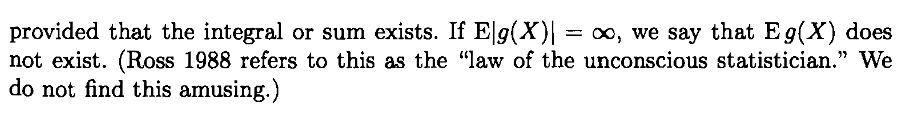Introducción
Como parte de nuestro estudio del valor esperado, en esta entrada abordaremos algunas más de sus propiedades. En la entrada antepasada vimos un primer conjunto de propiedades, y probablemente habrás notado que se trataba de propiedades en las que sólamente había una v.a. Por el contrario, conforme a lo visto en la entrada anterior, las propiedades que veremos en esta entrada involucran a más de una v.a., así que necesitaremos algunos de los elementos básicos de probabilidad multivariada que vimos.
En esta entrada centraremos nuestra atención en ver cómo interactúa el valor esperado con dos operaciones de variables aleatorias: la suma y el producto. Veremos que el valor esperado de la suma de dos v.a.’s se comporta de forma muy agradable, y podremos decir que es lineal. No obstante, el valor esperado del producto de dos v.a.’s requerirá de una condición extra para poder comportarse de manera agradable.
Linealidad con respecto a escalares
Una consecuencia de la ley del estadístico inconsciente es una primera propiedad de linealidad del valor esperado, con respecto a constantes reales.
Propiedad 1. Sea $X\colon\Omega\to\RR$ una variable aleatoria y sean $a$, $b \in \RR$. Entonces se cumple que
\begin{align*} \Esp{aX + b} &= a\Esp{X} + b \end{align*}
Demostración. Sea $g\colon\RR\to\RR$ la transformación dada por
\begin{align*} g(x) &= ax + b & \text{para cada $x \in \RR$}.\end{align*}
De este modo, $g(X) = aX + b$. Aplicando la ley del estadístico inconsciente, se sigue que:
- Si $X$ es una v.a. discreta, entonces \begin{align*} \Esp{g(X)} &= \sum_{x \in X[\Omega]} g(x) \Prob{X = x} \\[1em] &= \sum_{x \in X[\Omega]} (ax + b) \Prob{X = x} \\[1em] &= \sum_{x \in X[\Omega]} {\left( ax\Prob{X = x} + b\Prob{X = x}\right)} \\[1em] &= a \sum_{x\in X[\Omega]} x \Prob{X = x} + \sum_{x\in X[\Omega]} b \Prob{X = x} \\[1em] &= a\Esp{X} + \Esp{b} \\[1em] &= a\Esp{X} + b, \end{align*}por lo que es cierto en el caso discreto.
- Si $X$ es una v.a. continua, entonces $g(X)$ es una v.a. continua (porque $g$ es una transformación continua). Así, tenemos que \begin{align*} \Esp{g(X)} &= \int_{-\infty}^{\infty} g(x) f_{X}(x) \, \mathrm{d}x, \\[1em] &= \int_{-\infty}^{\infty} (ax + b) f_{X}(x) \, \mathrm{d}x \\[1em] &= \int_{-\infty}^{\infty} (axf_{X}(x) + bf_{X}(x)) \, \mathrm{d}x \\[1em] &= \int_{-\infty}^{\infty} axf_{X}(x) \, \mathrm{d}x + \int_{-\infty}^{\infty} bf_{X}(x) \, \mathrm{d}x \\[1em] &= a \int_{-\infty}^{\infty} xf_{X}(x) \, \mathrm{d}x + b\int_{-\infty}^{\infty} f_{X}(x) \, \mathrm{d}x \\[1em] &= a\Esp{X} + b, \end{align*}por lo que también es cierto en el caso continuo.
Por lo tanto, podemos concluir que si $X$ es una v.a. y $a$ y $b \in \RR$ son constantes reales, entonces
\begin{align*} \Esp{aX + b} &= a\Esp{X} + b, \end{align*}
que es justamente lo que queríamos demostrar.
$\square$
Es importante notar que para \(a = 1\), la propiedad anterior nos dice que para cualquier \(b \in \RR\) se cumple que
\begin{align*} \Esp{X + b} &= \Esp{X} + b, \end{align*}
lo cual es muy natural: si la v.a. \(X\) tiene una tendencia central hacia \(\Esp{X}\), entonces el comportamiento aleatorio de \(X + b\) estará centrado alrededor de \(\Esp{X} + b\), pues el valor \(b\) está fijo.
Valor esperado de la suma de v.a.’s
Dadas $X\colon\Omega\to\RR$ y $Y\colon\Omega\to\RR$ dos v.a.’s definidas sobre el mismo espacio de probabilidad, podemos definir la v.a. $(X+Y)\colon\Omega\to\RR$ dada por
\begin{align*} (X+Y)(\omega) &= X(\omega) + Y(\omega) & \text{para cada $\omega\in\Omega$}. \end{align*}
Ahora, si por alguna razón queremos calcular el valor esperado de $X+Y$, podríamos caer en la trampa de utilizar directamente la definición, e intentaríamos calcular
\begin{align*} \Esp{X+Y} &= \sum_{z \in (X+Y)[\Omega]} z \Prob{X + Y = z}, \end{align*}
en caso de que $X+Y$ sea discreta; o
\begin{align*} \Esp{X+Y} &= \int_{-\infty}^{\infty} z f_{X+Y}(z) \, \mathrm{d}z, \end{align*}
donde $f_{X+Y}\colon\RR\to\RR$ es la función de densidad de $X+Y$… algo que inicialmente no poseemos, incluso si las distribuciones de $X$ y de $Y$ son conocidas. Sin embargo, no es necesario hacer nada de esto: ¡el valor esperado es lineal! Esto lo enunciamos en la siguiente propiedad.
Propiedad 2. Sean $X\colon\Omega\to\RR$, $Y\colon\Omega\to\RR$ variables aleatorias con valor esperado finito definidas sobre el mismo espacio de probabilidad. Entonces
\begin{align*} \Esp{X + Y} &= \Esp{X} + \Esp{Y}. \end{align*}
Demostración. Demostraremos el caso en el que $X$ y $Y$ son v.a.’s discretas. Para ello, podemos recurrir directamente a la definición formal de valor esperado.
\begin{align*} \Esp{X + Y} &= \sum_{\omega\in\Omega} (X + Y)(\omega) \Prob{\{ \omega \}}. \end{align*}
Sabemos que $(X + Y)(\omega) = X(\omega) + Y(\omega)$, por lo que
\begin{align*} \sum_{\omega\in\Omega} (X + Y)(\omega) \Prob{\{ \omega \}} &= \sum_{\omega\in\Omega} (X(\omega) + Y(\omega)) \Prob{\{\omega\}} \\[1em] &=\sum_{\omega\in\Omega} {\left[X(\omega)\Prob{\{\omega\}} + Y(\omega)\Prob{\{\omega\}} \right]} \\[1em] &= \sum_{\omega\in\Omega} X(\omega) \Prob{\{\omega\}} + \sum_{\omega\in\Omega} Y(\omega) \Prob{\{\omega\}} \\[1em] &= \Esp{X} + \Esp{Y}, \end{align*}
por lo que $\Esp{X + Y} = \Esp{X} + \Esp{Y}$, que es justamente lo que queríamos demostrar.
$\square$
Por otro lado, omitiremos el caso cuando $X$ y $Y$ son v.a.’s continuas, pues la demostración (a este nivel) requiere de hacer más trampa, utilizando además una variante multivariada de la ley del estadístico inconsciente. No obstante, para propósitos de este curso, podrás asumir que el valor esperado es lineal en el caso discreto y en el continuo.
Valor esperado del producto de v.a.’s
De manera similar a la suma, dadas \(X\colon\Omega\to\RR\), \(Y\colon\Omega\to\RR\) v.a.’s, se define el producto de \(X\) con \(Y\) como la función \((XY)\colon\Omega\to\RR\) dada por
\begin{align*} (XY)(\omega) &= X(\omega) Y(\omega) & \text{para cada \(\omega\in\Omega\)}. \end{align*}
Es natural preguntarnos, ¿cómo se comporta esta operación con respecto al valor esperado? ¿Se comporta igual que la suma? Es decir, ¿será cierto que para cualesquiera v.a.’s \(X\) y \(Y\) se cumple que
\begin{align*} \Esp{XY} &= \Esp{X}\Esp{Y}? \end{align*}
La respuesta es que no, y te ofrecemos el siguiente ejemplo.
Ejemplo 1. Sean \(X\), \(Y\) v.a.’s con función de masa de probabilidad conjunta \(p_{X,Y}\colon\RR^{2}\to\RR\) dada por los valores en la siguiente tabla:
| \(X\) | ||||
| -1 | 1 | \(p_{Y}(y) \) | ||
| \(Y\) | 0 | 0.1 | 0.4 | 0.5 |
| 1 | 0.4 | 0.1 | 0.5 | |
| \(p_{X}(x)\) | 0.5 | 0.5 | ||
De este modo, se tiene que
\begin{align*} p_{X,Y}(-1,0) &= \Prob{X= -1, Y = 0} = 0.1, \\[1em] p_{X,Y}(1,0) &= \Prob{X = 1, Y = 0} = 0.4, \end{align*}
etcétera. En los extremos de la tabla hemos colocado las funciones de masa de probabilidad marginal de \(X\) y de \(Y\). Con ellas podemos calcular \(\Esp{X}\) y \(\Esp{Y}\) como sigue:
\begin{align*} \Esp{X} &= (−1)\cdot p_{X}(−1) + 1 \cdot p_{X}(1) = (−0.5) + 0.5 = 0, \\[1em] \Esp{Y} &= 0\cdot p_{Y}(0) + 1 \cdot p_{Y}(1) = 0 + 0.5 = 0.5. \end{align*}
Así, obtenemos que \(\Esp{X}\Esp{Y} = 0 \cdot 0.5 = 0\). Por otro lado, observa que \(XY\) puede tomar alguno de tres posibles valores: \(0\), \(1\) y \(-1\). \(XY\) vale \(0\) cuando \(Y\) toma el valor \(0\) y \(X\) toma cualquier valor; mientras que \(XY = 1\) cuando \(Y=1\) y \(X = 1\); y además \(XY = -1\) cuando \(Y=1\) y \(X=-1\). Esto nos da todas las probabilidades de \(XY\), que son
\begin{align*} \Prob{XY = 0} &= \Prob{X = 1, Y = 0} + \Prob{X = -1, Y = 0} = 0.4 + 0.1 = 0.5, \\[1em] \Prob{XY=1} &= \Prob{X=1,Y=1} = 0.1, \\[1em] \Prob{XY=-1} &= \Prob{X=-1,Y=0} = 0.4, \end{align*}
así que \(XY\) es una v.a. con función de masa de probabilidad \(p_{XY}\colon\RR\to\RR\) dada por
\begin{align*} p_{XY}(z) &= \begin{cases} 0.4 & \text{si \(z=-1\)}, \\[1em] 0.5 & \text{si \(z = 0\)}, \\[1em] 0.1 & \text{si \(z=1\)}, \\[1em] 0 & \text{en otro caso.}\end{cases}\end{align*}
Por lo tanto, el valor esperado de \(XY\) es
\begin{align*} \Esp{XY} &= (-1)\cdot p_{XY}(-1) + 0\cdot p_{XY}(0) + 1\cdot p_{XY}(1) = −0.4 + 0 + 0.1 = −0.3, \end{align*}
así que claramente \(\Esp{XY} \neq \Esp{X}\Esp{Y}\).
Sin embargo, hay una condición bajo la cual sí se cumple que \(\Esp{XY} = \Esp{X}\Esp{Y}\), que está dada por el siguiente teorema:
Teorema 1. Si \(X\), \(Y\) son variables aleatorias independientes, entonces se cumple que
\begin{align*} \Esp{XY} &= \Esp{X}\Esp{Y}. \end{align*}
La demostración de este teorema requiere de más acrobacias tramposas (a este nivel) con integrales múltiples, por lo que la omitiremos.
Observa que el teorema establece que si \(X\) y \(Y\) son v.a.’s independientes, entonces se tendrá que \(\Esp{XY} = \Esp{X}\Esp{Y}\). La implicación conversa no es verdadera, existen v.a.’s no-independientes que satisfacen \(\Esp{XY} = \Esp{X}\Esp{Y}\).
Tarea moral
Los siguientes ejercicios son opcionales. Es decir, no formarán parte de tu calificación. Sin embargo, te recomiendo resolverlos para que desarrolles tu dominio de los conceptos abordados en esta entrada.
- ¿Cómo interpretas la linealidad del valor esperado? Es decir, sabemos que si \(X\) es una v.a., entonces \(\Esp{X}\) es el «centroide esperado» al obtener muchas observaciones de \(X\), ¿cómo se interpreta que \(\Esp{X + Y} = \Esp{X} + \Esp{Y}\)?
- Por otro lado, no siempre se cumple que \(\Esp{XY} = \Esp{X}\Esp{Y}\). ¿Por qué pasa esto con el producto?
- Construye dos v.a.’s \(X\) y \(Y\) tales que \(\Esp{XY} = \Esp{X}\Esp{Y}\), pero de tal manera que \(X\) y \(Y\) no sean independientes. Sugerencia: Para asegurar la no-independencia, escoge una v.a. \(X\) sencilla (como las del Ejemplo 1), y toma a \(Y = g(X)\), donde \(g\) es una transformación conveniente.
Más adelante…
Debido a que el valor esperado es un concepto muy importante en la teoría (y en la práctica) de la probabilidad, las propiedades presentadas en esta entrada y la anterior son muy importantes, y te encontrarás con ellas muy a menudo. Además, en las materias de Probabilidad II y Procesos Estocásticos I verás temas que involucran más de una variable aleatoria (probabilidad multivariada) en los que utilizarás las propiedades vistas en esta entrada (y otras muy parecidas, pero más generales).
Volviendo a nuestro curso, en la entrada siguiente veremos otro valor asociado a una distribución de probabilidad: la varianza.
Entradas relacionadas
- Ir a Probabilidad I
- Entrada anterior del curso: Interacciones Entre Dos Variables Aleatorias
- Siguiente entrada del curso: Varianza de una Variable Aleatoria