerdo a nuestro modelo de epidemia un habitante primero debe presentar síntomas leves, luego graves y luego ya tal vez fallece. Al día 3 el modelo predice $300$ fallecidos.
Esto son sólo tres días, pero sería bueno poder entender qué sucede en todo el periodo de 60 días. Para ello, vamos a pedir a Python que nos muestre una gráfica de cómo evoluciona la población a través del tiempo. Para ello hacemos lo siguiente
# Hacemos gráfica para mostrar la evolución de todo el tiempo
plt.plot([j[0] for j in evolution], label="Sanos")
plt.plot([j[1] for j in evolution], label="Síntomas leves")
plt.plot([j[2] for j in evolution], label="Síntomas graves")
plt.plot([j[3] for j in evolution], label="Recuperados")
plt.plot([j[4] for j in evolution], label="Fallecidos")
plt.title("Evolución de la población, contagio=0.30")
plt.legend()
plt.show()
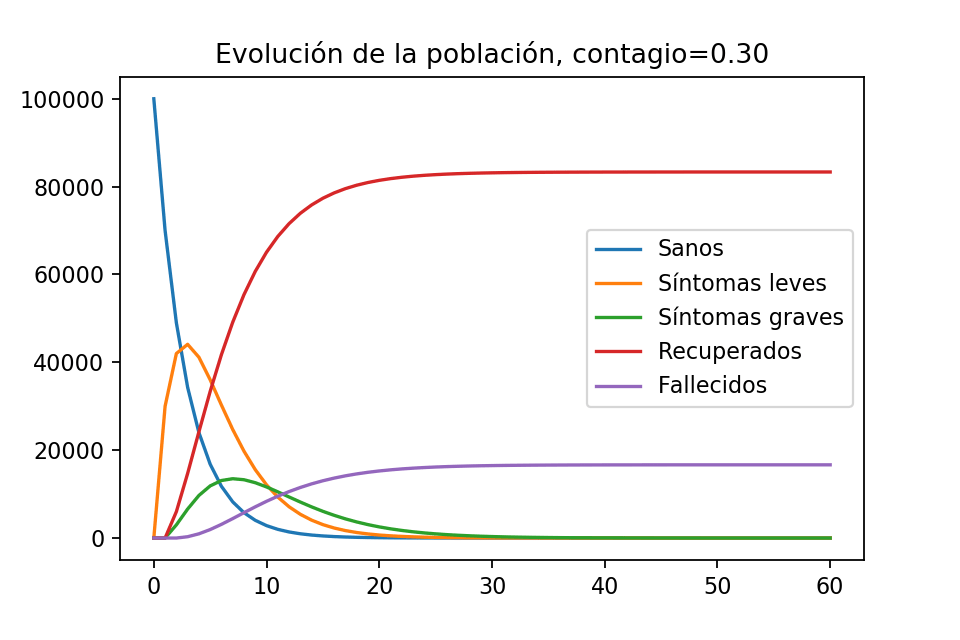
Obtenemos la siguiente imagen
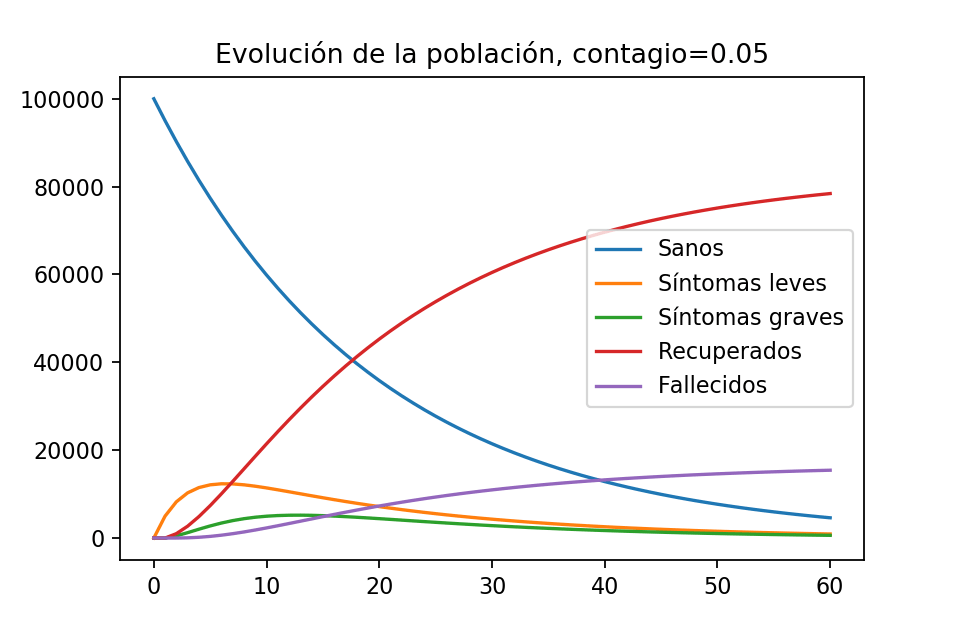
Evolución de la población con contagio $0.30$
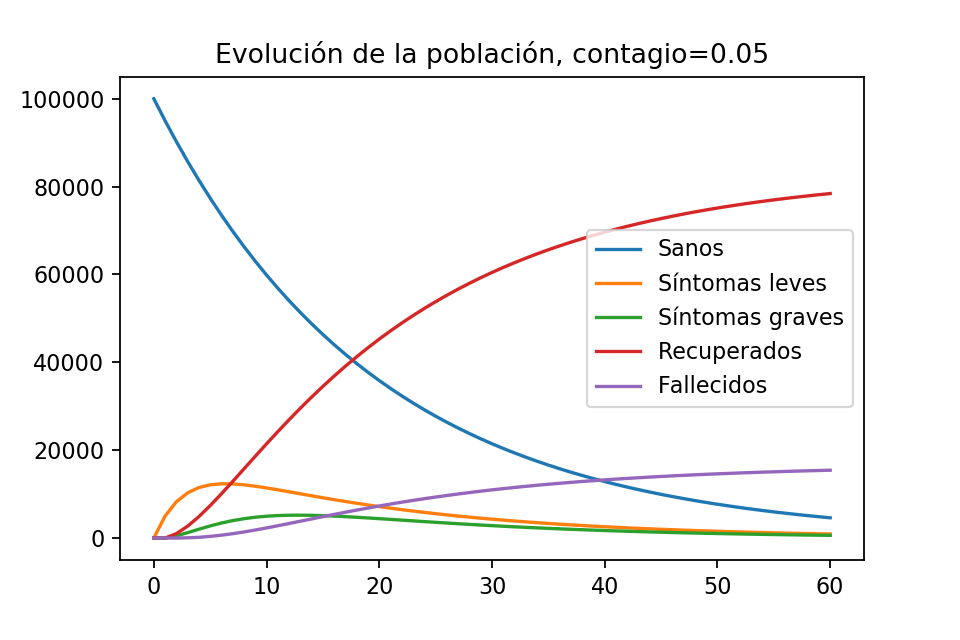
La gráfica tiene sentido es de esperarse que, tras cierta cantidad de tiempo, ya sólo haya habitantes recuperados y fallecidos. Notemos que hay un momento el el que la población con síntomas leves es de aproximadamente $40,000$ habitantes y que la población con síntomas graves llega a ser, en algún momento, como de $12,000$ habitantes.
¿Qué sucede al final de nuestro periodo de estudio? Si le pedimos a Python que nos de las últimas dos entradas del vector de población al día $60$,
#Mostramos recuperados y fallecidos al último día
print(evolution[-1][3])
print(evolution[-1][4])
obtenemos $\sim 83,333$ recuperados y $\sim 16,666$ fallecidos al día $60$, de modo que en este escenario la epidemia cobró $16,666$ vidas de Imagilandia. De hecho una observación muy importante, viendo la gráfica, es que ya se tenía prácticamente esta cantidad de víctimas desde el día 30.
Disminuir la tasa de infección para retrasar la epidemia
Antes de que sucediera la tragedia, las autoridades de Imagilandia estudiaron el modelo de epidemia que acabamos de mencionar y se dieron cuenta de que tenían que tomar una acción inmediata para mejorar la situación. Decidieron que una cosa muy importante para que la situación mejorara era pedirle a la gente que se quedara en sus casas lo más posible, pues con ello se disminuiría la tasa de contagio. Para ello sacaron la campaña #QuédateEnCasa. Las personas hicieron caso.
Habiendo más personas sanas y enfermas en su propia casa, ahora ni los enfermos pueden contagiar a sanos, ni los sanos estar expuestos a enfermos. Así, una persona sana ahora tiene menor probabilidad de estar enferma al día siguiente. Supongamos que $s_l$ pasa de ser $0.30$ a ahora ser $0.05$. De esta forma, ahora tenemos una nueva matriz que ayuda a calcular la evolución de la pandemia:
Vamos a pedirle de nuevo a Python que haga las cuentas para los primeros 60 días bajo las suposiciones de nuestro modelo de epidemia y que nos muestre una gráfica de la evolución de la población.
# Definimos las probabilidades de transición, que son iguales salvo que ahora la tasa de contagio es menor, y por lo tanto S_L es menor
S_L = 0.05
L_G = 0.10
L_R = 0.20
G_R = 0.10
G_F = 0.10
# Definimos la matriz A
A=np.array([[1-S_L,0,0,0,0],[S_L,1-L_G-L_R,0,0,0],[0,L_G,1-G_R-G_F,0,0],[0,L_R,G_R,1,0],[0,0,G_F,0,1]])
evolution2=[x_0]
for j in range(60):
evolution2.append(np.matmul(A,evolution2[-1]))
plt.plot([j[0] for j in evolution2], label="Sanos")
plt.plot([j[1] for j in evolution2], label="Síntomas leves")
plt.plot([j[2] for j in evolution2], label="Síntomas graves")
plt.plot([j[3] for j in evolution2], label="Recuperados")
plt.plot([j[4] for j in evolution2], label="Fallecidos")
plt.title("Evolución de la población, contagio=0.05")
plt.legend()
plt.show()
La gráfica que obtenemos es la siguiente:
Evolución de la población con contagio $0.05$
Una cosa fantástica en este escenario es que nunca hay muchas personas enfermas simultáneamente. En el peor día, parece haber como $12,000$ personas enfermas con síntomas leves, y parece que nunca hay más de $6000$ personas con síntomas graves. ¿Qué sucede con la mortalidad? Si le pedimos a Python que nos diga el número de habitantes recuperados y fallecidos al día 60,
print(evolution2[-1][3])
print(evolution2[-1][4])
obtenemos $\sim 78,419$ recuperados y $\sim 15,438$ fallecidos. Esto es ligeramente mejor que en la situación anterior, en donde había $\sim 16,000$ fallecidos. Donde sí hay una diferencia es en lo que sucede al día $30$. Si pedimos a Python que nos muestre la cantidad de fallecidos al día $30$ en ambos escenarios obtenemos lo siguiente.
print(evolution[30][4])
print(evolution2[30][4])
En el primer escenario, en el que la gente no se queda en casa, al día $30$ tenemos $\sim 16,493$ fallecidos, que es prácticamente ya todos los que habrá. Cuando la gente se queda en casa, al día $30$ sólo hay $\sim 10,963$, una buena parte menos.
Esto parece estar mejor, sin embargo, el tiempo va a seguir pasando, y de todas formas llegaremos al día $60$, en donde ambos escenarios son muy parecidos ¿Por qué entonces todo el esfuerzo de pedirle a la gente que se quede en casa, si la diferencia es mínima? Porque el tiempo es oro.
La carrera contra el tiempo
Hay muchas razones por las cuales es conveniente retrasar la epidemia de Imagivid en Imagilandia, aunque el modelo sencillo que mostramos arriba muestre qe a los 60 días parecería que habrá la misma cantidad de fallecidos.
Primero, es importante retrasar los contagios pues existe la posibilidad de que los científicos de Imagilandia entiendan mejor a Imagivid y, por ejemplo, desarrollen una vacuna o un tratamiento. ¿Qué sucedería si los científicos encuentran una cura al día $30$? En el primer escenario sólo se salvan unas $\sim 150$ vidas, pero en el segundo escenario se salvan unas $\sim 4,500$, osea, unas $\sim 4350$ más. En otras palabras, en el primer escenario el desarrollo científico llega demasiado tarde.
Segundo, también es importante retrasar la epidemia pues permite tener el número de casos simultáneos bajo control. Esto ya lo discutimos un poco arriba, pero pidamos a Python una gráfica más, para poder discutirlo de manera más clara. Supondremos, además, que Imagilandia cuenta con solamente $6000$ camas de hospital en donde se pueden tratar los casos severos de Imagivid, y le pediremos a Python que ponga esto como una línea horizontal.
plt.plot([j[1] for j in evolution2], color="green", linestyle=":", label="Leves, Contagio=0.05")
plt.plot([j[2] for j in evolution2], color="green", label="Severos, Contagio=0.05")
plt.plot([j[1] for j in evolution], color="red", linestyle=":", label="Severos, Contagio=0.30")
plt.plot([j[2] for j in evolution], color="red", label="Severos, Contagio=0.30")
plt.hlines(6000,0,60, color="black", label="Capacidad sistema salud")
plt.title("Enfermos a través del tiempo")
plt.legend()
plt.plot()
Obtenemos la siguiente gráfica:
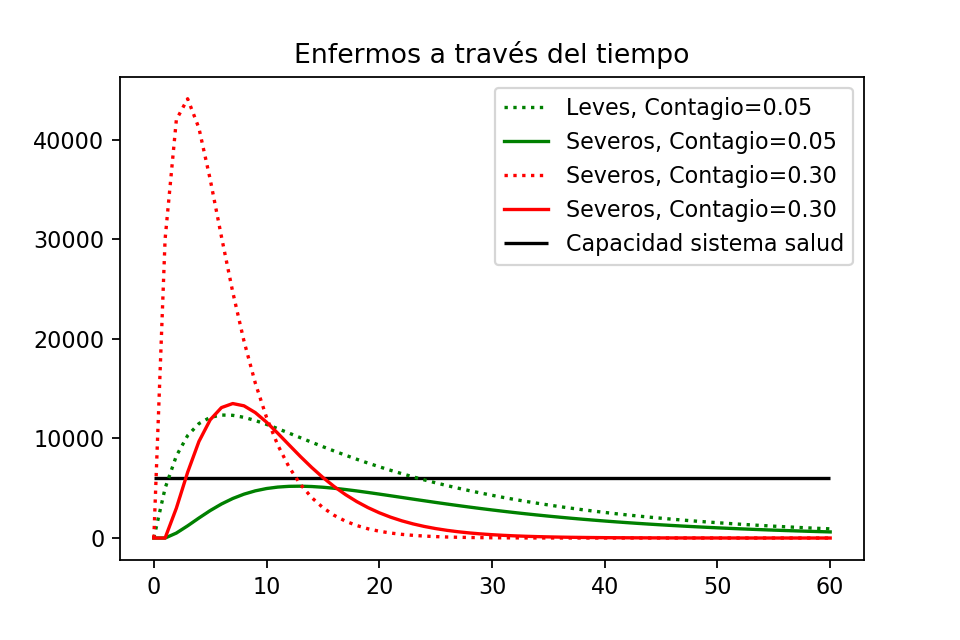
Comparación de enfermos leves y graves. Rojo es con alto contagio y verde con bajo.
Cuando la gente sí se queda en sus casas y la tasa de contagio es baja (en verde), siempre hay suficiente espacio en el sistema de salud para tratar a a los enfermos graves.
Cuando la gente no se queda en sus casas y la tasa de contagio es alta (en rojo), notemos que los casos severos sobrepasan al sistema de salud. Aproximadamente entre los días $3$ y $15$ se tienen muchos enfermos graves que no podrán ser atendidos correctamente. Por ejemplo, al día 9 hay aproximadamente $\sim 6000$ enfermos graves por encima de la capacidad del sistema de salud. Sin atención médica, probablemente en vez de que sólo fallezcan el $10\%$ de ellos (según nuestro modelo), fallecerán casi todos, dando $5400$ víctimas más que no hemos contado.
De esta forma, siguiendo los consejos de quedarse en casa, la población de Imagilandia puede salvar, potencialmente, $\sim 4350$ personas por la vacuna y $\sim 5400$ personas por evitar saturar el sistema de salud, osea, salvar unas $\sim 9750$ vidas. Para ello es necesario que las autoridades hagan el llamado a quedarse, y que la población de Imagilandia haga caso. De aquí la importancia del #QuédateEnCasa.
Más contenido
Todo el código de Python del modelo lo corrí en una libreta de Jupyter. Puedes ver una versión en PDF de todo el código a continuación.
El modelo de epidemia que presentamos es una aplicación muy sencilla de álgebra lineal. En este blog hemos estado subiendo material de un curso de álgebra lineal que se imparte en la UNAM, y que ahora estamos impartiendo a distancia por la contingencia. A continuación ponemos el enlace a este curso y a otro material que te puede interesar.
En entradas anteriores ya hablamos acerca de la idea básica del principio de inducción y también vimos cómo la inducción puede interactuar con las heurísticas de trabajar hacia atrás y de generalización. En esta entrada hablaremos de dos formas adicionales y válidas en las que se puede hacer inducción.
Inducción fuerte
El principio de inducción funciona pues es un mecanismo que pasa por los números naturales «uno por uno». Al momento en el que suponemos la hipótesis inductiva para cierto natural $n$, lo que queremos hacer para continuar es mostrar la afirmación para el natural $n+1$. Es decir, el natural $n+1$ es el primer natural para el que todavía no sabemos que la afirmación funciona. Dicho de otra forma, para todo natural $m\leq n$ ya sabemos que la afirmación sí funciona.
Aunque típicamente usemos únicamente la afirmación para el paso $n$ para demostrar la validez del paso $n+1$, en realidad podríamos usar toda la información que ya tenemos de que la inducción se vale para todo $m$ entre la base inductiva y $n$. Esta es la idea detrás del principio de inducción fuerte.
Principio de inducción fuerte. Sea $P(n)$ una afirmación (o proposición o propiedad) que depende del número natural $n$. Si
la afirmación $P(a)$ es cierta y
la veracidad de la afirmación «$P(m)$ es cierto para todo $a\leq m \leq n$» implica la veracidad de la afirmación $P(n+1)$,
entonces la afirmación $P(n)$ es cierta para toda $n \geq a$.
Veamos un ejemplo de teoría de gráficas. No entraremos en detalles de las definiciones. Aunque no conozcas mucho de teoría de gráficas, es posible que de cualquier forma las definiciones te hagan sentido.
Problema. Un árbol es una gráfica que no tiene ciclos y que es conexa. Demuestra que todo árbol de $n$ vértices tiene $n-1$ aristas.
Solución. Lo vamos a demostrar por inducción sobre el número de vértices que tiene el árbol. Si el árbol tiene $1$ vértice, entonces el resultado es cierto, pues tiene $0$ aristas.
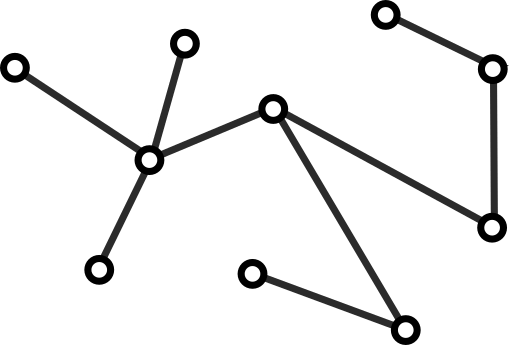
Tomemos ahora un entero $n$ y supongamos que el resultado es cierto para cuando el número de vértices es cualquier entero entre $1$ y $n$. Tomemos un árbol $T$ de $n+1$ vértices.
Árbol con $n+1$ vértices.
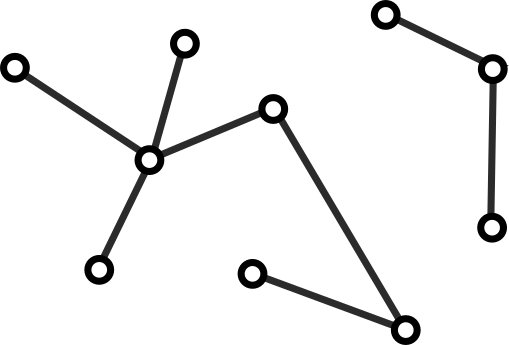
Tomemos una arista cualquiera de $T$ y quitémosla. Esto parte a $T$ en dos árboles (¡demuéstralo!) con, digamos $a$ y $b$ vértices, de modo que $a+b=n+1$.
Después de quitar la arista
Tenemos $1\leq a < n$ y $1\leq b <n$, así que cada uno de esos árboles tiene, por hipótesis inductiva, $a-1$ y $b-1$ aristas, respectivamente. Así, $T$ tiene esas aristas, y la que quitamos, es decir, $(a-1)+(b-1)+1=a+b-1=n$ aristas, como queríamos demostrar.
$\square$
Los que han estudiado teoría de gráficas quizás noten que pudimos haber evitado usar inducción fuerte si en vez de usar una arista arbitraria usábamos una que llegaba a un vértice hoja (de grado $1$). Haciendo eso se puede usar inducción «normal». La demostración anterior tiene la ventaja de no necesitar definir qué es una hoja.
Inducción de Cauchy
Hablemos ahora de otra variante. El principio de inducción es un mecanismo que nos permite probar una afirmación para los naturales «pasando por todos ellos» de una manera muy natural se prueba para el primero, luego para el siguiente, luego para el siguiente y así sucesivamente. Hay otras formas de cubrir a los números enteros.
Principio de inducción de Cauchy. Sea $P(n)$ una afirmación (o proposición o propiedad) que depende del número natural $n$. Si
la afirmación $P(1)$ es cierta,
la veracidad de la afirmación $P(n)$ implica la veracidad de la afirmación $P(2n)$ y
la veracidad de la afirmación $P(n)$ para un $n>a$ implica la veracidad de la afirmación $P(n-1)$,
entonces la afirmación $P(n)$ es cierta para toda $n \geq 1$.
Intuitivamente, lo que está pasando es que al probar $P(1)$ y la segunda afirmación, estamos probando $P(2)$, de ahí $P(4)$, de ahí $P(8)$ y en general $P(n)$ para cuando $n$ es potencia de $2$. Luego, con $P(4)$ y la tercera afirmación sale $P(3)$. Con $P(8)$ y la tercera afirmación sale $P(7), P(6),P(5)$. Esto garantiza cubrir todos los naturales pues para cualquier natural $n$ hay una potencia de dos $2^m$ mayor que él para la que sabemos que el resultado es cierto, y de ahí con la tercera afirmación «vamos bajando cubriendo todos los naturales», incluido $n$.
Como ejemplo, presentamos una demostración de la desigualdad entre la media aritmética y la media geométrica,
Problema. Sea $n$ un entero positivo y $x_1,x_2,\ldots,x_n$ números reales positivos. Demuestra que $$\frac{x_1+x_2+\ldots+x_n}{n}\geq \sqrt[n]{x_1x_2\cdots x_n}.$$
Solución. Vamos a proceder por inducción de Cauchy sobre $n$. Sea $P(n)$ la afirmación del problema.
En el caso $n=1$ tenemos sólo un real $x_1$ y tenemos que demostrar que $\frac{x_1}{1}\geq \sqrt[1]{x_1}$, lo cual es cierto pues en ambos lados tenemos $x_1$. Así, $P(1)$ es cierta.
Para el resto de la demostración, será útil que probemos también por separado el caso para dos números, es decir, $P(2)$. Pero esto es sencillo pues si tenemos reales positivos $a$ y $b$, entonces $\frac{a+b}{2}\geq \sqrt{ab}$ es equivalente a $a-2\sqrt{ab}+b\geq 0$, la cual es cierta pues el lado izquierdo es el número no negativo $(\sqrt{a}-\sqrt{b})^2$.
Ahora veremos que $P(n)$ implica $P(2n)$. Supongamos la veracidad de $P(n)$ y tomemos $2n$ números reales $x_1,x_2,\ldots,x_{2n}$. Queremos demostrar que $$\frac{x_1+\ldots+x_{2n}}{2n}\geq \sqrt[2n]{x_1\cdots x_{2n}}.$$ Llamemos $A$ al lado izquierdo y $G$ al lado derecho.
Sea $B$ la media aritmética de $x_1,\ldots, x_n$ y $C$ la de $x_{n+1},\ldots, x_{2n}$. Aplicando por separado $P(n)$ a estos números, tenemos que \begin{align*} B:=\frac{x_1+\ldots+x_n}{n}&\geq \sqrt[n]{x_1\cdots x_n}\\ C:=\frac{x_{n+1}+\ldots+x_{2n}}{n}&\geq \sqrt[n]{x_{n+1}\cdots x_{2n}}\\ \end{align*}
Notemos que $A=\frac{B+C}{2}$. Aplicando $P(2)$ a los números $B$ y $C$ tenemos que \begin{align*} A&=\frac{B+C}{2}\\ &\geq \sqrt[2]{BC} \\ &\geq \sqrt[2]{\sqrt[n]{x_1\cdots x_n} \cdot \sqrt[n]{x_{n+1}\cdots x_{2n}}}\\ & = G. \end{align*}
Es decir, $P(2n)$ es cierta.
Para terminar con la inducción de Cauchy, el último paso es suponer la veracidad de $P(n)$ para $n>1$ y con ella demostrar la veracidad de $P(n-1)$. Supongamos entonces la veracidad de $P(n)$ y tomemos $n-1$ números $x_1,\ldots, x_{n-1}$. Queremos usar la veracidad de $P(n)$, así que tenemos que «inventarnos» otro número $m$ para poder aplicar $P(n)$. Tomemos $m=\frac{x_1+\ldots+x_{n-1}}{n-1}$, es decir, la media aritmética de los números de $x_1$ hasta $x_{n-1}$.
Observemos que $$\frac{x_1+\ldots+x_{n-1}+m}{n}=m.$$ Usando la veracidad de $P(n)$ para los números $x_1,\ldots, x_{n-1},m$ tenemos que $$m=\frac{x_1+\ldots+x_{n-1}+m}{n}\geq \sqrt[n]{x_1\cdots x_{n-1}m}.$$
Dividiendo entre $\sqrt[n]{m}=m^{1/n}$ en ambos extremos de la cadena, obtenemos $$m^{\frac{n-1}{n}}\geq \sqrt[n]{x_1 \cdots x_{n-1}}.$$
Elevando ambos lados de esta desigualdad a la $n/(n-1)$ obtenemos $$m\geq \sqrt[n-1]{x_1 \cdots x_{n-1}}.$$
Esto es exactamente lo que queríamos probar. Con esto se comprueba la veracidad de $P(n-1)$ y así terminamos la inducción de Cauchy.
$\square$
La elección de $m$ en la última parte de la demostración parece un poco sacada de la manga. En realidad, sí tiene una cierta motivación. En la hipótesis $P(n)$ tenemos a la izquierda $\frac{x_1+x_2+\ldots+x_n}{n}$, pero lo que queremos es tener $\frac{x_1+x_2+\ldots+x_{n-1}}{n-1}$. Nuestra elección de $x_n=m$ vino de igualar ambas expresiones y despejar $x_n$.
Más ejemplos
Hay más ejemplos bastante elaborados del uso de estas ideas en Problem Solving Through Problems de Loren Larson, Secciones 2.1, 2.2, 2.3 y 2.4. Otro libro con muchos ejemplos interesantes es el Putnam and Beyond, de Gelca y Andreescu. También hay otros ejemplos de inducción en las siguientes entradas: