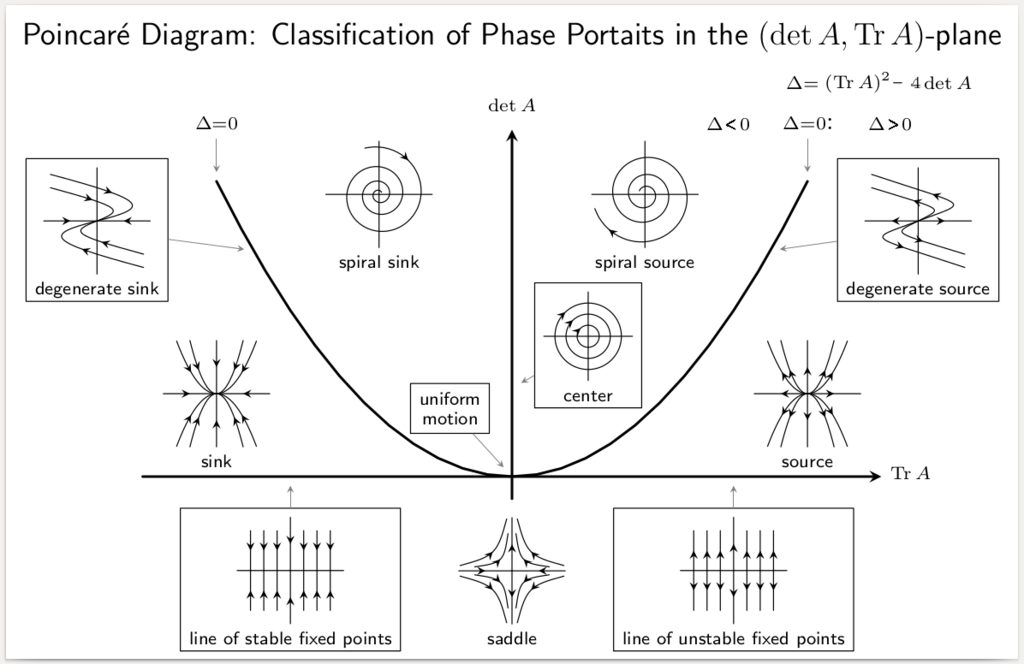
Antes de finalizar con el estudio cualitativo a sistemas de ecuaciones de la forma $$\begin{pmatrix} \dot{x} \\ \dot{y} \end{pmatrix}=\begin{pmatrix} a & b \\ c & d \end{pmatrix} \begin{pmatrix} x \\ y \end{pmatrix}$$, vamos a clasificar la estabilidad del punto de equilibrio, y por tanto el plano fase, en un diagrama que resume toda la información que estudiamos en las últimas entradas. Este diagrama es llamado plano traza – determinante. En esta entrada veremos cómo interpretar dicho diagrama.
Vimos que el plano fase y la estabilidad de los puntos de equilibrio depende de la forma de los valores propios asociados. Es fácil observar que los valores propios del sistema son las soluciones a la ecuación $$\det{(\textbf{A}-\lambda\textbf{Id})}=\lambda^{2}-(a+d)\lambda+(ad-bc)=0.$$ Notemos que podemos reescribir la ecuación anterior en términos de dos propiedades de la matriz asociada $\textbf{A}$: su traza y su determinante. En efecto, resulta que $$ \lambda^{2}-(a+d)\lambda+(ad-bc)=\lambda^{2}-\lambda\mathrm{tr}{A}+\det{A}.$$ Entonces los valores propios están dados por la fórmula $$\lambda=\frac{\mathrm{tr}{A}\pm\sqrt{\mathrm{tr}{A}^{2}-4\det{A}}}{2}$$ Así, el plano fase y la estabilidad de los puntos de equilibrio dependerán de la traza y el determinante de la matriz asociada. Analizaremos la forma de los valores propios según la última fórmula.
La información obtenida se podrá resumir en el plano traza – determinante, que puedes observar en la siguiente imagen (tomada del siguiente sitio) que nos indica la forma del plano fase, según los valores de la traza y el determinante.
Plano traza – determinante. Imagen tomada de https://es.m.wikipedia.org/wiki/Archivo:Stability_Diagram.png
El plano traza – determinante
Clasificamos la naturaleza del plano fase y la estabilidad de los puntos de equilibrio del sistema de ecuaciones $$\begin{pmatrix} \dot{x} \\ \dot{y} \end{pmatrix}=\begin{pmatrix} a & b \\ c & d \end{pmatrix}\begin{pmatrix} x \\ y \end{pmatrix}.$$ según la traza y el determinante de la matriz asociada. Englobamos toda la información obtenida en el plano traza – determinante.
Tarea moral
Los siguientes ejercicios no forman parte de la evaluación del curso, pero te servirán para entender mucho mejor los conceptos vistos en esta entrada, así como temas posteriores.
Considera el sistema de ecuaciones $$\begin{pmatrix} \dot{x} \\ \dot{y} \end{pmatrix}=\begin{pmatrix} a & b \\ c & d \end{pmatrix}\begin{pmatrix} x \\ y \end{pmatrix}.$$ Muestra que los valores propios del sistema $\lambda_{1}, \lambda_{2}$ satisfacen las identidades $$\lambda_{1}+\lambda_{2}=\mathrm{tr}{A}$$ $$\lambda_{1}\lambda_{2}=\det{A}.$$ Recuerda considerar los casos cuando los valores propios son distintos o iguales.
Clasifica el plano fase y puntos de equilibrio de los siguientes sistemas de ecuaciones, calculando únicamente la traza y el determinante de la matriz asociada:
$$\begin{pmatrix} \dot{x} \\ \dot{y} \end{pmatrix}=\begin{pmatrix} 15 & -1 \\ -60 & 4 \end{pmatrix}\begin{pmatrix} x \\ y \end{pmatrix}$$
$$\begin{pmatrix} \dot{x} \\ \dot{y} \end{pmatrix}=\begin{pmatrix} \pi & 0 \\ e & -1 \end{pmatrix}\begin{pmatrix} x \\ y \end{pmatrix}$$
Considera el sistema de ecuaciones $$\begin{pmatrix} \dot{x} \\ \dot{y} \end{pmatrix}=\begin{pmatrix} a & a+2 \\ a-2 & a \end{pmatrix}\begin{pmatrix} x \\ y \end{pmatrix}.$$ Determina la forma del plano fase y la estabilidad del punto de equilibrio según la traza y el determinante de la matriz asociada, y el valor $a$.
Para el ejercicio anterior, identifica la región del plano traza – determinante donde los planos fase tienen comportamientos similares.
Realiza el mismo análisis de los dos ejercicios anteriores para el sistema $$\begin{pmatrix} \dot{x} \\ \dot{y} \end{pmatrix}=\begin{pmatrix} a & a+b \\ a-b & a \end{pmatrix}\begin{pmatrix} x \\ y \end{pmatrix}$$ para cualquier valor de $a$ y $b$.
Más adelante
Con todo el conocimiento adquirido acerca de sistemas de ecuaciones lineales, es momento de estudiar, al menos de manera cualitativa, sistemas de ecuaciones no lineales. En la próxima entrada daremos una breve introducción a tales sistemas.
Además, veremos que es posible linealizar este tipo de sistemas para obtener un sistema de ecuaciones lineales equivalente que nos brinde la información cualitativa de las soluciones al sistema no lineal. Así, podremos dibujar el plano fase de un sistema no lineal, sin conocer explícitamente las soluciones a dicho sistema.
Trabajo realizado con el apoyo del Programa UNAM-DGAPA-PAPIME PE104522 «Hacia una modalidad a distancia de la Licenciatura en Matemáticas de la FC-UNAM – Etapa 2»
En esta primera unidad abordaremos varios los temas relacionados con las circunferencias coaxiales. Para ello, iniciaremos hablando de la potencia de un punto con respecto a una circunferencia. A grandes rasgos, esto trata de lo siguiente.
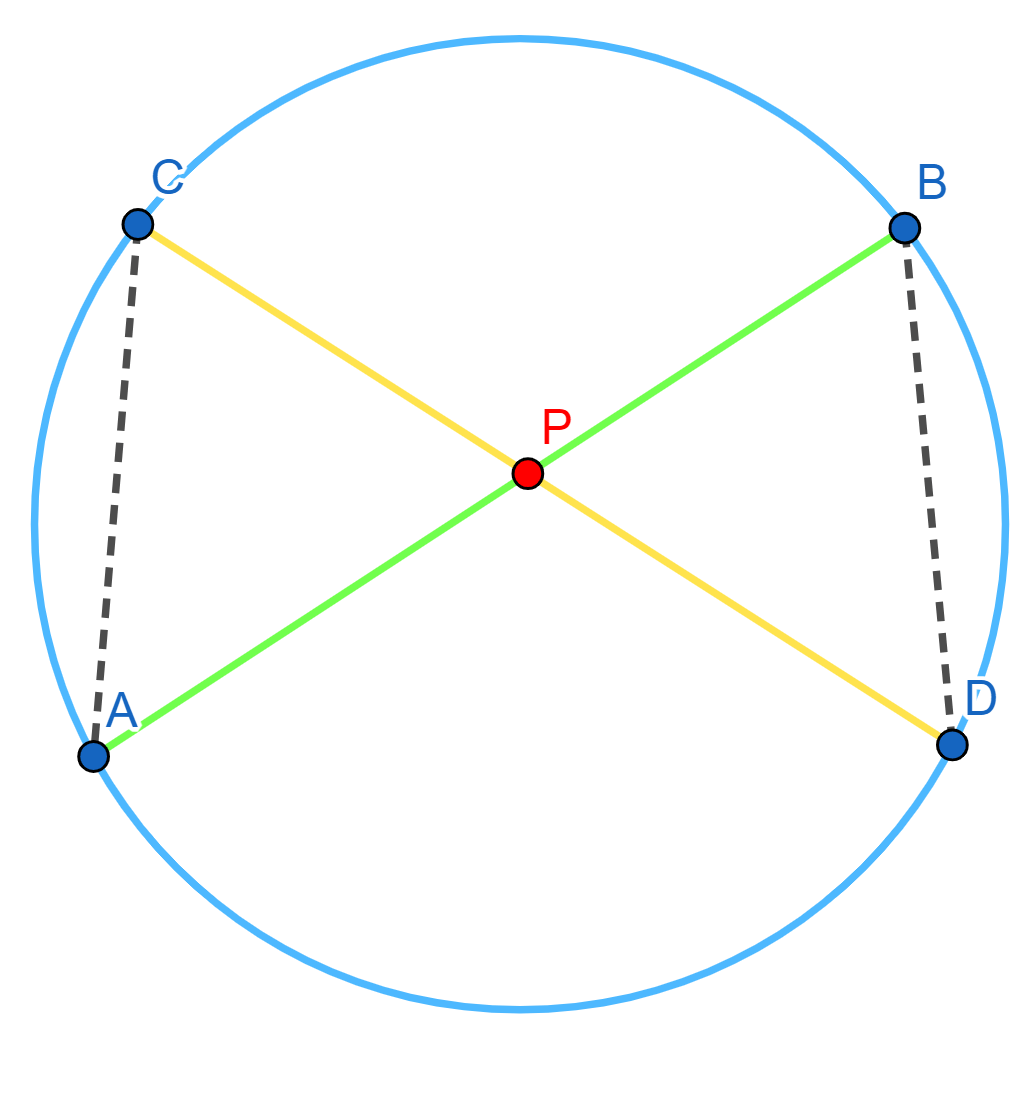
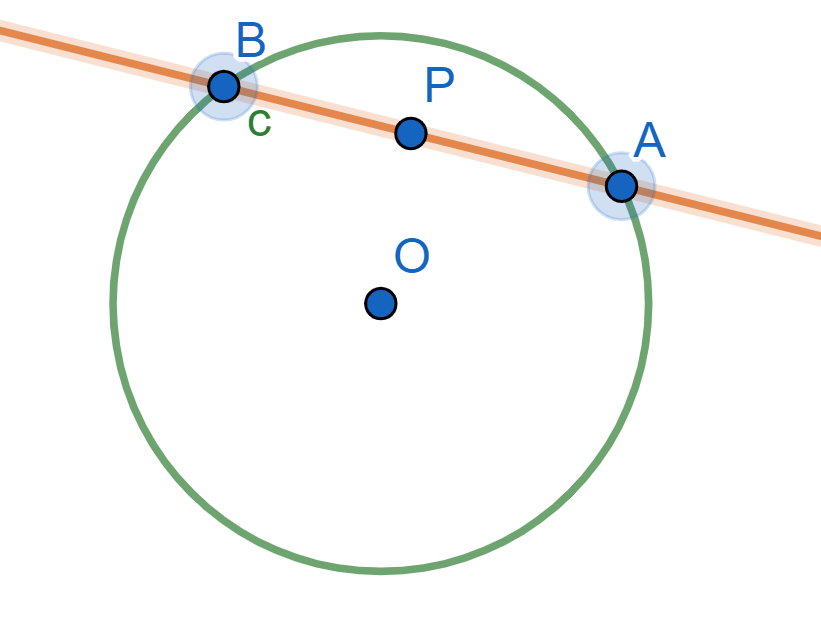
Tomemos una circunferencia $\mathcal{C}$. Tomemos $P$ un punto cualquiera. Tomemos una recta $l$ por $P$ y llamemos $A$ y $B$ los puntos de intersección de $l$ con $\mathcal{C}$. Bajo estas elecciones, la potencia de $P$ será $PA\cdot PB$. Lo que veremos en esta entrada es que dicho producto es constante sin importar la elección de $l$. Para mostrar esto, introduciremos algunas definiciones y posteriormente haremos una demostración por casos.
Definición de potencia de un punto
Comenzaremos dando una primer definición de potencia, que dependerá de cierto punto, circunferencia y recta que elijamos.
Definición. Sea $\mathcal{C}$ una circunferencia, $P$ un punto y $l$ una recta que intersecta a $\mathcal{C}$. Sean $A$ y $B$ los puntos de intersección de $l$ y $\mathcal{C}$ ($A=B$ si $l$ es tangente a $\mathcal{C}$). La potencia de $P$ con respecto a $\mathcal{C}$ en la recta $l$ es la cantidad $PA\cdot PB$. Usaremos la siguiente notación: $$\text{Pot}(P,\mathcal{C},l):=PA\cdot PB.$$
En esta definición y de aquí en adelante, a menos que se diga lo contrario, se estará trabajando con segmentos dirigidos. Es decir, estamos pensando que cada segmento tiene una dirección del primer punto al segundo. Así, por ejemplo, el valor de $PA$ dependerá de la longitud del segmento y su signo dependerá de una dirección (usualmente implícita) que se le asigne a la recta por $A$ y $P$. De este modo, tendremos, por ejemplo, que $PA=-AP$.
La definición de potencia de un punto puede simplificarse notablemente en vista de la siguiente proposición.
Proposición. La potencia de un punto con respecto a una circunferencia no depende de la recta elegida. Es decir, tomemos $\mathcal{C}$ una circunferencia, $P$ un punto y $l,m$ rectas. Supongamos que los puntos de intersección de $l$ con $\mathcal{C}$ son $A$ y $B$; y que los puntos de intersección de $m$ con $\mathcal{C}$ son $C$ y $D$ (en caso de tangencias, repetimos los puntos). Entonces: $$PA\cdot PB = PC\cdot PD.$$
Demostración. Haremos la demostración por casos de acuerdo a cuando $P$ está dentro o fuera de la circunferencia, o sobre ella.
Dentro de la circunferencia:
Tomemos las cuerdas $AB$ y $CD$ en la circunferencia, las cuales se cortan en $P$. Los triángulos $\triangle APC$ y $\triangle DPB$ son semejantes ya que:
$\angle PAC = \angle PDB $ por abrir el mismo arco $\overline{BC}$.
$\angle APC = \angle BPD $ por ser opuestos al vértice.
$\angle PCA = \angle PBD $ por abrir mismo arco $\overline{AD}$.
Entonces de la semejanza $\triangle APC \cong \triangle DPB $ tenemos que
$\frac{PA}{PD}=\frac{PC}{PB},$
de donde obtenemos la igualdad $PA\cdot PB =PC \cdot PD$ deseada.
Fuera de la circunferencia:
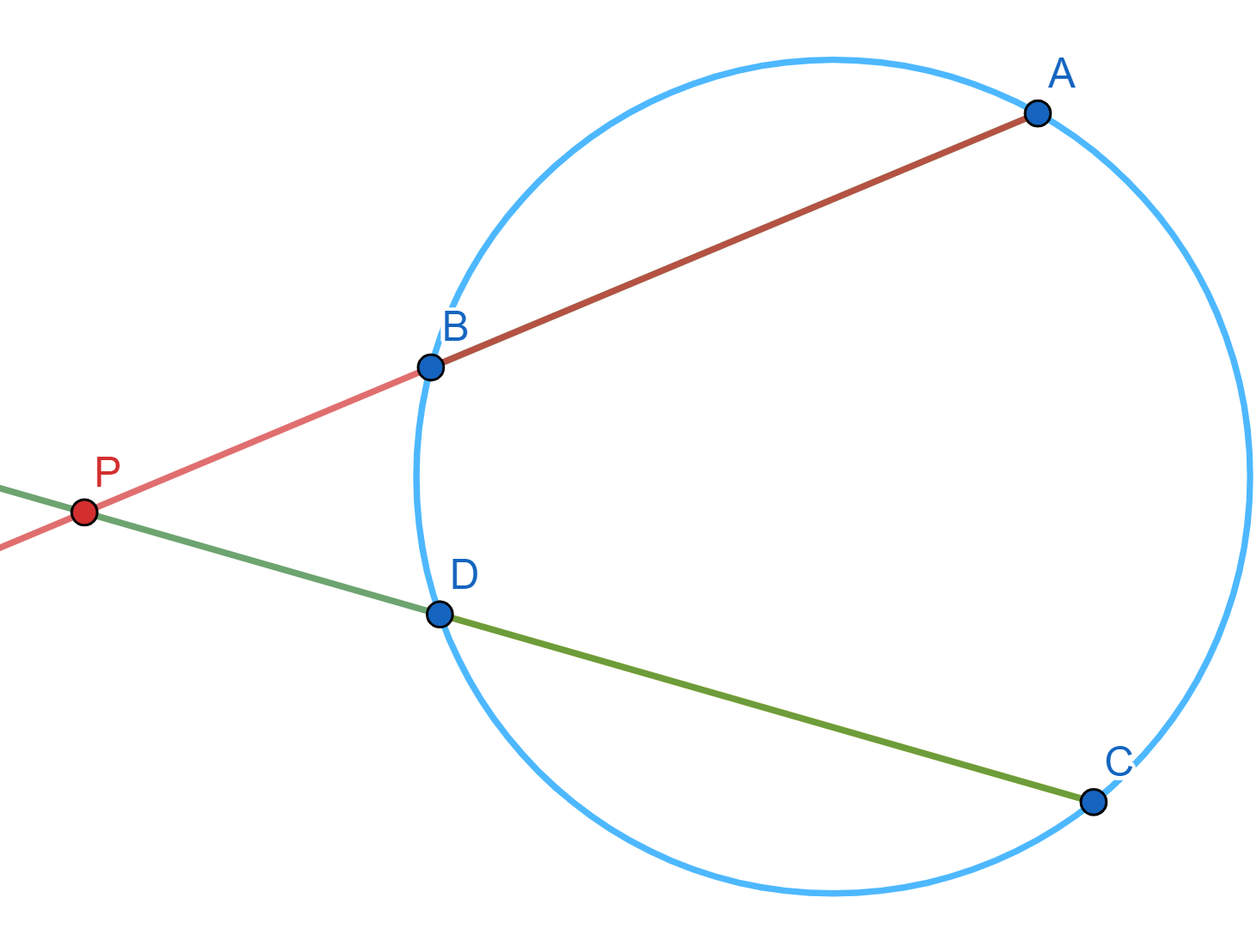
Ahora, $AB$ y $CD$ son dos secantes que se intersecan en $P$, pero con $P$ exterior a $\mathcal{C}$. Tenemos que $\triangle APC $ y $\triangle DPB $ son semejantes, ya que:
El cuadrilátero $\square ABDC$ es cíclico, entonces: $\angle ACD + \angle ABD = 180^\circ$ y $\angle ABD + \angle DBP = 180^\circ $, de donde $\angle DBP = \angle ACD$.
$\angle BPD$ y $\angle CPA$ son los mismos ángulos.
Entonces $\frac{PA}{PC}=\frac{PD}{PB},$ de donde se obtiene la igualdad buscada $PA\cdot PB=PC\cdot PD.$
Sobre la circunferencia:
Este caso es sencillo pues sin importar las secantes tomadas, en cada una hay un punto igual a $P$ y por lo tanto una distancia igual a cero. De este modo, $PA\cdot PB=0=PC\cdot PD$.
$\square$
Nota que las demostraciones anteriores sirven aunque $l$ ó $m$ sean tangentes, sólo que hay que hacer ligeras adaptaciones sobre los ángulos usados y los motivos por los que son iguales. Enunciaremos el caso de la tangencia un poco más abajo.
En vista de la proposición anterior, podemos simplificar nuestra definición notablemente.
Definición. Sea $\mathcal{C}$ una circunferencia y $P$ un punto. Tomemos $l$ una recta que intersecta a $\mathcal{C}$. Sean $A$ y $B$ los puntos de intersección de $l$ y $\mathcal{C}$ ($A=B$ si $l$ es tangente a $\mathcal{C}$). La potencia de $P$ con respecto a $\mathcal{C}$ es la cantidad $PA\cdot PB$. Usaremos la siguiente notación: $$\text{Pot}(P,\mathcal{C}):=PA\cdot PB.$$
La potencia queda bien definida sin importar la recta $l$, debido a la proposición anterior.
El signo de la potencia
En esta definición estamos usando segmentos dirigidos, y eso nos lleva a que la potencia de un punto puede tener distintos signos. El comportamiento queda determinado por el siguiente resultado.
Proposición. La potencia de un punto $P$ con respecto a una circunferencia $\mathcal{C}$ es positiva, negativa o cero, de acuerdo a si el punto $P$ está fuera de $\mathcal{C}$, dentro de ella, o sobre ella, respectivamente.
Demostración. Veamos esto caso por caso.
Sea $P$ un punto externo a $\mathcal{C}$. Entonces $PA$ y $PB$ tienen la misma orientación y por lo tanto el mismo signo. Además, como $P$ no está sobre $\mathcal{C}$, ninguno de ellos es cero. Así, $\text{Pot}(P,\mathcal{C})> 0$.
Sea $P$ un punto interno a $\mathcal{C}$. Entonces $PA$ está dirigido hacia un lado y $PB$ está dirigido hacia el otro, de modo que tienen signo contrario. Además, ninguno de ellos es cero. Así, $\text{Pot}(P,\mathcal{C})<0$.
Finalmente, sea $P$ un punto sobre $\mathcal{C}$. Esto quiere decir que alguno de los puntos $A$ o $B$ es $P$ (quizás ambos, si $l$ es tangente). Así, $PA=0$ ó $PB=0$. De este modo $\text{Pot}(P,\mathcal{C})=0$.
$\square$
Otras fórmulas para la potencia
La potencia es invariante sin importar la recta elegida. De este modo, podemos elegir a una recta tangente y obtener una fórmula para la potencia en términos de la longitud de dicha tangente.
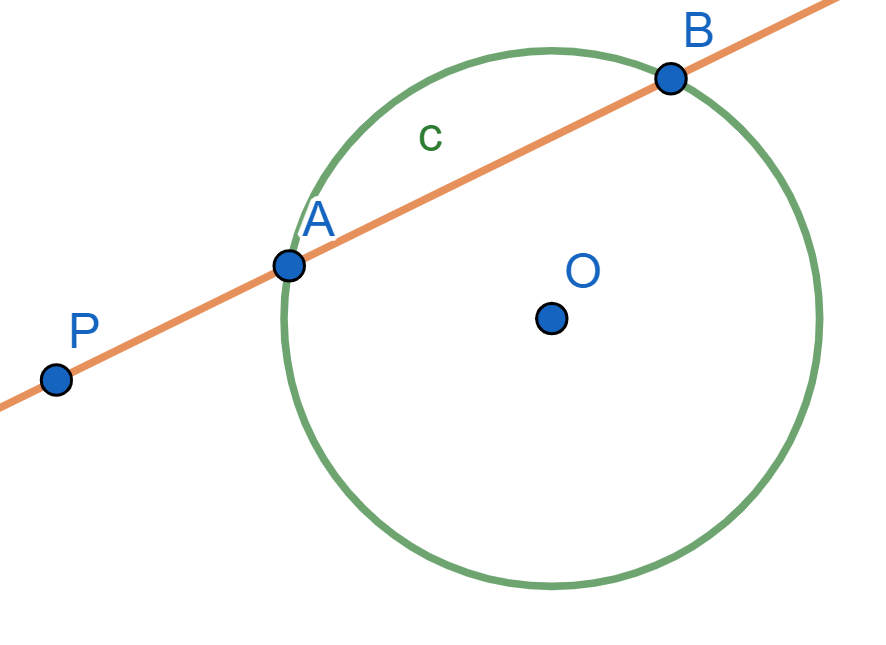
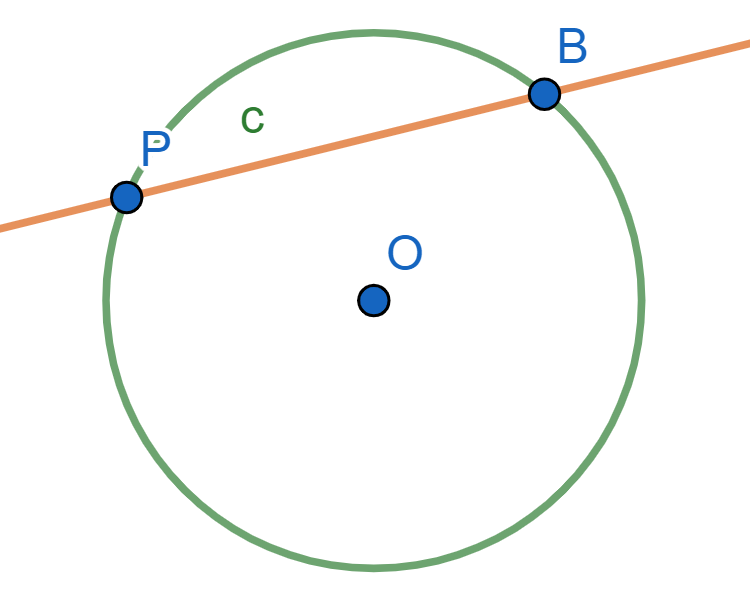
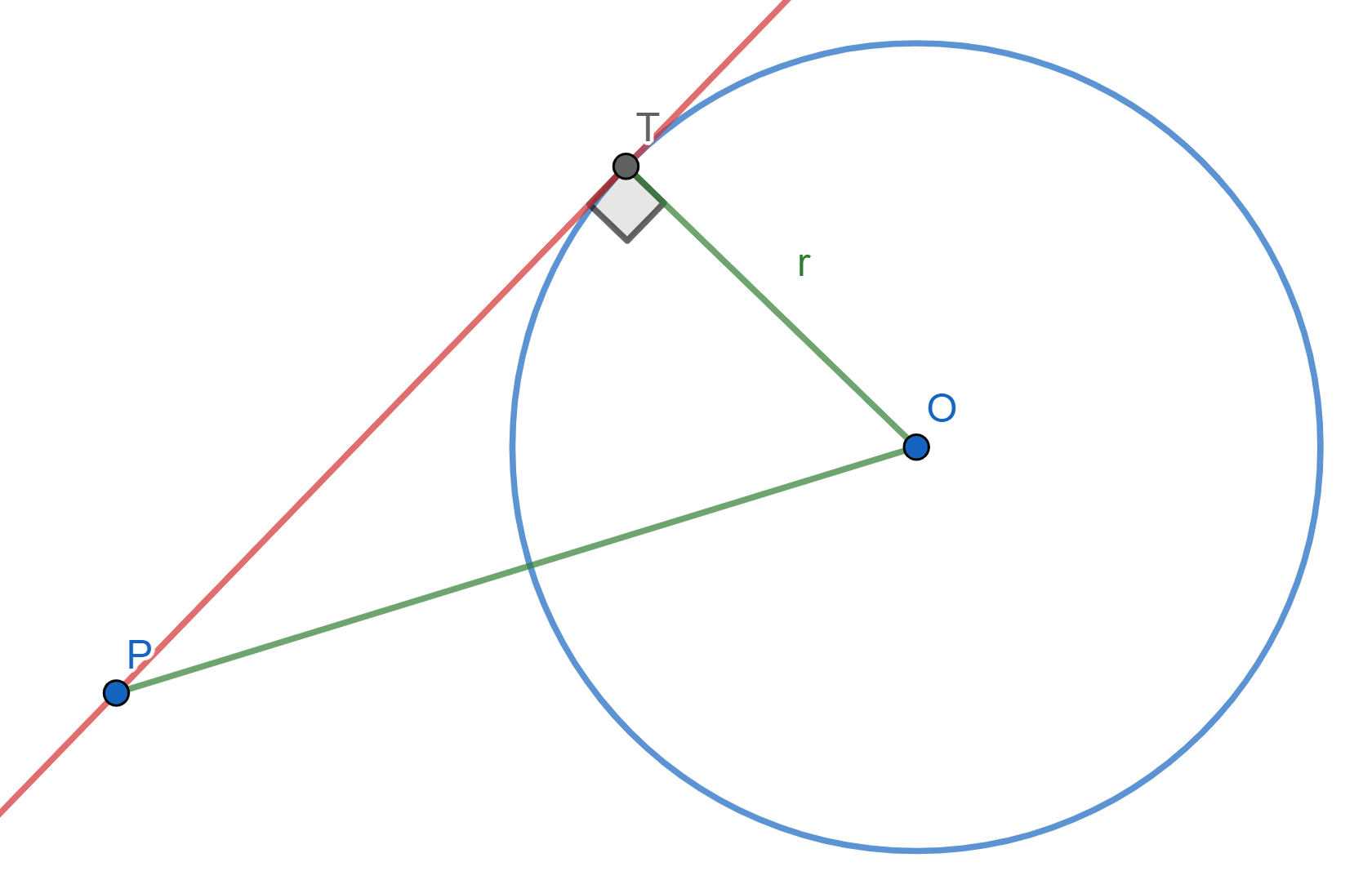
Proposición. Sea $\mathcal{C}$ una circunferencia. Para un punto $P$ fuera de $\mathcal{C}$, su potencia es igual al cuadrado de la longitud de una tangente de él a la circunferencia.
Es decir, sea $T$ un punto sobre la circunferencia tal que $PT$ sea tangente a $\mathcal{C}$. Entonces, $\text{Pot}(P,\mathcal{C})=PT^2$.
El resultado se sigue de llevar al límite lo que ya probamos en la proposición de invarianza de la potencia. Pero a continuación damos un argumento alternativo.
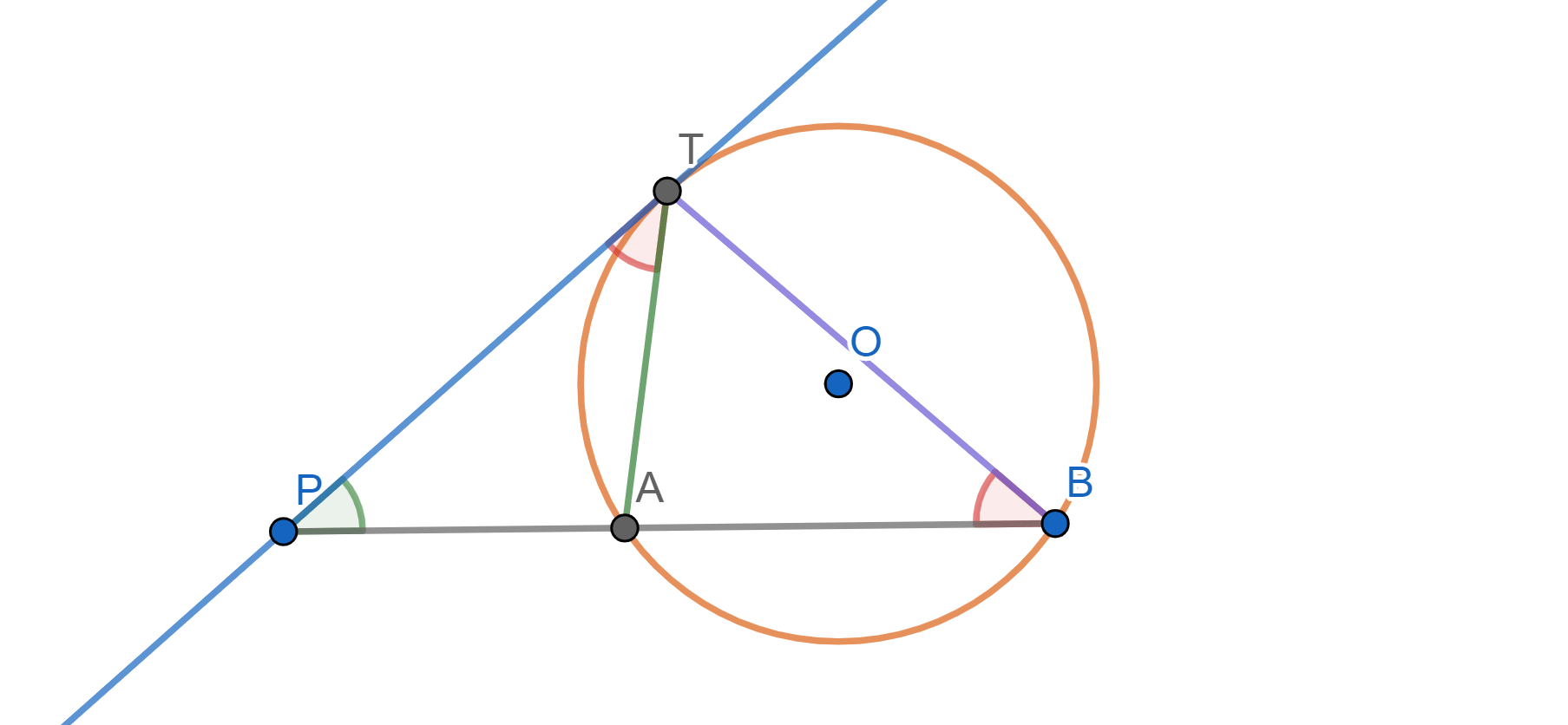
Demostración. Tracemos otra recta por $P$ que no sea tangente a $\mathcal{C}$ y cuyos puntos de intersección con $\mathcal{C}$ son $A$ y $B$ como en la figura. Tenemos que mostrar que $PA\cdot PB =PT^2$.
El ángulo $\angle PTA$ es semi-inscrito y es igual al ángulo inscrito $ \angle TBA$, pues ambos tienen el mismo arco $\overline{AT}$.
Entonces los triángulos $\triangle APT$ y $\triangle TPB$ comparten el ángulo con vértice en $P$ y $\angle PTA=\angle TBA$. Por ello, se tiene que $\triangle APT \cong \triangle TPB $ son semejantes y sus lados son proporcionales: $\frac{PA}{PT} = \frac{PT}{PB}$. De aquí, $$PT^2=PT\cdot PT=PA\cdot PB=\text{Pot}(P,\mathcal{C}).$$
$\square$
También es posible conocer la potencia de un punto hacia una circunferencia si conocemos el radio de la circunferencia y la distancia del punto al centro.
Proposición. Sea $\mathcal{C}$ una circunferencia de centro $O$ y radio $r$. Sea $P$ un punto en cualquier posición. La potencia de $P$ con respecto a $\mathcal{C}$ es $$\text{Pot}(P,\mathcal{C}) = OP^2 – r^2.$$
Demostración. Haremos la demostración por casos
Dentro de la circunferencia:
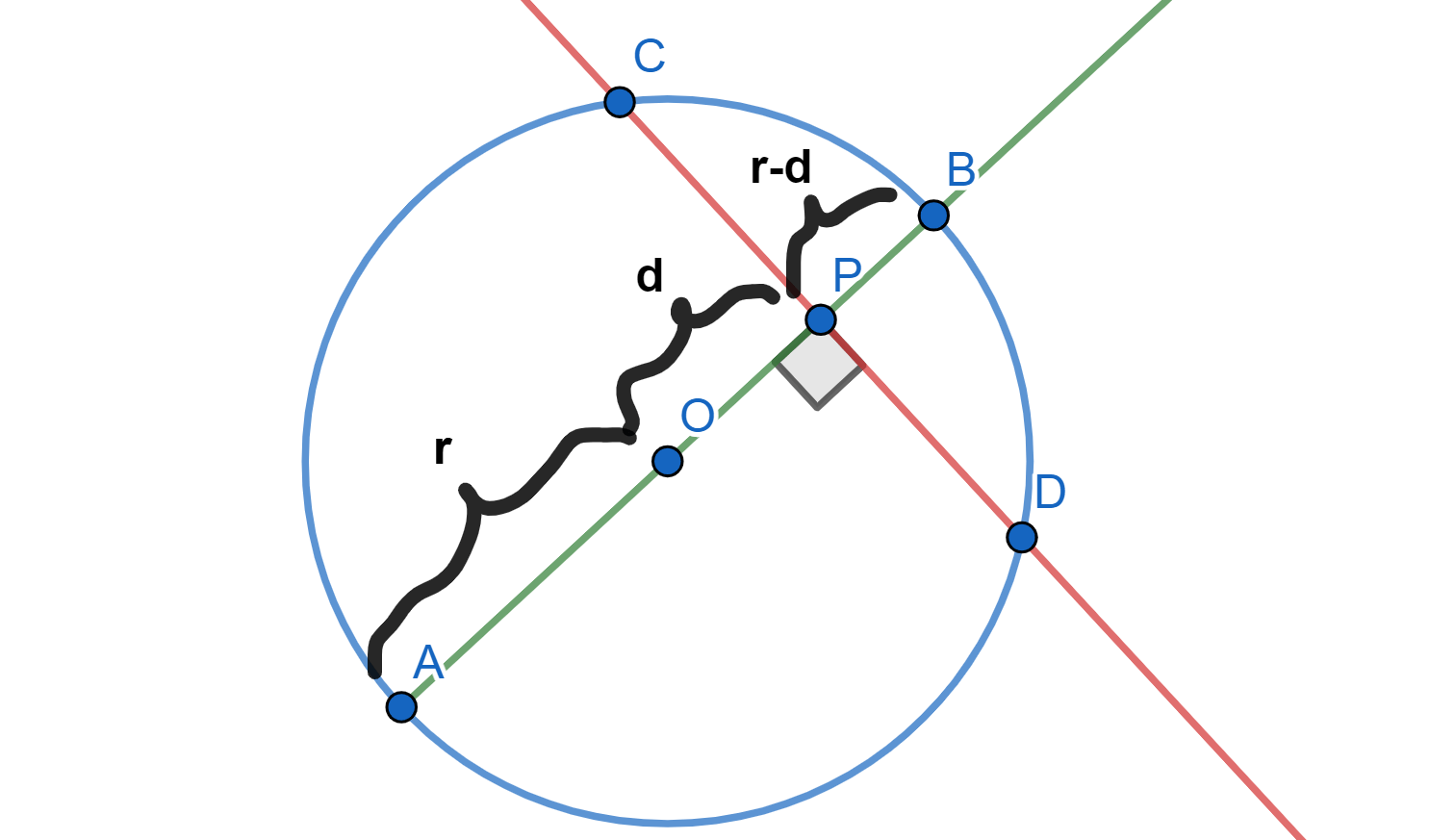
Sea $AB$ la cuerda que pasa por el centro $O$ y $P$ (si $O=P$, tomamos cualquier cuerda $AB$ por el centro). Supongamos sin pérdida de generalidad que la recta está dirigida de $A$ a $B$. Tenemos que $AO=r>0$ y llamemos $d=OP>0$. De aquí, $PB=r-d>0$. La siguiente figura resume estas igualdades.
La potencia desde $P$ sería entonces, cuidando los signos:
Ahora desde $P$ tracemos una tangente $PT$ a $\mathcal{C}$ con $T$ sobre $\mathcal{C}$. Como $\angle PTO =90^o$, entonces $\triangle POT$ es un triángulo rectángulo.
Por el teorema de Pitágoras y la expresión de potencia en términos de la tangente: $$OP^2=r^2+PT^2=r^2+\text{Pot}(P,\mathcal{C}).$$ Despejando, obtenemos la expresión deseada: $$\text{Pot}(P,\mathcal{C})=OP^2-r^2.$$
Sobre la circunferencia:
Este caso es sencillo, pues sabemos que la potencia de $P$ debe ser cero. Pero además, como $P$ está en la circunferencia, entonces $OP=r$, de modo que $OP^2-r^2=0$, y entonces la expresión también es lo que queremos.
$\square$
Más adelante…
Seguiremos abordando el tema de potencia de un punto y veremos cómo a partir de él se define el eje radical de dos circunferencias.
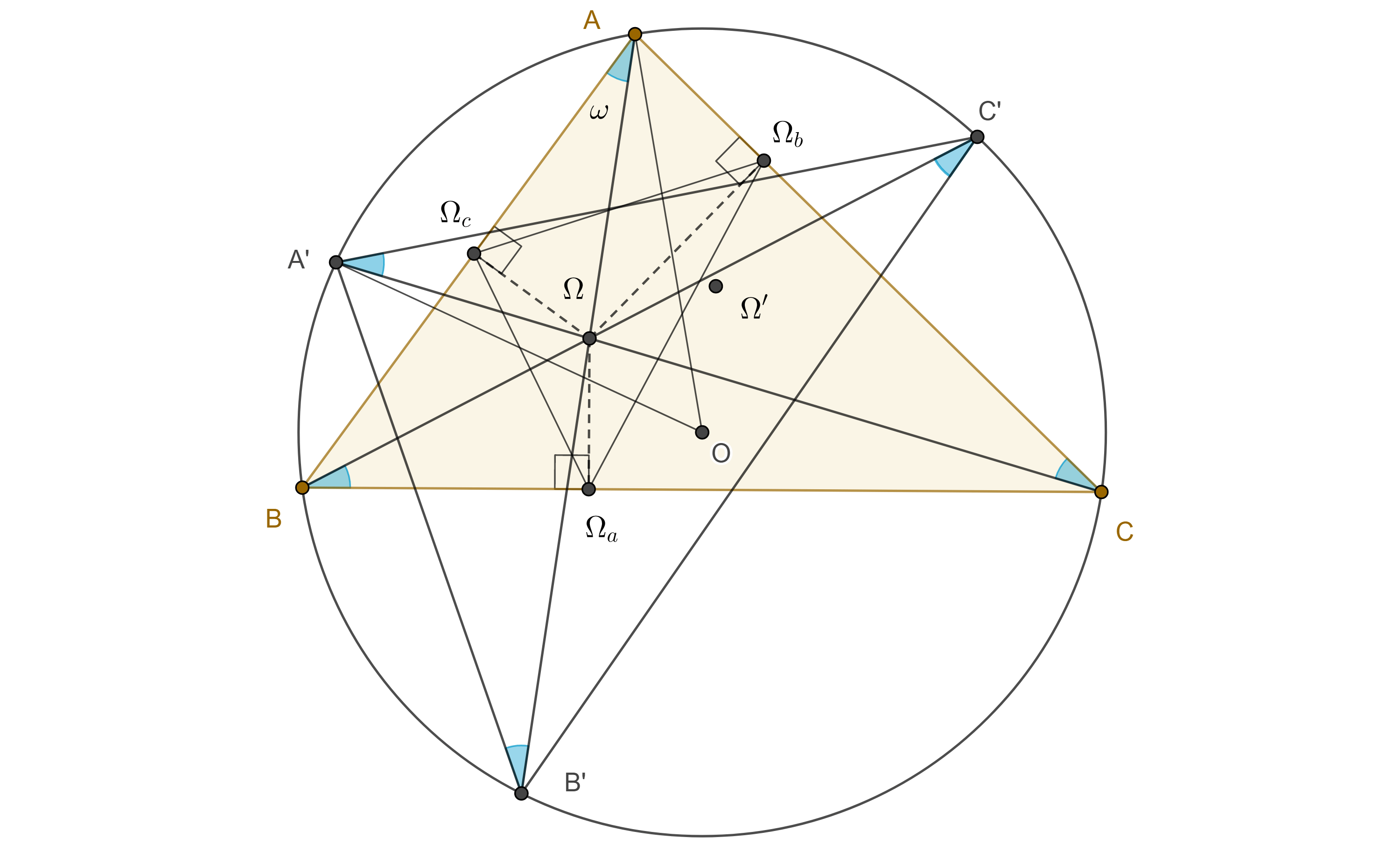
En esta entrada hablaremos sobre un par de puntos conjugados isogonales del triángulo, los puntos de Brocard, que surgen de una construcción particular de circunferencias tangentes a los lados del triángulo.
Puntos de Brocard
Definición y notación. Dado un triángulo $\triangle ABC$, considera $\Gamma(BC)$ la circunferencia tangente a $BC$ en $B$ que pasa por $A$, $\Gamma(CA)$ la circunferencia tangente a $CA$ en $C$ que pasa por $B$, $\Gamma(AB)$ la circunferencia tangente a $AB$ en $A$ que pasa por $C$. Llamaremos a este conjunto de circunferencias, grupo directo de circunferencias.
De manera análoga, la circunferencia $\Gamma(CB)$ tangente a $BC$ en $C$ que pasa por $A$, la circunferencia $\Gamma(AC)$ tangente a $CA$ en $A$ que pasa por $B$ y la circunferencia $\Gamma(BA)$ tangente a $AB$ en $B$ que pasa por $C$, seran referidas como grupo indirecto de circunferencias.
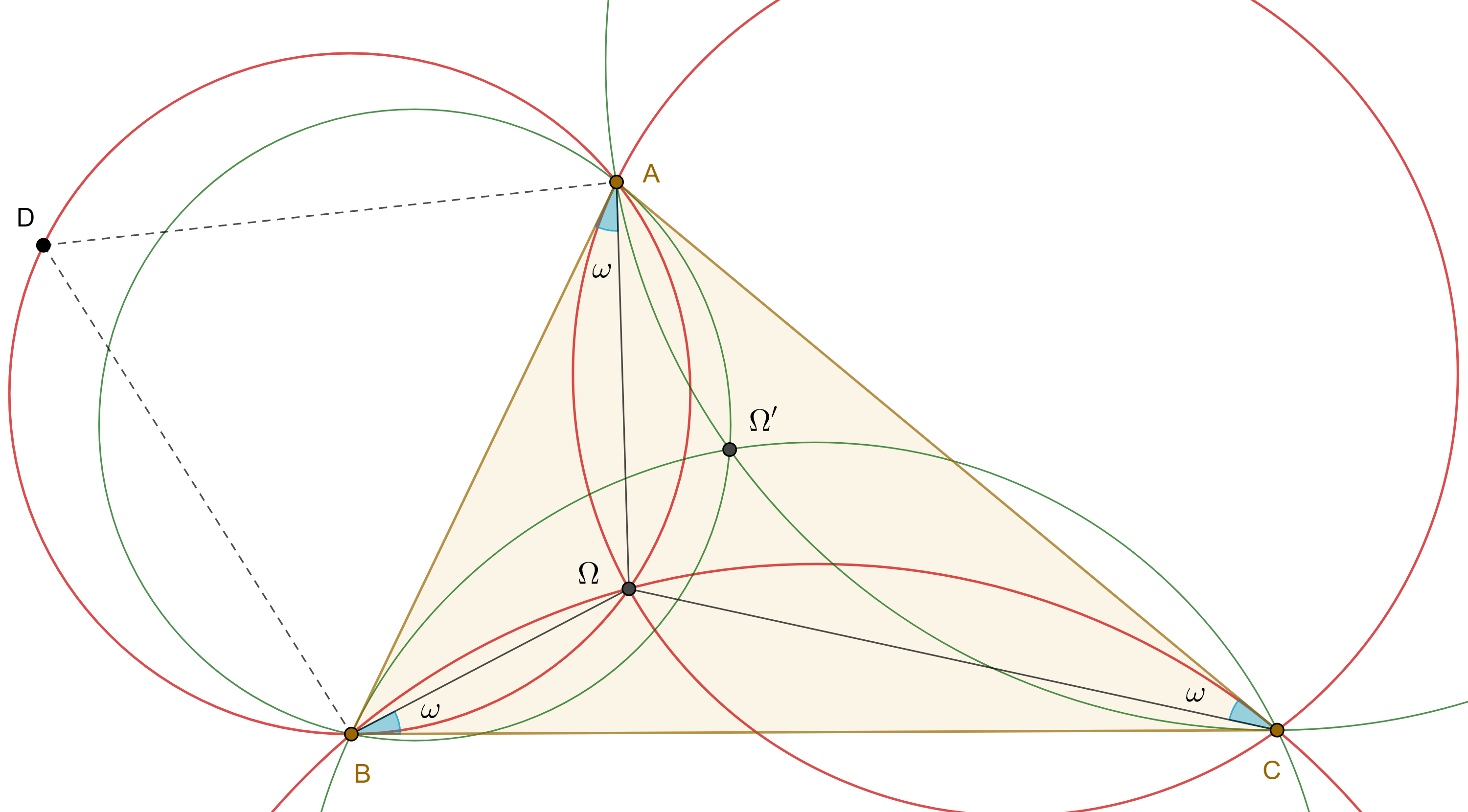
Teorema 1. Las tres circunferencias del grupo directo (indirecto) asociado a un triángulo tienen un punto en común, al punto de concurrencia $\Omega$ $(\Omega’)$ se le conoce como primer(segundo) punto de Brocard.
Demostración. Sean $\triangle ABC$ y $\Omega = \Gamma(BC) \cap \Gamma(CA)$, considera $D \in \overset{\LARGE{\frown}}{AB}$ arco de $\Gamma(BC)$, recorrido en ese sentido.
Como $\angle CBA$ es un ángulo semiinscrito de $\Gamma(BC)$ entonces $\angle BDA = \angle CBA$, por lo tanto, $\angle A\Omega B = \pi – \angle B$.
Figura 1
De manera análoga vemos que $\angle B\Omega C = \pi – \angle C$.
En consecuencia, $\angle C\Omega A = 2\pi – (\angle A\Omega B) – (\angle B\Omega C) $ $= 2\pi – (\pi – \angle B) – (\pi – \angle C) = \angle B + \angle C $ $= \pi – \angle A$.
Por otra parte, como $\angle BAC$ es un ángulo semiinscrito de $\Gamma(AB)$, entonces todos los puntos en el arco $\overset{\LARGE{\frown}}{CA}$, recorrido en ese sentido, subtienden un ángulo $\angle A$ con la cuerda $CA$, por lo tanto, el arco $\overset{\LARGE{\frown}}{AC}$ es el lugar geométrico de los puntos que subtienden con la cuerda $CA$ un ángulo igual a $\pi – \angle A$.
En conclusión $\Omega \in \Gamma(AB)$.
La demostración es análoga para el caso del grupo indirecto.
$\blacksquare$
Corolario 1. Los dos puntos de Brocard son los únicos puntos dentro de un triángulo $\triangle ABC$ que tienen la siguiente propiedad: $i)$ $\angle BA\Omega = \angle CB\Omega = \angle AC\Omega $, $ii)$ $\angle \Omega’ AC = \angle \Omega’ CB = \angle \Omega’ BA$.
Demostración. $i)$ $\angle BA\Omega$ y $\angle CB\Omega$ son ángulos inscrito y semiinscrito respectivamente de $\Gamma(BC)$ que abarcan el mismo arco, por lo tanto son iguales.
De manera análoga vemos que $\angle CB\Omega = \angle AC\Omega$.
Por otro lado supongamos que existe un punto $F$ dentro de $\triangle ABC$ tal que $\angle BAF = \angle CBF = \angle ACF$, considera el circuncírculo de $\triangle ABF$, como $\angle CBF$ es igual al ángulo inscrito $\angle BAF$, entonces $BC$ debe ser tangente al circuncírculo de $\triangle ABF$ en $B$, por lo tanto, $F \in \Gamma(BC)$.
De manera análoga vemos que $F \in \Gamma(CA)$ y $F \in \Gamma(AB)$ por lo tanto $F$ coincide con $\Omega$.
Demostración. Si $X$ es el conjugado isogonal de $\Omega$ entonces (figura 1) $\angle BA\Omega = \angle XAC$, $\angle CB\Omega = \angle XBA$, $ \angle AC\Omega = \angle XCB$.
Pero $\angle BA\Omega = \angle CB\Omega = \angle AC\Omega = \omega$, por lo tanto, el conjugado isogonal de $\Omega$ respecto a $\triangle ABC$ cumple que $\angle XAC = \angle XBA = \angle XCB$.
Como $\Omega’$ es el único punto que tiene esa propiedad dentro de $\triangle ABC$ entonces $X = \Omega’$.
$\blacksquare$
Definición 2. Los segmentos $A\Omega$, $A\Omega’$; $B\Omega$, $B\Omega’$; $C\Omega$, $C\Omega’$, se conocen como rayos de Brocard y el ángulo $\angle BA\Omega = \angle \Omega’AC = \omega$ se conoce como ángulo de Brocard.
Definición 3. Los lados del triángulo anticomplementario de un triángulo dado (las rectas paralelas a los lados de un triángulo por los vértices opuestos), se llaman exmedianas del triángulo dado.
Teorema 2. Una exsimediana, una exmediana y un rayo de Brocard, cada una por un vértice distinto de un triángulo dado, son concurrentes.
Demostración. En $\triangle ABC$ sea $B\Omega$ el rayo de Brocard que pasa por el primer punto de Brocard y $D$ la intersección de este rayo con la exmediana por $A$.
Figura 2
Como $AD \parallel BC$ entonces $\angle CAD = \angle C$ y $\angle ADB = \angle CB\Omega = \omega = \angle AC\Omega$, por lo tanto, $\square A\Omega CD$ está inscrito en $\Gamma(AB)$.
Por el corolario 1, $\angle C\Omega A = \angle B + \angle C$, esto implica que $\angle ADC = \angle A$, por lo tanto, $\angle DCA = \angle B$.
Como resultado $CD$ es exsimediana de $\triangle ABC$, es decir, es tangente al circuncírculo de $\triangle ABC$ en $C$.
$\blacksquare$
Corolario 3. El ángulo de Brocard $\omega$ de un triángulo $\triangle ABC$ satisface la siguiente igualdad $\cot \omega = \cot \angle A + \cot \angle B + \cot \angle C$
Demostración. En la figura anterior sean $H_a$, $H_d$ las proyecciones de $A$ y $D$ en $BC$, como $\angle DCA = \angle B$ entonces $\angle H_dCD = \angle A$, por lo tanto, $\cot \omega = \dfrac{BH_d}{DH_d}$ $= \dfrac{BH_a}{DH_d} + \dfrac{H_aC}{DH_d} + \dfrac{CH_d}{DH_d}$ $= \dfrac{BH_a}{AH_a} + \dfrac{H_aC}{AH_a} + \dfrac{CH_d}{DH_d}$ $ = \cot \angle B + \cot \angle C + \cot \angle A$.
$\blacksquare$
Construcción de un triángulo dado su ángulo de Brocard
Problema. Construye un triángulo, dados un lado, un ángulo y $\omega$, su ángulo de Brocard.
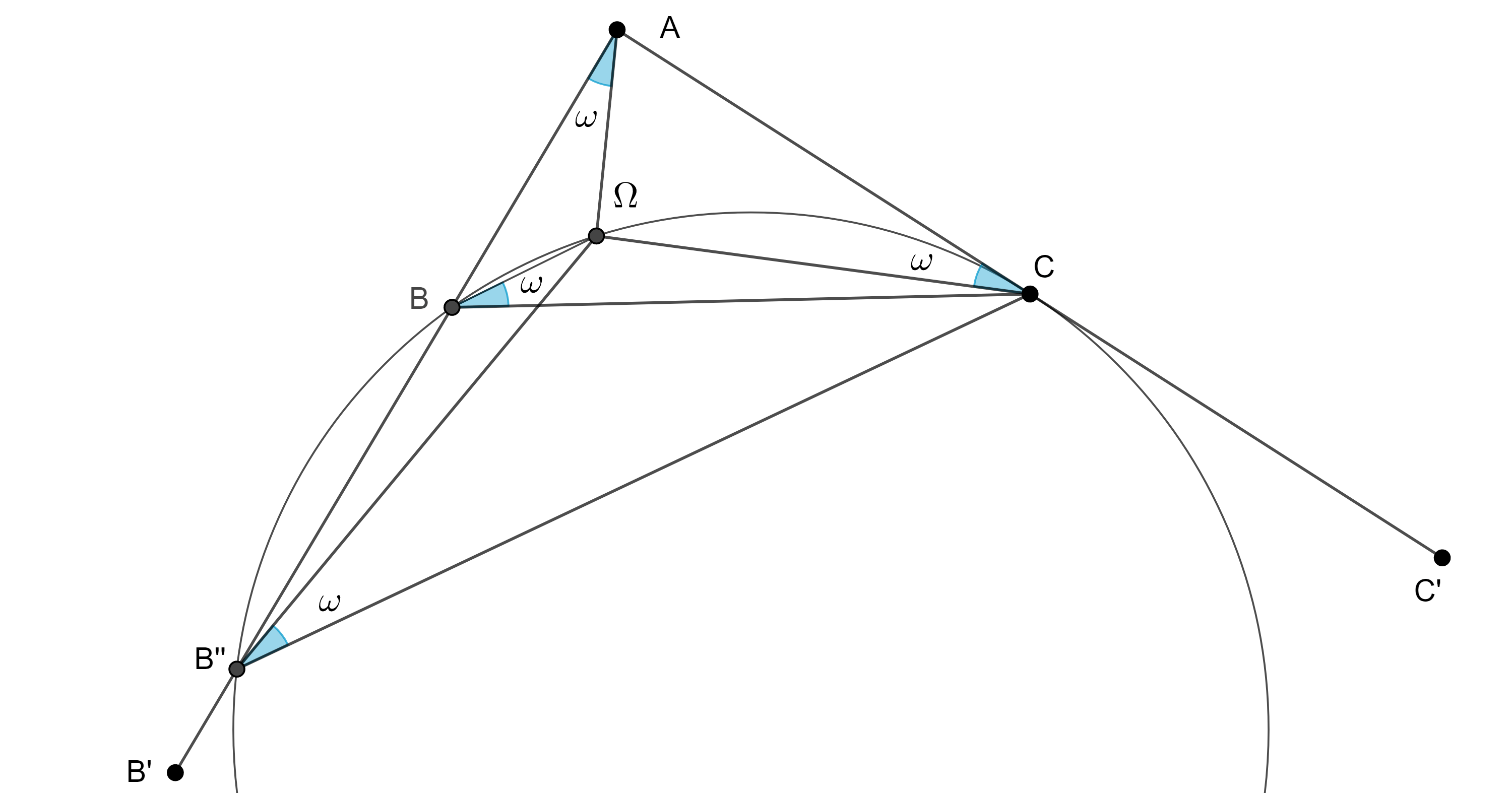
Solución. Sea $\angle B’AC’$ el ángulo dado, en $AC’$ tomamos un punto $C$ arbitrario, sobre $CA$ y con vértice en $C$ abrimos un ángulo igual a $\omega$ en el sentido contrario al de las manecillas del reloj, hacemos lo mismo pero esta vez sobre $AB$ en y vértice en $A$.
Figura 3
La intersección de los segundos lados de los ángulos construidos será $\Omega$, el primer punto de Brocard, ahora sobre $\Omega C$ construimos el lugar geométrico de los puntos que subtienden un ángulo igual a $\omega$ con los puntos $\Omega$ y $C$, el cual es un arco de circunferencia.
Este arco puede intersecar a $AB’$ en dos puntos $B$ y $B’’$, entonces obtenemos $\triangle ABC$ y $\triangle ACB’’$, sin embargo, estos dos triángulos son semejantes, si este arco no interseca a $AB$ entonces no hay solución.
$\triangle ABC$ es semejante al triangulo requerido, el cual puede ser construido a partir del lado dado.
$\blacksquare$
Triángulo circunscrito de ceva de los puntos de Brocard
Teorema 3. $i)$ Los rayos de Brocard intersecan otra vez al circuncírculo del triángulo, en tres puntos que forman un triángulo congruente con el triángulo original, $ii)$ este triángulo puede ser obtenido rotando el triángulo original un ángulo igual a dos veces su ángulo de Brocard con centro en el circuncentro, $iii)$ el primer (segundo) punto de Brocard del triángulo original es el segundo (primer) punto de Brocard del triángulo rotado.
Demostración. Sea $\Omega$ el punto positivo de Brocard de $\triangle ABC$, consideremos $B’$, $C’$, $A’$ las segundas intersecciones de $A\Omega$, $B\Omega$, $C\Omega$ con el circuncírculo de $\triangle ABC$.
Por lo tanto $\Omega$ es el segundo punto de Brocard de $\triangle A’B’C’$.
$\blacksquare$
Corolario 4. Los dos puntos de Brocard de un triángulo son equidistantes del circuncentro del triángulo.
Demostración. Si partimos esta vez del triángulo $\triangle A’B’C’$ y hacemos una rotación un ángulo igual a $2\omega$ con centro en $O$ en el sentido de las manecillas del reloj, entonces su segundo punto de Brocard coincidirá con el segundo punto de Brocard de $\triangle ABC$.
Ya que el segundo punto de Brocard de $\triangle A’B’C’$, es el primer punto de Brocard de $\triangle ABC$, entonces estos puntos son equidistantes a $O$.
$\blacksquare$
Triángulo pedal de los puntos de Brocard
Corolario 5. El triángulo pedal del primer (segundo) punto de Brocard es semejante a su triángulo de referencia, además el primer (segundo) punto de Brocard es el mismo para ambos triángulos.
Demostración. En la figura anterior, sean $\Omega_a$, $\Omega_b$, $\Omega_c$, las proyecciones de $\Omega$ en $BC$, $CA$, $AB$, respectivamente.
En la entrada anterior mostramos que para cualquier punto $\omega$, su triángulo pedal $\triangle \Omega_a\Omega_b\Omega_c$, es semejante a su triángulo circunscrito de Ceva respecto de $\triangle B’C’A’$.
Por el teorema anterior, $\triangle ABC \cong \triangle A’B’C’$, por lo tanto $\triangle \Omega_c\Omega_a\Omega_b \sim \triangle ABC$.
Por otro lado, como $\square \Omega_cB\Omega_a\Omega$ es cíclico entonces $\angle \Omega\Omega_c\Omega_a = \angle \Omega B\Omega_a = \omega$.
Igualmente vemos que $\angle \Omega\Omega_a\Omega_b = \omega = \angle \Omega\Omega_b\Omega_c$.
La prueba es análoga para el caso del segundo punto de Brocard.
$\blacksquare$
Corolario 6. Los triángulos pedales de los dos puntos de Brocard de un triángulo son congruentes.
Demostración. Como los dos puntos de Brocard de un triángulo son conjugados isogonales, entonces sus triangulo pedales tienen el mismo circuncírculo y como son semejantes, entonces son congruentes.
$\blacksquare$
Más adelante…
Continuando con el tema de geometría de Brocard, en la siguiente entrada hablaremos de la circunferencia de Brocard, veremos que los puntos de Brocard están en esta circunferencia y que estos permiten la construcción de un triángulo que es semejante y esta en perspectiva con el triángulo original.
Tarea moral
A continuación hay algunos ejercicios para que practiques los conceptos vistos en esta entrada. Te será de mucha utilidad intentarlos para entender más la teoría vista.
Altshiller, N., College Geometry. New York: Dover, 2007, pp 274-278.
Johnson, R., Advanced Euclidean Geometry. New York: Dover, 2007, pp 263-270.
Honsberger, R., Episodes in Nineteenth and Twentieth Century Euclidean Geometry. Washington: The Mathematical Association of America, 1995, pp 99-106.
Shively, L., Introducción a la Geómetra Moderna. México: Ed. Continental, 1961, pp 71-73.
Aref, M. y Wernick, W., Problems and Solutions in Euclidean Geometry. New York: Dover, 2010, pp 188-191.
Agradecimientos
Trabajo realizado con el apoyo del Programa UNAM-DGAPA-PAPIME PE104522 «Hacia una modalidad a distancia de la Licenciatura en Matemáticas de la FC-UNAM – Etapa 2»
Continuando con lo visto en la entrada anterior, en esta entrada presentaremos algunas propiedades fundamentales del valor esperado. Lo primero que veremos será el valor esperado de una constante, que será una propiedad muy básica pero de uso muy frecuente en la teoría que veremos.
Por otro lado, veremos un teorema muy importante desde los puntos de vista teórico y práctico, conocido como la ley del estadístico inconsciente. A grandes rasgos, este teorema hará posible obtener el valor esperado de \(g(X)\), donde \(X\) es una v.a. y \(g\) es una función.
Valor esperado de una función constante
La primera propiedad importante es que el valor esperado de una constante es la constante misma. Esto tiene sentido, pues si una v.a. toma un único valor $a \in \RR$, entonces se espera que su promedio a la larga sea $a$.
Propiedad. Sea $a \in \RR$ y $f_{a}\colon\Omega\to\RR$ la función constante $a$, de tal modo que $f_{a}(\omega) = a$ para cada $\omega \in \Omega$. Entonces se tiene que
\begin{align*} \Esp{f_{a}} &= a. \end{align*}
Abusando un poco de la notación, lo anterior significa que para cualquier valor constante $a \in \RR$ se cumple que $\Esp{a} = a$.
Demostración. Sea $a \in \RR$ y sea $(\Omega, \mathscr{F}, \mathbb{P})$ un espacio de probabilidad. Se define la función constante $a$ $f_{a}\colon\Omega\to\RR$ como sigue: para cada $\omega\in\Omega$, $f_{a}(\omega) = a$. Se sigue inmediatamente que $f_{a}[\Omega] = \{ a \}$, por lo que $f_{a}$ es una v.a. discreta. De este modo,
\begin{align*} \Esp{f_{a}} &= \sum_{x\in f_{a}[\Omega]} x \Prob{f_{a} = x} \\[1em] &= \sum_{x\in\{a\}} x \Prob{f_{a} = x} \\[1em] &= a \Prob{f_{a} = a} \end{align*}
Ahora, como $f_{a}[\Omega] = \{ a \}$, entonces $f_{a}^{-1}[f_{a}[\Omega]] = f_{a}^{-1}[\{a\}]$, por lo que $\Omega = f_{a}^{-1}[\{ a \}]$. En consecuencia, se tiene que $(f_{a} = a) = \Omega$. Así, llegamos a que
\begin{align*} a \Prob{f_{a} = a} &= a \Prob{ \Omega } = a \cdot 1 = a, \end{align*}
por lo que podemos concluir que
\begin{align*} \Esp{f_{a}} &= a, \end{align*}
que es justamente lo que queríamos demostrar.
$\square$
Valor esperado de la transformación de una v.a.
Otra propiedad importante del valor esperado surge cuando queremos calcular el valor esperado de la transformación de una v.a. Para hacerlo, aparentemente necesitaríamos obtener la densidad o la masa de probabilidad de la transformación para luego calcular su valor esperado. Afortunadamente, esto no será necesario.
Si $X\colon\Omega\to\RR$ es una v.a. y $g\colon\RR\to\RR$ es una función tal que $g(X)$ es una v.a., hay que recordar que la distribución de $g(X)$ puede obtenerse en términos de la de $X$, por lo que el comportamiento probabilístico de $g(X)$ puede expresarse en términos del de $X$. Debido a esto, ¡también el valor esperado de $g(X)$ puede obtenerse usando la densidad o la masa de probabilidad de $X$!
La ley del estadístico inconsciente
De acuerdo con la discusión anterior, presentamos un teorema que posibilita el cálculo del valor esperado de una v.a. $g(X)$ conociendo únicamente la densidad de $X$. Este resultado es conocido como la ley del estadístico inconsciente. ¡Advertencia! La teoría con la que contamos hasta el momento hace necesario dividir la demostración en dos casos: uno para v.a.’s discretas y otro para v.a.’s continuas. En particular, la demostración para el caso discreto es clara y puedes centrar tu atención en ella, ya que te puede brindar una intuición firme de lo que pasa también en el caso continuo. Por el contrario, la demostración del caso continuo es un poco más técnica, e incluso requiere el uso de herramientas que quizás no hayas visto hasta ahora. Durante la demostración te comentaremos cuáles son estas herramientas, y las materias posteriores de la carrera en donde posiblemente las veas.
Teorema. Sea $X\colon\Omega\to\RR$ una v.a. y $g\colon\RR\to\RR$ una función Borel-medible.
Si $X$ es una v.a. discreta, entonces \begin{align*} \Esp{g(X)} &= \sum_{x \in X[\Omega]} g(x) \Prob{X = x}, \end{align*}siempre que esta suma sea absolutamente convergente.
Si $X$ y $g(X)$ son v.a.’s continuas, entonces \begin{align*} \Esp{g(X)} &= \int_{-\infty}^{\infty} g(x) f_{X}(x) \, \mathrm{d}x, \end{align*} siempre que esta integral sea absolutamente convergente, y donde $f_{X}\colon\RR\to\RR$ es la función de densidad de $X$.
Demostración.1. El caso discreto sirve para ilustrar la intuición, pues para cada $x \in X[\Omega]$ se tiene que $g(x) \in (g \circ X)[\Omega]$. Además, ya sabemos que para cada $y \in (g \circ X)[\Omega]$ se cumple que
y cada uno de estos términos es una suma que corre sobre $x$, donde $x \in g^{-1}[\{ y \}]$. Es decir, estamos sumando sobre todos los $y \in (g \circ X)[\Omega]$, y en cada $y$ tomamos la suma sobre todos los $x \in g^{-1}[\{y \}]$. Esto quiere decir que podemos mover a $x$ sobre la unión de todos los $g^{-1}[\{y\}]$, y prescindir de la suma sobre $y$. Esto es,
y por propiedades de la imagen inversa, se tiene que $X[\Omega] \subseteq g^{-1}[g[X[\Omega]]]$. Ahora bien, los $x$ que aparecen en la suma son únicamente aquellos que están en $X[\Omega]$, pues de lo contrario son valores que no toma la v.a. $X$. En consecuencia, la suma se puede reducir a
que es justamente lo que queríamos demostrar. Intuitivamente, esta última igualdad hace sentido, pues $g(X)$ toma el valor $g(x)$ cuando $X$ toma el valor $x$, y el evento en el que eso ocurre tiene probabilidad $\Prob{X = x}$.
La demostración del caso 2. es menos ilustrativa. Cuando $X$ y $g(X)$ son v.a.’s continuas, será necesario hacer una «doble integral», algo con lo que quizás no te hayas encontrado hasta ahora. Esto es algo que (por desgracia) haremos en algunas demostraciones del valor esperado.
Primero, demostraremos el siguiente lema:
Lema. Si $X\colon\Omega\to\RR$ es una v.a. continua tal que para todo $\omega\in\Omega$ se cumple que $X(\omega) \geq 0$ (es decir, $X$ es una v.a. no-negativa), entonces
Es decir, $\mathbf{1}_{D}(x,y)$ vale $1$ si $(x,y) \in D$, es decir, vale $1$ si $x$ es mayor a $y$; y vale $0$ en caso contrario. Una función de este tipo es conocida como una función indicadora. Ahora, observa que para cualquier $x \in [0, \infty)$ se cumple que
\begin{align*} x &= \int_{0}^{x} 1 \, \mathrm{d}t, \tag{$*$}\end{align*}
pues la integral devuelve como resultado la longitud del intervalo $(0, x)$, que está bien definido, ya que $x \geq 0$. Dicha longitud es precisamente $x − 0 = x$, por lo que la igualdad $(*)$ es verdadera. Ahora, observa que $\mathbf{1}_{D}(x, t) = 1$ si y sólamente si $x > t$, o equivalentemente, si $t \in (-\infty, x)$. Así, tenemos que
pues para $t \in (0, \infty)$, $\mathbf{1}_{D}(x, t) = 1$ sobre $(0, x)$, y es $0$ en otro caso. En conclusión, para cualquier $x \in [0, \infty)$ se cumple que
\begin{align}\label{id:integral} x &= \int_{0}^{\infty} \mathbf{1}_{D}(x, t) \, \mathrm{d}t. \end{align}
Usaremos esta «mañosa» identidad en el valor esperado de $X$. Primero, observa que $X$ es una v.a. no-negativa, así que $f_{X}(x) = 0$ para $x < 0$. En consecuencia, tenemos que
\begin{align*} \Esp{X} &= \int_{-\infty}^{\infty} x f_{X}(x) \, \mathrm{d}x = \int_{0}^{\infty} x f_{X}(x) \, \mathrm{d}x. \end{align*}
Usando la identidad \eqref{id:integral}, obtenemos que
Observa que «metimos» a $f_{X}(x)$ dentro de la integral respecto a $t$ debido a que es una constante con respecto a $t$ (únicamente depende de $x$). La trampa que vamos a hacer es cambiar el orden de integración. Esto NO siempre se puede hacer, y la validez de este paso está dada por el teorema de Fubini, que verás en Cálculo Diferencial e Integral IV. Intercambiando el orden de integración, se tiene que
Ahora, observa que, para cada $x \in (0, \infty)$, $\mathbf{1}_{D}(x, t) = 1$ si y sólamente si $x > t$, o equivalentemente, si $x \in (t, \infty)$. En consecuencia,
Con este lema podemos demostrar el caso 2. del teorema. Lo que haremos será presentar el caso en el que $g$ es una función no-negativa. De esta manera, $g(X)$ es una v.a. que toma valores no-negativos, y podemos aplicarle el lema. Así, tenemos que
donde la integral de adentro se toma sobre $g^{-1}[(x, \infty)]$, pues esto nos devuelve el valor $\Prob{X \in g^{-1}[(x, \infty)]}$. Nuevamente haremos trampa y cambiaremos el orden de integración. Un detalle adicional es que al cambiar el orden de integración, también cambian los dominios de integración.
Como comentamos anteriormente, el teorema que acabamos de demostrar es conocido como la ley del estadístico inconsciente. De acuerdo con Sheldon M. Ross, en su libro Introduction to Probability Models (1980, 1a Ed.) «Esta ley recibió su nombre por los estadísticos ‘inconscientes’ que la han utilizado como si fuese la definición de $\Esp{g(X)}$».
Figura. Extracto del libro Statistical Inference, de George Casella y Roger Berger (2001, 2a Ed.), en el que los autores expresan su descontento por el nombre de este teorema.
Independientemente de esto, la ley del estadístico inconsciente es un resultado muy importante, y la utilizaremos mucho de aquí en adelante.
Ejemplos del uso de la ley del estadístico inconsciente
Ejemplo 1. Sea \(U\) una v.a. con función de densidad \(f_{U}\) dada por
Para resolver esta integral, observa que se trata de una integral casi inmediata, únicamente le falta el factor \(1 − \lambda\), por lo que multiplicamos por \(1\):
Como usualmente pasa con los valores esperados de v.a.’s que toman el valor \(0\), el primer término de la serie \eqref{eq:serie1} es \(0\), así que la igualdad anterior pasa a ser
Para obtener el valor de la serie anterior, vamos a utilizar una expresión equivalente basada en la siguiente identidad: sea \(n\in\mathbb{N}^{+}\), entonces se cumple que
Es decir, multiplicar la serie \eqref{eq:serie2} por \( (1 − p)\) nos da la \eqref{eq:serie3}, que simplemente «desplaza» el índice por \(1\). Por ello, se tiene que
Usaremos la igualdad \eqref{eq:serie4} más adelante. Por ahora, centraremos nuestra atención en desarrollar la serie en \eqref{eq:serie4}. Primero, recuerda que la serie debe de ser convergente para que los siguientes pasos tengan sentido, así que revisa la tarea moral en caso de que lo dudes. Así pues, tenemos que
Por un lado, observa que la expresión \((*)\) es el valor esperado de \(N\) (y ya calculamos ese valor esperado en la entrada pasada), así que \((*) = \frac{ 1 − p }{p}\). Por otro lado, la expresión \((*)\) es casi la suma de las probabilidades de \(N\), por lo que debería de ser \(1\) menos el término en \(0\), ya que la suma empieza en \(1\). Veámoslo:
\begin{align*} \sum_{n=1}^{\infty} (1 − p)^{n}p &= p − p + \sum_{n=1}^{\infty} (1 − p)^{n}p \\[1em] &= {\left[\sum_{n=0}^{\infty} (1 − p)^{n}p\right]} − p \\[1em] &= p\underbrace{\left[\sum_{n=0}^{\infty} (1 − p)^{n}\right]}_{\text{serie geométrica}} − p \\[1em] &= p \frac{1}{1 − (1 − p)} − p \\[1em] &= p\frac{1}{p} − p \\[1em] &= 1 − p. \end{align*}
Los siguientes ejercicios son opcionales. Es decir, no formarán parte de tu calificación. Sin embargo, te recomiendo resolverlos para que desarrolles tu dominio de los conceptos abordados en esta entrada.
Demuestra el caso 2. de la ley del estadístico inconsciente cuando $g$ es una función cualquiera. Sugerencia: Toma la siguiente descomposición de $g$: definimos la parte positiva de $g$, $g^{+}\colon\RR\to\RR$, como sigue: \begin{align*} g^{+}(x) &= \max{\{ g(x), 0 \}} & \text{para cada $x \in \RR$},\end{align*} y definimos la parte negativa de $g$, $g^{-}\colon\RR\to\RR$, como sigue: \begin{align*} g^{-}(x) &= \max{\{ -g(x), 0 \}} & \text{para cada $x \in \RR$}.\end{align*} Verifica que $g$ puede escribirse en términos de $g^{+}$ y $g^{-}$ como\begin{align*} g = g^{+} − g^{-}, \end{align*}y nota que tanto $g^{+}$ como $g^{-}$ son funciones no-negativas. Concluye utilizando lo que demostramos en esta entrada.
Verifica que la serie \eqref{eq:serie1} es convergente. Sugerencia: Utiliza algún criterio de convergencia como el de d’Alembert.
Demuestra la validez de la identidad \eqref{eq:identidad}.
Más adelante…
La ley del estadísico inconsciente es un teorema muy útil en contextos teóricos y aplicados. De hecho, la utilizaremos con mucha frecuencia en la Unidad 3, ya que veremos algunas características de algunas distribuciones de probabilidad importantes.
Por otro lado, en la siguiente entrada veremos más propiedades del valor esperado, centrando nuestra atención en aquellas propiedades que involucran a más de una variable aleatoria.
En esta entrada hablaremos acerca del complemento de un conjunto y algunos resultados que se dan a partir de esta definición. A su vez, veremos las leyes de De Morgan, las cuales nos dirán cuál es el complemento de la intersección y de la unión de dos o más conjuntos.
Complemento de un conjunto
Definición. Sean $A$ y $X$ conjuntos, tales que $A\subseteq X$. Definimos al complemento de $A$ respecto del conjunto $X$, como la diferencia $X\setminus A$.
Ejemplo.
Sea $X=\set{\emptyset, \set{\emptyset}, \set{\set{\emptyset}}, \set{\emptyset, \set{\emptyset}}}$ y sea $A=\set{\emptyset, \set{\emptyset, \set{\emptyset}}}$. Tenemos que $X\setminus A=\set{x\in X: x\notin A}=\set{\set{\emptyset}, \set{\set{\emptyset}}}$.
En efecto, pues $\emptyset\in X$ y $\emptyset\in A$ por lo que $\emptyset\notin X\setminus A$ pues no cumple la propiedad para ser elemento del conjunto $X\setminus A$. Por su parte, $\set{\emptyset,\set{\emptyset}}$ tampoco es elemento de $X\setminus A$ pues $\set{ \emptyset,\set{\emptyset}}\in X$ y $\set{ \emptyset,\set{\emptyset}}\in A$. Finalmente, $\set{\emptyset}$, $\set{\set{\emptyset}}\in X$ y $\set{\emptyset}$, $\set{\set{\emptyset}}\notin A$, por lo que $\set{\emptyset}$, $\set{\set{\emptyset}}\in X\setminus A$.
$\square$
Resultados del conjunto complemento
Usaremos el siguiente resultado repetidamente para la demostración de propiedades posteriormente.
Proposición. Sean $A$, $B$, $X$ conjuntos, tales que $A$, $B\subseteq X$. Se cumple que $A\setminus B=A\cap (X\setminus B)$.
Demostración.
$\subseteq$] Sea $a\in A\setminus B$, entonces $a\in A$ y $a\notin B$. Como $a\in A\subseteq X$, entonces $a\in X$. Así, es cierto que $a\in A$ y ($a\in X$ y $a\notin B$), por lo que $a\in A$ y $a\in X\setminus B$ y por lo tanto, $a\in A\cap (X\setminus B)$.
Concluimos que $A\setminus B\subseteq A\cap (X\setminus B)$.
$\supseteq$] Sea $a\in A\cap(X\setminus B)$, entonces $a\in A$ y $a\in X \setminus B$. Entonces $a\in A$ y $a\in X$ y $a\notin B$, en particular, $a\in A$ y $a\notin B$. Así, $a\in A\setminus B$.
Por lo tanto, $A\cap (X\setminus B)= A\setminus B$.
$\square$
Veamos otras tres propiedades del complemento.
Proposición. Sean $A$ y $X$ conjuntos tales que $A\subseteq X$. Entonces se cumple lo siguiente:
a) $A\cap (X\setminus A)=\emptyset$,
b) $A\cup (X\setminus A)=X$,
c) $X\setminus(X\setminus A)= A$.
Demostración:
a) Supongamos que $A\cap(X\setminus A)\not=\emptyset$ en búsqueda de una contradicción. Entonces, existe $x\in A\cap(X\setminus A)$, de donde $x\in A$ y $x\in X\setminus A$.
Así, $x\in A$ y $x\in X$ y $x\notin A$. En particular, $x\in A$ y $x\notin A$ lo cual no puede ocurrir. Por lo tanto, $A\cap(X\setminus A)=\emptyset$.
b) Sea $x\in A\cup (X\setminus A)$, entonces $x\in A$ o $x\in X\setminus A$.
Caso 1: Si $x\in A$, entonces $x\in X$ pues $A\subseteq X$.
Caso 2: Si $x\in X\setminus A$, entonces $x\in X$ y $x\notin A$. En particular, $x\in X$.
En cualquier caso, $x\in X$. Por lo tanto, $A\cup (X\setminus A)\subseteq X$.
Por otro lado, supongamos que $x\in X$. Tenemos dos casos: $x\in A$ o $x\notin A$.
Caso 1: Si $x\in A$, entonces $x\in A\cup (X\setminus A)$.
Caso 2: Si $x\notin A$, entonces $x\in X$ y $x\notin A$ y así, $x\in X\setminus A$. Por lo tanto, $x\in A\cup(X\setminus A)$.
En cualquiera de los dos casos concluimos que $X\subseteq A\cup (X\setminus A)$.
Por lo tanto, $A\cup (X\setminus A)= X$.
c) Primero veamos que $A\subseteq X\setminus (X\setminus A)$. Sea $x\in A$, entonces $x\notin X\setminus A$. Por otro lado, $x\in X$ pues $A\subseteq X$.
Por lo que $x\in X$ y $x\notin X\setminus A$, es decir, $x\in X\setminus(X\setminus A)$. Esto concluye la prueba de que $A\subseteq X\setminus (X\setminus A)$.
Ahora, sea $x\in X\setminus (X\setminus A)$, entonces $x\in X$ y $x\notin X\setminus A$. Esto implica que $x\in X$ y ($x\notin X$ o $x\in A$). Como $x\in X$, entonces $x\notin X$ no es posible y así, $x\in A$. Por lo tanto, $X\setminus(X\setminus A)\subseteq A$.
Por lo tanto, $A=X\setminus (X\setminus A)$.
$\square$
Leyes de De Morgan
Las leyes de De Morgan nos dicen cómo se comportan los complementos de uniones e intersecciones. A continuación damos la versión para uniones e intersecciones de dos conjuntos. En los ejercicios tendrás que demostrar las versiones para uniones e intersecciones arbitrarias.
Se tiene $x\in X\setminus (A\cap B)$, si y sólo si $x\in X$ y $x\notin A\cap B$ por definición de complemento, si y sólo si $x\in X$ y ($x\notin A$ o $x\notin B$), si y sólo si ($x\in X$ y $x\notin A$) o $(x\in X$ y $x\notin B$), si y sólo si $x\in X\setminus A$ o $x\in X\setminus B$, si y sólo si $x\in (X\setminus A)\cup (X\setminus B)$. Por lo tanto, $X\setminus(A\cap B)=(X\setminus A)\cup (X\setminus B)$.
Se tiene $x\in X\setminus (A\cup B)$, si y sólo si $x\in X$ y $x\notin A\cup B$ por definición de complemento, si y sólo si $x\in X$ y ($x\notin A$ y $x\notin B$), si y sólo si ($x\in X$ y $x\notin A$) y $(x\in X$ y $x\notin B$), si y sólo si $x\in X\setminus A$ y $x\in X\setminus B$, si y sólo si $x\in (X\setminus A)\cap (X\setminus B)$. Por lo tanto, $X\setminus(A\cup B)=(X\setminus A)\cap (X\setminus B)$.
$\square$
Tarea moral
Demuestra que para $X$ un conjunto cualquiera se cumple que $X\setminus \emptyset= X$.
Prueba que si $X$ un conjunto arbitrario, entonces $X\setminus X=\emptyset$.
Sean $A$, $B\subseteq X$ conjuntos. Prueba que $A\subseteq B$ si y sólo si $X\setminus B\subseteq X\setminus A$.
Muestra que si $A$ es un conjunto no vacío, entonces $(A\cup A)\setminus A\not=A\cup (A\setminus A)$.
Sean $X$ y $F$ conjuntos: – Muestra que $X\setminus (\bigcup F) = \bigcap (X\setminus F)$. – Supongamos que $F\neq \emptyset$. Muestra que $X\setminus (\bigcap F) = \bigcup (X\setminus F)$.
Este último ejercicio son las leyes de De Morgan para intersecciones y uniones arbitrarias.
Más adelante…
En la siguiente entrada hablaremos acerca del álgebra de conjuntos, para ello retomaremos las operaciones entre conjuntos que definidas anteriormente. Así mismo, haremos uso de los resultados que probamos en esta sección acerca del complemento de un conjunto. Un poco después, definiremos una nueva operación entre conjuntos: la diferencia simétrica.
Trabajo realizado con el apoyo del Programa UNAM-DGAPA-PAPIME PE109323 «Hacia una modalidad a distancia de la Licenciatura en Matemáticas de la FC-UNAM – Etapa 3»
También puedes consultar la demostración de este teorema en: Gómez L. C, Álgebra Superior Curso Completo. Publicaciones Fomento Editorial, 2014, pp. 32-33. ↩︎

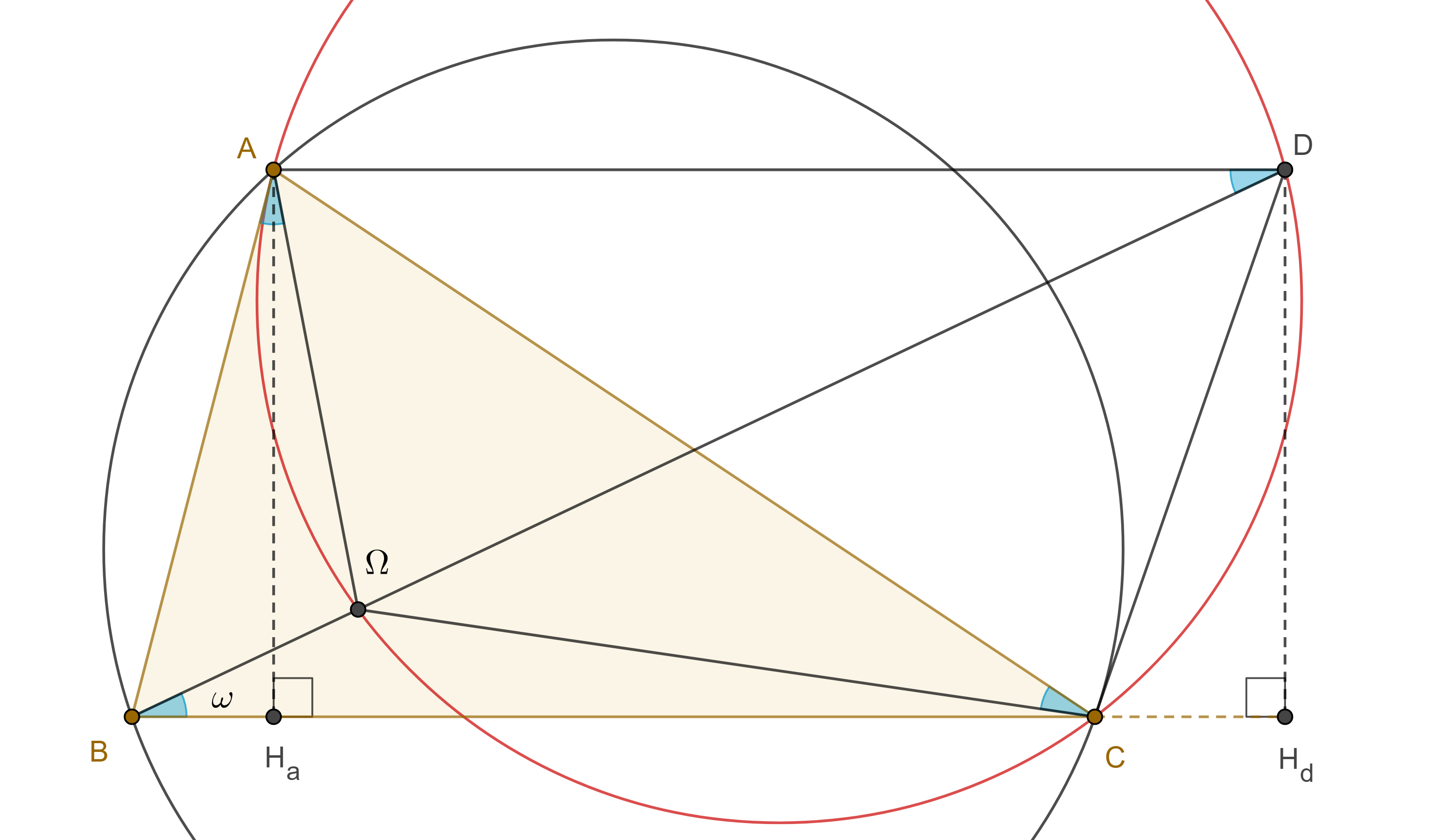
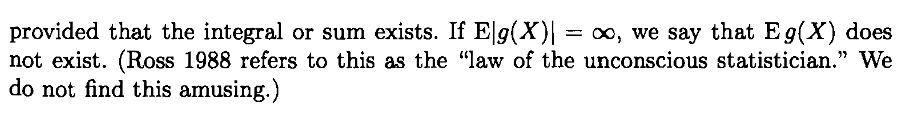
{kind=link}