
Introducción
En este apartado, se abordarán los orígenes que dieron lugar al nacimiento de las matemáticas financieras, las primeras operaciones en las que fueron utilizadas, la aparición del concepto de interés, la descripción de las variables y cómo fueron evolucionando a través de los años y se hablara de forma general acerca del sistema financiero mexicano, tema indispensable para poder llevar a cabo cualquier actividad económica.
Las matemáticas financieras están presentes en la vida cotidiana, tanto de empresas como de personas ya que, muchas de las actividades que se realizan a diario, y sobre todo las que tienen que ver con decisiones que involucra dinero, se llevan a cabo gracias al uso de la matemática, aunque en la gran mayoría de veces lo hagamos de forma inconsciente.
Y es que justamente la matemática, nos proporciona una gran cantidad de herramientas que nos permiten modelar, al mismo tiempo que nos otorgan información para tomar mejores decisiones, cuando nos enfrentamos a algún problema de índole económico.
Historia
El origen del concepto de interés, se puede ubicar a lo largo de la historia, desde el momento en el que, el ser humano, comenzó ha prestar sus bienes o posesiones a otro; exigiendo que se le devuelve el bien o recurso inicial, más aparte una cantidad extra.
A lo largo de miles de años y en diversas culturas como la fenicia, hebrea, griega, egipcia y china, ha sido una práctica común y equitativa recibir una compensación cuando una persona presta un bien, servicio o una suma de dinero a otra persona. Esto nos lleva a pensar que en la idea de que se tiene que hacer un pago en agradecimiento a por haber hecho uso de un bien ajeno. Este pago de compensación, a menudo denominado interés, se fundamenta en el hecho de que el prestamista está cediendo temporalmente su propiedad a favor del prestatario. Durante este período, el prestamista se priva del uso de ese bien, lo que justifica recibir una recompensa que compense esta privación.
En el Siglo XVIII, Jeremy Bentham (1748-1832) formuló la teoría utilitarista, en la que planteaba que todo individuo que prestaba un bien, también sacrificaba la utilidad de que él mismo había podido darle si hubiera decidido conservarlo. De ésta idea surge, que es razonable que al finalizar el dicho préstamo, la persona que había sido beneficiada, otorgará una cantidad extra como por haberse privado de dicho bien o recurso.
Éstas ideas fueron adoptadas por los economistas del siglo XX, en particular por Irving Fisher, el cual desarrollo la teoría del interés, en la que plantea la razón de la exigencia de intereses en la devolución de cualquier préstamo, agregando que dicha compensación no solamente se basa en la utilidad del bien, sino que también agrego la cantidad de tiempo en que fue prestado. Es decir, no sólo tenían que ver aspectos cuantitativos, sino también temporales. Es Fisher quien comienza a introducir la noción de tasas de interés.
Objetivo de las Matemáticas Financieras
El objetivo principal de las Matemáticas Financieras es desarrollar modelos matemáticos, que describan este fenómeno social que hemos mencionado. Para lograrlo, examinaremos cómo se realizan los pagos de intereses y analizaremos las variables involucradas en esta actividad, considerando cómo interactúan a lo largo del tiempo.
Definición de Finanzas
Las finanzas es un concepto que de acuerdo con la RAE, es una palabra que tiene sus orígenes del frances «finance» y significa como una obligación que asume una persona para responder a la obligación de otra. La relación que salta a la vista, es muy estrecha con el concepto de interés mencionado anteriormente. En otras palabras Finanzas se define como una rama de la economía que se enfoca en la administración científica y el desarrollo futuro de recursos que comprenden dinero, créditos y activos, con el fin de obtener un máximo beneficio y equilibrado para los dueños, socios, trabajadores de las empresas, y de la sociedad.
Sistema Financiero Mexicano
En la actualidad, para que dichas operaciones se puedan llevar a cabo, es necesario contar con un sistema que regule cada una de ellas, en ése entendido de ideas, el sistema que nos permite realizarlas de forma sana y equitativa posible. El Sistema Financiero Mexicano es el encargado de regular todas las operaciones financieras que se realizan en nuestro país. Dicho Sistema Financiero está formado por intermediarios financieros que captan, administran canalizando el ahorro y la inversión para prestarlo a quien requieren el dinero. Dentro de este sistema se encuentran también incluidas, autoridades financieras las cuales se encargan de regular, supervisar y proteger dichos recursos económicos, En otras palabras el sistema financiero mexicano, es el que se encarga de generar las condiciones necesarias para poder desarrollar cualquier actividad económica tales como producir o consumir, y que el dinero que resulta de realizar dicha actividad, pueda tener los medios para llegar a las personas que necesitan dichos recursos.
En términos formales, se define como Sistema Financiero Mexicano al conjunto de instituciones públicas, del sector gubernamental, privadas y del sector empresarial, a través de las cuales se llevan a cabo y se regulan las actividades en las operaciones de otorgación y obtención de créditos, la realización de inversiones, prestación de diversos servicios bancarios, emisión y colocación de instrumentos bursátiles y todas aquellas relativas a la actividad financiera.*
Las personas que cuentan con dinero pero no lo necesitan en un corto plazo, son las que se encuentran en posición de poder prestarlo, de esta manera las personas que t necesitan más dinero del que poseen, ya sea porque se encuentran realizando un proyecto de emprendimiento (un negocio, poner una panadería por ejemplo), tiene la forma de poder obtenerlo, y en tal situación; se comprometen a devolver esos recursos después de un tiempo determinado con una compensación adicional. Para poder llevarlo a la practica dichas actividades, los bancos y las tasas de interés tienen un papel un importante.
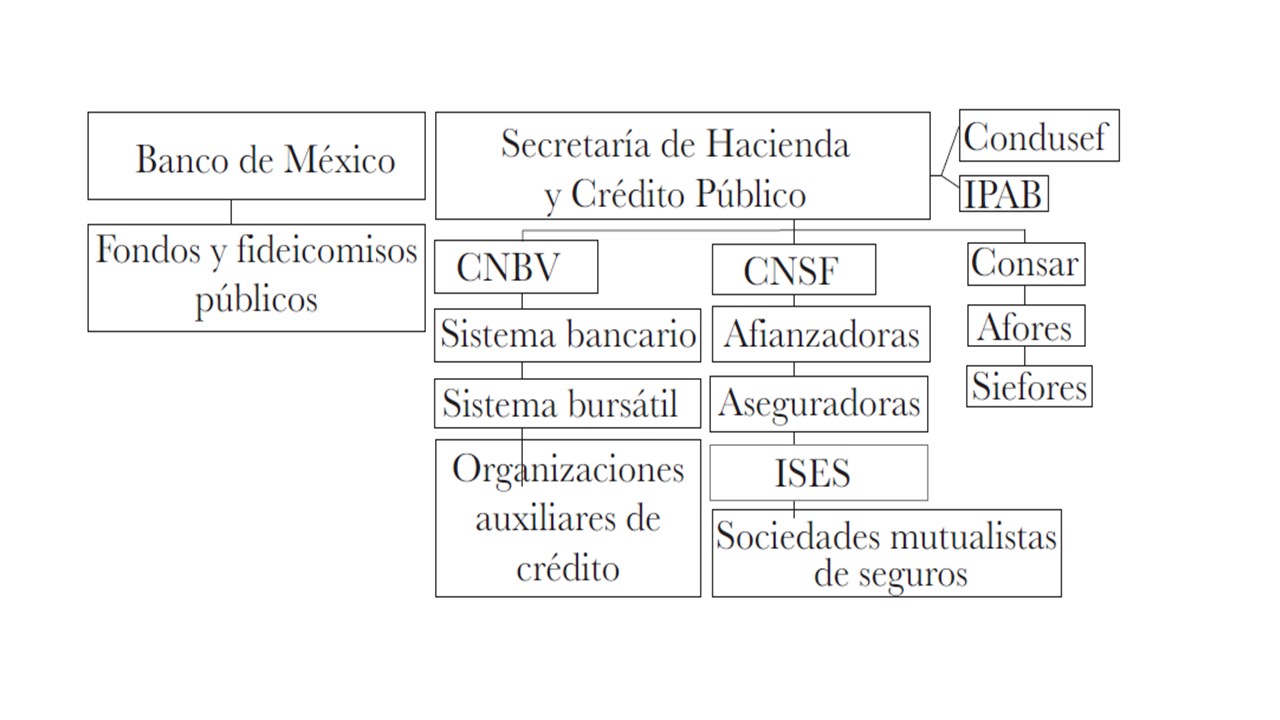
El sistema financiero mexicano esta conformado por Banco de México y la Secretaría de Haciendo y Crédito Publico.
Banco de México
La función del Banco de México es promover las condiciones para que se dé un sano desarrollo de las actividades económicas, que se accesible para los usuarios y que opere en un ambiente regulado, supervisado, así como competitivo.
Su función principal es procurar la estabilidad del poder adquisitivo del dinero (cuidar que el dinero no pierda su valor, capacidad de compra), con el que se realizan cualquier actividad económica. abasteciendo de papel moneda (billetes, monedas) al país, y propiciar un buen funcionamiento de los sistemas de pago; ésta ultima se logra a través de la ejecución de políticas monetarias y cambiarias. Es importante señalar que cualquier cambio que se realice a dichas políticas tienen su afectación directa en los precios que se pactan en los mercados financieros, como las tasas de interés, que para efectos prácticos se traducen en los costos que se pagan por adquirir créditos, rendimientos que se obtienen de inversiones, regular el cobro de comisiones por parte de los bancos, por mencionar algunos.
Secretaria de Hacienda y Crédito Público (SHCP)
Coordina la regulación y supervisión de las autoridades financieras, para asegurarse que el sistema financiero mexicano funcione de manera correcta; dichas autoridades son las siguientes:
- Comisión Nacional Bancaria y de Valores (CNBV): Supervisa a todos los bancos, que cumplan con la normativa vigente, además emite los permisos para poder abrir nuevos bancos y en caso de que no cumplan con los requisitos tiene la facultad de cerrarlos.
- Comisión Nacional de Seguros y Fianzas (CNSF): Se encarga de vigilar a las instituciones de seguros y fianzas, que tengan los recursos suficientes para poder hacer frente a sus obligaciones adquiridas respectivamente. Emite los permisos para poder abrir una compañía de seguros o para cerrar a todas las que no cumplen los requisitos para operar de acuerdo con la ley.
- Comisión Nacional para la Protección y Defensa de los Usuarios de Servicios Financieros: Autoridad que protege a los usuarios del sistema financiero mexicano, por ejemplo, en caso de existir alguna queja en contra de un banco, ellos te pueden asesorar para resolver dicha situación.
- Comisión Nacional del Sistema de Ahorro para el Retiro (CONSAR): tiene la función de vigilar a las Administradoras de Fondos para el Retiro (AFORES), que son instituciones encargadas de administrar los ahorros para el retiro de los trabajadores para que después de haber trabajado por muchos años, puedan garantizar un ingreso futuro a través de su pensión.
- Instituto para la Protección del Ahorro Bancario (IPAB): Se encarga de generar un seguro de cada uno de los depósitos bancarios, es decir; si al banco le pasa algo que quiebre y tenga que cerrar, y al dinero que tengas ahorrado no le pase nada, esta protegido (hasta cierta cantidad).
Intermediarios financieros
Son instituciones que actúan como puente entre quienes tienen dinero (ahorradores/inversores) y quienes lo necesitan (prestatarios/empresas), facilitando la realización de las actividades económicas.ofrecen servicios como depósitos, préstamos, seguros y gestión de inversiones, siendo esenciales para el desarrollo económico. Incluyen bancos, aseguradoras, casas de cambio, afores, casas de bolsa.
- Bancos: Empresas que son intermediarios entre las personas que quieren ahorrar su dinero y los clientes que quieren prestarlo.
- Aseguradoras: Se dedican a la emisión de pólizas de seguros mediante la cual, ofrecen cubrir gastos imprevistos como daños algún bien (seguro de auto) o la salud (seguro de gastos médicos), a cambio de una cantidad de dinero conocida como prima.
- Casas de cambio: Es el lugar donde se puede adquirir otras divisas (dinero de otro país) o cambio de moneda a pesos mexicanos. Por ejemplo si quieres salir de viaje y necesitas dolares, entonces acudes a una cas de cambio y puedes cambiar los pesos mexicanos en dolares.
- Afores: Como ya se menciono, son las instituciones encargadas de administrar los ahorros de los trabajadores para que en un futuro puedan vivir de ellos a través de una pensión
- Casa de Bolsa: Es la institución que se encarga de llevar a cabo la compra y venta de acciones, así como de otros instrumentos financieros. Es mediante este proceso que las personas pueden hacer inversiones mediante la compra de acciones lo que les da derecho a tener un porcentaje de las utilidades que genere la empresa.
La importancia que tiene abordar estos temas, radica en el hecho que porque el dinero nos conecta como sociedad ya que todos los días lo usamos para poder solventar nuestras necesidades; y saber como funciona el sistema financiero nos ayudara mucho para poder determinar estrategias sanas de consumo de productos, bienes, servicios, créditos, etc. Entender como funciona el dinero como medio de pago, de ahorro, permite conocer los puntos de mejora en las finanzas personales de cada individuo, así como identificar las fortalezas y oportunidades para un mejor manejo.
En el siguiente link se puede consultar el organigrama completo del sistema financiero mexicano: chrome-extension://efaidnbmnnnibpcajpcglclefindmkaj/https://www.gob.mx/cms/uploads/attachment/file/23187/Estructura_del_Sistema_Financiero_Mexicano_2015.pdf
*Obtenido de Marco Jurídico de las Finanzas, Quintana Adriano, Instituto de Investigaciones Jurídicas, UNAM, https://archivos.juridicas.unam.mx/www/bjv/libros/11/5140/16.pdf
Más adelante…
Se abordara el concepto de interés simple, su construcción del modelo matemático que lo describe, así como las variables que interviene y la forma en que se aplica.
Ir a Matemáticas Financieras
Ir a Interés Simple