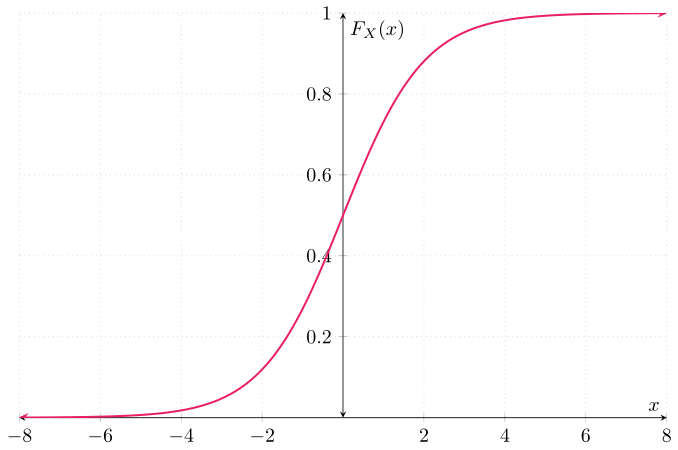Introducción
En la entrada pasada comenzamos a abordar el problema de encontrar la distribución de la transformación de una v.a. conocida. En particular, analizamos un método para el caso en el que la v.a. conocida es discreta, y sólamente para ese caso. No obstante, este método nos servirá como «base» para dar paso al caso continuo. Primero presentaremos un método que consiste en manipular directamente la función de distribución; muy parecido al método que vimos en la entrada pasada. Después, analizaremos un método más especializado que permite encontrar la función de densidad de la transformación de una v.a. sin necesidad de manipular la función de distribución.
Motivación del primer método
Sea $X$ una v.a. y $g\colon\RR\to\RR$ una función Borel-medible. En la entrada pasada ya describimos el proceso para obtener los eventos de $g(X)$ en términos de eventos que involucran a $X$. De hecho, vimos que para cada $A \in \mathscr{B}(\RR)$ se cumple que
\begin{align*} (g(X) \in A) = (X \in g^{-1}[A]). \end{align*}
¡Atención! En la entrada pasada centramos nuestra atención en las v.a.’s discretas, pero la igualdad anterior es cierta para cualquier variable aleatoria. Por ello, también aplica para las v.a.’s continuas. En particular, para cada $y \in \RR$ se cumple que $(-\infty, y] \in \mathscr{B}(\RR)$, por lo que
\begin{align*} {\left(g(X) \leq y\right)} = \left(g(X) \in (-\infty, y]\right) = {\left(X \in g^{-1}[(-\infty, y]]\right)}. \end{align*}
Por lo tanto, se tiene que
\begin{align*} \Prob{g(X) \leq y} = \Prob{X \in g^{-1}[(-\infty, y]]}. \end{align*}
Es decir, si definimos a $Y = g(X)$ y $F_{Y}\colon\RR\to\RR$ es la función de distribución de $Y$, entonces lo anterior quiere decir que para cada $y \in \RR$,
\begin{align*} F_{Y}(y) = \Prob{X \in g^{-1}[(-\infty, y]]}; \end{align*}
por lo que es posible obtener la distribución de $Y$ en términos de la probabilidad de un evento que involura a $X$, cuya distribución sí conocemos.
Primer método: manipular la función de distribución
Con la discusión anterior llegamos a que si $X$ es una v.a. (cuya distribución es conocida), $g\colon\RR\to\RR$ es una función Borel-medible, y $Y$ es la v.a. definida como $Y = g(X)$, entonces la función de distribución de $Y$, $F_{Y}\colon\RR\to\RR$, puede obtenerse como
\begin{align*} F_{Y}(y) &= \Prob{X \in g^{-1}[(-\infty, y]]} & \text{para cada $y \in \RR$.} \end{align*}
Por ello, el problema consistirá en encontrar el conjunto $g^{-1}[(-\infty, y]]$, y así encontrar la probabilidad de ${\left(X \in g^{-1}[(-\infty, y]]\right)}$.
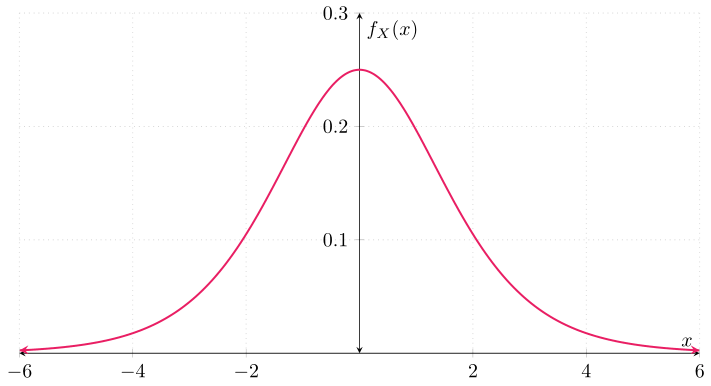
Ejemplo 1. Sea $X$ una v.a. con función de densidad $f_{X}\colon\RR\to\RR$ dada por
\begin{align*} f_{X}(x) &= \frac{1}{2}e^{-{\left| x \right|}}, & \text{para cada $x \in \RR$}. \end{align*}
Una v.a. con esta función de densidad es conocida como una v.a. con distribución Laplace, o distribución doble exponencial. Su función de distribución $F_{X}\colon\RR\to\RR$ está dada por
\begin{align*} F_{X}(x) &= \begin{cases} \dfrac{1}{2}e^{x} & \text{si $x < 0$}, \\[1em] 1 − \dfrac{1}{2} e^{-x} & \text{si $x \geq 0$}. \end{cases}\end{align*}
Sea $g\colon\RR\to\RR$ la función dada por $g(x) = |x|$ para cada $x \in \RR$. De este modo, defínase $Y = g(X) = {\left| X \right|}$. Para obtener la función de distribución $Y$, podemos seguir un método similar al que usamos en la entrada anterior. Sea $y \in \RR$. Un primer detalle que podemos observar sobre $Y$ es que no toma valores negativos. Por ello, si $y < 0$, se tiene que $(Y \leq y) = \emptyset$, y en consecuencia, $\Prob{Y \leq y} = 0$ para $y < 0$. Por otro lado, para $y \geq 0$ se tiene que que
\begin{align*} \omega \in (Y \leq y) &\iff Y(\omega) \leq y \\[1em] &\iff |X(\omega)| \leq y \\[1em] &\iff -y \leq X(\omega) \leq y \\[1em] &\iff \omega \in ( -y \leq X \leq y ), \end{align*}
por lo que para cada $y \geq 0$ se tiene que $(Y \leq y) = (-y \leq X \leq y)$. Como esos dos eventos son iguales, se sigue que $\Prob{Y \leq y} = \Prob{ -y \leq X \leq y}$. , por lo queAdemás, nota que
\begin{align*} \Prob{-y \leq X \leq y} &= \Prob{X \leq y} − \Prob{X < -y} \\[1em] &= \Prob{X \leq y} − \Prob{X \leq -y} \tag{$*$} \\[1em] &= F_{X}(y) − F_{X}(-y), \end{align*}
donde el paso $(*)$ es válido debido a que $X$ es una v.a. continua. Por ello, podemos concluir que para cada $y \geq 0$,
\begin{align*} F_{Y}(y) = F_{X}(y) − F_{X}(−y). \end{align*}
Por lo tanto, la función de distribución de $Y$ queda como sigue:
\begin{align*} F_{Y}(y) &= \begin{cases} 0 & \text{si $y < 0$}, \\[1em] F_{X}(y) − F_{X}(-y) & \text{si $y \geq 0$}. \end{cases} \end{align*}
De aquí podemos obtener una expresión explícita. Para cada $y \geq 0$ se tiene que $-y \leq 0$, así que
\begin{align*} F_{X}(y) − F_{X}(-y) &= {\left(1 − \frac{1}{2}e^{-y}\right)} − \frac{1}{2}e^{-y} \\[1em] &= 1 − \frac{1}{2}e^{-y} − \frac{1}{2}e^{-y} \\[1em] &= 1 − e^{-y}. \end{align*}
En conclusión, la función de distribución de $Y$ queda así:
\begin{align*} F_{Y}(y) &= \begin{cases} 0 & \text{si $y < 0$}, \\[1em] 1 − e^{-y} & \text{si $y \geq 0$}. \end{cases} \end{align*}
Probablemente te resulte familiar: ¡Es la función de distribución de una v.a. exponencial! Este ejemplo exhibe que algunas transformaciones de algunas v.a.’s «famosas» resultan en otras v.a.’s «famosas». En este caso, vimos que si $X$ es una v.a. que sigue una distribución Laplace, entonces $|X|$ sigue una distribución exponencial. Más adelante veremos muchas más distribuciones importantes, y veremos cómo se relacionan entre sí mediante transformaciones.
Segundo método: teorema de cambio de variable
Existe un método más especializado para obtener la función de densidad de la transformación de una v.a. continua. La razón por la que decimos que es más especializado es porque funciona para transformaciones que cumplen ciertas condiciones.
Teorema. Sea $X\colon\Omega\to\RR$ una v.a. continua con función de densidad $f_{X}\colon\RR\to\RR$, y sea $g\colon X[\Omega]\to\RR$ una función diferenciable y estrictamente creciente o decreciente. Entonces la función de densidad de $Y = g(X)$ está dada por
\begin{align*} f_{Y}(y) &= \begin{cases} f_{X}{\left( g^{-1}(y) \right)} {\left| \dfrac{\mathrm{d}}{\mathrm{d} y} {\left[ g^{-1}(y) \right]} \right|} & \text{si $y \in (g \circ X )[ \Omega ]$}, \\[1em] 0 & \text{en otro caso}, \end{cases} \end{align*}
donde $g^{-1}\colon g[\RR] \to\RR$ es la inversa de $g$, y $(g \circ X )[ \Omega ]$ es la imagen directa de $\Omega$ bajo $g \circ X$. Esto es, $(g \circ X) [ \Omega ] = \{\, y \in \RR \mid \exists \omega \in \Omega : (g \circ X )(\omega) = y \,\}$, que corresponde al conjunto de valores que toma la v.a. $Y = g(X)$.
Demostración. Demostraremos el caso en el que $g$ es estrictamente creciente. Para ello, sea $y \in \RR$. Primero, recuerda que
\begin{align*} (Y \leq y) &= (X \leq g^{-1}[(-\infty,y]]). \end{align*}
Por un lado, se tiene el caso en el que $y \in (g \circ X)[\Omega]$; es decir, $y$ es uno de los valores que toma la v.a. $Y$ (pues $(g \circ X)[\Omega] = Y[\Omega]$). En este caso, el valor $g^{-1}(y)$ está bien definido, ya que $g^{-1}\colon (g \circ X)[\Omega]\to\RR$ es una función cuyo dominio es la imagen de $g$. De este modo, para cada $\omega\in\Omega$ tendremos que
\begin{align*} Y(\omega) \leq y &\iff X(\omega) \leq g^{-1}(y). \tag{$*$} \end{align*}
Como $g$ es una función estrictamente creciente, su inversa $g^{-1}\colon (g \circ X)[\Omega]\to\RR$ también es estrictamente creciente, y por lo tanto, la desigualdad en $(*)$ «no se voltea».
De lo anterior se sigue que $\Prob{Y \leq y} = \Prob{X \leq g^{-1}(y)}$ para cada $y \in (g \circ X)[\Omega]$. En consecuencia, se tiene que
\begin{align*} F_{Y}(y) = F_{X}(g^{-1}(y)). \end{align*}
Podemos diferenciar ambos lados de la igualdad respecto a $y$, y por la regla de la cadena obtenemos
\begin{align*} f_{Y}(y) &= f_{X}{\left( g^{-1}(y) \right)} \frac{\mathrm{d}}{\mathrm{d} y} {\left[ g^{-1}(y) \right]} \\[1em] &= f_{X}{\left( g^{-1}(y) \right)} {\left| \frac{\mathrm{d}}{\mathrm{d} y} {\left[ g^{-1}(y) \right]} \right|}, \end{align*}
donde el último paso se obtiene de que $g^{-1}$ es estrictamente creciente, y por lo tanto, su derivada es positiva.
Por otro lado, resta el caso en el que $y \notin (g \circ X)[\Omega]$; es decir, cuando $y$ no es uno de los valores que puede tomar $Y$. En este caso, simplemente $f_{Y}$ vale $0$, pues la densidad de una v.a. continua es $0$ en aquellos valores que no toma. De este modo, $Y$ tiene densidad $f_{Y}\colon\RR\to\RR$ dada por
\begin{align*} f_{Y}(y) &= \begin{cases} f_{X}{\left( g^{-1}(y) \right)} {\left| \dfrac{\mathrm{d}}{\mathrm{d} y} {\left[ g^{-1}(y) \right]} \right|} & \text{si $y \in (g \circ X )[ \Omega ]$}, \\[1em] 0 & \text{en otro caso}, \end{cases} \end{align*}
que es justamente lo que queríamos demostrar.
El caso para $g$ estrictamente decreciente es casi análogo, por lo que te lo dejamos de tarea moral.
$\square$
Es importante notar que el teorema anterior no funciona para cualquier $g\colon\RR\to\RR$ Borel-medible, sólamente para aquellas que cumplen las hipótesis del teorema. Bajo estas hipótesis, el teorema permite obtener la densidad de la transformación de una v.a. de manera más eficiente que los otros métodos que hemos abordado.
Ejemplo 2. Sea $Z$ una v.a. con densidad $f_{Z}\colon\RR\to\RR$ dada por
\begin{align*} f_{Z}(z) &= \frac{1}{\sqrt{2\pi}} e^{-z^{2} / 2}, & \text{para cada $z \in \RR$}.\end{align*}
Se dice que una v.a. con esa función de densidad sigue una distribución normal estándar. Observa que $f_{Z}(z) > 0$ para todo $z \in \RR$, por lo que $Z[\Omega] = \RR$. Es decir, $Z$ puede tomar cualquier valor en $\RR$.
Sea $W = e^{Z}$. La función $\exp\colon\RR\to\RR^{+}$ dada por $\exp(x) = e^{x}$ es estrictamente creciente y diferenciable, por lo que podemos usar el teorema anterior para obtener la función de densidad de $W$. Así, tenemos que
\begin{align*} f_{W}(w) = f_{Z}{ \left(\exp^{-1}(w) \right)} {\left| \frac{\mathrm{d}}{\mathrm{d} w} {\left[ \exp^{-1}(w) \right]} \right|}, \end{align*}
donde $\exp^{-1}\colon\RR^{+}\to\RR$ es la inversa de la función exponencial $\exp$. De hecho, la inversa de $\exp$ es la función $\ln\colon\RR^{+}\to\RR$, el logaritmo natural. Ahora, como $Z[\Omega] = \RR$, se tiene que $(\exp{} \circ Z)[\Omega] = \RR^{+}$, pues la función $\exp{}$ toma únicamente valores positivos.
En consecuencia, para $w \in \RR^{+}$ se tiene
\begin{align*} f_{W}(w) &= f_{Z}{ \left(\ln(w) \right)} {\left| \frac{\mathrm{d}}{\mathrm{d} w} {\left[ \ln(w) \right]} \right|} \\[1em] &= f_{Z}{ \left(\ln(w) \right)} {\left| \frac{1}{w} \right|} \\[1em] &= \frac{1}{w \sqrt{2\pi}} \mathrm{exp} { \left( − \frac{(\ln(w))^{2}}{2}\right) }\end{align*}
y así, tenemos que $W$ tiene densidad $f_{W}\colon\RR\to\RR$ dada por
\begin{align*} f_{W}(w) &= \begin{cases} \dfrac{1}{w \sqrt{2\pi}} \mathrm{exp} { \left( − \dfrac{(\ln(w))^{2}}{2}\right) } & \text{si $w > 0$}, \\[1em] 0 & \text{en otro caso}. \end{cases} \end{align*}
Como nota adicional, $f_{W}$ es la densidad de una v.a. cuya distribución es conocida como log-normal.
Para concluir, es importante mencionar que la transformación $g$ del teorema sólamente necesita ser diferenciable y estrictamente creciente sobre $X[\Omega]$ (por eso es que en el enunciado la pusimos como $g\colon X[\Omega] \to \RR$). Por ejemplo, la función $g\colon\RR^{+}\cup\{0\}\to\RR$ dada por $g(x) = x^{2}$ es una función creciente sobre su dominio. Por ello, si $X$ es una v.a. continua que toma únicamente valores no-negativos, entonces puede aplicarse el teorema para obtener la densidad de $g(X)$. En resumidas cuentas, el teorema puede aplicarse siempre y cuando la transformación $g$ sea diferenciable y estrictamente creciente sobre el conjunto de valores que puede tomar $X$.
Tarea moral
Los siguientes ejercicios son opcionales. Es decir, no formarán parte de tu calificación. Sin embargo, te recomiendo resolverlos para que desarrolles tu dominio de los conceptos abordados en esta entrada.
- Verifica que la función de distribución de la v.a. $X$ del Ejemplo 1 es la función que te dimos. Es decir, obtén la función de distribución de $X$ a partir de su función de densidad.
- Demuestra el caso en el que $g$ es estrictamente decreciente del teorema de cambio de variable.
- Retoma el segundo Ejemplo 2, pero esta vez comienza con la v.a. $W$, cuya función de densidad es \begin{align*} f_{W}(w) &= \begin{cases} \dfrac{1}{w \sqrt{2\pi}} \mathrm{exp} { \left( − \dfrac{(\ln(w))^{2}}{2}\right) } & \text{si $w > 0$}, \\[1em] 0 & \text{en otro caso}, \end{cases} \end{align*}y encuentra la función de densidad de $Z = \ln(W)$ usando el teorema.
Más adelante…
El teorema de esta entrada es muy útil para obtener la densidad (y, en consecuencia, la distribución) de muchas transformaciones de v.a.’s continuas. Por ello, nos será de utilidad en el futuro relativamente cercano, cuando veamos las distribuciones de probabilidad más conocidas. Por otro lado, te será de utilidad mucho más adelante en materias posteriores, pues este teorema puede generalizarse al caso en el que la transformación tiene como dominio a $\RR^{n}$ y como codominio a $\RR$ con $n \in \mathbb{N}^{+}$ y $n \geq 2$ (por ejemplo, $g\colon\RR^{2}\to\RR$ dada por $g(x, y) = x + y$).
En la siguiente entrada comenzaremos el estudio de un concepto asociado a las v.a.’s llamado el valor esperado de una variable aleatoria.
Entradas relacionadas
- Ir a Probabilidad I
- Entrada anterior del curso: Transformaciones de Variables Aleatorias
- Siguiente entrada del curso: Valor Esperado de una Variable Aleatoria