(Trabajo de titulación asesorado por la Dra. Diana Avella Alaminos)
INTRODUCCIÓN
Si tenemos un conjunto $C$ con ciertas propiedades de nuestro interés, no forzosamente todo subconjunto de $C$ va a conservar esas propiedades, pero nos interesa encontrar condiciones suficientes (y de preferencia también necesarias) para saber si un subconjunto $D$ de $C$ dado tiene o no las propiedades que queremos.
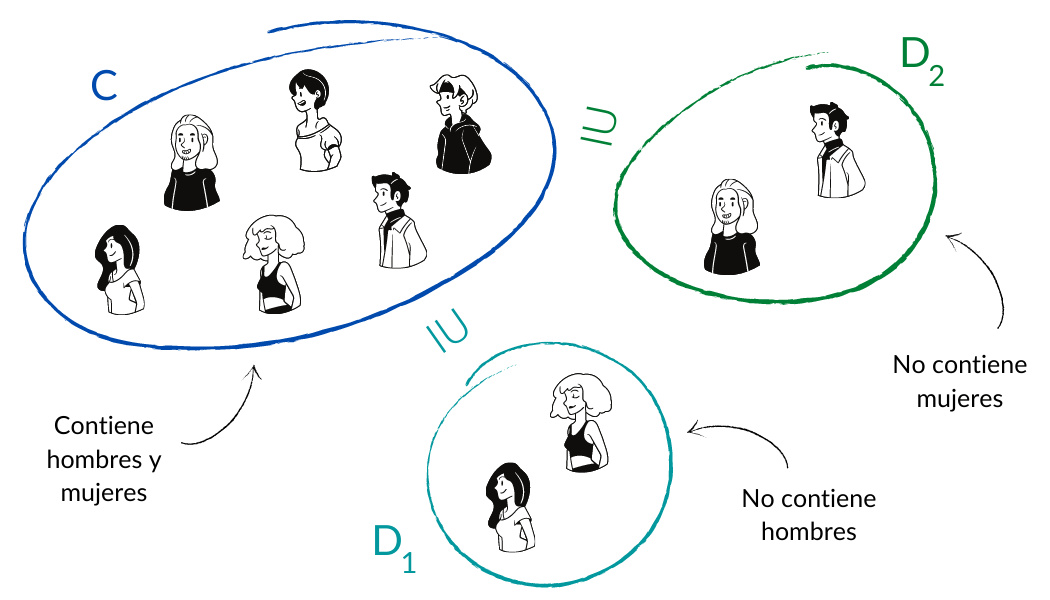
En esta entrada analizaremos qué se requiere para que un subconjunto de un espacio vectorial, tenga también estructura de espacio vectorial. Veremos que aunque aparentemente se requiere pedir muchas condiciones, en realidad éstas se pueden reducir sólo a unas cuantas.
SUBESPACIO
Definición: Sea $V$ un $K$ – espacio vectorial y $W$ un subconjunto de $V$. Decimos que $W$ es un subespacio de $V$, y se le denota como $W\leqslant V$ si:
i) $W$ contiene al neutro del espacio $V$,
i.e. $\theta_V\in W$
ii) La suma es cerrada en $W,$
i.e. $\forall u,v\in W:$
$u+v\in W$
iii) El producto por escalar es cerrado en $W$,
i.e. $\lambda\in K$, $w\in W:$
$\lambda w\in W$
Veamos una equivalencia a esta definición que nos facilitará demostrar si un subconjunto dado de un espacio vectorial es por sí mismo un espacio vectorial.
Proposición (1.4.1.): Sean $V$ un $K$ – espacio vectorial y $W$ un subconjunto de $V$. Se cumple que $W\leqslant V$ si y sólo si $W$ con las operaciones restringidas de $V$ es un $K$ – espacio vectorial.
Demostración: Veamos que se cumplen ambas implicaciones.
$\Longrightarrow )$ Supongamos que $W\leqslant V$.
Por ii) y iii) la suma y el producto por escalar son cerrados en $W$, entonces las operaciones restringidas de $V$ dan una suma y un producto por escalar en $W$.
Propiedades $1$, $2$, $5$, $6$, $7.1$ y $7.2$ de espacio vectorial: Como $u+v=v+u$ para cualesquiera $u,v\in V$, en particular $u+v=v+u$ para toda $u,v\in W$. Por lo tanto, la suma en $W$ es conmutativa.
Nota: Decimos en este caso que la conmutatividad de la suma se hereda de $V$.
Análogamente se heredan la asociatividad de la suma en $W$ y las propiedades $5$, $6$, $7.1$ y $7.2$ de espacio vectorial.
Propiedad $4$ de espacio vectorial: Para cada $w\in W$ se cumple que $-w=(-1_K)w\in W$ ya que el producto es cerrado en $W$.
Propiedad $5$ de espacio vectorial: Por hipótesis $\theta_V\in W$ y como es el neutro en $V$, $\theta_V+v=v+\theta_V=v$ para todo $v\in V$, en particular $\theta_V+w=w+\theta_V=w$ para todo $w\in W$, así $\theta_V$ funciona como neutro en $W$.
$\therefore W$ con las operaciones restringidas de $V$ es un $K$ – espacio vectorial.
$\Longleftarrow )$ Supongamos que $W$ es un $K$ – espacio vectorial con las operaciones restringidas de $V$.
Entonces la suma y el producto por escalar son cerrados en $W$, es decir, se cumplen ii. y iii.
Además $W$ tiene un neutro, digamos $\theta_W\in W$.
Por un lado $\theta_V+\theta_W=\theta_W$ en $V$, pues $\theta_V$ es neutro en $V$.
Por otro lado $\theta_W+\theta_W=\theta_W$ en $W$, pues $\theta_W$ es neutro en $W$.
Así, $\theta_V+\theta_W=\theta_W+\theta_W$ en $V$ y por cancelación en $V$, $\theta_V=\theta_W$.
De donde $\theta_V\in W$
$\therefore W\leqslant V$ .
Observación: Sean $V$ un $K$ – espacio vectorial, $W$ un subconjunto de $V$. Resulta que
$W\leqslant V$ si y sólo si se cumple que: a) $W\not=\emptyset$ y b) $\forall u,v\in W$ $\forall\lambda\in K(\lambda u+v\in W)$.
La implicación de ida es muy directa y queda como ejercicio. Para justificar el regreso supongamos que se cumplen a) y b). Dados $u,v\in W$ se tiene que $u+v=1_Ku+v$ y gracias a b) sabemos que $1_Ku+v\in W$, así se cumple la propiedad ii). Por otro lado, como se cumple a) podemos asegurar que existe $v \in W$, y por la propiedad b) $\theta_V=-v+v=(-1_K)v+v\in W$, por lo que $\theta_V\in W$ y se cumple i). Finalmente dados $u\in W, \lambda \in K$ como $\theta_V\in W$, usando b) se tiene que $\lambda u=\lambda u+\theta_V\in W$ por lo que se cumple la propiedad iii).
Ejemplos:
- $\{ (x,y,0)|x,y\in\mathbb{R}\}$ es un subespacio de $\mathbb{R}^3.$
- $\left\{ \begin{pmatrix}a&b\\b&a\end{pmatrix}|a,b\in\mathbb{R} \right\}$ es un subespacio de $\mathcal{M}_{2\times 2}(\mathbb{R})$.
- $\mathcal{P}_n(\mathbb{R})$ (el conjunto de polinomios de grado mayor o igual a $n$ con coeficientes en $\mathbb{R}$) es un subespacio de $\mathbb{R}[x]$
- $\{ f:\mathbb{R}\longrightarrow\mathbb{R}| f$ es continua$\}$ es un subespacio de $\{ f|f:\mathbb{R}\longrightarrow\mathbb{R}\}.$
- $\{(x,y,z)|x=y=z\in \mathbb{R}\}$ es un subespacio de $\mathbb{R}^3.$
EJEMPLO SISTEMA HOMOGÉNEO
Sean $V=\mathcal{M}{n\times 1}(K)$ y $A\in\mathcal{M}{m\times n}(K)$.
$W= \{ X\in V|AX=0 \}$$\leqslant V$.
Recordemos que si tenemos el sistema de ecuaciones homogéneo de $m$ ecuaciones con $n$ incógnitas
\begin{align*}
\begin{cases}
\begin{matrix}
a_{11}x_1 & +a_{12}x_2 & \cdots & +a_{1n}x_n=0\\ a_{21}x_1 & +a_{22}x_2 & \cdots & +a_{2n}x_n=0 \\ \vdots & & \ddots & \vdots \\ a_{m1} x_1& +a_{m2}x_2 & \cdots & +a_{mn}x_n=0
\end{matrix}
\end{cases}
\end{align*}
entonces su forma matricial es:
\begin{align*}
AX=\begin{pmatrix}a_{11} & a_{12} & \cdots & a_{1n}\\ a_{21} & a_{22} & \cdots & a_{2n} \\ \vdots & & \ddots & \vdots \\ a_{m1} & a_{m2} & \cdots & a_{mn} \end{pmatrix} \begin{pmatrix}x_1\\ \vdots\\ x_n\end{pmatrix}
= \begin{pmatrix}0\\ \vdots\\ 0\end{pmatrix} = 0_{n \times 1} \end{align*}
Recordemos que estamos usando al $0_{n \times 1}$ para denotar a la matriz $n\times 1$ con todas sus entradas iguales al cero del campo. Veamos que las soluciones del sistema homogéneo dado por $A$ es un subespacio del espacio vectorial de matrices de $n\times 1$ con entradas en el campo $K$.
DEMOSTRACIÓN
Vamos a ver que $W$ cumple las tres condiciones suficientes y necesarias (por definición) para ser subespacio de $V$:
Sean $X,Y\in W$, $\lambda\in K$.
- P.D. $W$ tiene al neutro de $V$
$i.e.$ $\theta_V\in W.$
Sabemos que $A\theta_V=A0=0$.
$\therefore\theta_V\in W.$
- P.D. La suma es cerrada en $W$
$i.e.$ $X+Y\in W$.
Como $X,Y\in W$, $AX=AY=0$ y por lo tanto, $AX+AY=0+0=0$.
Basta recordar que por distributividad en las matrices $A(X+Y)=AX+AY$ para obtener que $A(X+Y)=0$.
$\therefore X+Y\in W.$
- P.D. El producto por escalar es cerrado en $W$
$i.e.$ $\lambda X\in W$.
Como $X\in W$, $AX=0$ y por lo tanto, $\lambda (AX)=0$.
Basta recordar que por propiedad del producto por escalar en matrices $A(\lambda X)=\lambda(AX)$ para obtener que $A(\lambda X)=0$
$\therefore\lambda X\in W.$
Así, concluimos que $W=\{X\in V|AX=0\}$, donde $A\in\mathcal{M}_{m\times n}(K)$, es un subespacio de $V=\mathcal{M}_{n\times 1}(K)$.
Proposición (1.4.2.): La intersección de una familia no vacía de subespacios es un subespacio.
Demostración: Sean $V$ un $K$ – espacio vectorial y $W=\{W_i|i\in I\}$ una familia no vacía de subespacios de $V$.
Sean $V$ un $K$ – espacio vectorial y $W=\{W_i|i\in I\}$ una familia no vacía de subespacios de $V$. Vamos a ver que $W$ cumple las tres condiciones suficientes y necesarias (por definición) para ser subespacio de $V$:
Sean $u,v\in W$, $\lambda\in K$.
- P.D. $W$ contiene al neutro de $V$
$i.e.$ $\theta_V\in W.$
Sabemos que $\forall i\in I(\theta_V\in W_i)$ porque todos los $W_i$ son subespacios de $V$.
$\displaystyle\therefore\theta_V\in\bigcap_{i\in I}W_i.$
- P.D. La suma es cerrada en $W$
$i.e.$ $u+v\in W$.
Dado que $u,v\in W$, $\forall i\in I(u,v\in W_i)$ y como todos los $W_i$ son subespacios de $V$, entonces $\forall i\in I(u+v\in W_i)$.
$\displaystyle\therefore u+v\in\bigcap_{i\in I}W_i.$
- P.D. El producto por escalar es cerrado en $W$
$i.e.$ $\lambda u\in W$.
Dado que $u\in W$, $\forall i\in I(u\in W_i)$ y como todos los $W_i$ son subespacios de $V$, entonces $\forall i\in I(\lambda u\in W_i)$.
$\displaystyle\therefore\lambda u\in\bigcap_{i\in I}W_i.$
Concluimos así que $W\leqslant V.$
Tarea Moral
- Dado $V$ un $K$ – espacio vectorial. Sean $W_1, W_2\leqslant V$. Demuestra que si $W_1\bigcup W_2\leqslant V$, entonces $W_1\subseteq W_2$, o bien, $W_2\subseteq W_1$.
Para lograrlo se te sugiere lo siguiente:- Supongamos que $W_1 \nsubseteq W_2$.
- Observamos que para cualesquiera $w_1\in W_1\backslash W_2$ y $w_2\in W_2$, tenemos que $w_1,w_2\in W_1\bigcup W_2$. Y como $W_1\bigcup W_2\leqslant V$, entonces $w_1+w_2\in W_1\bigcup W_2$. Además, gracias a la primera proposición de esta entrada, sabemos que $W_1$ y $W_2$ son $K$ – espacios vectoriales, de modo que los inversos aditivos de $w_1$ y $w_2$ son elementos de $W_1$ y $W_2$ respectivamente.
- Ahora argumenta por qué $w_1+w_2\notin W_2$ para concluir que $w_1+w_2\in W_1$.
- Por último argumenta por qué gracias a que $w_1+w_2\in W_1$, obtenemos que $w_2\in W_1$ para concluir que $W_2\subseteq W_1$.
- Sean $K=\mathbb{R}$ y $V=\{a+bx+cx^2+dx^3\mid a,b,c,d\in\mathbb{R}\}$.
Determina si $U=\{p(x)\in V|p(1)=0\}$ y $T=\{p(x)\in V|p'(1)=0\}$ son subespacios de $V$ y encuentra $U\cap T$.
MÁS ADELANTE…
Definiremos y analizaremos un nuevo concepto que dará lugar a un nuevo subespacio muy peculiar y central en el Álgebra Lineal.
Entradas relacionadas
- Ir a Álgebra Linea l – Diana Avella
- Entrada anterior del curso: 1.3. ESPACIOS VECTORIALES: propiedades
- Siguiente entrada del curso: 1.5. COMBINACIÓN LINEAL: definición y ejemplos