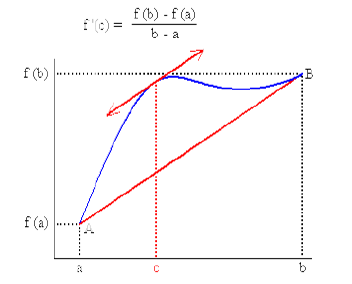
El Teorema del valor medio es un resultado fundamental del cálculo diferencial. En cálculo de una variable nos dice que en algún punto del intervalo, la pendiente de la tangente a la curva (es, decir la derivada) es igual a la pendiente de la recta secante que une los puntos extremos $(a,f(a))$ y $(b,f(b))$. En esta sección estudiaremos para el caso en más dimensiones.
Recordemos el teorema del valor medio para funciones de $\mathbb{R}\rightarrow \mathbb{R}$
Suponga que $f:[a,b]\rightarrow\mathbb{R}$ es derivable en $(a,b)$ y continua en $[a,b]$ entonces existe $c\in(a,b)$ tal que $$f'(c)=\frac{f(b)-f(a)}{b-a}$$
En esta sección se presenta el caso en la versión para funciones de $\mathbb{R}^{n}$ en $\mathbb{R}$. De esta manera el caso general se ve de la siguiente manera:
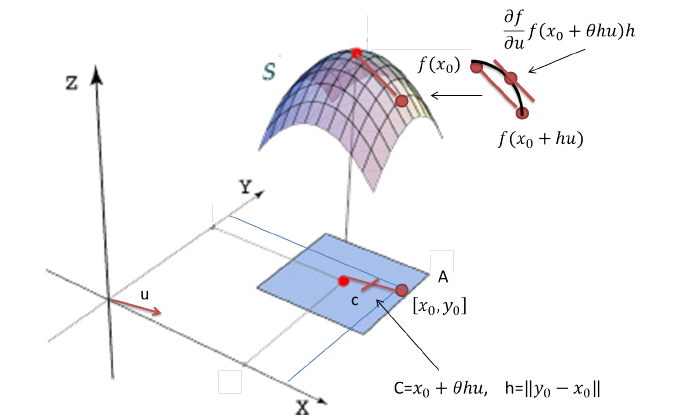
Teorema. Sea $f:A\subset\mathbb{R}^{n} \rightarrow \mathbb{R}$ una función definida en el conjunto abierto $A$ de $\mathbb{R}^{n}$. Si $x_{0},y_{0} \in A$ se pide que el conjunto $A$ sea tal que $[x_0,y_0]=\left\{x_{0}+t(y_{0}-x_{0})~|~t\in[0,1]\right\}\subset A$. Sea $u$ un vector unitario en la dirección del vector $y_{0}-x_{0}$. Si la función $f$ es continua en los puntos del segmento $[x_0,y_0]$ y tiene derivadas direccionales en la dirección del vector $u$ en los puntos del segmento $(x_0,y_0)$, entonces existe $\theta$ , $0<\theta<1$ tal que $f(x_0+hu)-f(x_0)=\displaystyle\frac{\partial f}{\partial u}(x_0+\theta hu)h$ donde $h=|y_0-x_0|$.
Una consecuencia del teorema anterior es el teorema Teorema. Sea $f:A\subset\mathbb{R}^{n} \rightarrow \mathbb{R}$ una función definida en el conjunto abierto $A$ de $\mathbb{R}^{n}$. Si las derivadas parciales $\displaystyle{\frac{\partial f}{\partial x_{i}}~~\forall i=1,..,n}$ son continuas en $x_{0}\in A$ entonces f es diferenciable en $x_{0}\in A$ Vamos a dar una idea de la demostración para el caso n=2
Teorema del Valor Medio para Funciones de $\mathbb{R}^{2}\rightarrow \mathbb{R}$
Teorema. Sea $f:A\subset\mathbb{R}^{2} \rightarrow \mathbb{R}$ una función definida en el conjunto abierto $A$ de $\mathbb{R}^{2}$. Si $x_{0},y_{0} \in A$ se pide que el conjunto $A$ sea tal que $[x_0,y_0]=\left\{x_{0}+t(y_{0}-x_{0})~|~t\in[0,1]\right\}\subset A$. Sea $u$ un vector unitario en la dirección del vector $y_{0}-x_{0}$. Si la función $f$ es continua en los puntos del segmento $[x_0,y_0]$ y tiene derivadas direccionales en la dirección del vector $u$ en los puntos del segmento $(x_0,y_0)$, entonces existe $\theta$ \, $0<\theta<1$ tal que $f(x_0+hu)-f(x_0)=\displaystyle\frac{\partial f}{\partial u}(x_0+\theta hu)h$ donde $h=|y_0-x_0|$.
Demostración. Considere la función $\phi:[0,h]\rightarrow \mathbb{R}$ dada por $\phi(t)=f(x_0+tu)$ ciertamente la función $\phi$ es continua en $[0,h]$ pues $f$ lo es en $[x_0,y_0]$. Ademas
de modo que para $t \in (0,h)$, $\phi'(t)$ existe y es la derivada direccional de $f$ en $x_0+tu \in (x_0,y_0)$ en la dirección del vector $u$. Aplicando entonces el teorema del valor medio a la función $\phi$, concluimos que existe un múmero $\theta \in (0,1)$ que da $\phi(h)-\phi(0)=\phi'(\theta h)h$\ es decir de modo que $$f(x_0+hu)-f(x_0)=\frac{\partial f}{\partial u}(x_0+\theta hu)h$$
Ahora para la verisón del teorema 3
Teorema 5. Sea $f:A\subset\mathbb{R}^{2} \rightarrow \mathbb{R}$ una función definida en el conjunto abierto $A$ de $\mathbb{R}^{n}$. Si las derivadas parciales $\displaystyle{\frac{\partial f}{\partial x},~~\frac{\partial f}{\partial y}}$ son continuas en $(x_{0},y_{0})\in A$ entonces f es diferenciable en $(x_{0},y_{0}\in A$
Demostración. Vamos a probar que $$f((x_{0},y_{0})+(h_{1},h_{2}))=f(x_{0},y_{0})+\frac{\partial f}{\partial x}(x_{0},y_{0})h_{1}+\frac{\partial f}{\partial y}(x_{0},y_{0})h_{2}+r(h_{1},h_{2})$$donde $$\lim_{(h_{1},h_{2})\rightarrow(0,0)}\frac{r(h_{1},h_{2})}{|(h_{1},h_{2})|}=0$$
para ello tenemos que $$r(h_{1},h_{2})=f((x_{0},y_{0})+(h_{1},h_{2}))-f(x_{0},y_{0})-\frac{\partial f}{\partial x}(x_{0},y_{0})h_{1}-\frac{\partial f}{\partial y}(x_{0},y_{0})h_{2}$$ sumando un cero adecuado $$r(h_{1},h_{2})=f((x_{0},y_{0})+(h_{1},h_{2}))-\textcolor{Red}{f(x_{0},y_{0}+h_{2})}+\textcolor{Red}{f(x_{0},y_{0}+h_{2})}-f(x_{0},y_{0})-\frac{\partial f}{\partial x}(x_{0},y_{0})h_{1}-\frac{\partial f}{\partial y}(x_{0},y_{0})h_{2}$$ trabajaremos
$$f((x_{0},y_{0})+(h_{1},h_{2}))-\textcolor{Red}{f(x_{0},y_{0}+h_{2})}$$Considerando la función $\varphi(x)=f(x,y_{0}+h_{2})$ por lo tanto tenemos que $$\varphi'(x)=\lim_{h_{1}\rightarrow0}\frac{\varphi(x+h_{1})-\varphi(x)}{h_{1}}=\lim_{h_{1}\rightarrow0}\frac{f(x+h_{1},y_{0}+h_{2})-f(x,y_{0}+h_{2})}{h_{1}}$$ este limite existe y nos dice que $\varphi$ es es continua en este caso en el intervalo $[x_{0},x_{0}+h_{1}]$. Por lo tanto aplicando el TVM en dicho intervalo se obtiene $$\varphi(x_{0}+h_{1})-\varphi(x_{0})=\varphi'(x_{0}+\theta_{1} h_{1})h_{1}~p.a.~\theta_{1}\in(0,1)$$ es decir $$f((x_{0}+h_{1},y_{0}+h_{2})-\textcolor{Red}{f(x_{0},y_{0}+h_{2})}=\frac{\partial f}{\partial x}(x_{0}+\theta_{1} h_{1},y_{0}+h_{2})h_{1}$$ Analogamente
$$\textcolor{Red}{f(x_{0},y_{0}+h_{2})}-f(x_{0},y_{0})$$Considerando la función $\varphi(y)=f(x_{0},y)$ por lo tanto tenemos que $$\varphi'(y)=\lim_{h_{2}\rightarrow0}\frac{\varphi(x_{0},y_{0}+h_{2})-\varphi(y_{0}+h_{2})}{h_{2}}=\lim_{h_{2}\rightarrow0}\frac{f(x_{0},y_{0}+h_{2})-f(y_{0}+h_{2})}{h_{2}}$$ este limite existe y nos dice que $\varphi$ es es continua en este caso en el intervalo $[y_{0},y_{0}+h_{2}]$. Por lo tanto aplicando el TVM en dicho intervalo se obtiene $$\varphi(y_{0}+h_{2})-\varphi(y_{0})=\varphi'(y_{0}+\theta_{2} h_{2})h_{2}~p.a.~\theta_{2}\in(0,1)$$ es decir $$f((x_{0},y_{0}+h_{2})-\textcolor{Red}{f(x_{0},y_{0})}=\frac{\partial f}{\partial y}(x_{0},y_{0}+\theta_{2}h_{2})h_{2}$$
es decir $$r(h_{1},h_{2})=\left(\frac{\partial f}{\partial x}(x_{0}+\theta_{1} h_{1},y_{0}+h_{2})-\frac{\partial f}{\partial x}(x_{0},y_{0})\right)h_{1}+\left(\frac{\partial f}{\partial y}(x_{0},y_{0}+\theta_{2}h_{2})-\frac{\partial f}{\partial y}(x_{0},y_{0})\right)h_{2}$$ por lo tanto $$\frac{r(h_{1},h_{2})}{|(h_{1},h_{2})|}=\left(\frac{\partial f}{\partial x}(x_{0}+\theta_{1} h_{1},y_{0}+h_{2})-\frac{\partial f}{\partial x}(x_{0},y_{0})\right)\frac{h_{1}}{|(h_{1},h_{2})|}+\left(\frac{\partial f}{\partial y}(x_{0},y_{0}+\theta_{2}h_{2})-\frac{\partial f}{\partial y}(x_{0},y_{0})\right)\frac{h_{2}}{|(h_{1},h_{2})|}$$ ahora bien si $\displaystyle{|(h_{1},h_{2})|\rightarrow(0,0)}$ se tiene $$\left(\frac{\partial f}{\partial x}(x_{0}+\theta_{1} h_{1},y_{0}+h_{2})-\frac{\partial f}{\partial x}(x_{0},y_{0})\right)\rightarrow0$$ y $$\frac{h_{1}}{|(h_{1},h_{2})|}<1$$ Analogamente $$\left(\frac{\partial f}{\partial y}(x_{0},y_{0}+\theta_{2}h_{2})-\frac{\partial f}{\partial y}(x_{0},y_{0})\right)\rightarrow0$$ y $$\frac{h_{2}}{|(h_{1},h_{2})|}<1$$ en consecuencia $$\lim_{(h_{1},h_{2})\rightarrow(0,0)}\frac{r(h_{1},h_{2})}{|(h_{1},h_{2})|}=0$$por lo tanto f es diferenciable en $(x_{0},y_{0})$
Más adelante
Estudiremos la definición del vector gradiente, el cual, contiene las derivadas parciales de una función real y veremos su importancia en relación a una dirección (vector) dado para analizar el crecimiento de una función.
Tarea Moral
Mostrar que la siguiente función es diferenciable en cada punto de su dominio.
Bienvenido al curso de Geometría Analítica I. A través de esta serie de entradas cubriremos el temario oficial del programa de la materia tal y como se requiere en la Facultad de Ciencias de la UNAM. Esto incluye desarrollar no sólo habilidades para ejecutar procedimientos («hacer cuentitas»), sino también aquellas que nos permitan deducir los resultados que obtendremos a través de razonamientos lógicos («demostrar»).
Pre-requisitos del curso
En la mayoría de las entradas seguiremos un flujo matemático, en el cual escribiremos definiciones, proposiciones, ejemplos, teoremas y otro tipo de enunciados matemáticos. Siempre que digamos que algo sucede, es importante argumentar o justificar por qué es esto, es decir, que demos una demostración. Las demostraciones nos ayudarán a justificar que ciertos procedimientos (para encontrar distancias, ángulos, etc.) son válidos.
Para entender un poco más al respecto, te recomendamos leer las siguientes dos entradas, o incluso llevar a la par un curso de Álgebra Superior I:
Además de estos pre-requisitos de pensamiento lógico, haremos un repaso de algunos conceptos fundamentales de geometría, como los has visto en etapas anteriores de tu educación (punto, línea, segmento, triángulo, distancia, etc.). Si bien el objetivo es que más adelante todo lo construiremos «desde cero», el recordar estos conceptos te ayudará mucho en la intuición de por qué ciertas cosas las definimoxs como lo haremos, y por qué ciertos enunciados que planteamos «deben ser ciertos».
Finalmente, también supondremos que sabes manejar a buen nivel las operaciones y propiedades en $\mathbb{R}$ (los números reales). Por ejemplo, que la suma es conmutativa ($a+b=b+a$), que se distribuye con el producto ($a(b+c)=ab+ac$), etc. Si bien en otros cursos se definen a los reales con toda formalidad, para este curso sólo será importante que sepas hacer estas operaciones.
La idea fundamental
La geometría se trata de figuras, de ver, de medir. El álgebra se trata de sumar, de operar, de comparar. La idea clave que subyace a la geometría analítica, como la veremos en este curso, es la siguiente:
La geometría y el álgebra son complementarias e inseparables, ninguna con más importancia sobre la otra. Podemos entender al álgebra a partir de la geometría, y viceversa.
Un ejemplo muy sencillo que se ve desde la educación básica es que la suma de reales se corresponde con «pegar segmentos». Si en la recta real tenemos un segmento de longitud $a$ y le pegamos un segmento de longitud $b$ (iniciando el segundo donde termina el primero), entonces el segmento que se obtiene tiene longitud $a+b$. Si bien es obvio, cuando estemos estableciendo los fundamentos tendremos que preguntarnos, ¿por qué pasa? ¿qué es pegar segmentos?
Nuestro objetivo será entender a profundidad muchas de estas equivalencias.
Interactivos
En este curso procuraremos incluir interactivos para que explores las ideas que vayamos introduciendo. Si bien un interactivo no reemplaza a una demostración, lo cierto es que sí ayuda muchísimo a ver más casos en los cuales una proposición o teorema se cumple. Nuestros interactivos están hechos en GeoGebra y necesitarás tener activado JavaScript en tu navegador.
En el siguiente interactivo puedes mover los puntos $A$, $B$ y $C$. Observa como la suma de las longitudes de dos segmentos siempre es igual a la longitud del tercero. ¿Qué pasa si $B$ «se pasa de $C$»? ¿Cuál segmento es la suma de los otros dos?
Te recomendamos fuertemente que dediques por lo menos un rato a jugar con los interactivos: intenta ver qué se puede mover, qué no, qué cosas piensas que suceden siempre y para cuales crees que haya ejemplos que fallen.
Como sugerencia, en el interactivo de GeoGebra puedes hacer clic en el ícono de pantalla completa, para que tengas más espacio para explorar:
Una vez que termines tu exploración, para salir puedes pulsar la tecla ESC, o bien usar el botón de salir de pantalla completa:
Más adelante…
En esta entrada platicamos de cómo son las notas del curso en general. Platicamos de pre-requisitos y de la idea fundamental que subyace al curso. A partir de la siguiente entrada comenzaremos con un repaso de objetos y resultados geométricos con los que probablemente estés familiarizado, debido a que se estudian en etapas educativas previas.
Más adelante, cuando iniciemos con el tratamiento teórico de la materia, hablaremos de dos visiones de geometría: la sintética y la analítica. Veremos un primer resultado que nos dice que, en realidad, ambas están muy relacionadas entre sí.
Tarea moral
A continuación hay algunos ejercicios para que practiques los conceptos vistos en esta entrada. Te será de mucha utilidad intentarlos para entender más la teoría vista.
Escribe en una hoja de papel o en un documento digital qué significan para ti los siguientes términos: punto, línea, círculo, plano, semiplano, elipse, intersección, alineado, longitud, ángulo, dirección, vector. ¿En cuáles de estas palabras tuviste que usar las otras? ¿En cuáles no? Más adelante formalizaremos cada una de estas.
Si aprendes a manejar GeoGebra por tu cuenta, podrás hacer interactivos tú mismo. Si te interesa esto, revisa el siguiente curso de GeoGebra.
¿Cómo le harías para a cada punto del plano asociarle una pareja de números reales? ¿Cómo le harías para a cada pareja de números reales asociarle un punto en el plano?
Si la suma de números corresponde a pegar segmentos, ¿a qué corresponde la multiplicación de números?
En la entrada anterior mencionamos que cuando un espacio vectorial tiene una norma, esta a su vez induce una métrica. Al final de esa sección enunciamos algunos ejemplos de espacios normados, ahora procederemos a probar que, en efecto, las definiciones dadas cumplen con la desigualdad del triángulo. Esto se hará a través de las desigualdades de Young, Hölder, Minkowski y Cauchy-Schwarz, cuyas demostraciones, por medio de razonamientos algebraicos, pueden consultarse en diversas fuentes (presentamos algunas al final). Si bien, el álgebra nos da la certeza de la prueba, la geometría nos regala la intuición del por qué ocurre así. Esto nos lleva a motivar la argumentación a modo de dibujos «en bonito» para lo que dedicaremos las siguientes líneas.
La desigualdad de Young
Proposición. Desigualdad de Young. Sean $p,q \in (1, \infty)$ tales que $\frac{1}{p} + \frac{1}{q} =1.$ Entonces para cualesquiera $a,b \in \mathbb{R}$ tales que $a,b \geq 0$ se cumple que
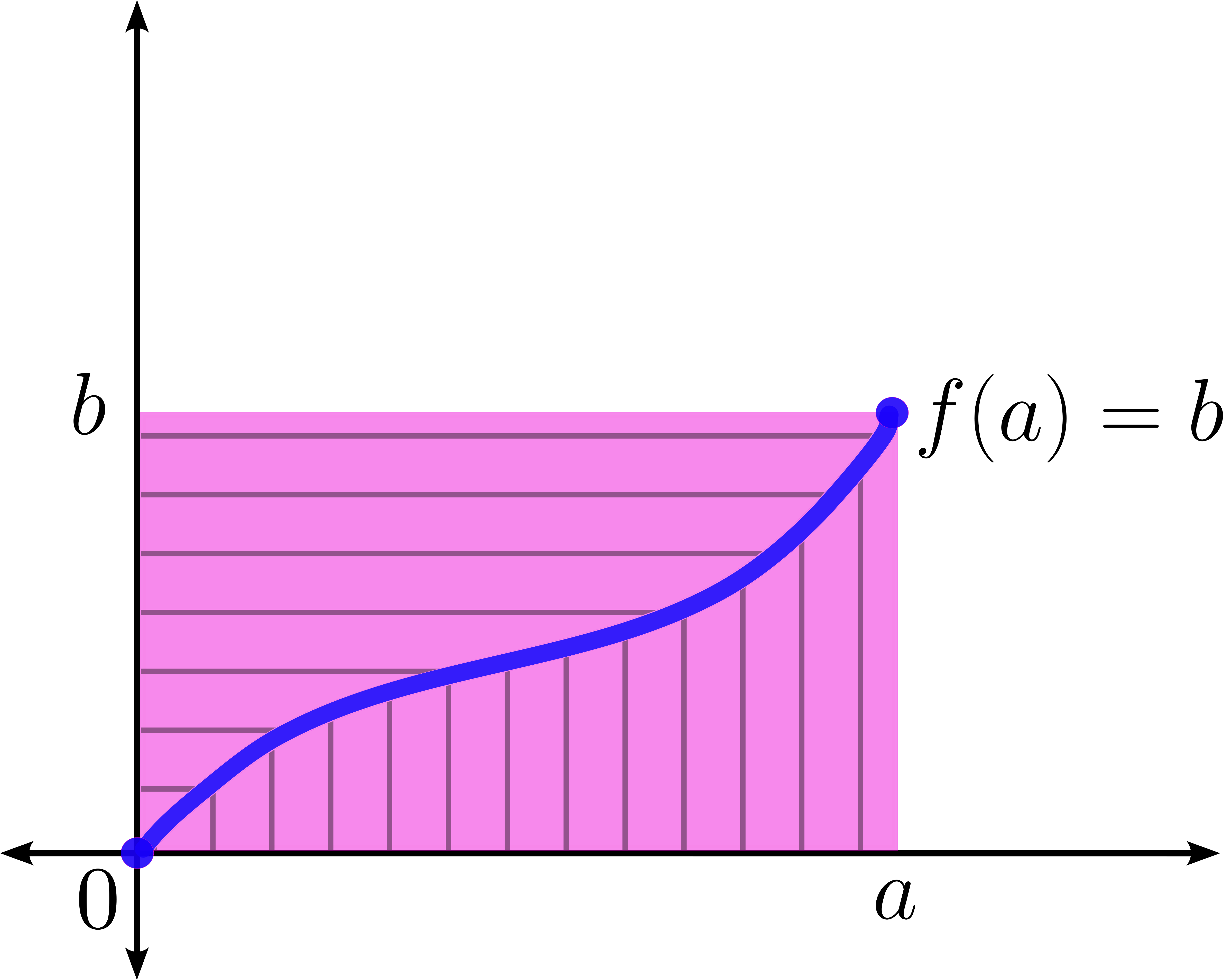
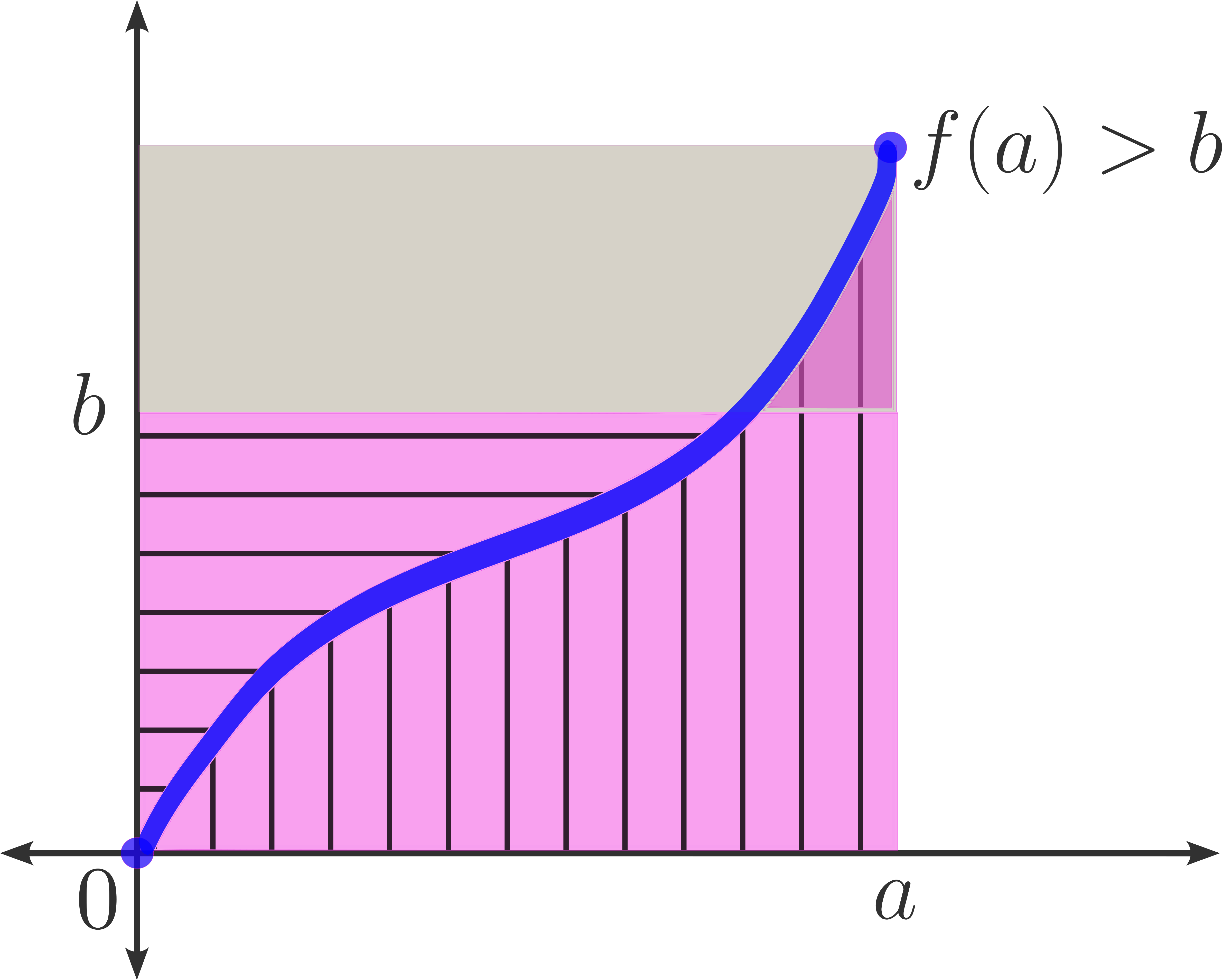
Siendo $a,b \geq 0,$ considera el rectángulo de base $a$ y altura $b$ posicionado en el primer cuadrante, como muestra la figura.
Ahora considera una función continua y creciente $f: [0, \infty) \to \mathbb{R}$ tal que $f(0) = 0$ y con $[0,b]$ contenido en la imagen de $f.$ Nota que $f$ es una función inyectiva en $[0, \infty]$ y tiene inversa, cuando menos en los siguientes casos:
Caso 1: Cuando $f(a) = b.$
La función restringida $f_{[0,a]}: [0,a] \to [0,b]$ es biyectiva. El área del rectángulo es $ab$ y esto es igual al área bajo la curva de $f$ en $[a,b]$ más el área bajo la curva de la función inversa $f^{-1}$ (que es el área entre la curva y el eje vertical).
$ \int_{0}^{a} f(x) dx+ \int_{0}^{b} f^{-1}(x) dx \,$ es igual al área del rectángulo.
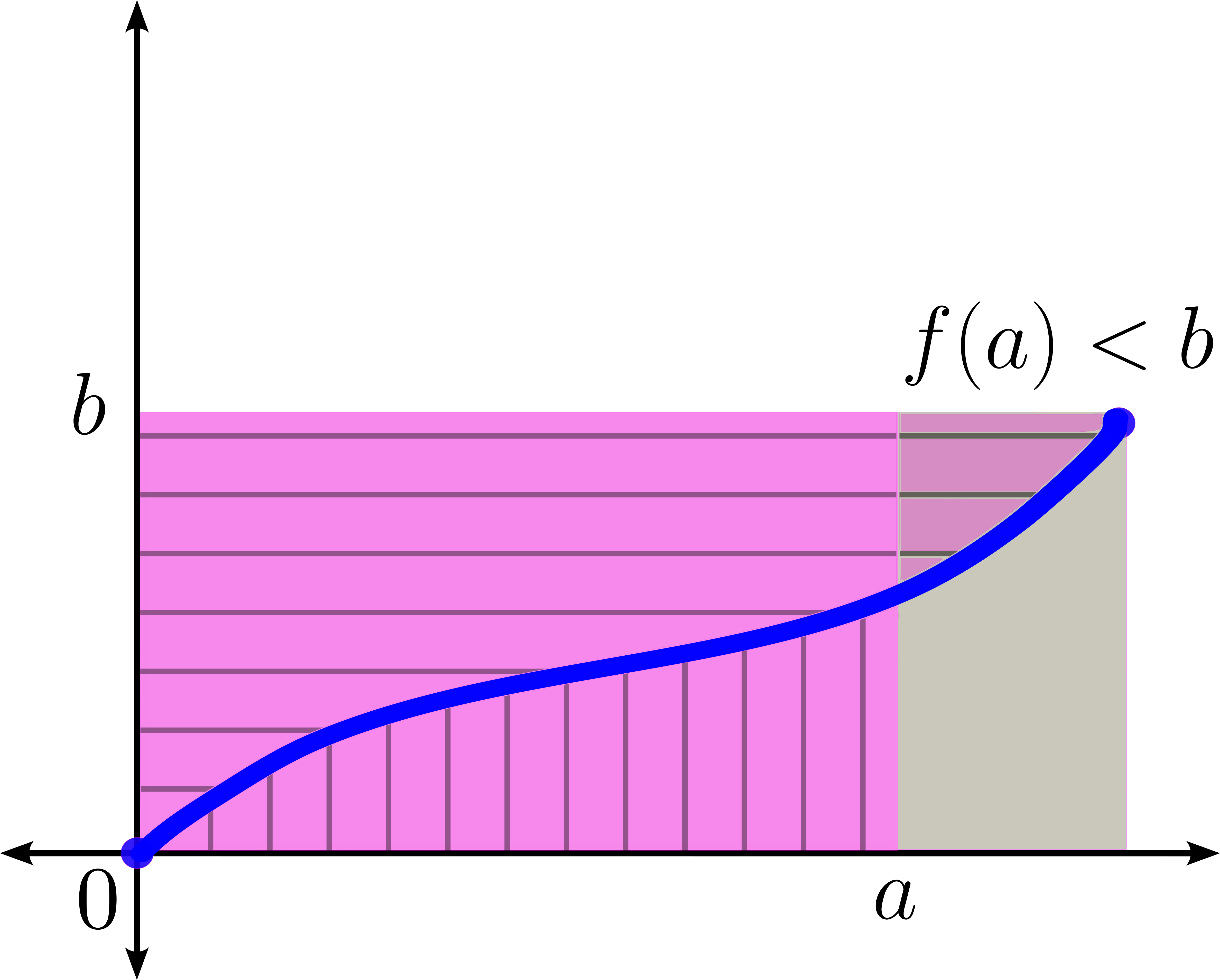
Caso 2: Cuando $f(a) < b.$
La función restringida $f_{[0,f^{-1}(b)]}: [0,f^{-1}(b)] \to [0,b]$ es biyectiva. En este caso, el área del rectángulo queda contenida en el área bajo la curva en el intervalo $[0,a]$ (en el eje horizontal) y el área entre la curva y el intervalo $[0,b]$ en el eje vertical.
$ \int_{0}^{a} f(x) dx+ \int_{0}^{b} f^{-1}(x) dx \,$ tiene un «pedazo» de área extra al rectángulo.
Caso 3: Cuando $f(a) >b.$
La función restringida $f_{[0,a]}: [0,a] \to [0,f(a)]$ es biyectiva. Podemos observar un «excedente» al rectángulo arriba del mismo.
El área entre la curva y los ejes en $[0,a]$ (horizontal) y $[0,b]$ (vertical) tiene un «pedazo» extra al rectángulo.
Apliquemos esto considerando la función $f(x)= x^{p-1},$ que es creciente. Nota que $f(0)=0$ y que $f^{-1}(x)=x ^{\frac{1}{p-1}}.$ Dado que $\frac{1}{p} + \frac{1}{q} =1,$ se puede ver que $\frac{1}{p -1}=q-1.$ En consecuencia
que es lo que queríamos probar. Esta desigualdad será aplicada en las siguientes demostraciones.
La función $\norm{\cdot}_p: \mathbb{R}^n \to \mathbb{R}$ satisface la desigualdad del triángulo.
Proposición. Desigualdad de Hölder en $\mathbb{R}^n$. Sean $p,q \in (1, \infty)$ tales que $\frac{1}{p}+\frac{1}{q}=1.$ Entonces para cualesquiera $x=(x_1,…,x_n), \, y=(y_1,…,y_n) \in \mathbb{R}^n,$ si $xy:= (x_1 y_1,…,x_n y_n),$ se cumple que
Demostración: Si algunos de los vectores es cero, la desigualdad es inmediata, entonces supongamos que ambos son distintos de cero. Nota que si la desigualdad se cumple para $x=(x_1,…,x_n), \, y=(y_1,…,y_n) \in \mathbb{R}^n,$ entonces, si $\lambda, \mu \in \mathbb{R},$ la desigualdad también se cumple para $\lambda x = (\lambda x_1,…, \lambda x_n)$ y para $\mu y= (\mu y_1,…, \mu y_n).$ Siendo así, basta con probar la desigualdad para vectores de norma uno (en sus respectivos espacios, inducidos por la norma p o la norma q), es decir cuando
Por lo tanto $\norm{xy}_1 \leq \norm{x \vphantom{y}}_p \norm{y}_q.$
Podemos pensar en la desigualdad de Hölder como un control sobre el producto término a término, de dos vectores, pues la suma no excede el producto del «tamaño» de cada vector en su respectiva norma. Cuando $2=p=q, \,$ la «balanza de los exponentes» es simétrica y tenemos la desigualdad de Cauchy-Schwarz. En este caso estaremos en el espacio métrico euclidiano. Veamos el resultado a través de la «sombra» de un vector, que nunca será más larga que el vector en cuestión.
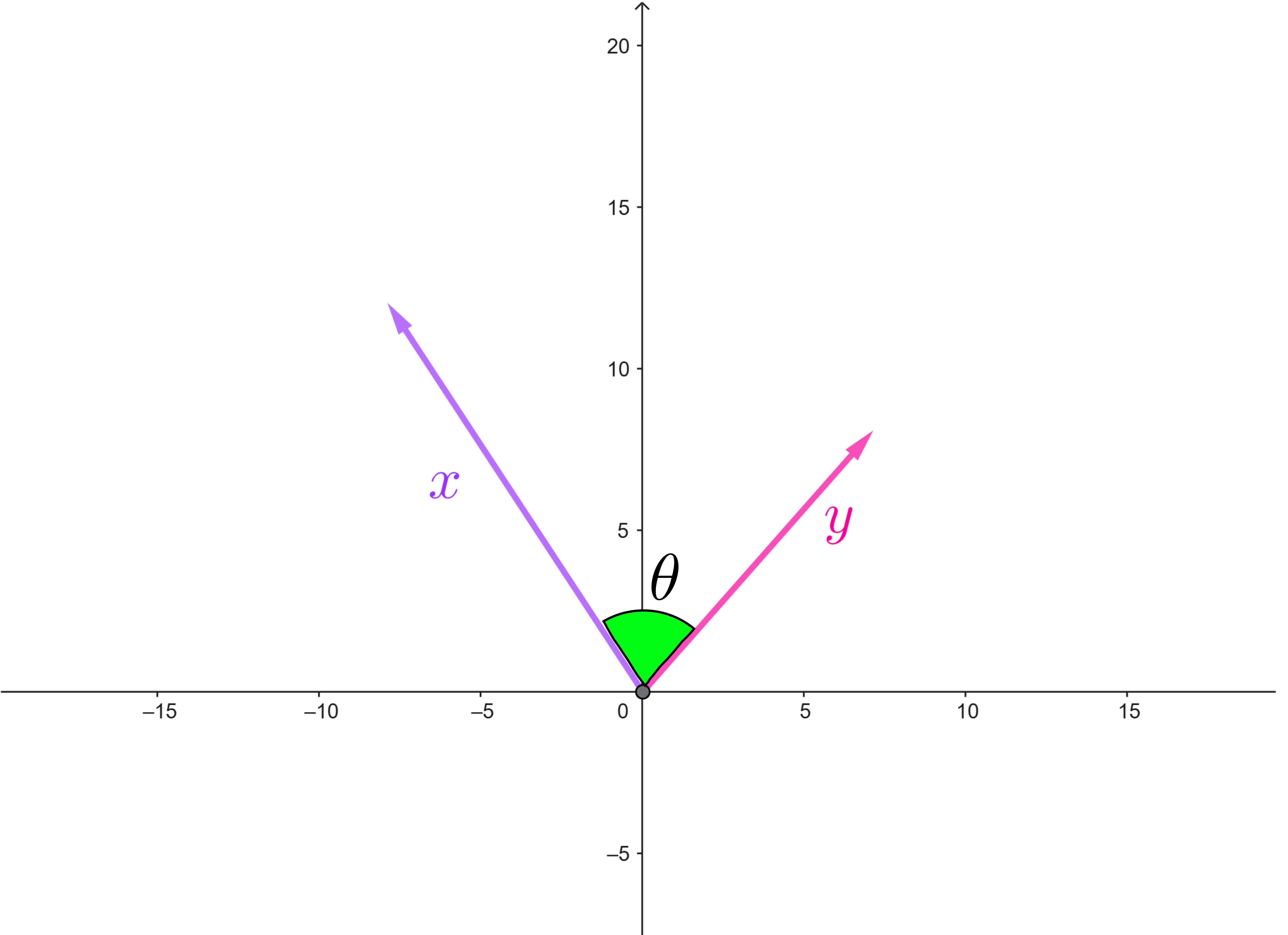
Proposición. Desigualdad de Cauchy Schwarz. Sean $x=(x_1,…,x_n), \, y=(y_1,…,y_n) \in \mathbb{R}^n.$ Se cumple que
donde $\theta$ es en ángulo entre los vectores $x$ y $y.$
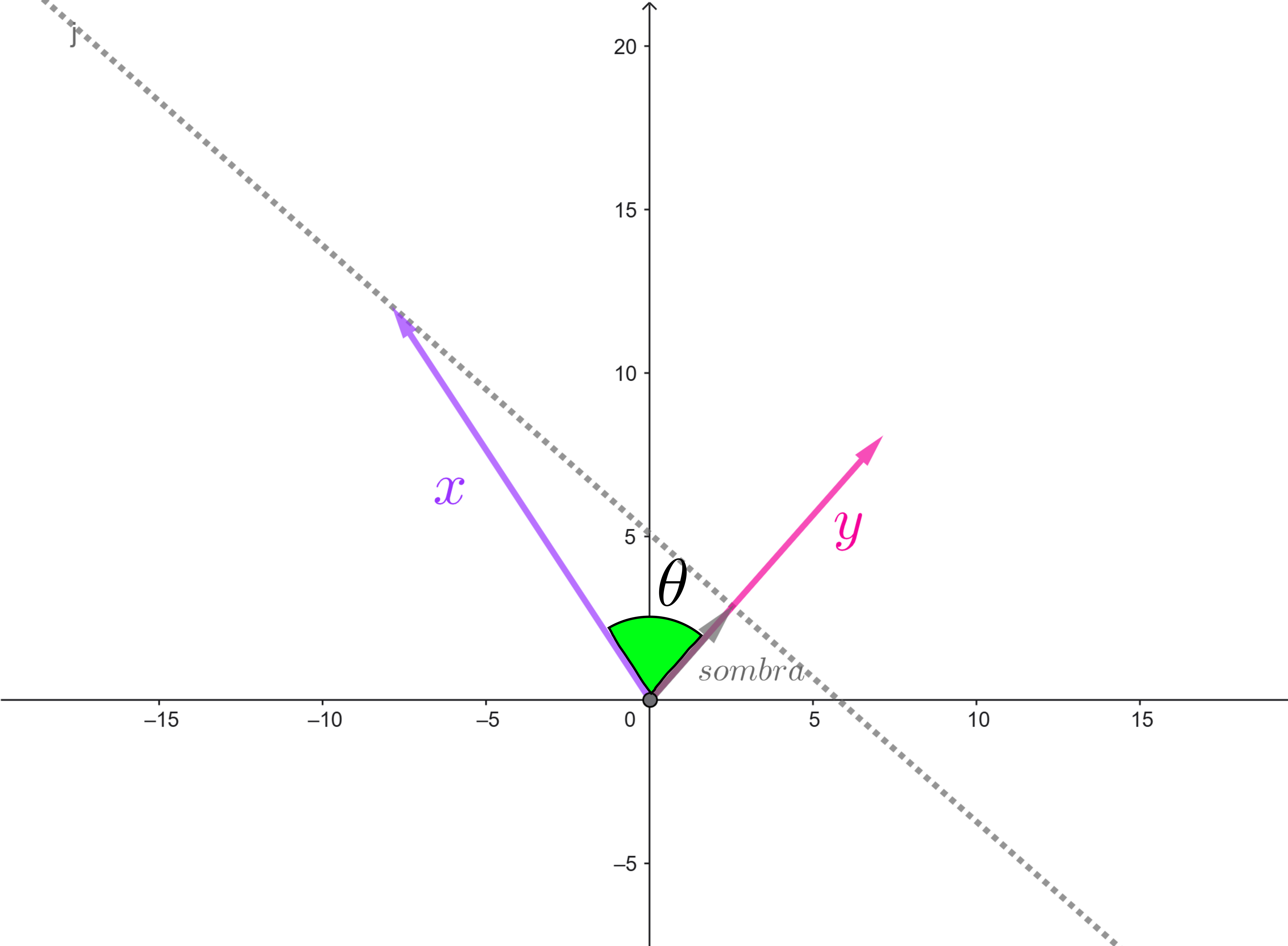
Las propiedades trigonométricas nos dicen que si proyectamos el vector $x$ en el vector $y,$ el valor de $cos \theta \norm{\vphantom{y}x}_2$ coincide con la norma del vector que genera la «sombra» de la proyección. Nota que el «tamaño» de esa sombra es menor igual que el tamaño del vector proyectado (la norma de $x$), por lo tanto se verifica que:
\begin{align*} x \cdot y &= \textcolor{magenta}{cos \theta\norm{x \vphantom{y}}_2 } \norm{y}_2 \\ &=\textcolor{magenta}{\norm{\text{sombra}}_2} \norm{y}_2 \\ &\leq \textcolor{magenta}{\norm{\vphantom{y}x}_2} \norm{y}_2 . \end{align*}
Representación de la proyección de $x$ sobre $y.$
A continuación vamos a comprobar que la norma p satisface la desigualdad del triángulo. Es lo que se conoce como:
Proposición. Desigualdad de Minkowski en $\mathbb{R}^n.$ Sean $x=(x_1,…,x_n), \, y=(y_1,…,y_n) \in \mathbb{R}^n$ y $p \in [1,\infty]$ Se cumple que
Sea $\textcolor{RedOrange}{q:= \frac{p}{p-1}}.$ Nota que $\frac{1}{p}+\frac{1}{q}= \frac{1}{p}+\frac{p-1}{p}=\frac{p}{p}=1.$ Apliquemos la desigualdad de Hölder a lo siguiente
Dividamos ambos lados de la desigualdad entre $\left(\sum_{i=1}^n(|x_i|+|y_i|)^{p} \right)^{\frac{1}{q}}.$ Esto nos lleva a usar las leyes de los exponentes del lado izquierdo. Al calcular $1-\frac{1}{q}= \frac{1}{p}$ se sigue:
Aplicaremos este resultado para probar la desigualdad del triángulo en espacios de sucesiones $\ell_p$ con la norma definida en Espacios normados:
La función $\norm{\cdot}_{p}: \ell_{p} \to \mathbb{R}$ satisface la desigualdad del triángulo.
Proposición. Desigualdad de Minkowski para series. Sea $p \in [1, \infty)$ y sean $(x_n)_{n \in \mathbb{N}}, \, (y_n)_{n \in \mathbb{N}} \in \ell_p.$ Se cumple que
Demostración: De acuerdo con el criterio de acotación para series de números reales (lo puedes repasar en Cálculo Diferencial e Integral II: Criterio de la divergencia y de acotación), para ver que la serie $\left( \sum_{i=1}^{\infty}|x_i+y_i|^p \right)^{\frac{1}{p}}$ converge basta probar que su sucesión de sumas parciales está acotada. Como las series $(x_n), \in (y_n) \in \ell_p$ podemos hablar del valor de su norma, donde:
Como $N$ es cualquier número natural, concluimos que la sucesión de sumas parciales está acotada por $\textcolor{magenta}{\norm{(x_n) \vphantom{y}}_p} + \textcolor{RoyalBlue}{ \, \norm{(y_n) \vphantom{y}}_p} \,$ entonces la serie converge y
Ahora conozcamos la versión continua de estas desigualdades, esto es, para espacios donde la norma se define a partir de una integral.
La función $\norm{\cdot \vphantom{b}}_{p}: \mathcal{C}^0[a,b] \to \mathbb{R}$ satisface la desigualdad del triángulo.
Proposición. Desigualdad de Hölder para integrales. Sean $f,g \in \mathcal{C}^0[a,b]$ y $p,q \in (1, \infty)$ tales que $\frac{1}{p} + \frac{1}{q}=1.$ Se cumple que
Demostración: La desigualdad es inmediata si $f=0 \,$ o $\, g=0$ entonces supongamos que tanto $f$ como $g$ son distintas de cero. Es sencillo probar que $\norm{f}_p \neq 0$ y $\norm{g}_p \neq 0.$
Sea $x \in [a,b].$ Apliquemos la desigualdad de Young, vista arriba, a los números:
\begin{align*} \textcolor{magenta}{\frac{|f(x)|}{\norm{f}_p}} \,\text{ y } \, \textcolor{RoyalBlue}{\frac{|g(x)|}{\norm{g}_q}} \end{align*}
que es lo que queríamos demostrar, pues $$\int_{a}^{b} |f(x)g(x)| \,dx = \norm{fg}_1$$ $$ \text{y }\, \left(\int_{a}^{b} |f(x)|^p \,dx \right)^{1/p} \left(\int_{a}^{b} |g(x)|^q \,dx \right)^{1/q} = \norm{f}_p \norm{g}_q$$
Proposición. Desigualdad de Minkowski para integrales. Sean $f,g \in \mathcal{C}^0[a,b]$ y $p \in [1, \infty].$ Entonces se verifica la desigualdad del triángulo en $\norm{\cdot}_p,$ es decir
Como $p>1,$ arriba vimos que si $\textcolor{RedOrange}{q:= \frac{p}{p-1}}$ entonces $\frac{1}{q}+\frac{1}{p}=1.$ Apliquemos la desigualdad de Hölder para integrales en $\textcolor{magenta}{\int_{a}^{b}|f(x)|(|f(x)|+|g(x)|)^{p-1} dx}$ de donde
Ahora dividamos ambos lados de la desigualdad entre $\left(\int_{a}^{b}(|f(x)|+|g(x)|)^{p} dx\right)^{\frac{1}{q}}.$ Del lado izquierdo aplicamos leyes de los exponentes, restando $1- \frac{1}{q}=\frac{1}{p}.$ Usamos también la desigualdad del triángulo en la parte señalada. Finalmente tenemos:
En la siguiente entrada procederemos a identificar todos los puntos que están «cerca» de un punto específico. ¿Te suena familiar? Vamos a ver si el conjunto formado por estos puntos es diferente al que estamos acostumbrados a representar como una bola «redonda» de radio $\varepsilon > 0$.
Tarea moral
Prueba que se cumple la igualdad en la desigualdad de Cauchy Schuarz si y solo si los vectores están en la misma línea.
Prueba la desigualdad de Hölder para series: Si $p,q \in (1, \infty)$ y $\frac{1}{p} +\frac{1}{q}=1$ y tenemos dos sucesiones tales que $(x_n)_{n \in \mathbb{N}} \in \ell_p$ y $(y_n)_{n \in \mathbb{N}} \in \ell_q,$ entonces $(x_ny_n)_{n \in \mathbb{N}} \in \ell_1$ y \begin{align*} \norm{(x_ny_n)}_1 &\leq \norm{(x \vphantom{y}_n)}_p \norm{(y_n)}_q \\ \sum_{i=1}^{\infty}|x_i y_i| & \leq \left(\sum_{i=1}^{\infty}|x_i|^p \right)^\frac{1}{p} \left(\sum_{i=1}^{\infty}|y_i|^q \right)^\frac{1}{q}. \end{align*}
Prueba que las funciones definidas en Espacios normados en efecto son normas.
En la sección de Compacidad en espacios métricos hablamos de un conjunto en el espacio $\ell_{\infty}:$ El conjunto dado por $\overline{B}(\mathcal{0},1)$ (donde $\mathcal{0}$ es la sucesión que en todos los términos vale 0). Tiene la propiedad de ser cerrado y acotado en $\ell_{\infty}$ pero no es compacto. Esto se probó mostrando que no era posible cubrirlo con una cantidad finita de bolas abiertas, cuyo radio era «muy pequeño», lo suficiente para no tener más de un elemento $e_i$ dentro (donde $e_i$ es la sucesión que toma a $1$ como valor en la entrada $i$ y $0$ en el resto). Se vio que era posible elegir un radio así porque los elementos $e_i$ estaban «alejados» entre sí.
Aparentemente no basta con tener nuestros elementos atrapados en un entorno para asegurar que no estén lejos unos de otros. En esta sección vamos a ver qué condiciones impiden que así suceda. Primero necesitaremos estos resultados:
Teorema. Cualesquiera dos normas en un espacio vectorial de dimensión finita son equivalentes.
Demostración: Sea $V$ un espacio vectorial de dimensión $n$ y $\{v_1, \, v_2,…,v_n\}$ una base para $V.$ Primero definiremos una norma $\textcolor{magenta}{\norm{\cdot}^*}$ en $V$ para luego demostrar que cualquier otra norma en $V$ es equivalente a esta:
Sea $v \in V.$ Entonces $v = \sum_{i=1}^{n}x_i v_i$ para algunos (únicos) escalares $x_i \in \mathbb{R}, \, i=1,…,n.$ Definimos
Nota que este valor coincide con la norma 1 en $\mathbb{R}^n$ del vector $(x_1,…,x_n).$ $\textcolor{orange}{\text{Dejaremos como ejercicio probar que }} \textcolor{magenta}{\norm{v}^*}$ $\textcolor{orange}{\text{ es una norma en $V$ y que la transformación}}$
$T: (\mathbb{R}^n, \norm{\cdot}_1) \to (V,\textcolor{magenta}{\norm{v}^*}) \,$ definida como $T(x_1,…,x_n)= \sum_{i=1}^{n}x_i v_i$ $\textcolor{orange}{\text{es una isometría entre estos espacios}}$ y por tanto, $T$ es una equivalencia (ejercicio 4 en Tarea moral de Más conceptos de continuidad).
Considera la esfera unitaria $S_V= \{v \in V \, | \, \textcolor{magenta}{\norm{v}^*} =1\}.$ Nota que es la imagen de $T$ en la esfera unitaria en $\mathbb{R}^n$ dada por $\mathbb{S}^{n-1}:= \{x \in \mathbb{R}^n \, | \, \norm{x}_1=1\}.$ $\textcolor{orange}{\text{Dejaremos como ejercicio probar que }}$ $\mathbb{S}^{n-1}$ es cerrado y acotado en $\mathbb{R}^n$ con la métrica usual y por tanto, compacto en ese espacio. En Más conceptos de continuidad vimos que $\norm{\cdot}_1$ y $\norm{\cdot}_2$ son equivalentes en $\mathbb{R}^n.$ Eso significa que ambos espacios métricos tienen los mismos abiertos (una cubierta abierta en $\norm{\cdot}_1$ lo es en $\norm{\cdot}_2$ y viceversa), por lo tanto $\mathbb{S}^{n-1}$ también es compacto en $(\mathbb{R}^n, \norm{\cdot}_1).$
Por la continuidad de $T$ se sigue que $T(\mathbb{S}^{n-1})= S_V$ es compacto en $(V,\textcolor{magenta}{\norm{v}^*}).$
Sea $\textcolor{RoyalBlue}{\norm{\cdot}}$ cualquier otra norma en $V.$ Vamos a probar que las normas $\textcolor{RoyalBlue}{\norm{\cdot}}$ y $\textcolor{magenta}{\norm{v}^*}$ son equivalentes.
Sea $v = \sum_{i=1}^{n}x_i v_i.$ Por propiedades de la norma se sigue:
Haciendo $c := \underset{1 \leq i \leq n}{max} \, \textcolor{RoyalBlue}{\norm{v_i}}$ concluimos que para cualquier $v \in V,$
\begin{align} \textcolor{RoyalBlue}{\norm{v}} \leq c \textcolor{magenta}{\norm{v}^*} \end{align}
Nota que podemos pensar en $\textcolor{RoyalBlue}{\norm{\cdot}}$ como una función continua en el espacio $(V,\textcolor{magenta}{\norm{v}^*})$ al espacio $\mathbb{R}.$ De hecho es lipschitz continua, pues por lo que acabamos de probar, para cada $u, v \in V$ se satisface:
$$|\textcolor{RoyalBlue}{\norm{v}} -\textcolor{RoyalBlue}{\norm{u}}| \leq \textcolor{RoyalBlue}{\norm{v -u}} \leq c \textcolor{magenta}{\norm{v -u}^*}$$
y como $S_V$ es compacto en $(V,\textcolor{magenta}{\norm{v}^*})$ se sigue que $\textcolor{RoyalBlue}{\norm{\cdot}}$ alcanza su mínimo $c_2$ en $S_V.$ Nota que para cualquier $v \in S_V,$ $c \leq \textcolor{RoyalBlue}{\norm{v}}$ y que $c_2 >0,$ pues si el mínimo se alcanza en $v_0 \in S_V$ entonces $c_2=0 \iff \textcolor{RoyalBlue}{\norm{v_0}}=0 \iff v_0 =0 \iff \textcolor{magenta}{\norm{v_0}^*} =0$ entonces $v_0$ no pertenece a $S_V,$ lo cual es una contradicción.
Sea $v \neq 0 \in V.$ Entonces $\frac{v}{\textcolor{magenta}{\norm{v}^*}} \in S_V$ entonces
De 1 y 2 concluimos que cualquier norma en $V$ es equivalente a $\textcolor{magenta}{\norm{v}^*}.$ Por lo tanto, cualesquiera dos normas en un espacio vectorial de dimensión finita son equivalentes.
Ahora estamos listos para mostrar la prueba de una afirmación presentada al final de Espacios métricos completos.
Corolario. Todo espacio normado de dimensión finita es de Banach.
Demostración: Sea $V$ un espacio de dimensión finita $n$ con norma $\textcolor{RoyalBlue}{\norm{\cdot}}.$ Ya que $(\mathbb{R}^n,\norm{\cdot}_2)$ es completo, de acuerdo con lo visto en Espacios métricos completos bastará mostrar que existe una equivalencia entre ambos espacios.
La prueba anterior muestra que existe una equivalencia entre $(V, \textcolor{magenta}{\norm{v}^*})$ y $(\mathbb{R}^n,\norm{\cdot}_1).$ También que todas las normas en $\mathbb{R}^n$ son equivalentes, por lo que, en particular $(\mathbb{R}^n,\norm{\cdot}_1)$ es de Banach (pues $\norm{\cdot}_1$ es equivalente a $\norm{\cdot}_2)$. Luego $(V, \textcolor{magenta}{\norm{v}^*})$ es de Banach y al ser $\textcolor{magenta}{\norm{v}^*}$ equivalente a $\textcolor{RoyalBlue}{\norm{\cdot}}$ se sigue que $(V, \textcolor{RoyalBlue}{\norm{\cdot}})$ es de Banach.
Corolario. Sea $V$ un espacio vectorial normado. Todo subespacio vectorial de dimensión finita de $V$ es cerrado en $V.$
Demostración: Sea $W$ subespacio vectorial de $V$ de dimensión finita. Por el resultado anterior, $W$ es completo. En Espacios métricos completos vimos que si un subespacio métrico es completo entonces es cerrado en el espacio que lo contiene, por lo tanto, $W$ es cerrado en $V.$
Lema de Riesz. Sea $V$ un espacio vectorial normado (de cualquier dimensión) y $W$ un subespacio vectorial de $V$ tal que $W$ es cerrado y $W \neq V.$ Entonces para cada $\delta \in (0,1)$ existe $v_{\delta} \in V$ tal que $\norm{v_{\delta}}=1$ y $\norm{v_{\delta}-w}\geq \delta$ para toda $w \in W.$
Demostración: Como $W \neq V$ podemos tomar $v \in V \setminus W.$ Como $W$ es cerrado, existe $\varepsilon >0$ tal que $B(v, \varepsilon) \subset V \setminus W,$ en consecuencia $0 < r := \underset{w \in W}{inf} \, \norm{v-w}.$
Sea $\delta \in (0,1),$ nota que $r < \frac{r}{\delta}.$ Como $r$ es ínfimo, existe $w_0 \in W$ tal que $r \leq \textcolor{RoyalBlue}{\norm{v -w_0} \leq \frac{r}{\delta}}.$
Sea $$v_{\delta} = \frac{v -w_0}{\norm{v -w_0}}$$
Entonces $\norm{v_{\delta}}=1.$ Probemos ahora que para cada $w \in W,$ $\norm{v_{\delta} -w}\geq \delta.$
Dado que $\textcolor{magenta}{w_0 -\norm{v -w_0}w}$ es combinación lineal de elementos en $W,$ se sigue que $\textcolor{magenta}{w_0 -\norm{v -w_0}w}$ pertenece a $W.$ En consecuencia
Teorema de Riesz. Sea $V$ un espacio vectorial normado. La esfera unitaria $S_V= \{v \in V \, | \, \norm{v} =1\}$ es compacta si y solo si, $V$ es de dimensión finita.
Demostración: Supongamos por el contrario que $V$ es de dimensión infinita. Partimos de que $S_V$ es compacto. En Compacidad en espacios métricos vimos que toda sucesión de un compacto tiene una subsucesión convergente. Nuestra contradicción será una sucesión que no tiene esta propiedad:
Sea $W_1 := \langle w_1 \rangle$ el espacio generado por un vector $w_1 \in S_V$ Entonces $W_1$ es subespacio propio de $V$ (pues $V$ es de dimensión infinita) y por los dos últimos resultados de arriba, $W_1$ es cerrado y para $\delta = \frac{1}{2}$ existe $w_2 \in S_V$ tal que $\norm{w_2 -w} \geq \frac{1}{2}$ para cada $w \in W_1.$
Sea $W_2 := \langle w_1, w_2 \rangle$ el espacio generado por los vectores $w_1$ y $w_2.$ Entonces $W_2$ es subespacio propio de $V$ (pues $V$ es de dimensión infinita) y por los dos últimos resultados de arriba, $W_2$ es cerrado y para $\delta = \frac{1}{2}$ existe $w_3 \in S_V$ tal que $\norm{w_3 -w} \geq \frac{1}{2}$ para cada $w \in W_2.$ . . . Sea $W_k := \langle w_1, w_2,…,w_k \rangle$ el espacio generado por los vectores $w_1, w_2,….,w_k.$ Entonces $W_k$ es subespacio propio de $V$ (pues $V$ es de dimensión infinita) y por los dos últimos resultados de arriba, $W_k$ es cerrado y para $\delta = \frac{1}{2}$ existe $w_{k+1} \in S_V$ tal que $\norm{w_{k+1} -w} \geq \frac{1}{2}$ para cada $w \in W_k.$
De esta construcción se tiene que $(w_n)_{n \in \mathbb{N}} \,$ es una sucesión de elementos de $S_V.$ Para cualesquiera dos elementos distintos de la sucesión $w_l, w_m$ supón sin pérdida de generalidad que $l < m$ entonces $w_l \in W_l \subset W_{m-1} \subsetneq W_m$ por lo que $\norm{w_l -w_m} \geq \frac{1}{2}$ en consecuencia no existe ninguna subsucesión de Cauchy para $(w_n)$ por lo que no hay tampoco una subsucesión convergente, lo que contradice que $S_V$ es compacto, por lo tanto $V$ es de dimensión finita. El regreso queda como ejercicio, (nota que $S_V$ es cerrado y acotado en $V$ y que lo puedes llevar a $(\mathbb{R}^n, \norm{\cdot}_2$ donde por Heine Borel sabemos que es compacto).
La misma argumentación prueba la siguiente:
Proposición. La bola cerrada $\overline{B}(0,1) = \{v \in V \, | \, \norm{v} \leq 1\}$ es compacta si y solo si $V$ es de dimensión finita. Lo mismo ocurre para cualquier bola cerrada en $V.$ Esto quedará como ejercicio.
De manera más general, se cumple:
Proposición. Sea $V$ un espacio vectorial normado de dimensión finita. Entonces $A \subset V$ es compacto en $V$ si y solo si $A$ es cerrado y acotado en $V.$
Demostración: Queda como ejercicio.
Más adelante…
Cuando hablamos de un espacio vectorial normado de dimensión finita $n$ podemos considerar una base de elementos $\{v_1, v_2,…,v_n\}$ todos de norma uno. La distancia entre cualesquiera dos de ellos siempre será mayor que cero y, de hecho, mayor que un $r \in \mathbb{R}.$ Ya que todos los elementos de la base están «lejos» del resto, cada uno necesitará su bolita para ser cubierto, pero al ser la base un conjunto finito, bastará una cantidad finita de bolitas para lograrlo. En dimensión infinita no ocurre así: tal como vimos, el Lema de Riesz permite seleccionar infinitos elementos en la esfera, alejados entre sí. Si queremos cubrir con bolitas «más pequeñas» que esa distancia necesitaremos una bolita para cada elemento, solo en eso ya se nos va una cantidad infinita de bolitas. Podemos ver que no podemos seleccionar cubiertas finitas para este tipo de cubiertas abiertas.
En esta entrada aprendimos que ser cerrado y acotado no basta para garantizar la compacidad en espacios de dimensión finita, lo siguiente será analizar específicamente cuando no falla lo que estamos intentando hacer (cubrir con finitas bolas chiquititas). Un conjunto donde sí se pueda hacer eso se denominará totalmente acotado. ¿Será suficiente para tener la compacidad?
Tarea moral
Resuelve la parte de la prueba que quedó pendiente en el primer teorema.
Demuestra el regreso del teorema de Riesz.
Prueba que si $V$ es un espacio vectorial normado, entonces una bola cerrada en $V$ es compacta si y solo si $V$ es de dimensión finita.
Sea $V$ un espacio vectorial normado de dimensión finita. Prueba que $A \subset V$ es compacto en $V$ si y solo si $A$ es cerrado y acotado en $V.$
Bibliografía
Carothers, N.L., Real Analysis. New York: Cambridge University Press, 2000. Págs: 124 y 125.
Si has sido seguidor de El blog de Leo y has aprovechado el material de aprendizaje de matemáticas universitarias que tenemos, esta entrada te interesa.
Quizás desde hace años has visto cómo este espacio ha crecido bastante. De hecho, yo mismo lo he visto crecer de formas que no imaginaba al principio. Empezó como un blog personal, que luego se volvió algo así como un blog de «la vida de un matemático en formación», con pensamientos matemáticos varios y algunas anécdotas personales, de viajes y de la academia. Sin embargo, al ser uno de los primeros espacios digitales que empecé a mantener, lo convertí en el hogar de otros proyectos de gran alcance en los que he estado involucrado, por ejemplo el Concurso Universitario de Matemáticas Galois-Noether y el repositorio de videos de resolución de problemas. Y, más recientemente, de todo un ecosistema de notas de matemáticas para estudiantes universitarios. En esta entrada quiero hablar un poco más de lo segundo, y de su relación con un proyecto más amplio que se llama Matemáticas a Distancia.
Antes de comenzar, me gusta recordar que, aunque el sitio lleva mi nombre, mucho del contenido que encuentran aquí es en realidad el fruto del esfuerzo de muchas personas. Por favor, recuerden siempre revisar a los autores de cada entrada, pues este es un esfuerzo colectivo para generar material libre y de calidad. Bueno, sin decir más, quiero entonces empezarles a platicar acerca del proyecto que engloba todas notas de docencia que hemos trabajado aquí en el blog, de Matemáticas a Distancia.
¿Qué es Matemáticas a Distancia y cómo nació?
Matemáticas a Distancia es una iniciativa que se empezó a planear en 2020 en la Facultad de Ciencias de la UNAM. Cuando presenté mis papeles para concursar por una plaza de tiempo completo en la Facultad, puse en mi plan de docencia que sería bueno que los estudiantes tuvieran un portal «tipo Khan Academy«, pero con material para la Licenciatura en Matemáticas. En aquel momento, había varias ventajas fáciles de describir sobre tener algo así. Sin embargo, la pandemia que se desató ese año aceleró los planes de que dicho portal naciera. Al irnos a trabajar a casa, resultó importante tener material para compartir con mis estudiantes durante el tiempo de la emergencia. Y entonces surgieron las primeras notas tipo blog.
No fui el único al que se le ocurrió crear material para sus cursos. Muchos de mis colegas o bien ya contaban con algo de material, o bien la pandemia los orilló a crearlo. Así, entre varios profesores nos pusimos de acuerdo para solicitar un apoyo PAPIME de la UNAM, con el fin de trabajar en un proyecto mejor armado. El objetivo principal que compartimos desde ese entonces fue ofrecer un ecosistema digital unificado para la Licenciatura en Matemáticas. Desde el inicio hay tres principios fundamentales que perseguimos:
Que el material sea gratuito.
Que el material sea abierto.
Que el material sea de calidad.
Así, todo empezó como una respuesta a la necesidad de flexibilizar la educación. Pero desde entonces el proyecto ha crecido muchísimo. Tras el primer año abrimos nuestra página de internet en https://www.mdistancia.com. En años posteriores conseguimos más apoyo institucional para acercar a numerosos profesores y estudiantes para desarrollar más material. Además, hemos trabajado para que no se trate únicamente de subir archivos a la red, sino que haya también en el material cierto acompañamiento adicional, ya sea mediante la respuesta a comentarios de blog, interacciones en YouTube u ofreciendo cuestionarios para que quien revise el material pueda ir verificando su entendimiento.
Lo que tenemos para ti hoy
Actualmente, el portal ha consolidado una oferta muy robusta que el equipo ha ido puliendo con el tiempo. En la plataforma contamos con 27 COMALes (Curso Online de Matemáticas Abierto para licenciatura), que son cursos en línea que cubren la teoría completa de diversas asignaturas obligatorias y optativas de la licenciatura.
También tenemos material para las carreras de Actuaría y Ciencias de la Computación.
Además de los cursos largos, hacia 2023 surgió la idea de que contáramos con otros mini-cursos de habilidades complementarias. Introducimos esa funcionalidad en la plataforma y hemos creado 7 mini-COMALes, para poder desarrollar en una menor cantidad de tiempo alguna habilidad complementaria o profesionalizante:
Cimientos Matemáticos: Para contar con los fundamentos matemáticos correctos antes de empezar en la vía universitaria.
Computación Científica Introductoria con Python: Para una aproximación informal, pero útil a la programación, desde su utilidad en las matemáticas mismas.
Curso de LaTeX para Ciencias: Para conocer los fundamentos de trabajar en LaTeX y realizar colaboraciones matemáticas en Overleaf.
Geometría Interactiva: Para descubrir con software distintos resultados de geometría.
Introducción a Pandas en Python: Para un primer acercamiento al análisis de datos.
Los Elementos de Euclides: Para visualizar en video distintos resultados de la clásica obra de Euclides.
Notas de Apoyo para Teoría de Gráficas I: Para contar con una guía express para esta materia optativa de la licenciatura.
Todo este material es gratuito. Intentamos que sea compatible entre sí, en el sentido de que permita fácilmente saltar de una materia a otra.
Además, la última noticia es que el portal ya permite tener un aprendizaje más personalizado, pues desde febrero de 2026 ya es posible abrir una cuenta.
¿Por qué te conviene abrir una cuenta en Matemáticas a Distancia?
Si eres usuario frecuente de este blog, te darás cuenta de que aquí la experiencia es principalmente de lectura y quizás de interactuar mediante los comentarios. Sin embargo, hay algunas limitaciones en quedarse sólo en el blog:
Es difícil saber cuáles son todas las entradas de blog de aprendizaje de matemáticas que existen.
No es tan fácil recordar cuáles entradas ya has visto y cuáles no.
Para guardar tus entradas favoritas tienes que saturar los favoritos de tu navegador.
Al abrir una cuenta en Matemáticas a Distancia, lo cual es totalmente gratuito, podrás hacer lo siguiente:
Llevar un registro detallado de tus avances en cada curso para que sepas exactamente dónde te quedaste la última vez que estudiaste.
Encontrar en los COMALes correspondientes material auxiliar para cada nota.
Marcar materiales, notas o videos como favoritos para que los tengas a la mano en consultas rápidas.
Resolver los cuestionarios de autoevaluación integrados en los cursos y guardar tus puntuaciones para ver cómo vas mejorando.
Recibir actualizaciones directas sobre nuevos contenidos, guías de supervivencia académica o herramientas que integremos a la plataforma.
Estar al tanto de material que no está en formato notas de blog.
Conclusión
En fin, esta entrada era para hacerles saber de la existencia de Matemáticas a Distancia, pues es un proyecto grande que, en particular, abarca las notas de docencia de El blog de Leo. Si bien esto no incluye a todo el blog, me parece que una gran cantidad de los seguidores y personas que visitan este blog pueden beneficiarse de tener también ese otro portal en mente.
En general, me entusiasma mucho ver que el material que empezó como material de clase, ahora sirva a tantas personas en distintas partes del mundo hispanohablante. Esto siempre es inspiración para seguir trabajando tanto en El blog de Leo como en Matemáticas a Distancia, y para que el equipo siga ofreciendo material cada vez más útil y diverso.
Si ya conoces el blog, pero no Matemáticas a Distancia, te invito entonces a que explores el sitio en https://www.mdistancia.com. Explora un poco el Árbol de Recursos. Usa el Buscador. Intenta ver si hay algún COMAL o mini-COMAL que te interese seguir. Si te animas, abre una cuenta para poder llevar un registro del esfuerzo. Y si sí te animas, cuéntame también por acá en los comentarios qué tal fue la experiencia.
Una pregunta geométrica muy natural es determinar cómo es la intersección de dos objetos geométricos, es decir, cuales son aquellos puntos que pertenecen a ambos. En el caso de las rectas, eso tiene una respuesta sencilla: la intersección de dos rectas puede ser vacía (cuando son paralelas), o bien un único punto, o bien una recta (cuando son la misma recta).
Como veremos a continuación, esto es sencillo de formalizar utilizando la forma normal de las rectas. Más aún, la forma normal nos ayudará a detectar mediante una cuenta sencilla exactamente en cuál de los casos anteriores nos encontramos. Así mismo, en caso de estar en la caso de que la intersección sea un único punto, también nos dará un procedimiento para encontrar sus coordenadas.
¿Cuándo dos vectores son paralelos?
Antes de estudiar concretamente la intersección de dos rectas, vamos a apoyarnos de la intuición que hemos desarrollado. Si tenemos rectas en forma normal correspondientes a vectores normales $u$ y $v$, entonces sabemos que las rectas son perpendiculares, respectivamente a los vectores $u$ y $v$. Si estos vectores están en la misma dirección, entonces las rectas también. Por ello, las rectas serán paralelas y entonces la intuición nos dice que o bien no se intersectarán, o bien serán la misma recta. Parece ser entonces importante encontar un criterio algebraico para saber cuándo dos vectores son paralelos o no.
Consideremos dos vectores no nulos $u=(u_1,u_2)$ y $v=(v_1,v_2)$. ¿Cuándo estos vectores son paralelos? Como los vectores están anclados en el origen, esto sucede únicamente cuando o bien $u$ es múltiplo escalar de $v$, o bien $v$ es múltiplo escalar de $u$. De esto sale el siguiente criterio algebraico:
Proposición. Tomemos dos vectores no nulos $u=(u_1,u_2)$ y $v=(v_1,v_2)$. Estos vectores son paralelos si y sólo si la expresión $u_1v_2-u_2v_1$ es igual a cero.
Demostración. Demostraremos la proposición en ambas direcciones.
$(\Rightarrow)$ Supongamos que los vectores $u=(u_1,u_2)$ y $v=(v_1,v_2)$ son paralelos. Si $u$ y $v$ son paralelos, entonces uno es un múltiplo escalar del otro. Sin pérdida de generalidad, supongamos que $u = k v$ para algún escalar $k \in \mathbb{R}$. Esto significa que:
$$u_1 = kv_1 \quad \text{y} \quad u_2 = kv_2.$$
Sustituyendo estas expresiones en $u_1v_2-u_2v_1$, obtenemos:
Por lo tanto, si $u$ y $v$ son paralelos, entonces $u_1v_2-u_2v_1 = 0$.
$(\Leftarrow)$ Ahora supongamos que $u_1v_2-u_2v_1 = 0$. Queremos demostrar que $u$ y $v$ son paralelos. La condición $u_1v_2-u_2v_1 = 0$ se puede reescribir como $u_1v_2 = u_2v_1$.
Como $v$ no es el vector nulo, tenemos los siguientes casos:
Caso 1: $v_1 \neq 0$. De la igualdad $u_1v_2 = u_2v_1$, podemos despejar $u_2$ como $u_2 = \frac{u_1v_2}{v_1}$. Definamos $k = \frac{u_1}{v_1}$. Entonces, $u_1 = kv_1$. Sustituyendo $u_1$ en la expresión para $u_2$: $$u_2 = \frac{(kv_1)v_2}{v_1} = kv_2.$$ Así, tenemos $u_1 = kv_1$ y $u_2 = kv_2$, lo que implica que $$u = (u_1, u_2) = (kv_1, kv_2) = k(v_1, v_2) = kv.$$ Por lo tanto, $u$ es un múltiplo escalar de $v$, y son paralelos.
Caso 2: $v_1 = 0$. Dado que $v \neq (0,0)$, si $v_1 = 0$, entonces $v_2 \neq 0$. La condición $u_1v_2 = u_2v_1$ se convierte en $u_1v_2 = u_2 \cdot 0$, lo que implica $u_1v_2 = 0$. Como $v_2 \neq 0$, debemos tener $u_1 = 0$. En este subcaso, los vectores son $v=(0,v_2)$ y $u=(0,u_2)$. Estos vectores son paralelos pues ambos están en el eje $y$. Más concretamente, $u=\frac{u_2}{v_2} v$.
En ambos casos, si $u_1v_2-u_2v_1 = 0$, los vectores $u$ y $v$ son paralelos.
$\square$
Así, la expresión $u_1v_2-u_2v_1$ parece ser muy importante para nuestro problema de determinar la intersección de dos rectas. En efecto, en las siguientes secciones volverá a aparecer.
Intersección de rectas en forma normal
La siguiente proposición nos dice exactamente cómo es la intersección de dos rectas una vez que las tenemos en forma normal.
Proposición. Sean $a_1,a_2$ vectores no nulos de $\mathbb{R}^2$ y $b_1,b_2$ número reales. Consideremos las siguientes dos rectas en forma normal:
Esto es un sistema de ecuaciones lineales. Analicemos las posibilidades:
Caso 1: $a_1$ y $a_2$ no son vectores paralelos. Según la proposición anterior, dos vectores $a_1=(a_{11},a_{12})$ y $a_2=(a_{21},a_{22})$ no son paralelos si y sólo si la expresión $a_{11}a_{22}-a_{12}a_{21}$ es distinta de cero. Multiplicando la primera ecuación por $a_{21}$ y la segunda ecuación por $a_{11}$ obtenemos lo siguiente: \begin{align*} a_{21}(a_{11}x + a_{12}y) &= a_{21}b_1 \\ a_{11}(a_{21}x + a_{22}y) &= a_{11}b_2 \end{align*} Lo que resulta en el sistema equivalente: \begin{align*} a_{11}a_{21}x + a_{12}a_{21}y &= a_{21}b_1 \\ a_{11}a_{21}x + a_{11}a_{22}y &= a_{11}b_2 \end{align*} Restando la primera ecuación de la segunda, eliminamos $x$ y obtenemos: \begin{align*} (a_{11}a_{21}x + a_{11}a_{22}y) – (a_{11}a_{21}x + a_{12}a_{21}y) &= a_{11}b_2 – a_{21}b_1 \\ (a_{11}a_{22} – a_{12}a_{21})y &= a_{11}b_2 – a_{21}b_1 \end{align*} Dado que $a_{11}a_{22}-a_{12}a_{21} \neq 0$, podemos despejar $y$ para obtener un valor único. De manera análoga, se puede encontrar un valor único para $x$. Esto demuestra que existe una única solución $(x,y)$ para el sistema, lo que significa que la intersección de $\ell_1$ y $\ell_2$ es única.
Caso 2: $a_1$ y $a_2$ son vectores paralelos, y $b_1=kb_2$ para algún $k \in \mathbb{R}$. Si $a_1$ y $a_2$ son paralelos, entonces $a_1 = ka_2$ para algún escalar $k \in \mathbb{R}$ (ya que $a_1$ y $a_2$ son vectores no nulos). Esto implica que $a_{11} = ka_{21}$ y $a_{12} = ka_{22}$. La ecuación de la recta $\ell_1$ es $a_{11}x + a_{12}y = b_1$. Sustituyendo las expresiones para $a_{11}$ y $a_{12}$ en esta ecuación, obtenemos: \begin{align*} (ka_{21})x + (ka_{22})y &= b_1 \\ k(a_{21}x + a_{22}y) &= b_1 \end{align*} Sabemos que para los puntos en $\ell_2$, se cumple $a_{21}x + a_{22}y = b_2$. Sustituyendo esto en la ecuación anterior, obtenemos $kb_2 = b_1$. Si se cumple la condición $b_1=kb_2$, entonces la ecuación de $\ell_1$ se convierte en $k(a_{21}x + a_{22}y) = kb_2$. Dado que $a_1$ es no nulo, $k$ no puede ser cero. Podemos dividir por $k$ para obtener $a_{21}x + a_{22}y = b_2$. Esta es exactamente la ecuación de la recta $\ell_2$. Por lo tanto, ambas ecuaciones representan la misma recta, y su intersección es la recta completa.
Caso 3: $a_1$ y $a_2$ son vectores paralelos, y $b_1 \neq kb_2$ para algún $k \in \mathbb{R}$. Similar al Caso 2, si $a_1$ y $a_2$ son paralelos, entonces $a_1 = ka_2$ para algún $k \in \mathbb{R}$. Esto lleva a que la ecuación de $\ell_1$ pueda escribirse como $k(a_{21}x + a_{22}y) = b_1$. Si existiera un punto $(x,y)$ en la intersección de $\ell_1$ y $\ell_2$, debería satisfacer ambas ecuaciones. Es decir, $a_{21}x + a_{22}y = b_2$ (por ser un punto de $\ell_2$) y $k(a_{21}x + a_{22}y) = b_1$ (por ser un punto de $\ell_1$). Sustituyendo la primera en la segunda, obtendríamos $kb_2 = b_1$. Sin embargo, la condición de este caso es que $b_1 \neq kb_2$. Esto significa que no puede haber ningún punto $(x,y)$ que satisfaga ambas ecuaciones simultáneamente. Por lo tanto, las rectas son paralelas y distintas, y su intersección es vacía.
$\square$
Ejemplo de rectas iguales
Veamos ahora ejemplos de cada una de estas posibilidades:
Ejemplo. Encuentra la intersección de las rectas dadas por las siguientes ecuaciones.
Dado que la expresión es cero, los vectores $a_1$ y $a_2$ son paralelos. De hecho, por inspección notamos que $(1,-2) = -\frac{1}{2}(-2,4)$.
Notemos que también sucede que $b_1=3=-\frac{1}{2}6$. Según la proposición, las rectas son entonces la misma. Por lo tanto, la intersección de las dos rectas es la recta misma, $\ell_1$. Podemos escribir la solución como el conjunto de puntos $(x,y)$ que satisfacen $x – 2y = 3$.
$\triangle$
Ejemplo de rectas que no se intersectan
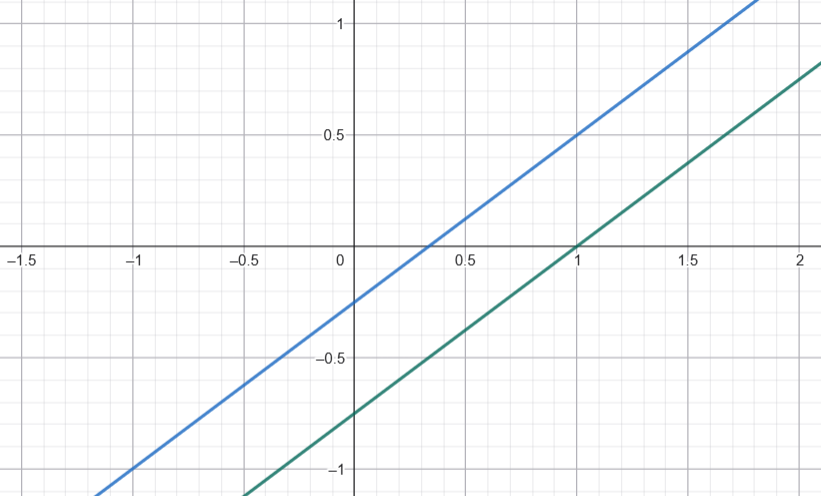
Ejemplo. Encuentra la intersección de las rectas dadas por las siguientes ecuaciones:
Como obtenemos cero, los vectores $a_1$ y $a_2$ son paralelos. Esto significa que $a_1 = ka_2$ para algún escalar $k$. En efecto, $a_1= -\frac{1}{2} a_2$. Sin embargo, ahora $-\frac{1}{2} b_2 = 1 \neq 3 = b_1$. Esto significa que las rectas son paralelas y distintas.
Por lo tanto, la intersección de las dos rectas es vacía.
$\triangle$
La siguiente figura muestra ambas rectas. En efecto, las rectas parecen ser paralelas.
Ejemplo de rectas que se intersectan en un único punto
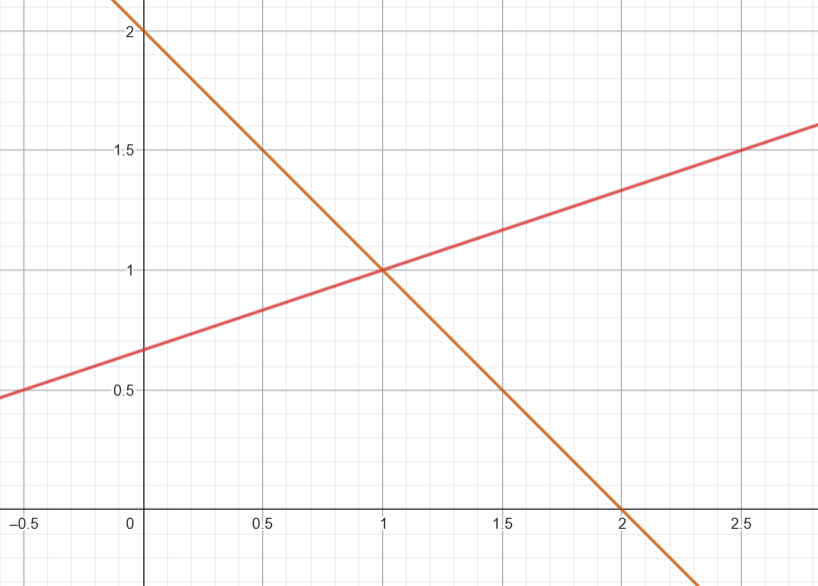
Ejemplo. Determina dónde se intersectan la recta paralela a $(3,1)$ que pasa por el punto $(1,1)$ y la recta perpendicular a $(2,2)$ que pasa por el punto $(5,-3)$.
Solución. Para poder usar los resultados de esta entrada, primero pasaremos cada una de estas ecuaciones a forma normal $a \cdot (x,y) = b$.
Recta 1: Paralela a $(3,1)$ y pasa por $(1,1)$.
Si la recta es paralela al vector $(3,1)$, su vector normal $a_1$ debe ser perpendicular a $(3,1)$. Un vector perpendicular a $(3,1)$ es, por ejemplo, $a_1 = (-1,3)$.
La ecuación de la recta es de la forma $-x + 3y = b_1$. Para encontrar $b_1$, sustituimos el punto $(1,1)$ por el que pasa la recta:
$$b_1= -(1) + 3(1) = 2.$$
Así, la primera recta en forma normal es $\ell_1 =\{(-1,3) \cdot (x,y) = 2\}$, correspondiente a la ecuación $-x+3y=2$.
Recta 2: Perpendicular a $(2,2)$ y pasa por $(5,-3)$.
Si la recta es perpendicular al vector $(2,2)$, entonces su vector normal $a_2$ es $(2,2)$.
La ecuación de la recta es de la forma $2x + 2y = b_2$. Para encontrar $b_2$, sustituimos el punto $(5,-3)$ por el que pasa la recta:
$$b_2 = 2(5)+2(-3)=4.$$
Así, la segunda recta en forma normal corresponde a la ecuación $2x+y=4$, que es equivalente a $x+y=2$. Así, podemos ponerle en forma normal como $\ell_2=\{(1,1) \cdot (x,y) = 2\}$.
De este modo, encontrar los puntos de intersección de las rectas corresponde a resolver el siguiente sistema de ecuaciones:
$$\begin{cases} -x + 3y = 2\\ x + y = 2. \end{cases}$$
Identificamos los vectores normales $a_1 = (-1,3)$ y $a_2 = (1,1)$. Veamos si $a_1$ y $a_2$ son paralelos. Para ello, calculamos la expresión $a_{11}a_{22}-a_{12}a_{21}$:
Dado que el resultado no es cero, los vectores $a_1$ y $a_2$ no son paralelos. Según la proposición, esto significa que la intersección de las dos rectas es un punto único, que podemos encontrar resolviendo el sistema de ecuaciones. Sumando la primera ecuación con la segunda:
Como $y$ es $1$, entonces de la segunda igualdad concluimos que $x=1$ también. Por lo tanto, las rectas se intersecan en el punto $(1,1)$.
$\triangle$
La siguiente figura muestra ambas rectas. La visualización coincide con lo que demostramos formalmente.
Más adelante…
Hemos entendido cómo se ve la intersección de rectas a partir de su forma normal. Pero la forma normal de una recta no sólo nos ayuda a hablar de la recta misma. Una pequeña variación nos permite hablar también de cada uno de los dos pedazos en los que queda dividido el plano por la recta. A cada uno de estos pedazos le llamamos semiplano. ¿Cómo se verá la intersección de semiplanos? Daremos una introducción a estas ideas en la siguiente entrada.
Tarea moral
De la siguiente lista de vectores, identifica todos aquellos $u$ y $v$ que cumplan que $u$ es paralelo a $v$: \begin{align*}&(1,1), (3,3), (5,2), (2,5), (10,4), \\&(-5,-2), (-3,3), (2,-2), (4,0), (5,1).\end{align*}
Encuentra la intersección de las siguientes parejas de rectas:
$2x+3y=1$ y $3x+2y=2$.
$15+20y=12$ y $-6x-8y=7$.
$x+y=1$ y $-x-y=-1$.
En los resultados de esta entrada hemos pedido que los vectores $u$ y $v$ sean no nulos para que las rectas en forma normal estén bien definidas. Pero si alguno de estos vectores es cero, todavía se pueden plantear un sistema de dos ecuaciones. ¿Qué posibilidades hay para estos sistemas de ecuaciones?
Si tenemos vectores $u$, $v$ y $w$ en el plano, muestra que están en una misma línea si y sólo si $u-v$ y $w-v$ son paralelos.
Toma tres vectores $u$, $v$ y $w$ de modo que no estén en una misma línea. La altura desde $u$ es la recta por $u$, perpendicular a $v-w$. De manera análoga se definen las alturas por $v$ y $w$.
Encuentra la intersección de la altura por $u$ y la altura por $v$.
Encuentra la intersección de la altura por $u$ y la altura por $w$.
Demuestra analíticamente, con las técnicas que hemos platicado aquí, que las tres alturas pasan por un mismo punto.
(Trabajo de titulación asesorado por la Dra. Diana Avella Alaminos)
INTRODUCCIÓN
En el mundo de las transformaciones lineales, algunas tienen una propiedad muy especial: no solo transforman el espacio, sino que permiten deshacer esa transformación sin perder nada en el camino. Estas son las transformaciones invertibles, y entenderlas es como tener la llave que abre y cierra una puerta sin cambiar lo que hay al otro lado. Nos permiten movernos entre espacios de forma reversible, conservando toda la información.
«Ir y venir» de un espacio a otro da ventajas enormes En estos casos, las transformaciones no crean un cambio permanente, podemos pensarlo también como un puente que permite retornar
Cuando una transformación lineal no solo es invertible, sino que además conecta completamente dos espacios —sin dejar nada fuera y sin repetir información— decimos que es un isomorfismo. Estudiar estas transformaciones nos ayuda a ver cuándo dos espacios son, en esencia, «el mismo» desde el punto de vista de la estructura lineal. Reconocer estas equivalencias abre la puerta a simplificar problemas complejos y entender mejor la relación entre distintos espacios matemáticos.
Teorema (2.7.1.): Sean $V$ y $W$ dos $K$ – espacios vectoriales de dimensión finita con $\dim V=\dim W$ y $T\in\mathcal{L}(V,W)$. Las siguientes condiciones son equivalentes:
a) $T$ es invertible b) $T$ es inyectiva c) $T$ es suprayectiva d) Para toda $\beta =\{ v_1,v_2,…,v_n\}$ base de $V$, $\{ T(v_1),T(v_2),…,T(v_n) \}$ es una base de $W$ e) Existe $\beta =\{ v_1,v_2,…,v_n \}$ una base de $V$ tal que $\{ T(v_1),T(v_2),…,T(v_n) \}$ es una base de $W$
Demostración: Veamos la cadena de implicaciones.
a) $\Rightarrow$ b) Sup. que $T$ es invertible.
Por lo visto en la entrada anterior, tenemos que $T$ es biyectiva. En particular, $T$ es inyectiva.
b) $\Rightarrow$ c) Sup. que $T$ es inyectiva.
Entonces $Núc T=\{ \theta_V\}$. De modo que $\dim Núc T=0$. Por el Teorema de la dimensión (2.3.1.), $\dim V =\dim NúcT+\dim ImT=\dim ImT$.
Como $\dim W=\dim V$, entonces $\dim W=\dim ImT$. Y sabemos que $ImT\leqslant W$, así que al tener la misma dimensión resulta que $ImT=W$. Por lo tanto, $T$ es suprayectiva.
c) $\Rightarrow$ d) Sup. que $T$ es suprayectiva.
Sea $\beta =\{ v_1,v_2,…,v_n\}$ una base de $V$.
Sabemos que $\langle T(v_1),T(v_2),…,T(v_n) \rangle\subseteq W$. Veamos que tenemos también la otra igualdad. Sea $w\in W$.
Como $T$ es suprayectiva, $\exists v\in V(T(v)=w)$. Y como $\beta$ es base de $V$, entonces existen únicos $\lambda_1,\lambda_2,…,\lambda_n\in K$ tales que $v=\sum_{i=1}^{n}(\lambda_i v_i)$.
Entonces $w=T(v)=T(\sum_{i=1}^{n}(\lambda_i v_i))$$=\sum_{i=1}^{n}(\lambda_i T(v_i))\in \langle T(v_1),T(v_2),…,T(v_n) \rangle$.
Así, $W=\langle T(v_1),T(v_2),…,T(v_n) \rangle$.
Y como $\dim W=\dim V$ y es finita, entonces $\{ T(v_1),T(v_2),…,T(v_n) \}$ debe ser l.i. Por tanto, $\{ T(v_1),T(v_2),…,T(v_n) \}$ es base de $W$.
d) $\Rightarrow$ e) Sup. que para toda $\beta =\{ v_1,v_2,…,v_n\}$ base de $V$, $\{ T(v_1),T(v_2),…,T(v_n) \}$ es una base de $W$.
Como todo espacio vectorial tiene al menos una base, entonces es inmediato concluir que existe al menos una base $\beta =\{ v_1,v_2,…,v_n \}$ una base de $V$ tal que $\{ T(v_1),T(v_2),…,T(v_n) \}$ es una base de $W$.
e) $\Rightarrow$ a) Sup. que $\beta =\{ v_1,v_2,…,v_n \}$ es una base de $V$ tal que $\{ T(v_1),T(v_2),…,T(v_n) \}$ es una base de $W$.
Entonces $W=\langle T(v_1),T(v_2),…,T(v_n) \rangle\leqslant Im(T)\leqslant W$. De donde, $W=Im(T)$. Por lo tanto, $T$ es suprayectiva.
Ahora, sea $v\in NúcT$ y sean $\lambda_1,\lambda_2,…,\lambda_n\in K$ tales que $v=\sum_{i=1}^{n}(\lambda_i v_i)$. Entonces $\theta_W=T(v)=T(\sum_{i=1}^{n}(\lambda_i v_i))=\sum_{i=1}^{n}(\lambda_i T(v_i))$. Y como $\{ T(v_1),T(v_2),…,T(v_n) \}$ es base de $W$, resulta que $\theta\notin \{ T(v_1),T(v_2),…,T(v_n) \}$.
Así, $\theta_W=\sum_{i=1}^{n}(\lambda_i T(v_i))$ implica que $\forall i\in\{1,2,…,n\}(\lambda_1=\lambda_2=…=\lambda_n=0)$. Y $v=\sum_{i=1}^{n}(\lambda_i v_i)=\sum_{i=1}^{n}(0 v_i)=\theta_V$. De donde, $NúcT=\{\theta_V\}$. Por lo tanto $T$ es inyectiva.
Por lo tanto, $T$ es biyectiva.
Teorema (2.7.2.): Sean $V,W$ $K$ – espacios vectoriales con $V$ de dimensión finita. Si existe $T\in\mathcal{L}(V,W)$ invertible. Entonces $W$ es de dimensión finita y $\dim V=\dim W.$
Demostración: Sup. que existe $T\in\mathcal{L}(V,W)$ invertible.
Por el teorema 2.7.1., $T$ es biyectiva. Como es suprayectiva, $Im T=W$. Por lo que $\dim (ImT)=\dim W$. Como es inyectiva, $Núc T=\{\theta_V \}$. Por lo que $\dim(Núc T)=0$.
Por el teorema de la dimensión (2.3.1.) $\dim V=\dim (Núc T)+\dim (Im T)$$=0+\dim (ImT)=\dim (ImT)=\dim W$.
Como $V$ es de dimensión finita y $\dim V=\dim W$, entonces $W$ es de dimensión finita.
ISOMORFISMO
Definición: Sean $V,W$ $K$ – espacios vectoriales. Decimos que $V$ es isomorfo a $W$, denotado como $V\cong W$, si existe $\varphi \in\mathcal{L}(V,W)$ invertible. A $\varphi$ le llamamos isomorfismo de $V$ en $W$.
Ejemplos
Sea $T : \mathbb{R}^2 \longrightarrow \mathbb{R}^2$. $\varphi(x, y) = (x + y, x – y)$ es un isomorfismo entre $\mathbb{R}^2$ y $\mathbb{R}^2$
Justificación. Sean $u = (x_1, y_1) , v = (x_2, y_2) \in \mathbb{R}^2$ y $\lambda \in \mathbb{R}$.
Por el teorema (2.7.1.) es suficiente con mostrar que $\varphi$ es inyectiva.
Supongamos que $\varphi(x, y) = (0, 0)$. Entonces $(x+y, x-y) = (0,0) Así, $x + y = 0 = x – y = 0$
Resolviendo el sistema de ecuaciones tenemos que $x=y=0$
Así, $\ker( \varphi ) = \{ (0, 0) \}$. Por el teorema (2.3.2.) esto es equivalente a que $\varphi$ es inyectiva.
$\therefore \varphi$ es un isomorfismo entre $\mathbb{R}^2$ y $\mathbb{R}^2$
Sea $M = \left\{ \begin{pmatrix} a & b \\ 0 & 0 \end{pmatrix} | a, b \in \mathbb{R} \right\} \leqslant M_{2 \times 2}(\mathbb{R})$. $\varphi : \mathbb{R}^2 \longrightarrow M$ definida para cada $(x,y) \in \mathbb{R}^2$ como $\varphi(x, y) = \begin{pmatrix} x & y \\ 0 & 0 \end{pmatrix}$ es un isomorfismo entre $\mathbb{R}^2$ y $M$
Justificación. Sean $u = (x_1, y_1)$, $v = (x_2, y_2)$ en $\mathbb{R}^2$ y $\lambda \in \mathbb{R}$.
Por el teorema (2.7.1.) es suficiente con mostrar que $\varphi$ es inyectiva.
Supongamos que $\varphi(x, y) = \varphi(x’, y’)$. Es decir, $\begin{pmatrix} x & y \\ 0 & 0 \end{pmatrix} = \begin{pmatrix} x’ & y’ \\ 0 & 0 \end{pmatrix}$ Por lo tanto, $x = x’$, $y = y’$ Y como llegamos a la conclusión de que necesariamente $(x,y) = (x’,y’)$, entonces $\varphi$ es inyectiva.
$\therefore \varphi$ es un isomorfismo entre $\mathbb{R}^2$ y $M$
Teorema (2.7.3.): Sean $V,W$ $K$ – espacios vectoriales de dimensión finita. Entonces: $V\cong W$ si y sólo si $\dim V=\dimW$.
Demostración: Veamos cada implicación.
$\Rightarrow$) Sup. que $V\cong W$.
Por def. existe $\varphi\in\mathcal{L}(V,W)$ invertible.
Por el teorema (2.7.2.), $\dim V=\dim W$.
$\Leftarrow$) Sup. $\dim V=\dim W$.
Digamos que $\dim V=n=\dim W$ donde $n\in\mathbb{N}$.
Sean $\{ v_1,v_2,…,v_n\}$ base de $V$ y $\{ w_1,w_2,…,w_n\}$ de $W$. Sabemos que existe $S\in\mathcal{L}(V,W)$ tal que $\forall i\in\{ 1,2,…,n \}(S(v_i)=w_i)$. Así, $\{ w_1,w_2,…,w_n\}=\{ T(v_1),T(v_2),…,T(v_n)\}$ y por lo tanto, $\{ T(v_1),T(v_2),…,T(v_n)\}$ es base de $W$.
Por el teorema (2.7.1.), $S$ es invertible. Así, $S$ es un isomorfismo de $V$ en $W$.
Por lo tanto $V\cong W$.
Corolario (2.7.4.): Si $V$ es un $K$ espacio vectorial de dimensión finita $n$. Entonces $V\cong K^{n}$.
Demostración: Como $V$ es un espacio vectorial de dimensión $n$, existe una base ordenada $\beta = { v_1 , v_2 , … , v_n }$ de $V$.
Definimos entonces la transformación $\varphi: V \longrightarrow K^n$ como $\varphi(v) = (\lambda_1, \lambda_2, …, \lambda_n)$ y así para cada vector en $V$ usaremos la combinación lineal que le corresponde con la base $\beta$.
Viendo que $\varphi$ es lineal y biyectiva, exponemos que es un isomorfismo de espacios vectoriales y por lo tanto, $V \cong K^n$.
Tarea Moral
Sea $T : \mathbb{R}^2 \longrightarrow \mathbb{R}^2$ tal que $\forall (x,y) \in \mathbb{R}^2 (T (x,y) = (5x + 2y , 3x-y) )$ Prueba que $T$ es invertible y encuentra $T^{-1}$
Sean $K$ campo y $V = \left\{ \begin{pmatrix} a & a+b \\ 0 & c \end{pmatrix} | a,b,c \in K \right\}$ Determina si $V$ es isomorfismo a $K^3$ y si lo es construye un isomorfismo de $V$ a $K^3$
Demuestra que la transformación $\varphi$ definida en la demostración del corolario (1.7.4.) es un isomorfismo.
Más adelante…
Veremos muy brevemente los conceptos de base ordenada y vector de coordenadas.
Entenderemos por qué a veces conviene manejar conjuntos con un orden determinado en lugar de solo manejarlo como un listado indistinto… Al fin y al cabo, manejar transformaciones con matrices resulta muy útil y al hablar de matrices, es natural solicitar orden.