Las siguientes notas de la Dr. Diana Avella Alaminos son las correspondientes al curso de Álgebra Superior 1, que se imparte en el primer semestre de la carrera de matemáticas de la Facultad de Ciencias de la UNAM.
Están divididas en 4 unidades, la primera correspondiente a conjuntos y funciones, la segunda está dedicada a la construcción y propiedades de los números naturales, la tercera es una introducción al estudio del espacio vectorial $\mathbb R^n$ , la cuarta y última unidad al estudio de matrices y determinantes.
A continuación se deja el el enlace a cada una de las notas según el orden y la unidad.
En la entrada anterior hablamos de derivadas parciales de segundo orden y dimos una condición sencilla de verificar para garantizar que ciertas derivadas mixtas sean iguales. Lo que haremos ahora es dar un siguiente paso y hablar de derivadas parciales de orden superior. Enunciaremos un resultado análogo al de la entrada anterior, para garantizar que cualesquiera dos derivadas conmuten. Un poco más adelante, usaremos las derivadas de orden superior para enunciar un teorema de Taylor para funciones de varias variables.
Definiciones de derivadas parciales de orden superior
En la entrada anterior tomamos un campo escalar $f:S\subset \mathbb{R}^{n}\to\mathbb{R}$ con dominio cierto abierto $S$ con derivadas parciales $$\frac{\partial f}{\partial x_1}, \frac{\partial f}{\partial x_2}, \ldots, \frac{\partial f}{\partial x_n}$$
en un cierto abierto $R\subset S$. Hicimos notar que cada una de estas funciones es nuevamente un campo escalar en el abierto $R$ y que por lo tanto podríamos hacernos nuevamente la pregunta, para cada una de ellas, si resulta tener derivadas parciales o no. En caso de que sí, esto nos permitía crear derivadas parciales de segundo orden, del estilo $$\frac{\partial^2 f}{\partial x_i \partial x_j}.$$
Al variar $i$ y $j$ de $1$ a $n$, obtenemos otras $n^2$ posibles funciones, que nuevamente son campos escalares, de las cuales nuevamente podemos preguntarnos si tienen o no derivadas parciales. Esta idea podemos iterarla tantas veces como queramos. Para formalizarla, planteamos la siguiente definición. La definición es para funciones con dominio $\mathbb{R}^n$ y un punto dado $\bar{a}$, pero se pueden hacer las adecuaciones necesarias para hablar de la diferenciabilidad de una función cunado su dominio es cierto abierto, o cuando se quiere hablar de diferenciabilidad en todo un abierto.
Definición. Sea $f:\mathbb{R}^n\to \mathbb{R}$ una función y $\bar{a}\in \mathbb{R}^n$ un vector. Definimos recursivamente sobre $k$ el símbolo
para $i_1,\ldots,i_k\in \{1,2,\ldots,n\}$ como sigue:
Si $k=0$, el símbolo simplemente representa a $f(\bar{a})$.
En otro caso, $$\frac{\partial^k f}{\partial x_{i_k}\cdots \partial x_{i_1}}(\bar{a}):=\frac{\partial}{\partial x_{i_k}} \left(\frac{\partial^{k-1} f}{\partial x_{i_{k-1}}\cdots \partial x_{i_1}}\right)(\bar{a}),$$ siempre y cuando se pueda derivar $$\frac{\partial^{k-1} f}{\partial x_{i_{k-1}}\cdots \partial x_{i_1}}$$ con respecto a la variable $x_{i_k}$ en el punto $\bar{a}$.
A ese símbolo le llamamos la derivada parcial de $f$ de $k$-ésimo orden con respecto a las variables $x_{i_k},\ldots,x_{i_1}$.
En otras palabras, siempre y cuando sea posible, tomamos $f$ y la vamos derivando primero con respecto a $x_{i_1}$, luego con respecto a $x_{i_2}$ y así sucesivamente hasta que la última derivación es con respecto a $x_{i_k}$.
Como en el caso de dos variables, nos permitiremos «agrupar variables en potencias» para simplificar algunas notaciones en caso de que la derivación sea consecutivamente con respecto a una misma variable. Por ejemplo, a la siguiente derivada parcial de orden $3$:
$$\frac{\partial^3 f}{\partial x \partial x \partial y}$$
usualmente la escribiremos en forma simplificada
$$\frac{\partial^3 f}{\partial x^2 \partial y}.$$
Ejemplos de derivadas parciales de orden $3$
Ejemplo. Tomemos el campo escalar $f:\mathbb{R}^3 \to \mathbb{R}$ dado por
$$f(x,y,z)=\sin(xyz).$$
Encontremos las siguientes derivadas parciales:
$$\frac{\partial^3 f}{\partial x \partial y^2}, \frac{\partial^3 f}{\partial x \partial y \partial z}, \frac{\partial^3 f}{\partial y^3}.$$
Comenzamos con $$\frac{\partial^3 f}{\partial x \partial y^2}$$
Sería algo laborioso encontrar todas todas las derivadas parciales de orden $3$ en el ejemplo anterior. ¡Son 27! Aunque, bueno, muchas de ellas serán iguales gracias a un teorema que enunciaremos en la siguiente sección.
Veamos un ejemplo de $\mathbb{R}^2$ en el que sí encontraremos todas las $8$ derivadas parciales de orden $3$.
Ejemplo. Veamos cuáles son todas las derivadas parciales de orden $3$ para el siguiente campo escalar $g:\mathbb{R}^2\to \mathbb{R}$:
$$g(x,y)=3x^2y^3.$$
Primero encontremos ambas derivadas parciales de primer orden
Finalmente, usamos estas últimas para encontrar las derivadas parciales de tercer orden. Primero, aquellas en donde derivamos las anteriores con respecto a $x$:
Hay varias de estas derivadas parciales del ejemplo anterior que son iguales. ¿Cuáles? ¿Cuál parece ser que sea el criterio para que dos derivadas parciales de orden superior sean iguales?
Conmutatividad de derivadas parciales de orden superior
En los ejemplos anteriores hay algunas derivadas de orden superior que coinciden entre sí. El siguiente teorema nos da una condición para garantizar la conmutatividad en el orden en que derivamos para una gran cantidad de situaciones. Una vez más, nos limitamos a enunciar el resultado para un punto dentro de un abierto
Teorema. Sea $f:\mathbb{R}^n\to \mathbb{R}$ una función y $k\geq 2$ un entero. Sean $i_1,\ldots, i_k, j_1,\ldots,j_k$ enteros con valores en $\{1,\ldots, n\}$. Supongamos que:
Hay un abierto $S\subset \mathbb{R}^n$ en el que las siguiente derivadas de orden $k$ existen: $$\frac{\partial^k f}{\partial x_{i_k}\cdots \partial x_{i_1}} \quad \text{y} \quad \frac{\partial^k f}{\partial x_{j_k}\cdots \partial x_{j_1}}.$$
Dichas derivadas son continuas en un punto $\bar{a}\in S$.
Cada entero de $1$ a $n$ aparece la misma cantidad de veces en $i_1,\ldots, i_k$ que en $j_1,\ldots,j_k$.
Entonces, ambas derivadas coinciden en $\bar{a}$.
La última condición es muy natural: tuvimos que haber derivado la misma cantidad de veces con respecto a cada variable. Así pues, por ejemplo, si tenemos $f:\mathbb{R}^3\to \mathbb{R}$ con las condiciones adecuadas de continuidad y diferenciabilidad, podríamos por ejemplo garantizar que:
$$\frac{\partial^7 f}{\partial x^2 \partial y \partial z \partial y^2 \partial x} = \frac{\partial^7 f}{\partial z \partial x^3 \partial y^3}.$$
No daremos la demostración del teorema, pero quedará como tarea moral. Para que puedas realizarla, estudia con mucho detalle la demostración del teorema de la entrada anterior. Ya que la manejes bien, la demostración de este teorema requerirá de que plantees adecuadamente una inducción para aprovechar al máximo la definición recursiva para derivadas parciales de orden $k$.
Más adelante…
Ya que hemos definido y entendido las derivadas parciales para cualquier orden $k$, podemos enunciar otro de los teoremas clásicos de cálculo de una variable, pero en su versión para campos escalares: el teorema de Taylor. Haremos esto en la siguiente entrada.
Tarea moral
Encuentra todas las derivadas parciales de orden $3$ (con respecto a todas las formas de elegir variables) para las siguientes funciones, enunciando apropiadamente el dominio en el que estás trabajando y en el que funionan tus cálculos.
Demuestra que el campo escalar $f:\mathbb{R}^n\to \mathbb{R}$ dado por $$f(x_1,\ldots,x_n)=e^{-(x_1+\ldots+x_n)}$$ tiene todas sus derivadas parciales con respecto a cualesquiera variables para todos los órdenes $k$.
Cuando una función $f:\mathbb{R}\to\mathbb{R}$ tiene todas sus derivadas de todos sus órdenes $f^{\prime}, f^{\prime \prime}, f^{(3)},\ldots$, decimos que es infinitamente diferencible o $C$-infinito (en símbolos «$f$ es $C^{\infty}$»). Haz una propuesta de qué querría decir que un campo escalar sea $C$-infinito. Verifica que si un campo escalar es $C$-infinito en todo $\mathbb{R}^n$, entonces se dan todas las conmutatividades de derivadas parciales.
Para convencerte de que el teorema de conmutatividad de derivadas parciales funciona, encuentra explícitamente las derivadas $$\frac{\partial^7 f}{\partial x^2 \partial y \partial z \partial y^2 \partial x} = \frac{\partial^7 f}{\partial z \partial x^3 \partial y^3}$$ para el campo escalar $f:\mathbb{R}^3\to \mathbb{R}$ dado por $f(x,y,z)=x^4y^4z$.
Demuestra el teorema de conmutatividad para derivadas parciales.
En las entradas anteriores definimos qué quiere decir que un campo escalar sea diferenciable. Así mismo, definimos las derivadas parciales y el gradiente. Ya usamos estas herramientas para hablar de dirección de cambio máximo y de puntos críticos. Además demostramos una versión del teorema del valor medio para este caso, lo que nos permitió poner un poco de orden a nuestra teoría: una función es diferenciable en un punto cuando existen sus parciales en ese punto y son continuas. Es momento de hablar de derivadas parciales de segundo orden. Cualquiera de las derivadas parciales es por sí misma un campo escalar, así que podemos preguntarnos si tiene o no sus propias derivadas parciales. Exploraremos esta idea.
Derivadas parciales de segundo orden
Las derivadas parciales de un campo escalar $f$ nos originan nuevos campos escalares. Supongamos que $f:S\subseteq \mathbb{R}^{n}\rightarrow \mathbb{R}$ es un campo escalar para el cual existe la $k$-ésima derivada parcial en un conjunto abierto $S’\subseteq S$. Entonces, obtenemos un nuevo campo escalar $\frac{\partial f}{\partial x_{k}}:S’\rightarrow \mathbb{R}$.
Este campo escalar puede o no tener $j$-ésima derivada parcial. Suponiendo que la tiene en algún $U\subseteq S’$ podríamos escribirla como
A esto le llamamos una derivada parcial de segundo orden. Si $j=k$, introducimos la notación
\[ \frac{\partial ^{2}f }{\partial x_{k}^{2}}.\]
Las derivadas parciales de segundo orden vuelven a ser, una vez más, cada una de ellas un campo escalar. Esto permite seguir iterando la idea: podríamos hablar de derivadas parciales de segundo, tercero, cuarto, … , $k$-ésimo, … orden. Daremos una definición un poco más formal en una siguente entrada, pero por ahora trabajemos en entender a las derivadas parciales de segundo orden.
Un ejemplo de derivadas parciales de segundo orden
Ejemplo. Consideremos el campo escalar $f(x,y,z)=x^{2}yz$. Para este campo escalar tenemos que sus derivadas parciales con respecto a $x$, $y$ y $z$ son:
Cada una de estas expresiones es a su vez un campo escalar. Cada una de ellas es derivable con respecto a $x$ en todo $\mathbb{R}^3$. Al derivarlas con respecto a $x$ obtenemos:
Por otro lado, las derivadas parciales de primer orden también podríamos haberlas derivado con respecto a $y$. En este caso, hubieramos obtenido.
\begin{align*} \frac{\partial ^{2}f}{\partial y \partial x}(x,y,z)&=2xz,\\ \frac{\partial ^{2}f}{\partial y ^2}(x,y,z)&=0,\\ \frac{\partial ^{2}f}{\partial y\partial z}(x,y,z)&=x^2. \end{align*}
También podríamos derivar a las derivadas parciales de primer orden con respecto a $z$ para obtener las tres derivadas de orden dos faltantes. En total tenemos tres derivadas parciales de primer orden y nueve derivadas parciales de segundo orden.
$\triangle$
Igualdad de las derivadas parciales de segundo orden mixtas
En numerosos campos escalares de interés tenemos una propiedad muy peculiar: que los operadores «obtener la derivada parcial con respecto a $x$» y «obtener la derivada parcial con respecto a $y$» conmutan. Es decir, varias veces podemos intercambiar el orden de derivación de las parciales y obtener el mismo resultado. En el ejemplo anterior quizás hayas notado que
Esto no siempre pasa, pero hay criterios de suficiencia sencillos de verificar. Por ejemplo, basta que las parciales mixtas existan y sean continuas para que sean iguales. El siguiente teorema formaliza el resultado.
Teorema. Sea $f:S\subseteq \mathbb{R}^{2}\rightarrow \mathbb{R}$ un campo escalar tal que las derivadas parciales $\frac{\partial f}{\partial x}$, $\frac{\partial f}{\partial y}$, $\frac{\partial^{2} f}{\partial y\partial x}$, $\frac{\partial ^{2}f}{\partial x\partial y}$ existen en un conjunto abierto $U$. Si $(a,b)\in U$ es tal que $\frac{\partial^{2} f}{\partial y\partial x}$, $\frac{\partial ^{2}f}{\partial x\partial y}$ son continuas en $(a,b)$, entonces dichas derivadas mixtas de segundo orden son iguales en $(a,b)$.
Demostración. Sean $h,k\neq 0$ suficientemente chicos para que los puntos en el plano $(a,b)$, $(a,b+k)$, $(a+h,b)$, y $(a+h,b+k)$ estén en $U$.
Definamos la función $\Gamma (x)=f(x,b+k)-f(x,b)$ para $x\in [a,a+h]$ y definamos
Notemos que $\Gamma$ es una función de $\mathbb{R}$ en $\mathbb{R}$ cuya derivada es $$\Gamma'(x)=\frac{\partial f}{\partial x}(x,b+k)-\frac{\partial f}{\partial x}(x,b).$$ Así, se le puede aplicar el teorema del valor medio con extremos en $a$ y $a+h$ para concluir que existe $\xi _{1}\in [a,a+h]$ que nos permite escribir $\Delta(h,k)$ de la siguiente manera:
Ahora podemos aplicar el teorema del valor medio en la función $y\mapsto \frac{\partial f}{\partial x} (\xi _{1},y)$ con extremos $b$ y $b+k$. Esto nos permite continuar la cadena de igualdades anterior mediante un $\eta _{1}\in [b,b+k]$ que cumple
Como $(\xi _{1},\eta _{1})\in [a,a+h]\times[b,b+k]$, se tiene que $(\xi _{1},\eta _{1})\to (a,b)$ conforme $(h,k)\to \bar{0}$.
Ahora consideremos análogamente a la función $\varLambda (y)=f(a+h,y)-f(a,y)$. Mediante un procedimiento similar al que acabamos de hacer, pero aplicado a $\varLambda$ en vez de a $\Gamma$, se tiene otra forma de expresar a $\Delta(h,k)$:
En esta entrada hablamos de las derivadas parciales de segundo orden y vimos que bajo condiciones razonables podemos elegir las variables de derivación en el orden que queramos. Estas ideas son más generales, y a continuación nos llevarán a definir las derivadas parciales de cualquier orden $k$. Después, usaremos estas derivadas parciales para generalizar otro de los teoremas de cálculo unidimensional: el teorema de Taylor.
Tarea moral
Para las siguientes funciones calcula $\frac{\partial ^{2}f}{\partial x^{2}}$:
$f(x,y)=x^{2}+y^{2}cos(xy)$
$f(x,y)=e^{x}cos(y)$
$f(x,y,z)=\textup{log}(x^{2}+2y^{2}-3z^{2})$
En el teorema que afirma que las derivadas parciales mixtas son iguales usamos cuatro veces el teorema del valor medio (¿cuáles 4 son?). Asegúrate de que en verdad lo podamos usar.
Calcula $\frac{\partial ^{2}f}{\partial y^{2}}$, y $\frac{\partial ^{2}f}{\partial x\partial y}$ para las funciones del punto 1. Explica por qué no es necesario calcular de manera separada $\frac{\partial ^{2}f}{\partial y\partial x}$
Investiga de un ejemplo en el que las derivadas parciales $\frac{\partial ^{2}f}{\partial x\partial y}$ y $\frac{\partial ^{2}f}{\partial y\partial x}$ no sean iguales. Realiza las cuentas para verificar que en efecto tienen valores distintos en algún punto.
El teorema que enunciamos está muy limitado. Sólo nos habla de campos escalares de $\mathbb{R}^2$ en $\mathbb{R}$. Sin embargo, debería también funcionar si $f:\mathbb{R}^n\to \mathbb{R}$. Enuncia y demuestra un resultado similar que te permita garantizar que $$\frac{\partial^{2} f}{\partial x_i\partial x_j}=\frac{\partial ^{2}f}{\partial x_j\partial x_i}.$$
Ya hemos definido qué es el gradiente $\nabla f$ de un campo escalar $f$. Hemos visto cómo está relacionado con las derivadas direccionales. Así mismo, mostramos que conocer este gradiente nos permite dar información sobre los máximos y mínimos del campo escalar. En esta entrada mostraremos una propiedad más del gradiente: que nos ayuda a dar una generalización del teorema del valor medio de Cálculo I, pero para campos escalares. Este será un resultado fundamental para demostrar otras propiedades de los campos escalares. Como ejemplo, también damos en esta entrada un criterio suficiente para que un campo escalar sea diferenciable.
Teorema del valor medio para funciones de $\mathbb{R}$ en $\mathbb{R}$
Para facilitar la lectura de este material, recordemos lo que nos dice el teorema del valor medio sencillo, es decir, el de $\mathbb{R}$ en $\mathbb{R}$.
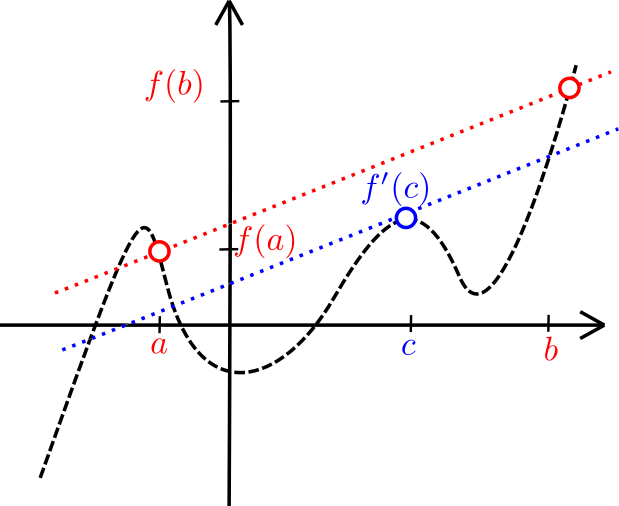
Teorema. Sean $a<b$ reales. Sea $f:[a,b]\to\mathbb{R}$ una función continua en el intervalo $[a,b]$ y diferenciable en el intervalo $(a,b)$. Entonces existe algún punto $c\in (a,b)$ tal que $$f'(c)=\frac{f(b)-f(a)}{b-a}.$$
Una vez que uno interpreta el teorema gráficamente, se vuelve muy intuitivo. Considera la siguiente figura.
Intuición geométrica del teorema del valor medio
El término $$\frac{f(b)-f(a)}{b-a}$$ es la pendiente del segmento que une los puntos $(a,f(a))$ y $(b,f(b))$ El término $f'(c)$ va marcando la pendiente de la recta tangente a $f$ en cada punto $c$. En términos geométricos, lo que nos dice este teorema es que para algún valor de $c$, la pendiente de la recta tangente en $c$ es la pendiente del segmento entre los extremos.
Lo que haremos a continuación es dar una generalización apropiada para funciones de $\mathbb{R}^n$ a $\mathbb{R}$.
Teorema del valor medio para funciones de $\mathbb{R}^n$ en $\mathbb{R}$
Para generalizar el teorema del valor medio a funciones de $\mathbb{R}^n$ a $\mathbb{R}$, necesitaremos cambiar un poco las hipótesis. El segmento $[a,b]$ que usábamos ahora será un segmento (multidimensional) que conecte a dos vectores $\bar{x}$ y $\bar{y}$ en $\mathbb{R}^n$. La diferenciabilidad la pediremos en todo un abierto que contenga al segmento. El enunciado apropiado se encuentra a continuación.
Teorema (del valor medio para campos escalares). Sea $S$ un abierto de $\mathbb{R}^n$. Tomemos $f:S\subseteq \mathbb{R}^{n}\rightarrow \mathbb{R}$ un campo escalar diferenciable. Sean $\bar{x}$ y $\bar{y}$ en $S$ tales que el segmento que une a $\bar{x}$ con $\bar{y}$ se queda contenido en $S$. Entonces, existe $c \in (0,1)$ tal que $$\nabla f((1-c )\bar{x}+c \bar{y})\cdot (\bar{y}-\bar{x})=f(\bar{y})-f(\bar{x}).$$
En este caso no podemos «pasar dividiendo $\bar{y}-\bar{x}$» pues no tiene sentido dividir entre vectores. Pero en el caso $n=1$ sí se puede, y justo obtenemos de vuelta el teorema del valor medio de $\mathbb{R}$ en $\mathbb{R}$. Uno podría pensar que entonces esta es una manera alternativa de demostrar el teorema para funciones de $\mathbb{R}$ en $\mathbb{R}$. Sin embargo, como veremos a continuación, la demostración de la versión para campos escalares usa la versión para funciones reales.
Demostración. Consideremos la función $\gamma:[0,1] \to \mathbb{R}^{n}$ dada $\gamma (t)=(1-t)\bar{x}+t\bar{y}$. Notemos que $\gamma$ es diferenciable, con $\gamma’ (t)=\bar{y}-\bar{x}$. Además, por hipótesis $f$ es diferenciable en $S$. Así, $f\circ \gamma:[0,1]\to \mathbb{R}$ también es diferenciable, y por regla de la cadena
¡Pero $f\circ \gamma$ ya es una función de $\mathbb{R}$ en $\mathbb{R}$! Así, podemos aplicarle el teorema del valor medio real (verifica las hipótesis como tarea moral). Al hacer esto, obtenemos que existe una $c\in (0,1)$ tal que \begin{align*} (f\circ \gamma)'(c) &= \frac{(f\circ \gamma)(1)-(f\circ \gamma)(0)}{1-0}\\ &=f(\bar{y})-f(\bar{x}). \end{align*}
Usando la fórmula que obtuvimos por regla de la cadena para $(f\circ \gamma)’$ y la definición de $\gamma$ obtenemos que
En el teorema anterior estamos pidiendo que $f$ sea diferenciable. Sin embargo, basta con que exista la derivada de la composición en el segmento que nos interesa y el resultado también se sigue. Es decir, tenemos la siguiente versión con una hipótesis más débil. La enunciamos pues la usaremos en la siguiente sección.
Teorema (del valor medio para campos escalares, hipótesis debilitada). Sea $S$ un abierto de $\mathbb{R}^n$. Tomemos $f:S\subseteq \mathbb{R}^{n}\rightarrow \mathbb{R}$ un campo escalar. Sean $\bar{x}$ y $\bar{y}$ en $S$ tales que el segmento que une a $\bar{x}$ con $\bar{y}$ se queda contenido en $S$ y tales que para toda $c\in[0,1]$ se cumple que la derivada (real) de $f((1-c)\bar{x}+c\bar{y}))$ existe. Entonces, existe $c \in (0,1)$ tal que $$\nabla f((1-c )\bar{x}+c \bar{y})\cdot (\bar{y}-\bar{x})=f(\bar{y})-f(\bar{x}).$$
La demostración es exactamente la misma.
Aplicación del teorema del valor medio
Como primera aplicación del teorema del valor medio para campos escalares mostraremos un criterio de diferenciabilidad muy útil, al que llamaremos el teorema de diferenciabilidad y derivadas parciales.
Teorema. Sea $f:S\subseteq \mathbb{R}^{n}\rightarrow \mathbb{R}$ un campo escalar. Supongamos que para cierto punto $\bar{a}\in S$ y cierta vecindad $B_r(\bar{a})\subset S$ existen las derivadas parciales $\frac{\partial f}{\partial x_{1}},\dots ,\frac{\partial f}{\partial x_{n}}$ y son continuas en $\bar{a}$. Entonces $f$ es diferenciable en $\bar{a}$.
Demostración. Elijamos un vector $\bar{u}=u_1\hat{e}_1+\dots +u_n\hat{e}_n$ de norma $1$ y tomemos $\bar{v}=\lambda \bar{u}$ con $\lambda$ suficientemente chico como para que $\bar{a}+\bar{v}$ esté en $B_{r}(\bar{a})$. Definamos los siguientes vectores:
Notemos que el $k$-ésimo término de esta suma puede ser escrito como $$f(\bar{a}+\lambda \bar{v}_{k-1}+\lambda u_{k}\hat{e}_{k})-f(\bar{a}+\lambda \bar{v}_{k-1}).$$ Para simplificar, definimos $\bar{b}_{k}=\bar{a}+\lambda \bar{v}_{k-1}$ y reescribiendo el $k$-ésimo término tenemos $$f(\bar{b}_{k}+\lambda u_{k}\hat{e}_{k})-f(\bar{b}_{k}).$$
Aplicando el teorema del valor medio con hipótesis debilidada para campos escalares a los puntos $\bar{b}_{k}$ y $\bar{b}_{k}+\lambda u_{k}\hat{e}_{k}$ (verifica las hipótesis), tenemos que para cada $k$ existe $\xi_k \in (0,1)$ tal que
en donde hemos definido $\bar{c}_k:=(1-\xi_k )\bar{b}_{k}+\xi_k (\bar{b}_{k}+\lambda u_{k}\hat{e}_{k})$, que es un punto en el segmento que une a $\bar{b}_k$ con $\bar{b}_k+\lambda u_k\hat{e}_k$.
Tenemos pues que podemos escribir al $k$-ésimo término como:
En unos momentos usaremos esta expresión. Antes de ello, estudiemos otro de los términos involucrados en la diferenciabilidad. Tenemos que:
\begin{align} \triangledown f(\bar{a})\cdot \bar{v}&=\triangledown f(\bar{a})\cdot \lambda u \nonumber\\ &=\lambda \triangledown f(\bar{a})\cdot u \nonumber\\ &=\lambda \sum_{k=1}^{n}u_{k}\frac{\partial f}{\partial x_{k}}(\bar{a}) \label{eq:ppunto}. \end{align}
Empecemos entonces a combinar lo visto hasta ahora para entender los términos en la definición de diferenciabilidad. Tenemos juntando \eqref{eq:resumen} y \eqref{eq:ppunto} que
El teorema de diferenciabilidad nos dice que si las derivadas parciales existen y son continuas, entonces la función es diferenciable. Sin embargo, el regreso de este teorema no se vale, en el sentido de que existen funciones diferenciables cuyas derivadas parciales no son continuas. En otras palabras, si las derivadas parciales no son continuas, no podemos descartar la diferenciablidad de una función.
A continuación esbozamos un ejemplo que deberás completar como tarea moral.
Se puede demostrar que $f$ es diferenciable en $(0,0)$. De manera intuitiva, la función queda entre las funciones $(x,y)\to x^2+y^2$ y $(x,y)\to -x^2-y^2$. Se puede usar un argumento de acotamiento para mostrar que el plano tangente coincide entonces con el de estas funciones en $(0,0)$ que es el plano $z=0$. Verifica los detalles de tarea moral.
Así mismo, se puede ver que las derivadas parciales en $(0,0)$ existen y que de hecho se satisface $$\frac{\partial f}{\partial x} (0,0) = \frac{\partial f}{\partial y} (0,0) = 0.$$
Finalmente, se puede ver que las derivadas parciales no convergen a $0$. Fuera del $(0,0)$, tenemos por reglas de derivación que
Una manear de ver que estas no son contínuas es aproximándonos por un eje. Por ejemplo, puedes verificar que sobre el eje $x$, conforme $x\to 0$, tenemos que la primera parcial oscila entre $-1$ y $1$.
$\triangle$
Más adelante…
Hemos enunciado y demostrado una versión del teorema del valor medio para campos escalaras. Gracias a ella hemos podido mostrar que si un campo escalar tiene derivadas parciales continuas, entonces es diferenciable. Las aplicaciones del teorema del valor medio para campos escalares van más allá. En la siguiente entrada hablaremos de las derivadas parciales de orden superior. El teorema del valor medio para campos escalares nos permitirá demostrar que bajo ciertas condiciones, en cierto sentido estas derivadas parciales «conmutan».
Tarea moral
¿Qué dice el teorema del valor medio para campos escalares para la función $f(x,y)=\sin(x)\cos(y)$ tomando como extremos los puntos $\left(0,\frac{\pi}{2}\right)$ y $\left(\frac{\pi}{2},0\right)$? Verifica si puedes aplicar las hipótesis.
En la demostración del teorema del valor medio que dimos, verifica que la función $f\circ \gamma$ dada en efecto satisface las hipótesis del teorema del valor medio real.
Supongamos que $f:\mathbb{R}^n\to \mathbb{R}$ es diferenciable en un abierto $S$ que contiene al segmento cuyos extremos son ciertos vectores $\bar{x}$ y $\bar{y}$ de $\mathbb{R}^n$. Supongamos que $f(\bar{x})=f(\bar{y})$. ¿Será cierto siempre que $\nabla f$ se anula en algún vector del segmento que une $x$ con $y$? Ten cuidado, pues hay un producto escalar involucrado. En caso de que no siempre sea cierto, ¿Qué es lo que sí puedes garantizar?
En la demostración del teorema de diferenciabilidad, verifica que se pueden usar las hipótesis del teorema del valor medio para campos escalares con hipótesis debilitada. Necesitarás ver que la derivada real que tiene que existir es justo una parcial de las que suponemos que existen, completa los detalles. Luego, verifica que en efecto la conclusión que obtuvimos es justo la que se obtiene. Observa además que no podemos usar el teorema del valor medio para campos diferenciables con la hipótesis usual pues necesitaríamos saber que $f$ es diferenciable, lo cual es justo lo que queremos mostrar.
Completa el contraejemplo al regreso del teorema de diferenciabilidad. Entre otras cosas, tienes que hacer lo siguiente:
Verificar que en efecto la función es diferenciable en $(0,0)$. Puedes proceder por definición o acotando como se sugiere.
Revisar que las parciales en $(0,0)$ en efecto existen y coinciden con lo que sabemos a partir de que el plano tangente en el origen es $(0,0)$.
Obtener paso a paso la fórmula que dimos para las parciales, usando lo que sabes de regla de la cadena, derivadas en $\mathbb{R}$, etc.
Verificar que ninguna de las dos derivadas parciales es continua, completando el argumento de que al acercarnos por los ejes tenemos oscilaciones.
(Trabajo de titulación asesorado por la Dra. Diana Avella Alaminos)
Introducción
¡Hoy es el día en el que comenzamos la Unidad 4!
A partir de esta unidad veremos que cada uno de los elementos de los grupos (para cualquier grupo) se puede ver como una permutación. Para fines introductorios, ilustremos qué pasa en el caso de un grupo finito. Sea $G = \{e,g_2,\dots, g_n\}$. Podemos escribir su tabla de producto ($*$):
$*$
$e$
$g_2$
$g_3$
$\cdots$
$g_n$
$e$
$g_2$
$g_3$
$\vdots$
$a = g_i$
$ae$
$ag_2$
$ag_3$
$\cdots$
$ag_n$
$\vdots$
$g_n$
¿Qué pasa si elegimos un elemento fijo? Fijemos $g_i$, para distinguirlo, denotémoslo como $a = g_i.$ Así, en la tabla del producto ese renglón quedaría $ae \;\; ag_2 \;\; ag_3 \;\; \cdots \;\; ag_n$. Como tanto $a = g_i$ como $e,g_2,\dots g_n$ están en $G$, ese renglón está conformado por elementos de $G$.
Podría darse el caso en que $ag_k = ag_t$ para algún $k,t\in \{1,\dots,n\}$, pero como $G$ es un grupo, podemos cancelar la $a$. Entonces $ag_k = ag_t \Leftrightarrow g_k = g_t$. Así, si suponemos que $g_k \neq g_t$ para todas $k \neq t$ con $k,t\in \{1,\dots,n\}$, en el renglón de $a$ aparecen $n$ elementos distintos. Es decir, aparecen todos los $n$ elementos de $G$ pero quizás en otro orden.
De esta manera, el efecto que tiene $a$ sobre los elementos de $G$ es de moverlos. Esto sucederá en cualquier renglón de la tabla, es decir, cualquier elemento de $G$ funciona como una permutación. Esto es importante porque nos permitirá visualizar a cualquier grupo como un grupo de permutaciones.
Ésta es la razón por la cual las permutaciones son tan importantes y por eso tenemos que estudiarlas bien.
La función tau $\tau$
Bajo la idea propuesta en la introducción de esta entrada, todo grupo se puede pensar como un subgrupo de un grupo de permutaciones. Para formalizar esta idea comenzaremos con un lema.
Lema. Sean $G$ un grupo y $a\in G$. La función $\tau_a:G \to G$ dada por $\tau_a(g) = ag$ para todo $g\in G$, es una biyección.
Demostración. Sean $G$ un grupo y $a\in G$. Consideremos la función $\tau_a:G\to G$ con $\tau_a(g) = ag$ para todo $g\in G$.
P.D. $\tau_a$ es biyectiva. Consideremos la función $\tau_{a^{-1}}:G\to G$ con $\tau_{a^{-1}} = a^{-1} g$, para toda $g\in G.$ Dado $g\in G$. \begin{align*} \tau_{a^{-1}}\circ\tau_a(g) & = \tau_{a^{-1}}(\tau_a(g)) = \tau_{a^{-1}}(ag) = a^{-1}(ag) = g\\ \tau_a\circ\tau_{a^{-1}}(g) &= \tau_a(\tau_{a^{-1}}(g)) = \tau_a(a^{-1}g) = a(a^{-1}g) = g. \end{align*}
Donde todas las igualdades son por definición de $\tau_a$ y $\tau_{a^{-1}}$ o por propiedades de grupo.
Así, $\tau_{a^{-1}}$ es la inversa de $\tau_a$ y entonces $\tau_a$ es biyectiva.
$\blacksquare$
Observación. Si $a\neq e$, $\tau_a$ no es un homomorfismo. La demostración queda como ejercicio. Sucederá que si $a\neq e$, entonces $\tau_a$ seguirá siendo una función biyectiva, pero no un homomorfismo.
El título de la entrada
El Teorema de Cayley es quien nos dirá exactamente lo que queremos formalizar en esta entrada.
Teorema. (Teorema de Cayley) Todo grupo $G$ es isomorfo a un subgrupo de $S_G$. En particular, todo grupo finito de orden $n$ es isomorfo a un subgrupo de $S_n$.
Demostración. Sea $G$ un grupo. De acuerdo al lema anterior, para cada $a\in G$ se tiene que $\tau_a$ es una función biyectiva de $G$ en $G$, es decir $\tau_a\in S_G$. Definimos entonces \begin{align*} \phi: G \to S_G \text{ con } \phi(a) = \tau_a \; \forall a\in G. \end{align*}
Veamos que $\phi$ es un homomorfismo. Tomemos $a,b\in G$. P.D. $\phi(ab) = \phi(a)\circ\phi(b)$.
Dado que en todas las funciones involucradas tanto el dominio como el condominio es $G$, basta probar que $\phi(ab) $ y $\phi(a)\circ\phi(b)$ tienen la misma regla de correspondencia. Sea $g\in G$. Entonces, apliquemos la función $\phi(ab)$ a $g$. Obtenemos, \begin{align*} \phi(ab)(g) &= \tau_{ab}(g)\\ &= (ab)g \\ &= a(bg) \\ &= \tau_a(\tau_b(g)) \\ & = \tau_a\circ\tau_b(g) = \phi(a)\circ\phi(b)(g). \end{align*}
Por lo tanto $\phi(ab) = \phi(a)\circ\phi(b)$, probando así que $\phi$ es un homomorfismo.
Veamos ahora que $\phi$ es un monomorfismo. Sea $a\in \text{Núc }\varphi$. Entonces, \begin{align*} a\in \text{Núc }\varphi \Rightarrow\; & \phi(a) = \text{id}_G & \text{Definición de Núc}\\ \Rightarrow\; & \phi(a) (g) = \text{id}_G(g) &\forall g\in G \\ \Rightarrow\; & \tau_a(g) = g & \forall g\in G\\ \Rightarrow\; &ag = g & \forall g\in G \\ \Rightarrow\; &a = e. \end{align*}
Donde la última implicación se puede justificar considerando el caso particular $g = e$. De esta manera $\phi$ es un monomorfismo.
Así, al restringir el codominio de $\phi $ a la imagen $\text{Im }\phi$ obtenemos un isomorfismo. Por lo tanto $G\cong \text{Im }\phi \leq S_G$. Con esto tenemos la primero parte del teorema demostrada.
En particular, si $|G| = n $ tenemos que $S_G \cong S_n$ y como $G\cong \text{Im }\phi \leq S_G\cong S_n$, entonces $G$ es isomorfo a un subgrupo de $S_n$.
$\blacksquare$
Ejemplo:
Tomemos $V = \{(0,0), (1,0), (0,1), (1,1)\}$ el grupo de Klein, con la suma entrada a entrada módulo 2. Sean $a_1 = (0,0), a_2 = (1,0), a_3 = (0,1), a_4 = (1,1)$. Tenemos la tabla de suma de la siguiente manera:
$+$
$a_1$
$a_2$
$a_3$
$a_4$
$a_1$
$a_1$
$a_2$
$a_3$
$a_4$
$a_2$
$a_2$
$a_1$
$a_4$
$a_3$
$a_3$
$a_3$
$a_4$
$a_1$
$a_2$
$a_4$
$a_4$
$a_3$
$a_2$
$a_1$
Entonces $\tau_{a_2}$ intercambia $a_1$ y $a_2$ e intercambia $a_3$ y $a_4$ de lugar. Viendo a $a_2$ como una permutación, correspondería a $\sigma \in S_4$ con $\sigma = (1\;2)(3\;4).$
Tarea moral
A continuación hay algunos ejercicios para que practiques los conceptos vistos en esta entrada. Te será de mucha utilidad intentarlos para entender más la teoría vista.
Demostrar la observación: Observación. Si $a\neq e$, $\tau_a$ no es un homomorfismo.
Para los siguientes grupos $G$ y $g\in G$ determina cómo es la función $\tau_g:$
$G$ es cíclico de orden 6, $g$ un generador de $G$.
$G = D_{2(4)}$, $g = b$ la reflexión sobre el eje $x$.
$G = Q$, $g = -j$.
En los diferentes inicios del ejercicio anterior, describe cómo se puede visualizar al elemento $g\in G$ como una permutación en $S_n$ con $n = |G|.$
Más adelante…
Esta entrada es la primera de la unidad 4 porque a partir de aquí vamos a abstraer aún más lo que se trabajó en el Teorema de Cayley. Aquí vimos que un grupo se puede ver como un subgrupo de permutaciones porque podemos multiplicar $g\in G$ con todos los elementos de $G$. Pero a lo largo de este curso vimos varias operaciones que están definidas a partir del producto de $G$, por ejemplo, si tenemos $aN \in G/N$ con $N$ normal en $G$, es perfectamente válido operar $gaN$. Siguiendo la lógica del Teorema de Cayley, ¿qué pasa si definimos una nueva función multiplicando las clases laterales por los elementos del grupo? ¿Será posible definir algún tipo de operación entre los elementos de un grupo y un conjunto ya no necesariamente de clases laterales? Éstas y más preguntas serán respondidas en las siguientes entradas.