A lo largo de los teoremas vistos en geometría moderna se han demostrado y visto propiedades, pero gracias a la inversión se pueden deducir y demostrar nuevos teoremas de los ya vistos. A esto se le denomina Inversión de un Teorema.
Inversión de un Teorema y circunferencia de antisimilitud
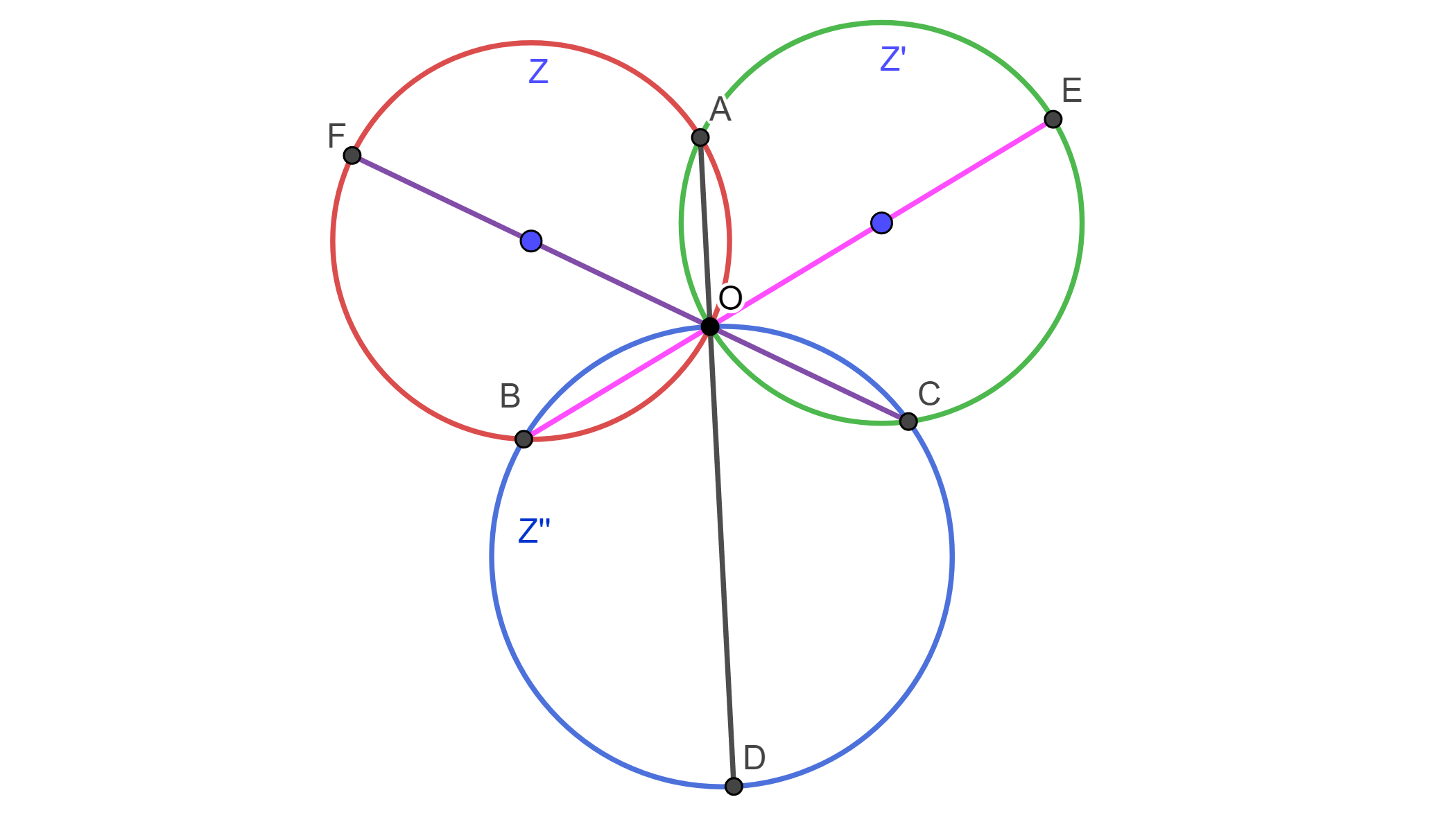
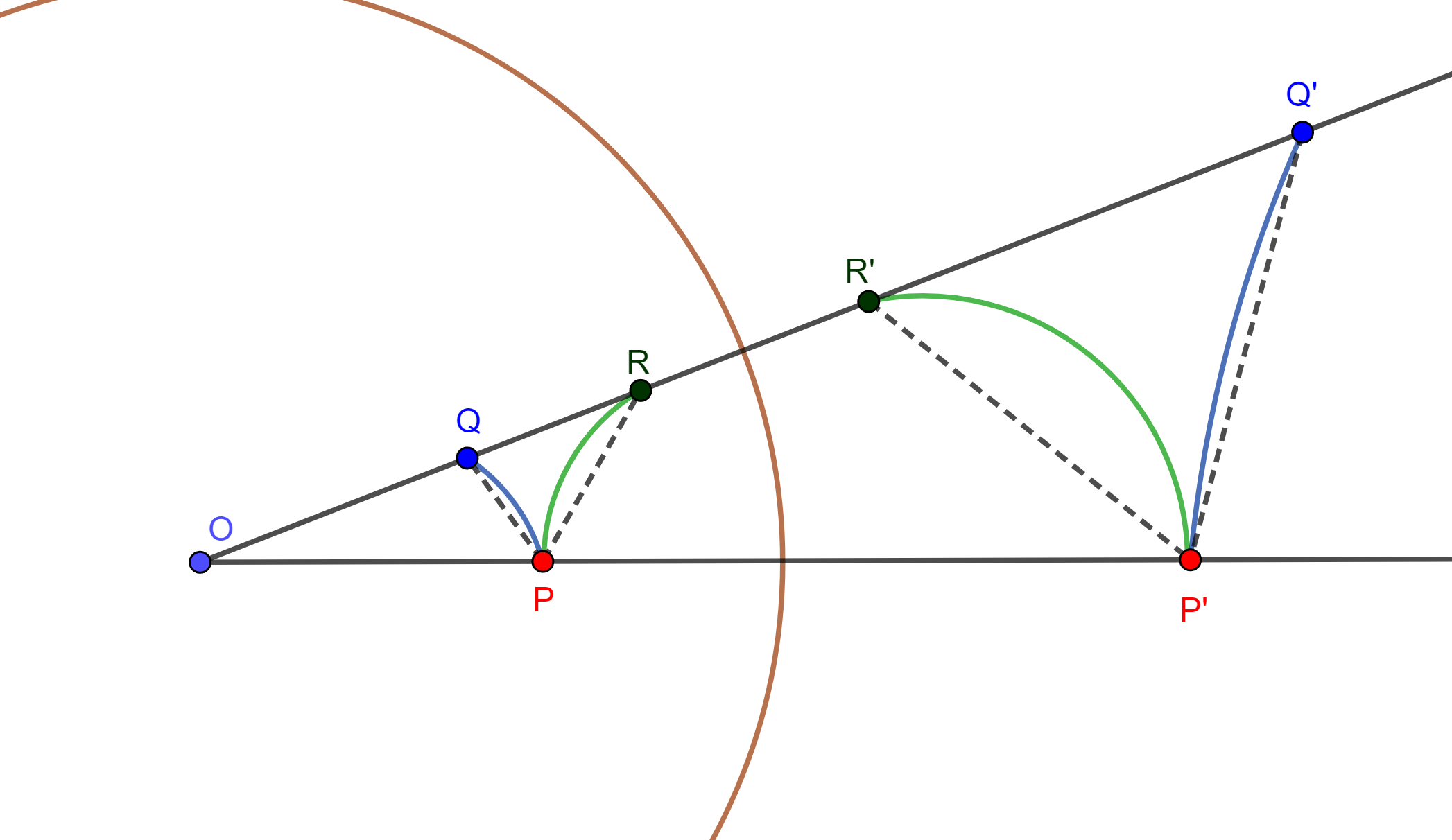
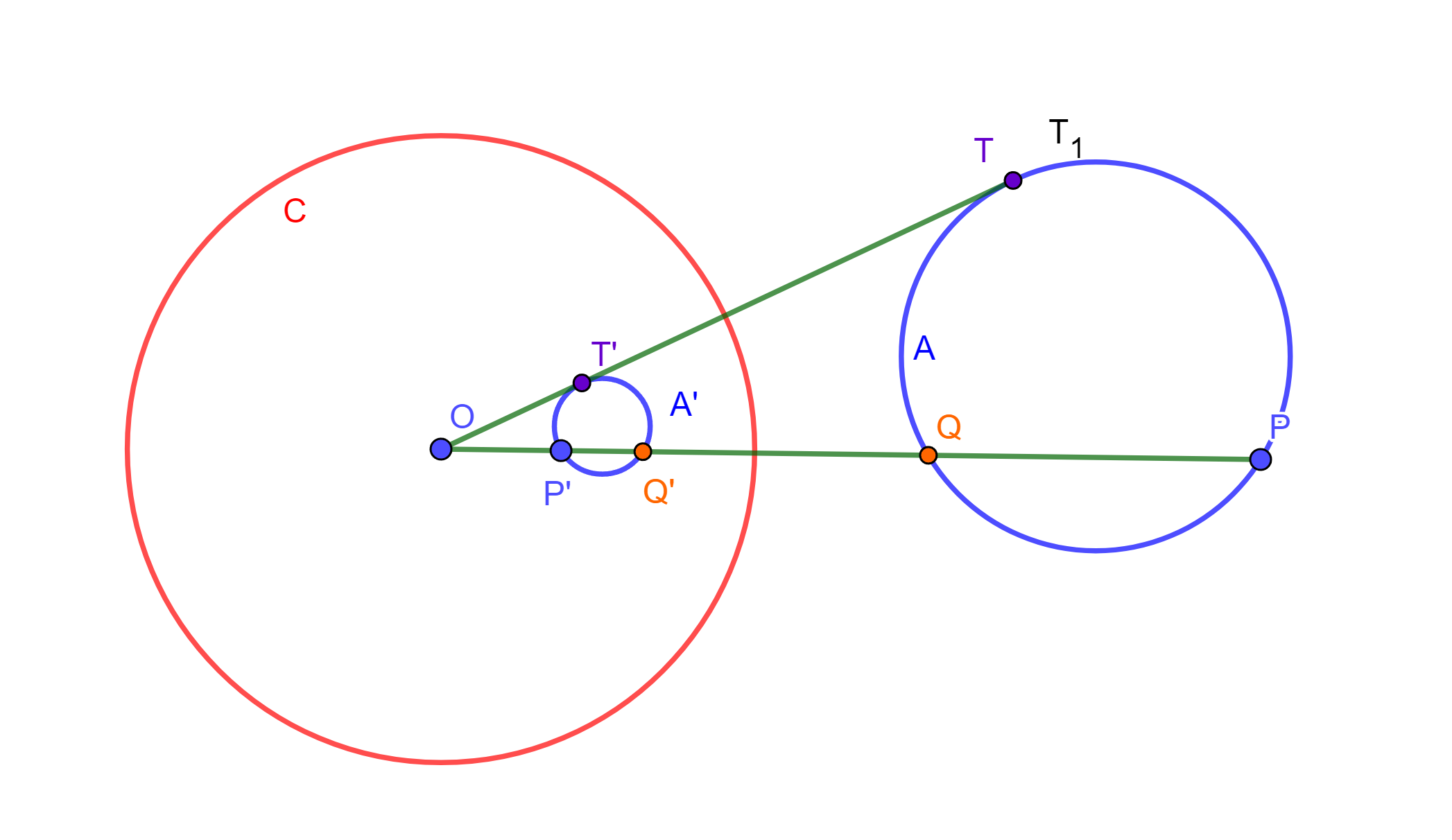
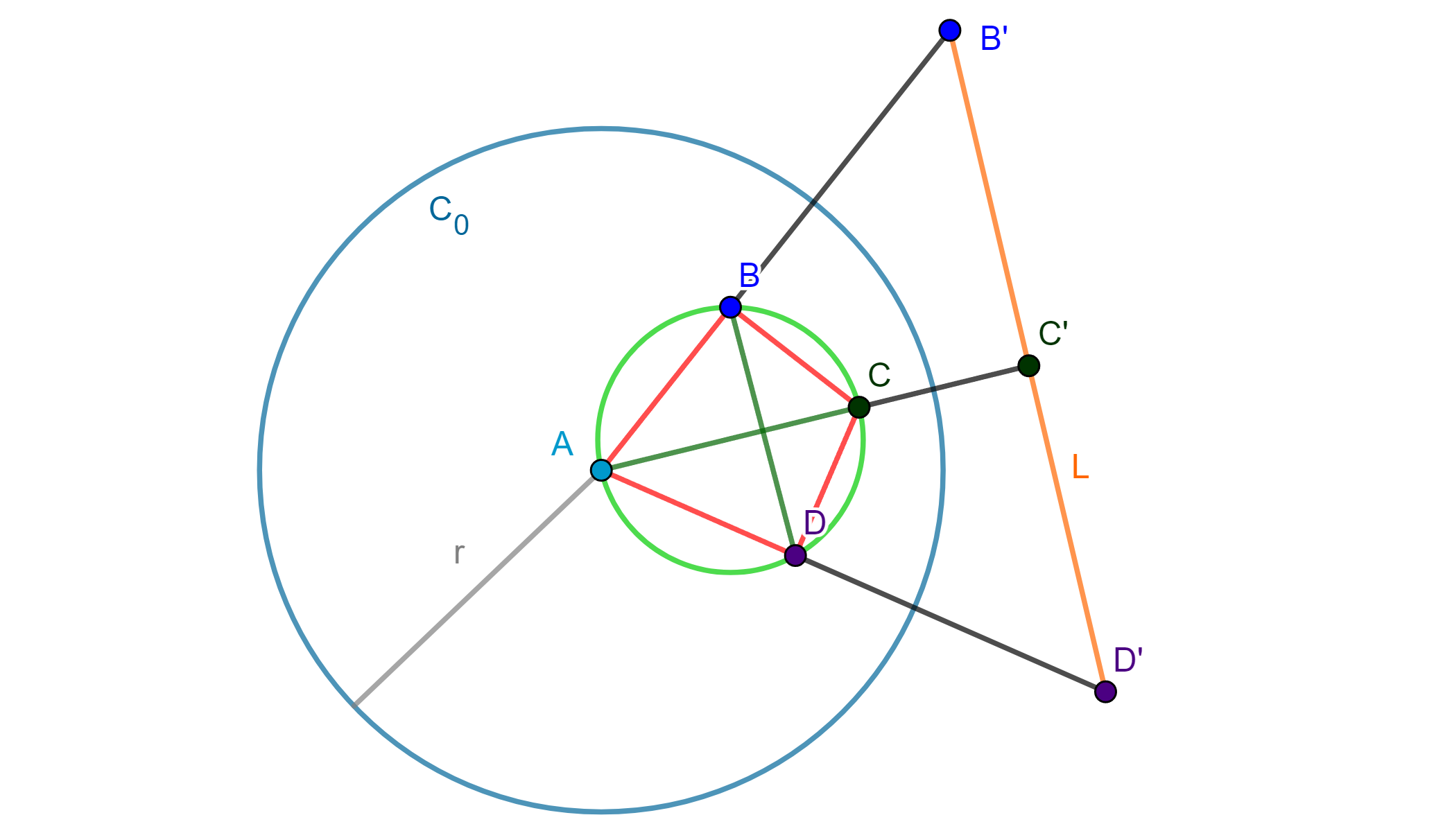
Ejemplo. Dado un teorema referente a las alturas de un triángulo, se puede demostrar usando inversión y referente a circunferencias. Sean $Z$ y $Z’$ dos circunferencias que se intersecan en $A$ y $O$, de $O$ se tiene los diámetros $OE$ de $Z’$ y $OF$ de $Z$ donde intersecan a $Z$ en $B$ y $Z’$ en $C$; Por lo cual el eje radical $AO$ pasa por el centro de la circunferencia de los puntos $O$, $B$ y $C$ la cual llamaremos $Z’$$’$.
Usando el Teorema. El inverso de una circunferencia que pasa por el centro de inversión es una recta que no pasa por el centro de inversión: Por lo cual, usando $O$ como centro de inversión, se tiene que los inversos de $A$, $B$ y $C$ son $A’$, $B’$ y $C’$ respectivamente. Las circunferencias $Z$, $Z’$ y $Z’$$’$ se invierten en $A’B’$, $A’C’$ y $B’C’$ correspondientemente. Y las líneas $AO$, $FO$ y $EO$ se invierten en sí mismas por Teorema de inversión de línea que pasa por el centro de inversión. Se tiene la inversión:
Ahora como un diámetro interseca su circunferencia ortogonalmente, entonces $B’O$ y $C’O$ por la propiedad de conservación de ángulos en la inversión son las alturas del triángulo $A’B’C’$, entonces $A’O \perp B’C’$. Por lo tanto, $AO \perp $ $Z’$$’$ entonces $AO$ pasa por el centro de $Z’$$’.$
$\triangle$
Circunferencia de Antisimilitud
Definición. La circunferencia de antisimilitud es una circunferencia respecto a la cual dos circunferencias son mutuamente inversas.
Recordemos dos propiedades:
El centro de inversión de dos circunferencias inversas es el centro de similitud.
Dado un par de puntos inversos son antihomologos con respecto al centro de similitud.
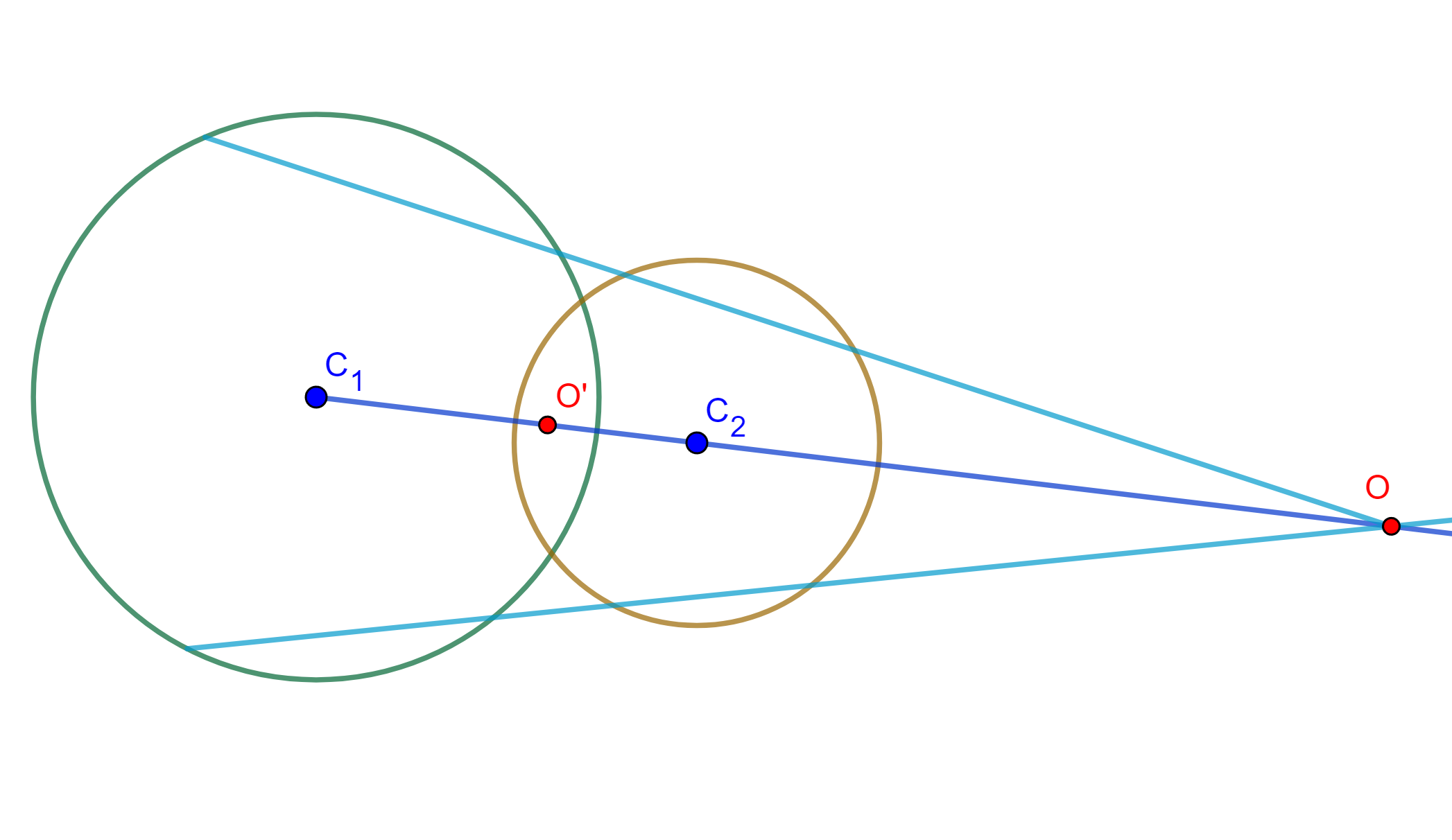
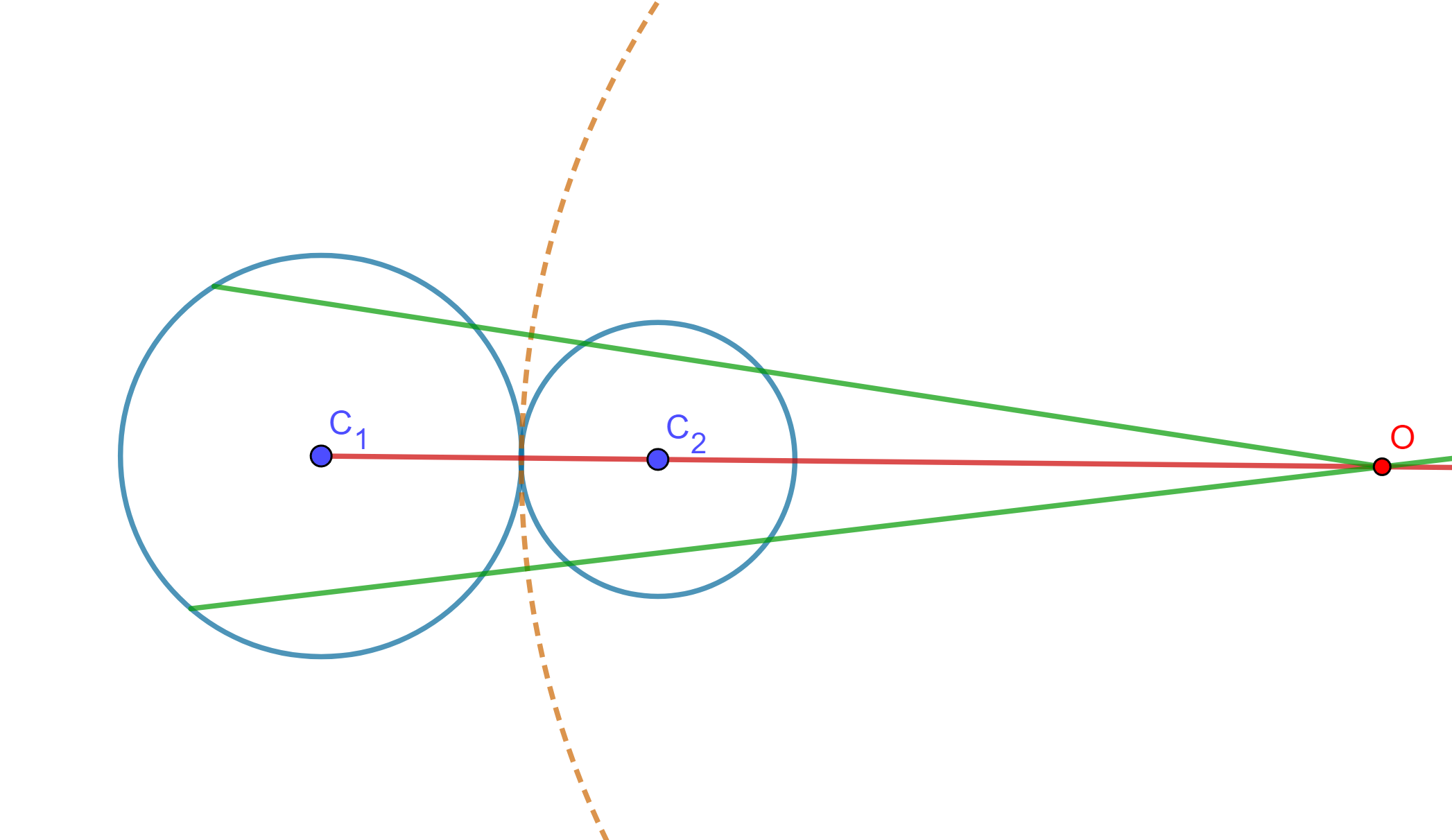
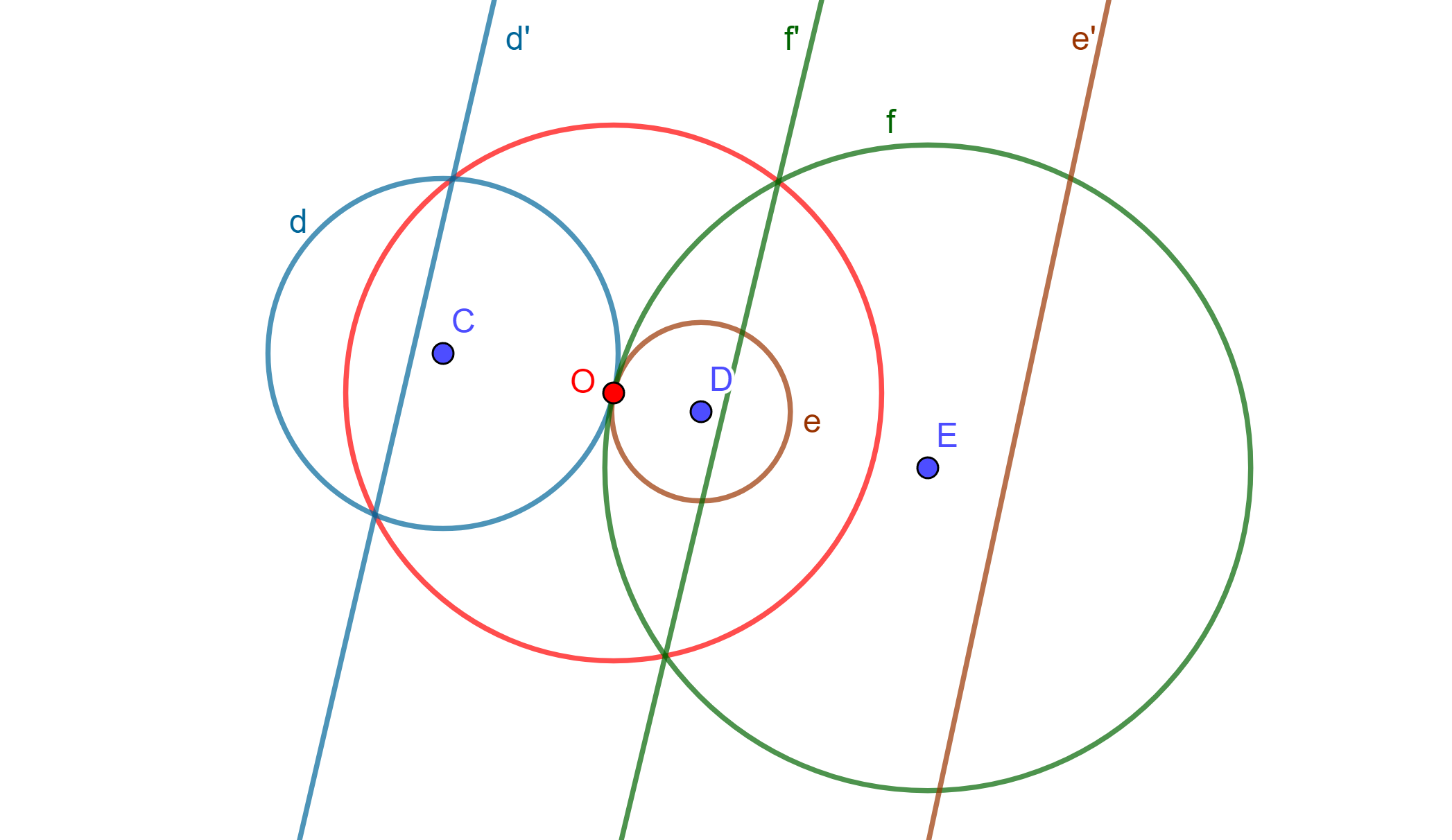
Teorema. Sean dos circunferencias de las cuales existen tres posibles casos ($O$ y $O’$ centros de similitud).
Caso 1. Si se intersecan, entonces tienen dos circunferencias de antisimilitud tal que sus centros son los centros de similitud de las circunferencias dadas y que pasan por sus puntos de intersección.
Caso 2. Si no se intersecan (o son tangentes), entonces solo tienen una circunferencia de antisimilitud cuyo centro está en el centro de similitud exterior si las circunferencias son mutuamente excluyentes.
Caso 3. Si no se intersecan, entonces solo tiene una circunferencia de antisimilitud cuyo centro está en el centro de similitud interior si las circunferencias son internas una a la otra.
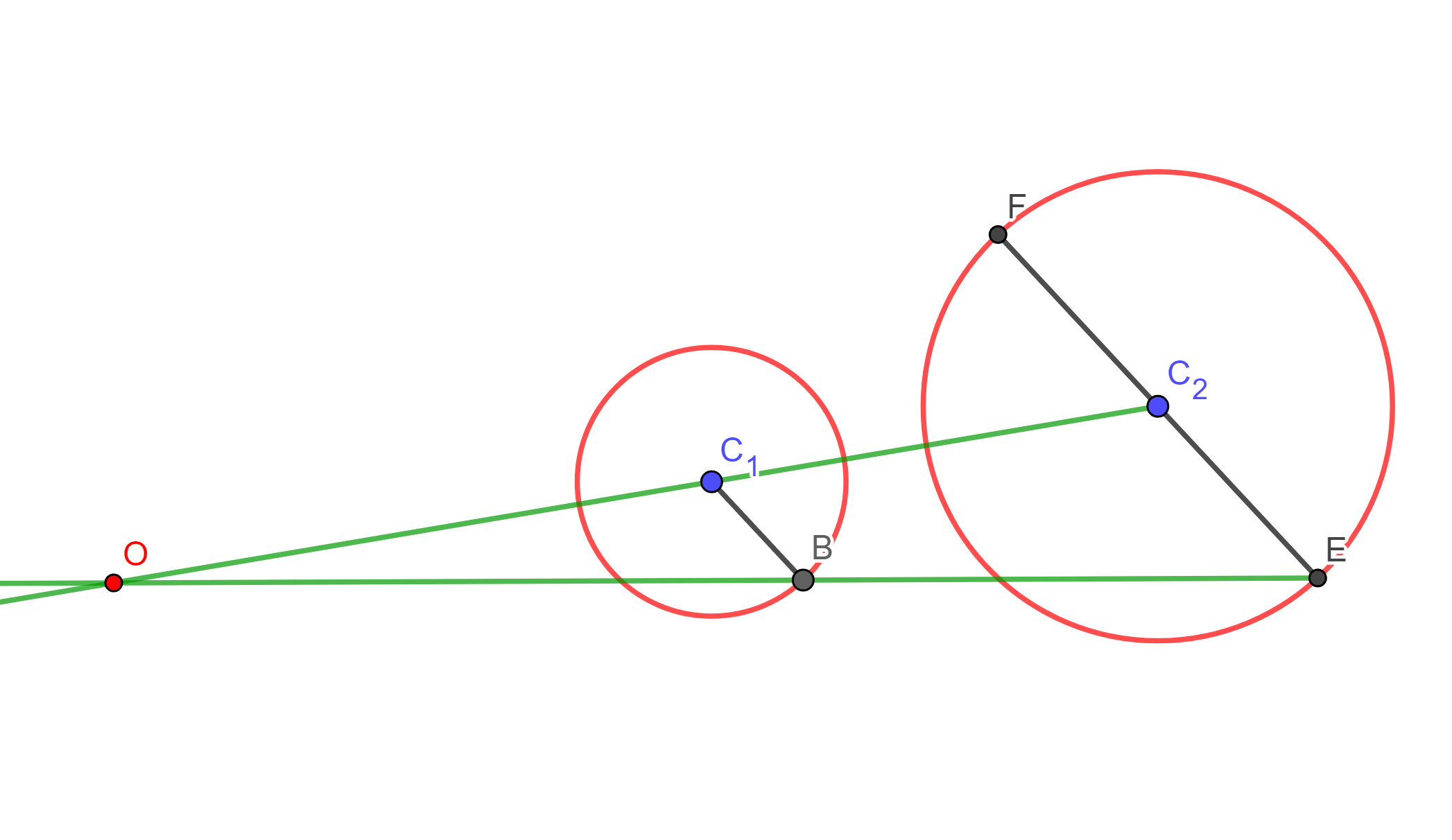
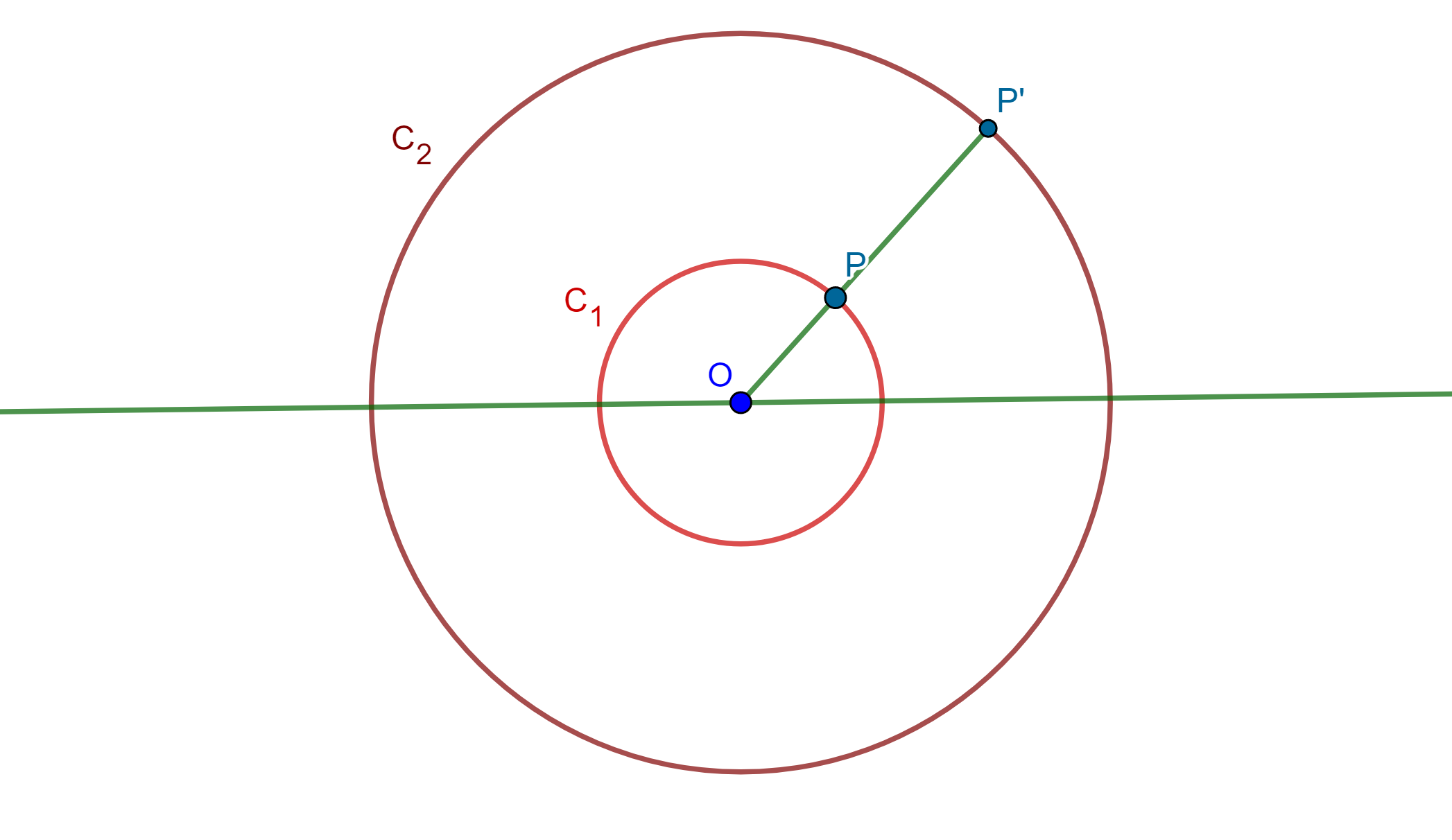
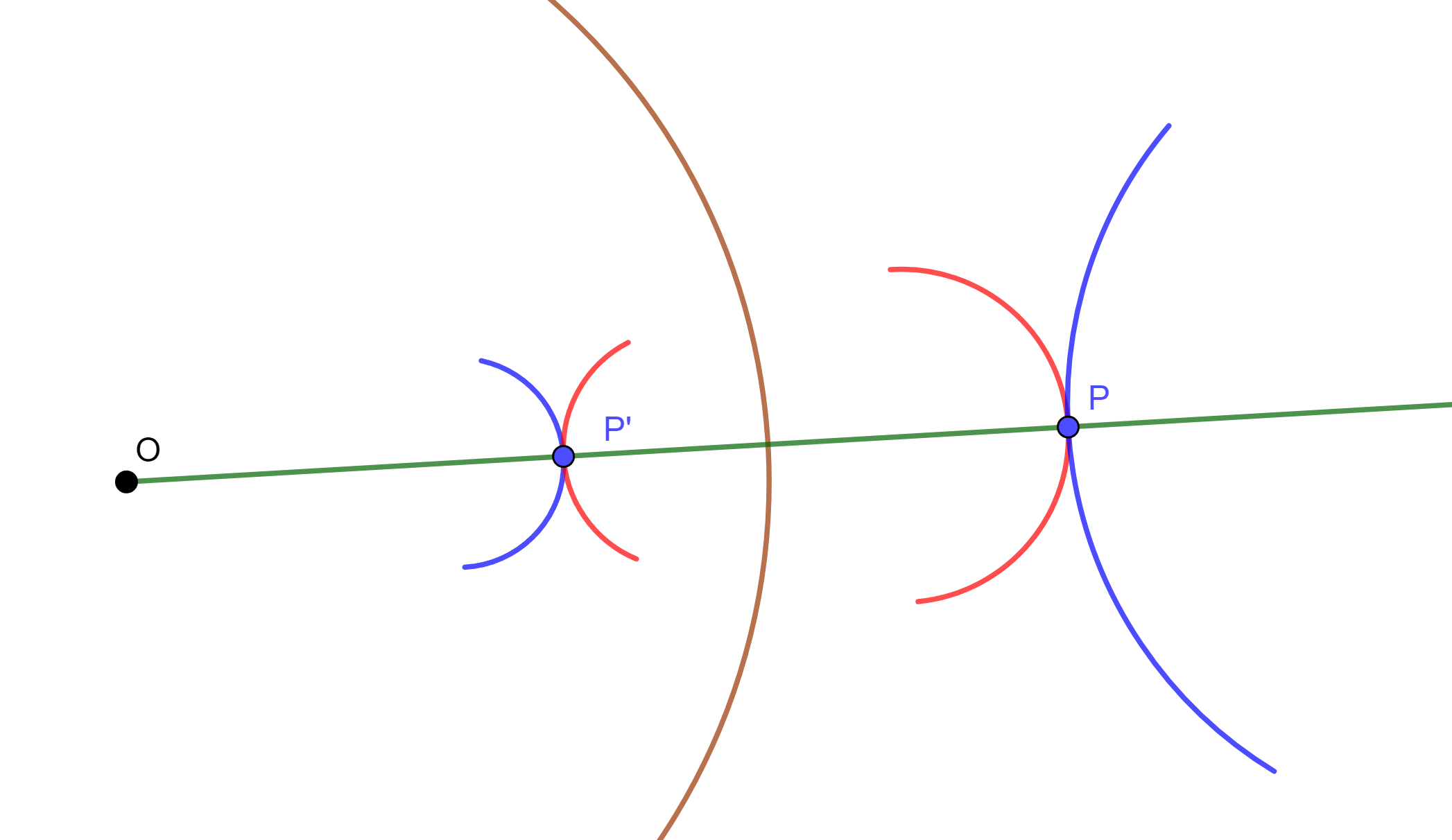
Lema. Una circunferencia $C_1$ y dos puntos inversos respecto a ella los llamaremos $S$ y $S’$ los cuales se invierten en una recta $C’_1$ y en dos puntos simétricos $P$ y $Q$ respecto a $C_1$, cuando el centro de inversión es un punto $A$ en $C_1$.
Teorema. Dos circunferencias que no se intersecan se pueden invertir en dos circunferencias iguales.
Demostración. Sean $C_1$ y $C’_1$ circunferencias y $C$ la circunferencia de antisimilitud de dichas circunferencias. Sea $A \in C$ y sea $C_2$ con centro $A$. Las inversas de $C_1$ y $C’_1$ respecto a $C_2$ son dos circunferencias simétricas respecto al inverso de $C$ (Por el Lema anterior).
$\square$
Más adelante…
Es hora de ver algunas construcciones respecto a la inversión.
Ya analizadas en el tema anterior la inversión de rectas y circunferencias, es momento de ver cómo la inversión conserva ángulos. En esta entrada estudiaremos la propiedad de conservación de ángulos, veremos cómo se relaciona con distancias, y finalmente presentaremos dos aplicaciones importantes: el teorema de Ptolomeo y el teorema de Feuerbach.
Conservación de ángulos
El siguiente resultado es fundamental para entender la inversión como transformación geométrica.
Teorema. La inversión es una transformación que preserva ángulos e invierte orientación.
Demostración. Presentaremos dos demostraciones distintas de este resultado.
Primera demostración:
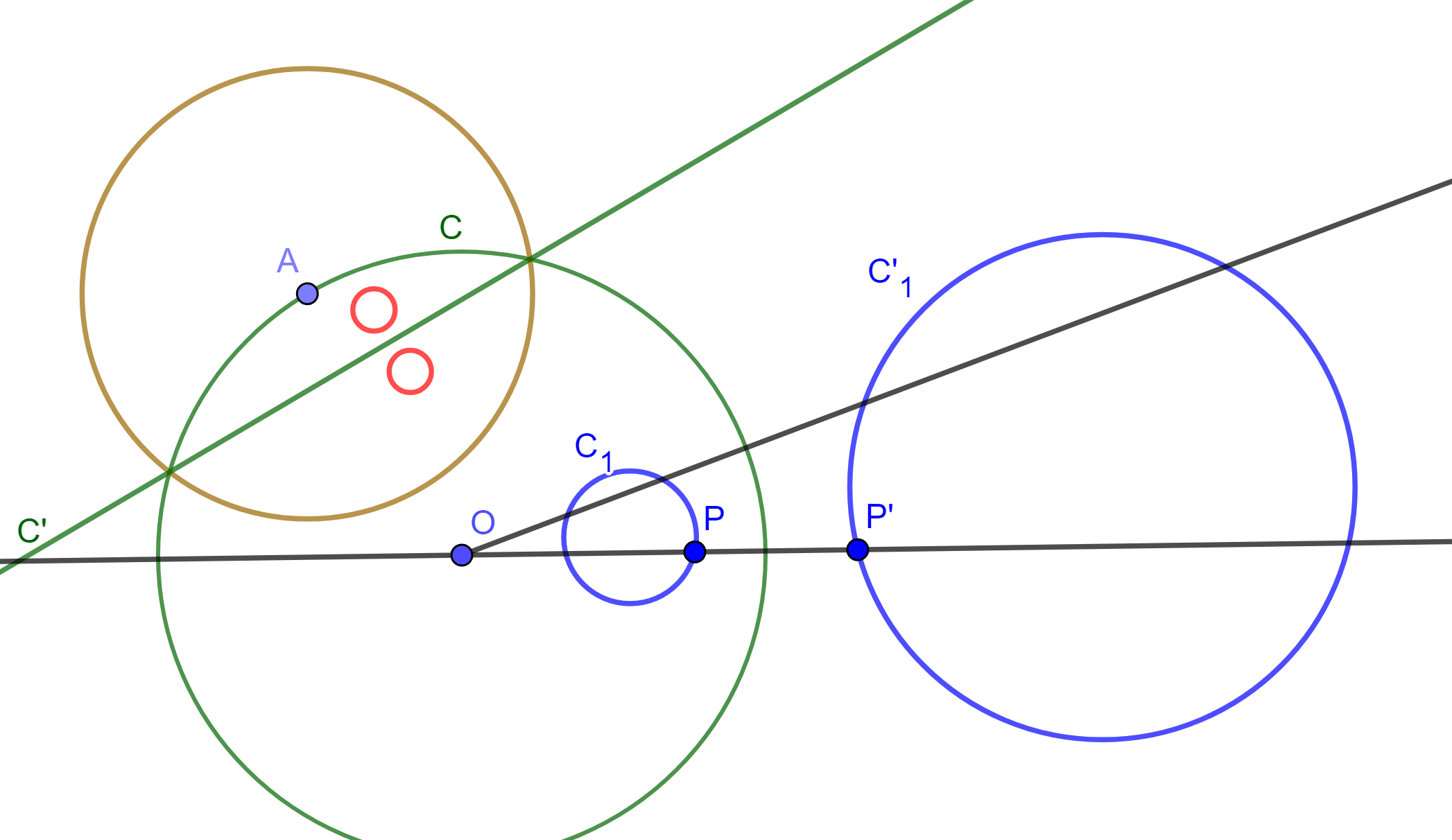
Sea $\mathcal{C}(O,r)$ la circunferencia de inversión. Sean $A$ y $B$ dos circunferencias que se intersecan, y sea $P$ uno de los puntos de intersección. Sea $P’$ el inverso de $P$.
Construyamos la circunferencia $C$ tangente a $A$ en $P$ y que pase por $P’$. De igual forma, construyamos $D$ tangente a $B$ en $P$ y que pase por $P’$. Sea $L_1$ la recta tangente a $A$ en $P$, la cual también es tangente a $C$ en $P$. Sea $L_2$ la recta tangente a $B$ en $P$, la cual es tangente a $D$ en $P$. Entonces el ángulo entre $A$ y $B$ es el mismo que el ángulo entre $C$ y $D$.
Como $C$ y $D$ pasan por puntos inversos $P$ y $P’$, entonces son ortogonales a $\mathcal{C}$, la circunferencia de inversión. Sean $A’$ y $B’$ las circunferencias inversas de $A$ y $B$ respectivamente. Dado que $P$ y $P’$ son inversos, se tiene que el ángulo entre $A’$ y $B’$ es el mismo que el ángulo entre $C$ y $D$, y por lo tanto es el mismo que el ángulo entre $A$ y $B$.
Por lo tanto, la inversión preserva ángulos e invierte orientación.
$\square$
Segunda demostración:
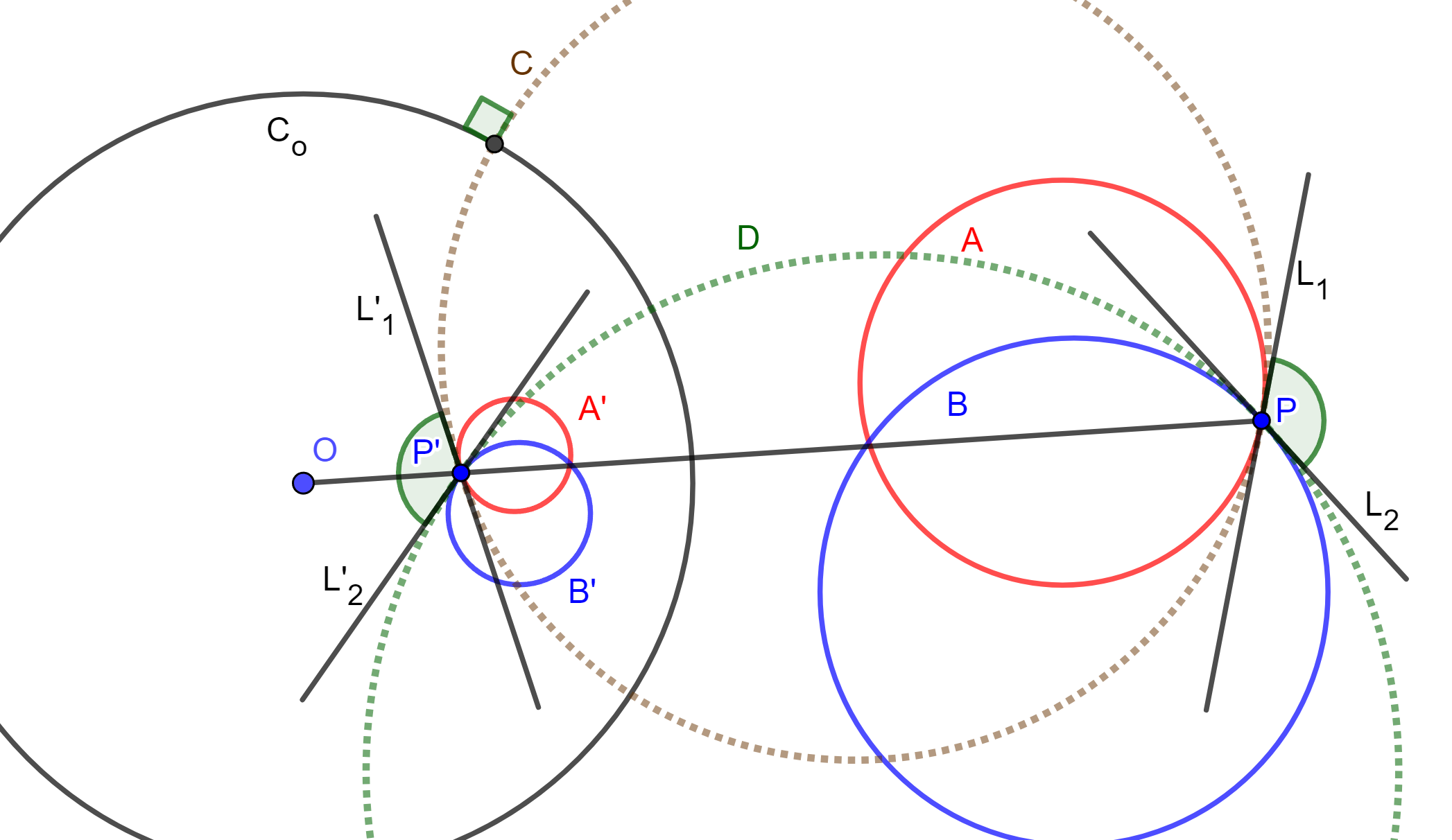
Sean dos curvas que se intersecan en $P$, con $P\neq O$. Tracemos una línea por $OP$ y otra por $O$ que corte a las curvas en $Q$ y $R$, con $O$, $Q$ y $R$ colineales.
Los puntos $P$, $Q$ y $R$ tienen inversos $P’$, $Q’$ y $R’$ respectivamente. Las inversas de las curvas que pasan por $P$, $Q$ y $P$, $R$ tendrán que intersecarse en $P’$, $Q’$ y $P’$, $R’$ respectivamente. Por definición de inversión: $$OP\cdot OP’=OQ\cdot OQ’=OR\cdot OR’=r^2.$$
Por lo tanto, $\triangle OPQ \sim \triangle OQ’P’$ y también $\triangle OPR \sim \triangle OR’P’$. Si trazamos las secantes que corten a las curvas en $P$ y que pasen por $Q$ y $R$, y análogamente en $P’$ que pasen por $Q’$ y $R’$, entonces $$\angle OPQ = \angle P’Q’O \quad \text{y} \quad \angle OPR = \angle P’R’O.$$
Por lo cual, $\angle QPR= \angle R’P’Q’$ y $\angle RPQ= – \angle R’P’Q’$. Ahora, si tomamos el límite cuando $Q$ y $R$ tienden a $P$, entonces $Q’$ y $R’$ tienden a $P’$. Por lo tanto, $\angle RPQ$ y $\angle R’P’Q’$ tienden a ser los ángulos límite de la intersección de las curvas.
Por lo tanto, los ángulos bajo inversión se preservan en magnitud pero son opuestos en signo.
$\square$
Observación. Es por esto que se dice que la inversión es una transformación isogonal.
Consecuencias de la conservación de ángulos
El teorema anterior tiene varias consecuencias importantes que enunciaremos a continuación.
Corolario. Si dos curvas son tangentes una a la otra en $P$, sus inversas son tangentes una a la otra en $P’$.
Corolario. Objetos ortogonales se invierten en objetos ortogonales.
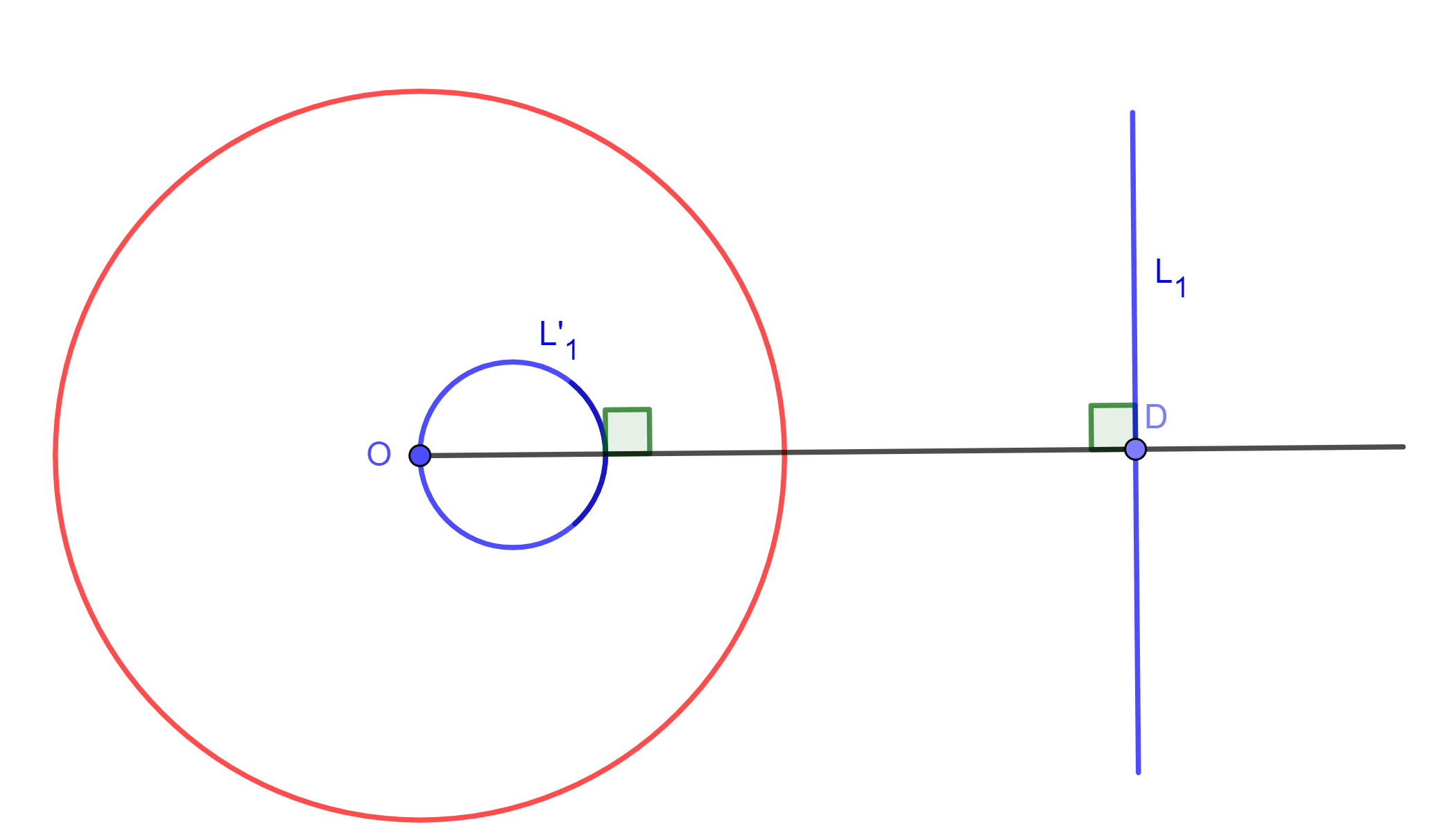
Corolario. Rectas paralelas se invierten en circunferencias tangentes en el centro de inversión.
Teorema. Sea $A$ una circunferencia y $A’$ su inversa. Entonces son homotéticas desde el centro de inversión.
Inversión y distancias
Aunque la inversión no preserva distancias, podemos relacionar las distancias antes y después de una inversión mediante las siguientes fórmulas.
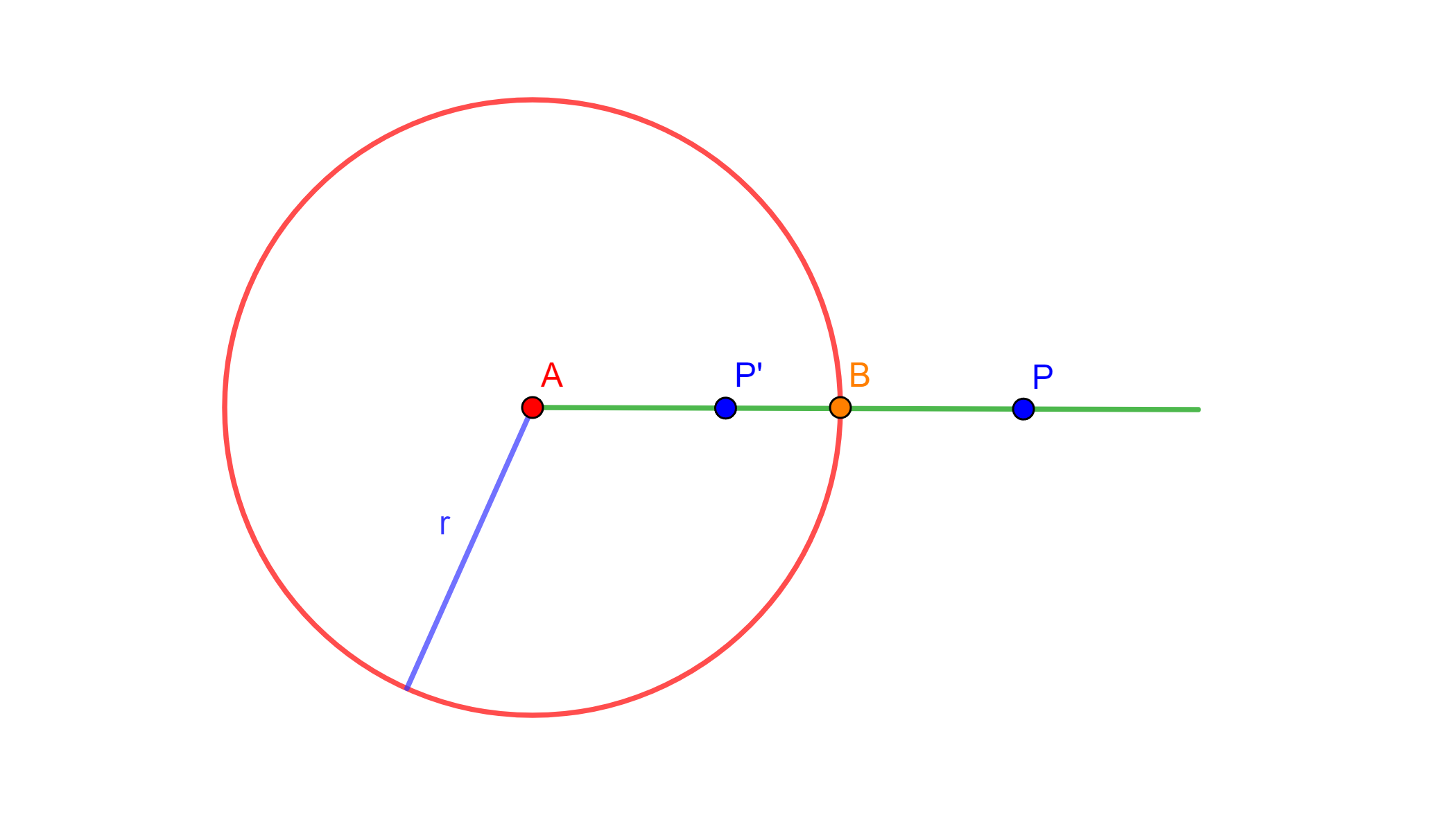
Teorema. Sean $P$ y $P’$ puntos inversos con respecto a una circunferencia de inversión de radio $r$. Sea $B$ un punto colineal a $P$ y $P’$ que intersecta a la circunferencia de inversión. Entonces: $$BP’ = \frac{BP}{1+BP/r} \quad \text{y} \quad BP=\frac{BP’}{1-BP’/r}.$$
Demostración. Tenemos que $BP’=r-OP’$. Por definición de inversión, $OP\cdot OP’=r^2$, de modo que $OP’= \frac{r^2}{OP}$. Entonces:
El siguiente resultado es más general y no requiere que los puntos sean colineales con el centro.
Teorema. Sea $\mathcal{C}(O,r)$ una circunferencia de inversión. Sean $P$ y $Q$ dos puntos con inversos $P’$ y $Q’$ respectivamente. Entonces: $$P’Q’= \frac{r^2 \cdot PQ}{OP \cdot OQ}.$$
Demostración. Por definición de inversión: $$OP \cdot OP’=r^2 \quad \text{y} \quad OQ \cdot OQ’=r^2.$$
Veamos una primera aplicación importante de la teoría de inversión.
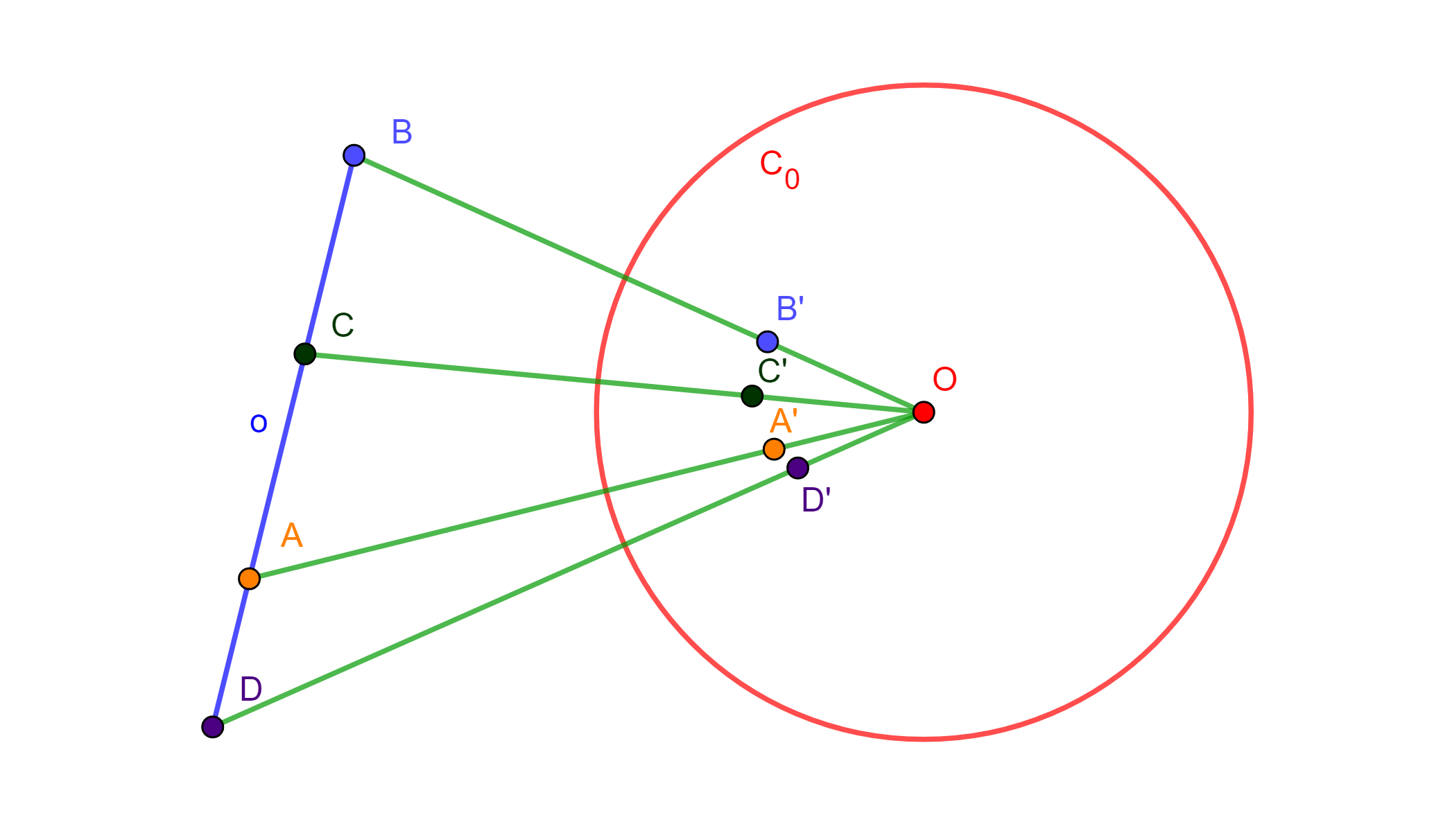
Teorema de Ptolomeo. Sea $ABCD$ un cuadrilátero cíclico convexo. Entonces: $$AC \cdot BD = BC \cdot AD + CD \cdot AB.$$
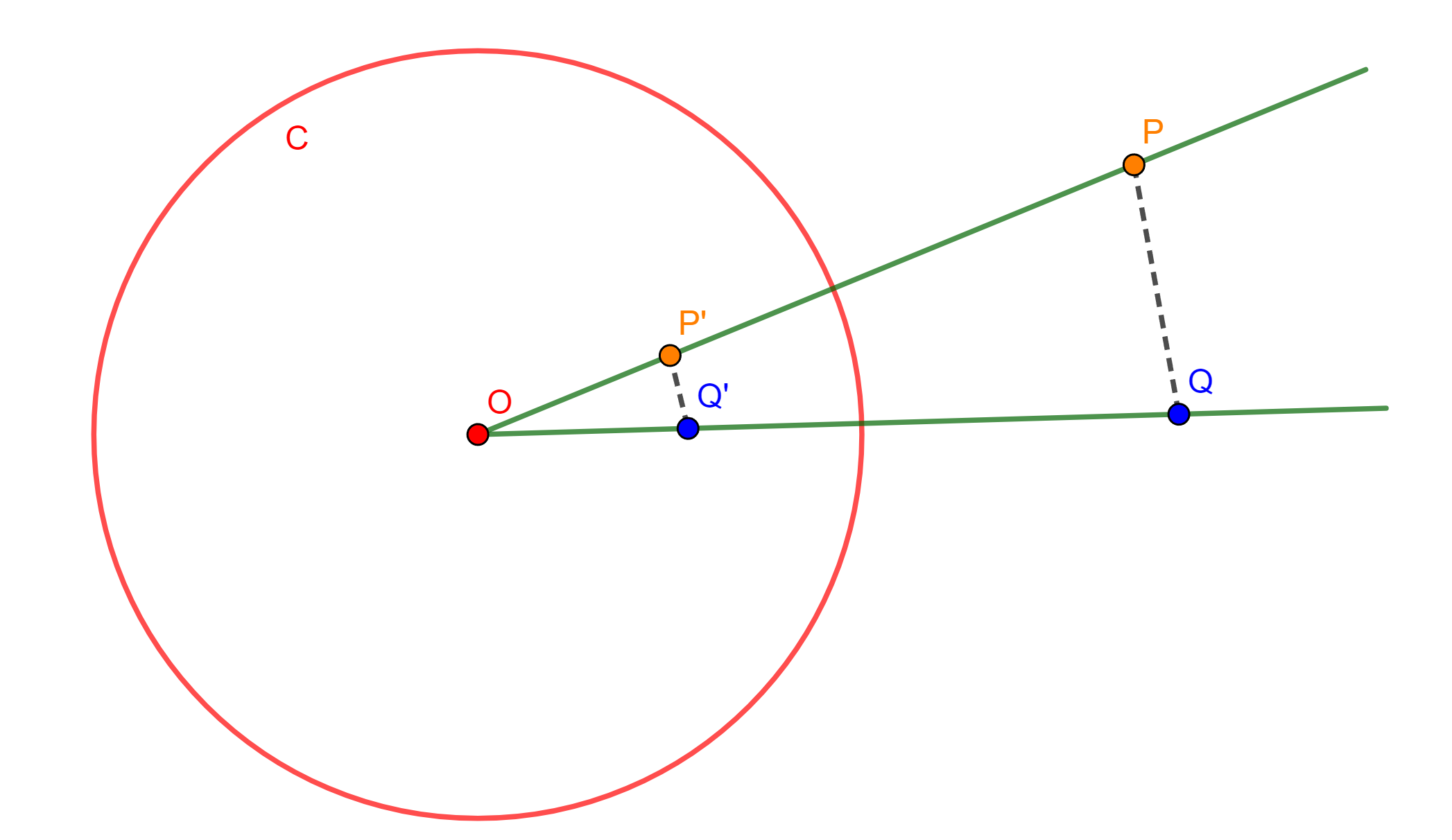
Demostración. Sea $\mathcal{C}(A,r)$ una circunferencia de inversión con centro en $A$. Consideremos la circunferencia circunscrita del cuadrilátero cíclico. La inversión transforma esta circunferencia (que pasa por $A$) en una línea recta $L$. Sean $B’$, $C’$ y $D’$ los inversos de $B$, $C$ y $D$ respectivamente. Estos puntos forman la línea $L$, como se muestra en la siguiente figura:
En la línea $L$ se tiene que $B’D’=B’C’+C’D’$. Por el teorema anterior sobre distancias bajo inversión:
Cancelando $r^2$ y multiplicando por $AB \cdot AC \cdot AD$:
$$BD \cdot AC = BC \cdot AD + CD \cdot AB.$$
Por lo tanto, $AC \cdot BD = BC \cdot AD + CD \cdot AB$.
$\square$
Aplicación: Teorema de Feuerbach
Veamos otra aplicación notable de la inversión: el teorema de Feuerbach, que relaciona la circunferencia de los nueve puntos con los círculos asociados a un triángulo.
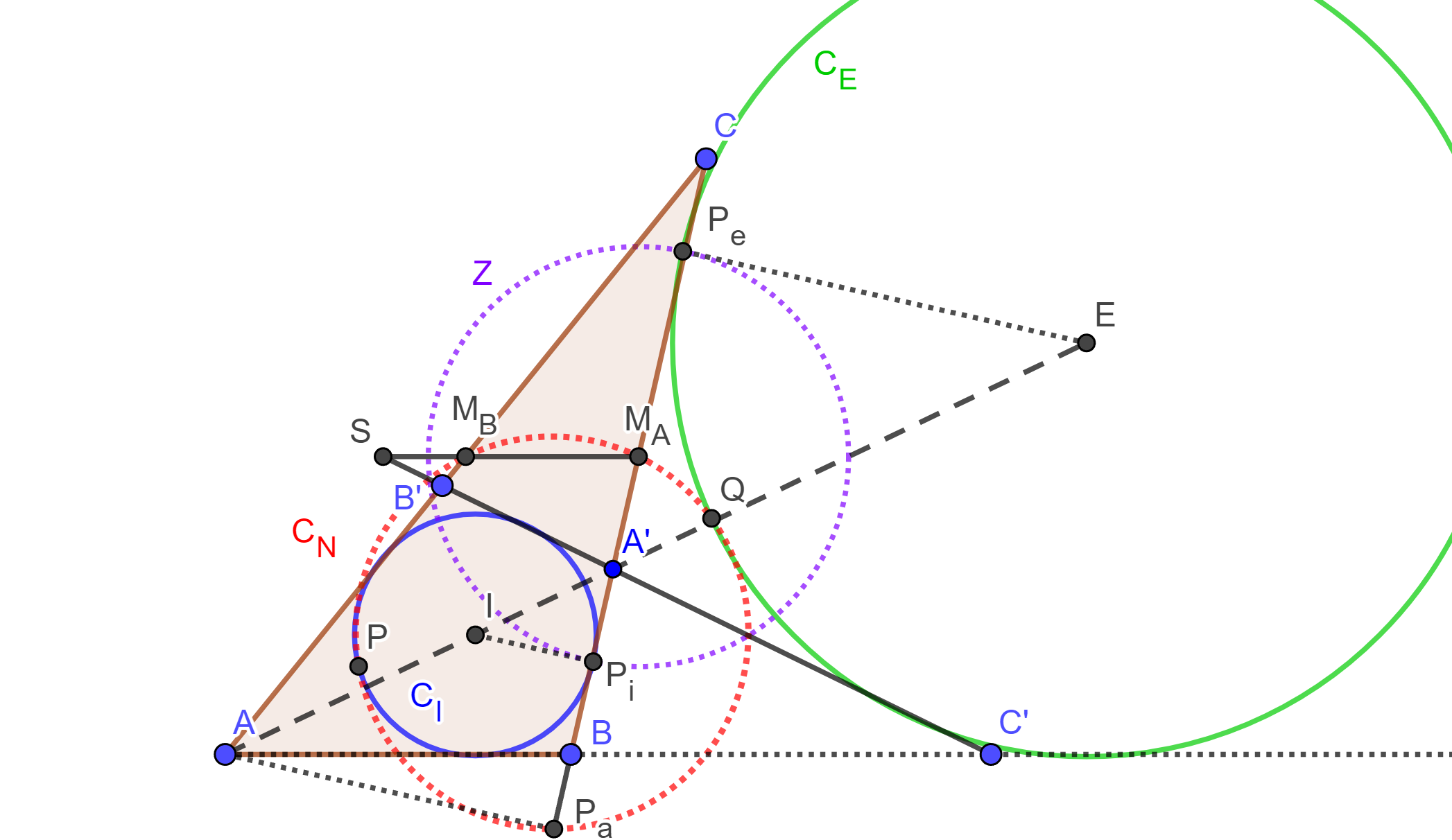
Teorema de Feuerbach. La circunferencia de los nueve puntos de un triángulo es tangente al incírculo y a los tres excírculos.
Demostración. Sea $\triangle ABC$ un triángulo con incírculo $C_I$ y excírculo $C_E$ (el excírculo correspondiente a $A$). Sea $BC$ la tangente común a $C_I$ y $C_E$. Tracemos otra tangente $B’C’$ simétrica a $BC$ con respecto a la bisectriz $AI$. De lo anterior, tenemos que $C \in AB$, $B’ \in AC$ y $A’=BC \cap B’C’$.
Los puntos $A$ y $A’$ son centros de homotecia de $C_I$ y $C_E$ respectivamente. Entonces el segmento $IE$ es dividido por $A’$ y $A$ interna y externamente en la razón de sus radios. Sea $r$ el radio de $C_I$ y $r_A$ el radio de $C_E$. Entonces: $$\frac{IA’}{A’E}=-\frac{IA}{AE}=\frac{r}{r_A}.$$
Por lo tanto, $A$ y $A’$ son conjugados armónicos respecto a $I$ y $E$. Tracemos perpendiculares desde $E$, $I$ y $A$ sobre la recta $BC$, y llamemos $P_e$, $P_i$ y $P_a$ a sus respectivos pies. Los triángulos $\triangle EP_eA’$, $\triangle IP_iA’$ y $\triangle AP_aA’$ son semejantes. Por lo tanto, $P_a$ y $A’$ son conjugados armónicos respecto a $P_i$ y $P_e$.
Sea $M_A$ el punto medio de $BC$. Entonces también es punto medio de $P_i$ y $P_e$. Tracemos la circunferencia $Z$ con centro $M_A$ y radio $M_AP_i$. Entonces $A’$ y $P_a$ son inversos respecto a $Z$.
Calculemos el radio de $Z$. Sean $a$, $b$, $c$ las longitudes de los lados opuestos a $A$, $B$, $C$ respectivamente, y sea $s$ el semiperímetro. Entonces:
$$P_eP_i=BC-2P_iC=a-2(s-c)=c-b.$$
Por lo tanto, el radio de $Z$ es $\frac{c-b}{2}$ y $M_AM_B=\frac{c}{2}$.
Sea $S=B’C’ \cap M_AM_B$. Entonces:
$$M_AS=M_AM_B – M_BS.$$
Como $M_AM_B$ es paralela a $BA$, entonces $\triangle B’SM_B \sim \triangle B’C’A$. Por lo tanto, sus lados son proporcionales: $$\frac{SM_B}{C’A}=\frac{M_BB’}{AB’}.$$
Por lo tanto, $S$ y $M_B$ son inversos respecto a la circunferencia $Z$ con diámetro $P_iP_e$. La inversa de la recta $B’C’$ es una circunferencia que pasa por $M_A$ (el centro de inversión), por $P_a$ y por $M_B$. Como una circunferencia está determinada por tres puntos y la circunferencia de los nueve puntos cumple esto, entonces $C_N$ (la circunferencia de los nueve puntos) es la inversa de la recta $B’C’$ con respecto a la circunferencia $Z$.
El inverso de $C_I$ con respecto a $Z$ es $C_I$ mismo, ya que $C_I$ es ortogonal a $Z$. De igual forma, el inverso de $C_E$ con respecto a $Z$ es $C_E$. Como $B’C’$ es tangente a $C_I$ y $C_E$, y la inversión conserva ángulos, se sigue que la circunferencia $C_N$ es tangente a las circunferencias $C_I$ y $C_E$. El mismo razonamiento aplica para los otros dos excírculos.
$\square$
Invarianza de la razón cruzada bajo inversión
Finalmente, veamos una propiedad proyectiva importante que se preserva bajo inversión.
Teorema. La razón cruzada es invariante bajo inversiones.
Demostración. Este resultado debe interpretarse tanto para la razón cruzada entre puntos colineales como para rectas concurrentes.
Sea $\mathcal{C}(O, r)$ una circunferencia de inversión. Sean $A$, $B$, $C$ y $D$ cuatro puntos colineales distintos de $O$, con inversos $A’$, $B’$, $C’$ y $D’$ con respecto a $\mathcal{C}$. Denotemos $a’=OA’$, $b’=OB’$, $c’=OC’$ y $d’=OD’$.
Queremos demostrar que las razones cruzadas coinciden: $$O(A’B’, C’D’)=O(AB, CD).$$
Como la razón cruzada es una propiedad proyectiva y las inversiones preservan ángulos e invierten orientación, tenemos:
Veremos cómo la inversión es una forma alternativa de resolver problemas ya demostrados, facilitando su comprensión. Además, revisaremos un tema de gran importancia: la circunferencia de antisimilitud.
En la entrada anterior establecimos una versión general del Teorema Integral de Cauchy, la cual nos es de mucha utilidad al resolver problemas relacionados con el cálculo de integrales.
En esta entrada veremos algunos resultados importantes que relacionan a las series de funciones y los conceptos de integral y derivada de las mismas, en particular probaremos bajo qué condiciones es posible integrar y derivar término a término a este tipo de series. Más aún, veremos que toda serie de potencias define a una función analítica en su disco de convergencia.
Proposición 39.1.(Weierstrass sobre integración término a término.) Sean $D\subset\mathbb{C}$ un dominio, $\gamma$ un contorno en $D$ y $\{f_n:D\to\mathbb{C}\}_{n\geq 0}$ una sucesión de funciones continuas que converge uniformemente a una función $f:D \to \mathbb{C}$ en $D$. Entonces: \begin{equation*} \lim_{n\to\infty} \int_{\gamma} f_n(z) dz = \int_{\gamma} f(z) dz = \int_{\gamma} \lim_{n\to\infty} f_n(z) dz. \end{equation*}
Demostración. Dadas las hipótesis, por la proposición 28.1 tenemos que $f$ es una función continua en $D$, por lo que $\int_\gamma f(z) dz$ existe.
Por la definición de convergencia uniforme, dado $\varepsilon>0$ existe $N\in\mathbb{N}$ tal que si $n\geq N$, se cumple que: \begin{equation*} |f_n(z) – f(z)|<\frac{\varepsilon}{1+\ell(\gamma)}, \quad \forall z\in D. \end{equation*}
Entonces, si $n\geq N$, por las proposiciones 34.2(1) y 34.3(5), tenemos que: \begin{align*} \left|\int_{\gamma} f_n(z) dz – \int_{\gamma} f(z) dz\right| & = \left|\int_{\gamma} \left[f_n(z)-f(z)\right] dz\right|\\ & \leq \int_{\gamma} \left|f(z)-f_n(z)\right| \, |dz|\\ & < \frac{\varepsilon}{1+\ell(\gamma)} \ell(\gamma)\\ & < \varepsilon. \end{align*}
Como $\varepsilon>0$ es arbitrario, entonces: \begin{equation*} \lim_{n\to\infty} \int_{\gamma} f_n(z) dz = \int_{\gamma} f(z) dz = \int_{\gamma} \lim_{n\to\infty} f_n(z) dz. \end{equation*}
La última parte se sigue de aplicar la primera parte del resultado a la sucesión de sumas parciales de la serie, por lo que los detalles se dejan como ejercicio al lector.
$\blacksquare$
Definición 39.1. (Convergencia uniformemente compacta.) Una sucesión de funciones $\{f_n\}_{n\geq 0}$ definidas en un conjunto abierto $U\subset\mathbb{C}$ se dice que converge uniformemente en compactos o que converge compactamente en $U$ si para cada subconjunto compacto $K\subset U$ la sucesión de restricciones $\{f_n:K\to\mathbb{C}\}_{n\geq 0}$ converge uniformemente a la restricción $f:K\to\mathbb{C}$.
Lema 39.1. Sea $\{f_n\}_{n\geq 0}$ una sucesión de funciones definidas en un conjunto abierto $U\subset\mathbb{C}$. La sucesión converge compactamente en $U$ si y solo si converge uniformemente en cada disco cerrado contenido en $U$.
Demostración.Se deja como ejercicio al lector.
$\blacksquare$
Teorema 39.1. (Weierstrass sobre la convergencia analítica.) Sea $\{f_n\}_{n\geq 0}$ una sucesión de funciones analíticas definidas en un dominio $D\subset\mathbb{C}$ y $f:D \to \mathbb{C}$ una función. Si $f_n \to f$ uniformemente en todo subconjunto compacto de $D$, entonces $f$ es analítica en $D$. Más aún, para cada $k\in\mathbb{N}$ se cumple que $f_n^{(k)} \to f^{(k)}$ uniformemente en cada subconjunto compacto de $D$.
Demostración. Dadas las hipótesis, sea $\gamma$ un contorno cerrado en $D$. Como cada función $f_n$ es analítica en $D$, en particular es continua en $D$, proposición 16.1, y dado que $f_n \to f$ uniformemente en todo subconjunto compacto de $D$, por la proposición 28.1 tenemos que $f$ es continua en todo subconjunto compacto de $D$, entonces de la proposición 10.12 se sigue que $f$ es continua en $D$.
Por el teorema de la curva de Jordan, teorema 36.1, sabemos que los puntos en $\gamma$ y su interior forman un conjunto cerrado y acotado $S$, es decir, compacto, proposición 10.7.
Entonces, por la definición de convergencia uniforme, dado $\varepsilon>0$ existe $N\in\mathbb{N}$ tal que si $n\geq N$, se cumple que: \begin{equation*} |f_n(z) – f(z)|<\varepsilon, \quad \forall z\in \gamma. \end{equation*}
Como para todo $n\geq 0$ la función $f_n$ es analítica en $D$, entonces, por la proposición 34.3(5), el teorema de integral de Cauchy y la desigualdad del triángulo, tenemos que: \begin{align*} \left|\int_{\gamma} f(z) dz\right| & = \left|\int_{\gamma} \left[f(z)-f_n(z) + f_n(z)\right] dz\right|\\ & \leq \left|\int_{\gamma} \left[f(z)-f_n(z) \right] dz\right| + \left|\int_{\gamma} f_n(z) dz\right|\\ & = \left|\int_{\gamma} \left[f(z)-f_n(z) \right] dz\right|\\ & \leq \int_{\gamma} \left|f(z)-f_n(z)\right| \, |dz|\\ & < \varepsilon \cdot \ell(\gamma). \end{align*}
Como $\varepsilon>0$ es arbitrario, entonces: \begin{equation*} \left|\int_{\gamma} f(z) dz\right| = 0 \quad \Longrightarrow \quad \int_{\gamma} f(z) dz = 0, \end{equation*}y dado que $\gamma$ es un contorno cerrado arbitrario en $D$, el resultado se cumple para todo contorno cerrado $\gamma$ en $D$. Entonces, por el teorema de Morera tenemos que $f$ es una función analítica en $D$.
De acuerdo con el lema 39.1, solo basta con verificar el resultado para discos cerrados contenidos en $D$. Sean $z_0\in D$ fijo, $r>0$ tal que $\overline{B}(z_0,r) \subset D$ y parametrizamos a la frontera del disco cerrado como $\gamma_r = \partial \overline{B}(z_0,r)$, orientada positivamente. Por la definición de convergencia uniforme, dado $\varepsilon>0$ existe $N\in\mathbb{N}$ tal que si $n\geq N$, se cumple que: \begin{equation*} |f_n(z) – f(z)| < \frac{\varepsilon r^{k}}{k! 2^{k+1}}, \quad \forall z\in \overline{B}(z_0,r), \tag{39.1} \end{equation*}donde $r>0$ y $k\in\mathbb{N}^{+}$.
Para $k\in\mathbb{N}^+$ fijo, por la fórmula integral de Cauchy para las derivadas de orden superior, proposición, tenemos que: \begin{equation*} f^{(k)}(z) = \frac{k!}{2\pi i} \int_{\gamma_r} \frac{f(\zeta)}{(\zeta – z)^{k+1}} d\zeta, \quad \forall z\in B(z_0,r). \tag{39.2} \end{equation*}
Notemos que para $z\in \overline{B}(z_0,r/2) \subset \overline{B}(z_0,r)$ se tiene por la proposición 3.3 que: \begin{equation*} \frac{r}{2} \leq |\zeta – z_0| – |z_0 -z| \leq |\zeta -z| \quad \Longrightarrow \quad \frac{1}{|\zeta -z|} \leq \frac{2}{r} \tag{39.4}. \end{equation*}
Es claro que: \begin{equation*} \ell(\gamma_r) = \int_{\gamma_r} |d\zeta| =2 \pi r. \end{equation*}
Entonces, si $n\geq N$ y $z\in \overline{B}(z_0,r/2)$, por las proposiciones 34.2(1), 34.3(5) y por (39.1), (39.2), (39.3) y (39.4), se tiene que: \begin{align*} \left|f_n^{(k)}(z) – f^{(k)}(z)\right| & = \left| \frac{k!}{2\pi i} \int_{\gamma_r} \frac{f_n(\zeta)}{(\zeta – z)^{k+1}} d\zeta – \frac{k!}{2\pi i} \int_{\gamma_r} \frac{f(\zeta)}{(\zeta – z)^{k+1}} d\zeta \right|\\ & = \frac{k!}{2\pi} \left|\int_{\gamma_r} \frac{f_n(\zeta) – f(\zeta)}{(\zeta – z)^{k+1}} d\zeta \right|\\ & \leq \frac{k!}{2\pi} \int_{\gamma_r}\left| \frac{f_n(\zeta) – f(\zeta)}{(\zeta – z)^{k+1}} \right| \, |d\zeta| \\ & = \frac{k!}{2\pi} \int_{\gamma_r} \frac{\left|f_n(\zeta) – f(\zeta)\right|}{\left|\zeta – z\right|^{k+1}} \, |d\zeta| \\ & \leq \frac{k!}{2\pi} \frac{2^{k+1}}{r^{k+1}} \frac{\varepsilon r^{k}}{k! 2^{k+1}} \int_{\gamma_r} |d\zeta|\\ & = \varepsilon, \end{align*}como $z\in \overline{B}(z_0,r/2)$ y $r>0$ son arbitrarios, entonces $f_n^{(k)} \to f^{(k)}$ uniformemente en cualquier disco cerrado contenido en $D$, por lo que del lema 39.1 se sigue el resultado.
$\blacksquare$
Corolario 39.1. Sean $z_0\in\mathbb{C}$ fijo y $f:B(z_0, R) \to \mathbb{C}$ una función dada por la serie de potencias: \begin{equation*} f(z) = \displaystyle \sum_{n=0}^\infty c_n (z-z_0)^n, \end{equation*}con radio de convergencia $R>0$. Entonces $f$ es analítica en $B(z_0, R)$.
Demostración. Dadas las hipótesis, por la proposición 29.2 tenemos que la serie de potencias converge uniformemente a $f$ en todo subdisco cerrado $\overline{B}(z_0,r)$, con $r<R$, por lo que, del teorema 39.1 se sigue que $f$ es analítica en $B(z_0, R)$.
$\blacksquare$
Teorema 39.2. (Weierstrass sobre derivación término a término.) Sea $\{f_n\}_{n\geq 0}$ una sucesión de funciones analíticas definidas en un dominio $D\subset\mathbb{C}$ y sea $f(z) = \displaystyle \sum_{n=0}^\infty f_n(z)$. Si la serie converge uniformemente a $f$ en cada disco cerrado contenido en $D$, definición 28.6, entonces $f$ es analítica en $D$ y puede derivarse término a término, es decir: \begin{equation*} f^{(k)}(z) = \displaystyle \sum_{n=0}^\infty f_n^{(k)}(z), \quad \forall z\in D, \end{equation*}para todo $k\in\mathbb{N}^+$.
Demostración.Se deja como ejercicio al lector.
$\blacksquare$
Observación 39.1. Notemos que los resultados anteriores no suponen la convergencia uniforme en todo el dominio $D$, es decir, la convergencia uniforme es únicamente en los subconjuntos compactos de $D$ o equivalentemente, lema 39.1, en los subdiscos cerrados en $D$.
Ejemplo 39.1. Sea $D = \{z\in\mathbb{C} : |z|<1\}$. Consideremos a la serie: \begin{equation*} f(z) = \sum_{n=1}^\infty \frac{z^n}{n}, \quad \forall \, z\in D. \end{equation*}
No es difícil verificar que dicha serie converge puntualmente en $D$ y uniformemente en los discos cerrados $\overline{B}(0,r)$, para $0\leq r <1$, ejercicio 1. Por lo que converge uniformemente en todos los discos cerrados en $A$, entonces por los teoremas 39.1 y 39.2 concluimos que $f$ es analítica en $D$ y que su derivada $f'(z) = \displaystyle \sum_{n=1} z^{n-1}$ también converge en $D$. Sin embargo, se tiene convergencia puntual y no uniforme en $D$.
Ejemplo 39.2. (Derivación término a término.) Consideremos a la serie geométrica $\displaystyle\sum_{n=0}^\infty z^n$. De acuerdo con el ejemplo 28.8 sabemos que dicha serie converge uniformemente en todo disco cerrado $\overline{B}(0,r)$, con $0<r<1$, en tal caso: \begin{equation*} \displaystyle\sum_{n=0}^\infty z^n = \dfrac{1}{1-z}. \tag{39.5} \end{equation*}
Es claro que la función $f_n(z) = z^n$ es entera para todo $n\in\mathbb{N}$, en particular es analítica en $\overline{B}(0,r)$. Por lo que, podemos utilizar el teorema 39.2 para derivar a la serie geométrica término a término.
Derivando el lado derecho de la igualdad (39.5) tenemos: \begin{equation*} \frac{d}{dz} \frac{1}{1-z} = \frac{1}{(1-z)^2}. \end{equation*}
Por otra parte, derivando el lado izquierdo de la igualdad (39.5), por el teorema tenemos que: \begin{align*} \frac{d}{dz} \left(\displaystyle\sum_{n=0}^\infty z^n \right) & = \displaystyle\sum_{n=0}^\infty \frac{d}{dz} z^n\\ & = 1 + 2z + 3z^2 + 4z^3 + \cdots\\ & = \displaystyle\sum_{n=0}^\infty (n+1) z^n. \end{align*}
Notemos que este mismo resultado se obtuvo en el ejemplo 27.13 de la entrada 27, sin embargo, es claro que mediante el teorema de derivación término a término fue más sencillo deducirlo.
Ejemplo 39.3. (Integración término a término.) Continuemos trabajando con la serie geométrica $\displaystyle\sum_{n=0}^\infty z^n$. Dado que dicha serie converge uniformemente en todo disco cerrado $\overline{B}(0,r)\subset B(0, 1)$ y para todo $n\in\mathbb{N}$ la función $f_n(z) = z^n$ es entera, entonces podemos considerar a dicha serie para utilizar el la proposición 39.1 para integrar término a término.
Sea $\gamma$ el segmento de recta que une a $0$ y $\zeta$ de modo que $\gamma \subset B(0,1)$, es decir, $\gamma$ es el segmento de recta $[0,\zeta]$, tal que $|\zeta|<1$. Entonces: \begin{align*} \int_{[0, \zeta]} \frac{1}{1-z} dz & = \sum_{n=0}^\infty \int_{[0, \zeta]} z^n \, dz \\ & = \int_{[0, \zeta]} 1 \, dz + \int_{[0, \zeta]} z \, dz + \int_{[0, \zeta]} z^2 \, dz + \cdots \end{align*}
Notemos que el integrando del lado izquierdo de la igualdad, es decir, la función $\dfrac{1}{1-z}$, salvo una constante, corresponde con la derivada de alguna de las ramas de la función multivaluada $\operatorname{log}(1-z)$.
Dado que la rama principal $\operatorname{Log}(1-z)$ es analítica en $\mathbb{C}\setminus[1, \infty)$, ejercicio 10 de la entrada 21, entonces en particular es analítica en el disco abierto $B(0, 1)$, por lo que, al tener la condición $|z|<1$, elegimos a dicha rama.
Por otra parte, por el corolario 21.1 sabemos que para la rama principal del logaritmo se cumple que $-\operatorname{Log}(w) = \operatorname{Log}(w^{-1})$ si $w$ no está en el corte de rama de dicha función. Para nuestro caso, como $|z|<1$, entonces los valores de $z$ que consideramos no están en el corte de rama de la función $\operatorname{Log}(1-z)$, por lo que se cumple: \begin{equation*} -\operatorname{Log}(1-z) = \operatorname{Log}\left(\frac{1}{1-z}\right). \end{equation*}
Notemos que habíamos llegado al mismo resultado en el ejercicio 5 de la entrada 30, sin embargo, utilizando el teorema de integración término a término el procedimiento fue más sencillo.
Tarea moral
Sea $D = \{z\in\mathbb{C} : |z|<1\}$. Considera a la serie: \begin{equation*} f(z) = \sum_{n=1}^\infty \frac{z^n}{n}, \quad \forall \, z\in D. \end{equation*}Muestra que dicha serie converge puntualemente en $D$ y uniformemente en todo disco cerrado $\overline{B}(0,r)$, para $0\leq r <1$.
Completa la demostración de la proposición 39.1.
Demuestra el lema 39.1.
Prueba el teorema 39.2.
Muestra que si $|z|<1$, entonces: \begin{equation*} \operatorname{Log}(1+z) = \displaystyle \sum_{n=0}^\infty (-1)^n \dfrac{z^{n+1}}{n+1}. \end{equation*}Hint: Considera el contorno $\gamma$ dado por el segmento de recta $[0, \zeta]$ con $|\zeta|<1$ y utiliza la proposición 39.1.
Muestra que la sucesión de funciones $\{f_n\}_{n\geq 1}$, dada por: \begin{equation*} f_n(z)=\frac{z^{n+1}}{n(n+1)}, \quad \forall n\in\mathbb{N}^+, \end{equation*}converge uniformemente en el disco abierto $B(0,1)$, pero que la sucesión de derivadas: \begin{equation*} f_n^{(2)}(z)=z^{n-1}, \quad \forall n\in\mathbb{N}^+, \end{equation*}no converge uniformemente en dicho disco.
$D\subset\mathbb{C}$ un dominio, $f:D \to \mathbb{C}$ una función y $\{f_n\}_{n\geq 0}$ una sucesión de funciones continuas definidas en $D$, tales que: \begin{equation*} \int_{\gamma} f_n(z) dz =0, \quad \forall n\in\mathbb{N}, \end{equation*}para todo contorno cerrado $\gamma$ en $D$. Si $f_n \to f$ converge uniformemente en $D$, muestra que $f$ es analítica en $D$.
Sean $D\subset\mathbb{C}$ un dominio, $f:D \to \mathbb{C}$ una función y $\{f_n\}_{n\geq 0}$ una sucesión de funciones continuas definidas en $D$, tales, que $f_n \to f$ converge uniformemente en $D$, entonces: \begin{equation*} \int_{\gamma} f(z) |dz| = \lim_{n\to\infty} \int_{\gamma} f_n(z) |dz|, \end{equation*}para todo contorno $\gamma$ en $D$.
Más adelante…
En esta entrada hemos establecido algunos resultados importantes sobre las series de funciones y los conceptos de convergencia uniforme, integración y diferenciación, en particular vimos bajo qué condiciones posible integrar o derivar término a término este tipo de funciones.
En la siguiente entrada definiremos dos tipos de funciones complejas muy particulares, las funciones conjugadas armónicas y las funciones conformes, las cuales están relacionadas con algunos de los conceptos de esta entrada y que nos serán de utilidad para construir funciones analíticas. Dichas funciones nos permitirán caracterizar aún más la geometría de las funciones complejas.
En la entrada anterior hemos definido formalmente la integral para funciones complejas de variable compleja, que como vimos dicha definición resulta familiar a la de integrales de línea vista en nuestros cursos de Cálculo.
En esta entrada veremos algunos resultados, como el Teorema Fundamental del Cálculo para integrales de contorno y el lema de Goursat, que serán clave al enunciar el Teorema de Cauchy para funciones complejas, que es sin duda un resultado fundamental en la teoría de las funciones analíticas y en general de la teoría de la Variable Compleja.
Definición 35.1. (Primitiva de una función compleja.) Sean $U\subset\mathbb{C}$ un conjunto abierto y $f:U\to\mathbb{C}$ una función continua en $U$. Se dice que $F:U\to\mathbb{C}$ es una primitiva de $f$ en $U$ si $F$ es una función analítica en $U$ tal que $F'(z)=f(z)$ para todo $z\in U$.
Observación 35.1. Dado que $f$ es continua y $F$ analítica, en particular continua, entonces por la proposición 19.2 se cumple que cualesquiera dos primitivas de $f$ difieren por una constante compleja.
Para determinar una primitiva de una función compleja continua $f$, podemos recurrir, cuando sea posible, al uso de los resultados de nuestros cursos de Cálculo y verificar mediante las reglas de diferenciación para funciones complejas.
Ejemplo 35.1. Consideremos a la función $f(z)=ze^z$ y determinemos una primitiva de $f$.
Solución. Es claro que $f$ es una función entera ya que $g(z)=z$ y $h(z)=e^z$ son funciones enteras, proposición 16.2, por lo que en particular es continua en todo $\mathbb{C}$.
Afirmamos que una primitiva de $f$ en $\mathbb{C}$ es $F(z)=ze^z – e^z$. Por la proposición 16.2 tenemos que: \begin{align*} F'(z) & =\frac{d}{dz}\left(ze^z – e^z\right)\\ & =\frac{d}{dz}ze^z – \frac{d}{dz}e^z\\ & = e^{z} + ze^z – e^z\\ & = ze^z. \end{align*}
Ejemplo 35.2. Determinemos una primitiva de las siguientes funciones complejas. a) $f(z)=z^3+7z-2$. b) $f(z)=\operatorname{Log}(z)$. c) $f(z)=\dfrac{1}{z}$.
Solución. Recurrimos a los resultados de diferenciación para funciones complejas establecidos a lo largo de la segunda unidad del curso.
a) Por el corolario 15.1 es claro que $f$ es una función continua en $\mathbb{C}$ por ser un polinomio complejo.
c) Sabemos que $f(z)=\dfrac{1}{z}$ es una función continua en $\mathbb{C}\setminus\{0\}$. En este punto inferimos que una posible primitiva de $f$ está dada por $F(z)=\operatorname{Log}(z)$, sin embargo, de acuerdo con la proposición 21.4, sabemos que la rama principal del logaritmo, dada por la función $F$, únicamente es analítica en $D=\mathbb{C}\setminus(-\infty, 0]$, por lo que si restringimos a $f$ al dominio $D$, en el cual sigue siendo una función continua, entonces es claro que $F$ es una primitiva de $f$ en $D$ ya que: \begin{equation*} F'(z) = \frac{d}{dz} \operatorname{Log}(z) = \frac{1}{z} = f(z), \quad \forall z\in D. \end{equation*}
Proposición 35.1. (Teorema Fundamental del Cálculo para integrales de contorno.) Sean $U\subset\mathbb{C}$ un conjunto abierto, $[a,b]\subset\mathbb{R}$, con $a<b$, un intervalo cerrado, $f:U\to\mathbb{C}$ una función continua en $U$ y $\gamma:[a,b]\to U$ un contorno en $U$. Si $F:U\to\mathbb{C}$ es una primitiva de $f$ en $U$, entonces: \begin{equation*} \int_{\gamma} f(z) dz = F(\gamma(b)) – F(\gamma(a)). \end{equation*}
En particular, si $\gamma$ es una contorno cerrado, entonces: \begin{equation*} \int_{\gamma} f(z) dz = 0. \end{equation*}
Demostración. Dadas las hipótesis, consideremos primero el caso en que $\gamma$ es una curva suave. Sean $g, G:[a,b]\to\mathbb{C}$ las funciones híbridas dadas, respectivamente, por: \begin{equation*} g(t) = f(\gamma(t))\gamma'(t) \quad \text{y} \quad G(t) = F(\gamma(t)). \end{equation*}
Dado que $f$ es continua en $U$, $F$ es analítica en $U$ tal que $F'(z)=f(z)$ para todo $z\in U$ y $g$ es de clase $C^1$ en $[a,b]$, entonces $g$ es una función continua en $[a,b]$ y $G$ una función continua en $[a,b]$ y diferenciable en $(a,b)$. Por la regla de la cadena, proposición 32.2, tenemos que: \begin{align*} \frac{d}{dt} G(t) & = F'(\gamma(t))\gamma'(t)\\ &= f(\gamma(t))\gamma'(t)\\ & = g(t), \quad \forall t\in(a,b), \end{align*}es decir, $G$ es una primitiva de $g$, definición 33.2.
Por lo tanto, del segundo TFC para funciones híbridas, proposición 33.2, se tiene que: \begin{align*} \int_{\gamma} f(z) dz & = \int_{a}^{b} f(\gamma(t))\gamma'(t) dt\\ & = \left. G(t)\right|_{a}^{b}\\ & = \left. F(\gamma(t))\right|_{a}^{b}\\ & = F(\gamma(b)) – F(\gamma(a)). \end{align*}
Si $\gamma$ es de clase $C^1$ a trozos, entonces por definición podemos elegir a la partición: \begin{equation*} P : a=t_0 < t_1 < \cdots < t_{n-1}<t_n=b, \end{equation*}del intervalo $[a,b]$, tal que $\gamma_k=\left.\gamma\right|_{[t_{k-1}, t_k]}$ es una curva suave para $1\leq k\leq n$, entonces: \begin{align*} \int_{\gamma} f(z) dz & = \int_{\gamma_1} f(z) dz + \cdots + \int_{\gamma_n} f(z) dz\\ & = F(\gamma(t_1)) – F(\gamma(a)) + F(\gamma(t_2)) – F(\gamma(t_1)) + \cdots + F(\gamma(b)) – F(\gamma(t_{n-1}))\\ & = F(\gamma(b)) – F(\gamma(a)). \end{align*}
Por último, si el contorno $\gamma$ es cerrado, entonces $\gamma(a) = \gamma(b)$, en tal caso, de lo anterior se sigue que: \begin{equation*} \int_{\gamma} f(z) dz = F(\gamma(b)) – F(\gamma(a)) = 0. \end{equation*}
$\blacksquare$
Observación 35.2. El resultado anterior es de suma importancia, ya que establece que para cualquier contorno $\gamma$ en un conjunto abierto $U\subset\mathbb{C}$, si $f:U\to\mathbb{C}$ es una función continua con primitiva $F$ en $U$, entonces la integral de contorno de $f$ no depende de $\gamma$, sino únicamente de sus extremos.
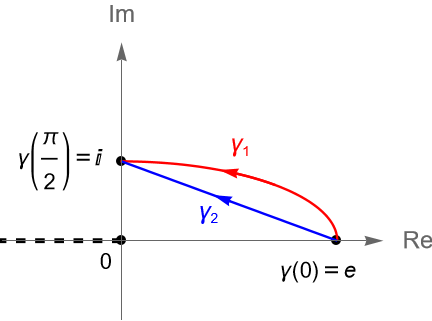
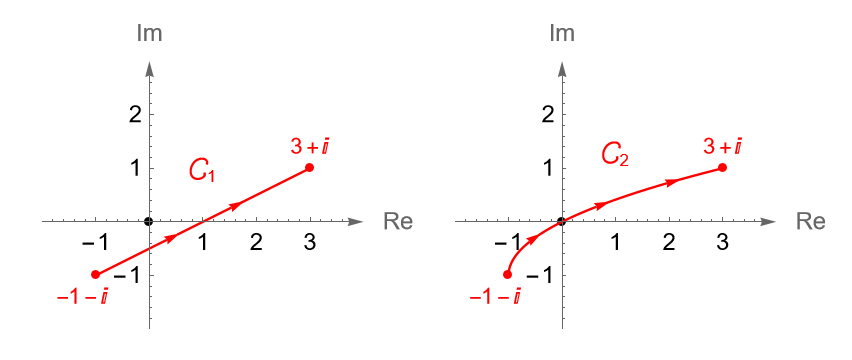
Ejemplo 35.3. Evaluemos la integral $\int_{\gamma} z^{-1} dz$ a lo largo de los contornos: \begin{align*} \gamma_1(t)&=e\operatorname{cos}(t)+i\operatorname{sen}(t), \quad \forall \, t\in[0,\pi/2],\\ \gamma_2(t) &= e(1-t)+it, \quad \forall \, t\in[0,1]. \end{align*}
Solución. Sean $f(z)=z^{-1}$ y $F(z)=\operatorname{Log}(z)$. Sabemos que $f$ es una función analítica en $\mathbb{C}\setminus\{0\}$ mientras que $F$ es una función analítica en $D=\mathbb{C}\setminus(-\infty, 0]$, por lo que si restringimos a $f$ al dominio $D$, entonces: \begin{equation*} F'(z) = \frac{d}{dz} \operatorname{Log}(z) = \dfrac{1}{z} = f(z), \quad \forall z\in D, \end{equation*}es decir, $F$ es una primitiva de $f$ en $D$.
Claramente $\gamma_1$ y $\gamma_2$ son dos contorno en $D$, figura 127, tales que $\gamma_1(0)=\gamma_2(0)=e$ y $\gamma_1(\pi/2)=\gamma_1(\pi/2)=i$. Entonces, de la proposición 35.1 se sigue que: \begin{equation*} \int_{\gamma_1} z^{-1} dz = \left. F(\gamma_1(t))\right|_{0}^{\pi/2} = \operatorname{Log}(i) – \operatorname{Log}(e) = -1 + i\frac{\pi}{2}. \end{equation*} \begin{equation*} \int_{\gamma_2} z^{-1} dz = \left. F(\gamma_2(t))\right|_{0}^{\pi/2} = \operatorname{Log}(i) – \operatorname{Log}(e) = -1 + i\frac{\pi}{2}. \end{equation*}
Figura 127: Contornos $\gamma_1$ y $\gamma_2$ del ejemplo 35.3.
Ejemplo 35.4. Evaluemos la integral $\int_{C} \operatorname{sen}(z) dz$, donde $C$ es el contorno dado en la figura 128.
Figura 128: Contorno $C$ del ejemplo 35.4.
Solución. Dado que $f(z)=\operatorname{sen}(z)$ es una función entera y $F(z)=-\operatorname{cos}(z)$ es una primitiva de $f$ en $\mathbb{C}$, entonces por la proposición 35.1 tenemos que: \begin{equation*} \int_{C} \operatorname{sen}(z) dz = \left. -\operatorname{cos}(z)\right|_{-3}^{6+3i} = -\operatorname{cos}(6+3i) + \operatorname{cos}(-3). \end{equation*}
Corolario 35.1. (Integración por partes para integrales de contorno.) Sean $D\subset\mathbb{C}$ un dominio, $[a,b]\subset\mathbb{R}$, con $a<b$ y $f, g: D \to\mathbb{C}$ dos funciones analíticas en $D$. Entonces, para cualquier contorno $\gamma:[a,b]\to D$ en $D$ se cumple que: \begin{equation*} \int_{\gamma} f(z) g'(z) dz = \left. f(z) g(z)\right|_{a}^{b} – \int_{\gamma} f'(z) g(z) dz. \end{equation*}
Demostración.Se deja como ejercicio al lector.
$\blacksquare$
Ejemplo 35.5. Si $f(z)=z$ y $g(z)=-\operatorname{cos}(z)$ y $\gamma$ describe al contorno $C$ en la figura 128, entonces por el corolario 35.1 tenemos que: \begin{align*} \int_{C} z \operatorname{sen}(z) dz & = \left.-z\operatorname{cos}(z)\right|_{-3}^{6+3i} + \int_{C} \operatorname{cos}(z) dz\\ & = -(6+3i)\operatorname{cos}(6+3i) -3\operatorname{cos}(-3) +\left.\operatorname{sen}(z)\right|_{-3}^{6+3i}\\ & = -(6+3i)\operatorname{cos}(6+3i) -3\operatorname{cos}(-3) + \operatorname{sen}(6+3i) – \operatorname{sen}(-3). \end{align*}
Proposición 35.2. Sean $D\subset\mathbb{C}$ un dominio, $[a,b]\subset\mathbb{R}$, con $a<b$, un intervalo cerrado, $f:D\to\mathbb{C}$ una función continua en $D$ y $\gamma:[a,b]\to D$ un contorno en $D$. Las siguientes condiciones son equivalentes.
Existe una primitiva de $f$ en $D$.
Si el contorno $\gamma$ es cerrado, entonces: \begin{equation*} \int_{\gamma} f(z) dz = 0. \end{equation*}
Las integrales de contorno de $f$ son independientes del contorno en $D$, es decir, si $\gamma_1$ y $\gamma_2$ son cualesquiera dos contornos en $D$ tales que tienen los mismos puntos inicial y final, entonces: \begin{equation*} \int_{\gamma_1} f(z) dz = \int_{\gamma_2} f(z) dz. \end{equation*}
Demostración. Dadas las hipótesis, del teorema 35.1 se sigue que $1\Rightarrow 2$ y $1\Rightarrow 3$. Veamos que $2\Rightarrow 3$ y $3\Rightarrow 1$.
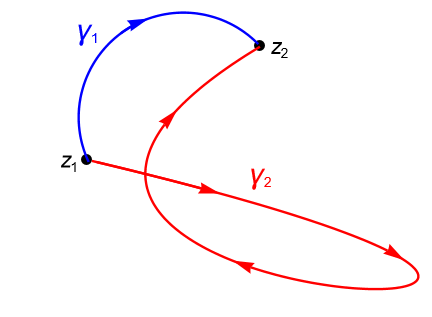
Supongamos que se cumple $2$. Sean $z_1, z_2 \in D$ dos puntos fijos. Si $\gamma_1$ y $\gamma_2$ son dos contornos en $D$ tales que ambos unen a $z_1$ con $z_2$, como en la figura 129, definimos al contorno cerrado $\gamma=\gamma_1+(-\gamma_2)$, entonces, por la proposición 34.2, tenemos que: \begin{align*} 0 = \int_{\gamma} f(z) dz & = \int_{\gamma_1} f(z) dz + \int_{-\gamma_2} f(z) dz\\ & = \int_{\gamma_1} f(z) dz – \int_{\gamma_2} f(z) dz, \end{align*}por lo que: \begin{equation*} \int_{\gamma_1} f(z) dz = \int_{\gamma_2} f(z) dz. \end{equation*}Entonces $2\Rightarrow 3$.
Figura 129: Contornos $\gamma_1$ y $\gamma_2$ que unen a los puntos $z_1$ y $z_2$.
Supongamos que se cumple $3$. Sea $z_0\in D$ un punto fijo y para cualquier $z_1\in D$ consideramos al contorno $\gamma$ que une a $z_0$ con $z_1$. Definimos: \begin{equation*} F(z_1) := \int_{\gamma} f(z) dz. \end{equation*}
Dado que $D$ es un dominio, es decir, es un conjunto abierto y conexo, del teorema 10.1 se sigue que $D$ es poligonal conexo, por lo que al menos existe un contorno poligonal en $D$ que une a $z_0$ y $z_1$. Como se cumple la condición $3$, entonces no importa el contorno que elijamos, ya que todos los posibles contornos en $D$ nos darán el mismo valor para $F(z_1)$. Por lo tanto, $F(z_1)$ es una función compleja bien definida en $D$.
Como $D$ es abierto, para algún $\varepsilon_1>0$, si $h\in\mathbb{C}$ es tal que $|h|<\varepsilon_1$, entonces el segmento de recta que va de $z_1$ a $z_1+h$, es decir, $[z_1, z_1+h]$, está completamente contenido en $D$ y se puede parametrizar como $\beta(t)=z_1+ht$, para $t\in[0,1]$.
Como $f$ es una función continua en $D$, en particular lo es en $z_1$, entonces dado $\varepsilon>0$ existe $\delta>0$ tal que: \begin{equation*} |z-z_1|<\delta \quad \Longrightarrow \quad |f(z)-f(z_1)| < \varepsilon. \end{equation*}
Por lo que, si $|h|<\delta$, entonces para todo $z\neq z_1$ en el segmento de recta $[z_1, z_1+h]$, se cumple que $|z-z_1|\leq |h| < \delta$. Por lo tanto, si $|h|<\delta$, entonces, por la proposición 34.3(5), se tiene que: \begin{align*} \left| \frac{F(z_1+h) – F(z_1)}{h} – f(z_1)\right| & = \left|\int_{\beta} \frac{f(z) – f(z_1)}{h} dz.\right|\\ & \leq \int_{\beta} \left|\frac{f(z) – f(z_1)}{h}\right| |dz|\\ & < \int_\beta \frac{\varepsilon}{|h|} |dz|\\ & = \frac{\varepsilon}{|h|} \int_\beta |dz|\\ & = \frac{\varepsilon}{|h|} \ell(\beta)\\ & =\varepsilon, \end{align*}es decir, si $|h|<\delta$ se cumple que: \begin{equation*} \left| \frac{F(z_1+h) – F(z_1)}{h} – f(z_1)\right| < \varepsilon. \end{equation*}
Como $\varepsilon>0$ es arbitrario, entonces: \begin{equation*} \lim\limits_{h\to 0} \frac{F(z_1+h) – F(z_1)}{h} = f(z_1). \end{equation*}
Dado que $z_1\in D$ es arbitrario, entonces $F'(z_1) = f(z_1)$ para todo $z_1\in D$, es decir, existe una primitiva de $f$ en $D$.
$\blacksquare$
Ejemplo 35.6. Sean $z_0\in\mathbb{C}$ fijo, $n\in\mathbb{Z}$ y $D = \overline{B}(0,1)$, es decir, el disco cerrado unitario. Veamos que: a) $f(z)=\dfrac{1}{z}$ no tiene primitiva en $D$; b) $g(z)=(z-z_0)^n$ tiene primitiva en $D$ si $n\neq -1$.
Solución. Es claro que el contorno cerrado descrito por $\gamma(t)=e^{it}$, con $t\in[0,2\pi]$, es decir, la circunferencia unitaria $C(0,1)$, es un contorno en $\overline{B}(0,1)$.
a) De acuerdo con el ejemplo 34.1 se tiene que: \begin{equation*} \int_{\gamma} \frac{1}{z} dz = i2\pi \neq 0, \end{equation*}entonces, por la proposición 35.3 concluimos que no existe una primitiva de $f$ en $D$.
b) De acuerdo con el ejemplo 34.2 tenemos que: \begin{equation*} \int_{\gamma} (z-z_0)^n dz = \left\{ \begin{array}{lcc} 0 & \text{si} & n \neq -1, \\ \\ i2\pi & \text{si} & n=-1, \end{array} \right. \end{equation*}por lo que de la proposición 35.3 se sigue que $g(z)=(z-z_0)^n$ tiene primitiva en $D$, dada por: \begin{equation*} G(z) = \dfrac{(z-z_0)^{n+1}}{n+1}, \end{equation*}si $n\in\mathbb{Z}$ y $n\neq 1$.
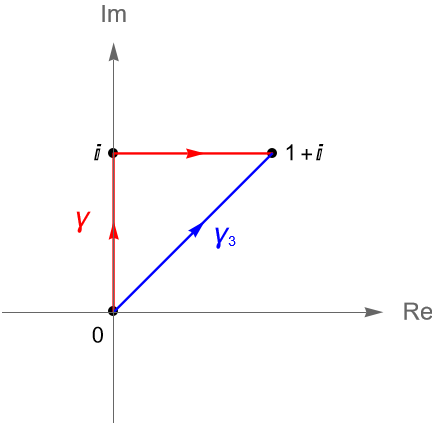
Ejemplo 35.7. Sean $z=x+iy\in\mathbb{C}$, $f(z)=(y-x)+i3x^2$ y $\gamma=\gamma_1+\gamma_2$, donde $\gamma_1(t)=it$ y $\gamma_2(t)=t+i$, con $t\in[0,1]$, figura 130.
Veamos que $f$ no tiene primitiva en $\mathbb{C}$.
Figura 130: Contornos $\gamma$ y $\gamma_3$ del ejemplo 35.7.
Solución. Es claro que $f$ es una función continua en $\mathbb{C}$ y que $\gamma$ es un contorno en $\mathbb{C}$.
De acuerdo con las proposiciones 33.2 y 34.2 tenemos que: \begin{align*} \int_{\gamma} f(z) dz & = \int_{\gamma_1} f(z) dz + \int_{\gamma_2} f(z) dz\\ & = \int_{0}^{1} f(\gamma_1(t))\gamma’_1(t) dt + \int_{0}^{1} f(\gamma_2(t))\gamma’_2(t) dt\\ & = \int_{0}^{1} it dt + \int_{0}^{1} (1-t+i3t^2) dt\\ & = \left.\frac{it^2}{2}\right|_{0}^{1} + \left.\left(t-\frac{t^2}{2}+it^3\right)\right|_{0}^{1}\\ & = \frac{i}{2} + \frac{1}{2} + i\\ & = \frac{1}{2} + \frac{3}{2} i. \end{align*}
Si consideramos al contorno $\gamma_3(t)=t+it$, con $t\in[0,1]$, no es difícil verificar que $\gamma$ y $\gamma_3$ tienen los mismos puntos inicial y final, pero: \begin{align*} \int_{\gamma_3} f(z) dz & = \int_{0}^{1} f(\gamma_3(t))\gamma’_3(t) dt\\ & = \int_{0}^{1} 3i(1+i)t^3 dt\\ & = \left. i(1+i)t^3\right|_{0}^{1}\\ & = -1 + i, \end{align*}es decir: \begin{equation*} \int_{\gamma} f(z) dz \neq \int_{\gamma_3} f(z) dz, \end{equation*}entonces, por la proposición 35.2 concluimos que $f$ no tiene primitiva en $\mathbb{C}$.
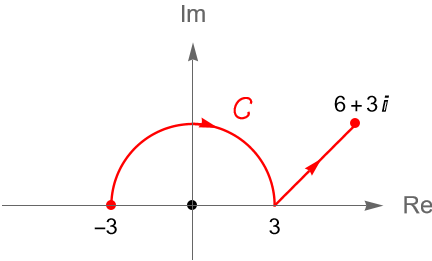
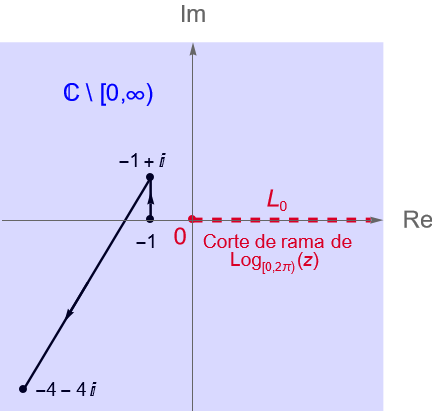
Ejemplo 35.8. Sean $z_1=-1, z_2=-1+i, z_3=-4-4i\in\mathbb{C}$. Evaluemos la integral: \begin{equation*} \int_{[z_1,z_2,z_3]} \frac{1}{z} dz. \end{equation*}
Solución. De acuerdo con la figura 131 es claro que el contorno poligonal $[z_1, z_2, z_3]$ pasa por la rama de corte de la rama principal del logaritmo, por tal motivo no podemos utilizar a dicha función como primitiva de $f(z)=z^{-1}$. Sin embargo, si consideramos a la rama natural del logaritmo, definición 21.3, es decir: \begin{equation*} F(z)=\operatorname{Log}_{[0,2\pi)}(z) = \operatorname{ln}|z| + i \operatorname{Arg}_{[0,2\pi)}(z), \end{equation*}tenemos que dicha rama tiene como corte de rama al semieje real positivo, incluyendo el origen, y que dicha rama es analítica en $D = \mathbb{C}\setminus{[0,\infty)}$, por lo que podemos considerar dicho dominio para la función $f$, pues ahí es una función continua.
Por la proposición 21.5 tenemos que: \begin{equation*} F'(z) = \frac{d}{dz} \operatorname{Log}_{[0,2\pi)}(z) = \frac{1}{z} = f(z), \quad \forall z \in D. \end{equation*}
Entonces, de la proposición 35.2 se sigue que: \begin{align*} \int_{[z_1,z_2,z_3]} \frac{1}{z} dz & = F(z_3) – F(z_1)\\ & = \operatorname{ln}|-4-4i| + i \operatorname{Arg}_{[0,2\pi)}(-4-4i) – \operatorname{ln}|-1| – i \operatorname{Arg}_{[0,2\pi)}(-1)\\ & = \operatorname{ln} \left(4\sqrt{2}\right) + i\frac{5\pi}{4} – \operatorname{ln}(1) – i\pi\\ & = \operatorname{ln} \left(4\sqrt{2}\right) + i\frac{5\pi}{4}\operatorname{Arg}_{[0,2\pi)}(-4-4i) – \operatorname{ln}(1) – i\pi\\ & = \frac{5}{2}\operatorname{ln}(2) + i\frac{\pi}{4}. \end{align*}
Figura 131: Contorno poligonal $[z_1, z_2, z_3]$ en el dominio $D=\mathbb{C}\setminus{[0,\infty)}$.
Observación 35.3. Hasta ahora hemos visto que muchas funciones complejas tienen primitivas. Por ejemplo, del corolario 16.1 se sigue que cualquier polinomio complejo: \begin{equation*} p(z)=c_0 + c_1 z + \cdots + c_n z^n, \end{equation*}tiene como primitiva al polinomio: \begin{equation*} P(z)=c_0z + \frac{c_1}{2} z^2 + \cdots + \frac{c_n}{n+1} z^{n+1}. \end{equation*}
Motivados en lo anterior y considerando los resultados de la tercera unidad podemos establecer la siguiente:
Proposición 35.3. Sean $z_0\in\mathbb{C}$ fijo y $f:B(z_0, R)\to\mathbb{C}$ una función dada por la serie de potencias: \begin{equation*} f(z) = \displaystyle \sum_{n=0}^\infty c_n (z-z_0)^n \end{equation*}con radio de convergencia $R>0$. Entonces: \begin{equation*} F(z) = \sum_{n=0}^\infty \frac{c_n}{n+1} (z-z_0)^{n+1}, \end{equation*}tiene el mismo radio de convergencia $R>0$ y $F'(z)=f(z)$ para todo $z\in B(z_0, R)$.
Demostración. Dadas las hipótesis, es suficiente probar que $F(z)$ tiene el mismo radio de convergencia que $f(z)$, ya que por la proposición 30.2 podemos diferenciar término a término a la serie que define a $F$ y así obtener el resultado.
Por la corolario 29.3 tenemos que: \begin{equation*} R = \lim\limits_{n\to\infty} \left|\frac{c_{n}}{c_{n+1}}\right| = \lim\limits_{n\to\infty} \left|\frac{c_{n-1}}{c_n}\right|. \end{equation*}
Si $R’$ es el radio de convergencia de $F(z)$, entonces: \begin{align*} R’ & = \lim\limits_{n\to\infty} \left|\frac{b_{n}}{b_{n+1}}\right|\\ & = \lim\limits_{n\to\infty} \left|\dfrac{c_{n-1}}{n} \dfrac{n+1}{c_{n}}\right|\\ & = \lim\limits_{n\to\infty} \left|\dfrac{c_{n-1}}{c_n}\right| \left|\dfrac{n+1}{n}\right|\\ & = \lim\limits_{n\to\infty} \left|\dfrac{c_{n-1}}{c_n}\right| \lim\limits_{n\to\infty} \left|1+\dfrac{1}{n}\right|\\ & = R. \end{align*}
$\blacksquare$
Observación 35.4. Si $f(z)=\displaystyle \sum_{n=0}^\infty c_n (z-z_0)^n$ tiene disco de convergencia $B(z_0, R)$, entonces para cualquier contorno $\gamma$ en $B(z_0, R)$, que une a los puntos $z_1, z_2 \in B(z_0, R)$, se tiene que: \begin{equation*} \int_{\gamma} f(z) dz = \sum_{n=0}^\infty \frac{c_n}{n+1} (z_2-z_0)^{n+1} – \sum_{n=0}^\infty \frac{c_n}{n+1} (z_1-z_0)^{n+1}. \end{equation*}
En particular, para cualquier contorno $\gamma$ en $B(z_0, R)$ que une a $z_0$ con $z\in B(z_0, R)$ se tiene que: \begin{equation*} \int_{\gamma} f(z) dz = \sum_{n=0}^\infty \frac{c_n}{n+1} (z-z_0)^{n+1}. \end{equation*}
Ejemplo 35.9. Evaluemos la integral: \begin{equation*} \int_{C(0,1)} \frac{\operatorname{cos}^2(z)}{z^3} dz. \end{equation*}
Dado que la serie del coseno tiene radio de convergencia infinito, entonces la serie del lado derecho de la igualdad también tiene radio de convergencia infinito, entonces: \begin{align*} \frac{\operatorname{cos}^2(z)}{z^3} & = \frac{1}{z^3} \left( 1 + \sum_{n=1}^\infty \frac{i^{2n} \, 2^{2n-1} \, z^{2n}}{(2n)!}\right)\\ & = z^{-3} -z^{-1} + \sum_{n=2}^\infty \frac{i^{2n} \, 2^{2n-1} \, z^{2n-3}}{(2n)!}\\ & = z^{-3} -z^{-1} + \sum_{k=0}^\infty c_k z^{k}, \end{align*}donde: \begin{equation*} c_k = \left\{ \begin{array}{lc} \dfrac{i^{2n} \, 2^{2n-1}}{(2n)!} & \text{si existe} \,\, n\in\mathbb{N} \,\, \text{tal que} \,\, k=2n-3,\\ \\ 0 & \text{en otro caso.} \end{array} \right. \end{equation*}
Cerraremos esta entrada con un resultado que nos será de mucha utilidad la siguiente entrada al probar el teorema de Cauchy.
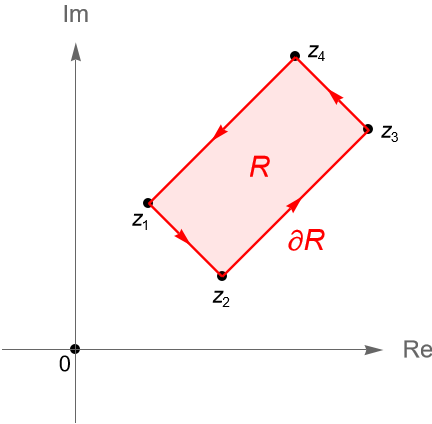
Lema 35.1. (Lema de Goursat.) Sean $U\subset\mathbb{C}$ un conjunto abierto, $R\subset U$ un rectángulo cerrado y $f:U\to\mathbb{C}$ una función analítica en $U$. Entonces: \begin{equation*} \int_{\partial R} f(z) dz = 0. \end{equation*}
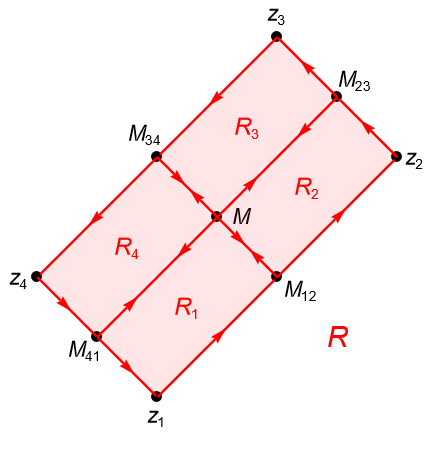
Demostración. Dadas las hipótesis, procedemos a subdividir al rectángulo $R$, con vértices $z_1,z_2,z_3,z_4\in U$, en cuatro subrectángulos congruentes denotados por $R_1, R_2, R_3$ y $R_4$. Si orientamos positivamente a las fronteras de los cuatro subrectángulos, figura 132, por la proposición 34.2(3) tenemos que: \begin{align*} \int_{\partial R_1} f(z) dz & = \int_{z_1}^{M_{12}} f(z) dz + \int_{M_{12}}^{M} f(z) dz + \int_{M}^{M_{41}} f(z) dz + \int_{M_{41}}^{z_1} f(z) dz,\\ \int_{\partial R_2} f(z) dz & =\int_{M_{12}}^{z_2} f(z) dz + \int_{z_2}^{M_{23}} f(z) dz + \int_{M_{23}}^{M} f(z) dz + \int_{M}^{M_{12}} f(z) dz,\\ \int_{\partial R_3} f(z) dz & =\int_{M}^{M_{23}} f(z) dz + \int_{M_{23}}^{z_3} f(z) dz + \int_{z_3}^{M_{34}} f(z) dz + \int_{M_{34}}^{M} f(z) dz,\\ \int_{\partial R_4} f(z) dz & =\int_{M_{41}}^{M} f(z) dz + \int_{M}^{M_{34}} f(z) dz + \int_{M_{34}}^{z_{4}} f(z) dz + \int_{z_{4}}^{M_{41}} f(z) dz. \end{align*}
Figura 132: Rectángulo $R\subset U$ dividido en cuatro subrectángulos congruentes.
De la desigualdad del triángulo se sigue que: \begin{equation*} \left |\int_{\partial R} f(z) dz \right| \leq \left |\int_{\partial R_1} f(z) dz \right| + \left |\int_{\partial R_2} f(z) dz \right| + \left |\int_{\partial R_3} f(z) dz \right| + \left |\int_{\partial R_4} f(z) dz \right|. \end{equation*}
Notemos que si cada término en la suma anterior es tal que: \begin{equation*} \left |\int_{\partial R_j} f(z) dz \right| < \frac{1}{4}\left |\int_{\partial R} f(z) dz \right|, \end{equation*}con $j=1,2,3,4$, entonces obtenemos que: \begin{equation*} \left |\int_{\partial R} f(z) dz \right| = \left |\sum_{j=1}^{4} \int_{\partial R_{i}} f(z) dz \right| \leq \sum_{j=1}^{4} \left | \int_{\partial R_{i}} f(z) dz \right| < \left |\int_{\partial R} f(z) dz \right|, \end{equation*}lo cual es una contradicción. Por lo que, existe $k\in\{1,2,3,4\}$ tal que: \begin{equation*} \left |\int_{\partial R_k} f(z) dz \right| \geq \frac{1}{4}\left |\int_{\partial R} f(z) dz \right|. \end{equation*}
Sin pérdida de generalidad denotemos a dicho rectángulo $R_k$ como $R^{(1)}$, es decir, sea $R^{(1)} := R_k$. En caso de existir más de un rectángulo con la propiedad anterior, basta con tomar a $R^{(1)}$ como el rectángulo $R_j$, $j=1,2,3,4$, tal que: \begin{equation*} \left |\int_{\partial R^{(1)}} f(z) dz \right| = \max\limits_{1\leq j \leq 4} \left |\int_{\partial R_{j}} f(z) dz \right|. \end{equation*}
De manera análoga podemos aplicar la misma subdivisión al rectángulo $R^{(1)}$ para obtener un rectángulo $R^{(2)}$ tal que: \begin{equation*} \left |\int_{\partial R^{(2)}} f(z) dz \right| \geq \frac{1}{4}\left |\int_{\partial R^{(1)}} f(z) dz \right| \geq \frac{1}{4^2}\left |\int_{\partial R} f(z) dz \right|. \end{equation*}
Procediendo de manera inductiva con esta subdivisión, podemos construir la sucesión de rectángulos cerrados anidados $\{R^{(n)}\}_{n\geq 1}$, en $U$, es decir: \begin{equation*} U \supset R \supset R^{(1)} \supset R^{(2)} \supset R^{(3)} \supset \cdots, \end{equation*}tal que: \begin{equation*} \left |\int_{\partial R^{(n)}} f(z) dz \right| \geq \frac{1}{4} \left |\int_{\partial R^{(n-1)}} f(z) dz \right| \geq \cdots \geq \frac{1}{4^n} \left |\int_{\partial R} f(z) dz \right|, \end{equation*}es decir: \begin{equation*} \left |\int_{\partial R} f(z) dz \right| \leq 4^n \left |\int_{\partial R^{(n)}} f(z) dz \right|, \quad \forall n\in\mathbb{N}^+. \tag{35.1} \end{equation*}
Denotamos a $d$ como la longitud de una diagonal del rectángulo $R$ y a $L$ como su perímetro. En consecuencia, para todo $n\in\mathbb{N}^+$, $d_n$ es la longitud de una diagonal del rectángulo $R^{(n)}$ y $L_n$ su perímetro. Entonces, por construcción: \begin{equation*} d_n = \frac{d}{2^{n}} \quad \text{y} \quad L_n = \frac{L}{2^{n}}, \quad \forall n\in\mathbb{N}^{+}. \tag{35.2} \end{equation*}
Como la sucesión $\left\{R^{(n)}\right\}_{n\geq 1}$ de rectángulos anidados, está formada por conjuntos cerrados y acotados en $U$, entonces por el Teorema de Cantor, proposición 10.11, tenemos que existe $z_0 \in \bigcap\limits_{n=1}^\infty R^{(n)}$, por lo que $z_0\in U$.
Dado que $f$ es una función analítica en $U$, en particular es analítica en $z_0$, entonces, por la proposición 18.1 tenemos que: \begin{equation*} f(z) = f(z_0) + f'(z_0)(z-z_0) + \epsilon(z)(z-z_0), \end{equation*}donde la función $\epsilon(z)$ es continua en $z_0$ y $\lim\limits_{z\to z_0} \epsilon(z) = 0$.
Sea $g(z):= f(z_0) + f'(z_0)(z-z_0)$. Es claro que $g$ es una función continua en $U$ con primitiva: \begin{equation*} G(z) = f(z_0)z + \frac{f'(z_0)}{2}(z-z_0)^2, \end{equation*}entonces, como $\partial R^{(n)}$ es un contorno cerrado, de las proposiciones 34.2(3) y 35.1 se sigue que: \begin{align*} \int_{\partial R^{(n)}} f(z) dz & = \int_{\partial R^{(n)}} g(z) dz + \int_{\partial R^{(n)}} \epsilon(z)(z-z_0) dz\\ & = 0 + \int_{\partial R^{(n)}} \epsilon(z)(z-z_0) dz\\ & = \int_{\partial R^{(n)}} \epsilon(z)(z-z_0) dz. \end{align*}
Puesto que $\lim\limits_{z\to z_0} \epsilon(z) = 0$, entonces dado $\varepsilon>0$ existe $\delta>0$ tal que: \begin{equation*} |z-z_0|<\delta \quad \Longrightarrow \quad |\epsilon(z)|<\frac{2}{L^2} \varepsilon. \end{equation*}
Es claro que $\lim\limits_{n\to\infty} d_n = 0$, por lo que podemos fijar un índice $n$ tal que $d_n < \delta$. Además, como $z_0 \in R_n$ y para todo $z\in R_n$ se cumple que $|z-z_0|\leq d_n$, tenemos que $R_n \subset B(z_0\delta)$.
Observación 35.5. El lema de Goursat puede ser modificado para un triángulo cerrado $\triangle$ en $U$, es decir, considerando la frontera $\partial \triangle$ de dicho triángulo, se cumple que: \begin{equation*} \int_{\partial \triangle} f(z) dz = 0. \end{equation*}
Más aún, si $P\subset U$ es un polígono y $\partial P$ su frontera, es claro que se tiene un contorno poligonal, en tal caso se cumple que: \begin{equation*} \int_{\partial P} f(z) dz = 0, \end{equation*}ya que es posible agregar lados internos en $P$ hasta que su interior se subdivida en un número finito de triángulos, entonces con la modificación del lema de Goursat se tiene que la integral alrededor de cada triángulo es cero. Como la suma de las integrales a lo largo de las fronteras de todos estos triángulos es igual a la integral alrededor del contorno poligonal, entonces el resultado se cumple para el contorno poligonal.
En general, siguiendo este camino, se puede probar el resultado para un contorno cerrado simple arbitrario aproximando a dicho contorno lo suficientemente cerca con un contorno poligonal.
Observación 35.6. Podemos mejorar el lema de Goursat permitiendo que la función $f$ no sea analítica en algunos puntos del interior del rectángulo imponiendo una condición adicional.
Lema 35.2. (Lema de Goursat generalizado.) Sean $U\subset\mathbb{C}$ un conjunto abierto, $R\subset U$ un rectángulo cerrado, $z_1, z_2, \ldots z_n \in \operatorname{int} R$, $U’ := U\setminus\{z_1, z_2, \ldots z_n\}$ y $f:U’ \to \mathbb{C}$ una función analítica en $U’$ tal que: \begin{equation*} \lim_{z\to z_j} (z-z_j)f(z)=0, \end{equation*}para todo $j=1,\ldots, n$. Entonces: \begin{equation*} \int_{\partial R} f(z) dz = 0. \end{equation*}
Demostración. Dadas las hipótesis, notemos que es suficiente probar el caso para un único punto $z_0 \in \operatorname{int} R$, ya que por inducción se puede dividir a $R$ en pequeños rectángulos tales que cada uno contenga a lo más un punto interior $z_j$ de $R$, por lo que el caso general se deja como ejercicio al lector.
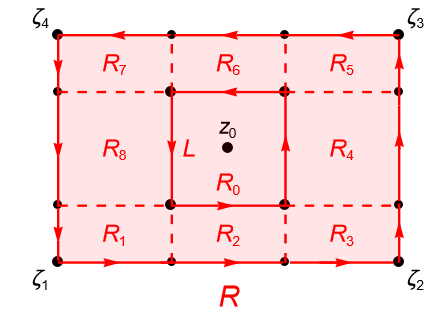
Dividimos a $R$ en nueve subrectángulos de modo que el rectángulo $R_0$ sea un cuadrado de lado $L$ y centro de simetría el punto $z_0 \in \operatorname{int} R$, como se muestra en la figura 133.
Figura 133: Rectángulo $R\subset U$ dividido en nueve subrectángulos, con $R_0$ un cuadrado de lado $L$ y centro en $z_0$.
Dado que $f$ es analítica en $U\setminus\{z_0\}$ y $R_j\subset U\setminus\{z_0\}$ para todo $j=1,\ldots,8$, por el lema de Goursat , para esos ocho rectángulos $R_j$, tenemos que: \begin{equation*} \int_{\partial R_j} f(z) dz = 0, \end{equation*}para todo $j=1,\ldots,8$.
Notemos que si orientamos positivamente a los nueve rectángulos, después de cancelar las integrales a lo largo de los segmentos de recta correspondientes con los lados en común de los rectángulos, como en la prueba del lema anterior, tenemos que: \begin{align*} \int_{\partial R} f(z) dz & = \int_{\partial R_0} f(z) dz + \sum_{j=1}^8 \int_{\partial R_j} f(z) dz\\ & = \int_{\partial R_0} f(z) dz + 0\\ & = \int_{\partial R_0} f(z) dz. \end{align*}
Dado que $\lim\limits_{z\to z_0} (z-z_0) f(z)=0$, para $\varepsilon>0$ tenemos que existe $\delta>0$ tal que si $0<|z-z_0|<\delta$, entonces: \begin{equation*} |f(z)(z-z_0)|<\varepsilon \quad \Longrightarrow \quad |f(z)| < \frac{\varepsilon}{|z-z_0|}. \end{equation*}
Más aún, para todo $z\in \partial R_0$ se cumple que: \begin{equation*} \frac{L}{2} \leq |z-z_0| \leq \frac{\sqrt{2} L}{2} \quad \Longrightarrow \quad \frac{1}{|z-z_0|} \leq \frac{2}{L}. \end{equation*}
Sean $R>0$ y $z_0\in\mathbb{C}$ fijo. Considera el contorno $C$ dado por la circunferencia $C(z_0, R)$ orientada positivamente. a) Evalúa la integral: \begin{equation*} \int_{C} \overline{z-z_0} \ dz. \end{equation*}b) Muestra que la función $f(z)=\overline{z}$ no tiene primitiva en ninguna región del plano complejo.
Considera a la integral: \begin{equation*} \int_{\gamma} \operatorname{Log}(z) dz, \end{equation*}donde $\gamma(t)=e^{it}$, para $t\in[0,\pi]$.
Dado que $\operatorname{Log}(z)$ es discontinua en $-1$, entonces no es continua en $\gamma(\pi)$, por lo que no puede aplicarse la proposición 35.2. a) Muestra que $\operatorname{Log}(z) = \operatorname{Log}_{\left(\frac{-\pi}{2}, \frac{3\pi}{2}\right]}(z)$ para todo $z$ en el contorno $\gamma$. b) Conluye que: \begin{equation*} \int_{\gamma} \operatorname{Log}(z) dz = \int_{\gamma} \operatorname{Log}_{\left(\frac{-\pi}{2}, \frac{3\pi}{2}\right]}(z) dz, \end{equation*}y evalúa la integral del lado derecho utilizando la proposición 35.2.
Determina una primitiva para cada una de las siguientes funciones y específica la región dónde cada una de dichas primitivas están definidas. a) $\dfrac{1}{(z-1)(z+1)}$. b) $\dfrac{\operatorname{Log}(z)}{z}$. c) $ze^{z^2} – \dfrac{1}{z}$. d) $e^z\operatorname{cos}(z)$.
Evalúa cada una de las siguientes integrales. a) \begin{equation*} \displaystyle \int_{C} \left[(z-2-i)^2+\dfrac{i}{z-2-i}-\dfrac{3}{(z-2-i)^2}\right] dz, \end{equation*}donde $C$ es la circunferencia unitaria $C(0,1)$ orientada positivamente. b) $\displaystyle \int_{[z_1, z_2, z_3]} ze^z dz$, donde $z_1=\pi$, $z_2=-1$ y $z_3=-1-i\pi$. c) $\displaystyle \int_{[z_1, z_2, z_3]} \operatorname{Log}(z) dz$, donde $z_1=-i$, $z_2=1$ y $z_3=i$. d) $\displaystyle \int_{\gamma} \dfrac{1}{z} dz$, donde $\gamma$ es un contorno contenido en $\left\{z\in\mathbb{C} : \operatorname{Im}(z) < 0\right\}$ que une a $1-i$ y $-i$.
Sean $D\subset\mathbb{C}$ un dominio, $\gamma:[a,b]\subset\mathbb{R} \to D$, con $a<b$, una curva cerrada y $f:D\to\mathbb{C}$ una función analítica en $D$ con $f'(z)$ continua en $D$. Muestra que: \begin{equation*} I = \int_{\gamma} \overline{f(z)} f'(z) dz, \end{equation*}es un número imaginario puro.
Sea $\triangle$ el triángulo con vértices $0,1$ e $i$. Evalúa las integrales $\displaystyle \int_{\partial \triangle} z dz$ y $\displaystyle \int_{\partial \triangle} \overline{z} dz$, donde $\partial \triangle$ es la frontera de $\triangle$ orientada positivamente.
Modifica la prueba del lema de Goursat para establecer lo siguiente: si $f$ es una función analítica en un conjunto abierto $U\subset\mathbb{C}$, entonces $\displaystyle \int_{\partial \triangle} f(z) dz = 0$, para cualquier triángulo cerrado $\triangle \subset U$.
Más adelante…
En esta entrada hemos probado algunos resultado importantes sobre las integrales de contorno como el Teorema Fundamental del Cálculo para el caso complejo y el lema de Goursat, que como veremos nos permitirá probar el Teorema de Cauchy para el caso en que se tiene un contorno cerrado arbitrario.
En la siguiente entrada probaremos algunas versiones del Teorema integral de Cauchy y abordaremos algunas de sus consecuencias más importantes, como la Fórmula Integral de Cauchy, el Teorema de Liouville, el Teorema Fundamental del Álgebra, entre otros. Además veremos un recíproco del Teorema de Cauchy conocido como el Teorema de Morera.
En la entrada anterior vimos la definición de la integral para funciones complejas de variable real, es decir, funciones híbridas. Aunque de cierta manera esta definición nos limita, ya que en general trabajamos con funciones complejas de variable compleja.
Al igual que sucedió con el concepto de diferenciabilidad para una función compleja de variable compleja, también existe el concepto de integrabilidad para funciones complejas. En esta entrada veremos que aunque muchas de las definiciones y resultados para este tipo de integrales son una extensión de los conceptos de integración para funciones de varias variables reales, vistos en nuestros cursos de Cálculo, la integración en el sentido complejo va más allá de un simple salto de los resultados para funciones reales a la variable compleja, ya que como veremos, a través de la integración compleja es posible obtener herramientas e ideas únicas para el estudio de la teoría de las funciones complejas.
Definición 34.1. (Integral de contorno o integral de línea compleja.) Sean $U\subset\mathbb{C}$ un conjunto abierto, $[a,b]\subset\mathbb{R}$, con $a<b$ un intervalo cerrado, $f: U \to \mathbb{C}$ una función continua en $U$ y $\gamma:[a,b] \to U$ un contorno en $U$ (definición 32.9). Se define a la integral de contorno o integral de línea compleja, a lo largo de $\gamma$, como: \begin{equation*} \int_{\gamma} f(z) dz := \int_{a}^{b} f(\gamma(t)) \gamma'(t)dt.\tag{34.1} \end{equation*}
Si $C$ denota al contorno dado por la trayectoria $\gamma$, entonces la integral en (34.1) se puede escribir como: \begin{equation*} \int_{C} f(z) dz. \end{equation*}
Observación 34.1. Recordemos que un contorno es una trayectoria $\gamma$ de clase $C^1$ o de clase $C^1$ a trozos, por lo que al igual que con las integrales de funciones híbridas, esta definición ya considera el caso en el que $\gamma$ sea una curva suave a trozos. En tal caso, para la partición: \begin{equation*} P : a=t_0 < t_1 < \cdots < t_{n-1}<t_n=b, \end{equation*}del intervalo $[a,b]$, tal que $\gamma_k$, la restricción de $\gamma$ al intervalo $[t_{k-1}, t_k]$, es una curva suave para $1\leq k\leq n$, entonces: \begin{equation*} \int_{\gamma} f(z) dz = \int_{\gamma_1} f(z) dz + \cdots + \int_{\gamma_n} f(z) dz = \sum_{k=1}^n \int_{\gamma_k} f(z) dz. \tag{34.2} \end{equation*}
Observación 34.2. Si $f(z) = u(z)+iv(z)$ y $\gamma(t)=\gamma_1(t)+i\gamma_2(t)$, tenemos que: \begin{align*} f(\gamma(t)) \gamma'(t) & = \left[u(\gamma(t))+iv(\gamma(t))\right]\left[\gamma_1 ‘(t)+i\gamma_2′(t)\right]\\ & = u(\gamma(t)) \gamma_1 ‘(t) – v(\gamma(t)) \gamma_2′(t) + i \left[u(\gamma(t)) \gamma_2 ‘(t) + v(\gamma(t)) \gamma_1′(t)\right], \end{align*}por lo que la función híbrida $g(t)= f(\gamma(t)) \gamma'(t)$ es continua (o continua a trozos) en $[a,b]$, entonces la integral del lado derecho en (34.1) está bien definida.
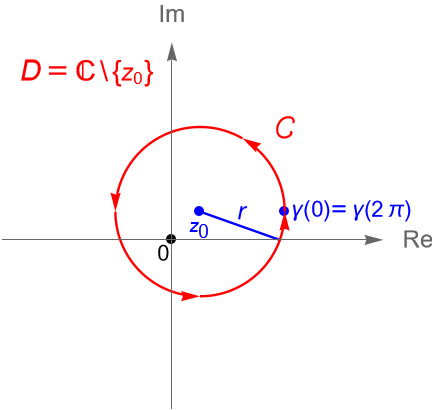
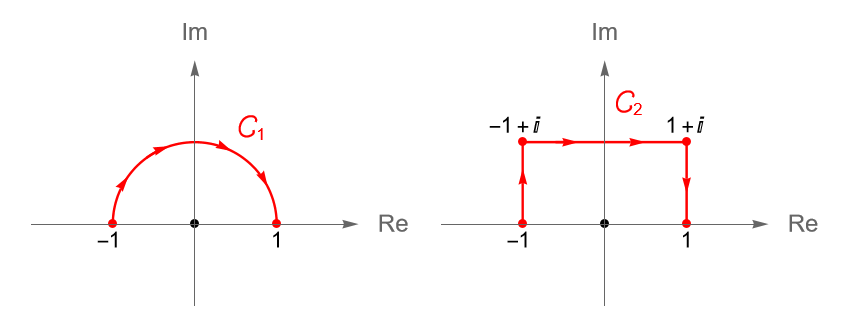
Ejemplo 34.1. Sea $C$ el contorno dado por la circunferencia $C(z_0, r)$, con $r>0$ y $z_0\in\mathbb{C}$ fijo, orientada positivamente.
a) Veamos que: \begin{equation*} \int_{C} \frac{1}{z-z_0} dz = i 2\pi. \end{equation*}
b) Si $n\in\mathbb{Z}$ es tal que $n\neq1$, veamos que: \begin{equation*} \int_{C} \frac{1}{(z-z_0)^n} dz = 0. \end{equation*}
Solución. Primeramente, podemos parametrizar al contorno $C$ mediante la trayectoria $\gamma(t)=z_0 + re^{it}$, con $0\leq t\leq 2\pi$. Por la proposición 32.1(1) y el ejemplo 32.1 tenemos que $\gamma'(t)=ire^{it}$.
Sea $D := \mathbb{C}\setminus\{z_0\}$. Claramente $C$ es un contorno en $D$.
Figura 122: Contorno $C$ dado por la circunferencia $C(z_0, r)$, orientada positivamente, en el dominio $D$.
a) Sea $f(z)=\dfrac{1}{z-z_0}$. Dado que $f$ es una función racional, entonces es analítica en el dominio $D$ y por tanto continua en $D$.
De acuerdo con la definición 34.1, tenemos que: \begin{align*} \int_{C} \frac{1}{z-z_0} dz & = \int_{0}^{2\pi} f(\gamma(t)) \gamma'(t)dt\\ & = \int_{0}^{2\pi} \frac{1}{z_0 +re^{it} – z_0} ire^{it} dt\\ & = \int_{0}^{2\pi} i dt\\ & = i 2\pi. \end{align*}
b) Sean $n\in\mathbb{Z}$ tal que $n\neq1$ y $f(z)=\dfrac{1}{(z-z_0)^n}$. Análogamente tenemos que la función racional $f$ es continua en $D$.
En particular, si $C$ es la circunferencia unitaria, orientada positivamente, es decir, dada por la trayectoria $\gamma(t)=e^{it}$, con $0\leq t\leq 2\pi$, entonces se cumple que: \begin{equation*} \int_{C} \frac{1}{z} dz = \int_{C(0,1)} \frac{1}{z} dz = 2\pi i. \end{equation*}
Ejemplo 34.2. De acuerdo con los ejemplos 32.1, 33.2 y las proposiciones 20.2(2) y 33.1(3), para el contorno $C$ dado por la circunferencia unitaria, orientada positivamente, es decir, $\gamma(t)=e^{it}$, con $0\leq t\leq 2\pi$, tenemos que: \begin{align*} \int_{C(0,1)} z^{n} dz & = \int_{0}^{2\pi} e^{itn} i e^{it} dt\\ & = i \int_{0}^{2\pi} e^{it(n+1)} dt\\ & = \left\{ \begin{array}{lcc} 0 & \text{si} & n \neq -1, \\ \\ i2\pi & \text{si} & n=-1. \end{array} \right. \end{align*}para todo $n\in\mathbb{Z}$.
Solución. Podemos parametrizar a $C$ como la trayectoria $\gamma(t)=e^{it}$, con $0\leq t\leq 2\pi$, por lo que $\gamma'(t)=ie^{it}$.
Por la proposición 20.2(8) tenemos que $\overline{e^{it}} = e^{\overline{it}} = e^{-it}$, entonces, de acuerdo con la definición 34.1, el ejemplo 33.2 y las proposiciones 20.2(2), 20.2(3) y 33.1(3), tenemos que: \begin{align*} \int_{C(0,1)} \frac{1}{\overline{z}} dz & = \int_{0}^{2\pi} \frac{1}{\overline{e^{it}}} i e^{it} dt\\ & = \int_{0}^{2\pi} \frac{1}{e^{-it}} i e^{it} dt\\ & = i \int_{0}^{2\pi} e^{i2t} dt\\ & = i \cdot 0\\ & = 0. \end{align*} \begin{align*} \int_{C(0,1)}\overline{z} dz & = \int_{0}^{2\pi} \overline{e^{it}} i e^{it} dt\\ & = \int_{0}^{2\pi} e^{-it} i e^{it} dt\\ & = i \int_{0}^{2\pi} 1 dt\\ & = i 2\pi. \end{align*}
Ejemplo 34.4. Evaluemos la integral $\int_{\gamma} (x+y) dz$ a lo largo del contorno $\gamma=[0,1+i]+[1+i, i]$.
Solución. De acuerdo con el ejemplo 15.1, es claro que para $z=x+iy\in\mathbb{C}$ la función $f(z)=\operatorname{Re}(z)+\operatorname{Im}(z)$ es una función continua en $\mathbb{C}$. Notemos que el contorno dado por la trayectoria $\gamma$ es una curva suave a trozos. Por el ejemplo 32.2 tenemos que: \begin{equation*} [0,1+i](t) = (1+i)t, \quad [1+i,i](t) = 1+i -t, \quad \forall t\in[0,1]. \end{equation*}
De acuerdo con la definición 32.13, tenemos que: \begin{equation*} \gamma(t) : = \left( [0,1+i] + [1+i,i] \right)(t) = \left\{ \begin{array}{lcc} (1+i)t & \text{si} & 0 \leq t \leq 1, \\ \\ 2-t+i & \text{si} & 1 \leq t \leq 2. \end{array} \right. \end{equation*}
Es claro que las curvas $\gamma_1 = \left. \gamma\right|_{[0,1]}$ y $\gamma_2 = \left. \gamma\right|_{[1,2]}$ son suaves, cuyas derivadas son, respectivamente, $\gamma_1′(t) = 1+i$ y $\gamma_2′(t) = -1$.
Entonces, por (34.2), (34.1) y las proposiciones 33.1 y 33.2, se tiene que: \begin{align*} \int_{\gamma} (x+y) dz & = \int_{\gamma_1} (x+y) dz + \int_{\gamma_2} (x+y) dz\\ & = \int_{0}^{1} 2t(1+i) dt + \int_{1}^{2} (3-t)(-1) dt\\ &= \left.(1+i)t^2\right|_{0}^{1} – \left.\left[3t – \frac{t^2}{2}\right]\right|_{1}^{2}\\ & = -\frac{1}{2} + i. \end{align*}
Si definimos a los campos vectoriales, en el plano, $F, G: U\subset\mathbb{R}^2 \to \mathbb{R}^2$ dados, respectivamente, por: \begin{equation*} F(x,y)=(u(x,y), -v(x,y)) \quad \text{y} \quad G(x,y)=(v(x,y), u(x,y)), \end{equation*}entonces: \begin{align*} \int_{\gamma} f(z) dz & = \int_{a}^{b} F(\gamma(t)) \cdot \gamma'(t) dt + i \int_{a}^{b} G(\gamma(t)) \cdot \gamma'(t) dt\\ & = \int_\Gamma F \cdot d\gamma + i \int_\Gamma G \cdot d\gamma, \end{align*}donde $\Gamma=\gamma([a,b])$. Es decir, la interal que definimos en 34.1 se puede expresar en términos de la integral de línea de dos campos vectoriales en $\mathbb{R}^2$.
En este punto es conveniente recordar el siguiente resultado de Cálculo.
Teorema 34.1. (Cambio de variable.) Sean $[a,b], [c,d]\subset\mathbb{R}$, con $a<b$ y $c<d$, dos intervalos cerrados, $f: [a,b] \to \mathbb{R}$ y $g: [c,d] \to \mathbb{R}$ dos funciones tales que $g([c,d])\subseteq [a,b]$, $f$ es continua en $[a,b]$ y $g$ de clase $C^1$ en $[c,d]$, entonces: \begin{equation*} \int_{c}^{d} f(g(t)) g'(t) dt = \int_{g(c)}^{g(d)} f(t)dt. \end{equation*}
Una consecuencia del resultado anterior es la siguiente:
Proposición 34.1. (Independencia de la parametrización.) Sean $U\subset\mathbb{C}$ un conjunto abierto, $[a,b], [c,d]\subset\mathbb{R}$, con $a<b$ y $c<d$, dos intervalos cerrados, $f: U \to \mathbb{C}$ una función continua en $U$ y $\gamma_1:[a,b] \to U$ un contorno en $U$. Si $\gamma_2:[c,d] \to U$ es una reparametrización de $\gamma_1$, entonces: \begin{equation*} \int_{\gamma_1} f(z) dz = \int_{\gamma_2} f(z) dz. \end{equation*}
Demostración. Dadas las hipótesis, tenemos que existe una biyección $\sigma:[c,d]\to[a,b]$ continua de clase $C^1$ tal que $\sigma$ es creciente y $\gamma_2=\gamma_1\circ \sigma$.
Entonces, de acuerdo con la observación 34.2, la definición 34.1, el teorema 34.1 y la regla de la cadena, para $s=\sigma(t)$ tenemos que: \begin{align*} \int_{\gamma_2} f(z) dz & = \int_{c}^{d} f(\gamma_2(t)) \gamma_2′(t)dt\\ & = \int_{c}^{d} f(\gamma_1(\sigma(t))) \gamma_1′(\sigma(t)) \sigma'(t)dt\\ & = \int_{\sigma(c)}^{\sigma(d)} f(\gamma_1(s)) \gamma_1′(s) ds\\ & = \int_{a}^{b} f(\gamma_1(s)) \gamma_1′(s) ds\\ & = \int_{\gamma_1} f(z) dz. \end{align*}
$\blacksquare$
Ejemplo 34.5. Determinemos el valor de la integral: \begin{equation*} \int_{C} \frac{dz}{z-2}, \end{equation*}donde $C$ es la semicircunferencia superior de radio $r=1$ y centro en $z_0=2$.
Solución. Es claro que $C$ es un contorno ya que la trayectoria $\gamma(t)=2+e^{i\pi}$, con $0\leq t\leq \pi$, que lo parametriza, es una curva suave.
De acuerdo con el ejemplo 34.1, inferimos que el valor de dicha integral es $i\pi$. Procedemos a verificar lo anterior utilizando la proposición 34.1, es decir, considerando otra parametrización para el contorno $C$.
De acuerdo con el ejemplo 32.13(b), sabemos que $\beta(t)=2+e^{i\pi t}$, con $0\leq t \leq 1$, es una reparametrización de la curva $\gamma$.
Al igual que con las integrales de funciones híbridas, las integrales de contorno cumplen algunas propiedades que resultan de utilidad al resolver ciertos problemas.
Proposición 34.2. (Propiedades integrales de contorno.) Sean $U\subset\mathbb{C}$ un conjunto abierto, $[a,b]\subset\mathbb{R}$, con $a<b$ un intervalo cerrado, $f, g: U \to \mathbb{C}$ dos funciones continuas en $U$ y $\gamma:[a,b] \to U$ un contorno en $U$. Se cumplen las siguientes propiedades.
Si $\lambda, \mu \in\mathbb{C}$ son dos constantes, entonces: \begin{equation*} \int_{\gamma} \left[\lambda f(z) + \beta g(z)\right] dz = \lambda \int_{\gamma} f(z) dz + \beta \int_{\gamma} g(z) dz. \end{equation*}
Si el contorno $\gamma$ es tal que $\gamma = \gamma_1 + \gamma_2$, entonces: \begin{equation*} \int_{\gamma} f(z) dz = \int_{\gamma_1} f(z) dz + \int_{\gamma_2} f(z) dz. \end{equation*}En general, si $\gamma = \gamma_1 + \cdots + \gamma_n$, entonces: \begin{equation*} \int_{\gamma} f(z) dz = \int_{\gamma_1} f(z) dz + \cdots + \int_{\gamma_n} f(z) dz = \sum_{k=1}^n \int_{\gamma_k} f(z) dz. \end{equation*}
Demostración. Dadas las hipótesis.
Se deja como ejercicio al lector.
De acuerdo con la definición 32.12 sabemos que $-\gamma(t) = \gamma(b+a-t)$ para toda $t\in[a,b]$, entonces, para $s=b+a-t$, por la observación 34.2, la definición 34.1, el teorema 34.1, la regla de la cadena y la proposición 33.1(7), tenemos que: \begin{align*} \int_{-\gamma} f(z) dz & = \int_{a}^{b} f(-\gamma(t)) \left[-\gamma(t)\right]’dt\\ & = \int_{a}^{b} f(\gamma(a+b-t)) \left[-\gamma'(a+b-t)\right]dt\\ & = \int_{b}^{a} f(\gamma(s)) \gamma'(s)ds\\ & = -\int_{a}^{b} f(\gamma(s)) \gamma'(s)ds\\ & = – \int_{\gamma} f(z) dz. \end{align*}
Supongamos que existen $\gamma_1:[a_1, b_1] \to U$ y $\gamma_2:[a_2, b_2] \to U$ tales que $a=a_1$, $b=b_1+b_2-a_2$ y $\gamma_1(b_1)=\gamma_2(a_2)$, es decir, $\gamma=\gamma_1+\gamma_2$, entonces, por las definiciones 32.13, 34.1, la observación 34.2, la proposición 33.1(4) y el teorema 34.1, para $s=t-b_1+a_2$ tenemos que: \begin{align*} \int_{\gamma} f(z) dz & = \int_{\gamma_1+\gamma_2} f(z) dz\\ & = \int_{a}^{b_1+b_2-a_2} f\left[\left(\gamma_1+\gamma_2\right)(t)\right] \left(\gamma_1+\gamma_2\right)'(t)dt\\ & = \int_{a}^{b_1} f(\gamma_1(t)) \gamma_1′(t)dt + \int_{b_1}^{b_1+b_2-a_2} f(\gamma_2(t-b_1+a_2)) \gamma_2′(t-b_1+a_2)dt\\ & = \int_{a}^{b_1} f(\gamma_1(t)) \gamma_1′(t)dt + \int_{a_2}^{b_2} f(\gamma_2(s)) \gamma_2′(s)ds\\ & = \int_{\gamma_1} f(z) dz + \int_{\gamma_2} f(z) dz. \end{align*}El caso general se deja como ejercicio al lector.
$\blacksquare$
Observación 34.4. Notemos que si $\gamma:[0,1] \to \mathbb{C}$ está dada por $\gamma(t)=it$ y $f(z)=1$, tenemos que: \begin{align*} \int_{\gamma} f(z) dz & = \int_{0}^{1} f(\gamma(t)) \gamma'(t)dt\\ & = \int_{0}^{1} 1 \cdot i \, dt\\ & = i. \end{align*}
De donde se sigue que $\operatorname{Re}\left(\displaystyle \int_{\gamma} f(z) dz \right) = 0$.
Sin embargo, tenemos que $\operatorname{Re} f(z) = 1$, por lo que: \begin{equation*} \int_{\gamma} \operatorname{Re} f(z) dz = i. \end{equation*}
Entonces, a diferencia de las integrales de funciones híbridas, para las integrales de contorno, en general tenemos que: \begin{equation*} \operatorname{Re}\left(\displaystyle \int_{\gamma} f(z) dz \right) \neq \int_{\gamma} \operatorname{Re} f(z) dz. \end{equation*}
Ejemplo 34.6. Verifiquemos el resultado del ejemplo 34.4 utilizando la proposición 34.2(3).
Solución. Para todo $t\in [0,1]$ se cumple que: \begin{align*} [0,1+i](t) & = (1+i)t, \quad [0,1+i]'(t) = 1+i,\\ [1+i,i](t) & = 1+i -t, \quad [1+i,i]'(t) = -1. \end{align*}
Entonces, de acuerdo con la definición 34.1 y las proposiciones 33.2 y 34.2(3), tenemos que: \begin{align*} \int_{\gamma} (x+y) dz & = \int_{[0,1+i]} (x+y) dz + \int_{[1+i,i]} (x+y) dz\\ & = \int_{0}^{1} 2t(1+i) dt + \int_{0}^{1} (2-t)(-1) dt\\ &= \left.(1+i)t^2\right|_{0}^{1} + \left.\left[\frac{t^2}{2} – 2t\right]\right|_{0}^{1}\\ & = -\frac{1}{2} + i. \end{align*}
Observación 34.5. Aunque puede suceder que la integral de contorno de una función compleja a lo largo de dos curvas distintas sea la misma, esto en general no es cierto.
Ejemplo 34.7. Veamos que: \begin{equation*} \int_{C_1} z dz = \int_{C_2} z dz, \end{equation*}donde $C_1$ es el contorno dado por el segmento de recta que une a $z_1 = -1-i$ con $z_2 = 3+i$ y $C_2$ es el contorno que va de $z_1$ a $z_2$ a través del pedazo de la parábola $x=y^2+2y$, figura 123.
Figura 123: Contornos $C_1$ y $C_2$ del ejemplo 34.7.
Solución. De acuerdo con el ejemplo 32.2, podemos parametrizar al contorno $C_1$ mediante la trayectoria $\gamma_1:[0,1]\to\mathbb{C}$ dada por: \begin{equation*} \gamma_1(t) = -1-i+[3+i-(-1-i)]t = -1-i+(4+2i)t, \quad \forall t\in[0,1]. \end{equation*}
Por otra parte, podemos parametrizar al contorno $C_2$ como $\gamma_2(t)=x_2(t)+iy_2(t)$, donde: \begin{equation*} x_2(t)=t^2+2t, \quad y_2(t)=t. \end{equation*}
Tenemos que $ t\in\mathbb{R}$, por lo que si $\gamma_2(t)=-1-i$, entonces: \begin{equation*} t^2+t(2+i)+1+i = (t+1)(t+1+i)=0 \quad \Longrightarrow \quad t=-1. \end{equation*}
Por lo tanto $\gamma_2 : [-1,1]\to \mathbb{C}$, dada por $\gamma_2(t)=t^2+2t+it$, es una parametrización de $C_2$.
De acuerdo con la definición 34.1 y las proposiciones 33.1 y 33.2, tenemos que: \begin{align*} \int_{C_1} z dz & = \int_{0}^{1} \left[-1-i+(4+2i)t\right](4+2i) dt\\ & = (-1-i)(4+2i) \int_{0}^{1} dt + (4+2i)^2 \int_{0}^{1} t dt\\ & = (-2-6i) \left. t\right|_{0}^{1} + 4(3+4i) \left. \frac{t^2}{2}\right|_{0}^{1}\\ & = -2-6i + 6+8i\\ & = 4+2i. \end{align*} \begin{align*} \int_{C_2} z dz & = \int_{-1}^{1} \left[t^2+2t+it\right](2t+2+i)dt\\ & = \int_{-1}^{1} \left[2t^3+6t^2+3t+i(3t^2+4t)\right]dt\\ & = \int_{-1}^{1} \left(2t^3+6t^2+3t\right)dt + +i\int_{-1}^{1}\left(3t^2+4t\right) dt\\ & = \left. \left(\frac{t^4}{2}+2t^3+\frac{3t^2}{2}\right)\right|_{-1}^{1} + \left. i\left(t^3+2t^2\right)\right|_{-1}^{1}\\ & = 4+2i. \end{align*}
Ejemplo 34.8. Veamos que: \begin{equation*} \int_{C_1} \overline{z} dz = -\pi i \quad \text{y} \quad \int_{C_2} \overline{z} dz = -4i, \end{equation*}donde $C_1$ es el contorno que va de $-1$ a $1$ a través de la semicircunferencia unitaria superior y $C_2$ es el contorno que va de $-1$ a $1$ a través de la poligonal $[z_1, z_2, z_3, z_4]$, donde $z_1 = -1, z_2 = -1+i, z_3=1+i$ y $z_4 = 1$, ambos orientados negativamente, figura 124.
Solución. Considerando la definición 32.12, podemos parametrizar a $C_1$ mediante la curva opuesta de la semicircunferencia unitaria superior, orientada positivamente, es decir, $\beta(t)=e^{it}$, con $0\leq t \leq \pi$. Entonces, una parametrización del contorno $C_1$ está dada por la trayectoria $\gamma_1:[0,\pi]\to\mathbb{C}$ dada por: \begin{equation*} \gamma_1(t):= -\beta(t) = \beta(\pi + 0 – t) = \beta(\pi-t) = e^{i(\pi-t)} = -e^{-it}, \quad \forall t\in[0,\pi]. \end{equation*}
Considerando lo anterior, del ejemplo 32.1 se sigue que: \begin{equation*} \gamma_1′(t) = \frac{d}{dt} \left(-e^{-it}\right) = -(-i)e^{-it} = ie^{-it}. \end{equation*}
Por otra parte, de acuerdo con la definición 32.13 y la observación 32.15, podemos parametrizar al contorno $C_2$, descrito por la poligonal $[z_1, z_2, z_3, z_4]$, donde $z_1 = -1, z_2 = -1+i, z_3=1+i$ y $z_4 = 1$, a través de la trayectoria $\gamma_2=[z_1, z_2] + [z_2, z_3] + [z_3, z_4]$. De acuerdo con el ejemplo 32.2 tenemos que: \begin{align*} [z_1, z_2](t) & = -1 + [-1+i-(-1)]t = -1+it,\\ [z_2, z_3](t) & = -1+i + [1+i-(-1+i)]t = -1+2t+i,\\ [z_3, z_4](t) & = 1+i + [1-(1+i)]t = 1+i(1-t), \end{align*}donde $t\in[0,1]$ para los tres segmentos de recta. Entonces: \begin{align*} [z_1, z_2]'(t) & = \frac{d}{dt} \left(-1+it\right) = i,\\ [z_2, z_3]'(t) & = \frac{d}{dt} \left(-1+2t+i\right) = 2,\\ [z_3, z_4]'(t) & = \frac{d}{dt} \left(1+i(1-t)\right) = -i. \end{align*}
Utilizando la definición 32.13 es fácil obtener de manera explícita la regla de correspondencia de $\gamma_2$, sin embargo, podemos utilizar la proposición 34.2(3) y simplificar las cuentas.
Figura 124: Contornos $C_1$ y $C_2$ del ejemplo 34.8.
Por lo tanto, de la definición 34.1 y las proposiciones 20.2 y 33.1, tenemos que: \begin{align*} \int_{C_1} \overline{z} dz & = \int_{0}^{\pi} \overline{-e^{-it}}(ie^{-it}) dt\\ & = -i\int_{0}^{\pi}e^{it}e^{-it} dt\\ & = -i\int_{0}^{\pi} e^{0} dt\\ & = -i \pi. \end{align*}
Mientras que de la definición 34.1 y las proposiciones 34.2(3), 33.1 y 33.2, se sigue que: \begin{align*} \int_{C_2} \overline{z} dz & = \int_{ [z_1, z_2]} \overline{z} dz + \int_{ [z_2, z_3]} \overline{z} dz + \int_{ [z_3, z_4]} \overline{z} dz\\ & = \int_{0}^{1} \left(\overline{-1+it}\right) i dt + \int_{0}^{1} \left(\overline{-1+2t+i}\right) 2 dt + \int_{0}^{1} \left[\overline{1+i(1-t)}\right](-i) dt\\ & = i\int_{0}^{1} \left(-1-it\right) dt + 2 \int_{0}^{1} \left(-1+2t-i\right) dt -i \int_{0}^{1} \left[1-i(1-t)\right] dt\\ & = \left.i\left(-t-i\frac{t^2}{2}\right)\right|_{0}^{1} + \left. 2 \left(-t+t^2-it\right)\right|_{0}^{1} – \left. i \left[t+i\frac{(1-t)^2}{2}\right]\right|_{0}^{1}\\ & = i\left(-1-\frac{i}{2}\right) – 2i – i \left(1-\frac{i}{2}\right)\\ & = -4i. \end{align*}
Definición 34.2. (Integral con respecto de la longitud de arco.) Sean $U\subset\mathbb{C}$ un conjunto abierto, $[a,b]\subset\mathbb{R}$, con $a<b$ un intervalo cerrado, $f: U \to \mathbb{C}$ una función continua en $U$ y $\gamma:[a,b] \to U$ un contorno en $U$. Se define a la integral de $f$ {\bf con respecto de la longitud de arco $|dz|$}, a lo largo de $\gamma$, como: \begin{equation*} \int_{\gamma} f(z) |dz| := \int_{a}^{b} f(\gamma(t)) \left|\gamma'(t)\right| dt.\tag{34.3} \end{equation*}
Si el contorno está dado por una trayectoria $\gamma$ suave a trozos, para la partición: \begin{equation*} P : a=t_0 < t_1 < \cdots < t_{n-1}<t_n=b, \end{equation*}del intervalo $[a,b]$, tal que $\gamma_k$, la restricción de $\gamma$ al intervalo $[t_{k-1}, t_k]$, es una curva suave para $1\leq k\leq n$, se cumple que: \begin{equation*} \int_{\gamma} f(z) |dz| = \int_{\gamma_1} f(z) |dz| + \cdots + \int_{\gamma_n} f(z) |dz| = \sum_{k=1}^n \int_{\gamma_k} f(z) |dz|. \tag{34.4} \end{equation*}
Observación 34.6. Notemos que si $f(z)=1$, entonces de (34.3) obtenemos: \begin{equation*} \int_{\gamma}|dz| = \int_{a}^{b} \left|\gamma'(t)\right| dt, \end{equation*}la cual corresponde con la longitud de arco de una curva en $\mathbb{C}$, definición 32.15.
El siguiente resultado justifica la definición anterior. Lema 34.1. Si $\gamma$ es una curva suave a trozos, es decir, un contorno en $\mathbb{C}$, entonces $\gamma$ es rectificable (definición 32.16) y la longitud de arco de dicha curva es: \begin{equation*} \ell(\gamma)=\int_{\gamma}|dz|. \end{equation*}
Se puede consultar una prueba detallada de este resultado en:
An Introduction to Complex Function Theory, Bruce P. Palka.
Function of One Complex Variable, John B. Conway.
Teoría de funciones de una variable compleja, Felipe Zaldívar.
Ejemplo 34.9. Evaluemos las siguientes integrales. a) $\displaystyle \int_{\gamma} z^{-2} |dz|$, donde la trayectoria $\gamma$ describe a la circunferencia $C(0,2)$ orientada positivamente, es decir, $\gamma(t)=2e^{it}$, con $0\leq t\leq 2\pi$. b) $\displaystyle \int_{\gamma} x |dz|$, donde $\gamma(t)=t+i\left(\dfrac{t^2}{2}\right)$, con $0\leq t\leq 1$, figura 125.
Figura 125: Contorno $\gamma(t)=t+i\left(\dfrac{t^2}{2}\right)$, con $0\leq t\leq 1$.
Solución.
a) Es claro que $\gamma$ es un contorno y $\gamma'(t)=i2e^{it}$. Más aún, sabemos que la función $f(z)=z^{-2}$ es analítica en el dominio $D=\mathbb{C}\setminus\{0\}$, por lo que es continua en $D$ y el contorno descrito por $\gamma$ está completamente contenido en $D$. Entonces, por la definción 34.2, las proposiciones 20.2(6), 20.2(7), 33.1(3) y el ejemplo 33.2, tenemos que: \begin{align*} \int_{\gamma} z^{-2} |dz| & = \int_{0}^{2\pi} \left(2e^{it}\right)^{-2}\left|i2e^{it}\right| dt\\ & = \frac{1}{2} \int_{0}^{2\pi}e^{-i2t} dt\\ & = \frac{1}{2}(0)\\ & = 0. \end{align*}
b) Es claro que $\gamma$ es un contorno, con $\gamma'(t)=1+it$. Por otra parte, por el ejemplo 15.1(a) sabemos que la función $f(z)=\operatorname{Re}(z)=x$, para $z=x+iy\in\mathbb{C}$, es continua en todo $\mathbb{C}$. Entonces, por la definción 34.2 tenemos que: \begin{align*} \int_{\gamma} x |dz| & = \int_{0}^{1} t\left|1+t^2\right| dt\\ & = \frac{1}{2} \int_{0}^{1}2t\sqrt{1+t^2}dt\\ & = \frac{1}{2} \left.\left[ \frac{2\left(1+t^2\right)^{3/2}}{3}\right]\right|_{0}^{1}\\ & = \frac{2\sqrt{2}-1}{3}. \end{align*}
Proposición 34.3. (Propiedades integrales con respecto de la longitud de arco.) Sean $U\subset\mathbb{C}$ un conjunto abierto, $[a,b]\subset\mathbb{R}$, con $a<b$ un intervalo cerrado, $f, g: U \to \mathbb{C}$ dos funciones continuas en $U$ y $\gamma:[a,b] \to U$ un contorno en $U$. Se cumplen las siguientes propiedades.
Si $\lambda, \mu \in\mathbb{C}$ son dos constantes, entonces: \begin{equation*} \int_{\gamma} \left[\lambda f(z) + \beta g(z)\right] |dz| = \lambda \int_{\gamma} f(z) |dz| + \beta \int_{\gamma} g(z) |dz|. \end{equation*}
Si el contorno $\gamma$ es tal que $\gamma = \gamma_1 + \gamma_2$, entonces: \begin{equation*} \int_{\gamma} f(z) |dz| = \int_{\gamma_1} f(z) |dz| + \int_{\gamma_2} f(z) |dz|. \end{equation*}En general, si $\gamma = \gamma_1 + \cdots + \gamma_n$, entonces: \begin{equation*} \int_{\gamma} f(z) |dz| = \int_{\gamma_1} f(z) |dz| + \cdots + \int_{\gamma_n} f(z) |dz| = \sum_{k=1}^n \int_{\gamma_k} f(z) |dz|. \end{equation*}
Si $\beta$ es una reparametrización de $\gamma$, entonces: \begin{equation*} \int_{\beta} f(z) |dz| = \int_{\gamma} f(z) |dz|. \end{equation*}
\begin{equation*} \left|\int_{\gamma} f(z) dz \right| \leq \int_{\gamma} |f(z)| |dz|. \end{equation*}En particular, si $M$ es una constante tal que $|f(z)|\leq M$ y $L=\ell\left(\gamma\right)$, entonces: \begin{equation*} \left|\int_{\gamma} f(z) dz\right| \leq ML. \end{equation*}
Demostración. Dadas las hipótesis.
Se deja como ejercicio al lector.
Se deja como ejercicio al lector.
Se deja como ejercicio al lector.
Se deja como ejercicio al lector.
De acuerdo con la definición 34.1 y la proposición 33.1(5) tenemos que: \begin{align*} \left|\int_{\gamma} f(z) dz \right| & = \left| \int_{a}^{b} f(\gamma(t)) \gamma'(t) dt\right|\\ & \leq \int_{a}^{b} \left| f(\gamma(t))\gamma'(t)\right| dt\\ & = \int_{a}^{b} \left| f(\gamma(t))\right| \, \left|\gamma'(t)\right| dt\\ & = \int_{\gamma} |f(z)| |dz|. \end{align*}Si $M=\max\limits_{z\in\gamma}|f(z)|$ y $L=\ell\left(\gamma\right)$, entonces $|f(z)| \leq M$, por lo que de la monotonía de la integral para funciones reales se sigue que: \begin{equation*} \left|\int_{\gamma} f(z) dz \right| \leq \int_{\gamma} |f(z)| |dz| \leq \int_{a}^{b} M |\gamma'(t)| dt = ML. \end{equation*}
$\blacksquare$
Observación 34.7. Muchas veces, en la teoría y en la práctica, no es necesario evaluar una integral de contorno, sino que simplemente basta con obtener una cota superior de su módulo, por ello la propiedad dada en la proposición 34.3(5) es de mucha utilidad.
Ejemplo 34.10. Determinemos una cota superior para: \begin{equation*} \left|\int_{\gamma} \frac{e^{z}}{z^2+1} dz \right|, \end{equation*}donde $\gamma$ describe a la circunferencia $C(0,2)$ en sentido positivo.
Solución. Tenemos que una parametrización del contorno $C(0,2)$ es $\gamma(t)=2e^{it}$, para $0\leq t \leq 2\pi$. Sabemos que $\gamma'(2)=i2e^{it}$, entonces, de la proposición 20.2(6) y la definción 32.15 se sigue que: \begin{equation*} L := \ell(\gamma) = \int_{0}^{2\pi}|\gamma'(t)| dt = \int_{0}^{2\pi}|i2e^{it}| dt = \int_{0}^{2\pi} 2 dt = 4\pi. \end{equation*}
Por el corolario 16.1(2) es claro que la función racional: \begin{equation*} f(z) = \frac{e^{z}}{z^2+1}, \end{equation*}es analítica en $D=\mathbb{C}\setminus\{-i, i\}$ y por tanto continua en $D$. Además el contorno $C(0,2)$ está completamente contenido en $D$.
Por la proposición 20.2(4), para $z=x+iy\in\mathbb{C}$ sabemos que $|e^z| = e^x$ y de la observación 3.1 tenemos que $x = \operatorname{Re}(z)\leq |z|$, entonces, corolario 31.1(1), $|e^z| \leq e^{|z|}$.
De lo anterior, para $z=\gamma(t)$ tenemos que: \begin{equation*} \left|e^{2e^{it}}\right| \leq e^{|2e^{it}|} = e^{2}, \end{equation*}y considerando la desigualdad del triángulo, proposición 3.3, tenemos que: \begin{equation*} \left|z^2+1\right| = \left|\left(2e^{it}\right)^2+1\right| = \left|4e^{i2t}+1\right| \geq \left|4e^{i2t}\right| – \left|1\right| = 4-1=3. \end{equation*}
Entonces, para $z=\gamma(t)$, es decir, para $|z|=2$, se cumple que: \begin{equation*} \left|f(z)\right| = \left|\frac{e^{z}}{z^2+1}\right| \leq \frac{e^2}{3} =: M. \end{equation*}
Por lo tanto, por la proposición 34.3(5) tenemos que: \begin{equation*} \left|\int_{\gamma} \frac{e^{z}}{z^2+1} dz \right| \leq M L = \frac{4\pi e^2}{3}. \end{equation*}
Solución. Sabemos que la función $f(z)=e^{iz^2}$ es entera y por tanto continua en $\mathbb{C}$. Por otra parte, es claro que el arco de circunferencia $C(0,r)$ descrito por $\gamma(t) = re^{it}$, $0\leq t \leq \dfrac{\pi}{4}$, es un contorno en $\mathbb{C}$ y $\gamma'(t)=ire^{it}$. Entonces, por la proposición 20.2(6), es claro que: \begin{equation*} \left|\gamma'(t)\right| = \left|ire^{it}\right| = r. \end{equation*}
Si $z=x+iy\in\mathbb{C}$, entonces $iz^2= i(x^2-y^2) – 2xy$, por lo que, de acuerdo con la proposición 20.2(4), tenemos que: \begin{equation*} \left|f(z)\right| = \left|e^{iz^2}\right| = e^{\operatorname{Re}\left(iz^2\right)} = e^{-2xy}. \end{equation*}
De la proposición 20.2(5) se sigue que $\gamma(t)=re^{it} = r\operatorname{cos}(t)+ir\operatorname{cos}(t)$, entonces: \begin{equation*} \left|f\left(\gamma(t)\right)\right| = e^{-2r^2\operatorname{cos}(t)\operatorname{sen}(t)} = e^{-r^2\operatorname{sen}(2t)}. \end{equation*}
Entonces, por la proposición 34.3(5) tenemos que: \begin{equation*} \left|\int_{\gamma} e^{iz^2} dz \right| \leq \int_{\gamma} \left|e^{iz^2}\right| \, |dz| \leq \frac{\pi(1-e^{-r^2})}{4r}. \end{equation*}
Observación 34.8. En este punto es importante hacer un comentario sobre la notación para integrales de contorno a lo largo de segmentos de recta. Si $f$ es una función compleja continua en el segmento de recta que une a los puntos $z_1, z_2\in\mathbb{C}$, con $z_1\neq z_2$, es decir, $f$ es continua en $[z_1, z_2]$, entonces denotamos lo anterior como: \begin{equation*} \int_{[z_1, z_2]} f(z) dz := \int_{z_1}^{z_2} f(z) dz. \end{equation*} \begin{equation*} \int_{[z_1, z_2]} f(z) |dz| := \int_{z_1}^{z_2} f(z) |dz|. \end{equation*}
Así por ejemplo, como $[z_2, z_1](t) = -[z_1, z_2](t)$, de la proposición 34.2(2) se sigue que: \begin{equation*} \int_{z_2}^{z_1} f(z) dz = – \int_{z_1}^{z_2} f(z) dz. \end{equation*}
Además, como $[z_1, z_1]$ corresponde con un contorno constante, entonces: \begin{equation*} \int_{z_1}^{z_1} f(z) dz = 0. \end{equation*}
Considerando lo anterior, si $z_3$ es un tercer punto en el segmento $[z_1, z_2]$, distinto de $z_1$ y de $z_2$, entonces: \begin{equation*} \int_{z_1}^{z_2} f(z) dz = \int_{z_1}^{z_3} f(z) dz + \int_{z_3}^{z_2} f(z) dz. \end{equation*}
Debe ser claro que lo anterior no es una consecuencia directa de la proposición 34.2(3), ya que si consideramos la definición 32.13, no es difícil verificar que el contorno dado por $[z_1, z_3] + [z_3, z_2]$ no es igual al contorno dado por $[z_1, z_2]$.
Ejemplo 34.12. Si $R\subset\mathbb{C}$ es un rectángulo en el plano complejo con vértices $z_1, z_2, z_3, z_4\in\mathbb{C}$, entonces el contorno poligonal dado por $\gamma = [z_1, z_2] + [z_2, z_3] + [z_3, z_4] + [z_4, z_1]$ parametriza a la frontera $\partial R$ de dicho rectángulo, en sentido positivo relativo a $R$, figura 126. Considerando la notación dada en la observación 34.6, la integral de contorno de una función $f$ continua a lo largo de $\gamma$ está dada por: \begin{equation*} \int_{\delta R} f(z) dz = \int_{z_1}^{z_2} f(z) dz + \int_{z_2}^{z_3} f(z) dz + \int_{z_3}^{z_4} f(z) dz + \int_{z_4}^{z_1} f(z) dz. \end{equation*}
Figura 126: Rectángulo $R$ en el plano complejo $\mathbb{C}$ y su frontera $\partial R$.
Tarea moral
Completa las demostraciones de las proposiciones 34.2 y 34.3.
Evalúa las siguientes integrales. a) $\displaystyle \int_{\gamma} (2xy-ix^2) dz$, donde $\gamma(t)=t+it^2$, con $0\leq t\leq 1$. b) $\displaystyle \int_{\gamma} \dfrac{z^2-1}{z(z^2+4)} dz$, donde $\gamma(t)=e^{it}$, con $0\leq t\leq 2\pi$. Hint: Utiliza fracciones parciales. c) $\displaystyle \int_{C} z^2 |dz|$, donde $C=C(i,2)$, orientada positivamente. d) $\displaystyle \int_{\gamma} z |dz|$, donde $C\gamma=[e, 1] + [1, -1+i\sqrt{3}]$.
Sea $C$ el contorno dado por el segmento de recta que va de $1$ a $i$. Determina una cota superior para: \begin{equation*} \left|\int_{C} \operatorname{cos}^2(z) dz\right|. \end{equation*}
Sea $f:C(0,1) \to \mathbb{C}$ una función continua tal que $|f(z)|\leq M$ para todo $z\in C(0,1)$, con $M>0$. Prueba que si: \begin{equation*} \left|\int_{C(0,1)} f(z) dz\right| = 2\pi M, \end{equation*} entonces $f(z)=c\overline{z}$, donde $c\in\mathbb{C}$ es una constante tal que $|c|=M$. Hint: Considera el ejercicio 4 de la entrada 33.
Si $\gamma(t)=e^{1+it}$, con $0\leq t \leq \pi$, muestra que: \begin{equation*} \left|\int_{\gamma} \left[\operatorname{Log}(z)\right]^{-1} dz\right| \leq e \operatorname{Log}(\pi+\sqrt{\pi^2+1}). \end{equation*}
Sean $P(z)$ y $Q(z)$ dos polinomios complejos de grado $n$ y $m$, respectivamente, tales que $m\geq n+2$. Muestra que: \begin{equation*} \lim\limits_{r\to \infty} \int_{C} \frac{P(z)}{Q(z)} dz = 0, \end{equation*}donde el contorno $C$ es la circunferencia $C(0,r)$. Hint: Utiliza la proposición 34.3(5).
Evalúa la integral $\int_{\gamma} \overline{z} dz$, donde: a) $\gamma$ es el pedazo de la parábola $y=x^2$ que va de $0$ a $1+i$; b) $\gamma$ es el arco de la cicloide dada por: \begin{equation*} x(t)=a(t-\operatorname{sen}(t)), \quad y(t)=a(1-\operatorname{cos}(t)), \end{equation*}entre los puntos $(0,0)$ y $(a\pi, 2a)$, con $a>0$.
Verifica que: \begin{equation*} \int_{\gamma_1} \frac{1}{z} dz \neq \int_{\gamma_2} \frac{1}{z} dz, \end{equation*}donde $\gamma_1(t)=e^{-it}$ y $\gamma_2(t)=e^{it}$, con $t\in[0,2\pi]$.
Más adelante…
En esta entrada hemos definido de manera formal lo que es una integral de una función compleja de variable compleja. Como vimos, esta definición es similar a la de una integral de línea y muchos de las propiedades de este tipo de integrales están sustentados por la teoría de integración para integrales reales, por lo que la operabilidad de estas integrales resulta sencilla gracias a los resultados de nuestros cursos de Cálculo.
En la siguiente entrada probaremos el Teorema Fundamental del Cálculo para integrales de contorno y el lema de Goursat, así como otros resultados importantes sobre las integrales de contorno para funciones complejas, los cuales nos serán de utilidad para probar algunos de los resultados fundamentales en la teoría de la Variable Compleja, como el teorema de Cauchy.