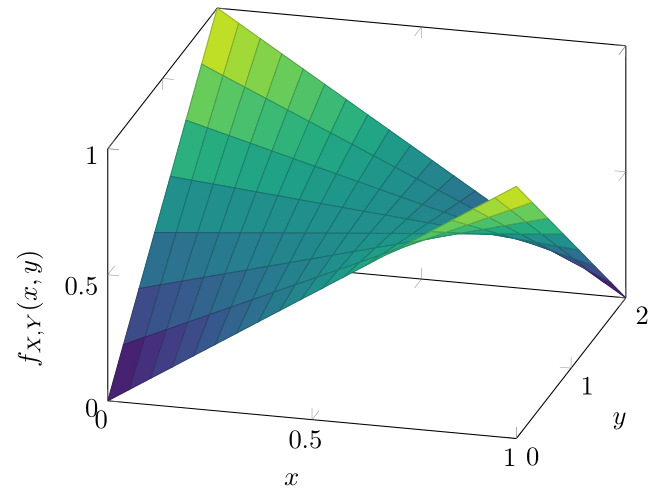En esta nueva entrada abordaremos a las operaciones entre conjuntos desde una perspectiva diferente: el álgebra. Veremos que existe otra forma de probar la igualdad entre conjuntos sin necesidad de usar la demostración por doble contención.
Algunos recordatorios
En el álgebra de conjuntos lo que se hace es primero probar algunas propiedades fundamentales de las operaciones de conjuntos, y usar estas propiedades repetidamente para demostrar otras, aprovechando que la igualdad de conjuntos es transitiva. Es por ello que nos conviene recopilar varias propiedades de las operaciones que tenemos hasta ahora.
Sean $A$, $B$, $C$ y $X$ conjuntos tales que $A, B,C\subseteq X$. Entonces:
Hay otras propiedades que ya hemos demostrado, pero no las pusimos aquí. Podríamos ponerlas para ir recopilando más cosas que sabemos que son válidas.
Demostraciones con álgebra de conjuntos
Ahora veremos algunos ejemplos de cómo se trabaja con álgebra de conjuntos. En varias de las siguientes proposiciones enunciamos resultados para cuando $A$ y $B$ son subconjuntos de un conjunto en común $X$. Toma en cuenta que para $A$ y $B$ arbitrarios, siempre podemos tomar $X=A\cup B$.
Proposición. Sean $A, B\subseteq X$ conjuntos. Prueba que $A\setminus B= A\setminus (A\cap B)$.
Tras realizar estas demostraciones es importante notar que muchas veces hacer el uso del álgebra nos ayuda a ahorrar tiempo. Sin embargo, para poder lograr esto es necesario utilizar muchas de las propiedades que sí hemos demostrado previamente por doble contención.
Tarea moral
Realiza las siguientes demostraciones haciendo uso del álgebra de conjuntos:
Prueba que para $A, B, C, X$ conjuntos tales que $A, B, C\subseteq X$ se cumple que: $(A\setminus B)\setminus (A\setminus C)= (A\cap C)\setminus B$.
Prueba que $(A\setminus B)\setminus (A\setminus C)=A\cap (C\setminus B)$.
Si $A, B\subseteq X$, entonces $(X\setminus A)\setminus (X\setminus B)=B\setminus A$.
Sean $A$ y $B$ conjuntos. Entonces $A\setminus (B\cap C)=(A\setminus B)\cap (A\setminus C)$.
Más adelante…
En la siguiente entrada definiremos una nueva operación entre conjuntos: la diferencia simétrica. Retomaremos los resultados que hemos visto hasta ahora y seguiremos haciendo uso del álgebra de conjuntos para demostrar algunas propiedades de esta nueva operación.
Trabajo realizado con el apoyo del Programa UNAM-DGAPA-PAPIME PE109323 «Hacia una modalidad a distancia de la Licenciatura en Matemáticas de la FC-UNAM – Etapa 3»
En esta entrada veremos un concepto que se relaciona cercanamente con el valor esperado: la varianza. Así como el valor esperado, la varianza será una cantidad numérica que tiene la intención de resumir numéricamente otro aspecto del comportamiento probabilístico de una variable aleatoria. En este caso, lo que intentaremos resumir será la variabilidad respecto al valor esperado. Es decir, en promedio, ¿qué tanto se aleja una variable aleatoria del «centro» de su distribución?
Además, con las herramientas que tenemos hasta ahora, podemos desarrollar algunas propiedades de la varianza, que no serán difíciles de demostrar utilizando las herramientas de las últimas entradas sobre valor esperado.
Motivación y definición
Dada una v.a. \(X\colon\Omega\to\RR\), vimos que el valor esperado de \(X\), \(\Esp{X}\), es el valor promedio (a la larga) de \(X\). Es decir, que si observamos muchas veces a \(X\), el promedio de esas observaciones debe de acercarse a \(\Esp{X}\). Además, gracias a la ley del estadístico inconsciente, podemos calcular \(\Esp{g(X)}\), que es el valor promedio de \(g(X)\).
La varianza de una v.a. \(X\) se define como el valor esperado de una transformación particular de \(X\), y lo que busca cuantificar la dispersión promedio que tiene \(X\) con respecto a su valor esperado. Por ello, se propone la transformación \(v\colon\RR\to\RR\) dada por
Así, observa que \(v(X) = {\left(X − \Esp{X}\right)}^{2}\) es una v.a. cuyo valor tiene un significado especial: \(v(X)\) es la distancia entre \(X\) y su valor esperado, elevada al cuadrado. Por ello, \(\Esp{v(X)}\) es la distancia cuadrada promedio entre \(X\) y su valor esperado. Esta discusión da lugar a la definición de varianza.
Definición. Sea \(X\) una variable aleatoria. La varianza de \(X\), denotada con \( \mathrm{Var}(X) \), se define como sigue:
siempre que \({\left(X − \Esp{X} \right)}^{2}\) sea una v.a. con valor esperado finito. En tal caso, se dice que \(X\) tiene varianza finita.
Definiciones para el caso discreto y el caso continuo
Debido a la distinción entre valores esperados de v.a.’s discretas y continuas, la varianza tiene dos formas de calcularse directamente. Sin embargo, veremos más adelante en esta entrada que no es necesario hacer el cálculo directo, y puede hacerse mediante una expresión más sencilla.
Varianza (Caso discreto). Si \(X\) es una v.a. discreta, entonces la varianza de \(X\) tiene la siguiente expresión:
siempre que esta serie sea absolutamente convergente.
Varianza (Caso continuo). Si \(X\) es una v.a. continua con función de densidad \(f_{X}\), entonces la varianza de \(X\) puede escribirse de la siguiente manera:
Es importante observar que, independientemente del caso en el que nos encontremos, para calcular la varianza de \(X\) es necesario conocer el valor esperado de \(X\).
Terminología y notación usual
Existe cierta notación especial para la varianza que encontrarás en la literatura referente a probabilidad y estadística. Si \(X\) es una v.a., entonces suele denotarse a la varianza de \(X\) con \(\sigma^{2}\), o con \(\sigma_{X}^{2}\), en caso de que sea necesario saber qué v.a. es la varianza. Además, a la raíz cuadrada (positiva) de la varianza (que bajo esta notación sería \(\sigma\) o \(\sigma_{X}\)) se le conoce como desviación estándar. En resumen, si \(X\) es una v.a., entonces podrías encontrarte con fuentes que adoptan la siguiente notación:
\(\sigma_{X}^{2} := \mathrm{Var}(X)\) para denotar a la varianza.
\(\sigma_{X} := \sqrt{\mathrm{Var}(X)}\) para denotar a la desviación estándar.
Nostros no adoptaremos esta notación en general, pero hay una distribución de probabilidad en particular en la que sí la utilizaremos.
Propiedades de la varianza
Debido a que la varianza se define como un valor esperado, tiene algunas propiedades que son consecuencia de lo que hemos estudiado en las últimas entradas.
La primera propiedad es muy elemental, y establece que la varianza de cualquier v.a. es no-negativa.
Propiedad 1. Sea \(X\) una variable aleatoria. Entonces se cumple que
Si abusamos un poco de la notación, lo anterior quiere decir que si \(c\in\RR\) es un valor constante, entonces \( \mathrm{Var}(c) = 0\).
Demostración. Sea \(v\colon\RR\to\RR\) la transformación que define a la varianza (en este caso, para cada \(x\in\RR\), \(v(x) = x − \Esp{f_{c}}\)). Como \(\Esp{f_{c}} = c\), entonces se tiene que \(v(x) = x − c\). Así, \(v(f_{c})\) es la v.a. dada por
\begin{align*} v(f_{c}(\omega)) &= f_{c}(\omega) − c & \text{para cada \(\omega\in\Omega\).} \end{align*}
Además, como \(f_{c}(\omega) = c\) para cualquier \(\omega\in\Omega\), entonces se tiene que \(v(f_{c})\) es la v.a. constante igual a \(0\). En consecuencia,
La propiedad 2 tiene sentido, pues la dispersión promedio de una v.a. que puede tomar un único valor debe de ser \(0\).
La propiedad siguiente nos dice que la varianza es invariante ante traslaciones.
Propiedad 3. Sean \(X\) una variable aleatoria y \(c \in \RR\). Entonces
\begin{align*} \mathrm{Var}(X + c) &= \mathrm{Var}(X) . \end{align*}
Demostración. Podemos obtener este resultado directamente desarrollando la expresión de la varianza de \(X + c\), recordando que \(\Esp{X + c} = \Esp{X} + c\):
\begin{align*} \mathrm{Var}(X + c) &= \Esp{(X + c − \Esp{X + c})^{2}} \\[1em] &= \Esp{(X + c − (\Esp{X} + c))^{2}} \\[1em] &= \Esp{(X + c − \Esp{X} − c))^{2}} \\[1em] &= \Esp{(X − \Esp{X})^{2}} \\[1em] &= \mathrm{Var}(X) ,\end{align*}
que es precisamente lo que queríamos demostrar.
\(\square\)
La propiedad 3 quiere decir que si trasladamos una v.a. sumándole una constante, su dispersión promedio no se ve afectada, pues el comportamiento probabilístico sigue siendo el mismo, lo único que se cambia es el «centro» de la distribución. Es decir, la v.a. trasladada tiene el mismo comportamiento, pero centrado alrededor de un valor distinto, por lo que su variabilidad con respecto a ese nuevo centro será la misma.
La propiedad que sigue establece que la varianza saca constantes multiplicando al cuadrado.
Propiedad 4. Sean \(X\) una variable aleatoria y \(c\in\RR\). Entonces
Observa que al pasar de \((*)\) a \((**)\) usamos que \(−2\Esp{X} \in \RR\) es constante, por lo que «sale multiplicando».
$\square$
La propiedad 5 nos otorga una manera alternativa de calcular la varianza de una v.a. que nos será muy útil más adelante, en especial cuando hayamos visto el tema de la entrada siguiente.
¿La varianza «abre» la suma? ¡No siempre!
Como una última «propiedad», vamos a demostrar que, en general, la varianza no es lineal respecto a la suma. Esto es, en general se tiene que
Con lo anterior, es evidente que no siempre \(\mathrm{Var}(X+Y) = \mathrm{Var}(X) + \mathrm{Var}(Y)\), pues hay muchas v.a.’s para las cuales el valor \(\Esp{(X − \Esp{X})(Y − \Esp{Y})}\) es distinto de \(0\). Sin embargo, un caso en el que sí se cumple que la varianza abre la suma es cuando \(X\) y \(Y\) son independientes. En tal caso, basta con demostrar que si \(X\) y \(Y\) son independientes, entonces
De hecho, en el futuro verás que el valor \( \Esp{(X − \Esp{X})(Y − \Esp{Y})}\) es conocido como la covarianza entre \(X\) y \(Y\), que generalmente se denota con \(\mathrm{Cov}(X,Y)\), y busca cuantificar la relación que existe entre \(X\) y \(Y\). De este modo, el resultado de la Proposición 1 puede reescribirse como sigue:
Antes de terminar, incluimos una lista de las propiedades vistas (y demostradas) en esta entrada. Todas estarán disponibles para que las uses en tus tareas y exámenes, a menos que tu profesor o profesora indique lo contrario.
Propiedades de la Varianza. Sean \(X\) y \(Y\) variables aleatorias con varianza finita, y sea \(c\in\RR\). Entonces se cumplen las siguientes propiedades:
La varianza es no-negativa: \begin{align*}\mathrm{Var}(X) \geq 0,\end{align*}
La varianza de una constante es \(0\): \begin{align*}\mathrm{Var}(c) = 0,\end{align*}
Es invariante ante traslaciones: \begin{align*}\mathrm{Var}(X+c) = \mathrm{Var}{X},\end{align*}
Saca constantes multiplicando al cuadrado: \begin{align*}\mathrm{Var}(cX) = c^{2}\mathrm{Var}(X),\end{align*}
Expresión alternativa para la varianza: \begin{align*}\mathrm{Var}(X) = \Esp{X^{2}} − {\left(\Esp{X}\right)}^{2},\end{align*}
Varianza de la suma de dos v.a.’s:\begin{align*}\mathrm{Var}({X + Y}) &= \mathrm{Var}({X}) + \mathrm{Var}({Y}) + 2\Esp{(X − \Esp{X})(Y − \Esp{Y})}.\end{align*}
Tarea moral
Los siguientes ejercicios son opcionales. Es decir, no formarán parte de tu calificación. Sin embargo, te recomiendo resolverlos para que desarrolles tu dominio de los conceptos abordados en esta entrada.
Demuestra la Propiedad 1 de la varianza.
Demuestra también la Propiedad 4 de la varianza.
Usando la Proposición 1, demuestra que si \(X\) y \(Y\) son v.a.’s independientes, entonces\begin{align*} \mathrm{Var}({X + Y}) &= \mathrm{Var}({X}) + \mathrm{Var}({Y}). \end{align*}Sugerencia: En la entrada pasada vimos que cuando \(X\) y \(Y\) son independientes, \(\Esp{XY}\) se puede «abrir». Utilíza eso para ver que \(\Esp{(X − \Esp{X})(Y − \Esp{Y})} = 0\).
Más adelante…
Así como el valor esperado, la varianza es un concepto ubicuo en la probabilidad y la estadística. En conjunto, el valor esperado y la varianza son valores numéricos que resumen dos características del comportamiento de una variable aleatoria: la tendencia central y la variabilidad respecto a esa tendencia central. Por ello, incluso sin visualizar la densidad o masa de probabilidad de una v.a., estas cantidades pueden utilizarse para «darse una idea» de su aspecto y de su comportamiento.
En la entrada que sigue veremos un conjunto de valores asociados a la distribución de una variable aleatoria, conocidos como momentos.
Con esta entrada concluimos la unidad tres y en general temas relacionados con el triángulo, hablaremos de la circunferencia de Brocard y el primer triángulo de Brocard, veremos como se relacionan con los puntos de Brocard.
Circunferencia de Brocard
Definición. La circunferencia $\Gamma(KO)$ que tiene como diámetro el segmento que une el punto simediano $K$ y el circuncentro $O$ de un triángulo se conoce como circunferencia de Brocard.
El triángulo cuyos vértices son las segundas intersecciones de las mediatrices de un triángulo con su circunferencia de Brocard es el primer triángulo de Brocard.
Observación. Recordemos que el centro de la primera circunferencia de Lemoine es el punto medio entre el punto simediano y el circuncentro de un triángulo, por lo tanto, la circunferencia de Brocard y la primera circunferencia de Lemoine son concéntricas.
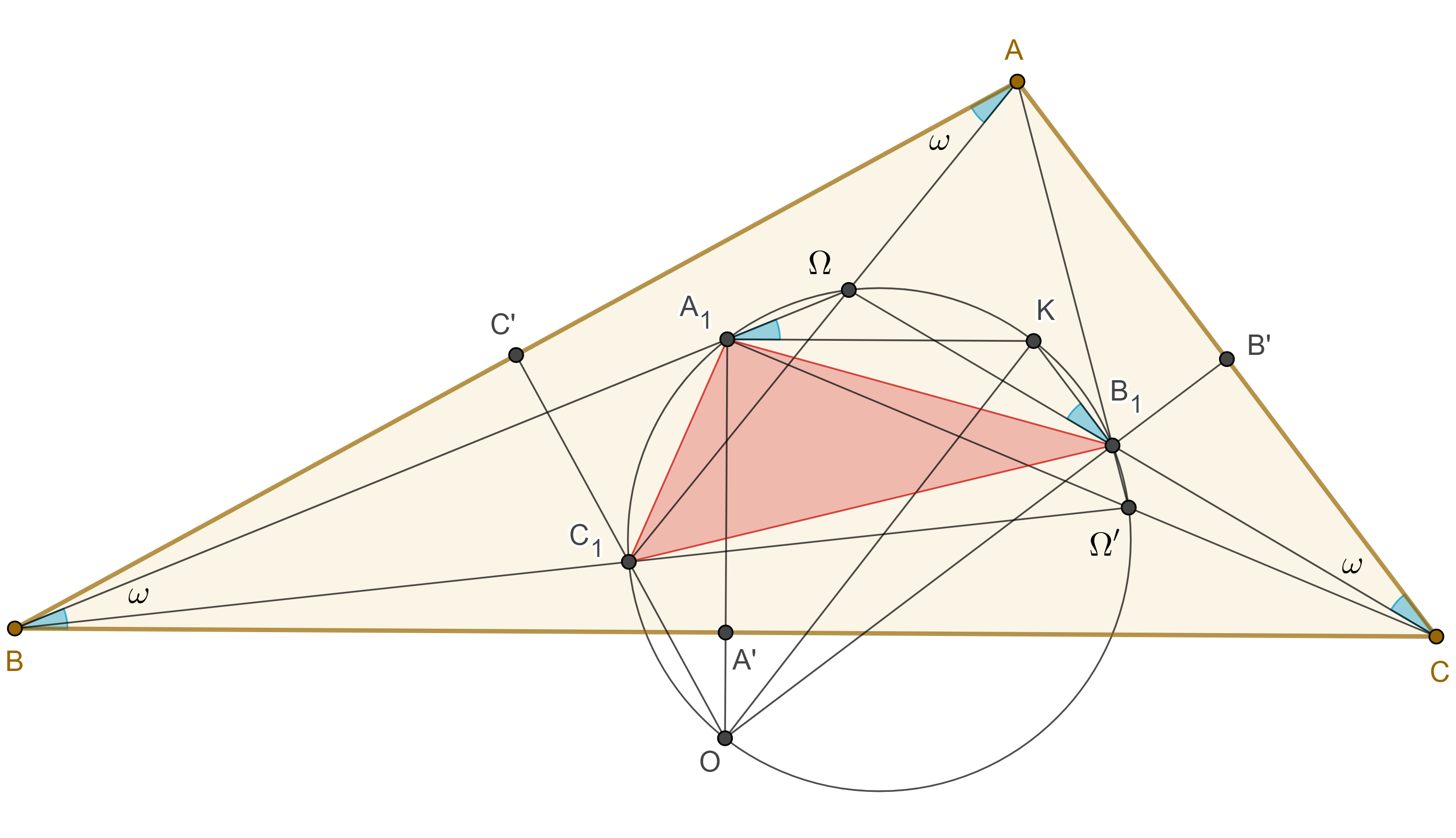
Teorema 1. Los puntos de Brocard están en la circunferencia de Brocard.
Demostración. En $\triangle ABC$ sea $\Omega$ el primer punto de Brocard, $K$ el punto simediano, $O$ el circuncentro y $A’$, $B’$, $C’$, los puntos medios de $BC$, $CA$ y $AB$ respectivamente.
Recordemos que las distancias de $K$ a los lados del triángulo son proporciónales a estos, $d(K, BC) = a \dfrac{2(\triangle ABC)}{a^2 + b^2 + c^2}$
Figura 1
En un ejercicio de la entrada anterior se pide mostrar que $\dfrac{1}{\tan \omega} = \cot \omega = \dfrac{a^2 + b^2 + c^2}{4(\triangle ABC)}$.
Donde $\omega$ es el ángulo de Brocard y $a$, $b$, $c$ los lados de $\triangle ABC$.
Por lo tanto, $d(K, BC) = \dfrac{a}{2} \tan \omega$.
Esto implica que $A_1K \parallel BC$, como $OA_1$ es mediatriz de $BC$ entonces $\angle OA_1K = \dfrac{\pi}{2}$, y por lo tanto $A_1 \in \Gamma (KO)$.
De manera similar si consideramos $B_1$ la intersección del rayo $C\Omega$ con la mediatriz de $CA$, podemos ver $B_1K \parallel CA$ y que $B_1 \in \Gamma(KO)$.
Como $A_1K \parallel BC$ y $B_1K \parallel CA$ entonces $\angle KA_1\Omega = \omega = \angle KB_1\Omega$.
En consecuencia, el cuadrilátero $\square \Omega A_1B_1K$ es cíclico, pero el circuncírculo de $\triangle A_1B_1K$, es la circunferencia de Brocard.
Por lo tanto, el primer punto de Brocard $\Omega$, está en la circunferencia de Brocard.
Sea $\Omega’$ el segundo punto de Brocard, como $A_1$ y $B_1$ están en las mediatrices de $BC$ y $CA$ entonces $\triangle A_1BC$ y $\triangle B_1CA$ son isósceles y $\angle A_1CB = \angle B_1AC = \angle \Omega’CB = \angle \Omega’AC = \omega$.
Esto implica que $CA_1$ y $AB_1$ se intersecan en $\Omega’$.
Ya que $A_1K \parallel BC$ y $B_1K \parallel CA$, entonces, $\angle \Omega’A_1K = \omega$ y $\angle KB_1\Omega’ = \pi – \omega$.
Esto implica que $\square A_1\Omega B_1K$ es cíclico, y así el segundo punto de Brocard está en la circunferencia de Brocard.
$\blacksquare$
Corolario 1. Un triángulo y su primer triángulo de Brocard están en perspectiva desde los puntos de Brocard.
Demostración. En el teorema anterior vimos que $BA_1$ y $CB_1$ se intersecan en el primer punto de Brocard, de manera similar se puede ver que $A$, $C_1$ y $\Omega$ son colineales.
También mostramos que $CA_1 \cap AB_1 = \Omega’$, de manera análoga podemos ver que $BC_1$ pasa por $\Omega’$.
Por lo tanto $\Omega$ y $\Omega’$ son centros de perspectiva de $\triangle ABC$ y $\triangle A_1B_1C_1$.
$\blacksquare$
Corolario 2. $\triangle ABC$ y su primer triángulo de Brocard son semejantes.
Demostración. Como $B_1K \parallel CA$, $A_1K \parallel BC$ y tomando en cuenta que $\square A_1C_1B_1K$ es cíclico entonces $\angle ACB = \pi – \angle A_1KB_1 = \angle B_1C_1A_1$.
De manera similar vemos que $\angle A = \angle A_1$ y $\angle B = \angle B_1$.
$\blacksquare$
Conjugado isotómico del punto simediano
En la entrada triángulos en perspectiva vimos que si dos triángulos tienen dos centros de perspectiva entonces existe un tercero, en la siguiente proposición describimos este punto.
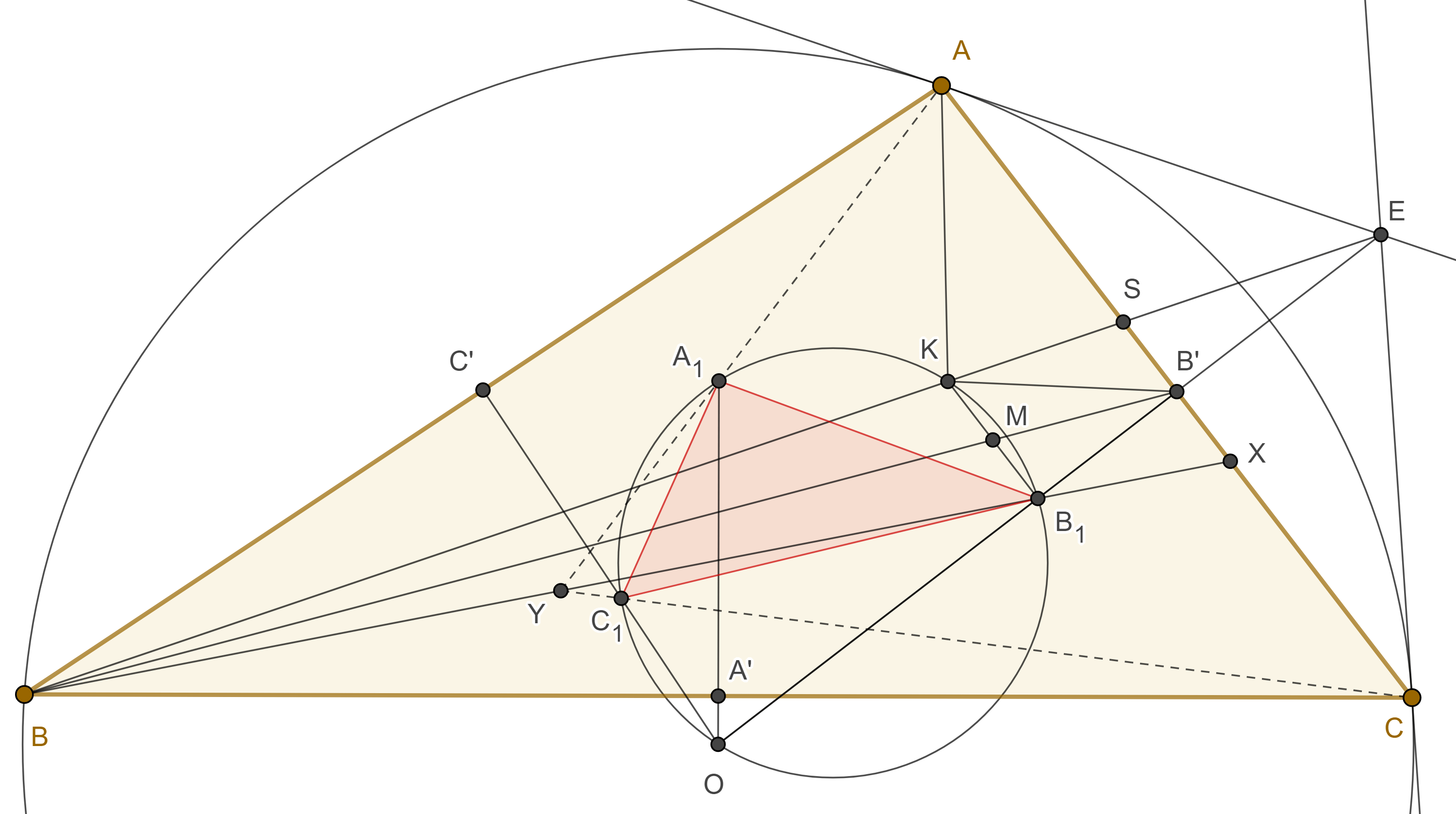
Proposición 1. El tercer centro de perspectiva entre un triángulo y su triángulo de Brocard es el conjugado isotómico del punto simediano respecto del triángulo original.
Demostración. Bajo la misma notación del teorema anterior, Recordemos que la $A$-simediana y la $A$-exsimediana son conjugadas armónicas respecto de $AB$, $AC$.
También sabemos que $BK$ y la $A$-exsimediana se intersecan en un punto exsimediano, es decir el punto de intersección de las tangentes por $A$ y $C$ al circuncírculo de $\triangle ABC$.
Figura 2
Sea $S = BK \cap AC$, entonces la hilera $BKSE$ es armónica, así, el haz $B’(BKSE)$ es armónico.
Tomando en cuenta que $OB_1B’E$ es una recta.
En el teorema anterior vimos que $B_1K \parallel AC$, entonces las otras tres rectas del haz bisecan a $B_1K$, es decir $BB’$ biseca a $B_1K$.
Sea $X = BB_1 \cap AC$, como $\triangle BB_1K$ y $\triangle BXS$ son semejantes entonces $B’$ es el punto medio entre $X$ y $S$.
Por lo tanto, $BK$, $BB_1$, son rectas isotómicas, es decir, unen puntos isotómicos con el vértice opuesto.
Igualmente vemos que $AK$, $AA_1$ y $CK$, $CC_1$ son rectas isotómicas, como las simedianas concurren en $K$, entonces, $AA_1$, $BB_1$, $CC_1$concurren en u punto $Y$.
$\blacksquare$
Centroide del triángulo de Brocard
Teorema 2. El centroide de un triángulo y el centroide de su primer triángulo de Brocard coinciden.
Demostración. Nuevamente emplearemos la notación del teorema 1.
Figura 3
$A_1$, $B_1$ y $C_1$ están en las mediatrices de $BC$, $CA$ y $AB$ entonces $\triangle A_1BC$, $\triangle B_1CA$, $\triangle C_1AB$ son isósceles, además son semejantes, pues $\angle A_1BC = \angle B_1CA = \angle C_1AB = \omega$, por lo tanto,
$\dfrac{AC_1}{AB_1} = \dfrac{AB}{CA}$ y $\dfrac{CA_1}{CB_1} = \dfrac{BC}{CA}$.
Sea $X$ la reflexión de $B_1$ respecto de $CA$, entonces $\angle C_1AX = \angle C_1AC + \angle CAX $ $= \angle C_1AC + \angle B_1AC = \angle C_1AC + \omega $ $= \angle A$,
además $\dfrac{AC_1}{AX} = \dfrac{AC_1}{AB_1} =\dfrac{AB}{CA}$.
Por criterio de semejanza LAL, $\triangle ABC \sim \triangle AC_1X$, igualmente podemos ver que $\triangle ABC \sim \triangle XA_1C$.
Por lo tanto, $\triangle AC_1X \sim \triangle XA_1C$, pero $AX = AB_1 = B_1C = CX$, así que $\triangle AC_1X$ y $\triangle XA_1C$ son congruentes.
En consecuencia, $C_1X = A_1C = A_1B$ y $XA_1 = AC_1 = C_1B$, esto implica que $\square C_1BA_1X$ es un paralelogramo y por lo tanto $A_1C_1$ y $BX$ se cortan en su punto medio $M$.
En $\triangle B_1BX$, $B_1M$ y $BB’$ son medianas, donde $B’$ es el punto medio de $B_1X$ y $CA$, por lo tanto, su intersección $G$, triseca a ambas medianas de $\triangle B_1BX$.
Pero el centroide de $\triangle ABC$ y de $\triangle A_1B_1C_1$ es el único punto con esa propiedad, por lo tanto, su centroide es el mismo.
$\blacksquare$
Concurrencia en el centro de los nueve puntos.
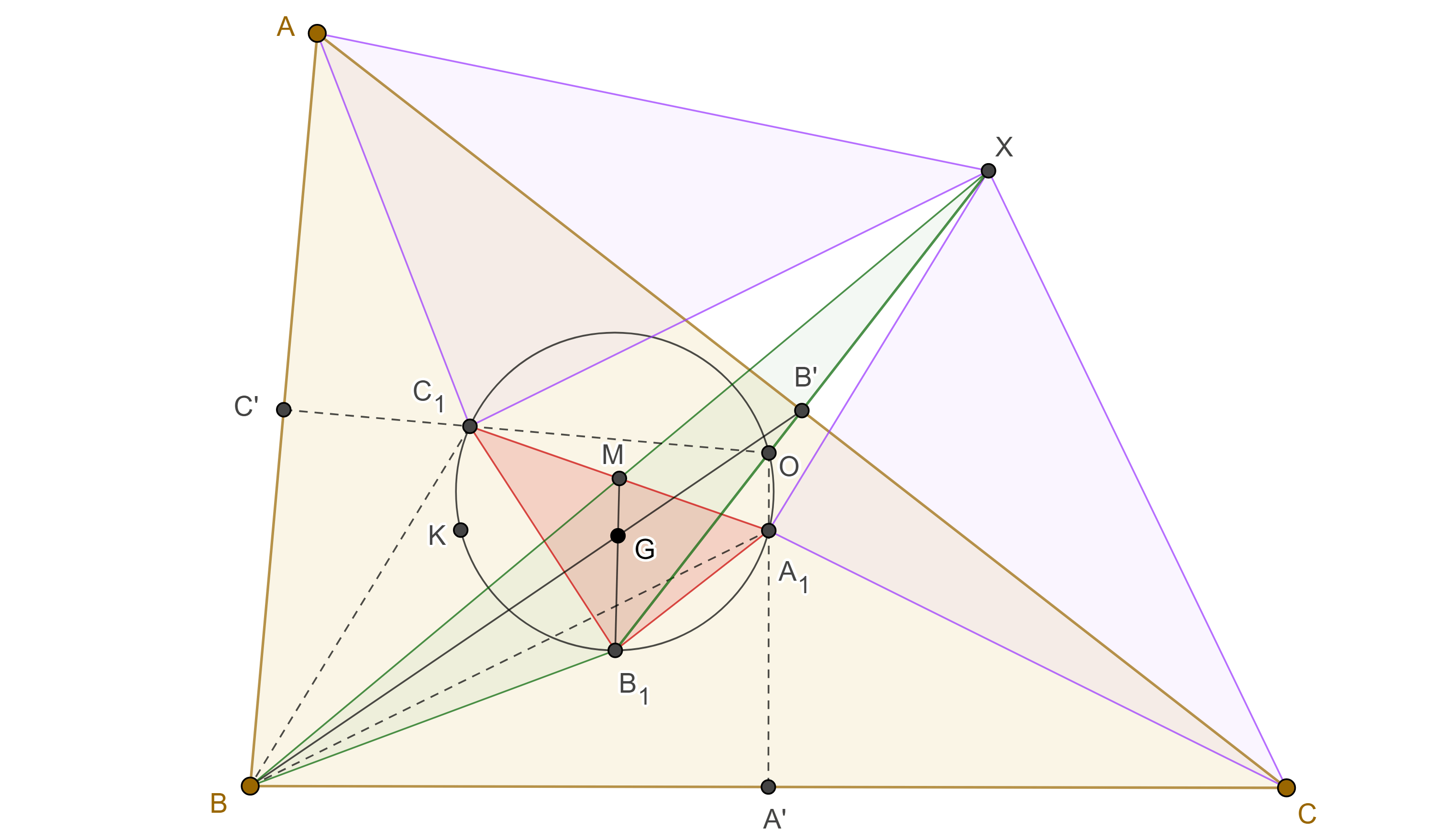
Proposición 3. Las perpendiculares a los lados de un triángulo desde los puntos medios de su primer triángulo de Brocard concurren en el centro de los nueve puntos.
Demostración. Sean $\triangle ABC$ y $\triangle A_1B_1C_1$ su primer triángulo de Brocard, $D$, $E$, $F$, los puntos medios de $B_1C_1$, $C_1A_1$, $A_1B_1$ respectivamente.
Figura 4
Notemos que las perpendiculares por $D$, $E$, $F$, a $BC$, $CA$, $AB$, respectivamente, son paralelas a $OA_1$, $OB_1$, $OC_1$ respectivamente, donde $O$ es el circuncentro de $\triangle ABC$.
Como $\triangle A_1B_1C_1$ y $\triangle DEF$, están en homotecia desde $G$, el centroide de $\triangle A_1B_1C_1$, y razón $\dfrac{- 1}{2}$, entonces los tres pares de rectas paralelas son pares de rectas homotéticas, pues pasan por puntos homólogos.
Como $OA_1$, $OB_1$, $OC_1$, concurren en $O$ entonces sus correspondientes rectas homotéticas concurren en el correspondiente punto homólogo, $O’$.
Entonces $O$, $G$ y $O’$ son colineales en ese orden y $\dfrac{OG}{2} = GO’$.
Como $G$ también es el centroide de $\triangle ABC$ entonces $O’$ es el centro de los nueve puntos de $\triangle ABC$.
$\blacksquare$
Punto de Steiner
Proposición 4. Las rectas paralelas (perpendiculares) por los vértices de un triángulo a los respectivos lados de su primer triángulo de Brocard concurren en el circuncírculo del triángulo original, el punto de concurrencia se conoce como punto de Steiner (Tarry).
Demostración. Si $\triangle A_1B_1C_1$ es el primer triángulo de Brocard de $\triangle ABC$, sea $S$ la intersección de la paralela a $A_1C_1$ por $B$ y la paralela a $A_1B_1$ por $C$.
Figura 5
$\angle BSC = \angle C_1A_1B_1 = \angle BAC$, por lo tanto, $S$ se encuentra en el arco $\overset{\LARGE{\frown}}{AB}$.
De manera análoga vemos que $CS$ y la paralela a $B_1C_1$ por $A$ se intersecan en el circuncírculo de $\triangle ABC$.
Por lo tanto, las paralelas concurren en $S$.
Considera $T$ el punto diametralmente opuesto a $S$, entonces $AT \perp AS \Rightarrow AT \perp B_1C_1$.
De manera similar vemos que $BT \perp A_1C_1$ y $CT \perp A_1B_1$.
Por lo tanto, las perpendiculares concurren en el circuncírculo de $\triangle ABC$.
$\blacksquare$
Más adelante…
Con la siguiente entrada comenzaremos la última unidad en la que hablaremos sobre cuadriláteros, mostraremos algunos teoremas que establecen propiedades análogas a la de los triángulos, como, cuando un cuadrilátero tiene un incírculo o la formula de Euler que mide la distancia entre el incentro y el circuncentro pero esta vez para cuadriláteros.
Tarea moral
A continuación hay algunos ejercicios para que practiques los conceptos vistos en esta entrada. Te será de mucha utilidad intentarlos para entender más la teoría vista.
Construye un triángulo, dado su primer triángulo de Brocard.
Muestra que la recta que une los vértices de un triángulo con los correspondientes vértices de su primer triángulo de Brocard dividen a los lados opuestos del triángulo original en el inverso de la razón de los cuadrados de los lados adyacentes.
Prueba que la reflexión del punto simediano respecto del centro de los nueve puntos de un triángulo es el centro de la circunferencia de Brocard de su triángulo anticomplementario.
Muestra que el punto simediano y el circuncentro de un triángulo son el punto de Steiner y el punto de Tarry de su primer triángulo de Brocard.
El triángulo cuyos vértices son las segundas intersecciones de las simedianas de un triángulo con su circunferencia de Brocard es el segundo triángulo de Brocard, demuestra que: $i)$ los vértices del segundo triángulo de Brocard son los puntos medios de las cuerdas del circuncírculo de su triángulo de referencia determinadas por sus simedianas, $ii)$ las circunferencias del grupo directo e indirecto que son tangentes a los lados de un mismo ángulo de un triángulo se intersecan en los vértices de su segundo triángulo de Brocard.
Altshiller, N., College Geometry. New York: Dover, 2007, pp 279-284.
Johnson, R., Advanced Euclidean Geometry. New York: Dover, 2007, pp 277-282.
Shively, L., Introducción a la Geómetra Moderna. México: Ed. Continental, 1961, pp 73-75.
Honsberger, R., Episodes in Nineteenth and Twentieth Century Euclidean Geometry. Washington: The Mathematical Association of America, 1995, pp 106-124.
Agradecimientos
Trabajo realizado con el apoyo del Programa UNAM-DGAPA-PAPIME PE104522 «Hacia una modalidad a distancia de la Licenciatura en Matemáticas de la FC-UNAM – Etapa 2»
Como parte de nuestro estudio del valor esperado, en esta entrada abordaremos algunas más de sus propiedades. En la entrada antepasada vimos un primer conjunto de propiedades, y probablemente habrás notado que se trataba de propiedades en las que sólamente había una v.a. Por el contrario, conforme a lo visto en la entrada anterior, las propiedades que veremos en esta entrada involucran a más de una v.a., así que necesitaremos algunos de los elementos básicos de probabilidad multivariada que vimos.
En esta entrada centraremos nuestra atención en ver cómo interactúa el valor esperado con dos operaciones de variables aleatorias: la suma y el producto. Veremos que el valor esperado de la suma de dos v.a.’s se comporta de forma muy agradable, y podremos decir que es lineal. No obstante, el valor esperado del producto de dos v.a.’s requerirá de una condición extra para poder comportarse de manera agradable.
Linealidad con respecto a escalares
Una consecuencia de la ley del estadístico inconsciente es una primera propiedad de linealidad del valor esperado, con respecto a constantes reales.
Propiedad 1. Sea $X\colon\Omega\to\RR$ una variable aleatoria y sean $a$, $b \in \RR$. Entonces se cumple que
\begin{align*} \Esp{aX + b} &= a\Esp{X} + b \end{align*}
Demostración. Sea $g\colon\RR\to\RR$ la transformación dada por
\begin{align*} g(x) &= ax + b & \text{para cada $x \in \RR$}.\end{align*}
De este modo, $g(X) = aX + b$. Aplicando la ley del estadístico inconsciente, se sigue que:
Si $X$ es una v.a. discreta, entonces \begin{align*} \Esp{g(X)} &= \sum_{x \in X[\Omega]} g(x) \Prob{X = x} \\[1em] &= \sum_{x \in X[\Omega]} (ax + b) \Prob{X = x} \\[1em] &= \sum_{x \in X[\Omega]} {\left( ax\Prob{X = x} + b\Prob{X = x}\right)} \\[1em] &= a \sum_{x\in X[\Omega]} x \Prob{X = x} + \sum_{x\in X[\Omega]} b \Prob{X = x} \\[1em] &= a\Esp{X} + \Esp{b} \\[1em] &= a\Esp{X} + b, \end{align*}por lo que es cierto en el caso discreto.
Si $X$ es una v.a. continua, entonces $g(X)$ es una v.a. continua (porque $g$ es una transformación continua). Así, tenemos que \begin{align*} \Esp{g(X)} &= \int_{-\infty}^{\infty} g(x) f_{X}(x) \, \mathrm{d}x, \\[1em] &= \int_{-\infty}^{\infty} (ax + b) f_{X}(x) \, \mathrm{d}x \\[1em] &= \int_{-\infty}^{\infty} (axf_{X}(x) + bf_{X}(x)) \, \mathrm{d}x \\[1em] &= \int_{-\infty}^{\infty} axf_{X}(x) \, \mathrm{d}x + \int_{-\infty}^{\infty} bf_{X}(x) \, \mathrm{d}x \\[1em] &= a \int_{-\infty}^{\infty} xf_{X}(x) \, \mathrm{d}x + b\int_{-\infty}^{\infty} f_{X}(x) \, \mathrm{d}x \\[1em] &= a\Esp{X} + b, \end{align*}por lo que también es cierto en el caso continuo.
Por lo tanto, podemos concluir que si $X$ es una v.a. y $a$ y $b \in \RR$ son constantes reales, entonces
lo cual es muy natural: si la v.a. \(X\) tiene una tendencia central hacia \(\Esp{X}\), entonces el comportamiento aleatorio de \(X + b\) estará centrado alrededor de \(\Esp{X} + b\), pues el valor \(b\) está fijo.
Valor esperado de la suma de v.a.’s
Dadas $X\colon\Omega\to\RR$ y $Y\colon\Omega\to\RR$ dos v.a.’s definidas sobre el mismo espacio de probabilidad, podemos definir la v.a. $(X+Y)\colon\Omega\to\RR$ dada por
Ahora, si por alguna razón queremos calcular el valor esperado de $X+Y$, podríamos caer en la trampa de utilizar directamente la definición, e intentaríamos calcular
\begin{align*} \Esp{X+Y} &= \sum_{z \in (X+Y)[\Omega]} z \Prob{X + Y = z}, \end{align*}
en caso de que $X+Y$ sea discreta; o
\begin{align*} \Esp{X+Y} &= \int_{-\infty}^{\infty} z f_{X+Y}(z) \, \mathrm{d}z, \end{align*}
donde $f_{X+Y}\colon\RR\to\RR$ es la función de densidad de $X+Y$… algo que inicialmente no poseemos, incluso si las distribuciones de $X$ y de $Y$ son conocidas. Sin embargo, no es necesario hacer nada de esto: ¡el valor esperado es lineal! Esto lo enunciamos en la siguiente propiedad.
Propiedad 2. Sean $X\colon\Omega\to\RR$, $Y\colon\Omega\to\RR$ variables aleatorias con valor esperado finito definidas sobre el mismo espacio de probabilidad. Entonces
Demostración. Demostraremos el caso en el que $X$ y $Y$ son v.a.’s discretas. Para ello, podemos recurrir directamente a la definición formal de valor esperado.
por lo que $\Esp{X + Y} = \Esp{X} + \Esp{Y}$, que es justamente lo que queríamos demostrar.
$\square$
Por otro lado, omitiremos el caso cuando $X$ y $Y$ son v.a.’s continuas, pues la demostración (a este nivel) requiere de hacer más trampa, utilizando además una variante multivariada de la ley del estadístico inconsciente. No obstante, para propósitos de este curso, podrás asumir que el valor esperado es lineal en el caso discreto y en el continuo.
Valor esperado del producto de v.a.’s
De manera similar a la suma, dadas \(X\colon\Omega\to\RR\), \(Y\colon\Omega\to\RR\) v.a.’s, se define el producto de \(X\) con \(Y\) como la función \((XY)\colon\Omega\to\RR\) dada por
\begin{align*} (XY)(\omega) &= X(\omega) Y(\omega) & \text{para cada \(\omega\in\Omega\)}. \end{align*}
Es natural preguntarnos, ¿cómo se comporta esta operación con respecto al valor esperado? ¿Se comporta igual que la suma? Es decir, ¿será cierto que para cualesquiera v.a.’s \(X\) y \(Y\) se cumple que
La respuesta es que no, y te ofrecemos el siguiente ejemplo.
Ejemplo 1. Sean \(X\), \(Y\) v.a.’s con función de masa de probabilidad conjunta \(p_{X,Y}\colon\RR^{2}\to\RR\) dada por los valores en la siguiente tabla:
etcétera. En los extremos de la tabla hemos colocado las funciones de masa de probabilidad marginal de \(X\) y de \(Y\). Con ellas podemos calcular \(\Esp{X}\) y \(\Esp{Y}\) como sigue:
Así, obtenemos que \(\Esp{X}\Esp{Y} = 0 \cdot 0.5 = 0\). Por otro lado, observa que \(XY\) puede tomar alguno de tres posibles valores: \(0\), \(1\) y \(-1\). \(XY\) vale \(0\) cuando \(Y\) toma el valor \(0\) y \(X\) toma cualquier valor; mientras que \(XY = 1\) cuando \(Y=1\) y \(X = 1\); y además \(XY = -1\) cuando \(Y=1\) y \(X=-1\). Esto nos da todas las probabilidades de \(XY\), que son
La demostración de este teorema requiere de más acrobacias tramposas (a este nivel) con integrales múltiples, por lo que la omitiremos.
Observa que el teorema establece que si \(X\) y \(Y\) son v.a.’s independientes, entonces se tendrá que \(\Esp{XY} = \Esp{X}\Esp{Y}\). La implicación conversa no es verdadera, existen v.a.’s no-independientes que satisfacen \(\Esp{XY} = \Esp{X}\Esp{Y}\).
Tarea moral
Los siguientes ejercicios son opcionales. Es decir, no formarán parte de tu calificación. Sin embargo, te recomiendo resolverlos para que desarrolles tu dominio de los conceptos abordados en esta entrada.
¿Cómo interpretas la linealidad del valor esperado? Es decir, sabemos que si \(X\) es una v.a., entonces \(\Esp{X}\) es el «centroide esperado» al obtener muchas observaciones de \(X\), ¿cómo se interpreta que \(\Esp{X + Y} = \Esp{X} + \Esp{Y}\)?
Por otro lado, no siempre se cumple que \(\Esp{XY} = \Esp{X}\Esp{Y}\). ¿Por qué pasa esto con el producto?
Construye dos v.a.’s \(X\) y \(Y\) tales que \(\Esp{XY} = \Esp{X}\Esp{Y}\), pero de tal manera que \(X\) y \(Y\) no sean independientes. Sugerencia: Para asegurar la no-independencia, escoge una v.a. \(X\) sencilla (como las del Ejemplo 1), y toma a \(Y = g(X)\), donde \(g\) es una transformación conveniente.
Más adelante…
Debido a que el valor esperado es un concepto muy importante en la teoría (y en la práctica) de la probabilidad, las propiedades presentadas en esta entrada y la anterior son muy importantes, y te encontrarás con ellas muy a menudo. Además, en las materias de Probabilidad II y Procesos Estocásticos I verás temas que involucran más de una variable aleatoria (probabilidad multivariada) en los que utilizarás las propiedades vistas en esta entrada (y otras muy parecidas, pero más generales).
Volviendo a nuestro curso, en la entrada siguiente veremos otro valor asociado a una distribución de probabilidad: la varianza.
En esta entrada veremos una breve introducción a las interacciones básicas entre dos v.a.’s. En una entrada previa vimos cómo se interpretaban las operaciones con eventos, y después vimos algunos conceptos asociados a la interacción entre eventos, como es el caso de la definición de independencia. De manera similar, es razonable que definamos ciertos conceptos para describir el comportamiento probabilístico de dos variables aleatorias de manera conjunta.
Primero, un poco de notación
Sea $(\Omega, \mathscr{F}, \mathbb{P})$ un espacio de probabilidad y sean $X\colon\Omega\to\RR$, $Y\colon\Omega\to\RR$ dos variables aleatorias. Aquí estamos siendo muy explícitos con el hecho de que el dominio de ambas v.a.’s debe de ser el mismo. Esto es importante porque los eventos que involucran a $X$ y a $Y$ deben de ser elementos del mismo σ-álgebra. Además, las operaciones entre v.a.’s están bien definidas siempre y cuando estas tengan el mismo dominio, pues se definen puntualmente.
Primero, demos un poco de notación. Sean $A$ y $B \in \mathscr{B}(\RR)$. Para denotar la probabilidad del evento en el que $X \in A$ y $Y \in B$ se sigue la siguiente notación:
\begin{align*} \Prob{X \in A, Y \in B} &= \Prob{(X \in A)\cap(Y \in B)}. \end{align*}
Es decir, $(X \in A, Y \in B)$ es la notación para expresar el evento $(X \in A) \cap (Y \in B)$. Observa que este conjunto sí es un evento, pues $X$ y $Y$ son v.a.’s, así que tanto $(X \in A)$ como $(Y \in B)$ son elementos de $\mathscr{F}$, así que también su intersección lo es.
De este modo, podemos expresar muchas probabilidades de intersecciones de eventos de forma más compacta. Por ejemplo:
En la Unidad 1 de este curso hablamos sobre la independencia de eventos. El paso que sigue ahora es definir la noción de independencia de variables aleatorias. De manera similar a los eventos, que $X$ y $Y$ sean variables aleatorias independientes significa que un evento que involucra a $X$ no afecta las probabilidades de $Y$. Por ello, la noción de independencia se dará en términos de eventos.
Definición 1. Sea $(\Omega, \mathscr{F}, \mathbb{P})$ un espacio de probabilidad y sean $X\colon\Omega\to\RR$ y $Y\colon\Omega\to\RR$ variables aleatorias. Diremos que $X$ y $Y$ son independientes si y sólamente si para todo $A$, $B \in \mathscr{B}(\RR)$ se cumple
\begin{align*} \Prob{X \in A, X \in B} &= \Prob{X \in A} \Prob{X \in B}. \end{align*}
También es posible caracterizar la independencia de v.a.’s mediante sus funciones de distribución. Para ello, es necesario definir el concepto de función de distribución conjunta de dos v.a.’s. Esta se define como sigue:
Definición 2. Sea $(\Omega, \mathscr{F}, \mathbb{P})$ un espacio de probabilidad y sean $X\colon\Omega\to\RR$ y $Y\colon\Omega\to\RR$ variables aleatorias. Se define la función de distribución conjunta de $X$ y $Y$, $F_{X,Y}\colon\RR^{2}\to\RR$, como sigue:
\begin{align*} F_{X,Y}(x,y) &= \Prob{X \leq x, Y \leq y}, & \text{para cada $(x,y) \in \RR^{2}$}. \end{align*}
Esta es una «generalización» multidimensional de la función de distribución de una variable aleatoria. Es decir, sabemos que \(\Prob{X \leq x}\) es la probabilidad de que la v.a. \(X\) tome un valor dentro del intervalo \((-\infty, x]\). De manera similar, \(\Prob{X \leq x, Y \leq y}\) es la probabilidad de que las v.a.’s \(X\) y \(Y\) tomen un valor dentro del intervalo \((-\infty, x]\) y \((-\infty, y]\), respectivamente. Esto es, si pensamos a \((X, Y)\) como un punto aleatorio en \(\RR^{2}\), entonces \(\Prob{X \leq x, Y \leq y}\) es la probabilidad de que \((X,Y)\) sea un punto dentro del rectángulo \((-\infty, x] \times (-\infty, y]\).
El siguiente teorema nos brinda un criterio de independencia más sencillo que el de la Definición 1:
Teorema 1. Sea $(\Omega, \mathscr{F}, \mathbb{P})$ un espacio de probabilidad y sean $X\colon\Omega\to\RR$ y $Y\colon\Omega\to\RR$ variables aleatorias. Las siguientes proposiciones son equivalentes:
$X$ y $Y$ son independientes.
Para cualesquiera $x$, $y \in \RR$ se cumple \begin{align*} F_{XY}(x,y) &= F_{X}(x) F_{Y}(y). \end{align*}
Demostrar que 1. implica a 2. no es complicado, y lo dejamos como tarea moral. Por otro lado, demostrar 2. implica a 1. rebasa los contenidos de este curso, por lo que omitiremos esta parte de la demostración.
Este teorema hace más sencillo verificar si dos v.a.’s son independientes o no lo son. Primero, porque el trabajo se reduce a trabajar con las funciones de distribución. Además, a continuación veremos que es posible recuperar las funciones de probabilidad (masa y densidad) a partir de las funciones de probabilidad conjunta. Por ello, podremos verificar si dos v.a.’s son independientes comparando su distribución conjunta con el producto de sus distribuciones univariadas, gracias al Teorema 1.
Funciones de probabilidad conjunta para v.a.’s discretas
Al haber definido la función de distribución conjunta, se desprenden dos casos importantes: el caso discreto y el caso continuo. En el caso en el que $X$ y $Y$ son v.a.’s discretas, es posible definir la función de masa de probabilidad conjunta de $X$ y $Y$. Esta se define como sigue.
Definición 3. Sea $(\Omega, \mathscr{F}, \mathbb{P})$ un espacio de probabilidad y sean $X\colon\Omega\to\RR$ y $Y\colon\Omega\to\RR$ v.a.’s discretas. Se define la función de masa de probabilidad conjunta de $X$ y $Y$, $p_{X,Y}\colon\RR^{2}\to\RR$ como sigue:
\begin{align*} p_{X,Y}(x, y) &= \Prob{X = x, Y = y}, & \text{para cada $(x,y) \in \RR^{2}$}. \end{align*}
Es decir, el valor $p_{X,Y}(x,y)$ es la probabilidad de que $X$ tome el valor $x$ y $Y$ tome el valor $y$. Ahora, antes de seguir, es recomendable que recuerdes el teorema de probabilidad total que vimos en una entrada previa. Sabemos que $Y[\Omega]$ es un conjunto a lo más infinito numerable, pues $Y$ es una v.a. discreta. Por ello, podemos ver a $Y[\Omega]$ como una unión numerable de conjuntos, donde cada uno de estos conjuntos tiene un único elemento. Es decir, tomamos los conjuntos $\{y\}$, para cada $y \in Y[\Omega]$, y los unimos a todos:
\begin{align*} Y[\Omega] &= \bigcup_{y \in Y[\Omega]} \{ y \}. \end{align*}
Observa que esta es una unión de conjuntos ajenos, pues para cada $y_{1}$, $y_{2} \in Y[\Omega]$ se cumple que si $y_{1} \neq y_{2}$, entonces $\{ y_{1} \} \cap \{ y_{2} \} = \emptyset$. Además,
Por otro lado, como el dominio de $Y$ es $\Omega$, también sabemos que $Y^{-1}[Y[\Omega]] \subseteq \Omega$, así que $\Omega = Y^{-1}[Y[\Omega]]$. Finalmente, por $(\triangle)$ se tiene que
Es decir, $\{ \, (Y = y) \mid y \in Y[\Omega] \,\}$ forma una partición de $\Omega$. Sea $x \in X[\Omega]$. Como lo anterior nos da una partición de $\Omega$, podemos aplicar el teorema de probabilidad total para obtener que
En términos de las funciones de masa de probabilidad, lo anterior quiere decir que podemos recuperar la masa de probabilidad de $X$ y de $Y$ a partir de la función de masa de probabilidad conjunta, como sigue:
Este procedimiento de obtener la función de masa de probabilidad de una v.a. a partir de la masa de probabilidad conjunta se conoce como marginalización, y las funciones resultantes son conocidas como las funciones de masa de probabilidad marginales.
Ejemplo 1. Sean $X$ y $Y$ dos v.a.’s discretas con función de masa de probabilidad conjunta $p_{X,Y}\colon\RR^{2}\to\RR$ dada por:
\begin{align*} p_{X,Y} &= \begin{cases} 0.05 & \text{si $(x, y) = (0,3)$ o $(x,y) = (1,1)$ o $(x, y) = (2,4)$}, \\[1em] 0.1 & \text{si $(x,y)=(0,2)$ o $(x,y) = (1,3)$ o $(x,y) = (2,1)$}, \\[1em] 0.15 & \text{si $(x,y) = (2,2)$}, \\[1em] 0.2 & \text{si $(x,y) = (0,1)$ o $(x,y) = (1,4)$}, \\[1em] 0 & \text{en otro caso}. \end{cases} \end{align*}
Una buena manera de organizar la información contenida en esta función es mediante una tabla como la siguiente:
Valores posibles de $X$
0
1
2
Valores posibles de $Y$
1
0.2
0.05
0.1
2
0.1
0
0.15
3
0.05
0.1
0
4
0
0.2
0.05
De este modo, $\Prob{X = 0, Y = 1} = 0.2$, y $\Prob{X=0, Y =3} = 0.05$. A partir de las probabilidades de la tabla podemos calcular la función de masa de probabilidad de $X$, $p_{X}\colon\RR\to\RR$. Para ello, simplemente debemos de marginalizar sobre cada uno de los valores que toma $X$. De este modo, obtenemos que
Sin embargo, observa que el uso de una tabla sólo tiene sentido si $X[\Omega]$ y $Y[\Omega]$ son conjuntos finitos. De otro modo, sería una «tabla» infinita, y nunca acabaríamos de escribirla…
Independencia en el caso discreto
Una consecuencia (casi inmediata) del Teorema 1 es el siguiente criterio de independencia para v.a.’s discretas.
Proposición 1. Sean \(X\), \(Y\) variables aleatorias. Si \(X\) y \(Y\) son discretas, entonces \(X\) y \(Y\) son independientes si y sólamente si
Sin embargo, de acuerdo con la tabla, \(\Prob{X = 1, Y = 1} = 0.05\), que no coincide con el valor en \eqref{eq:prod}. Por ello, podemos concluir que las v.a.’s del Ejemplo 1 no son independientes.
Función de densidad conjunta para v.a.’s continuas
Como de costumbre, el caso para las v.a.’s continuas es distinto. En este caso, lo que tendremos es una función de densidad conjunta, que juega el mismo papel que una función de densidad univariada, pero para \(2\) v.a.’s conjuntamente. Esto da lugar a la siguiente definición.
Definición. Sean \(X\) y \(Y\) v.a.’s continuas, y \(F_{X,Y}\colon\RR^{2}\to\RR\) su función de distribución conjunta. Entonces \(F_{X,Y}\) puede expresarse como sigue:
De este modo, \(f_{X,Y}\colon\RR^{2}\to\RR\) es llamada la función de densidad conjunta de \(X\) y \(Y\).
De igual forma que con las función de distribución conjunta, la función de densidad conjunta es una generalización multivariada de la función de densidad. Además, también existen técnicas de marginalización que son análogas al caso discreto. Primero, recuerda que integrar la función de densidad sobre un intervalo es nuestra forma de sumar continuamente las probabilidades de cada punto en el intervalo. Esto es:
Si tomamos la idea del teorema de probabilidad total, pero integramos sobre todo el conjunto de valores de una de las v.a.’s (en vez de sumar, como hicimos en el caso discreto), podemos expresar la función de densidad marginal de \(X\) como
Este es el proceso de marginalización para el caso continuo. Observa que las funciones resultantes son las funciones de densidad marginales. Como tal, los valores que toman estas funciones no son probabilidades, por lo que la marginalización es más sutil que en el caso discreto (ya que el teorema de probabilidad total se usa para probabilidades, y para particiones a lo más numerables).
Ejemplo 2. Sean \(X\) y \(Y\) dos v.a.’s tales que su función de densidad conjunta es \(f_{X,Y}\) dada por
\begin{align*} f_{X,Y}(x,y) &= \begin{cases} y{\left( \dfrac{1}{2} − x\right)} + x &\text{si \(x \in (0,1)\) y \(y \in (0,2)\),} \\[1em] 0 & \text{en otro caso.}\end{cases}\end{align*}
La gráfica de esta función se ve como sigue:
Figura. Gráfica de la función de densidad conjunta de \(X\) y \(Y\). Como el dominio de \(f_{X,Y}\) es \(\RR^{2}\), la gráfica de esta función es un lugar geométrico en \(\RR^{3}\).
Sin embargo, hay un detallito que quizás tengas en la cabeza: ¿cómo se interpreta que esta función sea «de densidad», en un sentido vibariado? A grandes rasgos, debe de cumplir lo mismo que una función de densidad univariada. En particular, el valor de la integral sobre su dominio debe de ser \(1\). En este caso, esto significa que se debe de cumplir que
Como muy probablemente no conoces métodos (ni teoría) de integración bivariada, simplemente te diremos que \(f_{X,Y}\) sí es una función de densidad bivariada, y que sí cumple la condición anterior.
Por otro lado, algo que sí podemos hacer con los conocimientos que posees hasta ahora es obtener las marginales. Obtengamos la densidad marginal de \(X\), para lo cual hay que integrar \(f_{X,Y}\) sobre todo el dominio de \(Y\):
en donde \(x \in (0,1)\), pues es donde la densidad conjunta no vale \(0\). Como esta integral es con respecto a \(y\), podemos pensar que \(x\) es una constante respecto a la variable de integración. Por ello, la integral anterior puede resolverse de manera directa con herramientas de Cálculo II:
Así, llegamos a que \(X\) sigue una distribución uniforme en el intervalo \((0,1)\).
Independencia en el caso continuo
De manera similar al caso discreto, además del criterio dado por el Teorema 1, podemos dar la siguiente criterio de independencia para dos v.a.’s continuas.
Proposición 2. Sean \(X\), \(Y\) variables aleatorias. Si \(X\) y \(Y\) son continuas, entonces \(X\) y \(Y\) son independientes si y sólamente si
donde \(f_{X,Y}\) es la función de densidad conjunta de \(X\) y \(Y\), y \(f_{X}\) y \(f_{Y}\) son las funciones de densidad marginales.
Es decir, dos v.a.’s continuas son independientes si su función de densidad conjunta es el producto de sus funciones de densidad (marginales).
Tarea moral
Los siguientes ejercicios son opcionales. Es decir, no formarán parte de tu calificación. Sin embargo, te recomiendo resolverlos para que desarrolles tu dominio de los conceptos abordados en esta entrada.
Demuestra que 1. implica a 2. en el Teorema 1.
En el Ejemplo 1:
Verifica que la función $p_{X}\colon\RR\to\RR$ que obtuvimos es una función de masa de probabilidad.
Encuentra $p_{Y}\colon\RR\to\RR$, la función de masa de probabilidad de $Y$.
En el Ejemplo 2:
Encuentra la función de densidad marginal de \(Y\).
¿Son independientes \(X\) y \(Y\)?
Más adelante…
Usaremos los temas que vimos en esta entrada en la próxima entrada, ya que serán necesarios algunos detallitos de probabilidad multivariada para entender las propiedades del valor esperado que veremos a continuación. Por el momento sólo es importante que sepas que existen estos temas de probabilidad multivariada, y entiendas lo que significan los conceptos vistos en esta entrada.
En un curso de Probabilidad II verás con muchísimo detalle los temas que presentamos en esta entrada, así que no te preocupes si los temas que vimos aquí no te quedaron completamente claros.