Introducción
Como lo habíamos adelantado, ya podemos definir una primera noción de medida. La idea es tomar «la mejor aproximación» de un conjunto que podamos hacer mediante cubiertas de rectángulos cerrados.
Un primer intento de definir medida: La medida exterior.
Definición. Dado $\Omega \subseteq \mathbb{R}^n$ definimos su medida exterior en $\mathbb{R}^n$, $\lambda^*(\Omega)$ como: $$\lambda^*(\Omega):=\inf \left\{ \sum_{i\in I} |R_i| \ : \ \Omega \subseteq \bigcup_{i\in I} R_i \right\} $$ Donde $R_1,R_2,\dots$ son rectángulos e $I$ es un conjunto de índices a lo más numerable.
Observación. En la definición anterior usamos la convención de que $\lambda^*(\Omega)=\infty$ si y sólo si $\sum_{i\in I} |R_i|$ diverge ($=\infty$) para cualquier cubierta numerable de rectángulos $\{ R_i\}_{i\in I}$ (i.e. «cuando el conjunto es demasiado grande»). Esta convención es compatible con todos los cálculos debajo.
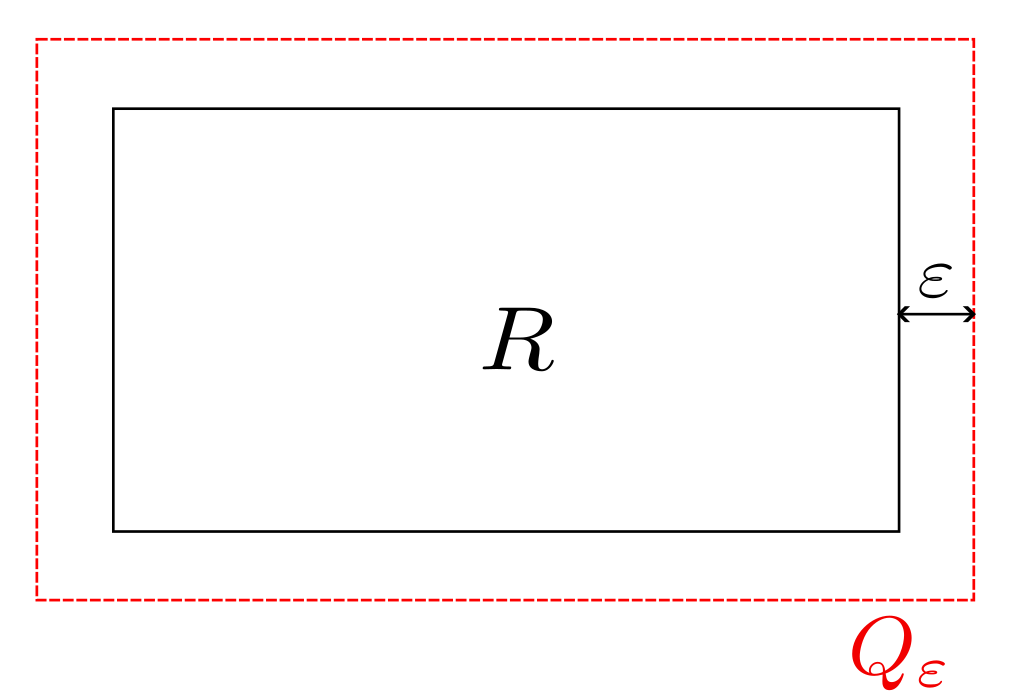
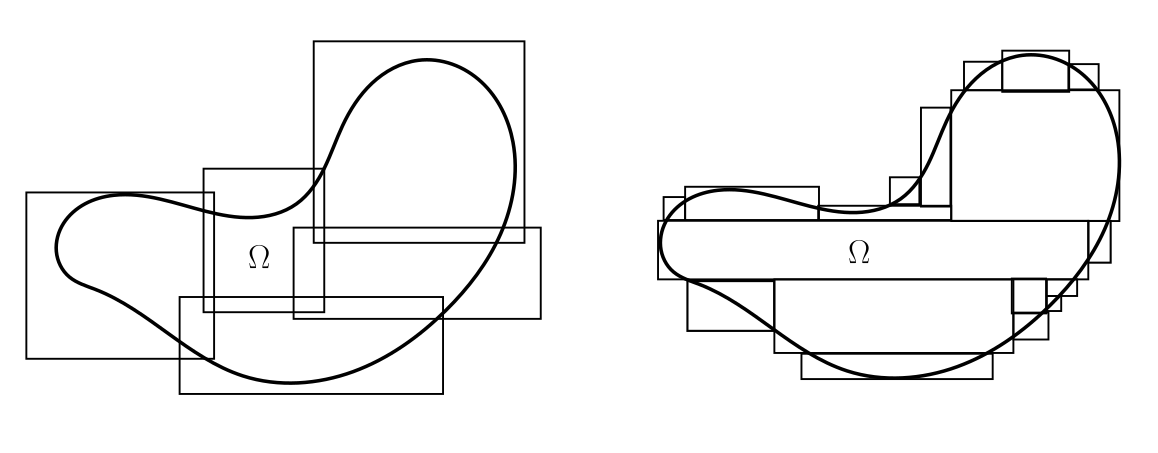
Para que la definición tenga sentido, habría que asegurar que cualquier subconjunto de $\mathbb{R}^n$ se puede cubrir con una cantidad numerable de rectángulos. Esto siempre es posible, considera, por ejemplo, la sucesión de rectángulos anidados $[-k,k]^n$ para $k=1,2,\dots$.
Es fácil convencerse de la necesidad de considerar subcubiertas posiblemente infinitas en la definición. En general no es claro como se podrían aproximar «bien» subconjuntos no acotados con una cantidad finita de rectángulos; ni conjuntos «curvos» como bolas o cilindros. La restricción de que el conjunto de índices sea a lo más numereable es una tecnicalidad. No es obvio como definir una suma con una cantidad no numerable de elementos y con las formas usuales de hacerlo normalmente la suma diverge si hay una cantidad no numerable de términos positivos.
Por simplicidad, en esta entrada nos referiremos a los rectángulos cerrados simplemenete como rectángulos.
Primeras propiedades de la medida exterior.
Proposición.
- (No-negatividad) La medida exterior de cualquier subconjunto de $\mathbb{R}^n$ es no negativa.
- (Medida exterior del conjunto vacío) $\lambda^*(\emptyset)=0$.
- (Monotonía) Si $A\subseteq B\subseteq \mathbb{R}^n$ entonces $\lambda^*(A)\leq \lambda^*(B)$.
- (Invarianza bajo traslaciones) Si $A\subseteq \mathbb{R}^n$ y $x\in \mathbb{R}^N$, entonces $\lambda^*(A)=\lambda^*(x+A)$.
- (Dilataciones) Si $A\subseteq \mathbb{R}^n$ y $c\in \mathbb{R}$, entonces $\lambda^*(cA)=|c|^n\lambda^*(A)$ (donde $cA= \{ ca \ : \ a\in A \}$).
Demostración.
- Notemos que cualquier suma de volúmenes de rectángulos es $\geq 0$ pues el volumen de cualquier rectángulo es $\geq 0$. Por tanto, para cualquier $\Omega$, 0 es cota inferior del conjunto sobre el que tomamos ínfimo, de donde $0\leq \lambda^*(\Omega)$.
- Por vacuidad, cualquier rectángulo degenerado o con volumen arbitrariamente pequeño funge como cubierta para el vacío, por tanto, $\lambda^*(\emptyset)\leq 0$. Por no-negatividad, $\lambda^*(\emptyset)\geq 0$. Se sigue 2.
- Si $A\subseteq B$, cualquier cubierta de rectángulos para $B$ es una cubierta de rectángulos para $A$. Tomando ínfimos sobre todas las cubiertas posibles se sigue 3.
- A cualquier cubierta con rectángulos de $A$: $R_1,R_2,\dots$, le podemos asociar una cubierta «trasladada» para $x+A$: $x+R_1,x+R_2,\dots$. La suma de los volúmenes de los rectángulos sobre ambas cubiertas es igual debido a la invarianza bajo traslaciones del volumen de rectángulos. Inversamente a cualquier cubierta de $x+A$: $Q_1,Q_2,\dots$ le podemos asociar la cubierta de $A$: $-x+Q_1,-x+Q_2,\dots$ la suma de los volúmenes coincide por la misma razón. Se sigue 4. pues los conjuntos sobre los que tomamos ínfimos son de hecho iguales.
- Similarmente al inciso anterior, podemos biyectar las cubiertas de $A$ con las de $cA$: A la cubierta $R_1,R_2,\dots$ de $A$ le asociamos la cubierta $cR_1,cR_2,\dots$ de $cA$ y viceversa. Por las propiedades de dilatación del volumen de rectángulos: $$\sum_{k=1}^{\infty}|cR_k|=|c|^n\sum_{k=1}^{\infty}|R_k|.$$ Tomando ínfimos sobre el conjunto de cubiertas se sigue 5.
$\square$
De momento, hacemos la distinción entre volumen y medida exterior. Aunque es tentador pensar que $|R|=\lambda^*(R)$ si $R$ es un rectángulo cerrado (y de hecho es cierto), ¡hay que probarlo! La desigualdad $\lambda^*(R)\leq |R|$ es obvia al considerar la cubierta de $R$ con el propio $R$. Sin embargo la desigualdad opuesta requiere más trabajo. No es trivial probar que $|R|$ es cota inferior de las sumas de volumenes sobre cubiertas de rectángulos para $R$.
Algunos ejemplos básicos
En general, es bastante complicado calcular la medida exterior de un conjunto arbitrario. Sin herramientas más avanzadas, lo único que podemos hacer es dar cubiertas de rectángulos cuya suma de volumenes se aproxime cada vez más a cierto valor y probar que dicho valor es una cota inferior para cualquier tal suma.
Cuando un conjunto tiene medida exterior cero, este proceso se suele simplificar bastante pues ya sabemos a priori que 0 es una cota inferior, así que basta dar cubiertas de rectángulos tal que las sumas de volúmenes se hagan arbitrariamente pequeñas.
Veamos un par de ejemplos importantes de conjuntos con medida exterior cero (o conjuntos nulos). Próximamente, aplicaremos métodos similares para calcular la medida exterior de otros conjuntos sencillos, como rectángulos y triángulos. Las técnicas de teoría de integración facilitarán en gran medida el cálculo de la medida (exterior) de conjuntos mucho más complicados.
Ejemplo. La medida exterior de un punto $\{ x \}$ con $x\in \mathbb{R}^n$ es 0. Por no-negatividad $\lambda^*(\{ x \})\geq 0$. Como el propio $\{ x \}$ es un rectángulo de volumen 0 (degenerado), al considerar la cubierta trivial $\{ x \}$, por definición de ínfimo $\lambda^*(\{ x \} )\leq |\{ x\}|=0$.
$\triangle$
Ejemplo. La medida exterior de un hiperplano $H=\mathbb{R}^{n-1}\times\{ 0\}\subseteq \mathbb{R}^n$ es 0. Consideremos la cubierta con rectángulos degenerados $\{ R_k \}_{k=1}^{\infty}$ donde $$R_k= [-k,k]\times[-k,k]\times\dots\times [-k,k]\times \{ 0\}.$$ Es claro que $H=\bigcup_{k=1}^{\infty}R_k$ y $|R_k|=0$ para todo $k$. Así $$ 0\leq \lambda^*(H)\leq \sum_{k=1}^{\infty}|R_k|=\sum_{k=1}^{\infty}0=0.$$ De donde $\lambda^*(H)=0$.
$\triangle$
Ejemplo. La medida exterior de un conjunto numerable $S=\{x_1,x_2\dots \}$ es 0. Uno simplemente puede tomar la cubierta trivial con rectángulos degenerados $\{x_1\},\{x_2 \},\dots$ Como cada uno de estos tiene volumen 0, usando la no-negatividad y la definición de ínfimo: $$0\leq \lambda^*(S)\leq \sum_{k=1}^{\infty} |\{ x_k \}|=\sum_{k=1}^{\infty}0=0.$$ De manera alternativa (y posiblemente mas ilustrativa para lo que sigue) podemos aproximar usando solamente rectángulos no degenerados:
Sea $\varepsilon>0$ arbitrario. Para cada $k=1,2,\dots$ tomemos un rectángulo no degenerado $R_k$ tal que $x_k\in R_k$ y el volumen de $R_k$ sea $<\frac{\varepsilon}{2^{k}}$ (siempre podemos hacer esto, imitando por ejemplo el argumento en la aproximación mediante rectángulos abiertos). Consideremos la cubierta por rectángulos $S\subseteq \bigcup_{k=1}^{\infty} R_k$, luego: $$0\leq \lambda^*(S)\leq \sum_{k=1}^{\infty}|R_k|<\sum_{k=1}^{\infty} \frac{\varepsilon}{2^{k}}=\varepsilon.$$
Como lo anterior es cierto para cualquier $\varepsilon>0$ necesariamente $\lambda^*(S)=0$.
$\triangle$
El ejemplo anterior es un caso particular de un resultado más general que será útil en el futuro.
Proposición. Si $A_1,A_2,\dots$ son subconjuntos de $\mathbb{R}^n$ tales que $\lambda^*(A_k)=0$ para todo $k\in \mathbb{N}$, entonces $$\lambda^*\left( \bigcup_{k=1}^{\infty}A_k \right)=0.$$
Demostración. Fijemos $\varepsilon>0$. Como $\lambda^*(A_k)=0$, por definición de ínfimo podemos encontrar una colección de rectángulos $\{ R^k_j\}_{j=1}^{\infty}$ tales que $$A_k\subseteq \bigcup_{j=1}^{\infty} R^k_j$$ Y $$\sum_{j=1}^{\infty}|R^k_j|<\frac{\varepsilon}{2^k}.$$ Consideremos la cubierta de rectángulos $\{ R^k_j\}_{j,k\in \mathbb{N}}$. Notemos que $$\bigcup_{k=1}^{\infty}A_k\subseteq \bigcup_{k,j\in \mathbb{N}}R^k_j.$$ Por lo tanto \begin{align*} 0 &\leq \lambda^*\left( \bigcup_{k=1}^{\infty} A_k \right) \\ &\leq \sum_{j,k\in \mathbb{N}}|R^k_j| \\ &=\sum_{k=1}^{\infty}\sum_{j=1}^{\infty}|R^k_j| \\ &\leq \sum_{k=1}^{\infty} \frac{\varepsilon}{2^k} \\ &= \varepsilon.\end{align*}
Como lo anterior es cierto para cualquier $\varepsilon>0$, concluimos que $$\lambda\left( \bigcup_{k=1}^{\infty}A_k \right)=0.$$
$\square$
Más adelante…
Continuaremos estudiando la medida exterior. Veremos una definición equivalente de la medida exterior usando rectángulos abiertos. También probaremos que el volumen coincide con la medida exterior de un rectángulo.
Tarea moral
- Sea $H^k_a$ un hiperplano de la forma $H^k_a=\{ (x_1,x_2,\dots, x_k,\dots, x_n) \ | \ x_k=a\}$. Demuestra que $\lambda^*(H^k_a)=0$.
- Demuestra que si $A\subseteq B$ y $\lambda^*(B)=0$, entonces $\lambda^*(A)=0$.
- Demuestra que para cualquier rectángulo $R$, $\lambda^*(\partial R)=0$, donde $\partial R$ denota la frontera del rectángulo. [SUGERENCIA: $\partial R$ está contenida en una unión finita de hiperplanos].