
Introducción
Una vez que hemos introducido el concepto de variable aleatoria, nos toca ver qué nuevas definiciones surgen a partir de este. Un primer concepto que surge es la función de distribución. A grandes rasgos, dado un espacio de probabilidad $(\Omega, \mathscr{F}, \mathbb{P})$, en la entrada anterior vimos que una función $X\colon\Omega\to\RR$ debe de satisfacer que para cualquier $x \in \RR$, $X^{-1}[(-\infty, x]]$ es un evento de $\Omega$. Básicamente, esta condición era suficiente para concluir que para cada $B \in \mathscr{B}(\RR)$ se cumple que $X^{-1}[B] \in \mathscr{F}$. En otras palabras, la imagen inversa de cualquier evento de $\RR$ es un evento de $\Omega$.
De manera similar, lo que haremos será definir la probabilidad de los eventos de la forma $(X \leq x)$, con $x \in \RR$. No lo veremos aquí (porque no tenemos las herramientas suficientes para hacerlo), pero resulta que asignarle probabilidad a esos eventos captura toda la información relevante sobre una variable aleatoria. Esto nos permitirá prescindir por completo de muchos detalles de la variable aleatoria, y centrar nuestra atención en el conjunto de valores que puede tomar.
Funciones de distribución de probabilidad
De manera general, existe un tipo de función que nos va a interesar a partir de ahora, que corresponde a las funciones de distribución de probabilidad. Estas se definen como sigue.
Definición. Sea $F\colon\RR\to\RR$ una función. Diremos que $F$ es una función de distribución de probabilidad si:
- $F$ es no-decreciente. Esto es, para cada $a, b \in \RR$, si $a < b$ entonces $F(a) \leq F(b)$.
- $F$ es continua por la derecha. Es decir, para cada $a \in \RR$ se cumple que\[ \lim_{x\to a^{+}} F(x) = F(a). \]
- Se cumple que\[ \lim_{x\to\infty} F(x) = 1 \quad\text{y}\quad \lim_{x\to -\infty} F(x) = 0. \]
Una función no requiere de ningún contexto adicional para considerarse una función de distribución de probabilidad. Es decir, para que una función $F\colon\RR\to\RR$ sea considerada una función de distribución de probabilidad, simplemente debe de ser no-decreciente, continua por la derecha y sus límites a $\infty$ y $-\infty$ deben de ser $1$ y $0$, respectivamente.
Ejemplo 1. Sean $a, b \in \RR$ tales que $a < b$. La función $F\colon\RR\to\RR$ dada por
\[ F(x) = \begin{cases} 0 & \text{si $x < a$,} \\[1em] \cfrac{x − a}{b − a} & \text{si $a \leq x \leq b$,} \\[1em] 1 & \text{si $b < x$.} \end{cases} \]
es no-decreciente, continua por la derecha y sus límites a $\infty$ y $-\infty$ son $1$ y $0$, así que es una función de distribución de probabilidad. Gráficamente, se ve como sigue.
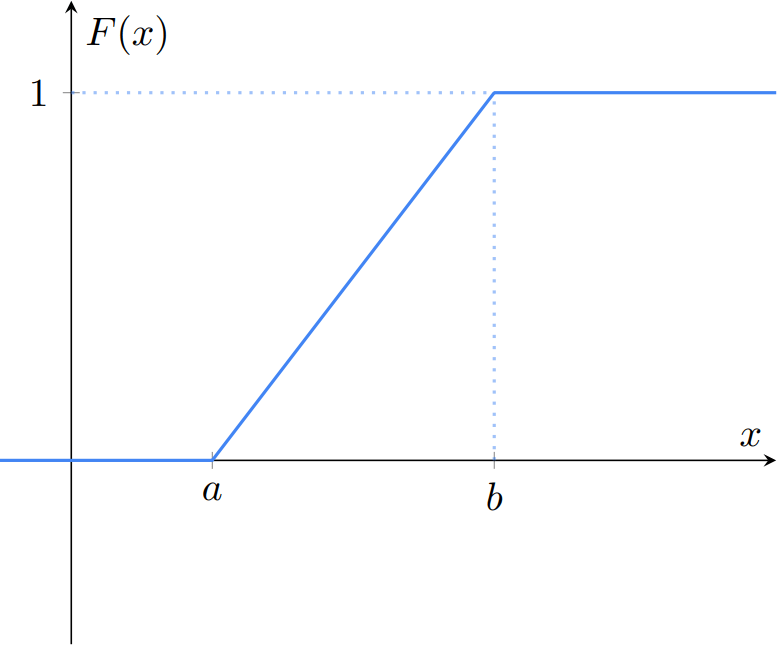
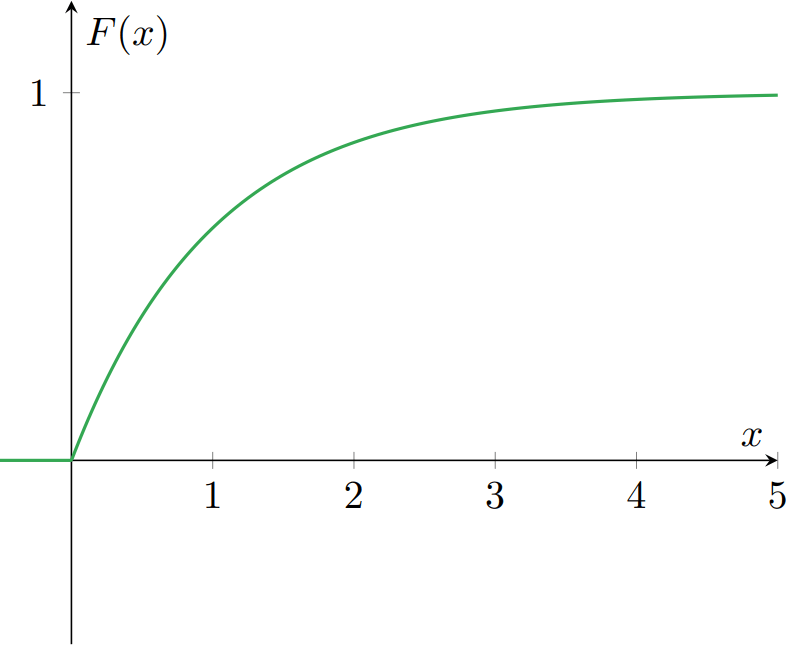
Ejemplo 2. Sea $\lambda \in \RR$ tal que $\lambda > 0$. La función $F\colon\RR\to\RR$ dada por
\[ F(x) = \begin{cases} 0 & \text{si $x < 0$,} \\[1em] 1 − e^{-\lambda x} & \text{si $x \geq 0$.} \end{cases} \]
es una función de distribución de probabilidad. Gráficamente:
Función de distribución de una variable aleatoria
Dada cualquier variable aleatoria $X$ sobre un espacio de probabilidad $(\Omega, \mathscr{F}, \mathbb{P})$, hay una función muy importante asociada a $X$: su función de distribución, definida como sigue.
Definición. Sea $(\Omega, \mathscr{F}, \mathbb{P})$ un espacio de probabilidad y sea $X\colon\Omega\to\RR$ una variable aleatoria. La función de distribución de $X$ es la función $F_{X}\colon\RR\to[0,1]$ dada por
\[ F_{X}(x) = \Prob{\{\, \omega\in\Omega \mid X(\omega) \leq x \,\}} = \Prob{X \leq x}, \quad \text{para cada $x \in \RR$}. \]
$F_{X}$ también es llamada la función de distribución acumulada de $X$, que en inglés se abrevia como CDF (cumulative distribution function).
Es decir, dada una variable aleatoria $X$, su función de distribución devuelve la probabilidad de que $X$ sea menor o igual a $x$, para cada $x \in\RR$. Como seguramente ya sospechas por el nombre de $F_{X}$, resulta que $F_{X}$ es una función de distribución de probabilidad. Este hecho es demostrado en el siguiente teorema.
Teorema. Sea $(\Omega, \mathscr{F}, \mathbb{P})$ un espacio de probabilidad y sea $X\colon\Omega\to\RR$ una variable aleatoria. Entonces $F_{X}\colon\RR\to[0,1]$ es una función de distribución de probabilidad.
Demostración. De acuerdo con la definición, para demostrar que $F_{X}\colon\RR\to\RR$ es una función de distribución de probabilidad, tenemos que demostrar 3 cosas:
- $F_{X}$ es no-decreciente: para cada $a, b \in \RR$, si $a < b$ entonces $F_{X}(a) \leq F_{X}(b)$.
- $F_{X}$ es continua por la derecha: que para cada $a \in \RR$ se cumple que\[ \lim_{x\to a^{+}} F_X(x) = F_{X}(a). \]
- Se cumple que\[ \lim_{x\to\infty} F_{X}(x) = 1 \quad\text{y}\quad \lim_{x\to -\infty} F_{X}(x) = 0. \]
Veamos que se cumple 1. Sean $a, b \in \RR$ tales que $a < b$. Ahora, observa que $(a, b] = (-\infty, b] \smallsetminus (-\infty, a]$, por lo que
\begin{align*} \Prob{X^{-1}[(a, b]]} &= \Prob{X^{-1}[(-\infty, b] \smallsetminus (-\infty, a]]} \\[0.5em] &= \Prob{X^{-1}[(-\infty, b]] \smallsetminus X^{-1}[(-\infty, a]]}. \end{align*}
Como $a < b$, se cumple que $(-\infty, a] \subseteq (-\infty, b]$, por lo que
\[ X^{-1}[(-\infty, a]] \subseteq X^{-1}[(-\infty, b]], \]
así que $\Prob{X^{-1}[(-\infty, b]] \smallsetminus X^{-1}[(-\infty, a]]} = \Prob{X^{-1}[(-\infty, b]]} − \Prob{X^{-1}[(-\infty, a]]}$. En consecuencia, tenemos que
\begin{align*} \Prob{X^{-1}[(a, b]]} &= \Prob{X^{-1}[(-\infty, b]]} − \Prob{X^{-1}[(-\infty, a]]} \\[0.5em] &= \Prob{X \leq b} − \Prob{X \leq a} \\[0.5em] &= F_{X}(b) − F_{X}(a). \end{align*}
Recuerda que $\mathbb{P}$ es una medida de probabilidad, por lo que $\Prob{X^{-1}[(a, b]]} \geq 0$; que implica $F_{X}(b) − F_{X}(a) \geq 0$, o equivalentemente, que $F_{X}(b) \geq F_{X}(a)$. En conclusión, para cualesquiera $a, b \in \RR$ tales que $a < b$, se cumple que $F_{X}(a) \leq F_{X}(b)$, que es justamente lo que queríamos demostrar. Por lo tanto, $F_{X}$ es una función no-decreciente.
Para demostrar 2, sea $(x_{n})_{n\in\mathbb{N}^{+}} \subseteq \RR$ una sucesión monótona decreciente de números reales tal que su límite es $0$. Es decir, $x_{1} > x_{2} > x_{3} > \cdots$ y
\[ \lim_{n\to\infty} x_{n} = 0. \]
Ahora, sea $a \in \RR$. Definimos la sucesión de eventos $\{ A_{n} \}_{n\in\mathbb{N}^{+}}$ tal que para cada $n \in \mathbb{N}^{+}$, $A_{n} = ( X \leq a + x_{n} )$. De este modo, se tiene que
\[ \bigcap_{n=1}^{\infty} A_{n} = (X \leq a), \]
pues la sucesión $(x_{n})_{n\in\mathbb{N}^{+}}$ converge a $0$. Ahora, por el teorema de continuidad de la probabilidad, tenemos que
\[ F_{X}(a) = \Prob{X \leq a} = \Prob{\bigcap_{n=1}^{\infty} A_{n}} = \lim_{n\to\infty} \Prob{A_{n}} = \lim_{n\to\infty} \Prob{X \leq a + x_{n}} = \lim_{n\to\infty} F_{X}(a + x_{n}), \]
es decir, $\lim_{n\to\infty} F_{X}(a + x_{n}) = F_{X}(a)$, para cualquier $a \in \RR$ y cualquier sucesión monótona decreciente $(x_{n})_{n\in\mathbb{N}^{+}}$. Por ello, se puede concluir que $F_{X}$ es una función continua por la derecha.
Finalmente, en 3 demostraremos que el límite de $F_{X}(x)$ cuando $x\to\infty$ es $1$. La demostración del otro límite es muy parecida. Sea $(x_{n})_{n\in\mathbb{N}^{+}} \subseteq \RR$ una sucesión de números reales tal que $x_{1} \leq x_{2} \leq x_{3} \leq \cdots$ y $\lim_{n\to\infty} x_{n} = \infty$. Para cada $n \in \mathbb{N}^{+}$ definimos
\[ A_{n} = (X \leq x_{n}) = X^{-1}[(-\infty, x_{n}]]. \]
De esta forma, tenemos que $\{ A_{n} \}_{n\in\mathbb{N}^{+}}$ es una sucesión creciente de eventos, pues observa que $A_{1} \subseteq A_{2} \subseteq A_{3} \subseteq \cdots$ De este modo, como supusimos que $(x_{n})_{n\in\mathbb{N}^{+}}$ es una sucesión que diverge a $\infty$, se tiene que
\[ \bigcup_{n=1}^{\infty} A_{n} = \bigcup_{n=1}^{\infty}(X \leq x_{n}) = \bigcup_{n=1}^{\infty}X^{-1}[(-\infty, x_{n}]] = X^{-1}{\left[ \bigcup_{n=1}^{\infty} (-\infty, x_{n}] \right]} = X^{-1}[\RR] = \Omega. \]
Ahora, aplicando el teorema de la continuidad de la probabilidad a $\{ A_{n}\}_{n\in\mathbb{N}^{+}}$ y usando que la sucesión $(x_{n})_{n\in\mathbb{N}^{+}}$ es divergente, tenemos que
\begin{align*} \lim_{x\to\infty} F_{X}(x) &= \lim_{n\to\infty} F_{X}(x_{n}) \\ &= \lim_{n\to\infty}\Prob{X \leq x_{n}} \\ &= \lim_{n\to\infty}\Prob{A_{n}} \\ &= \Prob{\bigcup_{n=1}^{\infty} A_{n}} \\ &= \Prob{\Omega} \\ &= 1. \end{align*}
En conclusión, tenemos que
\[ \lim_{x\to\infty} F_{X}(x) = 1, \]
que es justamente lo que queríamos demostrar. La demostración de que el límite a $-\infty$ de $F_{X}$ es $0$ se obtiene de manera casi análoga, pero la familia de eventos que se plantea es decreciente, y se utiliza el teorema de continuidad de la probabilidad para ese caso.
$\square$
Partiendo de una función de distribución de probabilidad
Por el teorema anterior, vimos que la función de distribución de cualquier variable aleatoria es también una función de distribución de probabilidad. Es decir, que si tienes un espacio de probabilidad $(\Omega, \mathscr{F}, \mathbb{P})$ y una variable aleatoria $X\colon\Omega\to\RR$, la función de distribución de $X$, $F_{X}\colon\RR\to[0,1]$, es una función de distribución de probabilidad.
Por otro lado, ahora imagina que te encuentras con una función $F\colon\RR\to\RR$ que es una función de distribución de probabilidad. No obstante, observa que no sabes nada más sobre esta función. Es decir, no hay ninguna variable aleatoria ni un espacio de probabilidad a la vista… ¿Será posible que $F$ provenga de alguna variable aleatoria $X$ definida sobre un espacio de probabilidad $(\Omega, \mathscr{F}, \mathbb{P})$?
En otras palabras: dada $F\colon\RR\to\RR$ una función de distribución de probabilidad, ¿siempre existen un espacio de probabilidad $(\Omega, \mathscr{F}, \mathbb{P})$ y una variable aleatoria $X\colon\Omega\to\RR$ tal que $F$ es la función de distribución de $X$? ¡La respuesta es que sí! A grandes rasgos, $F$ define la probabilidad de los eventos de la forma $(-\infty, x]$, para cada $x \in \RR$. Esto resulta suficiente para definir por completo la medida de probabilidad inducida por una variable aleatoria $X$… pero, ¿cuál variable aleatoria $X$? De manera canónica, siempre puede utilizarse la variable aleatoria identidad sobre $\Omega = \RR$, que es la función $X\colon\RR\to\RR$ tal que para cada $\omega\in\RR$, $X(\omega) = \omega$. De este modo, la medida de probabilidad inducida por $X$ es la misma que la medida en el dominio de $X$, que en este caso es $\RR$ con $\mathscr{B}(\RR)$ como σ-álgebra, y usando la medida determinada por $F$.
¡CUIDADO! Esto NO significa que todas las variables aleatorias son simplemente la función identidad. Lo que significa es que siempre que tengas una función de distribución de probabilidad $F\colon\RR\to\RR$, está garantizado que existen un espacio de probabilidad $(\Omega, \mathscr{F}, \mathbb{P})$ y una variable aleatoria $X\colon\Omega\to\RR$ de tal forma que $F$ es la función de distribución de $X$. La existencia está garantizada porque, al menos, siempre se puede usar la función identidad de $\RR$ en $\RR$ como variable aleatoria, pero puede haber otras distintas cuya función de distribución también es $F$.
Los siguientes ejemplos son largos, pero capturan muchas de las ideas vistas hasta ahora sobre variables aleatorias. Además, en conjunto, estos dos ejemplos exhiben lo que comentamos en el párrafo anterior.
Ejemplo 3. Sea $\Omega = \{ 0, 1\}^{3}$. Es decir, $\Omega$ es el conjunto
\[ \Omega = \{ (0,0,0), (0,0,1), (0,1,0), (1,0,0), (0,1,1), (1,0,1), (1,1,0), (1,1,1) \}. \]
$\Omega$ puede pensarse como el espacio muestral de un experimento aleatorio en el que se hacen $3$ ensayos de un experimento aleatorio que tiene dos resultados posibles: éxito o fracaso. Por ejemplo, el lanzamiento de una moneda («águila» o «sol»). Tomaremos como σ-algebra de $\Omega$ a $\mathscr{P}(\Omega)$, la potencia de $\Omega$.
Sea $p \in \RR$ tal que $p \in [0,1]$. Plantearemos una medida de probabilidad tal que los $3$ ensayos son independientes. Para ello, para cada $k \in \{1,2,3\}$ planteamos los eventos
- $A_{k}$: el evento de que el $k$-ésimo ensayo sea un éxito. Es decir, $A_{k}$ es el evento\[ A_{k} = \{\, (\omega_{1}, \omega_{2}, \omega_{3}) \in \Omega \mid \omega_{k} = 1 \,\}. \]
- $B_{k}$: el evento de que el $k$-ésimo ensayo sea un fracaso. Es decir, $B_{k}$ es el evento\[ B_{k} = \{\, (\omega_{1}, \omega_{2}, \omega_{3}) \in \Omega \mid \omega_{k} = 0 \,\}. \]
Observa que para cada $k \in \{1,2,3\}$ se cumple que $B_{k} = A_{k}^{\mathsf{c}}$. Por ejemplo, $A_{2}$ es el evento
\[ A_{2} = \{\, (\omega_{1}, \omega_{2}, \omega_{3}) \in \Omega \mid \omega_{2} = 1 \,\} = \{ (0,1,0), (0,1,1), (1,1,0), (1,1,1) \} \]
Comenzamos a definir la medida de probabilidad $\mathbb{P}\colon\mathscr{P}(\Omega)\to\RR$ como sigue: para cada $k \in \{1,2,3\}$ definimos
\[ \Prob{A_{k}} = p, \]
\[ \Prob{B_{k}} = 1 − p, \]
y pedimos que $\mathbb{P}$ sea tal que los eventos $A_{1}$, $A_{2}$ y $A_{3}$ son independientes. En consecuencia, se cumple lo siguiente
\begin{align} \Prob{A_{1} \cap A_{2} \cap A_{3}} &= \Prob{A_{1}}\Prob{A_{2}}\Prob{A_{3}} = p^{3} \\[1em] \Prob{B_{1} \cap A_{2} \cap A_{3}} &= \Prob{B_{1}}\Prob{A_{2}}\Prob{A_{3}} = (1 − p)p^{2} = p^{2}(1 − p) \\[1em] \Prob{A_{1} \cap B_{2} \cap A_{3}} &= \Prob{A_{1}}\Prob{B_{2}}\Prob{A_{3}} = p(1 − p)p = p^{2}(1 − p) \\[1em] \Prob{A_{1} \cap A_{2} \cap B_{3}} &= \Prob{A_{1}}\Prob{A_{2}}\Prob{B_{3}} = p^{2}(1 − p), \\[1em] \Prob{B_{1} \cap B_{2} \cap A_{3}} &= \Prob{B_{1}}\Prob{B_{2}}\Prob{A_{3}} = (1 − p)^{2}p = p(1 − p)^{2}, \\[1em] \Prob{B_{1} \cap A_{2} \cap B_{3}} &= \Prob{B_{1}}\Prob{A_{2}}\Prob{B_{3}} = (1− p)p(1− p) = p(1 − p)^{2}, \\[1em] \Prob{A_{1} \cap B_{2} \cap B_{3}} &= \Prob{A_{1}}\Prob{B_{2}}\Prob{B_{3}} = p(1 − p)^{2}, \\[1em] \Prob{B_{1} \cap B_{2} \cap B_{3}} &= \Prob{B_{1}}\Prob{B_{2}}\Prob{B_{3}} = (1 − p)^{3}. \\[1em] \end{align}
De hecho, observa que estas condiciones son suficientes para definir la probabilidad de cada resultado, y así, la de cada evento $A \in \mathscr{P}(\Omega)$. Por ejemplo, nota que
\[ A_{1} \cap A_{2} \cap A_{3} = \{ \, (\omega_{1}, \omega_{2}, \omega_{3}) \in \Omega \mid \omega_{1} = 1 \land \omega_{2} = 1 \land \omega_{3} = 1 \, \} = \{ (1,1,1) \}, \]
y por lo anterior, $\Prob{A_{1} \cap A_{2} \cap A_{3}} = p^{3}$. Por lo tanto, se concluye que
\[ \Prob{\{(1,1,1)\}} = p^{3}. \]
Los $8$ elementos de $\Omega$ pueden verse como las intersecciones de las identidades $(1)$ a $(8)$, así que la probabilidad de cada uno está determinada por cada una de esas igualdades. Por ejemplo, además de la anterior ($\Prob{\{(1,1,1)\}} = p^{3}$), observa que
\[ A_{1} \cap B_{2} \cap B_{3} = \{ \, (\omega_{1}, \omega_{2}, \omega_{3}) \in \Omega \mid \omega_{1} = 1 \land \omega_{2} = 0 \land \omega_{3} = 0 \, \} = \{ (1,0,0) \}, \]
por lo que $\Prob{\{(1,0,0)\}} = p(1−p)^{2}$. Ahora, presta atención a los exponentes de $p$ y de $1−p$ en estas probabilidades, y compáralos con el número de $1$’s y $0$’s de las ternas ordenadas. ¿Qué puedes observar? Resulta que el exponente de la $p$ es el número de $1$’s, es decir, el número de éxitos. Por otro lado, el exponente del $1−p$ es el número de $0$’s, es decir, el número de fracasos.
Ahora, para cada $\mathbf{a} \in \Omega$, $\mathbf{a}$ puede escribirse como $\mathbf{a} = (a_{1}, a_{2}, a_{3})$, con $a_{1}$, $a_{2}$, $a_{3} \in \{0,1\}$. En consecuencia, el número de éxitos en la terna $\mathbf{a}$ puede escribirse como
\[ {\lVert \mathbf{a} \rVert}_{1} = {\left\lVert (a_{1}, a_{2}, a_{3}) \right\rVert}_{1} = |a_{1}| + |a_{2}| + |a_{3}|. \]
Por el contrario, el número de fracasos en la terna $\mathbf{a}$ puede escribirse como
\[ 3 − {\lVert \mathbf{a} \rVert}_{1} = 3 − {\left\lVert (a_{1}, a_{2}, a_{3}) \right\rVert}_{1} = 3 − (|a_{1}| + |a_{2}| + |a_{3}|). \]
De este modo, para cada $\mathbf{a} \in \Omega$, se tiene que
\[ \Prob{\{\mathbf{a}\}} = p^{{\lVert \mathbf{a} \rVert}_{1}} (1−p)^{3 − {\lVert \mathbf{a}\rVert}_{1}}. \]
Por esta razón, definimos a la medida de probabilidad $\mathbb{P}\colon\mathscr{P}(\Omega) \to \RR$ dada por
\[ \Prob{A} = \sum_{\mathbf{a}\in A} p^{{\lVert \mathbf{a} \rVert}_{1}} (1−p)^{3 − {\lVert \mathbf{a}\rVert}_{1}}, \quad \text{para cada $A \in \mathscr{P}(\Omega)$.}\]
Ahora, definimos a la variable aleatoria $X\colon\Omega\to\RR$ como sigue. Para cada $\mathbf{a}\in\Omega$, se define
\[ X(\mathbf{a}) = \lVert \mathbf{a} \rVert_{1}, \]
por lo que si $\mathbf{a} = (a_{1}, a_{2}, a_{3})$, se tiene que
\[ X(\mathbf{a}) = |a_{1}| + |a_{2}| + |a_{3}|. \]
Por ejemplo, $X(1,0,1) = 1 + 0 + 1 = 2$, y $X(1,1,1) = 1+1+1 = 3$. Es decir, $X$ contabiliza el número de éxitos en los $3$ ensayos. Observa que el conjunto de valores que puede tomar $X$ es $\{ 0, 1, 2, 3 \}$. Obtengamos la probabilidad de que $X$ tome cada uno de estos valores.
\begin{align*} \Prob{X = 0} = \Prob{\{\, \omega \in \Omega \mid X(\omega) = 0 \,\}} &= \Prob{\{ (0,0,0) \}} \\[0.5em] &= (1−p)^{3}, \\[1.5em] \Prob{X = 1} = \Prob{\{\, \omega \in \Omega \mid X(\omega) = 1 \,\}} &= \Prob{\{ (1,0,0), (0,1,0), (0,0,1) \}} \\[0.5em] &= p(1−p)^{2} + p(1−p)^{2} + p(1−p)^{2} \\[0.5em] &= 3p(1−p)^{2}, \\[1.5em] \Prob{X = 2} = \Prob{\{\, \omega \in \Omega \mid X(\omega) = 2 \,\}} &= \Prob{\{ (1,1,0), (1,0,1), (0,1,1) \}} \\[0.5em] &= p^{2}(1−p) + p^{2}(1−p) + p^{2}(1−p) \\[0.5em] &= 3p^{2}(1−p), \\[1.5em] \Prob{X = 3} = \Prob{\{\, \omega \in \Omega \mid X(\omega) = 3 \,\}} &= \Prob{\{ (1,1,1) \}} \\[0.5em] &= p^{3}. \end{align*}
Ahora obtengamos la función de distribución de $X$. Esto es,
\[ F_{X}(x) = \Prob{X \leq x}. \]
Primero, observa que para cada $x \in (-\infty, 0)$ se tiene que $F_{X}(x) = 0$, pues la variable aleatoria no toma valores negativos. Después,
\[ F_{X}(0) = \Prob{X \leq 0} = \Prob{\{\, \omega \in \Omega \mid X(\omega) \leq 0 \,\}} = \Prob{\{ (0,0,0) \}} = (1−p)^{3}. \]
Por otro lado, para cada $x \in (0,1)$, observa que
\[ F_{X}(x) = \Prob{X \leq x} = \Prob{\{\, \omega \in \Omega \mid X(\omega) \leq x \,\}} = \Prob{\{ (0,0,0) \}}. \]
porque el único $\omega \in \Omega$ que hace que $X(\omega) \leq x$ es $\omega = (0,0,0)$, para todos los demás, $X(\omega)$ vale al menos $1$, que es mayor a $x$. Luego, tenemos que
\begin{align*} F_{X}(1) = \Prob{X \leq 1} &= \Prob{\{\, \omega \in \Omega \mid X(\omega) \leq 1 \,\}} \\[0.5em] &= \Prob{\{ (0,0,0), (0,0,1), (0,1,0), (1,0,0) \}} \\[0.5em] &= (1−p)^{3} + 3p(1−p)^{2}, \end{align*}
Observa que ahí se acumularon los elementos de $\Omega$ que hacen que $X(\omega) = 0$ y $X(\omega) = 1$, pues son todos los valores que toma la variable aleatoria que son menores o iguales a $1$.
Después, para cada $x\in(1,2)$, los $\omega\in\Omega$ que hacen que $X(\omega) \leq x$ son los mismos que en el caso anterior, por lo que $F_{X}(x) = F_{X}(1)$. Continuando de esta manera, se llega a que
\begin{align*} F_{X}(2) &= (1−p)^{3} + 3p(1−p)^{2} + 3p^{2}(1−p), \\[0.5em] F_{X}(x) &= F_{X}(2) & \text{para cada $x \in (2,3)$,} \\[0.5em] F_{X}(3) &= (1−p)^{3} + 3p(1−p)^{2} + 3p^{2}(1−p) + p^{3}, \\[0.5em] F_{X}(x) &= F_{X}(3) & \text{para cada $x \in (3,\infty)$.} \end{align*}
Observa que la expresión para $F_{X}(3)$ corresponde a $(p + (1−p))^{3}$, por el teorema del binomio. En consecuencia, $F_{X}(3) = (p + (1−p))^{3} = 1^3 = 1$. De este modo, obtenemos que la función de distribución de $X$ es la función dada por
\[ F_{X}(x) = \begin{cases} 0 & \text{si $x < 0$,} \\[1em] (1−p)^{3} & \text{si $0 \leq x < 1$,} \\[1em] (1−p)^{3} + 3p(1−p)^{2} & \text{si $1 \leq x < 2$,} \\[1em] (1−p)^{3} + 3p(1−p)^{2} + 3p^{2}(1−p) & \text{si $2 \leq x < 3$,} \\[1em] 1 & \text{si $3 \leq x$.} \end{cases} \]
Nota que a pesar de ser una función con discontinuidades (es una función escalonada), $F_{X}$ sí es continua por la derecha. Observa que también es no-decreciente, y sus límites a $-\infty$ y a $\infty$ son $0$ y $1$, respectivamente; algo que ya esperábamos por el teorema demostrado en esta entrada.

Ejemplo 4. Ahora sea $F\colon\RR\to\RR$ la siguiente función de distribución de probabilidad:
\[ F(x) = \begin{cases} 0 & \text{si $x < 0$,} \\[1em] (1−p)^{3} & \text{si $0 \leq x < 1$,} \\[1em] (1−p)^{3} + 3p(1−p)^{2} & \text{si $1 \leq x < 2$,} \\[1em] (1−p)^{3} + 3p(1−p)^{2} + 3p^{2}(1−p) & \text{si $2 \leq x < 3$,} \\[1em] 1 & \text{si $3 \leq x$.} \end{cases} \]
¡Es la función de distribución de la variable aleatoria $X$ del ejemplo pasado! Sin embargo, nota que aquí te la estamos dando sin ninguna información sobre el espacio de probabilidad subyacente, ni sobre la variable aleatoria involucrada. En primer lugar, ya tenemos garantizado que existe el espacio de probabilidad $(\{0,1\}^{3}, \mathscr{P}(\{0,1\}^{3}), \mathbb{P})$ y la variable aleatoria $X\colon\{0,1\}^{3}\to\RR$ dada por $X(\omega) = {\lVert \omega \rVert}_{1}$, para cada $\omega\in\{0,1\}^{3}$ de tal forma que $F$ es la función de distribución de $X$.
No obstante, observa que podemos definir otra variable aleatoria que resulta en la misma función de distribución. Para ello, toma a $(\RR, \mathscr{B}(\RR), \mathbb{P})$, donde $\mathbb{P}$ es la medida de probabilidad $\mathbb{P}\colon\mathscr{B}(\RR)\to\RR$ definida como sigue: para cada $x\in\RR$, definimos
\[ \Prob{(-\infty, x]} = F(x). \]
Ojo: Esto define la probabilidad de los elementos de $\mathscr{B}(\RR)$ (que son eventos) que tienen la forma $(-\infty, x]$, para cada $x \in \RR$. A su vez, esto define la probabilidad de los eventos de la forma $(a, b]$, para cada $a$, $b \in \RR$ tales que $a < b$, que es
\[ \Prob{(a,b]} = F(b) − F(a), \]
que se puede extender de manera única a una medida sobre todo $\mathscr{B}(\RR)$. Esto es algo que puede demostrarse, pero carecemos de las herramientas para hacerlo en este curso. De cualquier modo, la variable aleatoria que utilizamos en este caso es $Y\colon\RR\to\RR$, la función identidad, dada por
\[ Y(\omega) = \omega, \quad \text{para cada $\omega \in \RR$.} \]
De este modo, se tiene que
\begin{align*} (Y \leq y) &= \{ \, \omega \in \RR \mid Y(\omega) \leq y \, \} \\[0.5em] &= \{ \, \omega \in \RR \mid \omega \leq y \, \} \\[0.5em] &= (-\infty, y], \end{align*}
y por lo tanto, para cada $y \in \RR$,
\[ F_{Y}(y) = \Prob{Y \leq y} = \Prob{(-\infty, y]} = F(y), \]
por lo que la función de distribución de $Y$ es precisamente la función de distribución de probabilidad que escogimos al comenzar este ejemplo. De este modo, $Y$ es una variable aleatoria que puede tomar los valores $0$, $1$, $2$ y $3$… ¡con las mismas probabilidades que la variable aleatoria $X$ del ejemplo pasado! Sin embargo, ¡los espacios de probabilidad sobre los que estas están definidas son completamente distintos! Esto exhibe que lo más importante de una variable aleatoria es su función de distribución, pues esta determina los valores que puede tomar, y la probabilidad con la que los toma. Es decir, la función de distribución caracteriza el comportamiento probabilístico de una variable aleatoria.
¡Presta mucha atención a los últimos dos ejemplos! La conclusión es que el espacio de probabilidad que subyace a una variable aleatoria realmente no importa. Por ello, en muchos libros de probabilidad (y en este mismo curso), no le prestan atención a esto. Comúnmente, te dan una función $F$ que es una función de distribución de probabilidad, y te dicen «sea $X$ una variable aleatoria con distribución $F$». Con eso es suficiente, pues $F$ determina las probabilidades de todos los eventos que involucran a $X$, sin importar quiénes son $X$ y el espacio de probabilidad sobre el que ésta se define.
Tarea moral
Los siguientes ejercicios son opcionales. Es decir, no formarán parte de tu calificación. Sin embargo, te recomiendo resolverlos para que desarrolles tu dominio de los conceptos abordados en esta entrada.
- Determina si la función $F\colon\RR\to\RR$ dada por\[F(x) = \begin{cases} 0 & \text{si $x \leq -1$,} \\[0.5em] \frac{1}{2}(x+1)^2 & \text{si $-1 < x \leq 0$,} \\[0.5em] 1 − \frac{1}{2}(1 − x)^{2} & \text{si $0 < x < 1$,} \\[0.5em] 1 &\text{si $x \geq 1$} \end{cases} \]es una función de distribución de probabilidad. Utiliza su gráfica para auxiliarte, en caso de que lo necesites.
- Demuestra que el límite a $-\infty$ de la función de distribución de una variable aleatoria es $0$ Sugerencia: Revisa la demostración de la propiedad 3 que vimos en el teorema de esta entrada.
- ¿Podrías idear más variables que tengan la misma función de distribución del Ejemplo 3? Por ejemplo, si \(\Omega_{2} = \{0,2\}^{3}\), decimos que \(2\) representa éxito; y definimos \(Z\colon\Omega_{2}\to\RR\) como la función dada por\begin{align*} Z(\omega_{1}, \omega_{2}, \omega_{3}) &= \frac{\omega_{1} + \omega_{2} + \omega_{3}}{2} & \text{para cada \((\omega_{1}, \omega_{2}, \omega_{3}) \in \Omega_{2}\),} \end{align*}¿tiene \(Z\) la misma distribución que la \(X\) del Ejemplo 3?
Más adelante…
Lo siguiente que haremos en el curso es ver los dos tipos de variables aleatorias más importantes que hay, las discretas y las continuas. A grandes rasgos, las discretas son aquellas que pueden tomar una cantidad a lo más numerable de valores distintos, mientras que las continuas son aquellas que pueden tomar una cantidad no-numerable de valores. Es decir, pueden tomar valores en un conjunto cuya cardinalidad es igual a la de $\RR$. En la siguiente entrada abordaremos las particularidades de las variables aleatorias discretas.
Entradas relacionadas
- Ir a Probabilidad I
- Entrada anterior del curso: Variables Aleatorias
- Siguiente entrada del curso: Variables Aleatorias Discretas
excelente informacion