(Trabajo de titulación asesorado por la Dra. Diana Avella Alaminos)
Introducción
Cuando nació la Teoría de grupos uno de los problemas principales fue clasificar a los grupos finitos. Una manera de estudiar este problema es empezar por entender un tipo especial de grupos finitos: grupos con orden primo $p$, llamemos $G$ a este grupo. El estudio de $G$ se hace más sencillo pues sabemos que es un grupo cíclico y es isomorfo a $\z_p.$
Podemos aumentar la dificultad y considerar el caso cuando $|G| = p^t$, con $p$ primo y $t\in \n.$ Pero, ¿qué sucede si $G$ no es un $p$-grupo? Supongamos que $|G|= n = p^t m$ donde $t\in \n$ y $p$ no divide a $m.$
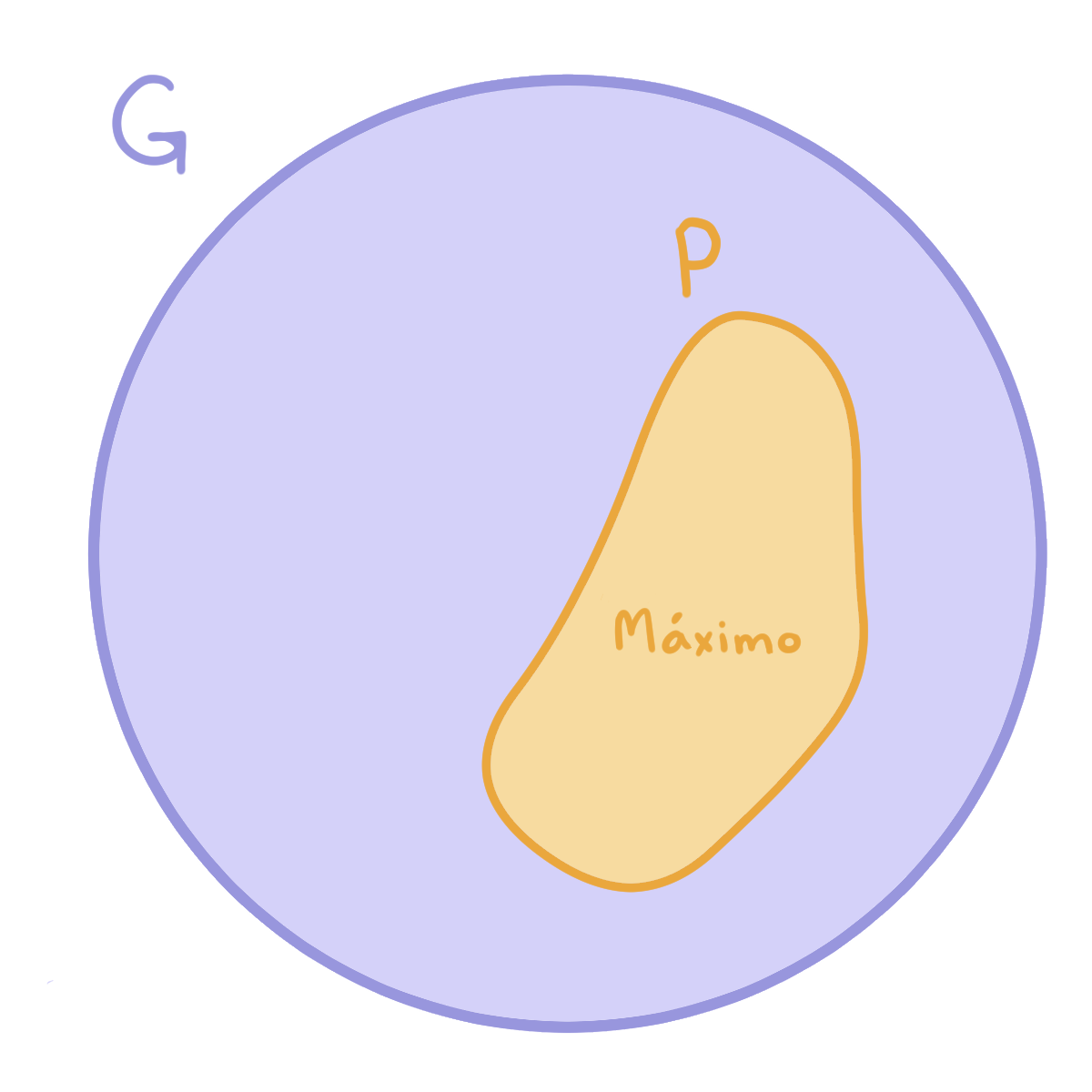
En esta entrada lo que haremos será intentar estudiar a un grupo cualquiera $G$ a partir de los $p$-grupos que lo conforman, que serán llamados $p$-subgrupos de $G$. Estos subgrupos pueden estar contenidos a su vez en otros $p$-subgrupos o bien ser máximos con respecto a la contención y no estar contenidos en ningún otro $p$-subgrupo. A estos $p$-subgrupos máximos se les llama $p$-subgrupos de Sylow de $G$.
Estudiar todos los $p$-subgrupos de Sylow de $G$ para los primos que dividen al orden de $G$ nos ayuda a entender cómo es el mismo $G.$
Comencemos con subgrupos de Sylow
Definición. Sean $p\in \z^+$ un primo y $G$ un grupo finito. Decimos que $P$ es un $p$-subgrupo de $G$ si el orden de $P$ es una potencia de $p$. Además, decimos que $P$ es un $p$-subgrupo de Sylow de $G$ si
- $P$ es un $p$-grupo,
- si $Q$ es un $p$-grupo con $P\subseteq Q \subseteq G$, entonces $P=Q$.
Es decir $P$ es un $p$-subgrupo de $G$ máximo con respecto a la contención.
Observación. Siempre existen los subgrupos de Sylow.
Demostración.
Sean $p\in \z^+$ un primo y $G$ un grupo finito con $|G|= n$.
Si $p \not{|} n$, entonces $\{e\}$ es un $p$-subgrupo de Sylow.
Si $p|n$, por el teorema de Cauchy existe $g\in G$ de orden $p$. Si $\left< g\right>$ no es $p$-subgrupo de Sylow, entonces existe $Q_1 \leq G$ $p$-subgrupo con $\left< g\right> \not\subseteq Q_1.$ Si $Q_1$ no es un $p$-subgrupo de Sylow debe existir $Q_2\leq G$ $p$-subgrupo con $Q_1\not\subseteq Q_2.$ Continuando de este modo, dado que $G$ es de orden finito y $1<|\left< g\right> |<|Q_1|<|Q_2|<\dots <|G|$ obtenemos un $p$-subgrupo de Sylow después de un número finito de pasos.
$\blacksquare$
Ejemplos
Ejemplo 1. Sea $G = S_4$, $|S_4| = 4! = 24 = 2^3\cdot 3$.
Entonces hay dos primos involucrados en $|S_4|$, estos son 2 y 3.
$\left< (1\, 2\, 3)\right>$ es un $3$-subgrupo de $S_4$. Como no hay otra potencia de 3 que divida a $|S_4|$, no hay grupos de orden 9,27, etc. por lo que $\left< (1\, 2\, 3)\right>$ es un $3$-subgrupo de Sylow de $S_4.$
Por otro lado, para los $2$-subgrupos de Sylow podríamos tener subgrupos de orden $2$, $4$ y hasta $8$.
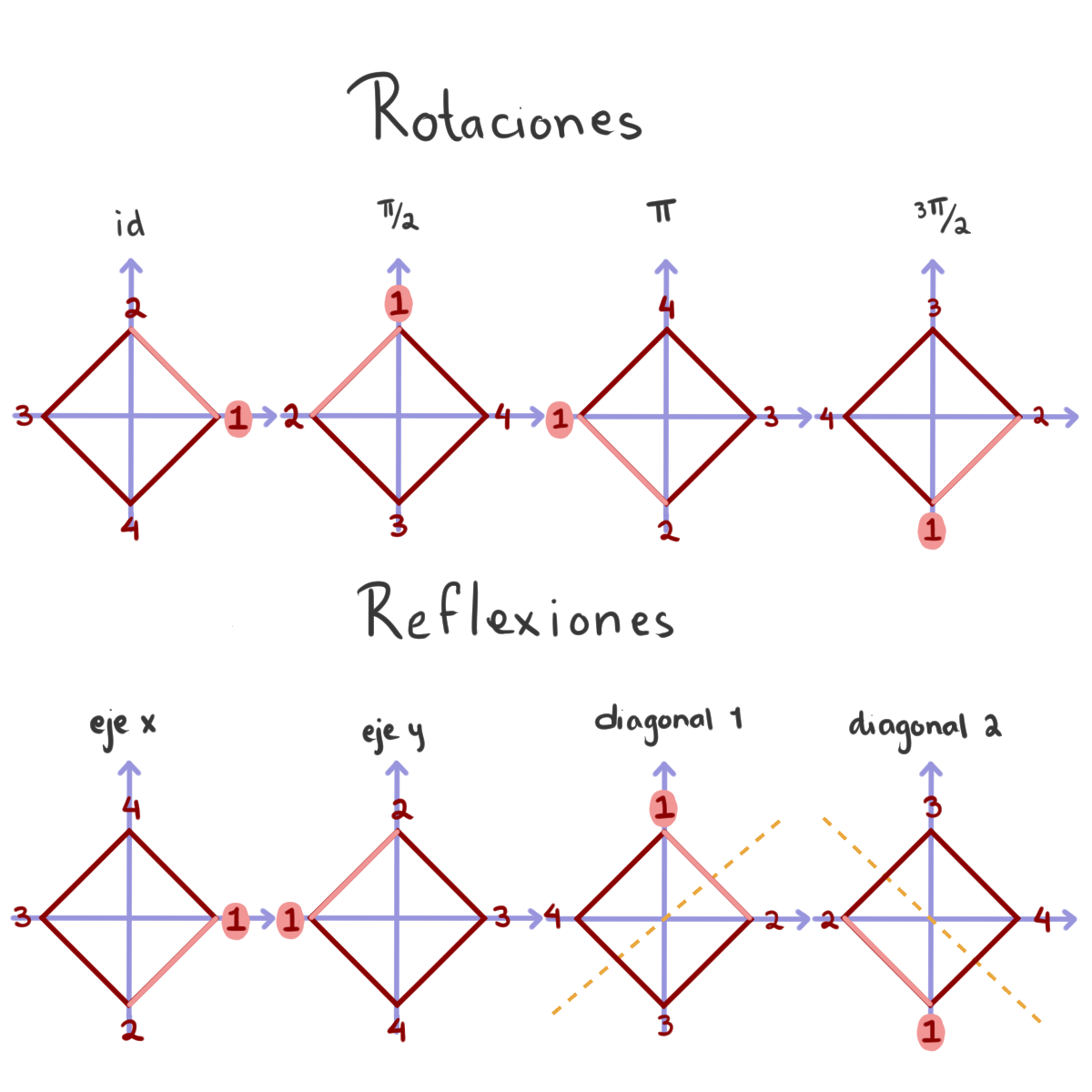
Notemos que no todas las permutaciones de los vértices de un cuadrado son simetrías, pero todas las simetrías de un cuadrado se pueden ver como permutaciones de sus vértices. Las permutaciones que también son simetrías son: las rotaciones por 90 grados, las reflexiones por los ejes y las reflexiones por las diagonales.
La rotación de $90$ grados, que corresponde a la permutación $(1\, 2\, 3\, 4),$ y la reflexión por el eje $x,$ que corresponde a la transposición $(2\,4)$, generan al grupo diédrico. Por lo que $\left< (1\, 2\, 3\, 4), (2\,4)\right>$ es isomorfo al grupo diédrico $D_{2(4)}$ que es de orden $8$. Así, $\left< (1\, 2\, 3\, 4), (2\,4)\right>$ es un $2$-subgrupo de Sylow de $S_4$ de orden 8.
Ejemplo 2. Sea $G = A_4$, $|A_5| = 60 = 2^2\cdot 3 \cdot 5$.
Consideremos el grupo de Klein $\{(1), (1\,2)(3\, 4), (1\,3)(2\,4), (1\,4)(2\,3) \} $ que es un subgrupo de $A_5$ de orden $4$ y por lo tanto un $2$-subgrupo de Sylow de $A_5$.
El subgrupo anterior se hizo considerando todas las permutaciones que son productos de dos transposiciones disjuntas de los números $1$, $2$, $3$ y $4$, si ahora hacemos lo mismo pero considerando todas las permutaciones que son productos de dos transposiciones disjuntas de los números $2$, $3$, $4$ y $5$ obtenemos $\{(1), (2\,3)(4\,5), (2\,4)(3\,5), (2\,5)(3\,4)\}$ que es otro $2$-subgrupo de Sylow de $A_5$. Siguiendo de esta manera podríamos construir distintos $2$-subgrupos de Sylow.
Si nos tomamos un $3$-ciclo y su generado obtenemos un $3$-subgrupo de Sylow de $A_5$, por ejemplo $\left< (1\, 2\, 3)\right>$ es un $3$-subgrupo de Sylow de $A_5$. Notamos que podemos elegir $3$-ciclos distintos de $ (1\, 2\, 3)$ y de su inverso y con ello crear diferentes $3$-subgrupos de Sylow de $A_5$.
Si tomamos un $5$-ciclo y su generado obtenemos un $5$-subgrupo de Sylow de $A_5$, por ejemplo $\left< (1\, 2\, 3\,4\,5)\right>$ es un $5$-subgrupo de Sylow de $A_5$. Pero también podemos tomar un $5$-ciclo que no esté en el generado $\left< (1\, 2\, 3\, 4\, 5)\right>$ y obtener otro $5$- subgrupo de Sylow de $A_5$.
Últimos preparativos
Definición. Sean $G$ un grupo y $H$ subgrupo de $G$. El normalizador de $H$ en $G$ es
\begin{align*}
N_G(H) = \{g\in G \;|\; gHg^{-1} = H \}.
\end{align*}

Observemos que un elemento $g $ del normalizador de $H$ no necesariamente está en $H$.
Observación. Por construcción $H \unlhd N_G(H)$.
Lema. Sean $p\in \z^+$ un primo, $G$ un grupo finito y $H$ un $p$-subgrupo de $G$. Entonces
\begin{align*}
[ N_G(H) : H ] \equiv [ G: H ] (\text{mód }p).
\end{align*}
Demostración.
Sean $p\in \z^+$ un primo, $G$ un grupo finito y $H$ un $p$-subgrupo de $G$. Consideremos $X = \{gH\;|\;g\in G\}$ y la acción de $H$ en $X$ dada por
\begin{align*}
h\cdot (gH) = hgH \quad \forall h\in H, \forall g\in G.
\end{align*}
Como $H$ es un $p$-grupo, de acuerdo al último teorema de la entrada Clase de Conjugación, Centro de $G$, Ecuación de Clase y $p$-Grupo sabemos que
\begin{align*}
[ G:H ] = \# X \equiv \# X_H (\text{mód }p).
\end{align*}
Pero
\begin{align*}
X_H &= \{gH \in X \;|\; h\cdot(gH) = gH \quad \forall h \in H\} \\
&= \{gH \in X \;|\; hgH = gH \quad \forall h \in H\}\\
&= \{gH \in X \;|\; g^{-1}hg\in H \quad \forall h \in H\}\\
&= \{gH \in X \;|\; g^{-1}Hg\subseteq H\}\\
&= \{gH \in X \;|\; g^{-1}Hg = H\} & \text{pues $G$ es finito y en consecuencia $H$ también}\\
&= \{gH \;|\; g\in N_{G}(H)\}\\
&= N_G(H) / H.
\end{align*}
Así, $\#X_H = [ N_G(H) : H ]$ y entonces $[ G:H ] \equiv [ N_G(H) : H] (\text{mód }p).$
$\blacksquare$
Tarea moral
A continuación hay algunos ejercicios para que practiques los conceptos vistos en esta entrada. Te será de mucha utilidad intentarlos para entender más la teoría vista.
- Encuentra los $2$-subgrupos de los cuaternios $Q_8.$
- Encuentra todos los $3$-subgrupos del grupo simétrico $S_4.$ Etiquetando los vértices del cuadrado de maneras distintas a la que viene en el ejemplo 2 de esta entrada, encuentra la mayor cantidad que puedas de $2$-subgrupos de Sylow de $S_4$.
- Sea $P$ un $p$-subgrupo de Sylow de un grupo finito $G$. Prueba que:
- Cada conjugado de $P$ también es un $p$-subgrupo de Sylow.
- $p$ no divide a $|N_g(P)/P|$.
- Si $g\in G$ es tal que $o(g) = p^m$ para alguna $m\in\z^+$ y si $gPg^{-1} = P$, entonces $g \in P.$
Más adelante…
¡Ahora sí! Todo está listo para que en la siguiente entrada estudiemos los tres Teoremas de Sylow. Te adelanto que todos los Teoremas de Sylow se sirven de los $p$-subgrupos que vimos en esta entrada. De hecho, los relaciona con los temas que hemos visto como subgrupo normal y conjugados.
Entradas relacionadas
- Ir a Álgebra Moderna I.
- Entrada anterior del curso: Teorema de Cauchy.
- Siguiente entrada del curso: Teoremas de Sylow.
- Resto de cursos: Cursos.