Introducción
A lo largo de esta unidad nos hemos enfocado en estudiar los vectores, las operaciones entre estos y sus propiedades. Sin embargo, hasta ahora solo hemos ocupado una definición provisional de vectores —listas ordenadas con entradas reales—, pero no hemos dado una definición formal de estos. En esta entrada definiremos qué es un espacio vectorial y exploraremos algunas de las propiedades de dos ejemplos importantes de espacios vectoriales: $\mathbb{R}^2$ y $\mathbb{R}^3$-
Las propiedades de espacio vectorial
En entradas anteriores demostramos que los pares ordenados con entradas reales (es decir, los elementos de $\mathbb{R}^2$), en conjunto con la suma entrada a entrada y el producto escalar, cumplen las siguientes propiedades:
1. La suma es asociativa:
\begin{align*}
(u+v)+w &= ((u_1,u_2) + (v_1,v_2)) + (w_1,w_2) \\
&= (u_1,u_2) + ((v_1,v_2) + (w_1,w_2)) \\
&= u+(v+w).\end{align*}
2. La suma es conmutativa:
\begin{align*}u+v &= (u_1,u_2) + (v_1,v_2) \\&= (v_1,v_2) + (u_1,u_2) \\&= v+u.\end{align*}
3. Existe un elemento neutro para la suma:
\begin{align*}
u + 0 &= (u_1,u_2) + (0,0) \\&= (0,0) + (u_1,u_2) \\&= (u_1,u_2) \\&= u.
\end{align*}
4. Para cada par ordenado existe un elemento inverso:
\begin{align*}
u + (-u) &= (u_1,u_2) + (-u_1,-u_2) \\&= (-u_1,-u_2) + (u_1,u_2) \\&= (0,0) \\&= 0.
\end{align*}
5. La suma escalar se distribuye bajo el producto:
\begin{align*}
(r+s)u &= (r+s)(u_1,u_2) \\&= r(u_1,u_2) + s(u_1,u_2) \\&= ru + su.
\end{align*}
6. La suma de pares ordenados se distribuye bajo el producto escalar:
\begin{align*}
r(u + v) &= r((u_1,u_2) + (v_1,v_2)) \\&= r(u_1,u_2) + r(v_1,v_2) \\&= ru + rv.
\end{align*}
7. El producto escalar es compatible con el producto de reales:
\[
(rs)u = (rs)(u_1,u_2) = r(s(u_1,u_2)) = r(su).
\]
8. Existe un elemento neutro para el producto escalar, que justo es el neutro del producto de reales:
\[
1u = 1(u_1,u_2) = (u_1,u_2) = u.
\]
Cuando una colección de objetos matemáticos, en conjunto con una operación de suma y otra operación de producto, cumple las ocho propiedades anteriormente mencionadas, decimos que dicha colección forma un espacio vectorial. Teniendo esto en consideración, los objetos matemáticos que pertenecen a la colección que forma el espacio vectorial los llamaremos vectores.
Así, podemos ver que los pares ordenados con entradas reales, en conjunto con la suma entrada a entrada y el producto escalar, forman un espacio vectorial, al cual solemos denominar $\mathbb{R}^2$. De este modo, los vectores del espacio vectorial $\mathbb{R}^2$ son exactamente los pares ordenados con entradas reales.
Como recordarás, anteriormente también demostramos que las ternas ordenadas con entradas reales, en conjunto con su respectiva suma entrada a entrada y producto escalar, cumplen las ocho propiedades antes mencionadas (¿puedes verificarlo?). Esto nos indica que $\mathbb{R}^3$ también es un espacio vectorial, y sus vectores son las ternas ordenadas con entradas reales. En general, el que un objeto matemático se pueda considerar o no como vector dependerá de si este es elemento de un espacio vectorial.
Como seguramente sospecharás, para valores de $n$ distintos de 2 y de 3 también se cumple que $\mathbb{R}^n$ forma un espacio vectorial. Sin embargo los espacios $\mathbb{R}^2$ y $\mathbb{R}^3$ son muy importantes pues podemos visualizarlos como el plano y el espacio, logrando así describir muchas de sus propiedades. Por esta razón, en esta entrada exploraremos algunas de las principales propiedades de $\mathbb{R}^2$ y $\mathbb{R}^3$.
Observación. Basándonos en la definición, el hecho de que una colección de elementos se pueda considerar o no como espacio vectorial depende también a las operaciones de suma y producto. Por esta razón, es común (y probablemente más conveniente) encontrar denotado el espacio vectorial $\mathbb{R}^2$ como $(\mathbb{R}^2,+,\cdot)$. Más aún, a veces será importante destacar a los elementos escalares y neutros, encontrando el mismo espacio denotado como $(\mathbb{R}^2, \mathbb{R}, +, \cdot, 0, 1)$. Esto lo veremos de manera más frecuente cuando trabajamos con más de un espacio vectorial, sin embargo, cuando el contexto nos permite saber con qué operaciones (y elementos) se está trabajando, podemos omitir ser explícitos y denotar el espacio vectorial simplemente como $\mathbb{R}^2$ o $\mathbb{R}^3$.
Combinaciones lineales
Como vimos en entradas anteriores, la suma de vectores en $\mathbb{R}^2$ la podemos visualizar en el plano como el resultado de poner una flecha seguida de otra, mientras que el producto escalar lo podemos ver como redimensionar y/o cambiar de dirección una flecha.
En el caso de $\mathbb{R}^3$, la intuición es la misma, pero esta vez en el espacio.
Si tenemos varios vectores, podemos sumar múltiplos escalares de ellos para obtener otros vectores. Esto nos lleva a la siguiente definición.
Definición. Dado un conjunto de $n$ vectores $v_1, \ldots, v_n$ en $\mathbb{R}^2$ o ($\mathbb{R}^3$), definimos una combinación lineal de estos vectores como el resultado de la operación
\[
r_1v_1 + r_2v_2 + \cdots + r_nv_n,
\]
donde $r_1, \ldots, r_n$ son escalares.
Ejemplo. En $\mathbb{R}^2$, las siguientes son combinaciones lineales:
\begin{align*}
4(9,-5) + 7(-1,0) + 3(-4,2) &= (17,-14), \\[10pt]
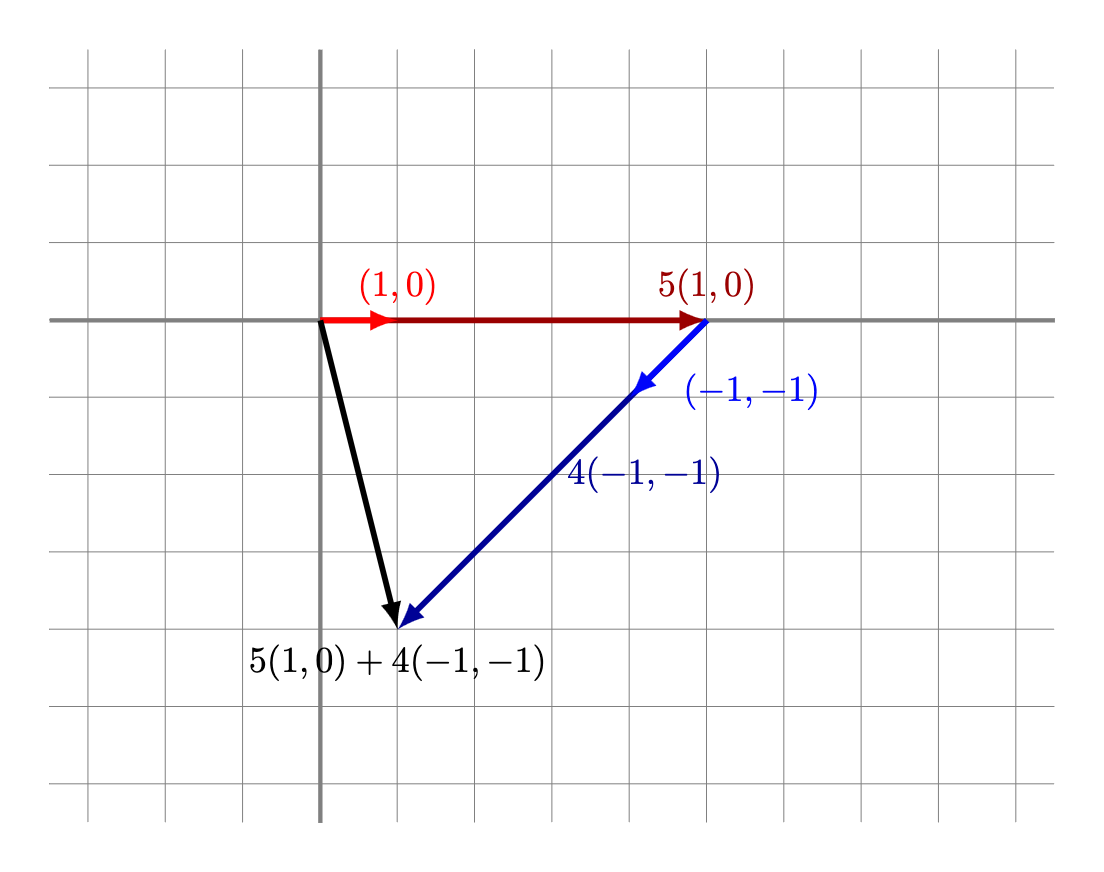
5(1,0) + 4(-1,-1) &= (1,-4), \\[10pt]
-1(1,0) + 0(-1,-1) &= (-1,0), \\[10pt]
5(3,2) &= (15,10).
\end{align*}
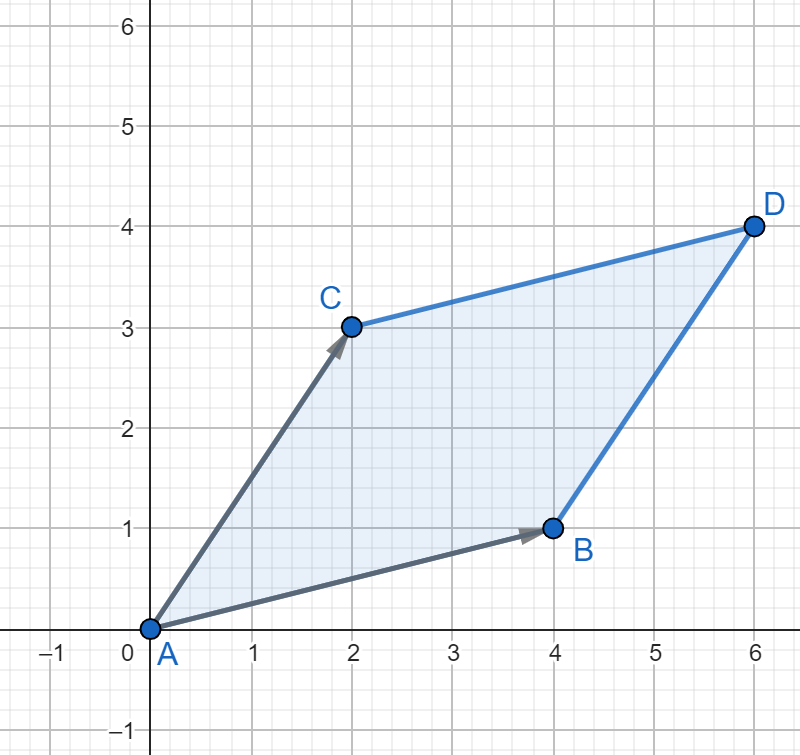
De este modo podemos decir que $(17,-14)$ es combinación lineal de los vectores $(9,-5)$, $(-1,0)$ y $(-4,2)$; los vectores $(1,-4)$ y $(-1,0)$ son ambos combinación lineal de los vectores $(1,0)$ y $(-1,-1)$; y $(15,10)$ es combinación lineal de $(3,2)$.
Las combinaciones lineales también tienen un significado geométrico. Por ejemplo, la siguiente figura muestra cómo se vería que $(1,-4)$ es combinación lineal de $(1,0)$ y $(-1,-1)$:
$\triangle$
Ejemplo. En el caso de $\mathbb{R}^3$, observamos que $(7,13,-22)$ es combinación lineal de los vectores $(8,1,-5)$, $(1,0,2)$ y $(9,-3,2)$, pues
\[
4(8,1,-5) + 2(1,0,2) + (-3)(9,-3,2) = (7,13,-22).
\]
$\triangle$
Espacio generado
La figura de la sección anterior nos sugiere cómo entender a una combinación lineal de ciertos vectores dados. Sin embargo, una pregunta natural que surge de esto es cómo se ve la colección de todas las posibles combinaciones lineales de una colección de vectores dados.
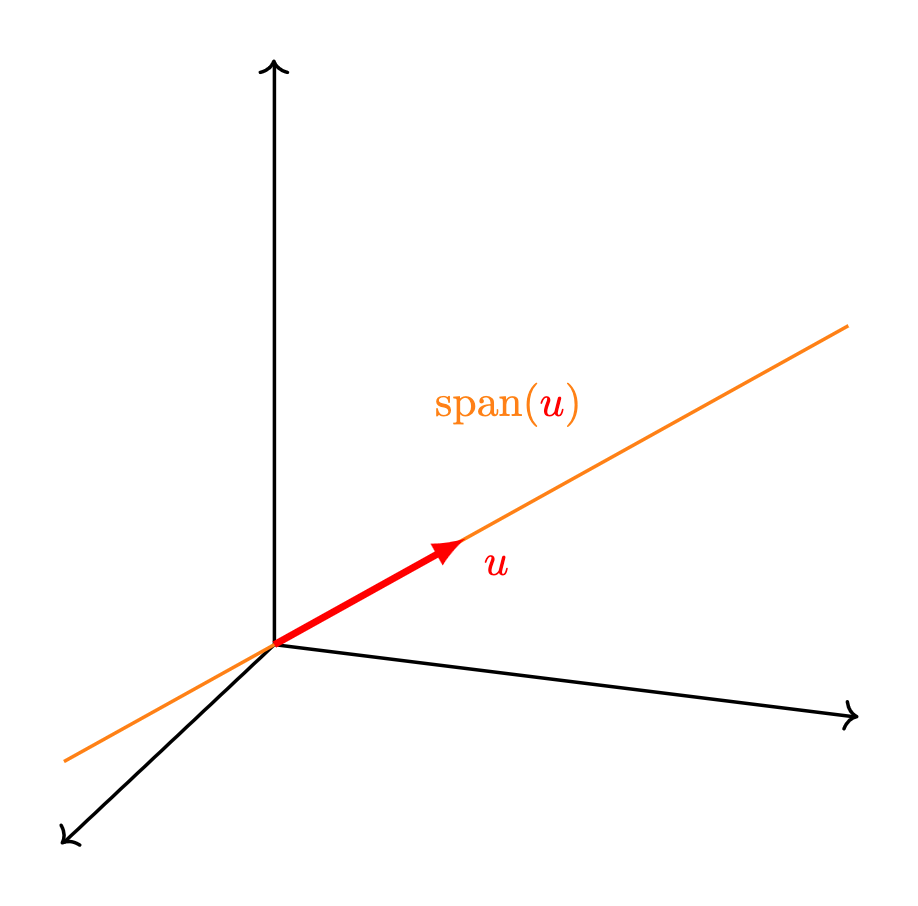
Definición. Dado un conjunto de $n$ vectores $v_1, \ldots, v_n$ en $\mathbb{R}^2$ o ($\mathbb{R}^3$), definimos al espacio generado por ellos como el conjunto de todas sus posibles combinaciones lineales. Al espacio generado por estos vectores podemos encontrarlo denotado como $\operatorname{span}(v_1, \ldots, v_n)$ o $\langle v_1, \ldots, v_n \rangle$ (aunque esta última notación a veces se suele dejar para otra operación del álgebra lineal).
¿Cómo puede verse el espacio generado por algunos vectores? Puede demostrarse que en el caso de $\mathbb{R}^2$ tenemos los siguientes casos.
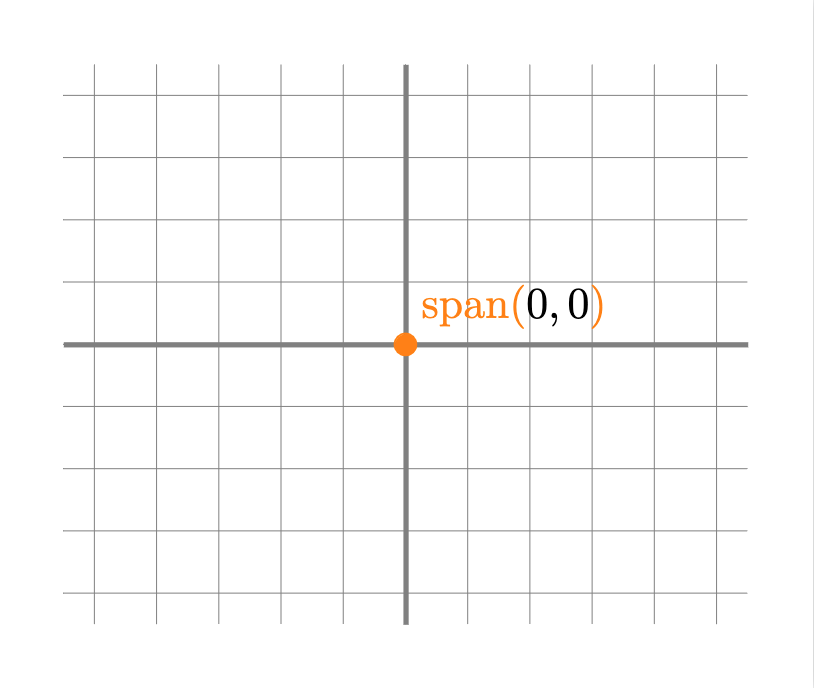
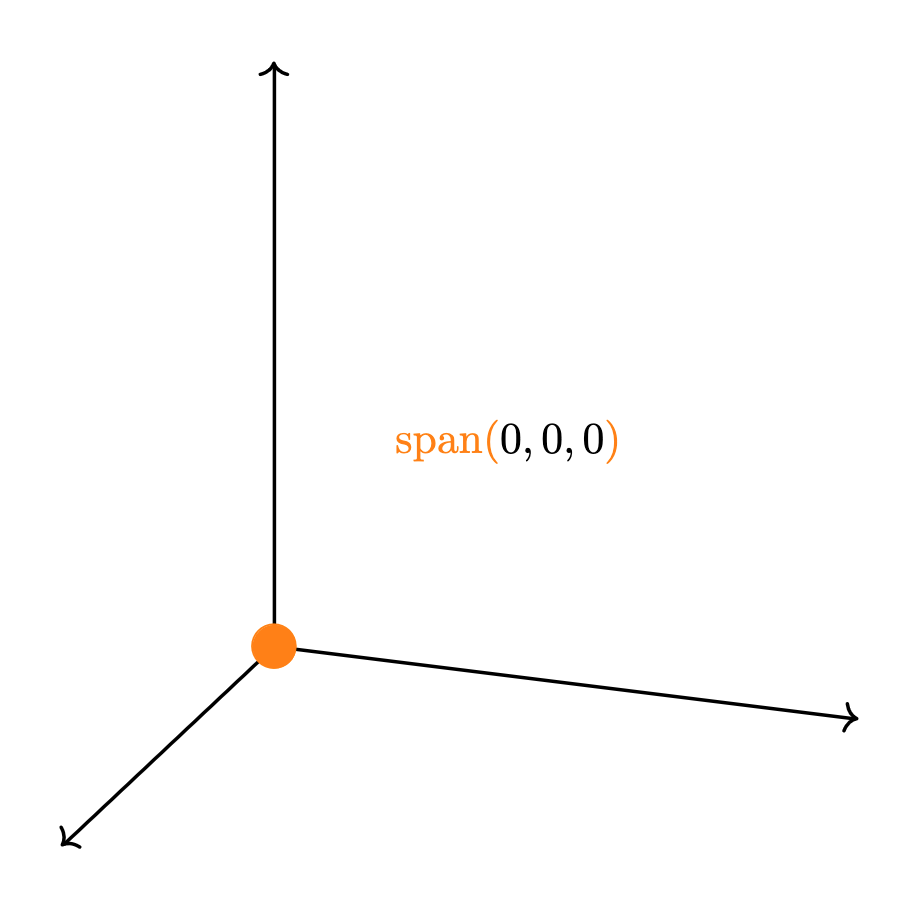
- Un punto: esto sucede si y sólo si todos los vectores del conjunto son iguales al vector $0$.
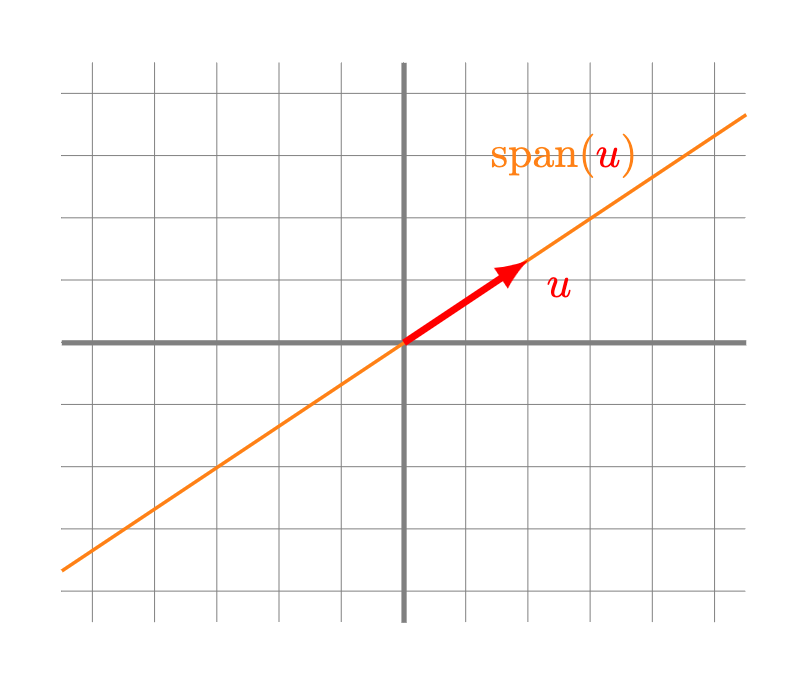
- Una recta: esto sucede si al menos un vector $u$ es distinto de 0 y todos los vectores se encuentran alineados. La recta será precisamente aquella formada por los múltiplos escalares de $u$.
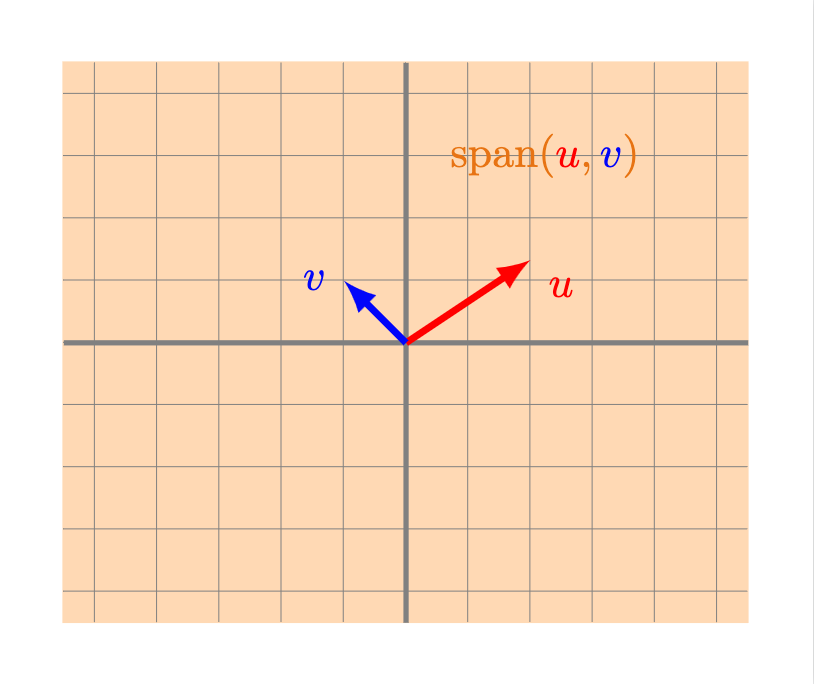
- Todo $\mathbb{R}^2$: esto sucede si al menos dos vectores $u$ y $v$ de nuestro conjunto no son cero y además no están alineados. Intenta convencerte que en efecto en este caso puedes llegar a cualquier vector del plano sumando un múltiplo de $u$ y uno de $v$.
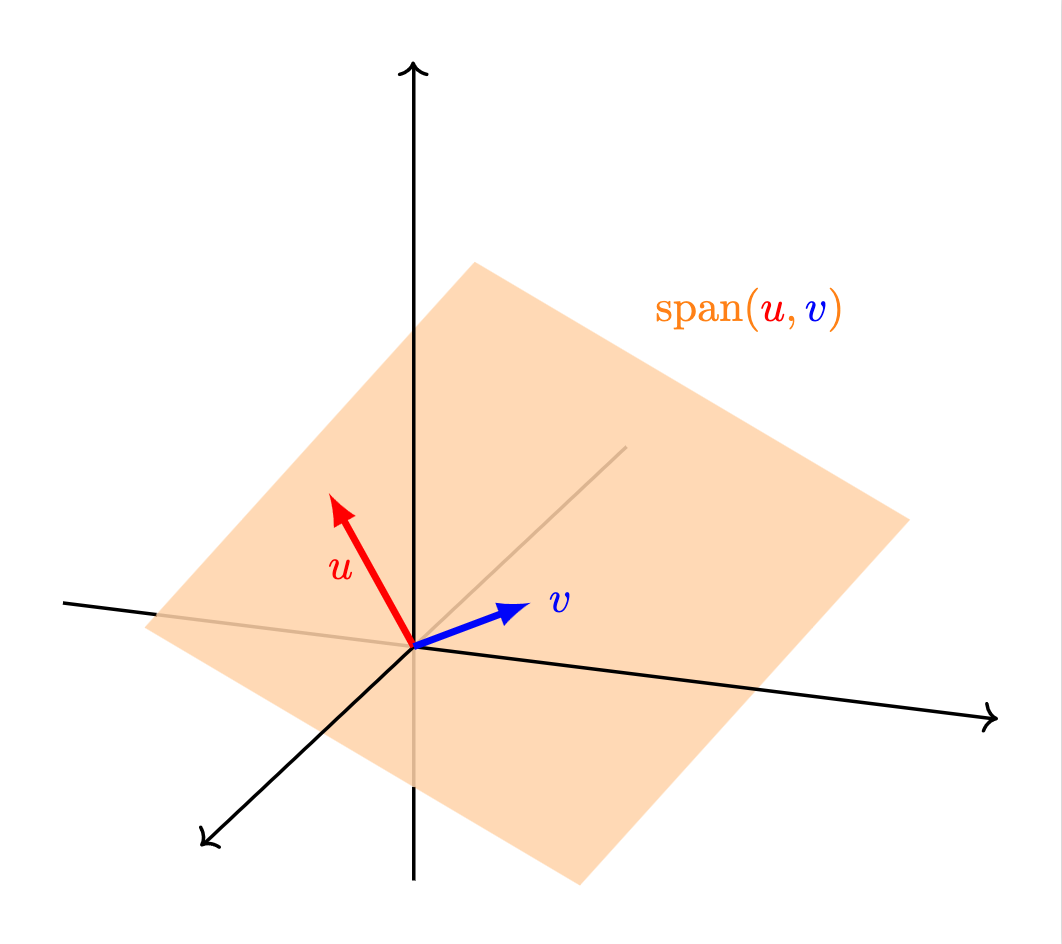
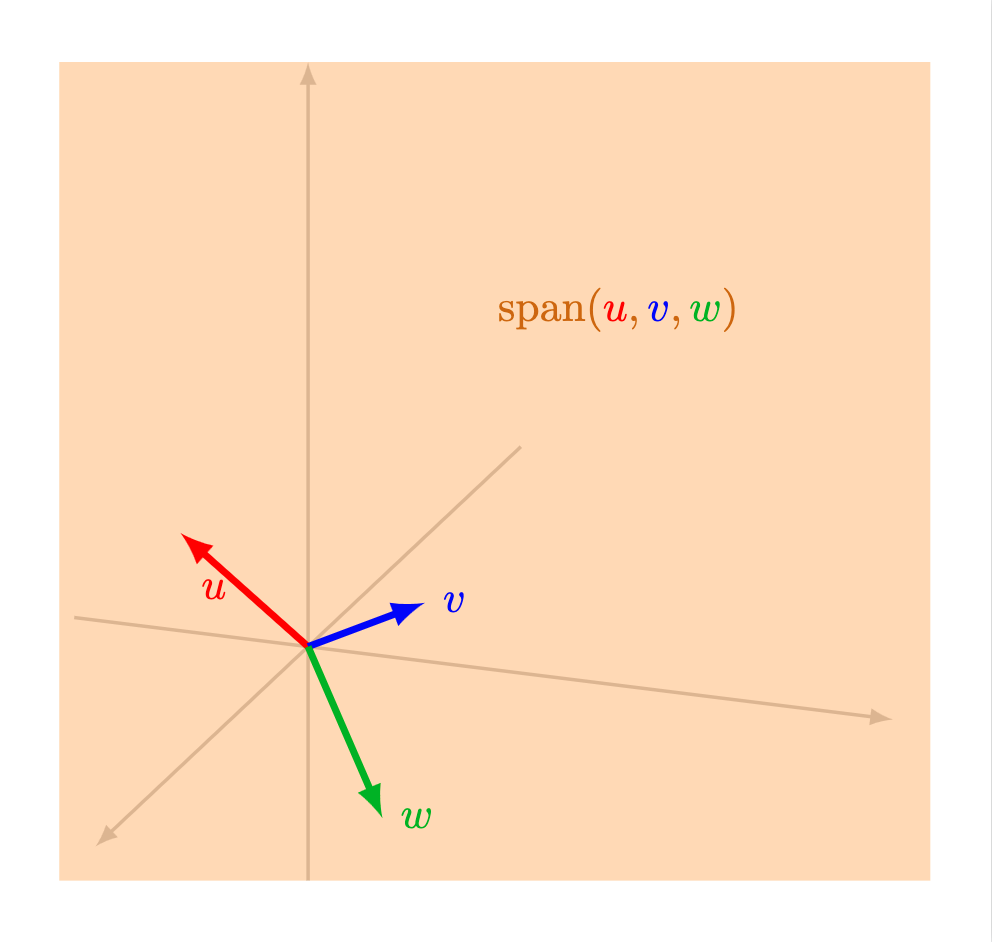
En $\mathbb{R}^3$, puede mostrarse que el espacio generado se ve como alguna de las siguientes posibilidades:
- Un punto: esto sucede si y sólo si todos los vectores del conjunto son iguales al vector $0$.
- Una recta: esto sucede si al menos un vector $u$ es distinto de $0$ y todos los vectores se encuentran alineados con $u$. La recta consiste precisamente de los reescalamientos de $u$.
- Un plano: esto sucede si al menos dos vectores $u$ y $v$ no son cero y no están alineados, y además todos los demás están en el plano generado por $u$ y $v$ estos dos vectores.
- Todo $\mathbb{R}^3$: esto sucede si hay tres vectores $u$, $v$ y $w$ que cumplan que ninguno es el vector cero, no hay dos de ellos alineados, y además el tercero no está en el plano generado por los otros dos.
Muchas veces no sólo nos interesa conocer la forma del espacio generado, sino también obtener una expresión que nos permita conocer qué vectores pertenecen a este. Una forma en la que podemos hacer esto es mediante ecuaciones.
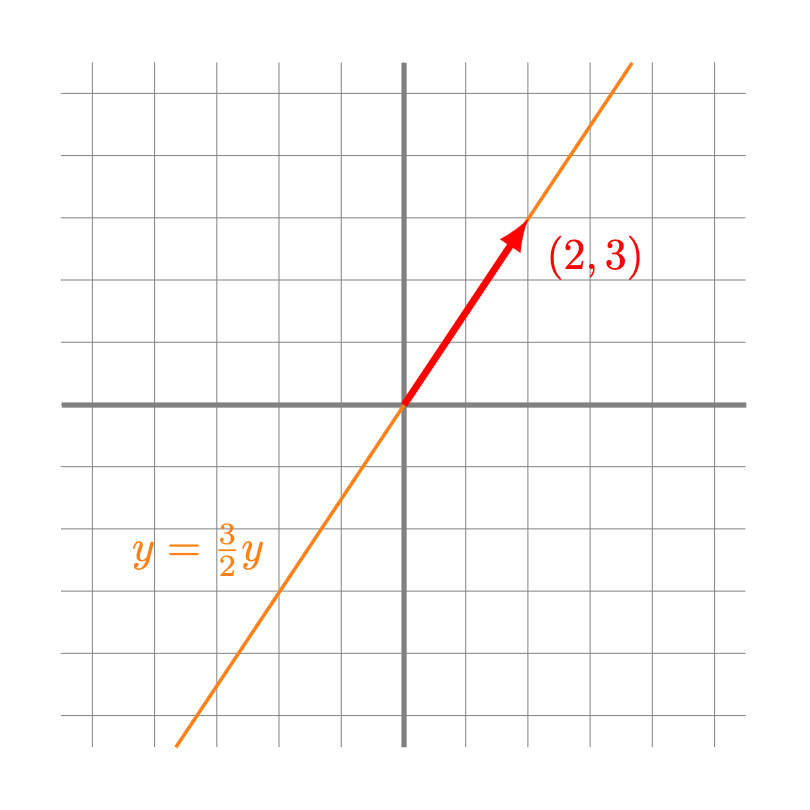
Ejemplo. Por ejemplo, observemos que el espacio generado el vector $(3,2)$ en $\mathbb{R}^2$ corresponde a los vectores $(x,y)$ que son de la forma
\[
(x,y) = r(2,3),
\]
donde $r \in \mathbb{R}$ es algún escalar. Esto se cumple si y sólo si
\[
(x,y) = (2r,3r),
\]
lo cual a su vez se cumple si y sólo si $x$ y $y$ satisfacen el sistema de ecuaciones
\[
\begin{cases}
x = 2r \\
y = 3r
\end{cases}.
\]
Si despejamos $r$ en ambas ecuaciones y las igualamos, llegamos a que
\[
\frac{x}{2} = \frac{y}{3},
\]
de donde podemos expresar la ecuación de la recta en su forma homogénea:
\[
\frac{1}{2}x – \frac{1}{3}y = 0;
\]
o bien en como función de $y$:
\[
y = \frac{3}{2}x.
\]
$\triangle$
La estrategia anterior no funciona para todos los casos, y tenemos que ser un poco más cuidadosos.
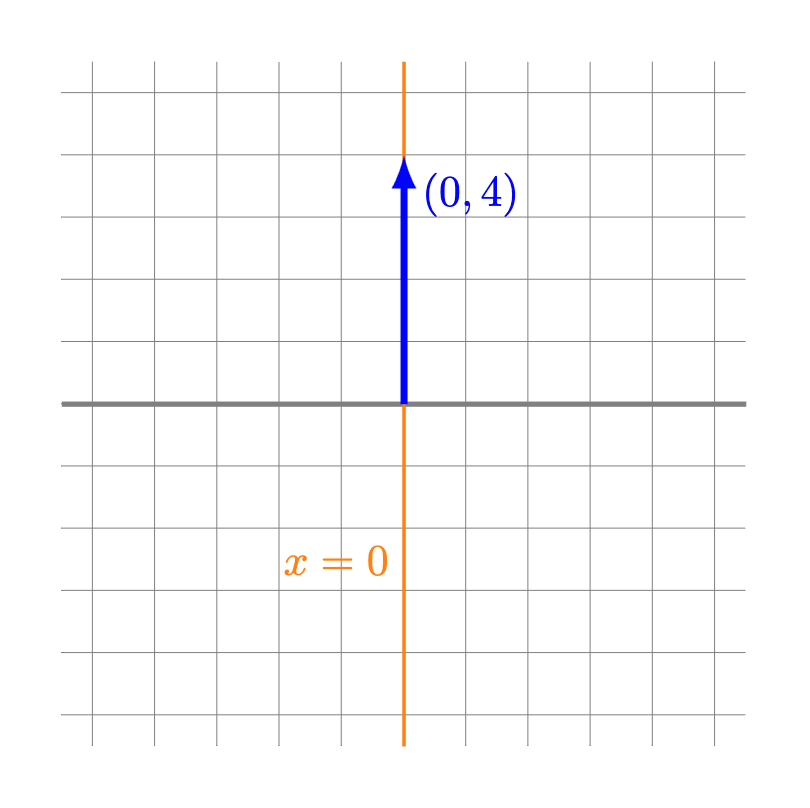
Ejemplo. El espacio generado por $(0,4)$ corresponde a todos los vectores $(x,y)$ tales que existe $r \in \mathbb{R}$ que cumple
\begin{align*}
(x,y) &= r(0,4) \\
(x,y) &= (0,4r),
\end{align*}
es decir,
\[
\begin{cases}
x = 0 \\
y = 4r
\end{cases}.
\]
En este caso, la única recta que satisface ambas ecuaciones es la recta $x = 0$, la cual no podemos expresar como función de $y$.
En la siguiente entrada veremos otras estrategias para describir de manera analítica el espacio generado.
$\triangle$
El saber si un vector está o no en el espacio generado por otros es una pregunta que se puede resolver con un sistema de ecuaciones lineales.
Ejemplo. ¿Será que el vector $(4,1,2)$ está en el espacio generado por los vectores $(2,3,1)$ y $(1,1,1)$? Para que esto suceda, necesitamos que existan reales $r$ y $s$ tales que $r(2,3,1)+s(1,1,1)=(4,1,2)$. Haciendo las operaciones vectoriales, esto quiere decir que $(2r+s,3r+s,r+s)=(4,1,2)$, de donde tenemos el siguiente sistema de ecuaciones:
$$\left\{\begin{matrix} 2r+s &=4 \\ 3r+s&=1 \\ r+s &= 2.\end{matrix}\right.$$
Este sistema no tiene solución. Veamos por qué. Restando la primera igualdad a la segunda, obtendríamos $r=1-4=-3$. Restando la tercera igualdad a la primera, obtendríamos $r=2-4=-2$. Así, si hubiera solución tendríamos la contradicción $-2=r=-3$. De este modo no hay solución.
Así, el vector $(4,1,2)$ no está en el espacio generado por los vectores $(2,3,1)$ y $(1,1,1)$. Geométricamente, $(4,1,2)$ no está en el plano en $\mathbb{R}^3$ generado por los vectores $(2,3,1)$ y $(1,1,1)$.
$\triangle$
Si las preguntas de espacio generado tienen que ver con sistemas de ecuaciones lineales, entonces seguramente estarás pensando que todo lo que hemos aprendido de sistemas de ecuaciones lineales nos servirá. Tienes toda la razón. Veamos un ejemplo importante.
Ejemplo. Mostraremos que cualquier vector en $\mathbb{R}^2$ está en el espacio generado por los vectores $(1,2)$ y $(3,-1)$. Para ello, tomemos el vector $(x,y)$ que nosotros querramos. Nos gustaría (fijando $x$ y $y$) poder encontrar reales $r$ y $s$ tales que $r(1,2)+s(3,-1)=(x,y)$. Esto se traduce al sistema de ecuaciones
$$\left \{ \begin{matrix} r+3s&=x\\2r-s&=y. \end{matrix} \right.$$
En forma matricial, este sistema es $$\begin{pmatrix} 1 & 3 \\ 2 & -1 \end{pmatrix} \begin{pmatrix} r \\ s \end{pmatrix} = \begin{pmatrix} x \\ y \end{pmatrix}.$$
Como la matriz $\begin{pmatrix} 1 & 3 \\ 2 & -1 \end{pmatrix}$ tiene determinante $1(-1)-(3)(2)=-7$, entonces es invertible. ¡Entonces el sistema siempre tiene solución única en $r$ y $s$ sin importar el valor de $x$ y $y$! Hemos con ello demostrado que cualquier vector $(x,y)$ es combinación lineal de $(1,2)$ y $(3,-1)$ y que entonces el espacio generado por ambos es todo $\mathbb{R}^2$.
$\triangle$
Independencia lineal
Mientras platicábamos en la sección anterior de las posibilidades que podía tener el espcio generado de un conjunto de vectores en $\mathbb{R}^2$ y $\mathbb{R}^3$, fuimos haciendo ciertas precisiones: «que ningún vector sea cero», «que nos vectores no estén alineados», «que ningún vector esté en los planos por los otros dos», etc. La intuición es que si pasaba lo contrario a alguna de estas cosas, entonces los vectores no podían generar «todo lo posible». Si sí se cumplían esas restricciones, entonces cierta cantidad de vectores sí tenía un espacio generado de la dimensión correspondiente (por ejemplo, $2$ vectores de $\mathbb{R}^3$ no cero y no alineados sí generan un plano, algo de dimensión $2$). Resulta que todas estas restricciones se pueden resumir en una definición muy importante.
Definición. Dado un conjunto de $n$ vectores $v_1, \ldots, v_n$ en $\mathbb{R}^2$ o ($\mathbb{R}^3$), diremos que son linealmente independientes si es imposible escribir al vector $0$ como combinación lineal de ellos, a menos que todos los coeficientes de la combinación lineal sean iguales a $0$. En otras palabras, si sucede que $$r_1v_1 + r_2v_2 + \cdots + r_nv_n=0,$$ entonces forzosamente fue porque $r_1=r_2=\ldots=r_n=0$.
Puede mostrarse que si un conjunto de vectores es linealmente independiente, entonces ninguno de ellos se puede escribir como combinación lineal del resto de vectores en el conjunto. Así, la intuición de que «generan todo lo que pueden generar» se puede justificar como sigue: como el primero no es cero, genera una línea. Luego, como el segundo no es múltiplo del primero, entre los dos generarán un plano. Y si estamos en $\mathbb{R}^3$, un tercer vector quedará fuera de ese plano (por no ser combinación lineal de los anteriores) y entonces generarán entre los tres a todo el espacio.
La independencia lineal también se puede estudiar mediante sistemas de ecuaciones lineales.
Ejemplo. ¿Serán los vectores $(3,-1,-1)$, $(4,2,1)$ y $(0,-10,-7)$ linealmente independientes? Para determinar esto, queremos saber si existen escalares $r,s,t$ tales que $r(3,-1,-1)+s(4,2,1)+t(0,-10,-7)=(0,0,0)$ en donde al menos alguno de ellos no es el cero. Esto se traduce a entender las soluciones del siguiente sistema de ecuaciones:
$$\left\{ \begin{array} 33r + 4s &= 0 \\ -r +2s -10t &= 0 \\ -r + s -7t &= 0.\end{array} \right. $$
Podemos entender todas las soluciones usando reducción Gaussiana en la siguiente matriz:
$$\begin{pmatrix} 3 & 4 & 0 & 0 \\ -1 & 2 & -10 & 0 \\ -1 & 1 & -7 & 0 \end{pmatrix}.$$
Tras hacer esto, obtenemos la siguiente matriz:
$$\begin{pmatrix}1 & 0 & 4 & 0\\0 & 1 & -3 & 0\\0 & 0 & 0 & 0 \end{pmatrix}.$$
Así, este sistema de ecuaciones tiene a $t$ como variable libre, que puede valer lo que sea. De aquí, $s=3t$ y $r=-4t$ nos dan una solución. Así, este sistema tiene una infinidad de soluciones. Tomando por ejemplo $t=1$, tenemos $s=3$ y $r=-4$. Entonces hemos encontrado una combinación lineal de los vectores que nos da el vector $(0,0,0)$. Puedes verificar que, en efecto, $$(-4)(3,-1,-1)+3(4,2,1)+(0,-10,-7)=(0,0,0).$$
Concluimos que los vectores no son linealmente independientes.
$\triangle$
Si la única solución que hubiéramos obtenido es la $r=s=t=0$, entonces la conclusión hubiera sido que sí, que los vectores son linealmente independientes. También podemos usar lo que hemos aprendido de matrices y determinantes en algunos casos para poder decir cosas sobre la independencia lineal.
Ejemplo. Mostraremos que los vectores $(2,3,1)$, $(0,5,2)$ y $(0,0,1)$ son linealmente independientes. ¿Qué sucede si una combinación lineal de ellos fuera el vector cero? Tendríamos que $r(2,3,1)+s(0,5,2)+t(0,0,1)=(0,0,0)$, que se traduce en el sistema de ecuaciones $$\left\{ \begin{array} 2r &= 0 \\ 3r + 5s &= 0 \\ r + 2s + t &= 0. \end{array}\right.$$
La matriz asociada a este sistema de ecuaciones es $\begin{pmatrix} 2 & 0 & 0 \\ 3 & 5 & 0 \\ 1 & 2 & 1 \end{pmatrix}$, que por ser triangular inferior tiene determinante $2\cdot 5 \cdot 1 = 10\neq 0$. Así, es una matriz invertible, de modo que el sistema de ecuaciones tiene una única solución. Como $r=s=t$ sí es una solución, esta debe ser la única posible. Así, los vectores $(2,3,1)$, $(0,5,2)$ y $(0,0,1)$ son linealmente independientes. Geométricamente, ninguno de ellos está en el plano hecho por los otros dos.
$\triangle$
Bases
Como vimos anteriormente, existen casos en los que el espacio generado por vectores en $\mathbb{R}^2$ (o $\mathbb{R}^3$) no genera a todo el plano (o al espacio). Por ejemplo, en ambos espacios vectoriales, el espacio generado por únicamente un vector es una recta. Esto también puede pasar aunque tengamos muchos vectores. Si todos ellos están alineados con el vector $0$, entonces su espacio generado sigue siendo una recta también. En la sección anterior platicamos que intuitivamente el problema es que los vectores no son linealmente independientes. Así, a veces unos vectores no generan todo el espacio que pueden generar.
Hay otras ocasiones en las que unos vectores sí generan todo el espacio que pueden generar, pero lo hacen de «manera redundante», en el sentido de que uno o más vectores se pueden poner de más de una forma como combinación lineal de los vectores dados.
Ejemplo. Si consideramos los vectores $(2,1)$, $(1,0)$ y $(2,3)$, observamos que el vector $(2,3)$ se puede escribir como
\[
0(2,1)+3(1,0) + 2(2,3) = (7,6)
\]
o
\[
3(2,2) + 1(1,0) + 0(2,3)= (7,6),
\]
siendo ambas combinaciones lineales del mismo conjunto de vectores.
$\triangle$
Uno de los tipos de conjuntos de vectores más importantes en el álgebra lineal son aquellos conocidos como bases, que evitan los dos problemas de arriba. Por un lado, sí generan a todo el espacio. Por otro lado, lo hacen sin tener redundancias.
Definición. Diremos que un conjunto de vectores es base de $\mathbb{R}^2$ (resp. $\mathbb{R}^3$) si su espacio generado es todo $\mathbb{R}^2$ (resp. $\mathbb{R}^3$) y además son linealmente independientes.
El ejemplo de base más inmediato es el conocido como base canónica.
Ejemplo. En el caso de $\mathbb{R}^2$, la base canónica es $(1,0)$ y $(0,1)$. En \mathbb{R}^3$ la base canónica es $(1,0,0)$, $(0,1,0)$ y $(0,0,1)$.
Partiendo de las definiciones dadas anteriormente, vamos que cualquier vector $(a,b)$ en $\mathbb{R}$ se puede escribir como $a(1,0) + b(0,1)$; y cualquier vector $(a,b,c)$ en $\mathbb{R}^3$ se puede escribir como $a(1,0,0) + b(0,1,0) + c(0,0,1)$.
Más aún, es claro que los vectores $(1,0)$ y $(0,1)$ no están alineados con el origen. Y también es claro que $(1,0,0),(0,1,0),(0,0,1)$ son linealmente idependientes, pues la combinación lineal $r(1,0,0)+s(0,1,0)+t(0,0,1)=(0,0,0)$ implica directamente $r=s=t=0$.
$\triangle$
Veamos otros ejemplos.
Ejemplo. Se tiene lo siguiente:
- Los vectores $(3,4)$ y $(-2,0)$ son base de $\mathbb{R}^2$ pues son linealmente independientes y su espacio generado es todo $\mathbb{R}^2$.
- Los vectores $(8,5,-1)$, $(2,2,7)$ y $(-1,0,9)$ son base de $\mathbb{R}^3$ pues son linealmente independientes y su espacio generado es todo $\mathbb{R}^3$.
¡Ya tienes todo lo necesario para demostrar las afirmaciones anteriores! Inténtalo y haz dibujos en $\mathbb{R}^2$ y $\mathbb{R}^3$ de dónde se encuentran estos vectores.
$\triangle$
Como podemos observar, las bases de un espacio vectorial no son únicas, sin embargo, las bases que mencionamos para $\mathbb{R}^2$ coinciden en tener dos vectores, mientras que las bases para $\mathbb{R}^3$ coinciden en tener tres vectores. ¿Será cierto que todas las bases para un mismo espacio vectorial tienen la misma cantidad de vectores?
Más adelante…
En esta entrada revisamos qué propiedades debe cumplir una colección de objetos matemáticos para que sea considerado un espacio vectorial, además de que analizamos con más detalle los espacios vectoriales $\mathbb{R}^2$ y $\mathbb{R}^3$.
Como seguramente sospecharás, para otros valores de $n$ también se cumple que $\mathbb{R}^n$, en conjunto con sus respectivas suma entrada a entrada y producto escalar, forman un espacio vectorial. Sin embargo, en contraste con los espacios $\mathbb{R}^2$ y $\mathbb{R}^3$, este espacio es más difícil de visualizar. En la siguiente entrada generalizaremos para $\mathbb{R}^n$ varias de las propiedades que aprendimos en esta entrada.
Tarea moral
- Realiza lo siguiente:
- De entre los siguientes vectores, encuentra dos que sean linealmente independientes: $(10,16),(-5,-8),(24,15),(10,16),(15,24),(-20,-32)$.
- Encuentra un vector de $\mathbb{R}^2$ que genere a la recta $2x+3y=0$.
- Determina qué es el espacio generado por los vectores $(1,2,3)$ y $(3,2,1)$ de $\mathbb{R}^3$.
- Da un vector $(x,y,z)$ tal que $(4,0,1)$, $(2,1,0)$ y $(x,y,z)$ sean una base de $\mathbb{R}^3$.
- Demuestra que $(0,0)$ es el único vector $w$ en $\mathbb{R}^2$ tal que para todo vector $v$ de $\mathbb{R}^2$ se cumple que $v+w=v=w+v$.
- Prueba las siguientes dos afirmaciones:
- Tres o más vectores en $\mathbb{R}^2$ nunca son linealmente independientes.
- Dos o menos vectores en $\mathbb{R}^3$ nunca son un conjunto generador.
- Sean $u$ y $v$ vectores en $\mathbb{R}^2$ distintos del vector cero. Demuestra que $u$ y $v$ son linealmente independientes si y sólo si $v$ no está en la línea generada por $u$.
- Encuentra todas las bases de $\mathbb{R}^3$ en donde las entradas de cada uno de los vectores de cada base sean iguales a $0$ ó a $1$.
Entradas relacionadas