Hola. Soy Leonardo Martínez. Soy Profesor de Tiempo Completo en la Facultad de Ciencias de la UNAM. Hice un doctorado en Matemáticas en la UNAM, un postdoc en Israel y uno en Francia. Además, me gusta colaborar con proyectos de difusión de las matemáticas como la Olimpiada Mexicana de Matemáticas.
Se nos acaba el año, y con él los años 10’s. Cada década ha traído muchas cosas buenas y malas.
Las cosas malas están en los medios y ya las tenemos presentes. Tenemos que seguir trabajando para que cada vez sean menos. Me enorgullece mucho la fuente lucha que están haciendo mis amigos y conocidos contemporáneos en causas importantes como el feminismo, la ecología, la normalización/atención a problemas psicológicos/psiquiátricos y el desarrollo científico/tecnológico.
Las cosas buenas también han sido bastantes, y qué mejor momento para recordarlas y agradecerlas, que cuando cambia el dígito de las decenas del año actual.
De los 80’s no recuerdo prácticamente nada, pero agradezco enormemente los cuidados de mis padres en mi primer año de vida.
De los 90’s agradezco y recuerdo mi infancia, los videojuegos, la educación primaria y las experiencias de vivir en cuatro estados.
De los 00’s agradezco y recuerdo el boom de internet, el campamento de mate en Stanford, mi primer amor y encontrar a través de la Olimpiada mi rumbo profesional.
De los 10’s agradezco y recuerdo mi vida independiente, mi maduración profesional, mi vida como extranjero y superar con éxito una delicada situación de salud.
Los 20’s me dan una enorme curiosidad, una pizca de miedo, pero sobre todo un gran entusiasmo.
Espero que pasen este último día de diciembre en grata compañía de sus seres queridos. Si tienen chance, entre sidra, calzones rojos y campanadas, los invito a acordarse y agradecer un ratito lo que les ha pasado en cada década.
Les comparto un problema que se me ocurrió en las (muchas) horas que he pasado en el carro escuchando música, cuando vivía en la Ciudad de México. El estéreo del carro ordena las canciones alfabéticamente. Tiene un botón que permite «avanzar una canción». Pero a veces tarda mucho: si estoy escuchando «Adele – Hello», hay que apretar el botón muchas veces para llegar a «Shakira – Dónde están los ladrones».
En esas épocas descubrí una estrategia «intuitiva» para llegar más rápido a la canción. La idea es la siguiente: pasar temporalmente al modo de «canción aleatoria», apretar el botón unas cuantas veces para acercarme a la canción que quiero (en el ejemplo anterior, digamos que después de dos o tres veces el botón me lleva a «Paquita la del Barrio – Rata de dos Patas»), y de ahí quitar el aleatorio y avanzar normal. Eso, intuitivamente, siempre me ahorró muchos pasos. El problema consiste en encontrar la estrategia óptima, en donde se permiten mezclar pasos normales y aleatorios.
Para eso, voy a plantear un problema muy concreto. De aquí en adelante supondré que el lector sabe un poco de probabilidad. Pensemos que hay $2n$ canciones, numeradas de $1$ a $2n$. Estoy en la canción $n$ y quiero llegar a la canción $2n$. Pensemos que el estéreo tiene exactamente dos botones, el $A$ que avanza $1$ (y de $2n$ lleva a $1$), y el $B$ que lleva a una canción aleatoria (cualquiera de las canciones, incluida la actual, tiene probabilidad $1/2n$ de ser elegida). En cada paso se permite ver en qué canción estoy, y de ahí decidir apretar $A$ o $B$. ¿Cuál es la estrategia que en valor esperado tiene menos pasos? ¿Cuál es ese valor esperado?
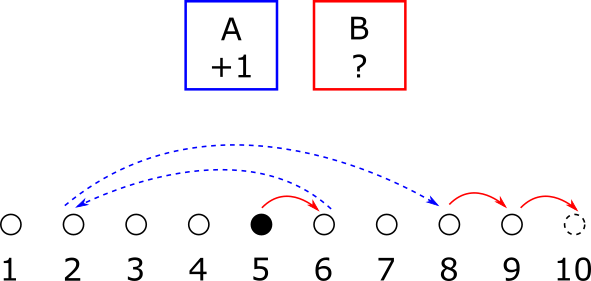
En la imagen de aquí abajo se muestra un ejemplo de una forma de apretar los botones para $n=5$, con $2n=10$ canciones. Las flechas rojas corresponden a avanzar $1$ apretando el botón $A$. Las flechas azules corresponden a ir a un lugar aleatorio apretando el botón $B$. Se apretaron los botones en el orden $ABBAA$, de modo que se hicieron $5$ pasos.
Un ejemplo en el que se usa la estrategia ABBAA. La canción 1 es de ABBA. Es Dancing Queen. «Feel the beat form the tambourine… Oh yeah…».
Ese es el enunciado del problema. De aquí en adelante empiezo a hablar de ideas para resolverlo, así que si quieres intentarlo, este es el momento correcto.
Primeras ideas
Notemos que la estrategia «siempre $A$, hasta llegar a $2n$» toma exactamente $n$ pasos siempre. La estrategia «siempre $B$» es para intentar atinarle, y en cada paso tiene probabilidad de éxito $1/2n$. Entonces, en esta segunda estrategia la cantidad de pasos requeridos es una variable aleatoria con distribución geométrica de parámetro $p=1/2n$, de modo que el número esperado de pasos es $1/p=2n$.
Sin embargo, suena a que la estrategia esbozada al inicio de esta entrada es intuitivamente mejor: usar el $B$ para acercarse y luego el $A$ para llegar.
La solución
Vamos a mostrar que la mejor estrategia en valor esperado es la siguiente: «apretar el botón $B$ hasta llegar aproximadamente al intervalo $[n-2\sqrt{n}, n]$, y de ahí apretar el botón $A$» hasta llegar a $n$.
El primer argumento es que en cada paso, lo que hace la estrategia sólo depende de en qué canción estamos. En efecto, el paso $A$ es determinista y el $B$ es una variable uniforme independiente de todo lo demás.
El segundo argumento es que, si en algún momento de la estrategia usamos el botón $A$, entonces después de ello nunca nos conviene usar el botón $B$. Lo probamos por contradicción: supongamos que por cualquier razón en la estrategia óptima tenemos que hacer un $AB$. El paso $A$ es determinista, y sabíamos exactamente a qué canción nos iba a llevar (a la siguiente). Pero hacer el paso $B$ en cualquier lugar que estemos es simétrico, pues nos lleva a una canción aleatoria. Si a priori sabíamos que íbamos a hacer un paso $B$, lo mejor es hacerlo lo antes posible. Así, la estrategia que substituye esos pasos $AB$ por $B$ se ahorra un paso, y no es óptima. Contradicción.
Ahora, afirmo lo siguiente. Si la estrategia óptima es apretar $A$ cuando estamos en la canción $j$, entonces también va a ser apretar $A$ cuando estemos en cualquier canción $k$ con $j\leq k < 2n$. Esto es debido al argumento anterior: al apretar $A$ llegamos a $j+1$, que por el párrafo de arriba, no le puede tocar $B$. Entonces le toca $A$. De ahí llegamos a $j+2$, que de nuevo no le puede tocar $B$. Y así sucesivamente (inductivamente), hasta llegar a $2n-1$.
Lo que acabamos de probar es que la estrategia óptima se ve de la siguiente manera para algún entero $k$: «Apretar $B$ hasta que lleguemos a alguno de los últimos $k$ elementos. De ahí, apretar $A$ hasta llegar a $2n$.» Nos falta determinar cuál es la mejor $k$ que podemos usar.
A estas alturas ya podemos calcular explícitamente el valor esperado de pasos en esta estrategia. El evento «llegar a alguno de los últimos $k$ elementos» tiene probabilidad $k/2n$ de ocurrir cada que se aprieta el botón $B$, así que la cantidad de veces que hay que apretar $B$ para ello es una variable aleatoria geométrica de valor esperado $2n/k$. Una vez que llegamos a los últimos $k$ elementos, caemos a cualquier elemento del intervalo $\{2n-k+1, 2n-k+2,\ldots,2n\}$ con la misma probabilidad, y respectivamente nos tomará $\{k-1, k-2,\ldots, 0\}$ pasos en llegar a $2n$, es decir, la cantidad de pasos que hacemos es una variable aleatoria uniforme discreta de media $(k-1)/2$.
Así, en total usamos $(2n/k) + (k-1)/2$ pasos para llegar. Queremos lograr que esta expresión sea lo más pequeña posible. Usando la desigualdad entre la media geométrica y la aritmética, notamos que $$\frac{2n}{k}+\frac{k-1}{2}=\frac{2n}{k}+\frac{k}{2}-\frac{1}{2} \geq 2\sqrt{n} – \frac{1}{2},$$ y que la igualdad se da si y sólo si $\frac{2n}{k}=\frac{k}{2}$, es decir, si y sólo si $k=2\sqrt{n}$. En este caso, la cantidad media de pasos que usamos es $2\sqrt{n}-\frac{1}{2}$.
Aquí arriba hicimos un poquito de trampa. En realidad $k=2\sqrt{n}$ tiene sentido para la estrategia sólo cuando $\sqrt{n}$ es un número entero. Sin embargo, por la convexidad de la función $ \frac{2n}{k}+\frac{k}{2}$ tenemos la garantía de que o bien $\lfloor 2\sqrt{n} \rfloor$ o bien $\lceil 2\sqrt{n} \rceil$ dan el máximo.
Conclusión y otros problemas
Está cool que hayamos bajado la cantidad de pasos que se necesitan de valor esperado de algo que era $n$ a algo que es del tamaño $2\sqrt{n}$. Para hacerse una idea de los pasos que se pueden ahorrar, toma una colección de $800$ canciones. Originalmente se necesitaban $400$ pasos $+1$ para ir de la mitad al final. Con la nueva estrategia se requieren como $40$.
Hacer esta estrategia en la vida real es un poco complicado pues los estéreos no muestran el número exacto de la canción en la que se está, además de que es difícil memorizar a qué canción le toca qué número. Pero a veces sí muestran el nombre de la canción y más o menos «se le puede aproximar».
Hay un par de variantes interesantes. Una es ¿qué sucede si además de tener botón $+1$ y aleatorio, también tenemos botón $-1$?. En esta variante la solución no cambia mucho, pero es bueno intentarla para repasar las ideas de la prueba.
La otra variante es la siguiente. La estrategia óptima, como está descrita arriba, tiene un problema: es posible que nunca termine, o que tome muchísimos pasos en terminar (esto será muy improbable y por eso el valor medio se compensa). Así, imaginemos que queremos la restricción adicional de que la estrategia que usemos nunca use más de, digamos, 4n pasos. En esta variante: ¿cuál es la estrategia óptima? ¿cuántos pasos toma?
¿Ahora qué?
Si te gustó esta entrada, puedes compartirla o revisar otras relacionadas con matemáticas a nivel universitario:
Imagina, por un momento, que en un futuro trabajas en la Agencia Espacial Mexicana (AEM). De repente, llega la directora y trae una función en las manos. «Para una misión crítica necesito que me conviertas esta función en una función invertible, cuanto antes posible». Te da la función. Le respondes «Ok, directora y, ¿cómo la quiere o qué?». Pero es demasiado tarde. Ya salió y hay que ponerse a trabajar. Entonces tomas la función, la pones en el gis y comienzas a estudiarla en el pizarrón.
Resulta que es una función de varias variables. Específicamente, es la función que pasa de coordenadas polares a coordenadas cartesianas. Es decir, es la función $F:\mathbb{R}^2 \to \mathbb{R}^2$ dada por:
$$F(r,\theta)=(r\cos\theta, r \sin\theta).$$
La función sí es suprayectiva, así que ya va parte del trabajo hecho. Pero el problema es que no es inyectiva. Por ejemplo,
Peor aún, para todo $\theta \in \mathbb{R}$ se tiene que $F(0,\theta)=(0,0)$.
Pero la situación no es tan terrible. Una forma de solucionarla es restringir el dominio de la función. Si en vez de pensarla en una función $F:\mathbb{R}^2\to \mathbb{R}^2$ la pensamos como una restricción $F:U\to V$ para algunos conjuntos $U$ y $V$, entonces muy posiblemente la podamos «convertir» en una función biyectiva.
No podemos ser demasiado arbitrarios. Por ejemplo, si tomamos $U=\{(0,0)\}$ y $V=\{(0,0)\}$, entonces claramente la restricción es una biyección, pero está muy chafa: sólo nos quedamos con un punto. Por esta razón, vamos a poner una meta un poco más ambiciosa y a la vez más concreta: lograr que $U$ y $V$ sean conjuntos abiertos alrededor de los puntos $x$ y $y:=F(x)$ para algún $x\in \mathbb{R}^2$. Si lo logramos, habremos encontrado una biyección «cerquita de $x$» en conjuntos «más gorditos». Para algunos puntos $x$ lo podemos hacer, y para algunos otros puntos $x$ es imposible. Veamos ejemplos de ambas situaciones.
Si $x=\left(\sqrt{2},\frac{\pi}{4}\right)$, entonces $y=\left(\sqrt{2}\cos \frac{\pi}{4}, \sqrt{2}\sin\frac{\pi}{4}\right)=(1,1)$. En este caso, podemos elegir una vecindad pequeña $U$ alrededor de $x$ y tomar $V:=F(U)$, pues los otros puntos $w$ con $F(x)=F(w)$ están lejos (están a brincos verticales de tamaño $2\pi$ de $x$). Para resolver el problema de la AEM, basta restringir $F$ a $U$.
Sin embargo, si $x=\left(0, \frac{\pi}{4}\right)$, entonces $y=(0,0)$. Sin importar qué tan pequeña tomemos la vecindad abierta $U$ alrededor de $x$, vamos a seguir tomando puntos $w$ sobre la recta $r=0$, para los cuales sucede $F(x)=0=F(w)$. Si la directora de la AEM insiste en que haya un punto con $r=0$, entonces no hay invertibilidad en todo un abierto alrededor de este punto. Esperemos que la misión no dependa de eso.
Aplicando el teorema de la función inversa
El teorema de la función inversa es una herramienta que da condiciones suficientes para que una función $F:\mathbb{R}^n\to \mathbb{R}^n$ pueda invertirse localmente «cerca» de un punto de su dominio. Podemos utilizar este resultado cuando la función que estudiamos es «bien portada», donde esto quiere decir que sea continuamente diferenciable. Si bien hay ligeras variantes en la literatura, el enunciado que presento aquí es el siguiente:
Teorema de la función inversa
Sea $F:\mathbb{R}^n\to \mathbb{R}^n$ una función de clase $\mathcal{C}^1$ con matriz Jacobiana $DF$. Supongamos que $F(a)=b$ y que $DF(a)$ es invertible. Entonces existen vecindades abiertas $U$ y $V$ de $a$ y $b$ respectivamente para las cuales:
a) $F:U\to V$ es una biyección, b) su inversa $F^{-1}:V\to U$ es de clase $\mathcal{C}^1$ y c) $DF^{-1}(b)=DF(a)^{-1}$.
En otra entrada hablo de la intuición de este teorema, así como de su demostración. Por el momento sólo me enfocaré en dar un ejemplo de cómo podemos usarlo.
Regresemos al ejemplo de la Agencia Espacial Mexicana. La función que tenemos es $F:\mathbb{R}^2\to \mathbb{R}^2$ que está dada por
$$F(r,\theta)=(F_1(r,\theta),F_2(r,\theta))=(r\cos\theta, r \sin\theta).$$
Para usar el teorema de la función inversa, tenemos que estudiar la invertibilidad de $DF$, su matriz Jacobiana. Esta está construida a partir de las derivadas parciales de las funciones coordenadas como sigue:
y que es distinto de $0$ si y sólo si $r\neq 0$. Esto coincide con las observaciones que hicimos «a mano»: la función es invertible localmente en $(r,\theta)$ si $r\neq 0$. Cuando $r=0$, la invertibilidad no está garantizada.
El teorema de la función inversa tiene más implicaciones. Nos dice además que la inversa $F^{-1}$ también es continuamente diferenciable y que su derivada es la inversa de $F$. Como ejemplo, consideremos el punto $\left(\sqrt{2},\frac{\pi}{4}\right)$. Tenemos que
Esto termina la motivación y el ejemplo del teorema de la función inversa. Si quieres entender un poco mejor la intuición detrás del teorema, así como su demostración, puedes darte una vuelta por esta otra entrada.
¿Ahora qué?
Si te gustó esta entrada, puedes compartirla o revisar otras relacionadas con matemáticas a nivel universitario:
Uno de los teoremas clave de los cursos de cálculo de varias variables es el teorema de la función inversa (TFI). En la Facultad de Ciencias de la UNAM se estudia en la materia Cálculo III. En esta entrada me gustaría presentar de la manera más auto-contenida posible este resultado.
Platicaré un poco de las definiciones de los términos que aparecen en el enunciado, así como de la intuición de por qué el teorema es cierto. Después presentaré los ingredientes principales para una prueba. Finalmente, presentaré la prueba intentando motivarla y dividiéndola en secciones pequeñas.
El enunciado con el que trabajaremos es el siguiente:
Teorema de la función inversa. Sea $F:\mathbb{R}^n\to \mathbb{R}^n$ una función de clase $\mathcal{C}^1$ con matriz Jacobiana $DF$. Supongamos que $F(a)=b$ y que $DF(a)$ es invertible. Entonces existen vecindades abiertas $U$ y $V$ de $a$ y $b$ respectivamente para las cuales:
a) $F:U\to V$ es una biyección, b) su inversa $F^{-1}:V\to U$ es de clase $\mathcal{C}^1$ y c) $DF^{-1}(b)=DF(a)^{-1}$.
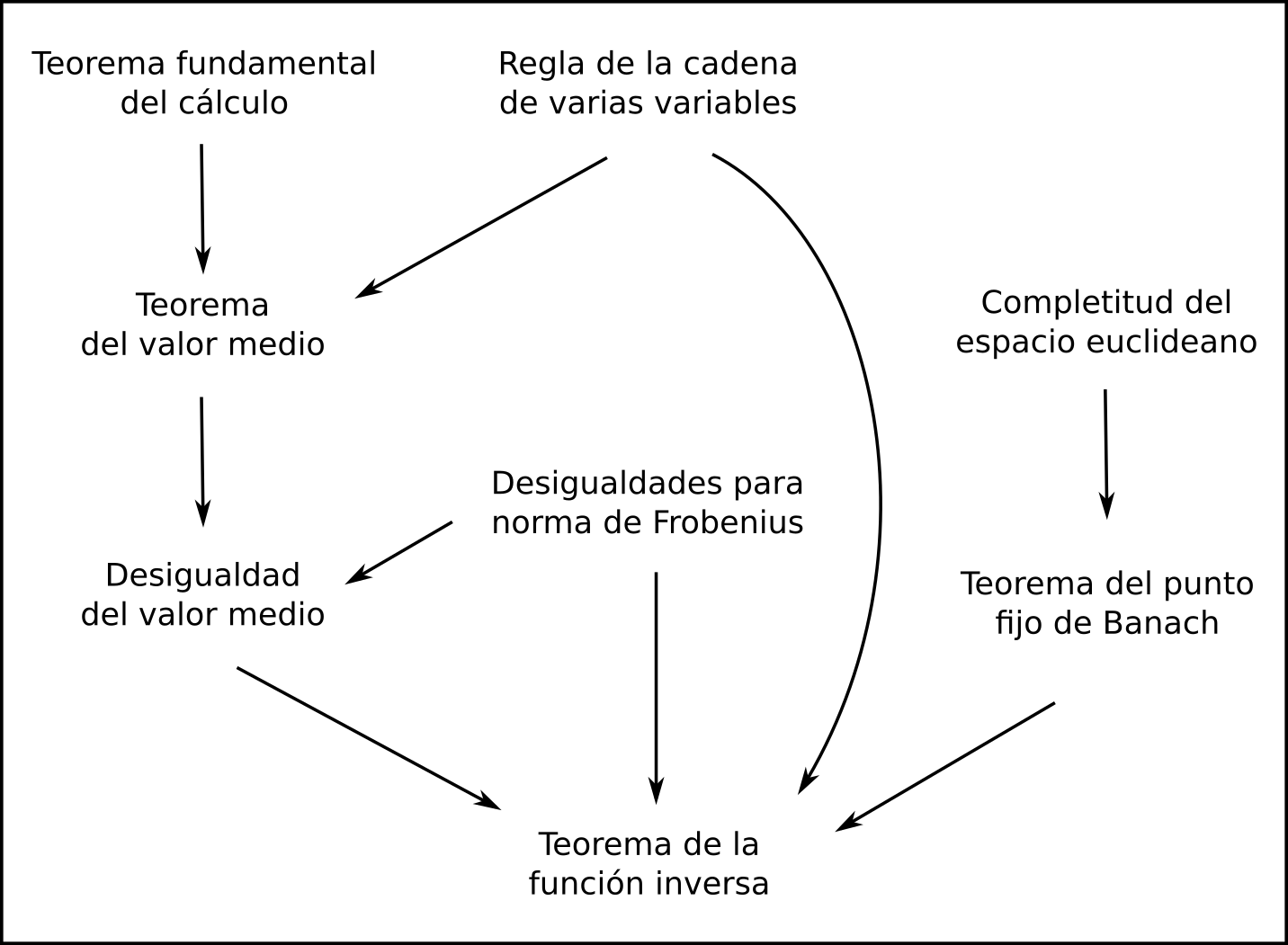
Lo que nos espera es aproximadamente lo que está en el siguiente diagrama, donde las flechas indican a grandes rasgos qué resultado se usa para probar qué otro.
Definiciones e intuición
La función con la que comenzamos es una función de $\mathbb{R}^n$ a $\mathbb{R}^n$, así que la podemos descomponer en sus funciones coordenadas de la siguiente manera: $$F(x)=(F_1(x), F_2(x),\ldots, F_n(x)).$$
Que la función sea de clase $\mathcal{C}^1$ quiere decir que las derivadas parciales con respecto a cada una de las variables existen, que estas son continuas y que localmente $F$ «se comporta» como la transformación lineal correspondiente a la matriz Jacobiana siguiente:
Entonces, a grandes rasgos lo que nos dice el teorema de la función inversa es lo siguiente. Si $F$ se comporta como una transformación lineal $T$ invertible «cerquita» del punto $a$, entonces en realidad es invertible «cerquita» del punto $a$ y más aún, la inversa se comporta como la transformación lineal $T^{-1}$ «cerquita» del punto $b=f(a)$.
Suena bastante razonable, pero hay algunos aspectos que son sorprendentes. Uno es que se garantiza la invertibilidad en todo un abierto $U$. Si no se requiriera que fuera abierto, sería chafa porque podríamos tomar $U=\{a\}$ y $V=\{b\}$ y la restricción sería trivialmente invertible. Lo otro es que el teorema también garantiza que la inversa es diferenciable, lo cual de entrada no es evidente.
Para la prueba necesitamos hablar de dos normas. Cuando tengamos un vector $x=(x_1,\ldots,x_n)$ en $\mathbb{R}^n$, $\norm{x}$ denotará la norma euclideana $$\norm{x}=\sqrt{\sum_{i=1}^nx_i^2}.$$
Necesitaremos también la norma de Frobenius. Como recordatorio, para una matriz $A=(a_{ij})$ de $n\times n$, su norma de Frobenius está dada por $$\norm{A}=\sqrt{\sum_{i=1}^n\sum_{j=1}^n a_{ij}^2},$$
o equivalentemente, si $A_i$ es el $i$-ésimo renglón de $A$, tenemos que
$$\norm{A}=\sqrt{\sum_{i=1}^n\norm{A_{i}}^2},$$
pues ambas expresiones suman todas las entradas de la matriz al cuadrado.
Ingredientes para la prueba
Pasemos ahora a algunos resultados auxiliares que es más cómodo probar desde antes. Algunos de ellos son más generales que lo que enuncio (e incluso con la misma prueba), pero con el fin de que la demostración sea auto-contenida, he decidido enunciar sólo lo que necesitamos.
Teorema del punto fijo de Banach (para $\mathbb{R}^n$). Sea $X$ un compacto de $\mathbb{R}^n$ y $\varphi:X\to X$ una función continua. Supongamos que $\varphi$ es una contracción, es decir, que existe un real $0<\lambda<1$ para el cual $\norm{\varphi(x)-\varphi(y)}\leq\lambda \norm{x-y}$ para todos $x,y \in X$.
Entonces $\varphi$ tiene un único punto fijo, es decir existe uno y sólo un punto $x_0\in X$ para el cual $\varphi(x_0)=x_0$.
Para probar el teorema del punto fijo de Banach basta tomar cualquier punto inicial $x_1$ y considerar la sucesión $\{x_m\}$ construida recursivamente con la regla $x_m=\varphi(x_{m-1})$ para $m\geq 2$. Usando que $\varphi$ es contracción y la fórmula para series geométricas se puede mostrar inductivamente que para $m>m’$ se tiene
Como $\lambda<1$, el lado derecho se hace arbitrariamente pequeño conforme $m’$ se hace grande, así que ésta es una sucesión de Cauchy. Por la compacidad de $X$ y completud de $\mathbb{R}^n$, tenemos que la sucesión converge a un punto $x_0$. Por continuidad, este punto satisface:
de donde $\norm{x-x_0}=0$, pues si no se tendría una contradicción. Así, $x=x_0$.
Desigualdades para la norma de Frobenius. Para $x\in \mathbb{R}^n$ y $A,B$ matrices reales de $n\times n$ tenemos que a) $\norm{Ax}\leq \norm{A} \norm{x}$ y b) $\norm{AB}\leq \norm{A} \norm{B}$.
La desigualdad (a) se prueba usando la desigualdad de Cauchy-Schwarz. En efecto, si $A_1,\ldots, A_n$ son los renglones de la matriz $A$, tenemos que $$Ax=(A_1\cdot x, A_2\cdot x, \ldots, A_n\cdot x),$$
entrada a entrada tenemos por Cauchy-Schwarz que
$$(A_i\cdot x)^2\leq \norm{A_i}^2\norm{x}^2,$$
de modo que sumando para $i=1,\ldots, n$ tenemos que
lo cual prueba la desigualdad (a). La desigualdad (b) se prueba de manera similar, tomando fila por fila a la matriz $A$ y columna por columna a la matriz $B$.
Desigualdad del valor medio. Sea $U\subset \mathbb{R}^n$ un abierto convexo y $F:U\to \mathbb{R}^n$ una función de clase $\mathcal{C}^1$. Sean $x,y$ puntos en $U$ para los cuales la cual la norma de Frobenius del Jacobiano $\norm{DF}$ está acotada sobre el segmento $xy$ por una constante $C$. Entonces:
$$\norm{F(x)-F(y)}\leq C \norm{x-y}.$$
La desigualdad del valor medio requiere de algunos pasos intermedios. Definamos $h=y-x$. La clave es probar las siguientes tres afirmaciones:
\begin{align*} F(x)-F(y)&=\int_0^1 DF(x+th) h \,dt\\ \norm{\int_0^1 DF(x+th) h \, dt } &\leq \int_0^1 \norm{DF(x+th)}\norm{h}\, dt\\ \int_0^1 \norm{DF(x+th)}\norm{h}\, dt &\leq C \norm{h}. \end{align*}
La primera es una «generalización» del teorema del valor medio de una variable. Se prueba coordenada a coordenada usando el Teorema Fundamental del Cálculo, la regla de la cadena y un intercambio de integral con suma (usando la continuidad de las derivadas parciales).
La segunda se prueba usando desigualdad del triángulo para integrales y la desigualdad (a) que probamos arriba para la norma de Frobenius.
La tercera se sigue de manera inmediata de la cota hipótesis para la matriz Jacobiana, pues $x+th=x+t(y-x)$ recorre el segmento $xy$ conforme $t$ recorre el intervalo $[0,1]$.
Combinando las tres afirmaciones concluimos
$$\norm{F(x)-F(y)}\leq C\norm{h}=C\norm{y-x},$$
que es justo lo que queríamos probar.
Con esto terminamos los pre-requisitos para probar el TFI. Aquí ya se ve algo interesante sucediendo. En el TFI queremos mostrar que cierta restricción es biyectiva, osea que cierto sistema de ecuaciones tiene una y sólo una solución. Esto se asemeja al teorema del punto fijo de Banach, donde, bajo ciertas condiciones de contracción, hay uno y sólo un punto fijo. El teorema de la desigualdad media puede ayudar a mostrar que una función contrae. Todo esto no es casualidad. A continuación veremos cómo combinar estos ingredientes.
Demostración del TFI
Estamos listos para dar la demostración del teorema de la función inversa. Por comodidad, aquí lo enunciamos de nuevo:
Teorema de la función inversa. Sea $F:\mathbb{R}^n\to \mathbb{R}^n$ una función de clase $\mathcal{C}^1$ con matriz Jacobiana $DF$. Supongamos que $F(a)=b$ y que $DF(a)$ es invertible. Entonces existen vecindades abiertas $U$ y $V$ de $a$ y $b$ respectivamente para las cuales:
a) $F:U\to V$ es una biyección, b) su inversa $F^{-1}:V\to U$ es de clase $\mathcal{C}^1$ y c) $DF^{-1}(b)=DF(a)^{-1}$.
Para el teorema necesitamos definir quién es el abierto $U$. Lo tomaremos como $U:=B(a,\epsilon)$, una bola abierta y centrada en $a$ de radio $\epsilon$. La idea es tomar $\epsilon$ tan pequeño como para que para $x\in U$ tengamos que $DF(x)$ sea invertible y
Ambas cosas las podemos hacer pues la asignación $x \mapsto DF(x)$ es continua ya que $F$ es de clase $\mathcal{C}^1$. En el transcurso de la prueba discutiremos la motivación de esta elección. A $V$ lo tomaremos como $F(U)$.
Lo primero que haremos es reformular parte (a) en términos de puntos fijos. Queremos que la restricción $F:U\to V$ que estamos buscando sea biyectiva. En otras palabras, para $y\in V$ queremos que la ecuación $y=F(x)$ tenga una y sólo una solución $x$ en $U$. Como por hipótesis la matriz $DF(a)$ es invertible, esto sucede si y sólo si
$$x+DF(a)^{-1}(y-F(x))=x,$$
es decir, si y sólo si $x$ es un punto fijo de la función $\varphi_y(x)=x+DF(a)^{-1}(y-F(x))$. Parece un poco artificial haber introducido a $DF(a)^{-1}$, pero como veremos a continuación tiene sentido pues nos ayudará para que $\varphi_y$ sea contracción.
Teniendo en mente que queremos usar la desigualdad del valor medio, calculamos y acotamos la norma de la derivada de $\varphi_y$ como sigue
Aquí es donde usamos (y se motiva parte de) nuestra elección de $U$: nos permite acotar $\norm{DF(a)-DF(x)}$ superiormente con $\frac{1}{2\norm{DF(a)^{-1}}} $ y por lo tanto podemos concluir la desigualdad anterior como
Por la desigualdad del valor medio, concluimos la siguiente observación clave.
Observacion. Para $y$ en $V$ tenemos que $\varphi_y$ es contracción en $U$ con factor $\lambda=\frac{1}{2}$. En otras palabras, para $x,w$ en $U$, tenemos $$\norm{\varphi_y(x)-\varphi_y(w)}\leq \frac{\norm{x-x’}}{2}.$$
La prueba a partir de ahora se divide en los siguientes pasos:
Mostrar que $F:U\to V$ es biyectiva.
Mostrar que $V$ es abierto
Mostrar que $F^{-1}:V\to U$ es diferenciable y y $DF^{-1}(b)=DF(a)^{-1}$
Mostrar que las derivadas parciales son continuas
$F:U\to V$ es biyectiva.
La suprayectividad la tenemos gratis, pues por definición $V=F(U)$.
Para la inyectividad, tomamos $y\in V$ y supongamos que existen $x$ y $w$ en $U$ tales que $F(x)=y=F(w)$. Esto quiere decir que $x$ y $w$ son puntos fijos de la contracción $\varphi_y$. Como vimos en la prueba del teorema del punto fijo de Banach, esto implica que $x=w$. Así, $x=w$, de modo que $F:U\to V$ es inyectiva y por lo tanto es biyectiva.
Nota: Aquí no estamos usamos el teorema del punto fijo de Banach pues $U$ no es compacto. Sólo estamos usando que las contracciones son inyectivas.
$V$ es abierto
Tomemos $y’$ en $V$, es decir, para la cual existe $x’$ en $U$ con $F(x’)=y’$. Queremos ver que si «$y$ está muy cerquita de $y’$» , entonces hay una solución para $F(x)=y$ con $x$ en $U$.
Como $U$ es abierto, existe $r$ tal que la bola $B(x’,2r)$ abierta de centro $x’$ y radio $2r$ se queda contenida en $U$. Tomemos $y$ en la bola $B\left(y’,\frac{r}{2\norm{DF(a)^{-1}}}\right)$. Vamos a ver que $F(x)=y$ tiene solución en $U$. Consideremos la función $\varphi_y$, pero restringida a la bola cerrada $X:=\overline{B}(x’,r)\subset U$. Mostraremos que la imagen de $\varphi_y$ se queda contenida en $\overline{B}(x’,r)$. En efecto:
\begin{align*} \norm{\varphi_y(x)-x’}&=\norm{\varphi_y(x)-\varphi_y(x’)+DF(a)^{-1}(y-y’)}\\ &\leq \norm{\varphi_y(x)-\varphi_y(x’)}+\norm{DF(a)^{-1}}\norm{y-y’}\\ &\leq \frac{\norm{x-x’}}{2}+\frac{r}{2}\leq r. \end{align*}
De este modo, $\varphi_y$ es una contracción del compacto $X$ a sí mismo. Por lo tanto, tiene un punto fijo en $X$, de modo que $F(x)=y$ para $x\in X\subset U$. Esto muestra que $V=F(U)$ es abierto.
$F^{-1}:V\to U$ es diferenciable y $DF^{-1}(b)=DF(a)^{-1}$
Vamos a demostrar que $F^{-1}:V\to U$ es diferenciable a partir de la definición de diferenciabilidad. Más aún, veremos que si $y=F(x)$ para $x$ en $U$, entonces $DF^{-1}(y)=DF(x)^{-1}$. Aquí es donde se termina de motivar nuestra elección en $U$, pues nos garantiza que a la derecha en efecto tenemos una matriz invertible.
Tomemos entonces $y=F(x)$. Nos interesa el límite cuando $\norm{h}\to 0$ de la siguiente expresión
Como $U$ es abierto, si $\norm{h}$ es pequeña entonces $y+h$ está en $U$. De este modo, existe $k$ tal que $x+k \in U$ y $F(x+k)=y+h$. Así, la expresión anterior la podemos reescribir como
Estamos listos para terminar. La desigualdad (3) también garantiza que $\norm{k}\to 0$ cuando $\norm{h}\to 0$. Así, como $F$ es diferenciable, tenemos que la expresión (4) tiende a $0$. Esto muestra que $F^{-1}$ es diferenciable en $y$ con $DF^{-1}(y)=DF(x)^{-1}$, tal como queríamos.
Las derivadas parciales son continuas
Esta parte es sencilla a partir de la parte anterior. Tenemos que:
$$DF^{-1}(b)=DF(F^{-1}(b))^{-1}$$
Por la regla de Cramer la inversa de una matriz depende continuamente de las entradas de la matriz original. Además, la asignación $b \mapsto F^{-1}(b)$ es continua. Así, las entradas de $DF^{-1}(b)$ (las derivadas parciales de $F^{-1}$) dependen continuamente de las derivadas parciales de $F$, que dependen continuamente de $b$ por hipótesis.
Con esto termina la prueba.
¿Ahora qué?
Si te gustó esta entrada, puedes compartirla o revisar otras relacionadas con matemáticas a nivel universitario:
En esta entrada se dan los resultados de la segunda etapa del VIII Concurso Universitario de Matemáticas Galois-Noether que se aplicó el día sábado 9 de junio de 2018. Hubo 27 participantes de habla hispana y 52 de habla portuguesa.
Problemas y soluciones
El examen consistió de seis problemas para resolver en cuatro horas y media. Al inicio del examen hubo media hora para aclarar los enunciados de los problemas. Puedes ver los problemas del examen, así como sus soluciones, en el siguiente archivo.
Cada problema se evaluó sobre 10 puntos, dando puntos parciales por avances hacia la solución.
A continuación se enuncia el tema de cada problema.
Problema 1: Desigualdades
Problema 2: Álgebra lineal
Problema 3: Cálculo
Problema 4: Teoría de números
Problema 5: Probabilidad
Problema 6: Teoría de grupos
De acuerdo a las estadísticas, los problemas 1, 2, 5 y 6 tuvieron aproximadamente la dificultad deseada. Los problemas 3 y 4 quedaron un poco más fáciles de lo que se esperaba, de modo que en las puntuaciones altas fue difícil marcar una distinción clara entre las habilidades de los concursantes. En años siguientes se buscará subir un poco la dificultad de estos problemas.
Sobre los concursantes
En total 79 personas presentaron el examen de segunda etapa. De entre los que presentaron el examen, el promedio redondeado a centésimas fue de 15.17. La calificación más alta fue 38 puntos y la más baja fue 2.
Ganadores del VIII Concurso Galois-Noether
A continuación se muestran los primeros tres lugares de la competencia. En caso de empate, el criterio de desempate fue la puntuación del examen de primera etapa.
Thiago – Landim de Souza Leao – Universidade Federal de Penambuco – Brasil
Thiago Ribeiro Tergolino – Instituto Militar de Engenharia – Brasil
Wesley Rodrigues Machado – Instituto Militar de Engenharia – Brasil
¡Muchas felicidades a ellos tres! Para quedar en estos lugares se requiere de una gran cantidad de trabajo bien orientado.
Selección de la UNAM para la IX CIIM
De acuerdo a la convocatoria, el examen Galois-Noether sirve como selectivo para determinar a los cuatro estudiantes que representan al equipo de la UNAM en la Competencia Iberoamericana Interuniversitaria de Matemáticas. Los cuatro alumnos de la UNAM con la mejor puntuación del examen y que participarán en la CIIM fueron:
Víctor Hugo Almendra Hernández
Leonardo Ariel García Morán
Siddhartha Emmanuel Guzmán Morales
Zeús Caballero Pérez
¡Muchas felicidades!
El Líder del Equipo de la UNAM para la IX CIIM fue el Mat. Luis Eduardo García Hernández, quien ha colaborado en la organización de la competencia y otras actividades de resolución de problemas a nivel universitario.
¡Les deseamos mucho éxito a todos ellos en la IX CIIM!
Constancias y dudas
Todos los concursantes que hayan participado en la segunda etapa pueden solicitar una constancia. Cualquier estudiante puede consultar su calificación personal desglosada por problema. Para realizar cualquiera de estas dos cosas, favor de escribir a leomtz@im.unam.mx.