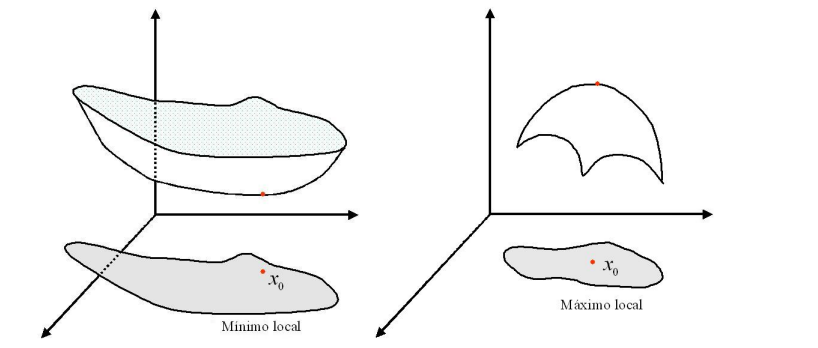
Extremos Locales parte 2 pequeño
Para el caso de funciones $f:\mathbb{R}^{3}\rightarrow\mathbb{R}$ tenemos que recordando un poco de la expresión de taylor
$$f(x,y)=f(x_{0},y_{0})+\left(\frac{\partial f}{\partial x}\right){p}(x-x_{0})+\left(\frac{\partial f}{\partial y}\right){p}(y-y_{0})+\left(\frac{\partial f}{\partial z}\right){p}(z-z_{0})+$$
$$\textcolor{Red}{\frac{1}{2!}\left(\frac{\partial^{2}f}{\partial
x^{2}}{p}(x-x_{0})^{2}+2\frac{\partial^{2}f}{\partial x \partial
y}{p}(x-x_{0})(y-y_{0})+\frac{\partial^{2}f}{\partial
y^{2}}{p}(y-y_{0})^{2}+2\frac{\partial^{2}f}{\partial
x\partial z}{p}(z-z_{0})(x-x_{0})+2\frac{\partial^{2}f}{\partial
y\partial z}{p}(z-z_{0})(y-y_{0})\right)}$$
$$\textcolor{Red}{+\frac{\partial^{2}f}{\partial
z^{2}}{p}(z-z_{0})}$$
Haciendo $x-x_{0}=h_{1},y-y_{0}=h_{2},z-z_{0}=h_{3}$ podemos escribir el término rojo de la siguiente manera
$$\frac{1}{2!}\left(\frac{\partial^{2}f}{\partial x^{2}}h_{1}^{2}+2\frac{\partial^{2}f}{\partial x\partial y}h_{1}h_{2}+\frac{\partial^{2}f}{\partial y^{2}}h_{2}^{2}+2\frac{\partial^{2}f}{\partial x\partial z}h_{3}h_{1}+2\frac{\partial^{2}f}{\partial y\partial z}h_{3}h_{2}+\frac{\partial^{2}f}{\partial z^{2}}h_{3}^{2}\right)$$
y también se puede ver como producto de matrices
$$\frac{1}{2!}(h_{1}~h_{2}~h_{3})\left(\begin{matrix}\frac{\partial^{2}f}{\partial
x^{2}}&\frac{\partial^{2}f}{\partial y\partial x}&\frac{\partial^{2}f}{\partial z\partial x}\\\frac{\partial^{2}f}{\partial x\partial y}&\frac{\partial^{2}f}{\partial
y^{2}}&\frac{\partial^{2}f}{\partial z\partial y}\\\frac{\partial^{2}f}{\partial
x\partial z}&\frac{\partial^{2}f}{\partial y\partial z}&\frac{\partial^{2}f}{\partial z^{2}}\end{matrix}\right){p}\left(\begin{matrix}h{1}\\h_{2}\\h_{3}\end{matrix}\right)$$
Si $(x_{0},y_{0},z_{0})$ es un punto critico de la función entonces en la expresión de Taylor
$$f(x,y)=f(x_{0},y_{0})+\left(\frac{\partial f}{\partial
x}\right){p}(x-x_{0})+\left(\frac{\partial f}{\partial
y}\right){p}(y-y_{0})+\left(\frac{\partial f}{\partial
z}\right){p}(z-z_{0})$$
$$\textcolor{Red}{\frac{1}{2!}\left(\frac{\partial^{2}f}{\partial
x^{2}}{p}(x-x_{0})^{2}+2\frac{\partial^{2}f}{\partial x \partial
y}{p}(x-x_{0})(y-y_{0})+\frac{\partial^{2}f}{\partial
y^{2}}{p}(y-y{0})^{2}+2\frac{\partial^{2}f}{\partial
x\partial z}{p}(z-z{0})(x-x_{0})+2\frac{\partial^{2}f}{\partial
y\partial z}{p}(z-z_{0})(y-y_{0})\right)}$$
$$\textcolor{Red}{+\frac{\partial^{2}f}{\partial
z^{2}}{p}(z-z_{0})(x-x_{0})}$$
El término
$$\frac{\partial f}{\partial x}{p}(x-x_{0})+\frac{\partial f}{\partial y}{p}(y-y_{0})+\frac{\partial f}{\partial z}{p}(z-z_{0})=0$$
y por lo tanto
$$f(x,y)-f(x_{0},y_{0})=\frac{1}{2!}(h_{1}~h_{2}~h_{3})\left(\begin{matrix}\frac{\partial^{2}f}{\partial
x^{2}}&\frac{\partial^{2}f}{\partial
y\partial x}&\frac{\partial^{2}f}{\partial
z\partial x}\\\frac{\partial^{2}f}{\partial
x\partial y}&\frac{\partial^{2}f}{\partial
y^{2}}&\frac{\partial^{2}f}{\partial
z\partial y}\\\frac{\partial^{2}f}{\partial
x\partial z}&\frac{\partial^{2}f}{\partial
y\partial z}&\frac{\partial^{2}f}{\partial
z^{2}}\end{matrix}\right){p}\left(\begin{matrix}h{1}\\h_{2}\\h_{3}\end{matrix}\right)$$
vamos a determinar el signo de la forma
$$Q(h)=\frac{1}{2!}(h_{1}~h_{2}~h_{3})\left(\begin{matrix}\frac{\partial^{2}f}{\partial
x^{2}}&\frac{\partial^{2}f}{\partial
y\partial x}&\frac{\partial^{2}f}{\partial
z\partial x}\\\frac{\partial^{2}f}{\partial
x\partial y}&\frac{\partial^{2}f}{\partial
y^{2}}&\frac{\partial^{2}f}{\partial
z\partial y}\\\frac{\partial^{2}f}{\partial
x\partial z}&\frac{\partial^{2}f}{\partial
y\partial z}&\frac{\partial^{2}f}{\partial
z^{2}}\end{matrix}\right){p}\left(\begin{matrix}h{1}\\h_{2}\\h_{3}\end{matrix}\right)$$
vamos a trabajar sin el término $\displaystyle{\frac{1}{2!}}$ que no afectara al signo de la expresión, tenemos entonces
$$Q(h)=(h_{1}~h_{2}~h_{3})\left(\begin{matrix}\frac{\partial^{2}f}{\partial
x^{2}}&\frac{\partial^{2}f}{\partial
y\partial x}&\frac{\partial^{2}f}{\partial
z\partial x}\\\frac{\partial^{2}f}{\partial
x\partial y}&\frac{\partial^{2}f}{\partial
y^{2}}&\frac{\partial^{2}f}{\partial
z\partial y}\\\frac{\partial^{2}f}{\partial
x\partial z}&\frac{\partial^{2}f}{\partial
y\partial z}&\frac{\partial^{2}f}{\partial
z^{2}}\end{matrix}\right){p}\left(\begin{matrix}h{1}\\h_{2}\\h_{3}\end{matrix}\right)=\textcolor{Red}{\frac{\partial^{2}f}{\partial x^{2}}h_{1}^{2}+2\frac{\partial^{2}f}{\partial x\partial y}h_{1}h_{2}+\frac{\partial^{2}f}{\partial y^{2}}h_{2}^{2}}+2\frac{\partial^{2}f}{\partial x\partial z}h_{3}h_{1}+2\frac{\partial^{2}f}{\partial y\partial z}h_{3}h_{2}+\frac{\partial^{2}f}{\partial z^{2}}h_{3}^{2}$$
$$=\textcolor{Red}{\frac{\partial^{2}f}{\partial x^{2}}\left(h_{1}+\frac{\frac{\partial^{2}f}{\partial y\partial x}}{\frac{\partial^{2}f}{\partial x^{2}}}h_{2}\right)^{2}+\left(\frac{\frac{\partial^{2}f}{\partial y^{2}}\frac{\partial^{2}f}{\partial x^{2}}-\left(\frac{\partial^{2}f}{\partial y\partial x}\right)^{2}}{\frac{\partial^{2}f}{\partial x^{2}}}\right)h_{2}^{2}}+2\frac{\partial^{2}f}{\partial x\partial z}h_{3}h_{1}+2\frac{\partial^{2}f}{\partial y\partial z}h_{3}h_{2}+\frac{\partial^{2}f}{\partial z^{2}}h_{3}^{2}$$
$$=\textcolor{Red}{\frac{\partial^{2}f}{\partial x^{2}}\left(h_{1}+\frac{\frac{\partial^{2}f}{\partial y\partial x}}{\frac{\partial^{2}f}{\partial x^{2}}}h_{2}\right)^{2}+\left(\frac{\frac{\partial^{2}f}{\partial y^{2}}\frac{\partial^{2}f}{\partial x^{2}}-\left(\frac{\partial^{2}f}{\partial y\partial x}\right)^{2}}{\frac{\partial^{2}f}{\partial x^{2}}}\right)h_{2}^{2}}+2\frac{\partial^{2}f}{\partial x\partial z}h_{3}h_{1}+2\frac{\partial^{2}f}{\partial y\partial z}h_{3}h_{2}+\frac{\partial^{2}f}{\partial z^{2}}h_{3}^{2}$$
hacemos $\displaystyle{b_{1}=\frac{\partial^{2}f}{\partial x^{2}},h_{1}’=\left(h_{1}+\frac{\frac{\partial^{2}f}{\partial y\partial x}}{\frac{\partial^{2}f}{\partial x^{2}}}h_{2}\right),b_{2}=\frac{\frac{\partial^{2}f}{\partial y^{2}}\frac{\partial^{2}f}{\partial x^{2}}-\left(\frac{\partial^{2}f}{\partial y\partial x}\right)^{2}}{\frac{\partial^{2}f}{\partial x^{2}}},~~h_{2}’=h_{2}}$ y obtenemos
$$=b_{1}h_{1}’^{2}+b_{2}h_{2}’^{2}+2\frac{\partial^{2}f}{\partial x\partial z}h_{3}h_{1}+2\frac{\partial^{2}f}{\partial y\partial z}h_{3}h_{2}+\frac{\partial^{2}f}{\partial z^{2}}h_{3}^{2}$$
que podemos escribir
$$=b_{1}h_{1}’^{2}+b_{2}h_{2}’^{2}+2\frac{\partial^{2}f}{\partial x\partial z}\left(h_{1}+\frac{\frac{\partial^{2}f}{\partial y\partial x}}{\frac{\partial^{2}f}{\partial x^{2}}}h_{2}-\frac{\frac{\partial^{2}f}{\partial y\partial x}}{\frac{\partial^{2}f}{\partial x^{2}}}h_{2}\right)h_{3}+2\frac{\partial^{2}f}{\partial y\partial z}h_{3}h_{2}+\frac{\partial^{2}f}{\partial z^{2}}h_{3}^{2}$$
$$=b_{1}h_{1}’^{2}+b_{2}h_{2}’^{2}+2\frac{\partial^{2}f}{\partial x\partial z}\left(h_{1}’-\frac{\frac{\partial^{2}f}{\partial y\partial x}}{\frac{\partial^{2}f}{\partial x^{2}}}h_{2}’\right)h_{3}+2\frac{\partial^{2}f}{\partial y\partial z}h_{3}h_{2}+\frac{\partial^{2}f}{\partial z^{2}}h_{3}^{2}$$
$$=b_{1}h_{1}’^{2}+b_{2}h_{2}’^{2}+2\frac{\partial^{2}f}{\partial x\partial z}h_{1}’h_{3}+\left(2\frac{\partial^{2}f}{\partial y\partial z}-\frac{2\frac{\partial^{2}f}{\partial x\partial z}\frac{\partial^{2}f}{\partial y\partial x}}{\frac{\partial^{2}f}{\partial x^{2}}}\right)h_{2}’h_{3}+\frac{\partial^{2}f}{\partial z^{2}}h_{3}^{2}$$
hacemos
$$2b_{23}=2\frac{\partial^{2}f}{\partial y\partial z}-\frac{2\frac{\partial^{2}f}{\partial x\partial z}\frac{\partial^{2}f}{\partial y\partial x}}{\frac{\partial^{2}f}{\partial x^{2}}}$$y obtenemos
$$=b_{1}h_{1}’^{2}+b_{2}h_{2}’^{2}+2\frac{\partial^{2}f}{\partial x\partial z}h_{1}’h_{3}+2b_{23}h_{2}’h_{3}+\frac{\partial^{2}f}{\partial z^{2}}h_{3}^{2}$$
que se puede escribir
$$=b_{1}\left(h_{1}’^{2}+2\frac{\frac{\partial^{2}f}{\partial x\partial z}}{b_{1}}h_{1}’h_{3}+\left(\frac{\frac{\partial^{2}f}{\partial x\partial z}h_{3}}{b_{1}}\right)^{2}\right)+b_{2}\left(h_{2}’^{2}+2\frac{b_{23}}{b_{2}}h_{2}’h_{3}+\left(\frac{b_{23}}{b_{2}}h_{3}\right)^{2}\right)+\left(\frac{\partial^{2}f}{\partial z^{2}}-\frac{\left(\frac{\partial^{2}f}{\partial x\partial z}\right)^{2}}{b_{1}}-\frac{b_{23}^{2}}{b_{2}}\right)h_{3}^{2}$$
hacemos
$$b_{3}=\frac{\partial^{2}f}{\partial z^{2}}-\frac{\left(\frac{\partial^{2}f}{\partial x\partial z}\right)^{2}}{b_{1}}-\frac{b_{23}^{2}}{b_{2}}$$
y obtenemos
$$=b_{1}\left(h_{1}’^{2}+2\frac{\frac{\partial^{2}f}{\partial x\partial z}}{b_{1}}h_{1}’h_{3}+\left(\frac{\frac{\partial^{2}f}{\partial x\partial z}h_{3}}{b_{1}}\right)^{2}\right)+b_{2}\left(h_{2}’^{2}+2\frac{b_{23}}{b_{2}}h_{2}’h_{3}+\left(\frac{b_{23}}{b_{2}}h_{3}\right)^{2}\right)+b_{3}h_{3}^{2}$$
$$=b_{1}\left(h_{1}’+\frac{\frac{\partial^{2}f}{\partial x\partial z}}{b_{1}}h_{3}\right)^{2}+b_{2}\left(h_{2}’+\frac{b_{23}}{b_{2}}h_{3}\right)^{2}+b_{3}h_{3}^{2}$$
esta última expresión será positiva si y solo si $b_{1}>0~~b_{2}>0$ y $b_{3}>0$ en clases pasadas vimos los dos primeros, veamos ahora que $$b_{3}=\frac{\partial^{2}f}{\partial z^{2}}-\frac{\left(\frac{\partial^{2}f}{\partial x\partial z}\right)^{2}}{b_{1}}-\frac{b_{23}^{2}}{b_{2}}>0$$
tenemos entonces que
$$\frac{\partial^{2}f}{\partial z^{2}}-\frac{\left(\frac{\partial^{2}f}{\partial x\partial z}\right)^{2}}{b_{1}}-\frac{b_{23}^{2}}{b_{2}}=\frac{\partial^{2}f}{\partial z^{2}}-\frac{\left(\frac{\partial^{2}f}{\partial x\partial z}\right)^{2}}{\frac{\partial^{2}f}{\partial z^{2}}}-\frac{\left(\frac{\partial^{2}f}{\partial y\partial z}-\frac{2\frac{\partial^{2}f}{\partial x\partial z}\frac{\partial^{2}f}{\partial y\partial x}}{\frac{\partial^{2}f}{\partial x^{2}}}\right)^{2}}{\frac{\frac{\partial^{2}f}{\partial y^{2}}\frac{\partial^{2}f}{\partial x^{2}}-\left(\frac{\partial^{2}f}{\partial y\partial x}\right)^{2}}{\frac{\partial^{2}f}{\partial x^{2}}}}$$
$$=\frac{\frac{\partial^{2}f}{\partial z^{2}}\frac{\partial^{2}f}{\partial x^{2}}\left(\frac{\partial^{2}f}{\partial x\partial z}\right)^{2}}{\frac{\partial^{2}f}{\partial x^{2}}}-\frac{\frac{\left(\frac{\partial^{2}f}{\partial y\partial z}\frac{\partial^{2}f}{\partial x^{2}}-\frac{\partial^{2}f}{\partial x\partial z}\frac{\partial^{2}f}{\partial y\partial x}\right)^{2}}{\left(\frac{\partial^{2}f}{\partial x^{2}}\right)^{2}}}{\frac{\frac{\partial^{2}f}{\partial y^{2}}\frac{\partial^{2}f}{\partial x^{2}}-\left(\frac{\partial^{2}f}{\partial y\partial x}\right)^{2}}{\frac{\partial^{2}f}{\partial x^{2}}}}=\frac{\frac{\partial^{2}f}{\partial z^{2}}\frac{\partial^{2}f}{\partial x^{2}}\left(\frac{\partial^{2}f}{\partial x\partial z}\right)^{2}}{\frac{\partial^{2}f}{\partial x^{2}}}-\frac{\left(\frac{\partial^{2}f}{\partial y\partial z}\frac{\partial^{2}f}{\partial x^{2}}-\frac{\partial^{2}f}{\partial x\partial z}\frac{\partial^{2}f}{\partial y\partial x}\right)^{2}}{\left(\frac{\partial^{2}f}{\partial y^{2}}\frac{\partial^{2}f}{\partial x^{2}}-\left(\frac{\partial^{2}f}{\partial y\partial x}\right)^{2}\right)\frac{\partial^{2}f}{\partial x^{2}}}$$
$$=\frac{\left(\frac{\partial^{2}f}{\partial z^{2}}\frac{\partial^{2}f}{\partial x^{2}}-\left(\frac{\partial^{2}f}{\partial x\partial z}\right)^{2}\right)\left(\frac{\partial^{2}f}{\partial y^{2}}\frac{\partial^{2}f}{\partial x^{2}}-\left(\frac{\partial^{2}f}{\partial y\partial x}\right)^{2}\right)-\left(\frac{\partial^{2}f}{\partial y\partial z}\frac{\partial^{2}f}{\partial x^{2}}-\frac{\partial^{2}f}{\partial x\partial z}\frac{\partial^{2}f}{\partial y\partial x}\right)^{2}}{\frac{\partial^{2}f}{\partial x^{2}}\left(\frac{\partial^{2}f}{\partial y^{2}}\frac{\partial^{2}f}{\partial x^{2}}-\left(\frac{\partial^{2}f}{\partial y\partial x}\right)^{2}\right)}$$
$$=\frac{\frac{\partial^{2}f}{\partial z^{2}}\frac{\partial^{2}f}{\partial x^{2}}\frac{\partial^{2}f}{\partial y^{2}}\frac{\partial^{2}f}{\partial x^{2}}-\frac{\partial^{2}f}{\partial z^{2}}\frac{\partial^{2}f}{\partial x^{2}}\left(\frac{\partial^{2}f}{\partial y\partial x}\right)^{2}-\frac{\partial^{2}f}{\partial y^{2}}\frac{\partial^{2}f}{\partial x^{2}}\left(\frac{\partial^{2}f}{\partial x\partial z}\right)^{2}+\left(\frac{\partial^{2}f}{\partial x\partial z}\right)^{2}\left(\frac{\partial^{2}f}{\partial y\partial x}\right)^{2}-\left(\frac{\partial^{2}f}{\partial y\partial z}\right)^{2}\left(\frac{\partial^{2}f}{\partial x^{2}}\right)^{2}-}{\frac{\partial^{2}f}{\partial x^{2}}\left(\frac{\partial^{2}f}{\partial y^{2}}\frac{\partial^{2}f}{\partial x^{2}}-\left(\frac{\partial^{2}f}{\partial y\partial x}\right)^{2}\right)}$$
$$\frac{2\left(\frac{\partial^{2}f}{\partial x^{2}}\frac{\partial^{2}f}{\partial y\partial z}\frac{\partial^{2}f}{\partial x\partial z}\frac{\partial^{2}f}{\partial y\partial x}\right)-\left(\frac{\partial^{2}f}{\partial x\partial z}\right)^{2}\left(\frac{\partial^{2}f}{\partial y\partial x}\right)^{2}}{\frac{\partial^{2}f}{\partial x^{2}}\left(\frac{\partial^{2}f}{\partial y^{2}}\frac{\partial^{2}f}{\partial x^{2}}-\left(\frac{\partial^{2}f}{\partial y\partial x}\right)^{2}\right)}$$
$$=\frac{\frac{\partial^{2}f}{\partial z^{2}}\frac{\partial^{2}f}{\partial y^{2}}\frac{\partial^{2}f}{\partial x^{2}}-\frac{\partial^{2}f}{\partial z^{2}}\left(\frac{\partial^{2}f}{\partial y\partial x}\right)^{2}-\frac{\partial^{2}f}{\partial y^{2}}\left(\frac{\partial^{2}f}{\partial x\partial z}\right)^{2}-\left(\frac{\partial^{2}f}{\partial y\partial z}\right)^{2}\frac{\partial^{2}f}{\partial x^{2}}+2\frac{\partial^{2}f}{\partial y\partial z}\frac{\partial^{2}f}{\partial x\partial z}\frac{\partial^{2}f}{\partial y\partial x}}{\frac{\partial^{2}f}{\partial y^{2}}\frac{\partial^{2}f}{\partial x^{2}}-\left(\frac{\partial^{2}f}{\partial y\partial x}\right)^{2}}$$
$$=\frac{\left|\begin{matrix}\frac{\partial^{2}f}{\partial x^{2}}&\frac{\partial^{2}f}{\partial y\partial x}&\frac{\partial^{2}f}{\partial z\partial x}\\\frac{\partial^{2}f}{\partial x\partial y}&\frac{\partial^{2}f}{\partial y^{2}}&\frac{\partial^{2}f}{\partial z\partial y}\\\frac{\partial^{2}f}{\partial x\partial z}&\frac{\partial^{2}f}{\partial y\partial z}&\frac{\partial^{2}f}{\partial z^{2}}\end{matrix}\right|}{\frac{\partial^{2}f}{\partial y^{2}}\frac{\partial^{2}f}{\partial x^{2}}-\left(\frac{\partial^{2}f}{\partial y\partial x}\right)^{2}}$$
por lo tanto
$$b_{3}>0~\Leftrightarrow~\left|\begin{matrix}\frac{\partial^{2}f}{\partial x^{2}}&\frac{\partial^{2}f}{\partial y\partial x}&\frac{\partial^{2}f}{\partial z\partial x}\\\frac{\partial^{2}f}{\partial x\partial y}&\frac{\partial^{2}f}{\partial y^{2}}&\frac{\partial^{2}f}{\partial z\partial y}\\\frac{\partial^{2}f}{\partial x\partial z}&\frac{\partial^{2}f}{\partial y\partial z}&\frac{\partial^{2}f}{\partial z^{2}}\end{matrix}\right|>0$$
Definición 1. La forma $Q(x)=xAx^{t}$, que tiene asociada la matriz A (respecto a la base canónica de $\mathbb{R}^{n}$) se dice:
$\textcolor{Red}{\textbf{Definida positiva}}$, si $Q(x)>0~\forall x \in~\mathbb{R}^{n}$
La forma $Q(x)=xAx^{t}$, que tiene asociada la matriz A (respecto a la base canónica de $\mathbb{R}^{n}$) se dice:
$\textcolor{Red}{\textbf{Definida negativa}}$, si $Q(x)<0~ \forall x \in~\mathbb{R}^{n}$
Definición 2. Si la forma $Q(x)=xAx^{t}$ es definida positiva, entonces f tiene un mínimo local en en x.
Si la forma $Q(x)=xAx^{t}$ es definida negativa, entonces f tiene un máximo local en en x.
Hay criterios similares para una matriz simetrica $A$ de $n\times n$ y consideramos las $n$ submatrices cuadradas a lo largo de la diagonal, $A$ es definida positiva si y solo si los determinantes de estas submatrices diagonales son todos mayores que cero. Para $A$ definida negativa los signos deberan alternarse $<0$ y $>0$. En casi de que los determinantes de las submatrices diagonales sean todos diferentes de cero pero que la matrix no sea definida positiva o negativa, el punto crítico es tipo silla. Y por lo tanto el punto no es máximo ni mínimo. Asi tenemos el siguiente resultado.
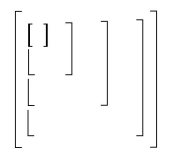
Definición 3. Dada una matriz cuadrada $A=a_{ij}j=1,…,ni=1,…,n$ se consideran las submatrices angulares $A_{k}k=1,…,n$ definidas como $$A_{1} (a_{11})~A_{2}=\left(\begin{matrix}a_{11}&a_{12}\\a_{21}&a_{22}\end{matrix}\right)~~A_{3}=\left(\begin{matrix}a_{11}&a_{12}&a_{13}\\a_{21}&a_{22}&a_{23}\\a_{31}&a_{32}&a_{33}\end{matrix}\right),\cdots,A_{n}=A$$
se define $\det A_{k}=\triangle_{k}$
Definición 4. Se tiene entonces que que la forma $Q(x)=xAX^{t}$ es definida positiva si y solo si todos los dterminantes $\triangle_{k}~~k=1,…,n$ son números positivos.
Definición 5. La forma $Q(x)=xAX^{t}$ es definida negativa si y solo si los dterminantes $\triangle_{k}k=1,…,n$ tienen signos alternados comenzando por $\triangle_{1}<0,\triangle_{2}>0,…$ respectivamente.
Ejemplo. Consideremos la función $f:\mathbb{R}^3\rightarrow
\mathbb{R}$ $f(x,y,z)=\sin x +\sin y + \sin z -\sin(x+y+z)$, el punto $P=\left(\frac{\pi}{2},\frac{\pi}{2},\frac{\pi}{2}\right)$ es
un punto crítico de $f$ y en ese punto la matriz hessiana de
$f$ es $$H(p)=\left[
\begin{array}{ccc}
-2 & -1 & -1 \\
-1 & -2 & -1 \\
-1 & -1 & -2 \
\end{array}
\right]
$$
los determinantes de las submatrices angulares son
$$\Delta_1=det(-2)\qquad \quad $$ $$\Delta_2=det \left[
\begin{array}{cc}
-2 & -1 \\
-1 & -2 \
\end{array}
\right]$$
$$\Delta_3=det H(p)=-4$$ puesto que son signos alternantes con $\Delta t< 0$ concluimos que la funcion $f$ tiene en $\left(\frac{\pi}{2},\frac{\pi}{2},\frac{\pi}{2}\right)$ un máximo local. Este máximo local vale $f\left(\frac{\pi}{2},\frac{\pi}{2},\frac{\pi}{2}\right)=4$