Introducción
En la entrada anterior buscábamos optimizar un campo escalar $f$. Retomaremos este problema, pero ahora agregando restricciones al dominio de $f$. Para ello hablaremos del método de los multiplicadores de Lagrange, el cual nos permitirá dar una solución bajo ciertas condiciones de diferenciabilidad.
Esto en general es lo mejor que podremos hacer. En realidad, los problemas de este estilo son muy difíciles y no tienen una solución absoluta. Si no tenemos las condiciones del teorema de Lagrange, es posible que se tengan que hacer cosas mucho más compliadas para obtener óptimos exactos, o bien que se tengan que hacer aproximaciones numéricas.
En la demostración del teorema de los multiplicadores de Lagrange usaremos el teorema de la función implícita, lo cual es evidencia adicional de lo importante y versátil que es este resultado.
Un ejemplo para motivar la teoría
Imagina que tenemos la función $f(x,y)=x^2+y^2$ y queremos encontrar su mínimo. Esto es muy fácil. El mínimo se da cuando $x=y=0$, pues en cualquier otro valor tenemos un número positivo. Pero, ¿Qué pasaría si además queremos que los pares $(x,y)$ que usamos satisfagan también otra condición?, por ejemplo, que cumplan $$2x^2+3y^2=10$$
En este caso, la respuesta ya no es obvia. Podríamos intentar encontrar el mínimo por inspección, pero suena que será difícil. Podríamos intentar usar la teoría de la entrada anterior, pero esa teoría no nos dice nada de qué hacer con nuestra condición.
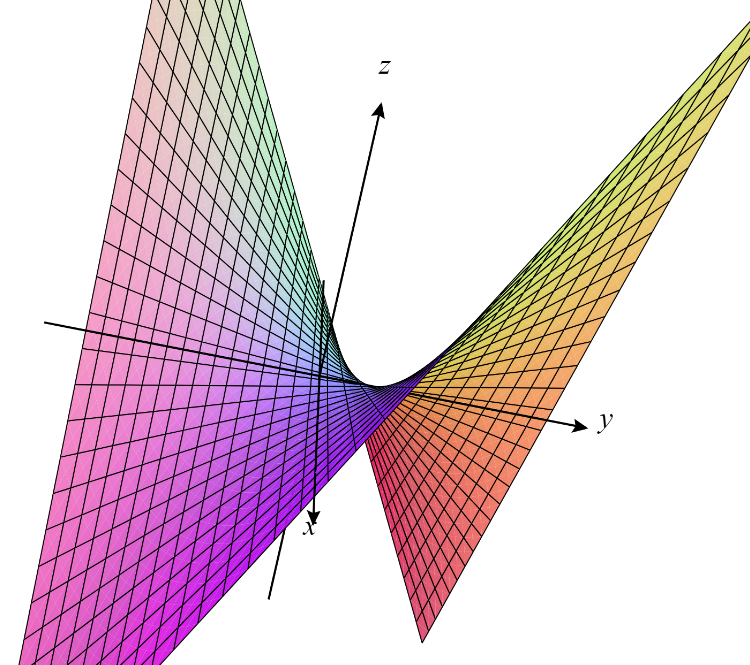
La teoría que desarrollaremos a continuación nos permitirá respondernos preguntas de este estilo. En este ejemplo en concreto, puedes pensar que la solución se obtendrá de la siguiente manera: La ecuación $2x^2+3y^2=10$ nos dibuja una elipse en el plano, como se ve en la figura 1 imagen 3. Las curvas de nivel de la superficie dibujada por la gráfica de la función $f$ corresponden a circunferencias concéntricas, cuyo centro es el origen. Al ir tomando circunferencias cada vez mas grandes en el plano comenzando con el punto $(0,0)$ nos quedaremos con la primera que toque a la elipse, de hecho la tocará en dos puntos, digamos $(x_1 ,y_1)$ y $(x_2 ,y_2)$, donde $f(x_1 ,y_1)=f(x_2 ,y_2)$ sería el mínimo buscado, es decir el mínimo que sobre la superficie $f(x,y)$ cumple con la ecuación $2x^2+3y^2=10$.
Pero como ahí se da una tangencia, entonces suena que justo en ese punto $(x,y)$ hay una recta simultáneamente tangente a la curva de nivel y a la elipse. Esto nos da una relación entre gradientes. El teorema de multiplicadores de Lagrange detecta y enuncia esta relación entre gradientes con precisión y formalidad, incluso cuando tenemos más de una condición. A estas condiciones también las llamamos restricciones, y están dadas por ecuaciones.
Enunciado del teorema de multiplicadores de Lagrange
A continuación enunciamos el teorema.
Teorema (multiplicadores de Lagrange). Sea $f:S\subseteq \mathbb{R}^{n}\rightarrow \mathbb{R}$ es un campo escalar de clase $C^{1}$. Para $m<n$, tomamos $g_{1},\dots ,g_{m}:S\in \subset \mathbb{R}^{n}\rightarrow \mathbb{R}$ campos escalares de clase $C^{1}$ en $S$. Consideremos el conjunto $S^\ast$ donde todos los $g_i$ se anulan, es decir:
$$S^\ast=\{ \bar{x}\in S|g_{1}(\bar{x})=g_2(\bar{x})=\ldots=g_m(\bar{x})=0\}.$$
Tomemos un $\bar{x}_0$ en $S^\ast$ para el cual
- $f$ tiene un extremo local en $\bar{x}_0$ para los puntos de $S^\ast$ y
- $\triangledown g_{1}(\bar{x}_{0}),\dots ,\triangledown g_{m}(\bar{x}_{0})$ son linealmente independientes.
Entonces existen $\lambda _{1},\dots ,\lambda _{m}\in \mathbb{R}$, a los que llamamos multiplicadores de Lagrange tales que:
\[ \triangledown f(\bar{x}_{0})=\lambda _{1}\triangledown g_{1}(\bar{x}_{0})+\dots +\lambda _{m}\triangledown g_{m}(\bar{x}_{0}).\]
Si lo meditas un poco, al tomar $m=1$ obtenemos una situación como la del ejemplo motivador. En este caso, la conclusión es que $\triangledown f(\bar{x}_0)=\lambda \triangledown g(\bar{x}_0)$, que justo nos dice que en $\bar{x}_0$, las gráficas de los campos escalares $f$ y $g$ tienen una tangente en común.
Demostración del teorema de multiplicadores de Lagrange
Demostración. La demostración del teorema de multiplicadores de Lagrange usa varios argumentos de álgebra lineal. Esto tiene sentido, pues a final de cuentas, lo que queremos hacer es poner un gradiente ($\triangledown f(\bar{x}_0)$) como combinación lineal de otros gradientes ($\triangledown g_1(\bar{x}_0),\ldots, \triangledown g_m(\bar{x}_0)$). A grandes rasgos, lo que haremos es:
- Definir un espacio $W$.
- Mostrar que $\triangledown g_1(\bar{x}_0),\ldots, \triangledown g_m(\bar{x}_0)$ generan al espacio ortogonal $W^\bot$.
- Mostrar que $\triangledown f(\bar{x}_0)$ es ortogonal a todo vector de $W$, por lo cual estará en $W^\bot$ y así por el inciso anterior será combinación lineal de $\triangledown g_1(\bar{x}_0),\ldots, \triangledown g_m(\bar{x}_0)$.
Para construir el espacio $W$ del que hablamos, usaremos el teorema de la función implícita y la regla de la cadena. Empecemos este argumento. Consideremos la siguiente matriz:
\[ \begin{equation} \begin{pmatrix} \frac{\partial g_{1}}{\partial x_{1}}(\bar{x}_{0}) & \dots & \frac{\partial g_{1}}{\partial x_{m}}(\bar{x}_{0}) & \frac{\partial g_{1}}{\partial x_{m+1}}(\bar{x}_{0}) & \dots & \frac{\partial g_{1}}{\partial x_{n}}(\bar{x}_{0}) \\ \vdots & \ddots & \vdots & \vdots & \ddots & \vdots \\ \frac{\partial g_{m}}{\partial x_{1}}(\bar{x}_{0}) & \dots & \frac{\partial g_{m}}{\partial x_{m}}(\bar{x}_{0}) & \frac{\partial g_{m}}{\partial x_{m+1}}(\bar{x}_{0}) & \dots & \frac{\partial g_{1}}{\partial x_{n}}(\bar{x}_{0}) \end{pmatrix}. \end{equation}\]
Dado que los vectores $\triangledown g_1(\bar{x}_0),\ldots, \triangledown g_m(\bar{x}_0)$ son linealmente independientes, el rango por renglones de esta matriz es $m$, de modo que su rango por columnas también es $m$ (tarea moral). Sin perder generalidad (quizás tras hacer una permutación de columnas, que permuta las entradas), tenemos que las primeras $m$ columnas son linealmente independientes. Así, la matriz
\[ \begin{pmatrix} \frac{\partial g_{1}}{\partial x_{1}}(\bar{x}_{0}) & \dots & \frac{\partial g_{1}}{\partial x_{m}}(\bar{x}_{0}) \\ \vdots & \ddots & \vdots \\ \frac{\partial g_{m}}{\partial x_{1}}(\bar{x}_{0}) & \dots & \frac{\partial g_{m}}{\partial x_{m}}(\bar{x}_{0}) \end{pmatrix}\]
es invertible. Hagamos $l=n-m$ y reetiquetemos las variables coordenadas $x_1,\ldots,x_m$ como $v_1,\ldots,v_m$, y las variables coordenadas $x_{m+1},\ldots,x_n$ como $u_1,\ldots, u_l$. Escribiremos $\bar{x}_0=(\bar{v}_0,\bar{u}_0)$ para referirnos al punto al que hacen referencia las hipótesis. Esto nos permite pensar $\mathbb{R}^{n}=\mathbb{R}^{m}\times \mathbb{R}^{l}$ y nos deja en el contexto del teorema de la función implícita. Como la matriz anterior es invertible, existen $U\subseteq \mathbb{R}^l$ y $V\subseteq \mathbb{R}^m$ para los cuales $\bar{u}_0\in U$, $\bar{v}_0\in V$ y hay una única función $h=(h_1,\ldots,h_m):U\to V$ de clase $C^1$ tal que para $\bar{u}\in U$ y $\bar{v}\in V$ se cumple que $g(\bar{v},\bar{u})=0$ si y sólo si $\bar{v}=h(\bar{u})$.
Definamos ahora la función $H:U\subseteq \mathbb{R}^{l}\rightarrow \mathbb{R}^{m}\times \mathbb{R}^{l}$ como $H(\bar{u})=(h(\bar{u}),\bar{u})$, la cual es de clase $C^{1}$ en $U$.
Por cómo construimos $h$, sucede que $(h(\bar{u}),\bar{u})\in S^{*}$ para toda $\bar{u}\in U$. Por definición, esto quiere decir que para toda $i=1,\ldots,m$ tenemos que $$(g_{i}\circ H)(\bar{u})=0$$ para toda $\bar{u}\in U$. Esto quiere decir que $g_i\circ H$ es una función constante y por lo tanto su derivada en $\bar{u}_0$ es la transformación $0$. Pero otra forma de obtener la derivada es mediante la regla de la cadena como sigue:
\begin{align*} D(g_{i}\circ H)(\bar{u}_{0})&=Dg_{i}(H(\bar{u}_{0}))DH(\bar{u}_{0})\\ &=Dg_{i}(\bar{v}_{0},\bar{u}_{0})DH(\bar{u}_{0}).\end{align*}
En términos matriciales, tenemos entonces que el siguiente producto matricial es igual al vector $(0,\ldots,0)$ de $l$ entradas (evitamos poner $(\bar{v}_0,\bar{u}_0)$ para simplificar la notación):
\[ \begin{equation}\begin{pmatrix} \frac{\partial g_{i}}{\partial v_{1}}& \dots & \frac{\partial g_{i}}{\partial v_{m}} & \frac{\partial g_{i}}{\partial u_{1}} & \dots & \frac{\partial g_{i}}{\partial u_{l}} \end{pmatrix}\begin{pmatrix} \frac{\partial h_{1}}{\partial u_{1}} & \dots & \frac{\partial h_{1}}{\partial u_{l}} \\ \vdots & \ddots & \vdots \\ \frac{\partial h_{m}}{\partial u_{1}} & \dots & \frac{\partial h_{m}}{\partial u_{l}} \\ 1 & \dots & 0 \\ \vdots & \ddots & \vdots \\ 0 & \dots & 1 \end{pmatrix}\end{equation},\]
para cada $i=1,\ldots, m$. Nos gustaría escribir esta conclusión de manera un poco más sencilla, para lo cual introducimos los siguientes vectores para cada $j=1,\ldots, l$:
\[ \bar{w}_{j}=\left( \left( \frac{\partial h_{1}}{\partial u_{j}}(\bar{u}_{0}),\dots ,\frac{\partial h_{m}}{\partial u_{j}}(\bar{u}_{0}) \right), \hat{e}_{j}\right).\]
Cada uno de estos lo pensamos como vector en $\mathbb{R}^m\times \mathbb{R}^l$. Además, son $l$ vectores linealmente independientes, pues sus entradas $\hat{e}_j$ son linealmente independientes. El espacio vectorial $W$ que generan es entonces un subespacio de $\mathbb{R}^m\times \mathbb{R}^l$, con $\dim(W)=l$.
De la ecuación $(2)$ tenemos que $\triangledown g_{i}(\bar{v}_{0},\bar{u}_{0})\cdot \bar{w}_{j}=0$ para todo $i=1,\dots ,m$, y $j=1,\dots ,l$. Se sigue que $\triangledown g_{i}(\bar{v}_{0},\bar{u}_{0})\in W^{\perp}$, donde $W^{\perp}$ es el complemento ortogonal de $W$ en $\mathbb{R}^{m}\times \mathbb{R}^{l}$. Pero además, por propiedades de espacios ortogonales tenemos que
\begin{align*}
\dim(W^{\perp})&=\dim(\mathbb{R}^{m}\times \mathbb{R}^{l})-dim(W)\\
&=m+l-l\\
&=m.
\end{align*}
Así $\dim(W^{\perp})=m$, además el conjunto $\left\{ \triangledown g_{i}(\bar{v}_{0},\bar{u}_{0}) \right\}_{i=1}^{m}$ es linealmente independiente con $m$ elementos, por tanto este conjunto es una base para $W^{\perp}$. Nuestra demostración estará terminada si logramos demostrar que $\triangledown f(\bar{v}_0,\bar{u}_0)$ también está en $W^\perp$, es decir, que es ortogonal a todo elemento de $W$.
Pensemos qué pasa al componer $f$ con $H$ en el punto $\bar{u}_0$. Afirmamos que $\bar{u}_0$ es un extremo local de $f\circ H$. En efecto, $(f\circ H)(\bar{u}_0)=f(g(\bar{u}_0),\bar{u}_0)=(\bar{v}_0,\bar{u}_0)$. Si, por ejemplo $(\bar{v}_0,\bar{u}_0)$ diera un máximo, entonces los valores $f(\bar{v},\bar{u})$ para $(\bar{v},\bar{u})$ dentro de cierta bola $B_\delta(\bar{v}_0,\bar{u}_0)$ serían menores a $f(\bar{v}_0,\bar{u}_0)$. Pero entonces los valores cercanos $\bar{u}$ a $\bar{u}_0$ cumplen $(f\circ H)(\bar{u})=f(h(\bar{u}),\bar{u})$, con $(\bar{u},h(\bar{u}))$ en $S^\ast$ y por lo tanto menor a $f(\bar{v}_0,\bar{u}_0)$ (para mínimos es análogo).
Resumiendo lo anterior, $\bar{u}_{0}$ es extremo local de $f\circ H$. Aplicando lo que aprendimos en la entrada anterior, la derivada de $f\circ H$ debe anularse en $\bar{u}_0$. Pero por regla de la cadena, dicha derivada es
\begin{align*}\triangledown (f\circ H)(\bar{u}_{0})&=D(f\circ H)(\bar{u}_{0})\\ &=Df(H(\bar{u}_{0}))DH(\bar{u}_{0})\\ &=Df(h(\bar{u}_{0}),\bar{u}_{0})DH(\bar{u}_{0})\\
&=Df(\bar{v}_0,\bar{u}_{0})DH(\bar{u}_{0})
\end{align*}
Viéndolo como multiplicación de matrices, el siguiente producto es el vector $(0,0,\ldots,0)$ de $l$ entradas:
\[ \begin{pmatrix} \frac{\partial f}{\partial v_{1}} & \dots & \frac{\partial f}{\partial v_{m}} & \frac{\partial f}{\partial u_{1}} & \dots & \frac{\partial f}{\partial u_{l}} \end{pmatrix}\begin{pmatrix} \frac{\partial h_{1}}{\partial u_{1}} & \dots & \frac{\partial h_{1}}{\partial u_{l}} \\ \vdots & \ddots & \vdots \\ \frac{\partial h_{m}}{\partial u_{1}} & \dots & \frac{\partial h_{m}}{\partial u_{l}} \\ 1 & \dots & 0 \\ \vdots & \ddots & \vdots \\ 0 & \dots & 1 \end{pmatrix}=0 \]
De donde concluimos $\triangledown f(\bar{v}_{0},\bar{u}_{0})\cdot \bar{w}_{j}=0$ para cada $j=1,\dots l$. Esto precisamente nos dice que $\triangledown f(\bar{v}_{0},\bar{u}_{0})\in W^{\perp}$. Esto es justo lo que queríamos, pues habíamos demostrado que $\left\{ \triangledown g_{i}(\bar{v}_{0},\bar{u}_{0}) \right\}_{i=1}^{m}$ es una base de $W^{\perp}$. Por ello podemos expresar a $\triangledown f(\bar{v}_{0},\bar{u}_{0})$ como combinación lineal de esta base, es decir, existen $\lambda _{1},\dots ,\lambda _{m}$ escalares tales que:
\[ \triangledown f(\bar{v}_{0},\bar{u}_{0})=\lambda _{1}\triangledown g_{1}(\bar{v}_{0},\bar{u}_{0})+\dots +\lambda _{m}\triangledown g_{m}(\bar{v}_{0},\bar{u}_{0}). \]
$\square$
¡Qué bonita demostración! Usamos el teorema de la función implícita, la regla de la cadena (dos veces), nuestros resultados para valores extremos de la entrada anterior, y un análisis cuidadoso de ciertos espacios vectoriales.
Ejemplos del método de multiplicadores de Lagrange
Veamos algunos problemas que podemos resolver con esta nueva herramienta.
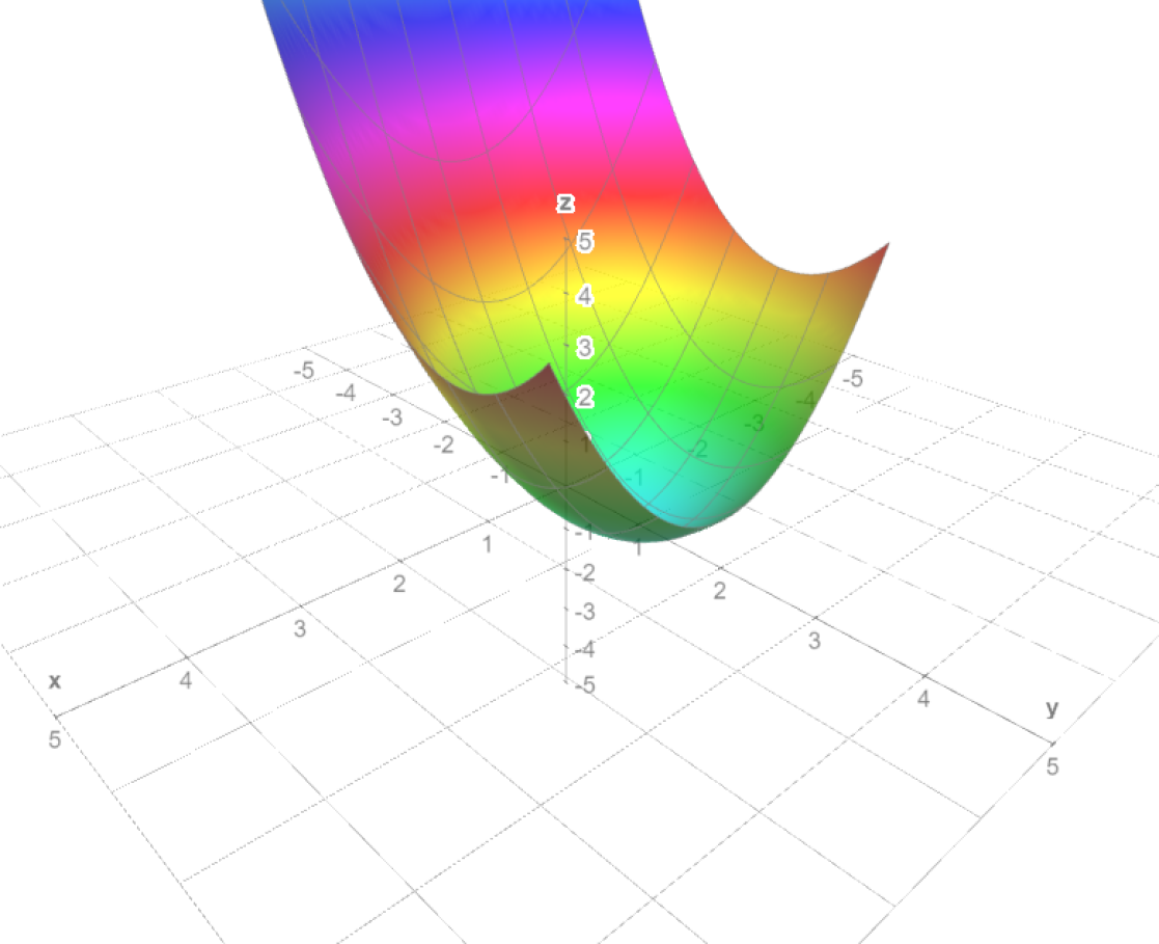
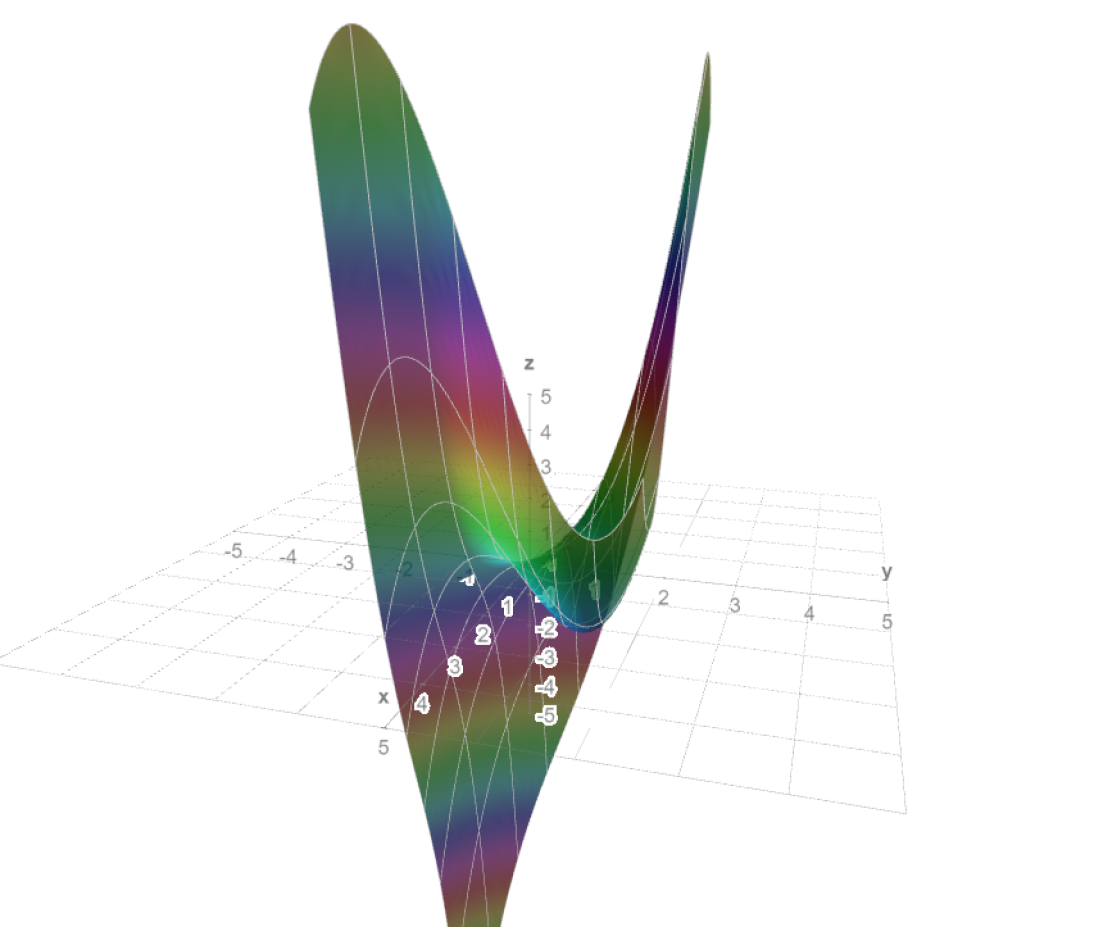
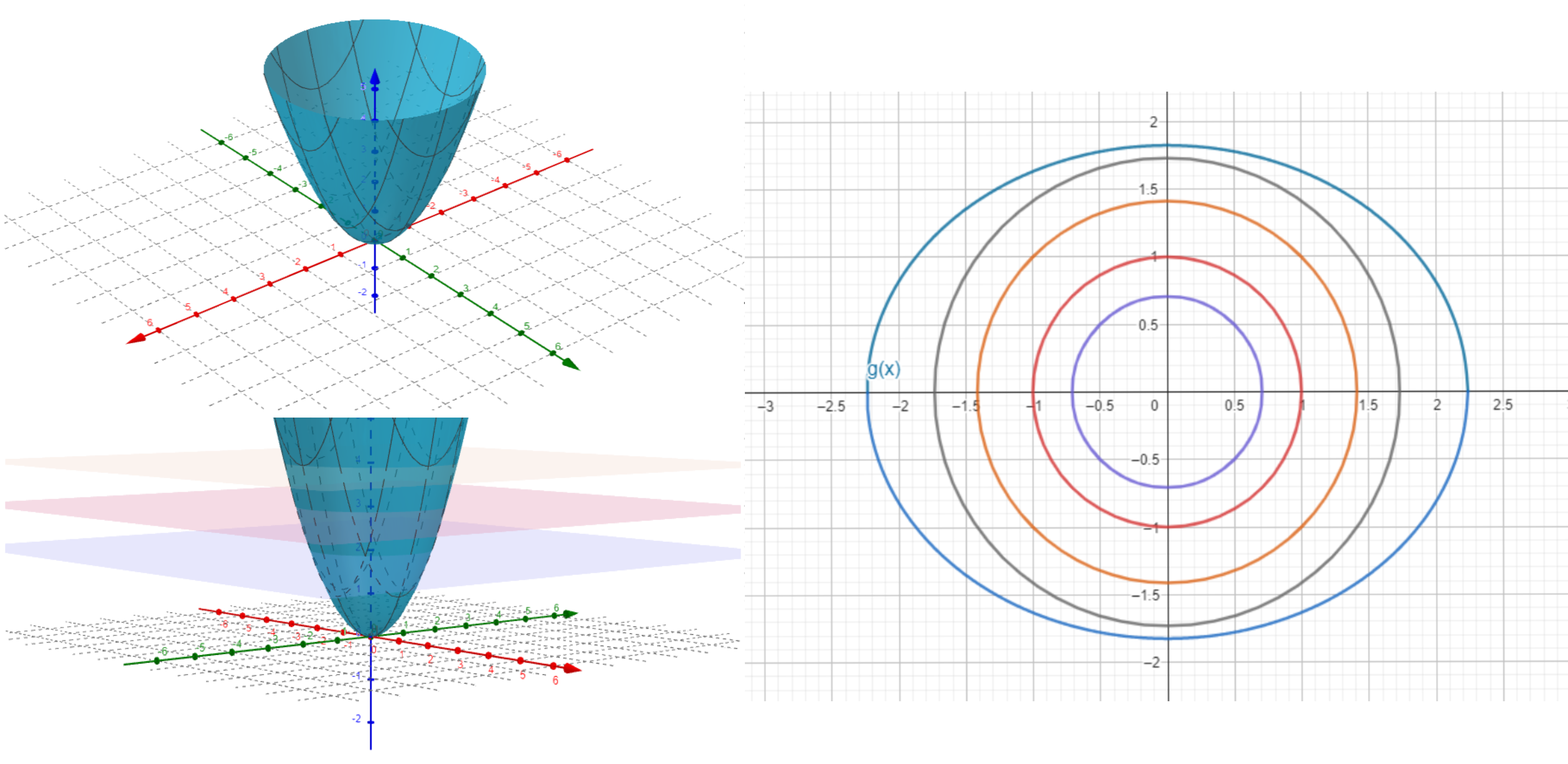
Ejemplo. Determinaremos los puntos extremos de $f(x,y)=x+2y$ bajo la condición $x^{2}+y^{2}=5$. Para poner todo en términos de nuestro teorema, definimos $g(x,y)=x^{2}+y^{2}-5$. Por el teorema de multiplicadores de Lagrange, en los puntos extremos debe existir una $\lambda$ tal que $\triangledown f(x,y)=\lambda \triangledown g(x,y)$. Calculando las parciales correspondientes, debemos tener entonces
\[ \left( 1,2 \right)=\lambda \left( 2x,2y \right).\]
Adicionalmente, recordemos que se debe satisfaces $g(x,y)=0$. Llegamos entonces al sistema de ecuaciones
\[ \left \{\begin{matrix} 1-2x\lambda=0 \\ 2-2y\lambda =0 \\ x^{2}+y^{2}-5=0 \end{matrix}\right. \]
Al despejar $x$ y $y$ en ambas ecuaciones tenemos:
\[ \begin{matrix} x=\frac{1}{2\lambda} \\ y=\frac{1}{\lambda} \\ x^{2}+y^{2}-5=0 \end{matrix}.\]
Poniendo los valores de $x$ y $y$ en la tercera ecuación, llegamos a $\left( \frac{1}{2\lambda}\right)^{2}+\left( \frac{1}{\lambda}\right)^{2}-5=0$, de donde al resolver tenemos las soluciones $\lambda _{1}=\frac{1}{2}$ y $\lambda _{2}=-\frac{1}{2}$.
Al sustituir en las ecuaciones de nuestro sistema, obtenemos como puntos críticos a $(x,y)=(-1,-2)$ y $(x,y)=(1,2)$.
Si intentamos calcular el hessiano de $f$, esto no nos dirá nada (no tendremos eigenvalores sólo positivos, ni sólo negativos). Pero esto ignora las restricciones que nos dieron. Podemos hacer una figura para entender si estos puntos son máximos o mínimos. En la Figura $1$ tenemos la gráfica de $f$, intersectada con la superfice dada por $g$. Nos damos cuenta que hay un punto máximo y uno mínimo. Al evaluar, obtenemos $f(1,2)=5$ y $f(-1,-2)=-5$. Esto nos dice que el máximo en la superficie se alcanza en $(1,2)$ y el mínimo en $(-1,-2)$.

$\triangle$
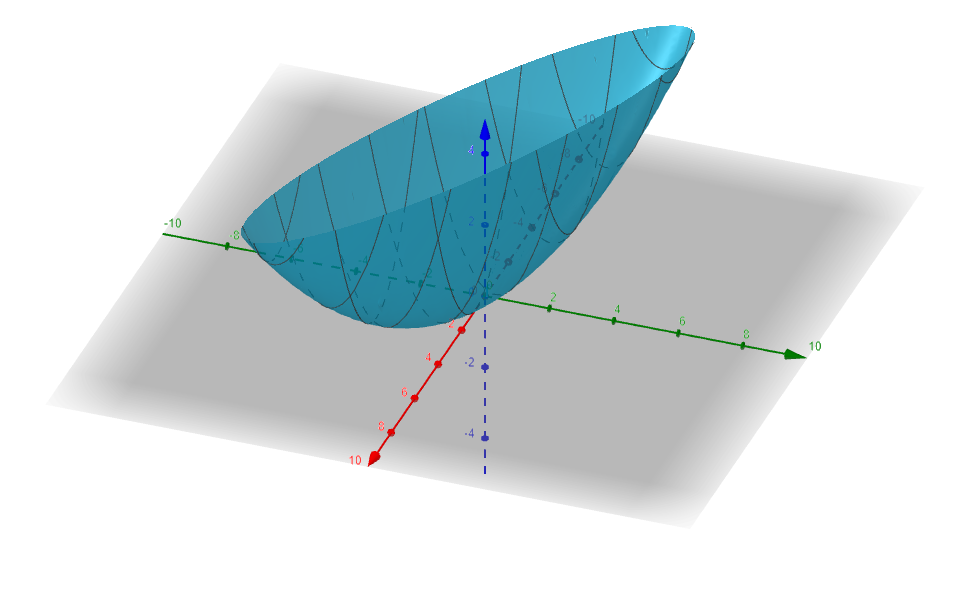
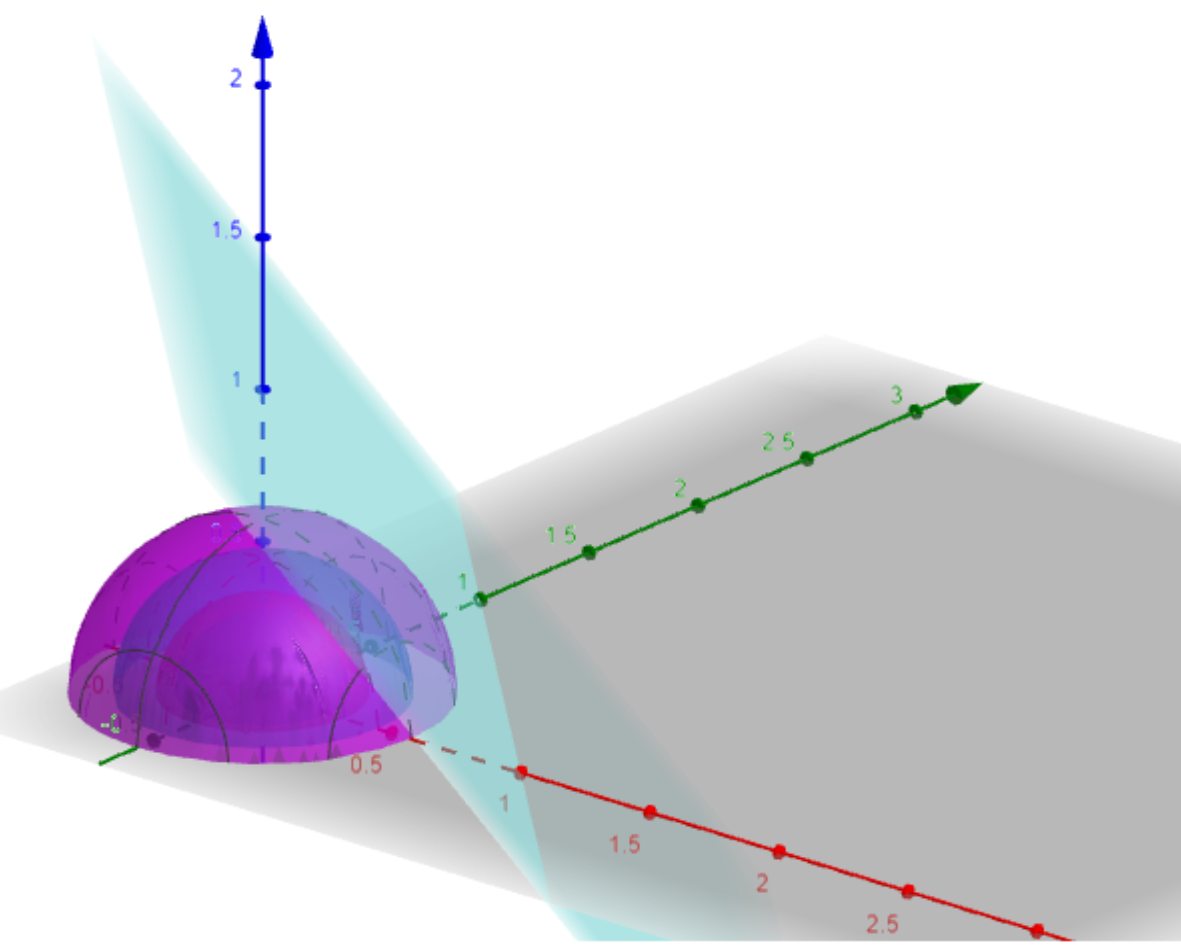
Ejemplo. Veamos cómo minimizar la expresión $$f(x,y,z)=x^{2}+y^{2}+z^{2}$$ sujetos a la condición $x+y+z=1$. Una vez más, proponemos $g(x,y,z)=x+y+z-1$ para tener la situación del teorema de multiplicadores de Lagrange. Debe pasar que $\lambda$ $\triangledown f(x,y,z)=\lambda \triangledown g(x,y,z)$. El gradiente de $g(x,y,z)$ es de puros ceros unos, así que tenemos el sistema de ecuaciones:
\[ \left \{\begin{matrix} 2x=\lambda \\ 2y=\lambda \\ 2z=\lambda \\ x+y+z-1=0 \end{matrix}\right.\]
De las primeras tres ecuaciones tenemos $2x=2y=2z$ de donde $x=y=z$. Sustituyendo en la tercera ecuación, $3x-1=0$, es decir $x=y=z=\frac{1}{3}$. Ya que sólo tenemos una solución, ésta es el mínimo del conjunto de soluciones. En la figura 3 tenemos la ilustración de la solución de este problema, la esfera centrada en el origen de radio $\frac{1}{3}$ toca al plano $x+y+z=1$ en el punto $\left( \frac{1}{3},\frac{1}{3},\frac{1}{3}\right)$
$\triangle$
Más adelante…
Con esta entrada cerramos el curso de Cálculo Diferencial e Integral III. ¡¡Felicidades!! Esperamos que todas estas notas te hayan sido de ayuda para estudiar, repasar o impartir la materia. Quedamos al pendiente de cualquier duda, observación o sugerencia en la sección de comentarios de las entradas.
Tarea moral
- Determina los extremos de la función $f(x,y)=xy+14$ bajo la restricción $x^{2}+y^{2}=18$
- El plano $x+y+2z=2$ interseca al paraboloide $z=x^{2}+y^{2}$ en una elipse $\mathbb{E}$. Determina el punto de la elipse con el valor mayor en el eje $z$, y el punto con el valor mínimo en el mismo eje. Sugerencia: $f(x,y,z)=x+y+2z-2$, y $g(x,y,z)=x^{2}+y^{2}-z$
- Determinar el máximo valor de $f(x,y,z)=x^{2}+36xy-4y^{2}-18x+8y$ bajo la restricción $3x+4y=32$
- Determinar los puntos extremos de la función $f(x,y,z)=x^{2}+y^{2}+z^{2}$ bajo la restricción $xyz=4$
- Demuestra que en una matriz $M$ su rango por columnas es igual a su rango por renglones. Sugerencia. Usa el teorema de reducción gaussiana. También, puedes revisar la entrada que tenemos sobre rango de matrices.
Entradas relacionadas
- Ir a Cálculo Diferencial e Integral III
- Entrada anterior del curso: Puntos críticos de campos escalares