(Trabajo de titulación asesorado por la Dra. Diana Avella Alaminos)
INTRODUCCIÓN
Analizaremos cuatro nuevos conceptos. Dos de ellos son conjuntos y los otros dos son las dimensiones de esos conjuntos.
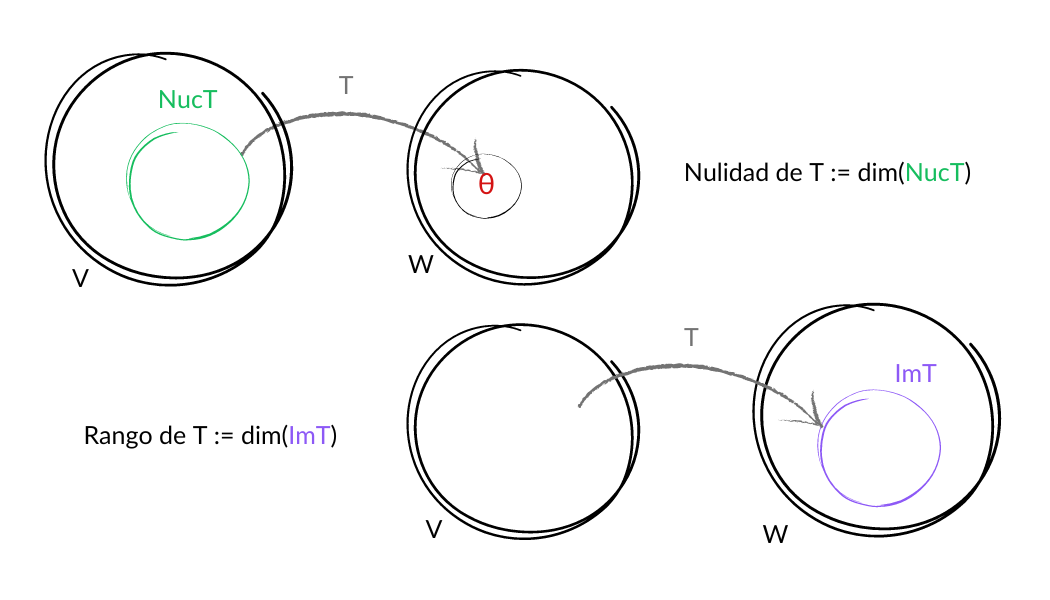
Representación gráfica del núcleo y la imagen de una transformación lineal $T$.
Al ir avanzando en el análisis del primer concepto que estudiaremos en esta entrada, el núcleo de una transformación lineal, podrás ver que una de las aplicaciones inmediatas es pensar al núcleo como el conjunto formado por las soluciones de un sistema de ecuaciones lineales homogéneo de alguna forma a la transformación lineal. Pero todo con calma…
NÚCLEO E IMAGEN DE UNA TRANSFORMACIÓN LINEAL
Definición: Sean $V$ y $W$ $K$ – espacios vectoriales y $T\in\mathcal{L}(V,W)$. El núcleo de $T$ es $Núc\,T=\{v\in V|T(v)=\theta_W\}$. La imagen de $T$ es $Im\, T=\{T(v)|v\in V\}$.
Nota: El núcleo de una transformación $T$, también suele llamarse kernel y denotarse como $ker\,T$.
Sean $K$ un campo y $T:K^\infty\longrightarrow K^\infty$ lineal donde $\forall (x_1,x_2,x_3,…)\in K^\infty (T(x_1,x_2,x_3,…)=(x_2,x_3,x_4,…))$. $Núc\,T=\{(x_1,0_K,0_K,…)\in K^\infty | x_1\in K\}$ ; $Im\,T=K^\infty$
Justificación. Para el núcleo de $T$:
\begin{align*} T(x_1,x_2,x_3,…)=(0_K,0_K,0_K,…) \\ \Leftrightarrow (x_2,x_3,x_4,…)=(0_K,0_K,0_K,…) \\ \Leftrightarrow x_i=0_K \text{ para toda }i\in\{2,3,4,…\}. \end{align*}
Para la imagen de $T$:
Sea $(y_1,y_2,y_3,…)\in K^\infty$. Tenemos que $T(0_K,y_1,y_2,…)=(y_1,y_2,y_3,…)$, por lo cual $T$ es suprayectiva y su imagen es todo el codominio.
Sea $T:\mathbb{R}^2\longrightarrow\mathbb{R}^2$ donde $\forall (x,y)\in\mathbb{R}^2(T(x,y)=(x,0))$ $Núc\,T=\{(0,y)\in\mathbb{R}^2|y\in\mathbb{R}\}$ ; $Im\,T=\{(x,0)\mathbb{R}^2|x\in\mathbb{R}\}$
Sea $(a,0)\in \{ (x,0)\in\mathbb{R}^2|x\in\mathbb{R}^2\}$. Dado que $T(a,0)=(a,0)$ se tiene que $(a,0)\in Im\,T$.
A la inversa, si $(a,b)\in Im\, T$ se tiene que $T(x,y)=(a,b)$ para alguna $(x,y)\in \mathbb{R}^2$, por lo que $(x,0)=(a,b)$ y así $b=0$.
Sean $K$ un campo, $A\in\mathcal{M}_{m\times n}(K)$ y $T:K^n\longrightarrow K^m$ donde $\forall X\in K^n(T(X)=AX)$ $Núc\,T$ es el conjunto de las soluciones del sistema homogéneo con matriz de coeficientes $A$ ; $Im\,T$ es el espacio generado por las columnas de $A$
Justificación. Para el núcleo de $T$:
$T(X)=\theta_{m\times 1}\Leftrightarrow AX=\theta_{m\times 1}$ $\Leftrightarrow X$ es solución del sistema homogéneo con matriz de coeficientes $A$.
Proposición (2.2.1.): Sean $V,W$ $K$ – espacios vectoriales, $T\in\mathcal{L}(V,W)$. Se cumple que:
a) $Núc\,T\leqslant V$. b) $Im\,T\leqslant W$.
Demostración: Para cada inciso es necesario demostrar dos propiedades:
a) P.D. $\theta_V\in Núc\,T$ y $\forall\lambda\in K$ $\forall u,v\in Núc\,T (\lambda u + v\in Núc\,T)$
Como $T$ es una transformación lineal tenemos que $T(\theta_V)=\theta_W$, por lo tanto, $\theta_V\in Núc\,T.$
Sean $\lambda\in K$ y $u,v\in Núc\,T$. Entonces $T(u)=\theta_W=T(v).$ Además, $T(\lambda u+v)=\lambda T(u)+T(v)$ por ser $T$ lineal. Así, $$T(\lambda u+v)=\lambda\theta_W +\theta_W=\theta_W$$ de donde $\lambda u + v\in Núc\,T.$
b) P.D. $\theta_W\in Im\,T$ y $\forall\lambda\in K$ $\forall w,z\in Im\,T (\lambda u + v\in Im\,T)$
Como $T$ es una transformación lineal tenemos que $\theta_V\in V$ cumple que $T(\theta_V)=\theta_W$, por lo tanto, $\theta_W\in Im\,T$.
Sean $\lambda\in K$ y $w,z\in Im\,T$. Entonces $\exists u,v\in V (T(u)=w\wedge T(v)=z)$. Además, $T(\lambda u+v)=\lambda T(u)+T(v)$ por ser $T$ lineal. Así, $$T(\lambda u+v)=\lambda w+z$$ de donde $\lambda w+ z\in Im\,T.$
NULIDAD Y RANGO DE UNA TRANSFORMACIÓN LINEAL
Definición: Sea $T$ una transformación lineal con $Núc \,T$ de dimensión finita. Decimos que la dimensión de $Núc\,T$ es la nulidad de $T$.
Definición: Sea $T$ una transformación lineal con $Im \,T$ de dimensión finita. Decimos que la dimensión de $Im\,T$ es el rango de $T$.
Ejemplo
Sea $K=\mathbb{R}$ y sean $V=\mathcal{P}_3$ y $W=\mathcal{P}_2$ $K$ – espacios vectoriales. Sea $T:V\longrightarrow W$ donde $\forall p(x)\in T(p(x))=p'(x)$. La nulidad de $T$ es $1$ y su rango es $3$
Justificación. Los polinomios con derivada cero son únicamente las constantes. Así, $Núc(T)=\{a|a\in\mathbb{R}\}$ que tiene dimensión $1$.
Por otro lado todo polinomio de grado $2$ se puede obtener derivando un polinomio de grado $3$. Basta con integrar el polinomio de grado $2$ para encontrar cómo son los polinomios de grado $3$ que cumplen lo deseado. De modo que $W\subseteq Im(T)$ y como $Im(T)\subseteq W$ por definición, entonces $Im(T)=W$ que tiene dimensión $3$.
Por lo tanto, el núcleo y la imagen son de dimensión finita y la nulidad de $T$ es $1$ y su rango es $3.$
Tarea Moral
Sean $K$ un campo, $V$ y $W$ $K$-espacios vectoriales y $T:V\longrightarrow W$ lineal. Sea $\{ w_1, w_2, …, w_k\}$ un subconjunto l.i. de $Im\,T$. Si $S=\{ v_1,v_2,…,v_k \}$ se selecciona de tal forma que $\forall i\in \{ 1,2,…,k\}(T(v_i)=w_i)$, demuestra que $S$ es l.i.
Para la transformación lineal $T:\mathbb{R}^3\longrightarrow \mathbb{R}^2$ con $T(a_1,a_2,a_3)=(a_1 + 2a_2, 2a_3 – a_1)$ encuentra bases para $Núc(T)$ e $Im(T)$.
Sean $K$ un campo y $P: \mathcal{M}_{m\times m}(K) \longrightarrow \mathcal{M}_{m\times m}(K)$ definida por $\forall A\in \mathcal{M}_{m\times m}(K) \left( P(A)=\frac{A + A^{t}}{2} \right)$. Verifica que $T$ es lineal y encuentra su núcleo e imagen.
Más adelante…
En la siguiente entrada veremos el vínculo que existe entre la dimensión del núcleo, de la imagen y del espacio vectorial que aparece como dominio de una transformación lineal. Esta relación numérica nos permite calcular cualquiera de estas dimensiones si tenemos conocimiento de las otras dos.
(Trabajo de titulación asesorado por la Dra. Diana Avella Alaminos)
INTRODUCCIÓN
¿Por qué el uso de la palabra «transformación»? Como veremos, una transformación lineal es una función que va de un espacio lineal a otro espacio lineal. Y toda función, básica e informalmente, transforma un elemento del dominio en uno del rango.
Al igual que en una máquina se introducen los ingredientes o materiales y son transformados para obtener un resultado final, en una función se introduce un elemento del dominio y se transforma mediante la regla de correspondencia en uno del rango
Ahora bien, no es una función «cualquiera». Y aunque sólo son dos condiciones las que se piden, estas transformaciones de un espacio vectorial en sí mismo o en otro espacio vectorial tienen un comportamiento que permite aplicaciones muy útiles tanto en matemáticas, como en física, ingenierías e incluso arte digital. Sus propiedades gracias a esas dos condiciones hacen de este tipo de funciones sea un punto esencial del Álgebra lineal.
TRANSFORMACIÓN LINEAL
Definición: Sean $V$ y $W$ $K$ – espacios vectoriales. Una función $T:V\longrightarrow W$ es una transformación lineal de $V$ en $W$ si: $1)$ $\forall u,v\in V(T(u+v)=T(u)+T(v))$ $2)$ $\forall \lambda\in K(\forall v\in V(T(\lambda v)=\lambda T(v)))$
Nota: Al conjunto de las transformaciones lineales de $V$ a $W$ se le denota como $\mathcal{L}(V,W)$. Cuando una función cumple la condición $1)$ diremos que abre sumas, y si cumple la condición $2)$ diremos que saca escalares.
Observación: Si $T$ abre sumas, entonces manda al neutro de $V$ en el neutro de $W$, pues $\theta_W+T(\theta_V)=T(\theta_V)=T(\theta_V+\theta_V)=T(\theta_V)+T(\theta_V)$ $\Rightarrow\theta_W+T(\theta_V)=T(\theta_V)+T(\theta_V)$ $\Rightarrow\theta_W=T(\theta_V)$ En otras palabras, las transformaciones lineales envían el neutro del dominio en el neutro del codominio.
Ejemplos
Sea $V$ un $K$ – espacio vectorial. $T:V\longrightarrow V$ donde $\forall v\in V(T(v)=\theta_V)$ es una transformación lineal de $V$ en $V$
Proposición (2.1.1.): Sean $V,W$ $K$ – espacios vectoriales, $T:V\longrightarrow W$. $T$ es lineal si y sólo si $\forall\lambda\in K , \forall u,v\in V$ $(T(\lambda u+v)=\lambda T(u)+T(v))$
$T:\mathbb{R}^3\longrightarrow\mathbb{R}^2$ donde $\forall (x,y,z)\in\mathbb{R}^3(T(x,y,z)=(x+y+z,2x-7y))$ es una transformación lineal de $\mathbb{R}^3$ en $\mathbb{R}^3$.
Justificación. Sean $(x,y,z),(u,v,w)\in\mathbb{R}^3$ y $\lambda\in\mathbb{R}$.
$T(\lambda(x,y,z)+(u,v,w))=T((\lambda x,\lambda y,\lambda z)+(u,v,w))$$=T(\lambda x + u,\lambda y + v,\lambda z + w)$$=(\lambda x + u+\lambda y + v+\lambda z + w,2(\lambda x + u)-7(\lambda y + v))$$=(\lambda(x+y+z)+u+v+w,2\lambda x-7\lambda y+2u-7v)$$=\lambda (x+y+z,2x-7y)+(u+v+w,2u-7v)$$=\lambda T(x,y,z)+T(u,v,w)$
Sea $K$ un campo. Si $A\in\mathcal{M}_{m\times n}(K)$, entonces $T:K^n\longrightarrow K^m$ donde $\forall X\in K^n(T(X)=AX)$ es una transformación lineal de $K^n$ en $K^m$.
Sean $V$ y $W$ espacios vectoriales sobre un campo $F$. Sea $T: V \longrightarrow W$ una transformación lineal. Demuestra que para todo $v_1,v_2,…,v_n\in V$ y para todo $\lambda_1, \lambda_2,…,\lambda_n\in F$ con $n\in\mathbb{N}^{+}$ se tiene que $T(\lambda_1 v_1 + \lambda_2 v_2 + … + \lambda_n v_n) = \lambda_1 T(v_1) + \lambda_2 T(v_2) + … + \lambda_n T(v_n)$.
Sea $T:\mathbb{R}^2 \longrightarrow \mathbb{R}^2$ una transformación lineal tal que $T(1,0)=(2,4)$ y $T(1,1)=(8,5)$. Determina si es posible hallar la regla de correspondencia de $T$, es decir, $T(x,y)$ para todo $(x,y)\in\mathbb{R}^2$. Si no es posible argumenta por qué y si es posible encuéntrala.
¿Existe una transformación lineal $T:\mathbb{R}^3\longrightarrow \mathbb{R}^2$ tal que $T(1,2,4)=(1,2)$ y $T(-2,-4,-8)=(-2,1)$?
Más adelante…
Veremos ahora cuatro elementos que surgen de una transformación lineal: Núcleo e imagen, que son dos conjuntos relevantes para dominio y codominio. Nulidad y rango, que son dos números que nos revelan dimensiones. Comenzaremos por definir el núcleo y la imagen de una transformación lineal y probando que son subespacios vectoriales.
En la entrada anterior empezamos a hablar del teorema de la función inversa. Dimos su enunciado y probamos varias herramientas que nos ayudarán ahora con su demostración.
Recordemos que lo que queremos demostrar es lo siguiente.
Teorema (de la función inversa). Sea $f:S\subseteq \mathbb{R}^{n}\rightarrow \mathbb{R}^{n}$ de clase $C^{1}$ en el abierto $S$. Si $Df(\bar{a})$ es invertible, entonces, existe $\delta >0$ tal que:
$B_{\delta}(\bar{a})\subseteq S$ y $f$ es inyectiva en $B_{\delta}(\bar{a})$.
$f^{-1}:f(B_{\delta}(\bar{a}))\subseteq \mathbb{R}^{n}\rightarrow \mathbb{R}^{n}$ es continua en $f(B_{\delta}(\bar{a}))$.
$f(B_{\delta}(\bar{a}))\subseteq \mathbb{R}^{n}$ es un conjunto abierto.
$f^{-1}$ es de clase $C^{1}$ en $f(B_{\delta}(\bar{a}))$ y además, si $\bar{x}=f(\bar{v})\in f(B_{\delta}(\bar{a}))$, entonces, $Df^{-1}(\bar{x})=Df^{-1}(f(\bar{v}))=(Df(\bar{v}))^{-1}$.
La herramienta más importante que probamos en la entrada anterior nos dice que si una función $f:S\subseteq \mathbb{R}^n\to \mathbb{R}^n$ es de clase $C^1$, $\bar{a}\in S$ y $DF(\bar{a})$ es invertible, entonces existe una $\delta>0$ tal que $B_\delta(\bar{a})\subseteq S$ y $Df(\bar{b})$ es invertible para todo $\bar{b}\in B_\delta(\bar{a})$. Veremos cómo esta herramienta y otras que desarrollaremos en el transcurso de esta entrada nos permiten demostrar el teorema.
La función $f$ es inyectiva en una vecindad de $\bar{a}$
Vamos a enfocarnos en el punto $(1)$ del teorema. Veremos que existe la $\delta$ que hace que la función restringida a la bola de radio $\delta$ centrada en $\bar{a}$ es inyectiva. En esta parte de la prueba es conveniente que recuerdes que la norma infinito de un vector $(x_1,\ldots,x_n)\in \mathbb{R}^n$ es $$||\bar{x}||_{\infty}:=máx\{ |x_{1}|,\dots ,|x_{n}|\}.$$
Además, cumple para todo $\bar{x}\in \mathbb{R}^{n}$ que $$||\bar{x}||\leq \sqrt{n} ||\bar{x}||_{\infty}.$$
Veamos que bajo las hipótesis del problema se puede acotar $||f(\bar{u})-f(\bar{v})||$ en términos de $||\bar{u}-\bar{v}||$ dentro de cierta bola.
Proposición. Sea $f:S\subseteq \mathbb{R}^{n}\rightarrow \mathbb{R}^{n}$ de clase $C^{1}$ en el conjunto abierto $S$, y $\bar{a}\in S$. Si $Df(\bar{a})$ es invertible, entonces existe $\delta >0$ y $\varepsilon>0$ tal que $B_{\delta}(\bar{a})\subseteq S$ y $||f(\bar{u})-f(\bar{v})||\geq \varepsilon||\bar{u}-\bar{v}||$ para cualesquiera $\bar{u},\bar{v}\in B_{\delta}(\bar{a})$.
Demostración. Por la diferenciabilidad de $f$ en $\bar{a}$, tenemos
para cada $\bar{a}\in S$ y cada $\bar{x}\in \mathbb{R}^{n}$.
Como $Df(\bar{a})$ es invertible, por los resultados de la entrada anterior existe un $m>0$ tal que
\[ ||Df(\bar{a})(\bar{x})||\geq m||\bar{x}|| \]
para todo $\bar{x}\in \mathbb{R}^{n}$.
También por resultados de la entrada anterior, para $\epsilon:=\frac{m}{2\sqrt{n}}>0$ existe $\delta >0$ tal que si $\bar{b}\in B_{\delta}(\bar{a})\subseteq S$ entonces
Usaremos en un momento estas desigualdades, pero por ahora fijemos nuestra atención en lo siguiente. Dados $\bar{u},\bar{v}\in B_{\delta}(\bar{a})$, tomemos el $k\in \{1,\dots ,n\}$ tal que $$||Df(\bar{a})(\bar{u}-\bar{v})||_{\infty}=|\triangledown f_{k}(\bar{a})\cdot (\bar{u}-\bar{v})|.$$
¿Cómo podemos seguir con nuestras desigualdades? Necesitamos usar el teorema del valor medio. Bastará el que demostramos para campos escalares. Aplicándolo a $f_k$ en los puntos $\bar{u},\bar{v}$ cuyo segmento se queda en la bola convexa $B_\delta(\bar{a})$, podemos concluir que existe un vector $\bar{w}$ en el segmento $\bar{\bar{u}\bar{v}}$ que cumple
Sabemos que para cualquier vector el valor absoluto de cualquiera de sus coordenadas es en valor menor o igual que la norma del vector. Además, demostramos inicialmente unas desigualdades anteriores. Juntando esto, obtenemos la siguiente cadena de desigualdades:
La gran conclusión de esta cadena de desigualdades es que $$||f(\bar{u})-f(\bar{v})||\geq \varepsilon||\bar{u}-\bar{v}||,$$ que es lo que buscábamos.
$\square$
¡Esto es justo lo que nos pide el primer punto! Hemos encontrado una bola alrededor de $\bar{a}$ dentro de la cual si $\bar{u}\neq \bar{v}$, entonces $||f(\bar{u})-f(\bar{v})||\geq \varepsilon ||\bar{u}-\bar{v}||>0$, de modo que $f(\bar{u})\neq f(\bar{v})$. ¡La función restringida en esta bola es invertible! En términos geométricos el último teorema nos dice lo siguiente: Si $f$ es diferenciable en un abierto $S$, y $Df(\bar{a})$ es invertible, entonces hay una vecindad alrededor de $\bar{a}$ en donde $f$ «no se pega», es decir $f$ es inyectiva.
Figura 1: Si la función no es inyectiva, lo que tenemos es que proyecta el rectángulo $\mathcal{R}$ en una superficie que pega los puntos $\bar{a}$ y $\bar{b}$. Arriba una función inyectiva y abajo una que no lo es.
Ya vimos cómo encontrar una bola $B_\delta(\bar{a})$ dentro de la cual $f$ es inyectiva. Si pensamos que el contradominio es exactamente $f(B_\delta(\bar{a}))$, entonces la función también es suprayectiva. Esto hace que sea biyectiva y por tanto que tenga inversa $f^{-1}$.
La función inversa es continua
Veamos ahora que la función inversa es continua. De hecho, mostraremos algo un poco más fuerte.
Teorema. Sea $f:S\subseteq \mathbb{R}^{n}\rightarrow \mathbb{R}^{n}$ de clase $C^{1}$ en el abierto $S$, y $\bar{a}\in S$. Si $Df(\bar{a})$ es invertible, entonces existe $\delta >0$ tal que $B_{\delta}(\bar{a})\subseteq S$, $f$ es inyectiva en $B_{\delta}(\bar{a})$ y además $f^{-1}:f(B_{\delta}(\bar{a}))\subseteq \mathbb{R}^{n}\rightarrow \mathbb{R}^{n}$ es uniformemente continua en su dominio.
Demostración. La primera parte y la existencia de $f^{-1}:f(B_\delta(a))\subseteq \mathbb{R}^n \to \mathbb{R}^n$ se debe a la discusión de la sección anterior. De hecho, lo que mostramos es que existe $\delta >0$ y $\varepsilon>0$ tal que $||f(\bar{v})-f(\bar{u})||\geq \varepsilon||\bar{v}-\bar{u}||$ para todo $\bar{u},\bar{v}\in B_{\delta}(\bar{a})$.
Supongamos que nos dan un $\varepsilon^\ast$. Tomemos $\delta^\ast=\varepsilon^\ast \varepsilon$. Tomemos $\bar{x},\bar{y}$ en $f(B_\delta(\bar{a}))$ tales que $||\bar{y}-\bar{x}||<\delta ^{\ast}$. Como $\bar{x}$ y $\bar{y}$ están en dicha bola, podemos escribirlos como $\bar{x}=f(\bar{u})$, $\bar{y}=f(\bar{v})$ con $\bar{u},\bar{v}\in B_{\delta}(\bar{a})$. Notemos entonces que
Tenemos entonces que $f^{-1}$ es uniformemente continua en $f(B_\delta(\bar{a}))$.
$\square$
Esto demuestra el punto $(2)$ de nuestro teorema. La prueba de que el conjunto $f(B_\delta(\bar{a}))$ es abierto no es para nada sencilla como parecería ser. Una demostración muy instructiva, al nivel de este curso, se puede encontrar en el libro Cálculo diferencial de varias variables del Dr. Javier Páez Cárdenas editado por la Facultad de Ciencias de la Universidad Nacional Autónoma de México (UNAM) en las páginas 474-476.
La función inversa es diferenciable
Resta hacer la demostración de $(4)$. En esta sección veremos que la inversa $f^{-1}$ es derivable y que la derivada es precisamente lo que propone el teorema. En la siguiente sección veremos que la inversa es $C^1$.
Tomemos un punto $\bar{x}_0=f(\bar{v}_0)\in f(B_{\delta}(\bar{a}))$. Mostraremos que, en efecto, $T=(Df(\bar{v}_0))^{-1}$ es la derivada de $f^{-1}$ en $\bar{x}_0$, lo cual haremos por definición verificando que
Esta función está bien definida, pues $f$ es inyectiva en la bola $B_{\delta}(\bar{a})$. La composición $g\circ f^{-1}$ también está bien definida en el abierto $f(B_{\delta}(\bar{a}))$ y
El factor que nos falta entender es $\frac{||\bar{v}-\bar{v}_{0}||}{||f(\bar{v})-f(\bar{v}_{0})||}$. Pero por la primera proposición de esta entrada, sabemos que existe una $\epsilon>0$ que acota este factor superiormente por $\frac{1}{\epsilon}$. De esta manera,
Resta verificar que $f^{-1}$ es de clase $C^{1}$ en $f(B_{\delta}(\bar{a}))$. Lo haremos con la caracterización de la entrada anterior. Tomemos una $\mu>0$. Nos gustaría ver que si $\bar{x}$ y $\bar{x}_0$ están suficientemente cerca, entonces
Tomando $X=Df(\bar{v})$ y $Y=Df(\bar{v}_0)$, aplicando la igualdad anterior en un punto $\bar{x}$ en $\mathbb{R}^n$, sacando normas y usando la desigualdad \eqref{eq:clasec1}, obtenemos:
Como $f$ es de clase $C^1$, por la entrada anterior podemos construir una $\delta^\ast$ tal que $B_{\delta^\ast}(\bar{v}_0)\subseteq B_\delta(\bar{a})$ y para la cual si $\bar{v}$ está en $B_{\delta^\ast}(\bar{v}_0)$, entonces:
Finalmente, como $f^{-1}$ es continua en $f(B_{\delta}(\bar{a}))$, si $\bar{x}$ y $\bar{x}_0$ están suficientemente cerca, digamos $||\bar{x}-\bar{x}_0||<\nu$, entonces
Esto implica que $f^{-1}$ es de clase $C^1$. Como tarea moral, revisa los detalles y di explícitamente qué resultado de la entrada anterior estamos usando.
$\square$
Ejemplo del teorema de la función inversa
Ejemplo. Consideremos $\xi :\mathbb{R}^{3}\rightarrow \mathbb{R}^{3}$ dada por $\xi (r,\theta, \phi)=(r\hspace{0.15cm}sen \phi \hspace{0.15cm}cos\theta ,r\hspace{0.15cm} sen \phi \hspace{0.15cm}sen\theta ,r\hspace{0.15cm}cos \phi)$. Se tiene que $\xi$ es diferenciable en todo su dominio pues cada una de sus derivadas parciales es continua. Esta es la función de cambio de coordenadas de esféricas a rectangulares o cartesianas. La matriz jacobiana está dada como sigue.
Luego $\det(D\xi (r,\theta ,\phi ))=-r^{2}\hspace{0.1cm}sen\phi$ entonces $D\xi$ es invertible cuando $r\neq 0$ y $\phi \neq k\pi$, $k\in \mathbb{Z}$. Su inversa es:
El teorema de la función inversa nos garantiza la existencia local de una función $\xi ^{-1}$. En este caso, sería la función de cambio de coordenadas rectangulares a esféricas. Si $f:S\subseteq \mathbb{R}^{3}\rightarrow \mathbb{R}$ es una función $C^{1}$ dada en coordenadas esféricas; podemos asumir que $f\circ \xi ^{-1}$ es la misma función pero en términos de coordenadas rectangulares.
$\triangle$
Más adelante…
¡Lo logramos! Hemos demostrado el teorema de la función inversa, uno de los resultados cruciales de nuestro curso. El siguiente tema es el teorema de la función implícita, que será otro de nuestros resultados principales. Uno podría pensar que nuevamente tendremos que hacer una demostración larga y detallada. Pero afortunadamente la demostración del teorema de la función implícita se apoya fuertemente en el teorema de la función inversa que ya demostramos. En la siguiente entrada enunciaremos y demostraremos nuestro nuevo resultado y una entrada más adelante veremos varios ejemplos para profundizar en su entendimiento.
Tarea moral
En el ejemplo que dimos, verifica que el determinante en efecto es $-r^2\sin\phi$. Verifica también que la inversa es la matriz dada.
Repasa cada una de las demostraciones de esta entrada y asegúrate de entender por qué se siguen cada una de las desigualdades. Explica en qué momentos estamos usando resultados de la entrada anterior.
Da la función inversa de la transformación de cambio de coordenadas polares a rectangulares $g(r,\theta)=(r\hspace{0.1cm}cos\theta , r\hspace{0.1cm}sen\theta )$.
Demuestra que para todo $\bar{x}\in \mathbb{R}^{n}$ se tiene $||\bar{x}||\leq \sqrt{n}||\bar{x}||_{\infty}.$
Verifica que en efecto $||\cdot||_{\infty}$ es una norma.
Estamos a punto de entrar a discutir dos de los resultados principales de nuestro curso: el teorema de la función inversa y el teorema de la función implícita. Repasemos un poco qué hemos hecho hasta ahora. En las dos entradas anteriores introdujimos la noción de diferenciabilidad, la cual cuando sucede para una función $f:\mathbb{R}^n\to \mathbb{R}^m$, nos dice que $f$ se parece mucho a una función lineal en un punto dado. Vimos que esta noción implica continuidad y que tiene una regla de la cadena relacionada con el producto de matrices. También, hemos discutido cómo esta noción se relaciona con la existencia de espacios tangentes a gráficas multidimensionales.
Ahora queremos entender todavía mejor a las funciones diferenciables. Hay dos teoremas que nos permiten hacer eso. Uno es el teorema de la función inversa y el otro es el teorema de la función implícita. En esta entrada hablaremos del primero, y en un par de entradas más introduciremos el segundo resultado. El propósito del teorema de la función inversa es dar una condición bajo la cual una función es invertible, por lo menos localmente. De hecho, la mayoría de las veces sólo se puede garantizar la invertibilidad localmente, pues las funciones usualmente no son inyectivas y esto da comportamientos globales más difíciles de manejar.
Enunciar el teorema y entenderlo requiere de cierto esfuerzo. Y demostrarlo todavía más. Por esta razón, en esta entrada nos enfocaremos sólo en dar el teorema y presentar herramientas preliminares que necesitaremos para hacer su demostración.
Enunciado del teorema de la función inversa
Supongamos que tenemos $f:\mathbb{R}^n\to \mathbb{R}^n$ y que es diferenciable en el punto $\bar{a}$. Entonces, $f$ se parece mucho a una función lineal en $\bar{a}$, más o menos $f(\bar{x})\approx f(\bar{a}) + T_{\bar{a}}(\bar{x}-\bar{a})$. Así, si $T_{\bar{a}}$ es invertible, suena a que «cerquita de $\bar{a}$» la función $f(\bar{x})$ debe de ser invertible. El teorema de la función inversa pone estas ideas de manera formal.
Teorema (de la función inversa). Sea $f:S\subseteq \mathbb{R}^{n}\rightarrow \mathbb{R}^{n}$ de clase $C^{1}$ en el abierto $S$. Si la matriz $Df(\bar{a})$ es invertible, entonces, existe $\delta >0$ tal que:
$B_{\delta}(\bar{a})\subseteq S$ y $f$ es inyectiva en $B_{\delta}(\bar{a})$.
$f^{-1}:f(B_{\delta}(\bar{a}))\subseteq \mathbb{R}^{n}\rightarrow \mathbb{R}^{n}$ es continua en $f(B_{\delta}(\bar{a}))$.
$f(B_{\delta}(\bar{a}))\subseteq \mathbb{R}^{n}$ es un conjunto abierto.
$f^{-1}$ es de clase $C^{1}$ en $f(B_{\delta}(\bar{a}))$ y además, si $\bar{x}=f(\bar{v})\in f(B_{\delta}(\bar{a}))$, entonces, $Df^{-1}(\bar{x})=Df^{-1}(f(\bar{v}))=(Df(\bar{v}))^{-1}$.
Veamos qué nos dice de manera intuitiva cada una de las conclusiones del teorema.
Tendremos una bola $B_\delta(\bar{a})$ dentro de la cual $f$ será inyectiva, y por lo tanto será biyectiva hacia su imagen. Así, $f$ restringida a esta bola será invertible. Es importante que sea una bola abierta, porque entonces sí tenemos toda una región «gordita» en donde pasa la invertibilidad (piensa que si fuera un cerrado, a lo mejor sólo es el punto $\bar{a}$ y esto no tiene chiste).
La inversa $f^{-1}$ que existirá para $f$ será continua. Esto es lo mínimo que podríamos esperar, aunque de hecho el punto $4$ garantiza algo mucho mejor.
La imagen de $f$ en la bola $B_\delta(\bar{a})$ será un conjunto abierto.
Más aún, se tendrá que $f^{-1}$ será de clase $C^1$ y se podrá dar de manera explícita a su derivada en términos de la derivada de $f$ con una regla muy sencilla: simplemente la matriz que funciona para derivar $f$ le sacamos su inversa como matriz y esa funciona al evaluarla en el punto apropiado.
El teorema de la función inversa es profundo pues tanto su enunciado como su demostración combina ideas de topología, álgebra y cálculo. Por esta razón, para su demostración necesitaremos recopilar varias de las herramientas de álgebra lineal que hemos repasado en la Unidad 2 y la Unidad 5. Así mismo, necesitaremos ideas topológicas de las que hemos visto en la Unidad 3. Con ellas desarrollaremos algunos resultados auxiliares que en la siguiente entrada nos permitirán concluir la demostración.
Un criterio para campos vectoriales $C^1$
El teorema de la función inversa es para funciones de clase $C^1$. Nos conviene entender esta noción mejor. Cuando una función $f$ es de clase $C^1$, entonces es diferenciable. Pero el regreso no es cierto y hay contraejemplos. ¿Qué le falta a una función diferenciable para ser de clase $C^1$? A grandes rasgos, que las funciones derivadas $T_\bar{a}$ y $T_\bar{b}$ hagan casi lo mismo cuando $\bar{a}$ y $\bar{b}$ son cercanos. En términos de matrices, necesitaremos que la expresión $||(Df(\bar{a})-Df(\bar{b}))(\bar{x})||$ sea pequeña cuando $\bar{a}$ y $\bar{b}$ son cercanos entre sí.
El siguiente teorema será importante en nuestro camino hacia el teorema de la función inversa. Intuitivamente, para lo que lo usaremos es para aproximar una función $f$ localmente, con «cuadritos» que corresponden a los planos tangentes, porque «muy cerquita» estos planos varían muy poco si pedimos que $f$ sea de clase $C^1$. Es decir si $\bar{a}$ y $\bar{b}$ son dos puntos en el dominio de una función diferenciable, y estos están muy cerca uno del otro, sus planos tangentes serán casi el mismo. Esto nos invita a cambiar localmente a una superficie por cuadritos como más adelante se explicará con detalle.
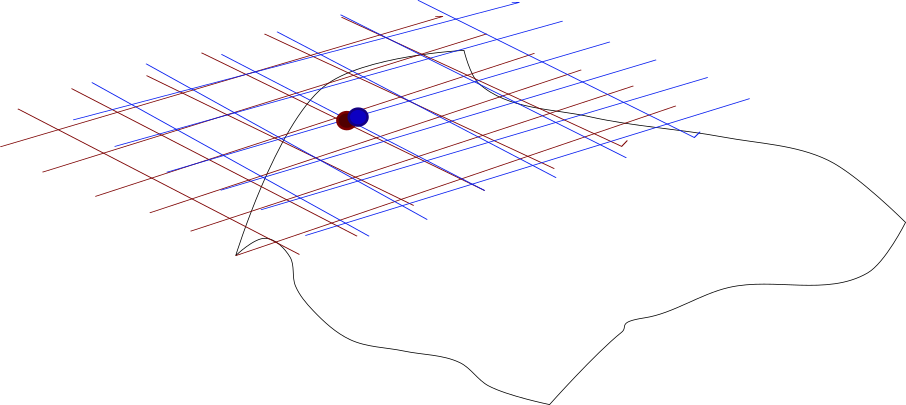
Figura 1. En azul y en rojo dos planos que corresponden a las derivadas $T_{\bar{a}}$ y $T_{\bar{b}}$. Este cambio calculado es distintos puntos cercanos es «suave», esto se expresará con la ecuación $||Df(\bar{b})(\bar{x})-Df(\bar{a})(\bar{x})||\leq \epsilon ||\bar{x}||$ ya con las diferenciales para todo $\bar{x}$.
El teorema concreto que nos interesa demostrar es la siguiente equivalencia para que una función sea de clase $C^1$.
Teorema. Sea $f:S\subseteq \mathbb{R}^{n}\rightarrow \mathbb{R}^{m}$ una función diferenciable en $S$. Se tiene que $f$ es de clase $C^{1}$ en $S$ si y sólo si para todo $\bar{a}\in S$ y para cada $\varepsilon >0$ existe $\delta >0$ tal que $B_{\delta}(\bar{a})\subseteq S$, y si $\bar{b}\in B_{\delta}(\bar{a})$ se tiene $||(Df(\bar{b})-Df(\bar{a}))(\bar{x})||\leq \varepsilon ||\bar{x}||$ para todo $\bar{x}\in \mathbb{R}^{n}$.
Demostración. $\Rightarrow).$ Supongamos que $f$ es de clase $C^1$ en $S$, es decir, todas sus funciones componentes tienen derivadas parciales en $S$ y son continuas. Sea $\varepsilon>0$. Veremos que se puede encontrar una $\delta$ como en el enunciado.
Tomemos $\bar{a}$ y $\bar{b}$ en $S$. Expresamos a $(Df(\bar{b})-Df(\bar{a}))(\bar{x})$ como
En este punto se ve la importancia de que las parciales sean continuas. Podemos encontrar una $\delta$ que nos garantice que $B_\delta\subseteq S$ y que si $||\bar{b}-\bar{a}||<\delta$, entonces $$\left| \frac{\partial f_{i}}{\partial x_{j}}(\bar{b})-\frac{\partial f_{i}}{\partial x_{j}}(\bar{a}) \right| < \frac{\varepsilon}{\sqrt{mn}}.$$ En esta situación, podemos seguir acotando $||(Df(\bar{b})-Df(\bar{a}))(\bar{x})||^2$ como sigue: \begin{align*} &\leq ||\bar{x}|| \sum_{i=1}^m \sum_{j=1}^{n}\frac{\varepsilon^2}{mn}\\ &=\varepsilon^2||\bar{x}||^2. \end{align*}
Al sacar raiz cuadrada, obtenemos la desigualdad $$||(Df(\bar{b})-Df(\bar{a}))(x)||\leq \varepsilon||\bar{x}||$$ buscada.
$\Leftarrow).$ Supongamos ahora que para cada $\varepsilon$ existe una $\delta$ como en el enunciado del teorema. Debemos ver que todas las derivadas parciales de todas las componentes son continuas. Podemos aplicar la desigualdad $||(Df(\bar{b})-Df(\bar{a}))(\bar{x})||\leq ||\bar{x}||\varepsilon$ tomando como $\bar{x}$ cada vector $\hat{e}_i$ de la base canónica. Esto nos dice que
Esto es precisamente lo que estábamos buscando: si $\bar{b}$ está lo suficientemente cerca de $\bar{a}$, cada derivada parcial en $\bar{b}$ está cerca de su correspondiente en $\bar{a}$.
$\square$
Invertibilidad de $Df(\bar{a})$ en todo un abierto
En esta sección demostraremos lo siguiente. Si $f:\mathbb{R}^n\to \mathbb{R}^n$ es un campo vectorial diferenciable en $\bar{a}$ y $Df(\bar{a})$ es invertible, entonces $Df(\bar{x})$ será invertible para cualquier $\bar{x}$ alrededor de cierta bola abierta alrededor de $\bar{a}$. Los argumentos en esta ocasión están un poco más relacionados con el álgebra lineal.
Será útil que recuerdes que una transformación lineal $T:\mathbb{R}^n \to \mathbb{R}^n$ es invertible si el único $\bar{x}\in \mathbb{R}^n$ tal que $T(\bar{x})=\bar{0}$ es $\bar{x}=\bar{0}$. El siguiente criterio es otra caracterización de invertibilidad en términos de lo que le hace $T$ a la norma de los vectores.
Teorema. Sea $T:\mathbb{R}^{n}\rightarrow \mathbb{R}^{n}$ una transformación lineal. La transformación $T$ es invertible si y sólo si existe $\varepsilon >0$ tal que $$||T(\bar{x})||\geq \varepsilon ||\bar{x}||$$ para todo $\bar{x}\in \mathbb{R}^{n}$.
Demostración. $\left. \Rightarrow \right)$ Como $T$ es invertible, para todo $\bar{x}\neq \bar{0}$ sucede que $T(\bar{x})\neq \bar{0}$. En particular, esto sucede para todos los vectores en $S^{n-1}$ (recuerda que es la esfera de radio $1$ y dimensión $n-1$ centrada en $\bar{0}$). Esta esfera es compacta y consiste exactamente de los $\bar{x}\in \mathbb{R}^n$ de norma $1$.
Sabemos que las transformaciones lineales y la función norma son continuas. Por la compacidad de $S^{n-1}$, la expresión $||T(\bar{x})||$ tiene un mínimo digamos $\varepsilon$, que alcanza en $S^{n-1}$. Por el argumento del párrafo anterior, $\varepsilon>0$.
Tomemos ahora cualquier vector $\bar{x}\in \mathbb{R}^n$. Si $\bar{x}=\bar{0}$, entonces $$||T(\bar{0})||=||\bar{0}||=0\geq \varepsilon ||\bar{0}||.$$ Si $\bar{x}\neq \bar{0}$, el vector $\frac{\bar{x}}{||\bar{x}||}$ está en $S^{n-1}$, de modo que $$\left|\left|T\left(\frac{\bar{x}}{||\bar{x}||}\right)\right|\right| \geq \varepsilon.$$ Usando linealidad para sacar el factor $||\bar{x}||$ y despejando obtenemos $$||T(\bar{x})||\geq \varepsilon ||\bar{x}||,$$ como estábamos buscando.
$\left. \Leftarrow \right)$ Este lado es más sencillo. Si existe dicha $\varepsilon >0$, entonces sucede que para $\bar{x}$ en $\mathbb{R}^n$, con $\bar{x}\neq \bar{0}$ tenemos $$||T(\bar{x})||\geq \varepsilon||\bar{x}||>0.$$ Por lo tanto, $T(\bar{x})\neq \bar{0}$ y así $T$ es invertible.
$\square$
Obtengamos una consecuencia del teorema de clasificación de la sección anterior que está muy relacionada con este resultado que acabamos de demostrar.
Teorema. Sea $f:S\subseteq \mathbb{R}^{n}\rightarrow \mathbb{R}^{n}$ de clase $C^{1}$ en el conjunto abierto $S$ y $\bar{a}\in S$. Si $Df(\bar{a})$ es invertible, entonces existen $\delta >0$ y $m>0$ tales que $B_{\delta}(\bar{a})\subseteq S$ y $||Df(\bar{b})(\bar{x})||\geq m||\bar{x}||$, para todo $\bar{b}\in B_{\delta}(\bar{a})$ y para todo $\bar{x}\in \mathbb{R}^{n}$.
Demostración. Como $Df(\bar{a})$ es invertible, por el teorema que acabamos de demostrar existe $\varepsilon’>0$ tal que $$||Df(\bar{a})(\bar{x})||\geq \varepsilon’||\bar{x}||$$ para todo $\bar{x}\in \mathbb{R}^{n}$.
Por nuestra caracterización de funciones $C^1$, Ahora como $f\in C^{1}$ en $S$ (abierto) para $\varepsilon =\frac{\varepsilon’}{2}>0$, existe $\delta >0$ tal que $B_{\delta}(\bar{a})\subseteq S$, y $||Df(\bar{b})(\bar{x})-Df(\bar{a})(\bar{x})||\leq \frac{\varepsilon’}{2}||\bar{x}||$ para todo $\bar{b}\in B_{\delta}(\bar{a})$ y para todo $\bar{x}\in \mathbb{R}^{n}$.
Por la desigualdad del triángulo, \[ ||Df(\bar{a})(\bar{x})-Df(\bar{b})(\bar{x})||+||Df(\bar{b})(\bar{x})||\geq ||Df(\bar{a})(\bar{x})||,\]
De esta manera, el resultado es cierto para la $\delta$ que dimos y para $m=\frac{\varepsilon’}{2}$.
$\square$
El siguiente corolario es consecuencia inmediata de lo discutido en esta sección y está escrito de acuerdo a la aplicación que haremos más adelante en la demostración del teorema de la función inversa.
Corolario. Sea $f:S\subseteq \mathbb{R}^{n}\rightarrow \mathbb{R}^{n}$ una función de clase $C^{1}$ en $S$ y $\bar{a}\in S$. Si $Df(\bar{a})$ es invertible, entonces, existe $\delta > 0$ tal que $B_{\delta}(\bar{a})\subseteq S$ y $Df(\bar{b})$ es invertible para todo $\bar{b}\in B_{\delta}(\bar{a})$.
Queda como tarea moral responder por qué este corolario es consecuencia inmediata del teorema anterior.
Un poco de intuición geométrica
Dejamos esta entrada hasta aquí, la naturaleza densamente teórica de lo que estamos haciendo puede hacer pesadas las exposiciones. Lo que hasta aquí demostramos es que para un campo vectorial $C^1$ si su derivada en $\bar{a}$ es invertible, entonces lo es en toda una vecindad que tiene a $\bar{a}$. Imaginemos al pedacito de superficie $f(B_{\delta}(\bar{a}))$ cubierto con pequeños rectángulos. En cada punto, las imágenes de estos rectángulos están muy cerquita, casi pegados a la superficie. Esto nos garantizaría la invertibilidad de $f$ en esta vecindad.
Figura 2
En la Figura 2 vemos ilustrado esto. El círculo inferior corresponde a la vecindad $B_{\delta}(\bar{a})$ en el dominio de $f$. La función $f$ levanta una porción del plano en la sabana delineada con negro arriba del círculo. En el círculo tenemos al punto $\bar{a}$ en verde agua. Sobre la sábana de arriba tenemos con el mismo color a $f(\bar{a})$. Los puntos negros pequeños dentro de la vecindad alrededor de $\bar{a}$ son alzados por $f$ a puntos negros sobre la sabana. Sobre de cada punto negro en la sabana tenemos un cuadrito rojo que representa al cachito de plano tangente cerca de la imagen de cada punto. La imagen esta llena de estos pequeños cuadritos, todos ellos representan diferenciales invertibles, esto nos permitirá asegurar la invertibilidad de $f$ en al menos una vecindad.
Más adelante…
En la siguiente entrada demostraremos el teorema de la función inversa, inciso por inciso. Es importante que estes familiarizado con los resultados de esta entrada, pues serán parte importante de la demostración.
Tarea moral
¿Qué diría el teorema de la función inversa para campos vectoriales $f:\mathbb{R}^2\to \mathbb{R}^2$? ¿Se puede usar para $$f(r,\theta)=(r\cos(\theta),r\sin(\theta))?$$ Si es así, ¿para qué valores de $r$ y $\theta$? ¿Qué diría en este caso explícitamente?
Explica por qué el corolario que enunciamos en efecto se deduce de manera inmediata de lo discutido en la sección correspondiente.
Revisa todas las desigualdades que usamos en esta entrada. ¿Qué resultado estamos usando? ¿Cuándo se darían estas igualdades?
Demuestra que el determinante de una matriz es una función continua en términos de las entradas de la matriz. Usa esto para demostrar que si $A\in M_n(\mathbb{R})$ es una matriz y $B$ es una matriz muy cercana a $A$, entonces $B$ también es invertible.
Demuestra que si una transformación $T$ es diagonalizable, entonces en el teorema de caracterización de invertibilidad se puede usar como $\epsilon$ al mínimo de la expresión $|\lambda|$ variando sobre todos los eigenvalores $\lambda$ de $T$.
Tenemos ya la definición de diferenciabilidad, y su versión manejable: la matriz jacobiana. Seguiremos construyendo conceptos y herramientas del análisis de los campos vectoriales muy importantes e interesantes. A continuación, enunciaremos una nueva versión de la regla de la cadena, que nos permitirá calcular las diferenciales de composiciones de campos vectoriales entre espacios de dimensión arbitraria. Esta regla tiene numerosas aplicaciones y es sorprendentemente fácil de enunciar en términos de producto de matrices.
Primeras ideas hacia la regla de la cadena
La situación típica de regla de la cadena es considerar dos funciones diferenciables que se puedan componer. A partir de ahí, buscamos ver si la composición también es diferenciable y, en ese caso, intentamos dar la derivada de la composición en términos de las derivadas de las funciones. Veamos qué pasa en campos vectoriales.
Pensemos en $f:S_{f}\subseteq \mathbb{R}^{m}\rightarrow \mathbb{R}^{n}$, $g:S_{g}\subseteq \mathbb{R}^{l}\rightarrow \mathbb{R}^{m}$ y en su composición $h=f\circ g$ definida sobre alguna vecindad $V\subseteq S_g$ de $\bar{a}$ y tal que $g(V)\subseteq S_f$. Pensemos que $g$ es diferenciable en $\bar{a}$ con derivada $G_\bar{a}$ y que $f$ es diferenciable en $\bar{b}:=g(\bar{a})$ con derivada $F_\bar{b}$.
Exploremos la diferenciabilidad de la composición $h$ en el punto $\bar{a}$. Para ello, tomemos un $\bar{y}\in \mathbb{R}^{l}$ tal que $\bar{a}+\bar{y}\in V$ y consideremos la siguiente expresión:
con $\lim\limits_{\bar{y}\to \bar{0}}E_{f}(\bar{b};\bar{v})=0$.
Concatenando nuestras igualdades, podemos reescribir esto como
\[ h(\bar{a}+\bar{y})-h(\bar{a})=(F_{\bar{b}}\circ G_{\bar{a}})(\bar{y})+||\bar{y}||E_{h}(\bar{a};\bar{y}),\] en donde hemos definido
\[ E_{h}(\bar{a};\bar{y})=(F_{\bar{b}}\circ E_{g})(\bar{a};\bar{y})+\frac{||\bar{v}||}{||\bar{y}||}E_{f}(\bar{b};\bar{v}).\] Si logramos demostrar que $\lim\limits_{\bar{y}\to \bar{0}}E_{h}(\bar{a};\bar{y})=0$, entonces tendremos la diferenciabilidad buscada, así como la derivada que queremos. Dejemos esto en pausa para enunciar y demostrar un lema auxiliar.
Un lema para acotar la norma de la derivada en un punto
Probemos el siguiente resultado.
Lema. Sea $\phi:S\subseteq \mathbb{R}^l\to \mathbb{R}^m$ un campo vectorial diferenciable en un punto $\bar{c}\in S$ y $T_\bar{c}$ su derivada. Entonces, para todo $\bar{v}\in \mathbb{R}^{l}$, se tiene:
De aquí se ve que conforme $\bar{y}\to \bar{0}$, la expresión $\frac{||\bar{v}||}{||\bar{y}||}$ está acotada superiormente por la constante $A:=\sum_{k=1}^{m}||\triangledown g_{k}(\bar{a})||.$ Además, si $\bar{y}\to \bar{0}$, entonces $\bar{v}\to \bar{0}$. Así,
Hemos concluido que $$h(\bar{a}+\bar{y})-h(\bar{a})=(F_{\bar{b}}\circ G_{\bar{a}})(\bar{y})+||\bar{y}||E_{h}(\bar{a};\bar{y}),$$
con $\lim_{\bar{y}\to \bar{0}} E_h(\bar{a};\bar{y})=0$. Esto precisamente es la definición de $h=f\circ g$ es diferenciable en $\bar{a}$, y su derivada en $\bar{a}$ es la transformación lineal dada por la composición de transformaciones lineales $F_\bar{b}\circ G_\bar{a}$.
Recapitulación de la regla de la cadena
Recapitulamos toda la discusión anterior en el siguiente teorema.
Teorema (Regla de la cadena). Sean $f:S_{f}\subseteq \mathbb{R}^{m}\rightarrow \mathbb{R}^{n}$, $g:S_{g}\subseteq \mathbb{R}^{l}\rightarrow \mathbb{R}^{m}$ campos vectoriales. Supongamos que la composición $f\circ g$ está definida en todo un abierto $S\subseteq S_g$. Supongamos que $g$ es diferenciable en un punto $\bar{a}\in S$ con derivada $G_\bar{a}$ y $f$ es diferenciable en $\bar{b}:=g(\bar{a})$ con derivada $F_\bar{b}$. Entonces, $h$ es diferenciable en $\bar{a}$ con derivada $F_\bar{b}\circ G_\bar{a}$.
Dado que la representación matricial de la composición de dos transformaciones lineales es igual al producto de estas, podemos reescribir esto en términos de las matrices jacobianas como el siguiente producto matricial: $$Dh(\bar{a})=Df(\bar{b})Dg(\bar{a}).$$
Usos de la regla de la cadena
Hagamos algunos ejemplos de uso de regla de la cadena. En el primer ejemplo que veremos a continuación, la función $f$ es un campo escalar.
Ejemplo 1. Tomemos $g:S\subseteq \mathbb{R}^{n}\rightarrow \mathbb{R}^{m}$ campo vectorial, y $f:U\subseteq \mathbb{R}^{m}\rightarrow \mathbb{R}$ campo escalar. Consideremos $h=f\circ g$ y supongamos que se satisfacen las hipótesis del teorema de la regla de la cadena. Tenemos: \[ Df(\bar{b})=\begin{pmatrix} \frac{\partial f}{\partial x_{1}}(\bar{b}) & \dots & \frac{\partial f}{\partial x_{m}}(\bar{b}) \end{pmatrix} \] y \[ Dg(\bar{a})=\begin{pmatrix}\frac{\partial g_{1}}{\partial x_{1}}(\bar{a}) & \dots & \frac{\partial g_{1}}{\partial x_{n}}(\bar{a}) \\ \vdots & \ddots & \vdots \\ \frac{\partial g_{m}}{\partial x_{1}}(\bar{a}) & \dots & \frac{\partial g_{m}}{\partial x_{n}}(\bar{a}) \end{pmatrix} . \]
En otras palabras, tenemos las siguientes ecuaciones para calcular cada derivada parcial de $h$: \[ \frac{\partial h}{\partial x_{j}}(\bar{a})=\sum_{i=1}^{m}\frac{\partial f}{\partial x_{i}}(\bar{b})\frac{\partial g_{i}}{\partial x_{j}}(\bar{a}).\]
$\triangle$
Ejemplo 2. Sean $\bar{a}=(s,t)$ y $\bar{b}=(x,y)$ puntos en $\mathbb{R}^{2}$. Pensemos que las entradas de $\bar{b}$ están dadas en función de las entradas de $\bar{a}$ mediante las ecuaciones $x=g_{1}(s,t)$ y $y=g_{2}(s,t)$. Pensemos que tenemos un campo escalar $f:\mathbb{R}^2\to \mathbb{R}$, y definimos $h:\mathbb{R}^2\to \mathbb{R}$ mediante $$h(s,t)=f(g_{1}(s,t),g_{2}(s,t)).$$
Por el ejemplo anterior \[ \frac{\partial h}{\partial s}=\frac{\partial f}{\partial x}\frac{\partial x}{\partial s}+\frac{\partial f}{\partial y}\frac{\partial y}{\partial s} \] y \[ \frac{\partial h}{\partial t}=\frac{\partial f}{\partial x}\frac{\partial x}{\partial t}+\frac{\partial f}{\partial y}\frac{\partial y}{\partial t}. \] Como tarea moral queda que reflexiones qué significa $\partial x$ cuando aparece en el «numerador» y qué significa cuando aparece en el «denominador».
$\triangle$
Ejemplo 3. Para un campo escalar $f(x,y)$ consideremos un cambio de coordenadas $x=rcos\theta$, $y=rsen\theta$ es decir tomemos la función $\phi (r,\theta)=f(rcos\theta ,rsen\theta )$.
Por el ejemplo anterior tenemos \[ \frac{\partial \phi }{\partial r}=\frac{\partial f}{\partial x}\frac{\partial x}{\partial r}+\frac{\partial f}{\partial y}\frac{\partial y}{\partial r} \] y \[ \frac{\partial \phi }{\partial \theta }=\frac{\partial f}{\partial x}\frac{\partial x}{\partial \theta }+\frac{\partial f}{\partial y}\frac{\partial y}{\partial \theta } \] donde, haciendo las derivadas parciales tenemos: \[ \frac{\partial x}{\partial r}=cos\theta ,\hspace{1cm}\frac{\partial y}{\partial r}=sen\theta \] y \[ \frac{\partial x}{\partial \theta }=-rsen\theta,\hspace{1cm}\frac{\partial y}{\partial \theta }=-rcos\theta. \] Finalmente obtenemos: \[ \frac{\partial \phi }{\partial r }=\frac{\partial f }{\partial x }cos\theta +\frac{\partial f }{\partial y }sen\theta \] y \[ \frac{\partial \phi }{\partial \theta }=-\frac{\partial f }{\partial x }rsen\theta +\frac{\partial f }{\partial y }rcos\theta \] que son las derivadas parciales del cambio de coordenadas en el dominio de $f$.
$\triangle$
Mas adelante…
En la siguiente entrada comenzaremos a desarrollar la teoría para los importantes teoremas de la función inversa e implícita si tienes bien estudiada esta sección disfrutaras mucho de las siguientes.
Tarea moral
Considera el campo escalar $F(x,y,z)=x^{2}+y sen(z)$. Imagina que $x,y,z$ están dados por valores $u$ y $v$ mediante las condiciones $x=u+v$, $y=vu$, $z=u$. Calcula $\frac{\partial F}{\partial u}$, $\frac{\partial F}{\partial v}$.
Sea $g(x,y,z)=(xy,x)$, y $f(x,y)=(2x,xy^{2},y)$. Encuentra la matriz jacobiana del campo vectorial $g\circ f$. Encuentra también la matriz jacobiana del campo vectorial $f\circ g$.
En la demostración del lema que dimos, hay un paso que no justificamos: el primero. Convéncete de que es cierto repasando el contenido de la entrada anterior Diferenciabilidad.
Imagina que sabemos que la función $f:\mathbb{R}^n\to \mathbb{R}^n$ es invertible y derivable en $\bar{a}$ con derivada $T_\bar{a}$. Imagina que también sabemos que su inversa $f^{-1}$ es derivable en $\bar{b}=f(\bar{a})$ con derivada $S_\bar{b}$. De acuerdo a la regla de la cadena, ¿Qué podemos decir de $T_\bar{a}\circ S_\bar{b}$? En otras palabras, ¿Cómo son las matrices jacobianas entre sí, en términos de álgebra lineal?
Reflexiona en cómo todas las reglas de la cadena que hemos estudiado hasta ahora son un corolario de la regla de la cadena de esta entrada.